Напомню предысторию. Меня зовут Алексей Редозубов и я занимаюсь
созданием сильного искусственного интеллекта. Мой подход крутится
вокруг контекстно-смысловой модели работы мозга. Об этом был цикл
статей на хабре и много видео на Youtube. Сейчас я хочу рассказать
об основах контекстно-смысловой модели и о недавних исследованиях,
которые позволили взглянуть на эту модель с новой, неожиданной
стороны. Исследованиях невероятных настолько, что уверен многие
сочтут их безумием.
Есть два интересных и важных термина искусственный интеллект
(ИИ) и сильный искусственный интеллект
(СИИ). В английской традиции Artificial
intelligence (AI) и Artificial general intelligence (AGI). Первый
подразумевает любую деятельность компьютера, имитирующую
человеческий интеллект, второй только такую, которая претендует на
что-то универсально общее, похожее на то, как мыслит человек.
Точного определения СИИ нет. Лучшее, что есть это знаменитый
Тест Тьюринга.
Человек взаимодействует с одним компьютером и одним
человеком. На основании ответов на вопросы он должен определить, с
кем он разговаривает: с человеком или компьютерной программой.
Задача компьютерной программы ввести человека в заблуждение,
заставив сделать неверный выбор.
Если человек признает, что не может отличить двух скрытых
собеседников, то можно говорить о достижении компьютером уровня
СИИ.

Отметим очень тонкий и при этом очень важный момент. Простой ИИ
может во много раз превзойти человека в какой-то области. Например,
сильнее играть в шахматы, обыгрывать в Го или Starcraft. Но от
этого он не становится сильным.
В английском названии СИИ не случайно называется общим или
универсальным. Суть этого названия в том, что СИИ должен уметь
решать не одну конкретную задачу и даже не широкий набор задач, он
должен быть человекоподобным. То есть обладать способностью, начав
с нуля, вникнуть в любую область и начать ориентироваться в ней
подобно тому, как это способен делать человек. И желательно не хуже
человека.
И тут мы приходим к понятию смысл. В принципе, отличие человека
от современных программ заключается в том, что программы и
алгоритмы пока не способны уловить суть того, что происходит или о
чем говорится. Они оперируют выученными шаблонами, не задаваясь
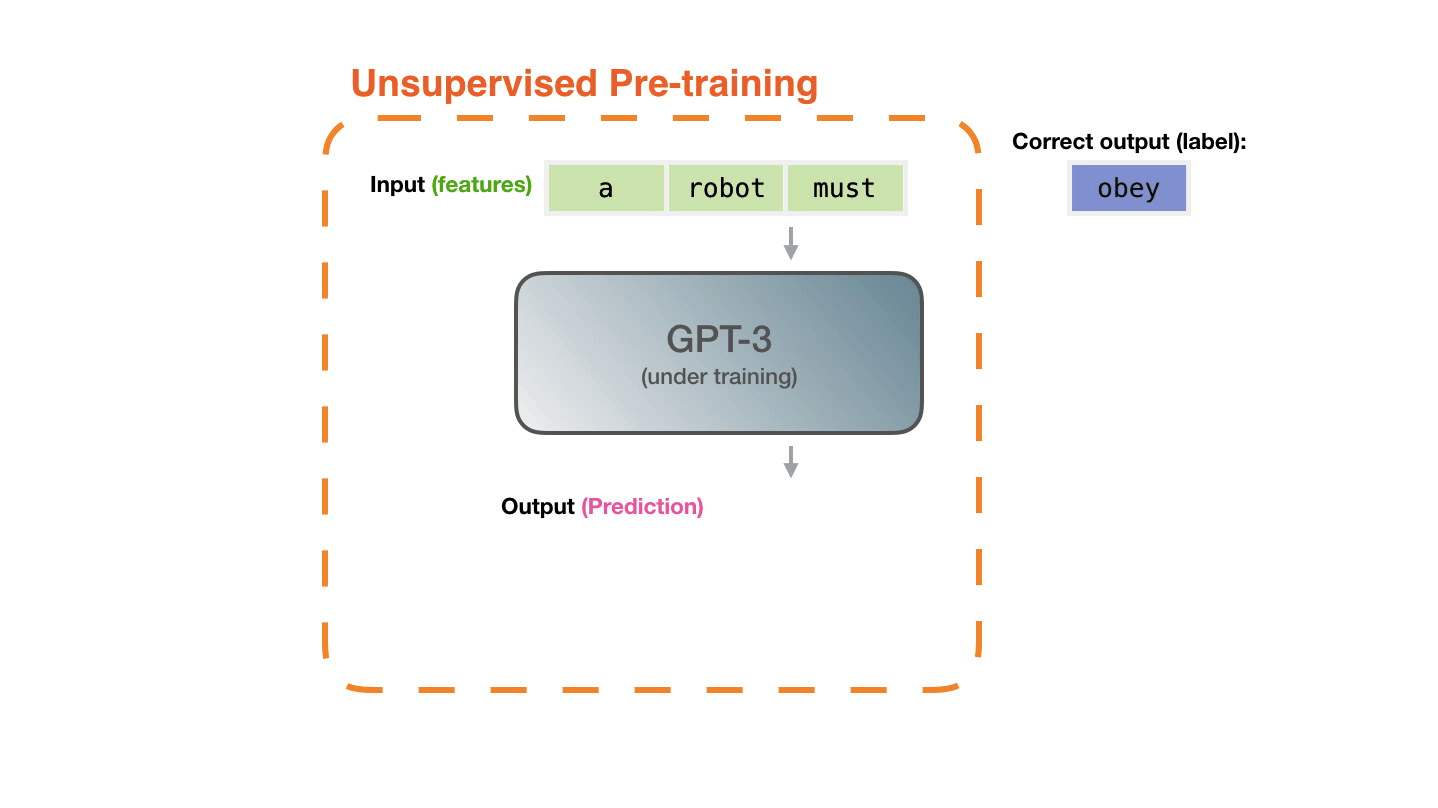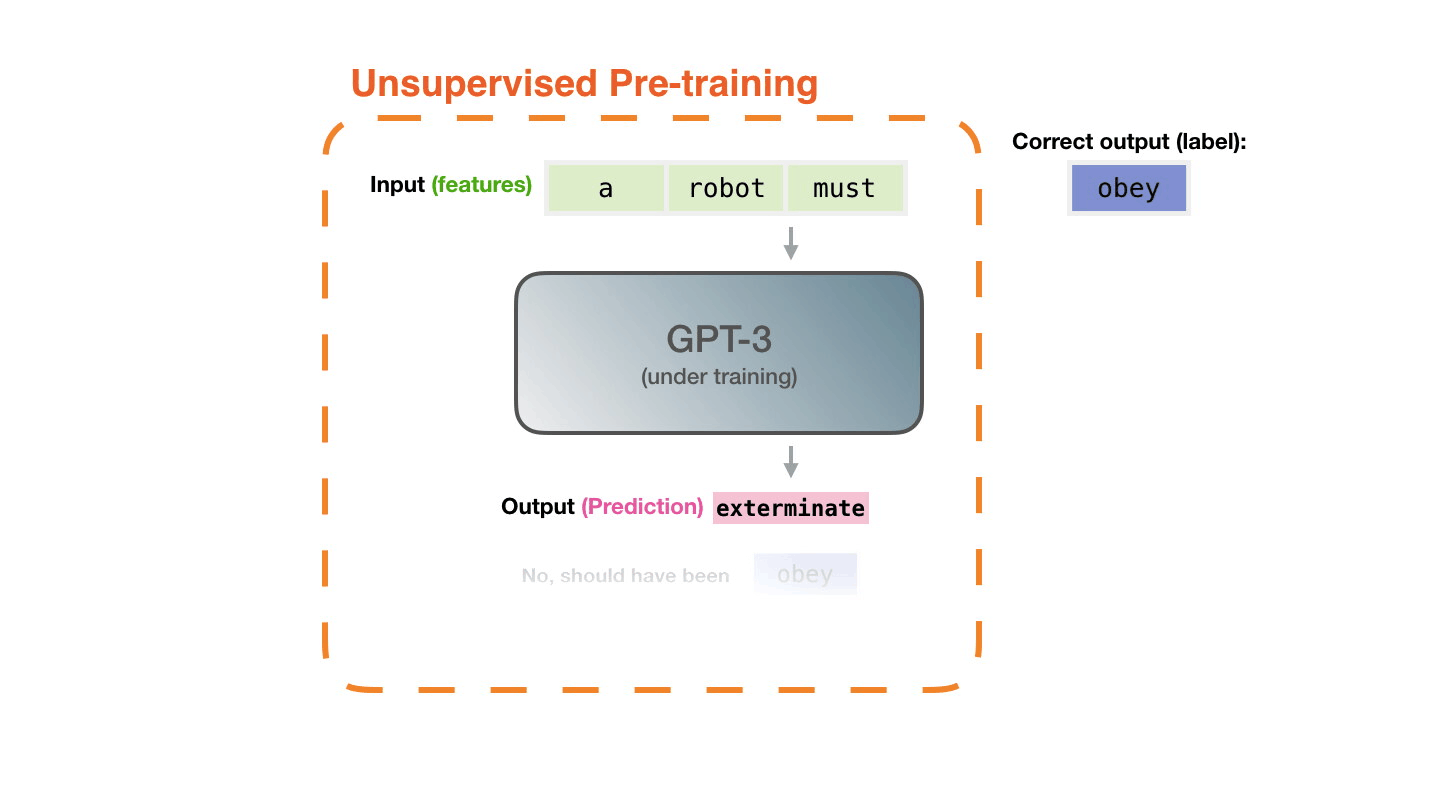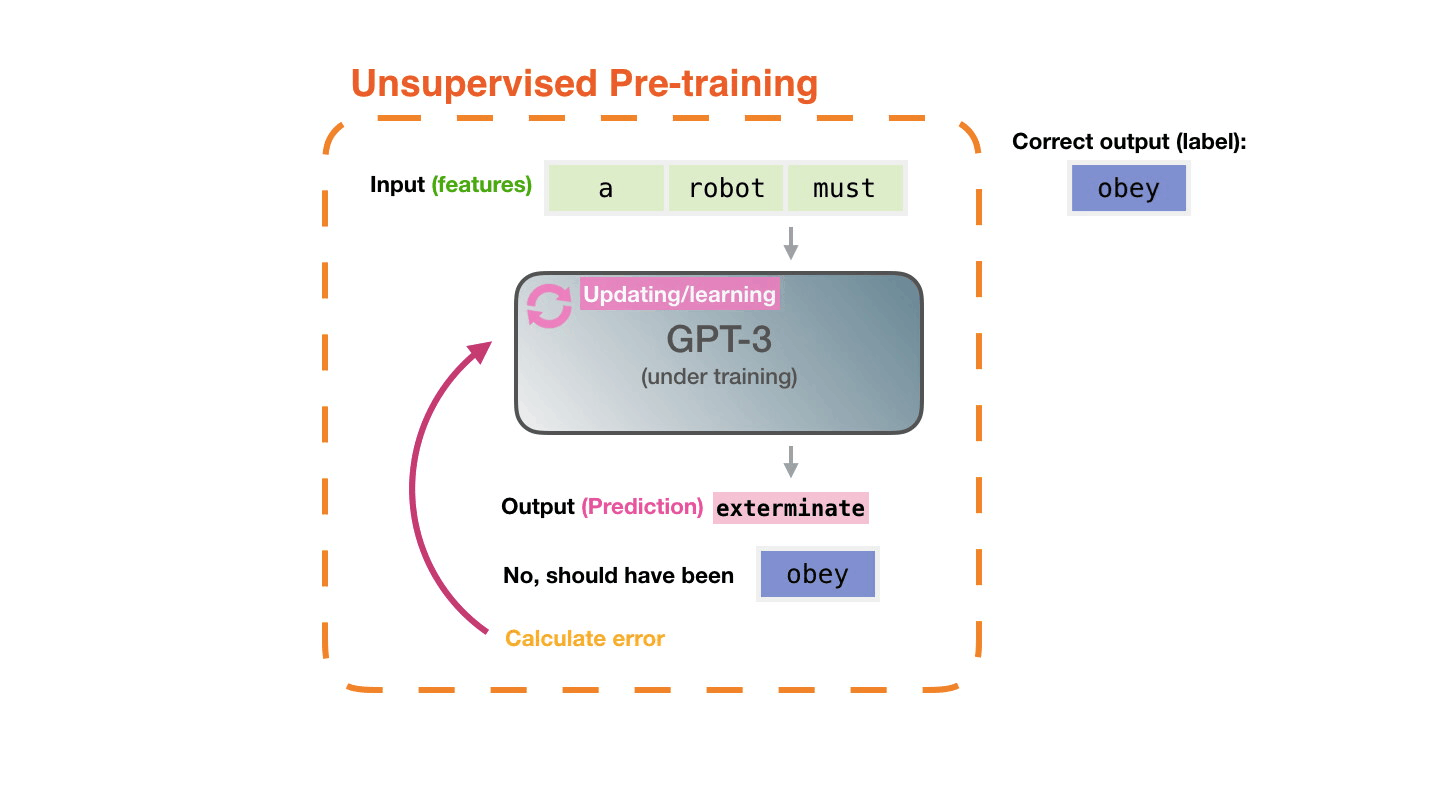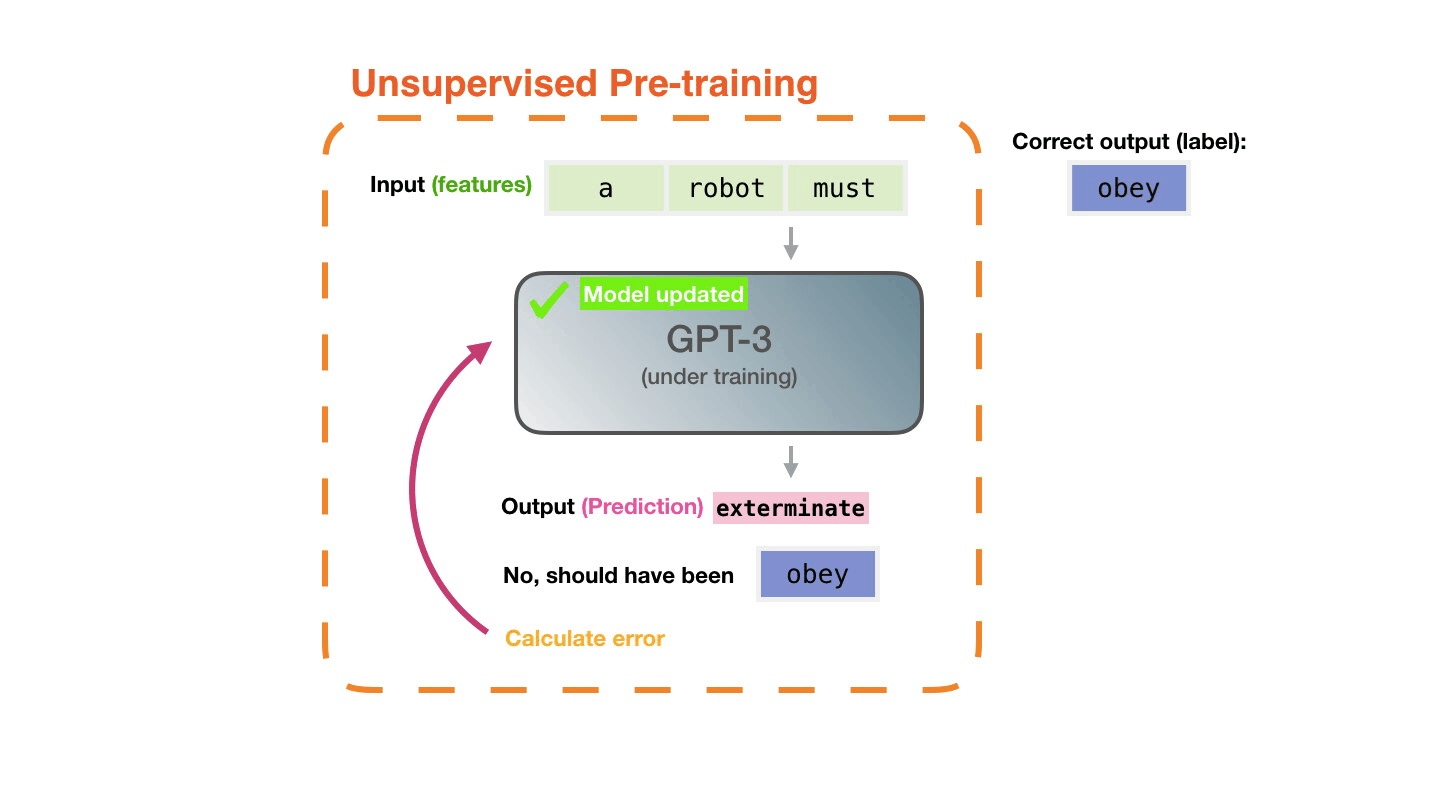
вопросом о смысле. Даже великий и могучий GPT3 является, по сути,
огромным генератором правдоподобного бреда и даже близко не
приближается к пониманию того, что он генерирует.
Берусь утверждать, что для создания СИИ в первую очередь надо
понять, что есть смысл. Но легко сказать. Вся современная философия
построена вокруг различных попыток это сделать. Но результата,
который можно было бы описать формально и запрограммировать, пока
нет.
Как же формально описать смысл? Для начала надо договориться, о
каком смысле пойдет речь. Слова коварны, каждый может дать свое
определение смысла и быть совершенно прав внутри данного им
определения. Двое с разными определениями могут спорить до хрипоты
и никогда ни о чем не договорятся; собственно, философия яркий тому
пример. Нас будет интересовать то понимание смысла, что существует
у людей интуитивно и то, которое ложится на суть теста
Тьюринга.
Тут надо пояснить. Еще Сократ обнаружил удивительную вещь. Люди
знают язык, понимают его слова, тонко чувствуют, когда какое слово
уместно употребить, но редко когда могут объяснить свое знание. То
есть наш мозг знает много больше, чем мы можем объяснить. Сейчас
такие знания принято называть имплицитными.
Интересно, что когда человек пытается объяснить то, что знает
его мозг, он не может получить непосредственный доступ к этим своим
знаниям. Например, он не может их просто вспомнить. Знания есть, но
они недоступны. Доступен только результат использования этих
знаний.
Поясню на примере. Прочитав шутку, вы смеетесь. Объявление:
меняю бензопилу на протез. Но если вас спросить, что в шутке
смешного, вы озадачитесь и скорее всего дадите объяснение, которое
будет неверным. Если бы ваше объяснение было верным, то вы, зная
секрет юмора, могли бы легко придумывать смешные шутки и стать
знаменитым юмористом. Ваш мозг всегда знает, смешно или не смешно,
но вы практически никогда не можете объяснить, почему. Более того,
ваш мозг тонко чувствует разницу между просто смешным и юмором, а
вы?
Так вот, мы будем говорить о смысле в том понимании, какое стоит
за этим словом, когда мы используем его в речи, не пытаясь дать ему
четкого определения. Дело в том, что наивное определение, которое
дается, пока явление еще не понято, будет обязательно построено на
неких видимых признаках и в итоге опишет нам совсем другое. Платона
попросили дать определение человека. Он сказал: двуногое без
перьев. Диоген принес ощипанного петуха и сказал: вот человек.
Сказанное не значит, что смысл непостижим и не может быть
выражен словами. Просто сложные явления не стоит недооценивать.
Кстати, для извлечения неочевидных скрытых знаний Сократ придумал
удивительный метод, который так и называется: метод Сократа. Метод
актуален сегодня, как был и во все времена, очень рекомендую.
Итак, приступим к извлечению природы смысла. Чтобы описывать
окружающий мир, наш мозг в результате эволюции приобрел возможность
формировать внутренние понятия. Такое
представление сегодня достаточно распространено, на нем основана
когнитивная
психология, согласимся с этим и мы.
Формирование внутренних понятий происходит под воздействием
опыта, который человек получает из окружающего мира. Хотелось бы
сказать, что явления, окружающие нас, приводят к
отражению их в понятия. Но беда в том, что в самом мире явлений
нет, явление это тоже одно из наших понятий. Скажем так: наличие в
окружающем мире определенной структуры приводит к формированию
понятий, способных адекватно эту структуру описать.
В какой-то момент эволюции у человека появился
язык. Внутренним понятиям были сопоставлены
слова. Устные слова это просто звуки, они не несут
смысла сами по себе. Но будучи связанными с понятиями, передают их
значения. То есть за содержание отвечает внутреннее понятие, а
слово это внешняя форма понятия. При этом надо учитывать, что
далеко не всем внутренним понятиям соответствуют какие-либо
слова.
Язык развивался и в нем появлялись новые слова. Кроме
непосредственно обозначения того, что видно или слышно, в языке
стали появляться слова, обозначающие некие сложные, порой
абстрактные явления. Люди открывали для себя эти явления и через
язык давали им названия. Например, так появились слова: понятие,
логика, определение и тому подобные.
Для появления внутренних понятий, в принципе, язык не нужен. Они
сформируются и без него. Своя система понятий сформируется и у
Маугли. Но с момента своего появления язык стал влиять на то, какая
именно система внутренних понятий формируется у людей. Образование
понятий напоминает рост виноградных лоз. Для лозы направляющая
служит опорой и задает направление ее роста. Сколько есть
направляющих, столько лоз их обовьет. Для формирования внутренних
понятий слова языка во многом служат такими направляющими.
Изобретенные когда-то слова, обозначающие некие абстракции, и
сегодня позволяют сформироваться у нас понятиям, которые не
возникли бы сами по себе без участия языка.
И вот мы подходим к самому интересному. Хорошо, внутри у нас
есть набор понятий. За каждым понятием стоит некое содержание. Но
как мозг это содержание описывает? Что это за содержание? Каков его
механизм? Собственно, это и есть те самые главные вопросы, от
ответа на которые все зависит. Ведь, по сути, мы говорим о том, что
за каждым понятием стоит некий смысл. И этот смысл
и определяет содержание понятия. То есть, когда мы говорим, что
мозг умеет, наблюдая за миром, формировать понятия, мы говорим о
том, что мозг умеет формировать описания смыслов.
Заданные вопросы очень коварны. Дело в том, что ответы на них
слишком очевидны. Предположим, вы бог и вам надо запрограммировать
мозг. Как вы в своей программе зададите понятия? Скорее всего так
же, как естественным образом это сегодня пытаются сделать многие
создатели ИИ. Попробуем воспроизвести их рассуждения.
Чтобы сформировать набор понятий, описывающих мир, надо поделить
этот мир на области, которые можно назвать, например, классами,
кластерами или как-либо еще в зависимости от вкуса. Чтобы было
проще, стоит, посмотрев на число слов в языке, ограничить себя,
например, набором из десятка тысяч понятий. Каждое из понятий
должно объединять похожие друг на друга явления. Но из-за бушующего
многообразия явлений (в море каждая волна уникальна) эти классы
нельзя задать простым перечислением. Надо придумать что-то более
универсальное.
Вполне логично дальше для каждой группы явлений, относящихся к
одному понятию, создать свой прототип. То есть вычислить образ
идеального явления.
Чтобы описать портреты явлений, нам понадобятся признаки. На
роль признаков подходят другие более мелкие явления. Удава можно
измерить в попугаях. Признаки, конечно, сами потребуют описаний, но
тут мы выкрутимся, сделав многоуровневую конструкцию и пойдем от
простого к более сложному.
Если мы запишем признаки в вектор, то получим очень удобное
признаковое описание.
Например, это может быть вектор, в котором каждое число указывает
на степень выраженности соответствующего признака в явлении. Можно
придумать и что-то посложнее, не суть.
Дальше нам понадобится обвести прототипы границами. Что внутри
границ относится к понятию, что выходит нет. Для этого придется
придумать некую метрику, которая позволит, взяв одно описание,
сравнить его с другим. Если мы имеем дело с векторами, то таких
метрик сотни и можно выбирать любую по вкусу.
Конечно, если подходить серьезнее, то имея учителя, который
скажет, какое явление к какому понятию относится, мы сможем не
только рассчитать центр класса и назвать его прототипом, но и
вычислить характер распределения. Это может сильно помочь на
практике. Средний вес килограммовой гири один килограмм. Средний
вес курицы 3 килограмма. Нечто весом кило сто, исходя из
распределений, скорее будет курицей, чем гирей. Хотите знать
подробнее, смотрите методы классификации и кластеризации, расстояние
Махаланобиса.
Рано или поздно обнаружится, что все явления многогранны, тогда
можно будет усложнить схему. Например, искать ключевые признаки,
определяющие явление, либо пытаться для каждого явления задать
набор его возможных проявлений и очертить границы вокруг них.
Собственно, вот вам краткий курс нейронных сетей.
Сухой остаток: понятия можно задать через перечисление их
признаков, тем самым разбив мир на области. Затем можно
совершенствовать описания, уточняя прототипы и границы вокруг них.
Разделяй и властвуй.
Так действительно можно сделать. На этом основаны методы
математической статистики, в этом основная идея машинного обучения,
на этом же фундаменте построен колосс нейронных сетей.
Так в чем подвох? А в том, что когда заходит речь о словах языка
и, как следствие, о стоящих за ними понятиях, то в первую очередь
всплывает именно такая модель. И полагается вполне очевидным, что,
видимо, мозг делает точно так же. Что, как и в искусственной
нейронной сети, в мозгу есть нейроны бабушки,
бодро реагирующие на ее появление и хранящие на своих весах ее
портрет.
Другими словами, кажется вполне очевидным, что у каждого понятия
есть его определение. А значит, потрудившись,
можно дать определения всем понятиям и тем самым понять скрытые
знания человека.
И тут мы возвращаемся к смыслу. С одной стороны, за каждым
понятием стоит его смысл. С другой, мы только что рассудили, что
понятию можно дать определение. Выходит, что определение и есть
смысл? Очевидно, что нет. Но в чем тогда разница? И тут приходит
спасительная мысль: даже если определение пока не соответствует
смыслу, то можно постараться определение уточнить, приблизив к
оному. Напрашивается вывод, что определение понятия это его
недоделанный смысл, который при желании можно доделать. И тогда
смысл хочется истолковать как некое идеальное определение. Отсюда
возникает вера, что усложняя описания понятий, создавая онтологии,
описывая связи между понятиями, мы рано или поздно сможем постичь
смысл и создать СИИ.
В популярном буддистском коане говорится: Рыжая корова проходит
мимо окна. Голова, рога и четыре ноги прошли. Почему не может
пройти хвост?. В математике беда почти всегда приходит с одной и
той же стороны. И имя этой стороны комбинаторный взрыв.
Имея дело с тепличными примерами, не нарадуешься красоте
определений. Но стоит только выйти в поле, и все идет прахом. Любое
реальное явление начинает давать такое разнообразие проявлений, что
никакие вычислительные мощности и датасеты не могут за этим
разнообразием угнаться. Все время кажется, что осталось еще совсем
немного дообучить модель и все будет хорошо. Мы слышим: автопилот
для автомобилей уже почти готов, осталось пару месяцев. На моей
памяти эти пару месяцев слышатся последние года три. Правда, сейчас
говорят: три месяца и точно. Проклятие размерности оно такое. К
сожалению, корову не определяет ни ее цвет, ни ее рога и ни ее
копыта, и хвосту всех признаков никогда не пройти мимо.
В этом и есть разница между ИИ и СИИ. Простой ИИ строится на
использовании сущностей, заданных определениями. Отсюда классы,
кластеры, тезаурусы, онтологии, нейроны бабушки и тому подобное.
СИИ, который может пройти тест Тьюринга это, в первую очередь,
интеллект, оперирующий смыслом.
Так что же такое смысл и чем он отличается от определения?
Попробую объяснить. Предположим, есть нечто, на что мы смотрим.
Допустим, мы не узнаем предмет перед нами. Тогда мы можем изменить
точку зрения и посмотреть на него с другой стороны. Если изучаемый
предмет в принципе нам знаком, то должна найтись такая точка
зрения, с которой мы его, наконец, узнаем. На этом можно было бы и
закончить, предмет опознан, что еще? Но важно (и об этом часто
забывают), что кроме того, что нам удалось понять, что перед нами,
мы еще узнали и точку зрения, глядя с которой, у нас все и
сложилось.
Почему это важно? Дело в том, что любое понятие может быть
точкой зрения. За всяким понятием стоит явление, которое меняет
наше восприятие мира. Одно и то же мы начинаем видеть по-разному в
зависимости от того, через призму какого явления мы смотрим. Ицик,
сколько будет дважды два? А мы таки покупаем или продаем?. Так вот,
если, глядя через призму явления, мы увидим правдоподобную картину,
то это будет означать, что скорее всего в этот момент присутствует
и само явление. Дважды два пять продаем, три покупаем.
То есть самого явления может быть вообще не видно, но по его
влиянию на картину мира мы можем понять, что оно есть. Это как тот
Чеширский кот, когда сначала появляется его улыбка, а вслед за ней
сам кот.
Уловили идею? Вы видите комнату и в ней разбитую вазу. Сначала
это просто разбитая ваза. Но если посмотреть на это в
предположении, что в комнате есть кот, то появляется картина кот
задел вазу и она, упав, разбилась, вот она, улыбка. Эта картина
оказывается вполне правдоподобной. В этот момент вслед за своей
улыбкой появляется и он сам. То есть вы узнали кота, вообще не видя
ни его, на каких-либо его непосредственных признаков.
Настоящая магия заключается в том, что для каждого явления,
наблюдая за ним, можно составить правила, по которым из
исходного описания получается его
трактовка. То есть любое явление может быть
контекстом, в котором исходное описание заменяется
его трактовкой в этом контексте.
Что это дает? Это позволяет проделать мысленный эксперимент.
Имея сформированный контекст, для любой входной
информации можно, используя вычисленные правила,
получить трактовку в этом контексте. Это как, имея волшебную лампу
Аладдина, посмотреть, что будет, если примерить на людей другие
роли. Получится ли что-то разумное или же выйдет полный бред.
Важно, что осмысленная трактовка появляется в контексте только
тогда, когда есть существенная вероятность, что присутствует
соответствующее явление. Отсюда возникает алгоритм. Возьмем все
слова языка, сформируем вокруг них контексты, то есть вычислим
правила трактовок. Теперь, когда будет поступать новая информация,
будем смотреть, в каких контекстах трактовка оказалась наиболее
достоверной.
В этом можно увидеть многое от байесовского подхода.
В нем, используя накопленные данные, для каждого интересующего нас
события строится условная плотность распределения. То есть строится
картина того, как будет выглядеть распределение при условии, что
данное событие уже реализовалось. Затем новые данные примеряются к
этой плотности для того, чтобы оценить, насколько достоверно они
выглядят на фоне этого распределения. Проделав это для всех
возможных событий, можно судить о том, в каком предположении все
выглядит наиболее достоверно, и из этого сделать заключение о
присутствии соответствующего события.
Но как в случае контекстов оценить достоверность трактовки?
Очень просто трактовка должна выглядеть, как что-то нам ранее
знакомое. Это значит, что надо иметь память того, что мы знаем, и
сравнивать трактовку с памятью. Увидели что-то знакомое, значит,
контекст подходит. Причем во всех контекстах память должна быть
одна и та же.
Тут напрашивается сравнение со сверточными сетями. В
них один и тот же набор ядер свертки (одна и та же память)
примеряется к разным частям изображения. Там, где есть совпадение,
мы говорим об обнаружении соответствующего образа. При этом сами
позиции, в которых осуществляется свертка, по сути, выступают в
роли контекстов. Мы примеряем известные нам картинки в
предположении, что эта картинка сдвинута к соответствующей позиции.
Поясню, ядро свертки это маленькая картинка. Она примеряется к
какому-то месту большой картины. Это равносильно тому, что мы взяли
пустую большую картину, в центре которой разместили маленькую
картинку. Сдвинули маленькую картинку к нужному месту, а затем
сравнили две больших картины.
Но у наших контекстов есть принципиальные отличия и от
байесовского подхода, и от сверточных сетей. Самое главное в том,
что там к неизменной входной информации примеряется некое искажение
памяти. Вот искаженное по отношению к исходному условное
распределение. Вот ядра свертки, перемещенные так, чтобы оказаться
в нужном месте изображения. У нас же память всегда остается
неизменной, а искажается входная информация. Вместо исходного
описания в каждом контексте появляется его трактовка. Если гора не
идет к Магомету, то Магомет идет к горе.
Кроме того, в сверточных сетях важно то, что увидели. В
байесовском подходе то, где увидели. У нас же и что увидели, и где.
Но, пожалуй, самое главное отличие это возможность автоматически
построить пространство контекстов. В сверточных сетях правила
свертки воспринимаются как нечто естественное, следующее из законов
геометрии, и вопрос об их формировании не ставится. Зачем, если
они, правила, и так понятны? Мы же говорим, что для любой
информации можно сформировать пространство контекстов, обучив
контексты соответствующим правилам трактовки. Кстати, мы показали,
как в зрительной истории контексты, соответствующие правилам
свертки относительно несложно получаются при самообучении.
В результате получается, что полное задание конкретного понятия
требует трех вещей. Нужны:
-
имя понятия. Слово языка или внутреннее кодирование имени
понятия.
-
правила трактовки. Правила преобразования, индивидуальные для
каждого контекста.
-
память. Накопленный ранее опыт, один и тот же для всех
контекстов.
И работает эта триада не по отдельности, для каждого понятия, а
только в пространстве всех понятий, где происходит сравнение
результатов между собой.
Теперь возвращаемся к смыслу. Смысл понятия это и есть
описывающий его контекст, состоящий из правил трактовки и памяти.
Смысл информации это тот контекст, в котором трактовка выглядит
достоверно, и сама полученная трактовка. И, заметьте, что смысл не
сводится к определению. Он имеет совсем другую природу, в которой
нет привычного прототипа и границ вокруг него.
Поясню все на моем любимом примере. Во время второй мировой
войны немцы использовали шифровальную машину под названием Энигма. Сообщение на
входе перекодировалось так, что одни буквы заменялись другими по
достаточно сложным правилам. Кодирование происходило с помощью
ключа. Если на принимающей стороне ключ был известен, то можно было
через обратное преобразование восстановить исходное сообщение.

Шифровальная машина Энигма
Примерно в декабре 1932 года Мариан Реевский,
польский математик и криптоаналитик, смог разработать алгоритмы,
позволяющие потенциально взломать код Энигмы. В это же время
французской разведке удалось получить ключи, реально используемые
немцами, и передать полякам. Анализируя перехваченные сообщения,
Реевскому удалось восстановить внутреннюю схему Энигмы. Для
расшифровки немецких сообщений поляки построили шесть машин, бомб,
которые позволяли за разумное время перебрать 100 000 возможных
кодов и найти среди них верный.
В 1938 году немцы усложнили конструкцию Энигмы, в результате
чего расшифровка ее сообщений стала в десять раз сложнее. За пять
недель до вторжения Германии в Польшу в 1939 году Реевский и его
коллеги передали свои результаты французской и британской разведке.
Это позволило англичанам построить в Блетчли-парк батарею из бомб,
которая успешно взламывала немецкие коды на протяжении всей
войны.
Определенную роль в этом сыграл тот самый Алан Тьюринг, что
придумал приведенный в начале тест.
Немецкие шифровальщики могли ежедневно менять коды, поэтому
главной задачей англичан было найти актуальный код, после чего все
остальное становилось делом техники. Для этого приходилось брать
сообщение и перебирать с помощью бомб миллион возможных вариантов.
То есть смотреть на сообщение в миллионе возможных контекстов,
получая миллион его потенциально возможных трактовок. Если код был
неверен, то на выходе получался бессмысленный набор знаков, но как
только обнаруживался правильный код, сообщение приобретало смысл.
Главный вопрос был в том, как без участия человека понять, что
сообщение получилось осмысленным?
Оказалось, что каждая ежедневная немецкая метеосводка
заканчивалась одной и той же подписью хайль Гитлер. Зная это,
англичане брали утреннюю метеосводку и перебирали коды до тех пор,
пока эта подпись не появлялась в конце сообщения.
Можно было бы обойтись и без известной подписи, а ждать, чтобы
слова в сообщении стали правильными, то есть соответствующими
немецкому языку. Это и есть сравнение трактовки с памятью для
определения ее достоверности.
И самое главное при расшифровке прогноза погоды англичан не
интересовал сам прогноз погоды. Был важен контекст, то есть код, в
котором получалась удачная расшифровка. Напомню, что в
контекстно-смысловом подходе удачная трактовка это только часть
расшифрованной информации, другая часть это контекст, в котором эта
трактовка возникла.
Замечу, что разбираясь с контекстным подходом, удобно
представлять себе Энигму и ее коды. Если понять правильные
сопоставления, многое становится простым и понятным.
Для полноты картины отмечу, что кора человеческого мозга делится
на зоны, которые в свою очередь состоят из миниколонок. Каждая
из миниколонок это порядка сотни нейронов, расположенных
вертикально, с плотными связями между собой и менее плотными по
сторонам. У меня есть статьи, где показывается, что каждая из
миниколонок является реализацией отдельного контекстного модуля и
что память зоны коры продублирована в каждой из ее миниколонок. При
этом сами зоны коры являются пространствами контекстов. Таким
образом, анализируя информацию, человек одновременно рассматривает
ее во множестве различных контекстов, выбирая из них наиболее
подходящие. Я полагаю, что мышление человека основывается именно на
контекстно-смысловых принципах.
Конечно, это только начало разговора о контекстах. Далее должен
следовать разговор о форме кодирования понятий, о методах хранения
памяти, о механизмах поиска закономерностей, о рекуррентной модели,
реализующей формальные грамматики, о пространственной организации
контекстов, о реализации обучения с подкреплением, о формировании
удачных описаний и многое другое. Подробнее об этом есть в цикле лекций Логика
сознания.
Все, что было сказано, было странно, но не безумно. А где же
обещанное безумие? Начнем.
Разрабатывая контекстно-смысловую модель, мы постоянно
задавались вопросом: неужели никто раньше до этого не додумался? В
конце концов, а как же философы? Великие древние, которые
рассуждали об устройстве мира и разума? И постепенно до нас стало
доходить. Как вы думаете, кто такой Диоген? Почему он жил в бочке?
Почему ел прямо на рынке? Почему с фонарем искал честного человека?
Почему его взбесило, когда горожанин нацепил на себя шкуру льва?
Пазл стал складываться.
Мы с удивлением обнаружили, что в древних текстах и преданиях
скрыто огромное количество устойчивых, согласующихся между собой и
непротиворечивых аллегорий, непосредственно отсылающих к философии
смысла. К той философии, что говорит ровно о том, над чем работаем
мы. В итоге параллельно с созданием СИИ наша команда несколько лет
работала над разгадками древних аллегорий.
И выяснилось, что действительно, ничто не ново под луной. И
шумерские мифы, и египетская книга мертвых, и аккадский Гильгамеш,
и греческие легенды, и буддийское учение, и Ветхий, и Новый Завет,
и Талмуд, и Коран, и Сказки тысяча и одной ночи, и много что еще
оказались аллегорически зашифрованными рассказами о философии
смысла. А еще обнаружилось, что причины шифрования философии смысла
в священные тексты и превращение этих текстов в религии было не
забавной шуткой авторов и не капризом истории, а страшной
драматической необходимостью.
Все наработки мы постепенно начали выкладывать на сайт нашего
проекта Поиск утраченного
смысла. Понять основные посылы можно из описания или посмотрев
короткое видео, где, кстати, рассказывается, почему не стоит
бояться конца света.
Ну и в развитие темы о смысле и определении я хотел бы
предложить вам рассказ о том, как на это смотрели наши предки и
какие подсказки они нам оставили. Я понимаю, что это будет
достаточно неожиданно, и уверен, многие сочтут за сумасшествие, но
я специально сделал это видео в форме провокации, не пробуя что-то
доказать, а пытаясь возбудить любопытство и вызвать желание
разобраться глубже.
Алексей Редозубов







 Усвоение стимула
Усвоение стимула
 Ярко
выраженная переподгонка
Ярко
выраженная переподгонка
 Нити исполнения
Нити исполнения

 Автор таблицы: д-р Педро Доминго,
Вашингтонский университет
Автор таблицы: д-р Педро Доминго,
Вашингтонский университет
 Дерево решений
Дерево решений
 Гауссова смесь
Гауссова смесь





























 "Man is to Computer Programmer as a Woman
is to Homemaker"Здесь вы можете увидеть распределение уже
"справедливых" word-embeddings: сверху гендерно-нейтральные слова,
снизу специальные для каждого гендера.
"Man is to Computer Programmer as a Woman
is to Homemaker"Здесь вы можете увидеть распределение уже
"справедливых" word-embeddings: сверху гендерно-нейтральные слова,
снизу специальные для каждого гендера.















 13 апреля 2021, на русском с субтитрами на русском.
13 апреля 2021, на русском с субтитрами на русском.

 Модуль внимания в энкодере
Модуль внимания в энкодере
 Поток
исходной последовательности
Поток
исходной последовательности
 Расположение каждого слова в исходной
последовательности
Расположение каждого слова в исходной
последовательности
 Линейные веса и веса векторного представления обучены
Линейные веса и веса векторного представления обучены
 Многоголовое внимание
Многоголовое внимание Расчёт оценки внимания
Расчёт оценки внимания
 Скалярное произведение матрицы запроса и матрицы
ключа
Скалярное произведение матрицы запроса и матрицы
ключа
 Скалярное произведение между матрицами запроса и
ключа
Скалярное произведение между матрицами запроса и
ключа
 Скалярное произведение между матрицами
ключа запроса и значения
Скалярное произведение между матрицами
ключа запроса и значения
 Оценка внимания это взвешенная сумма значения слов
Оценка внимания это взвешенная сумма значения слов
 Оценка внимания для слова blue обращает
внимание на каждое слово
Оценка внимания для слова blue обращает
внимание на каждое слово
 Каждая ячейка представляет собой скалярное
произведение двух векторов слов
Каждая ячейка представляет собой скалярное
произведение двух векторов слов
 Внимание в Трансформере
Внимание в Трансформере
 Внимание в декодере
Внимание в декодере
 Самовнимание декодера
Самовнимание декодера
 Энкодер-декодер Внимания
Энкодер-декодер Внимания
















 MS TECH | GETTY, UNSPLASH
MS TECH | GETTY, UNSPLASH

{kind=link}
{kind=link}