
В этой статье я бы хотел предложить вам пошаговый туториал по
развёртыванию контроллера домена Active Directory на Windows Server
2016 (с графической оболочкой), а также по вводу рабочей станции в
получившийся домен. Чем этот туториал может выделиться на фоне
других:
- Вместо простого "Далее, Далее, кликаем сюда, вбиваем это" я
постарался дать внятное объяснение каждому шагу, каждой настройке,
которую предстоит выполнить. Помимо основных понятий Active
Directory, DNS и DHCP вы также сможете найти много интересной
информации по всем галочкам, которые вы часто видели, но не
задумывались об их назначении.
- В конце статьи я предложу способ автоматизировать развёртывание
получившегося стенда полностью с нуля, имея на
компьютере только iso-образы ОС Windows 7 и Windows Server 2016. И
никакого PowerShell. Всего одной командой.
Статья предполагает наличие у читателя лишь самых начальных
знаний об устройстве сетей (на уровне "Что такое IP-адрес и
DNS-адрес").
Заинтересовало что-то из вышеперечисленного? Тогда погнали.
Туториал будет происходить не в вакууме, а на конкретном
виртуальном стенде, состоящим из двух виртуальных машин:

Начальное состояние стенда:
-
На машине windows_server уже установлена ОС Windows Server 2016
Standard Evaluation (с GUI). Машина находится в состоянии "сразу
после установки ОС". В процессе туториала на ней будут развернуты
службы Active Directory (с доменом mydomain.com), DNS и DHCP.
-
Машина workstation выполняет роль рабочей станции. На ней
установлена ОС Windows 7. Машина находится в состоянии "сразу после
установки ОС". В процессе туториала она будет подключена к домену
mydomain.com.
Туториал построен следующим образом (если вам интересен только
конкретный пункт смело кликайте прямо туда):
- Объясню, почему я выбрал
именно такой стенд для туториала;
- Супер-краткое описание технологии Active
Directory;
- Выполняется небольшая предварительная настройка windows_server;
- На windows_server производится включение необходимых
компонентов;
- На windows_server происходит настройка
контроллера домена AD (совместно с DNS);
- На windows_server происходит настройка сервера DHCP;
- На windows_server регистрируется
новая учетная запись в AD;
- На workstation происходит подключение к домену.
В конце туториала вас ждет приятный бонус я покажу вам как можно развернуть у
себя на компьютере весь этот работающий стенд одной единственной
командой. Вам понадобится только наличие двух установочных
iso-образов (windows 7 и windows server 2016), да небольшой скрипт,
ссылку на который я вам дам в конце статьи.
Почему такой стенд?
Такой стенд, с моей точки зрения, отлично подходит для первого
самостоятельного "прощупывания" технологии Active Directory. Он
минималистичен (всего 2 виртуальные машины), занимает минимум
ресурсов, но при этом изолирован и самодостаточен. Его можно
развернуть даже на довольно средненьком компьютере и ноутбуке. При
этом на стенде уже присутствуют основные сетевые службы (AD + DNS).
DHCP хоть и необязателен для функционирования AD, всё равно был
добавлен в стенд в ознакомительных целях.
Disclaimer
Данный туториал предлагает исключительно пробное знакомство с
Active Directory. Ни при каких обстоятельствах не рекомендуется
разворачивать подобную конфигурцию при решении реальных задач
администрирования сетей. В самом туториале я постараюсь обратить
внимание на основные моменты, которые не рекомендуется применять в
реальных сетях.
Туториал предполагает подробный разбор всех шагов по настройке,
с пояснениями "что, зачем и почему". Туториал ориентирован на
людей, не слишком знакомых с технологиями Active Directory, DNS и
DHCP, которые хотели бы немного узнать о внутренней кухне
администрирования сетей с Active Directory.
Если же базовая настройка AD вызывает у вас лишь зевоту,
переходите прямо сюда и посмотрите,
как можно автоматизировать весь процесс по
развёртыванию собственного стенда с AD и рабочей станцией.
Что такое Active
Directory
Active Directory это службы каталогов от компании Microsoft, как
подсказывает нам Википедия. За этим сухим и невзрачным определением
скрывается одна из важнейших технологий в администрировании сетей.
Благодаря Active Directory администоратор сети получает очень
удобное централизированное средство управления учетными записями
пользователей, групповыми политиками (в т.ч. политиками
безопасности) и объектами в сети (причём Active Directory без
особых проблем справляется даже с гигантскими сетями). А благодаря
встроенному механизму репликации, "положить" правильно настроенные
сервисы AD не так-то просто. Ну и напоследок, благодаря Windows,
настроить Active Directory можно буквально мышкой, так что даже
совсем начинающие IT-шники смогут с этим справиться.
Несмотря на то, что технологией заведует Microsoft, она вовсе не
ограничивается управлением Windows-машин все известные
Linux-дистрибутивы уже давным давно научились работать с этой
технологией. Повстречаться с Active Directory не просто, а очень
просто практически каждый офис предполагает наличие этой
технологии, поэтому даже самым заядлым линуксоидам было бы неплохо
разбираться в азах работы Active Directory.
Начинаем
Вы установили Windows Server 2016 и (надеюсь) видите следующий
экран:

Эта панель основное (графическое) средство администрирования
Windows Server 2016. Здесь вы можете управлять компонентами и
сервисами на вашем сервере (проще говоря, настраивать то, что умеет
делать сервер). Эту же панель можно использовать и для базовых
сетевых настроек Windows Server, для чего есть вкладка "Локальный
сервер".
Базовые настройки Windows Server
Первое, что нужно сделать это поменять сетевое имя сервера.
Сетевое имя (hostname) это удобный способ идентификации узла в
сети. Сетевое имя используется как альтернатива IP-адресу и
позволяет не запоминать IP-адрес компьютера (при том, что этот
адрес может меняться время от времени), а связываться с этим
компьютером по его логическому названию.
Проблема в том, что по-умолчанию для Windows Server генерируется
совершенно нечитаемое и неинформативное сетевое имя (я выделил его
красным цветом на скриншоте).
Рабочии станции ещё могут позволить себе иметь нечитаемый
Hostname, но никак не сервер. Поэтому я предлагаю поменять эту
абракадабру его на что-то более разумное (например, на
ADController), благо делается это быстро.
Смена сетевого имени
Нужно кликнуть на текущее имя сервера (отмечено красным цветом),
затем во вкладке "Имя компьютера" нажать на кнопку "Изменить...",
после чего ввести что-то более благоразумное:

После смены имени машину нужно будет перезагрузить.
Теперь зададим статический IP-адрес для сервера. В принципе это
делать не обязательно, раз мы всё равно собрались поднимать DHCP
службу, но на самом деле это хорошая практика, когда все ключевые
элементы корпоративной сети имеют фиксированные адреса. Открыть
меню по настройке сетевого адаптера можно из вкладки "Локальный
сервер", кликнув на текущие настройки Ethernet-адаптера (тоже
выделены красным цветом).
Настройки IP для интерфейса windows_server
Включаем нужные
компоненты
Для нашего стенда нам понадобится включить следующие сервисы
(или, как они тут называются, роли) на Windows Server:
- Доменные службы Active Directory;
- DNS-сервер;
- DHCP-сервер.
Пройдемся вкратце по каждому из них.
Доменные службы Active
Directory
Эта роль фактически "включает" технологию Active Directory на
сервере и делает его контроллером домена (под доменом в
технологии AD понимается группа логически связанных объектов в
сети). Благодаря этой роли администратор получает возможность
управлять объектами в сети, а также хранить информацию о них в
специальной распределенной базе данных.
Эта база данных содержит всю информацю об объектах в сети
(например, именно в неё заносится информация об учётных записях
пользователей). Когда человек подходит к рабочей станции и пытается
выполнить вход в свою доменную учётную запись, эта рабочая станция
связывается с контроллером домена с запросом на аутентификацию, и в
случае успеха загружает пользовательский рабочий стол.
Однако, что же делать, если контроллер домена выйдет из строя
(или просто будет недоступен для рабочих станций)? Если вы
настроили только один контроллер домена, то дела ваши довольно
плохи без связи с рабочим контроллером домена пользователи не
смогут выполнить вход на свои рабочие места. Поэтому в реальных
сетях всегда рекомендуется устанавливать как минимум
два контроллера на каждый домен. Каждый контроллер домена
участвует в так называемом механизме репликации, благодаря
чему все контроллеры домена имеют полную копию базы данных со всеми
объектами в домене. Если по какой-то причине один из контроллеров
выйдет из строя, его место всегда может занять резервный котнроллер
и пользователи даже ничего не заметят.
Однако этот туториал рассчитан на простое ознакомление с
технологией AD "на виртуалках", поэтому здесь не будет
рассматриваться вопрос создания нескольких контроллеров AD в одном
домене.
С этим пунктом все более менее понятно, а зачем же нам включать
дополнительно ещё DNS-сервер?
DNS-сервер
Обычно протокол DNS (Domain Name System) используется для
обращения к узлам в сети не по их IP-адресу, а по доменному имени
(строковый идентификатор), что, конечно, гораздо удобнее. Другими
словами, DNS чаще всего используется для разрешения доменных
имен.
Но область применения протокола DNS не ограничивается только
сопоставлением хостового имени и IP-адреса, что как раз
подтверждает технология Active Directory. Дело в том, что Microsoft
решила построить технологию Active Directory не с нуля, а на основе
протокола DNS. В частности, протокол DNS используется при
определении местонахождения всех ключевых сервисов Active Directory
в сети. Другими словами, рабочая станция при подключении к
контроллеру домена понимает, "куда" ей надо обращаться, именно с
помощью протокола DNS.
Все DNS-записи (в том числе с информацией о сервисах Active
Directory) хранятся на DNS-сервере, а это значит, что нам нужно
заиметь свой собственный DNS-сервер! Вот только вопрос, откуда его
взять? Есть два варианта:
- Использовать отдельную машину в роли DNS-сервера;
- Использовать саму машину windows_server в роли
DNS-сервера.
Первый вариант, безусловно, самый правильный именно так и надо
поступать при реальном администрировании сетей (чем больше вы
разносите логику по разным узлам в сети тем лучше). Но в учебных
целях я решил выбрать второй вариант (хотя бы потому что не
придётся создавать ещё одну виртуальную машину).
Именно поэтому эту роль (DNS-сервера) тоже нужно добавить к
ролям машины windows_server.
Кстати, если не добавить роль "DNS-сервер" сейчас, то в будущем
у вас ещё будет такая возможность при конфигурировании контроллера
домена AD.
DHCP-сервер
Протокол DHCP (Dynamic Host Configuration Protocol) нужен для
автоматической выдачи сетевых настроек узлам в сети. Под сетевыми
настройками понимается IP-адрес, адрес шлюза по-умолчанию, адрес
DNS-сервера, и ещё ряд других настроек. Этот протокол чрезвычайно
удобен при администрировании сетей, особенно больших.
В этом туториале я использую протокол DHCP чтобы рабочая станция
workstation могла получить сетевые настройки (в частности, адрес
DNS-сервера) без каких-либо действий с моей стороны.
Протокол DHCP не имеет никакого отношения к технологии Active
Directory, и можно было бы обойтись вовсе без него (достаточно
прописать все сетевые настройки на рабочей станции самостоятельно),
но я решил включить этот протокол в данный туториал просто для
общего ознакомления. К тому же, такая связка "Контроллер AD
DNS-сервер DHCP-сервер" довольно часто встречается в реальной
жизни, потому что это очень удобный набор сервисов.
При этом вопрос о том, стоит ли выделять отдельную машину под
DHCP-сервер, остаётся открытым. Для небольших сетей однозначно не
стоит разносить DNS и DHCP-серверы по разным машинам, но для
больших сетей, возможно, имеет все-таки
смысл задуматься об этом. В нашей же крошечной сети мы
абсолютно ничего не потеряем, если включим DHCP-сервер на той же
машине, что и DNS-сервер.
Что ж, довольно теории, давайте лучше перейдём к включению этих
самых ролей.
Мастер добавления
ролей и компонентов
Возвращаемся на панель мониторинга (самый первый скриншот) и
щелкаем на пункт "Добавить роли и компоненты". Вас поприветствует
мастер добавления ролей и компонентов. Первый экран ("Перед началом
работы") пропускаем, он совсем неинтересный, а вот дальше идёт
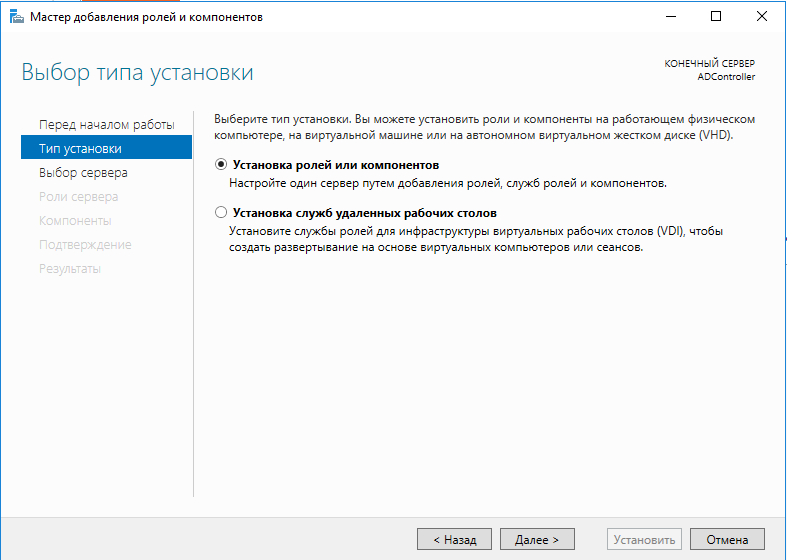
экран "Выбор типа установки"
Нас устраивает значение по-умолчанию (Установка ролей или
компонентов"), но интересен и второй пункт он позволяет
задействовать ещё одну возможность Windows Server инфраструктуру
виртуальных рабочих мест (Virtual Desktop Environment VDI). Эта
интереснейшая технология позволяет, буквально, виртуализировать
рабочее место. То есть для пользователя создаётся виртуальное
рабочее место, к которому он может подключаться через тонкий
клиент. Пользователь лишь видит картинку, тогда как само рабочее
место может совершенно прозрачно работать где угодно.
Впрочем, технология VDI это отдельная большая тема, а в этом
туториале надо сосредоточиться на контроллере AD, так что кликаем
"Далее" и видим экран выбора целевого сервера.
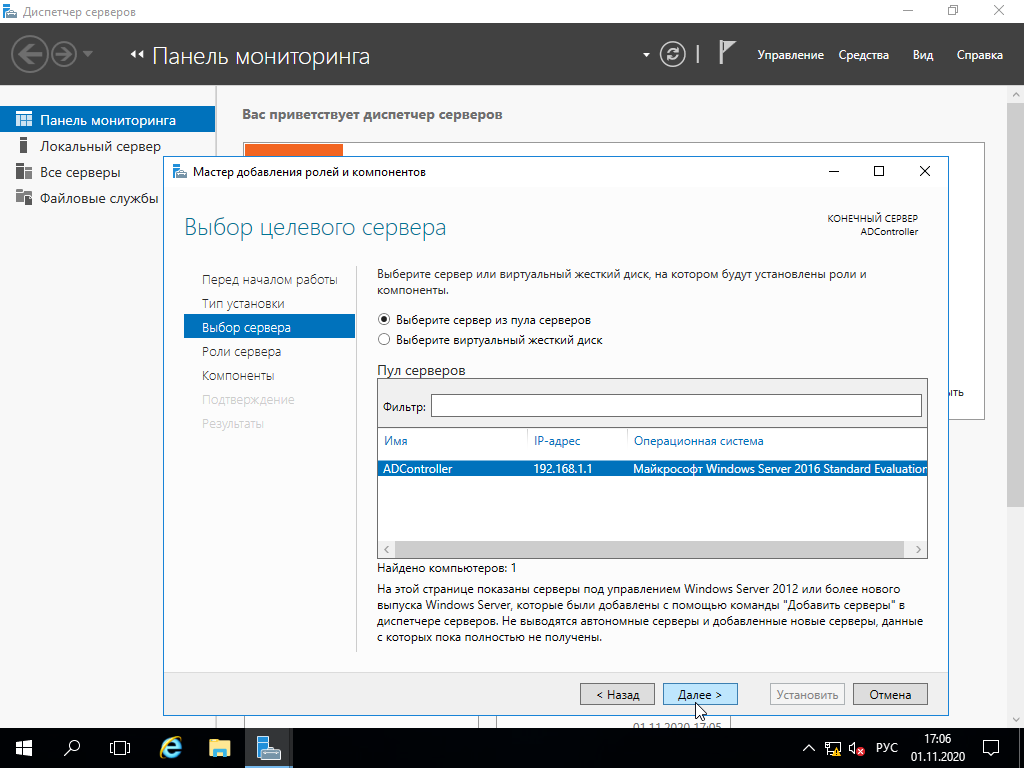
Мастер добавления ролей позволяет устанавливать роль не только
на текущую машину, но вообще на любой добавленный сервер, и даже на
виртуальный жёсткий диск. Да, если ваша Windows Server развернута
на виртуальной машине (а это довольно частое явление), то вы можете
администрировать эту виртуальную машину даже не запуская её!
Понаблюдать за этим процессом можно, например,
здесь.
Нам же такая экзотика ни к чему, так что просто выбираем
единственный возможный сервер (обратите внимание, что он теперь
называется ADController место непонятной абракадабры), жмём "Далее"
и, наконец, попадаем на экран выбора ролей, которые нужно
добавить.
Выбираем три роли, о которых уже говорили ранее, и
продолжаем.
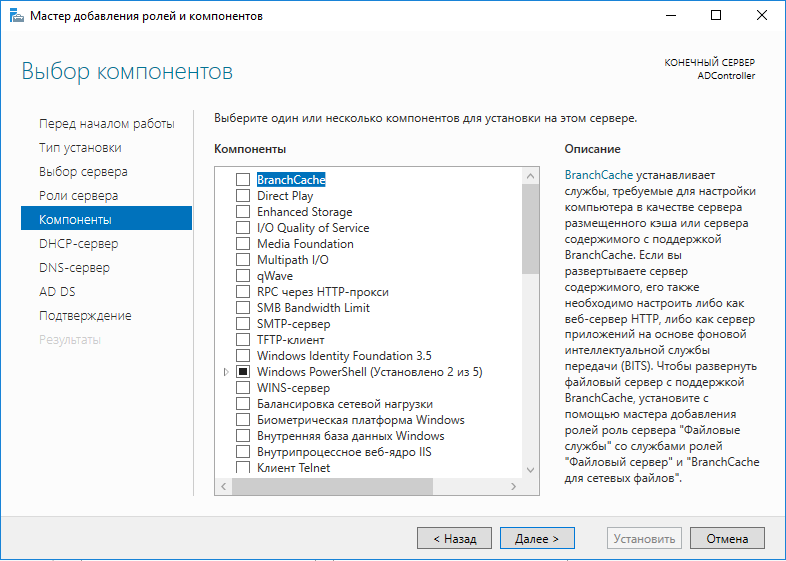
Теперь необходимо выбрать дополнительные компоненты. В чём
разница между ролью и компонентом, можете спросить вы? О, это не
такой уж и лёгкий вопрос, честно говоря!
Согласно
идеологии Microsoft, роль это набор программ, которые позволяют
компьютеру предоставлять некоторые функции для пользователей в
сети. Например, DNS, DHCP, контроллер домена AD это всё роли. А вот
компоненты это набор программ, которые улучшают либо возможности
ролей сервера, либо самого сервера.
При этом глядя на список "Компонентов" так сходу и не скажешь,
что какие-то вещи в списке лишь "вспомогательные". Вот например,
DHCP-сервер расценивается как роль, а WINS-сервер уже как
компонент. А чем SMTP-сервер хуже DNS?
В общем-то, чёткой границы между ролью и компонентом не
существует. Я лично предпочитаю относиться к ролям как к большим
функциональным возможностям сервера, а к компонентам как к
небольшим дополнительным аддонам.
В любом случае, дополнительные компоненты нам не нужны, так что
кликаем "Далее".
После этого идёт несколько пояснительных экранов с информацией
по каждой добавленной роли, но эту информацию я уже разбирал,
поэтому останавливаться лишний раз не буду.
Подтверждение устанавливаемых ролей и
компонентов
На экране подтверждения ещё раз видим все устанавливаемые роли и
компоненты, после чего жмём "Установить".
Остаётся лишь дождаться, когда заполнится progress-bar, и
перейти к следующему пункту туториала настройке контроллера домена
AD.
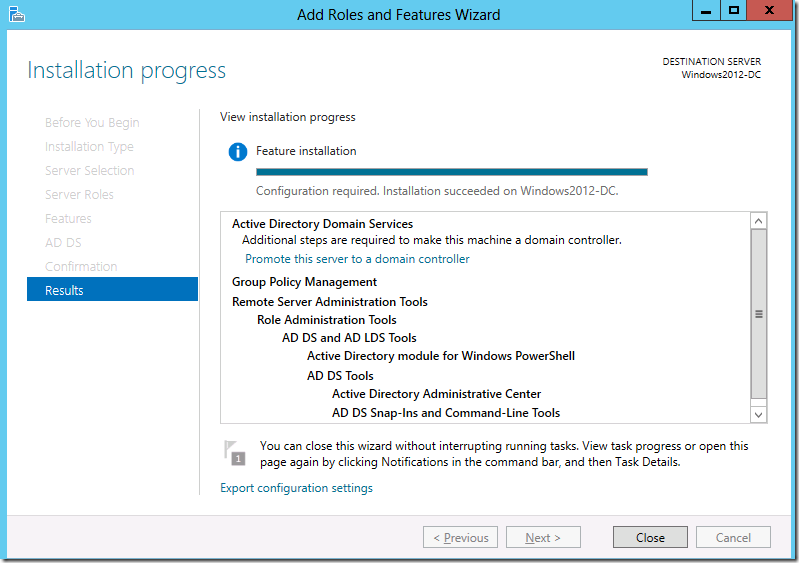
Настраиваем
контроллер домена Active Directory
Все роли и компоненты успешно добавлены, о чём свидетельствует
следующий экран:
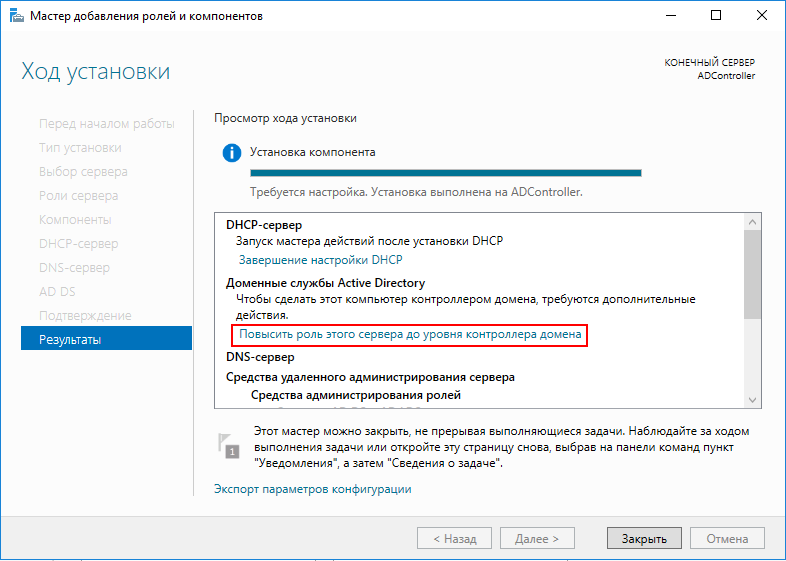
Вот только AD на сервере всё еще не работает для этого его
необходимо донастроить. Для этого нам настойчиво предлагают
"Повысить роль этого сервера до уровня контроллера домена".
Погодите-ка, ЧТО?!
А чем же я занимался последние 15 минут? Я же добавлял роли, и
судя по сообщению, они успешно добавились! И тут меня снова хотят
заставить добавлять какие-то новые роли? В чем-то тут подвох.
Подвох тут действительно имеется, но вообще в не самом очевидном
месте. Вот так выглядит предыдущий скриншот в английской версии
Windows Server (картинка из интернета).
Английская версия скриншота
Видите разницу? В английской версии ни слова ни про какие роли!
Про повышение есть, про роли нет. Один из тех случаев, когда
перевод вносит сумятицу на пустом месте. Согласно английской
версии, никакими ролями мы дальше не занимаемся, что и логично,
ведь мы их как раз только что добавили.
Что ж, тыкаем на предложение "Повысить роль этого сервера до
уровня контроллера домена", и теперь нас привествует мастер
настройки доменных служб Active Directory с предложением выбрать
конфигурацию развёртывания.
Конфигурация развёртывания
Всего тут есть 3 варианта развития событий. Для того, чтобы
выбрать правильный пункт, давайте сначала разберёмся, что эти
пункты означают. В этом нам поможет вот такая картинка (картинка,
если что, отсюда):
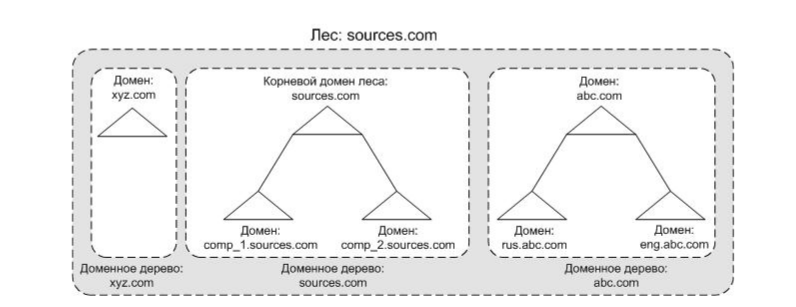
Технология Active Directory (как и DNS) подразумевает
иерархическое построение имён на основе доменов. Домены могут
выстраиваться в доменные деревья по принципу "родительско-дочерних"
отношений. В основе дерева лежит так называемый корневой домен (на
картинке выше это sources.com, xyz.com и abc.com). При этом домен
может иметь сколько угодно потомков. Домен-потомок располагается в
просранстве имён родителя и является его "поддоменом" (subdomain).
У доменного имени домена-потомка есть дополнительный префикс
относительно доменного имени родителя (rus.abc.com, eng.abc.com).
Один корневой домен основывает только одно доменное дерево со своим
независимым пространством имён.
Теперь представьте, что таких независимых деревьев может быть
много в этом случае эти деревья образуют структуру, которая
называется "лес". При этом в Active Directory доменные деревья не
могут быть "сами по себе" они обязательно должны находиться в лесу
(даже если лес будет состоять всего из одного-единственного
домена). Первый домен, который добавляется в лес, называется
корневым доменом леса (на рисунке выше это sources.com).
Корневой домен леса используется для идентификации всего леса (то
есть если корневой домен называется sources.com, то и весь лес
называется sources.com).
Теперь возвращаемся к мастеру настройки доменных имен. На этом
этапе мастер предлагает следующие варианты:
- Добавить контроллер домена в существующий домен (помните про
резервирование контроллеров в домене, так ведь?). Этот вариант не
для нас, ведь домена ещё никакого нет;
- Добавить новый домен в лес. Этого мы тоже сделать не можем,
т.к. и леса у нас тоже никакого нет;
- Добавить новый лес. Это вариант как раз для нас. При этом нам
тут же предлагают выбрать корневой домен для этого леса (первый
домен, который будет создан в лесу).
Назовём корневой домен mydomain.com и кликнем "Далее"
Параметры контроллера домена
Рассмотрим возможные параметры:
- Режим работы леса и домена. Домены в одном лесе могут работать
в разных режимах в зависимости от версии Windows Server на борту.
Лес должен иметь режим не выше, чем самый "старый" домен в его
составе. Т.к. мы планируем использовать только Windows Server 2016,
то оставим этот режим и для леса и для домена;
- DNS-сервер. Если ранее Вы не активировали роль DNS-сервера в
мастере добавления ролей, то можете сделать это сейчас (вам даже
предложат такой вариант по-умолчанию);
- Должен ли контроллер домена выступать в роли Global
Catalog-сервера;
- Включить ли режим базы данных Active Directory "только на
чтение". Основная задача, которую преследует технология RODC
возможность безопасной установки собственного контролера домена в
удаленных филиалах и офисах, в которых сложно обеспечить физическую
защиту сервера с ролью DC. Контроллер домена RODC содержит копию
базы Active Directory, доступную только на чтение. Это означает,
что никто, даже при получении физического доступа к такому
контроллеру домена, не сможет изменить данные в AD (в том числе
сбросить пароль администратора домена) (информация взята
отсюда)
А вот пункт 3 рассмотрим поподробнее, он довольно
интересный.
Как я уже упоминал выше, каждый контроллер домена имеет полную и
исчерпывающую инофрмацию обо всех объектах в своём домене. Если же
в домене несколько контроллеров, то они ещё и участвуют в механизме
репликации, поддерживая несколько актуальных копий базы данных с
объектами домена. Получается, что рабочая станция в домене может
узнать информацию о любом объекте из этого домена от своего
ближайшего контроллера домена.
Но что же делать, если рабочей станции нужно получить информацию
об объекте из другого домена? И вот тут в дело вступает ещё один
важнейший механизм технологии Active Directory, который разывается
глобальный каталог.
Что такое вообще "Глобальный каталог"? Согласно
Miscrosoft это распределенное хранилище данных, которое хранит
частичное представление обо всех AD-объектах в лесу. Это хранилище
располагается на котроллерах домена, которые имеют дополнительную
роль "Global Catalog Server" (Сервер глобального каталога). От
обычного кнтроллера домена GC-сервер отличается в первую очередь
тем, что помимо полной копии всех объектов в своем домене, хранит
также частичную информацию обо всех объектах в других доменах
леса.
Чего это позволяет достичь? Давайте представим, что рабочая
станция запросила информацию об объекте из другого домена. Она
обращается на GC-сервер с просьбой предоставить ей информацию об
этом объекте. GC-сервер, в свою очередь, может:
- Либо отдать рабочей станции нужную информацию сразу (если эта
информация у GC-сервера имеется);
- Либо перенаправить запрос к нужному контроллеру домена, где эта
информация точно будет находиться. Чтобы понять, какому контроллеру
домена нужно перенаправить запрос, как раз и происходит поиск по
GC.
Информация о том, какие атрибуты попадают в глобальный каталог,
определена в Partial Attribute Set (PAS), который может настраивать
администратор AD. Например, если администроатр понимает, что
рабочие станции часто будут обращаться к атрибуту, который не
содержится в глобальном каталоге, он может добавить туда этот
атрибут. Тогда запросы рабочих станций при чтении этого атрибута
будут выполняться значительно быстрее, т.к. уже ближайший GC-сервер
сможет предоставить им всю нужную информацию.
Однако, если в лесе всего один домен (как у нас), то Глобальный
каталог содержит полную копию объектов в домене и всё.
Что ж, возвращаемся к галочке GC, которую за нас уже проставил
мастер настройки доменных служб. Если вы попробуете её отключить,
то убедитесь, что отключить её нельзя. Это связано с тем, что
каждый домен в AD должен иметь хотя бы один GC-сервер, и при
добавлении первого контроллера в домен этот контроллер сразу
помечается как GC-сервер.
Что ж, давайте согласимся с этим "выбором" мастера и перейдём к
последнему параметру на этом скриншоте к паролю для режима
восстановления служб каталогов. Это особый режим безопасной
загрузки Windows Server, который позволяет администратору работать
с базой данных AD. Этот режим применяется, например, в следующих
случаях:
- база Active Directory повреждена и нуждается в
исправлении;
- требуется выполнить обслуживание базы данных AD (сжатие, анализ
на наличие ошибок);
- требуется восстановить резервную копию базы данных AD;
- требуется сменить пароль администратора.
Да да, вы не ослышались. Чтобы просто восстановить резервную
копию базы данных, нужно перезагрузить машину и загрузиться в
особом "безопасном" режиме. Это вам не Linux какой-нибудь.
Фух, вроде разобрались. Давайте перейдем дальше на шаг, где нам
предложат настроить делегирование DNS.
Что такое делегирование DNS? По большей части, это передача
ответственности за некоторую DNS-зону отдельному DNS-серверу. Это
распространенная практика в больших сетях, в которых требуется
разграничить зоны ответственности за доменные зоны между различными
серверами. При делегировании DNS в "главный" DNS-сервер вносится
запись о том, что "вот за эту DNS-зону несёт ответственность вон
тот DNS-сервер, обращайся туда".
Т.к. у нас всего одна зона DNS и DNS-сервер тоже один, то этот
шаг нам необходимо пропустить и перейти к выбору NetBIOS-имени.
Мы видим, что мастер предложил нам на выбор сразу же имя для
нашего домена MYDOMAIN. Но вы можете (и должны) задать себе вопрос:
а что такое вообще NetBIOS-имя и зачем оно нужно? И разве мы уже не
настраивали сетевое имя узла (Hostname) в самом начале? Чего же от
вас хотят?
NetBIOS (Network Basic Input/Oputout) это ещё один способ
разрешения имён узлов в сети (более древний и более примитивный,
чем DNS). NetBIOS-имена не предполагают никакой иерархии, их длина
ограничивается всего лишь 16 символами, и они применяются только
для разрешения имён компьютеров в локальной сети. Когда мы в самом
начале туториала выбрали сетевое имя ADController мы, на самом
деле, задали именно NetBIOS-имя для сервера. Но теперь от нас снова
требуют выбрать NetBIOS-имя (да ещё и другое, отличное от
ADContoller). Не много ли NetBIOS-имён для одного компьютера?
Дело в том, что Microsoft пошла ещё дальше и ограничила длину
NetBIOS-имен не 16 символами, а 15 символами. 16-ый символ при этом
считается зарезервированным суффиксом, который может
принимать фиксированные значения. В зависимости от значения 16-го
байта получаются разные классы
NetBIOS-имён. Например, если суффикс равен 00, то NetBIOS-имя
относится к рабочей станции. Если суффикс равен 1С, то это
имя относится к имени домена.
То есть, как вы понимаете, на первом шаге мы задавали
NetBIOS-имя для компьютера Windows Server (с суффиком 00). А теперь
задаём NetBIOS-имя домена mydomain.com (с суффиксом 1С).
Кстати, можете, ради интереса, отмотать туториал в самое начало
и посчитать количество символов в "нечитаемом" автоматически
сгенерированном сетевом имени windows_server. Будет как раз 15
символов (максимальная длина NetBIOS-имени).
И напоследок скажу, что вы не можете пропустить этот шаг.
NetBIOS хоть и устаревшая технология, но до сих пор используется
ради совместимости с некоторыми старыми службами. Настроить
контроллер домена Active Directory без NetBIOS-имени нельзя.
Что ж, и с этим тоже разобрались. Оставляем NetBIOS-имя
по-умолчанию и двигаемся дальше, к выбору места расположения базы
данных AD. Можно оставить значение по-умолчанию, комментировать
особо нечего.
Все ваши настройки должны пройти предварительную проверку:
Проверка предварительных требований
Как только всё готово, жмите "Установить" и спокойно идёте пить
чай, потому что после установки автоматически начнётся очень-очень
долгая перезагрузка. Зато настройка контроллера домена AD на этом
закончена, поздравляю!
Настройка DHCP-сервера
Пришло время заняться настройкой DHCP-сервера. Настройка
глобально состоит из двух частей:
- Авторизация DHCP-сервера в домене AD. Не каждый DHCP-сервер
может раздавать сетевые настройки в домене AD только
авторизованные. Это сделано с целях безопасности, чтобы другие
DHCP-серверы не могли "подсунуть" неправильные настройки
компьютерам в домене;
- Настройка новой DHCP-области. Это уже непосредственно настройка
самого DHCP-сервера, в ходе которой определяются какие сетевые
настройки будут выдаваться компьютерам в сегменте сети.
Для того, чтобы авторизировать DHCP-сервер, нужно вернуться на
панель мониторинга (она и так должна быть перед вами после
перезагрузки), перейти на вкладку DHCP (слева) и кликнуть на
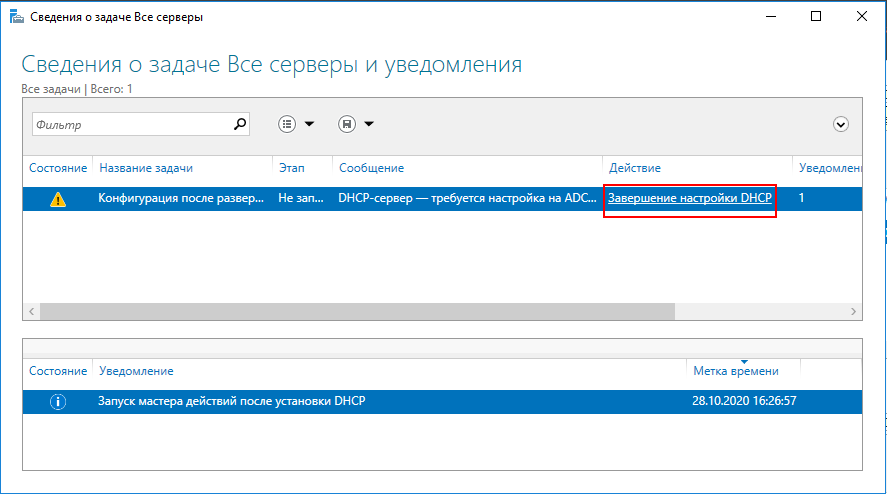
предложение донастроить DHCP-сервер:
Запуск авторизации DHCP-сервера
В открывшемся мастере настройки DHCP после установки пропускаем
первый приветственный экран и переходим к экрану авторизации
Авторизация DHCP-сервера в домене
На выбор предлагаются три варианта:
- Использовать учётные администратора (по-умолчанию)
- Использовать учётные данные другого пользователя;
- Пропустить авторизацию AD.
По-умолчанию авторизовать DHCP-сервер в домене могут только
члены группы
EnterpriseAdmins, куда как раз и входит пользователь
MYDOMAIN\Администратор. При желании можно потратить немного времени
и делегировать эту возможность админам "помельче" (региональным
администраторам), подчерпнуть больше информации по этой теме можно
отсюда.
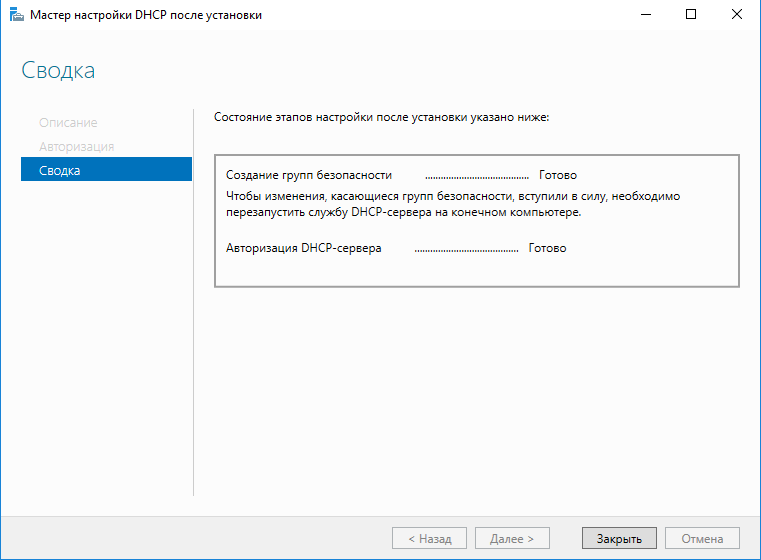
Итак, выбираем вариант по-умолчанию и завершаем первый этап
настроки DHCP-сервера.
Завершение авторизации DHCP-сервера
Теперь переходим непосредственно к настройкам DHCP. Для этого на
панели мониторинга кликаем вкладку "Средства" и выбираем пункт
"DHCP"

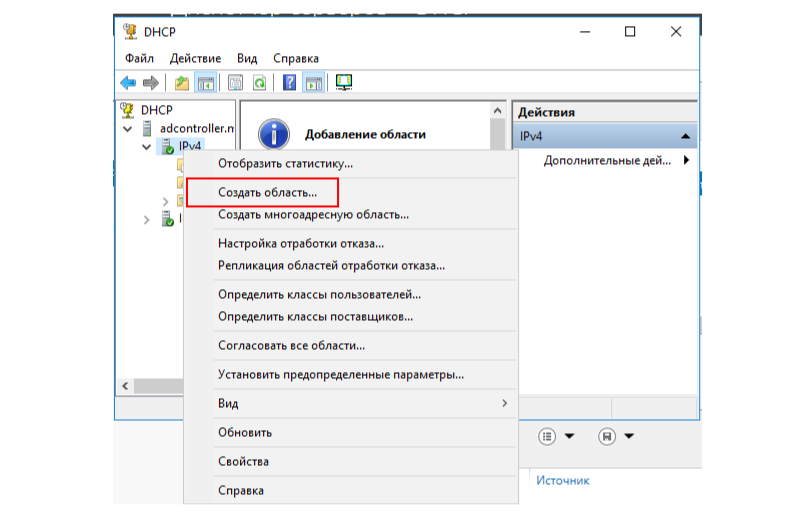
В открывшемся окне с настройками DHCP нужно кликнуть правой
кнопкой мышки на IPv4 и затем на пункт меню "Создать область".
После этого откроется мастер создания новой области.
Открытие мастера создания новой области
Что такое DHCP-область? Под этим понимается некий диапазон
IP-адресов, которые может выдавать DHCP-сервер другим компьютерам в
сети. Каждая область помимо диапазона IP-адресов также содержит
другие сетевые настройки, с которыми мы сейчас и познакомимся.
Назовём DHCP-область SCOPE1 и перейдём дальше.
На следующем экране вам предложат выбрать диапазон адресов,
которые будут выдаваться компьютерам в сети. Ранее я настраивал
сетевой интерфейс на Windows Server, выдав ему адрес
192.168.1.1/24. Это статический адрес и он зарезервирован, его
выдавать другим компьютерам нельзя.
Зато никто не мешает выдавать все остальные адреса в сети
192.168.1.0/24 так что задаём диапазон от 192.168.1.2 до
192.168.1.254 (192.168.1.255 это зарезервированный
широковещательный адрес, его выдавать тоже нельзя).
Настройка диапазона адресов
В целом, никто не мешает вам как администратору выдавать меньше
IP-адресов, чем доступно в адресации сети. Например, можно было бы
выделить в сети всего 100 адресов для автоматической выдачи:
192.168.1.101-192.168.1.200.
Переходим далее и видим предложение о выборе исключений из
указанонного диапазона адресов, а также о настройке задержки при
передаче сообщения DHCPOFFER
Исключения в диапазоне и задержка DHCPOFFER
С исключениями всё более-менее понятно: если вы не хотите
выдавать некоторые адреса в указанном ранее диапазоне, то вы можете
указать эти адреса здесь в виде исключений. А что за задержка в
DHCPOFFER такая?
Эта настройка уже относится к довольно продвинутому
администрированию сетей: если в вашей сети есть несколько
DHCP-серверов, то с помощью этой задержки вы можете регулировать
нагрузку между ними (подробнее можно прочитать, например,
тут).
В любом случае, исключений в диапазоне у нас нет, да и задержка
по-умолчанию нас устраивает, так что кликаем дальше и видим
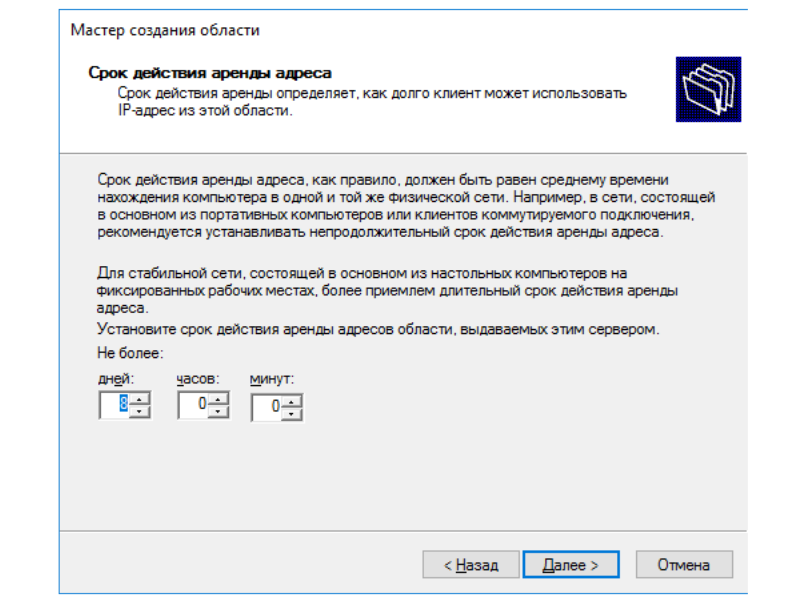
настройку сроков аренды адресов.
Настройка времени аренды адресов
Протокол DHCP предполагает выделение адресов только на
определённое время, после чего компьютеры должны продлять аренду.
Здесь можно настроить это время (по-умолчанию 8 дней).
8 дней меня лично вполне устраивает, так что кликаем "Далее" и
видим предложение настроить другие настройки, которые будут
получать клиенты в сети (помимо IP-адреса). Соглашаемся.
Настроить дополнительные параметры
Первая сетевая настройка для клиентов это шлюз по-умолчанию. В
стенде из двух виртуальных машин эта настройка в принципе не нужна,
можно представить, что windows_server будет играть роль шлюза во
внешнюю сеть, и добавить адрес 192.168.1.1 как шлюз
по-умолчанию.
Далее идет настройка DNS. Здесь можно задать имя родительского
домена и адреса DNS-серверов. С адресами DNS-серверов всё
более-менее понятно это IP-адреса серверов, куда следует обращаться
клиентам за помощью в разрешении DNS-имён. Сейчас в этом списке
фигурирует тот же адрес, что мы добавили как шлюз по-умолчанию.
А вот для понимания имени родительского домена, рассмотрим
следующую ситуацию.
Допустим, есть домен mydomain.com и есть два компьютера в этом
домене с именами comp1.mydomain.com и comp2.mydomain.com. Если
comp1 хочет связаться с comp2, то он должен, по-хорошему,
использовать следующую команду (обращение по Fully Qualified Domain
Name FQDN):
ping comp2.mydomain.com
Но задумывались ли вы когда-нибудь, что именно произойдет, если
попытаться пропинговать другой узел следующим образом?
ping comp2
На самом деле, в этом случае начинается целая магия очень хитрый
процесс разрешения имён (картинка из интернетов).
Процесс разрешения сетевых имён

- Поиск информации в hosts.txt или в кеше;
- Попытка найти имя через DNS;
- Попытка найти NetBIOS-имя в кеше;
- Попытка найти NetBIOS-имя через WINS-сервер;
- Попытка найти NetBIOS-имя путём отправки широковещательных
пакетов в локальную сеть;
- Попытка найти NetBIOS-имя в LMHOSTS-файле.
Согласно алгоритму разрешения сетевых имен, сначала comp1
попробует найти информацию о comp2 в hosts.txt файле. Если этой
информации там не окажется, то начинается процесс поиска узла через
DNS. Вот только вопрос DNS-имена же находятся в каком-то домене,
верно? Какое доменное имя нужно "пристыковать" к comp2 при
выполнении пинга?
Вот тут в дело и вступает настройка DHCP, которая называется
"имя родительсокго домена". Это как раз тот суффикс, который будет
автоматически "пристыкован" к имени comp2 при выполнении
DNS-разрешения имени. Так что если имя родительского домена равно
"mydomain.com", то команда ping comp2 неявно
преобразуется в ping comp2.mydomain.com.
Если же DNS-разрешение окажется неудачным, дальше начнутся
попытки найти comp2 уже по NetBIOS-имени. Что такое WINS, и чем он
отличается от Broadcast информация будет чуть дальше по тексту.
Что ж, в нашем случае имя родительсокго домена должно быть
mydomain.com (значение по-умолчанию), а нужный DNS-сервер уже
находится в списке, так что в итоге просто кликаем "Далее".
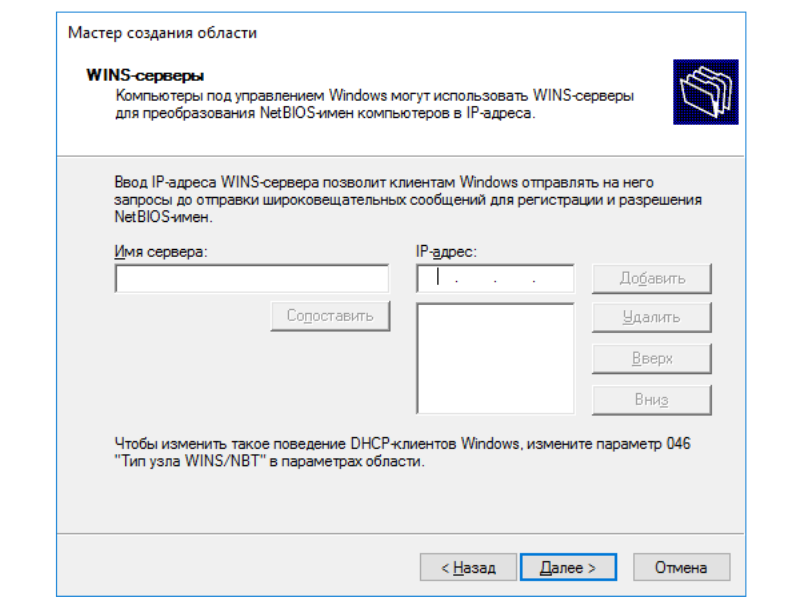
Теперь нас попросят указать настройки WINS-сервера. WINS
(Windows Internet Name Service) сервер участвует в разрешении
NetBIOS-имён в сети (прямо как DNS-сервер для DNS-имён). Вот
только, в отличие от DNS, WINS-сервер не обязательно должен
присутствовать в сети, чтобы разрешение NetBIOS-имён работало. Так
зачем же он нужен тогда?
Дело в том, что по-умолчанию разрешение NetBIOS-имен происходит
через широковещательные запросы. С одной стороны, это очень простой
механизм (проще не придумаешь), но, с другой стороны, обладает
парой недостатков:
- При наличии большого количества NetBIOS-имён в сети
широковещательный тафик может начать "зашумлять" канал;
- Широковещательные запросы не могут "выйти" за пределы текущей
сети, поэтому узнать NetBIOS-имя из другой сети таким способом не
выйдет.
Так вот, WINS-сервер позволяет решить обе этих проблемы. Этот
сервер централизованно хранит NetBIOS-имена компьютеров, и обычные
узлы в сети могут обращаться к нему для поиска IP-адреса
интересующего их имени (как и для DNS). Такой подход, во-первых,
резко уменьшает количество широковещательного трафика в сети, а,
во-вторых, позволяет посылать NetBIOS-запросы в другие сети, а не
только в текущую.
В нашей небольшой сети WINS-сервер нам ни к чему, поэтому просто
пропускаем эту настройку и едем дальше.
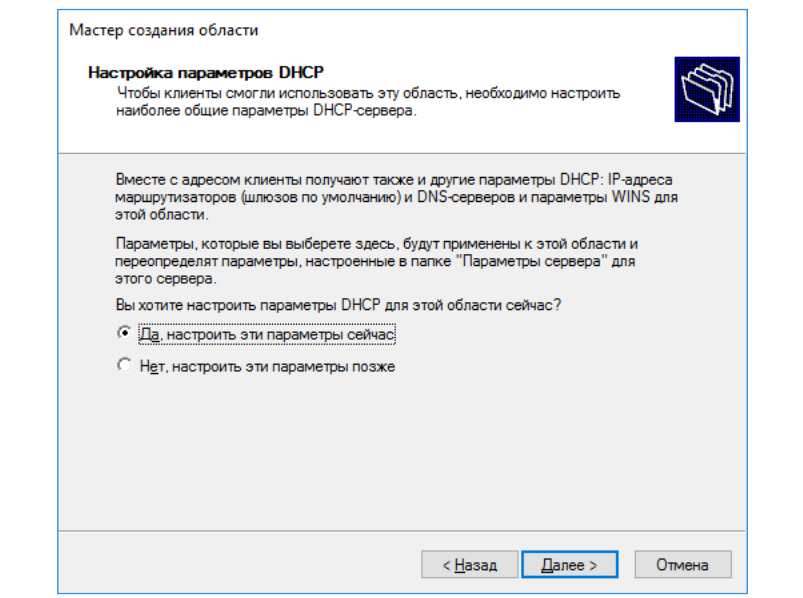
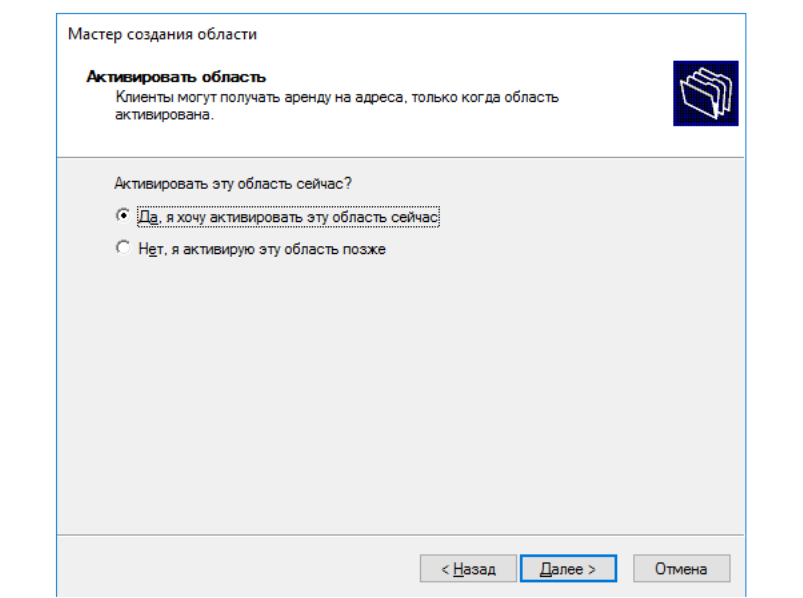
В последнем шаге настройки вам предлагают сразу активировать
настроенную область. Соглашаемся, и на этом заканчиваем настройку
DHCP.
Создаём нового
пользователя в домене AD
Собственно настройка контроллера домена и различных сервисов уже
фактически закончена, все параметры выставлены как надо. Теперь
нужно просто зарегистрировать нового пользователя, от имени
которого рабочая станция workstation будет выполнять вход в
домен.
Для этого возвращаемся на панель мониторинга, кликаем на
"Средства" и затем на "Пользователи и Компьютеры Active
Directory"
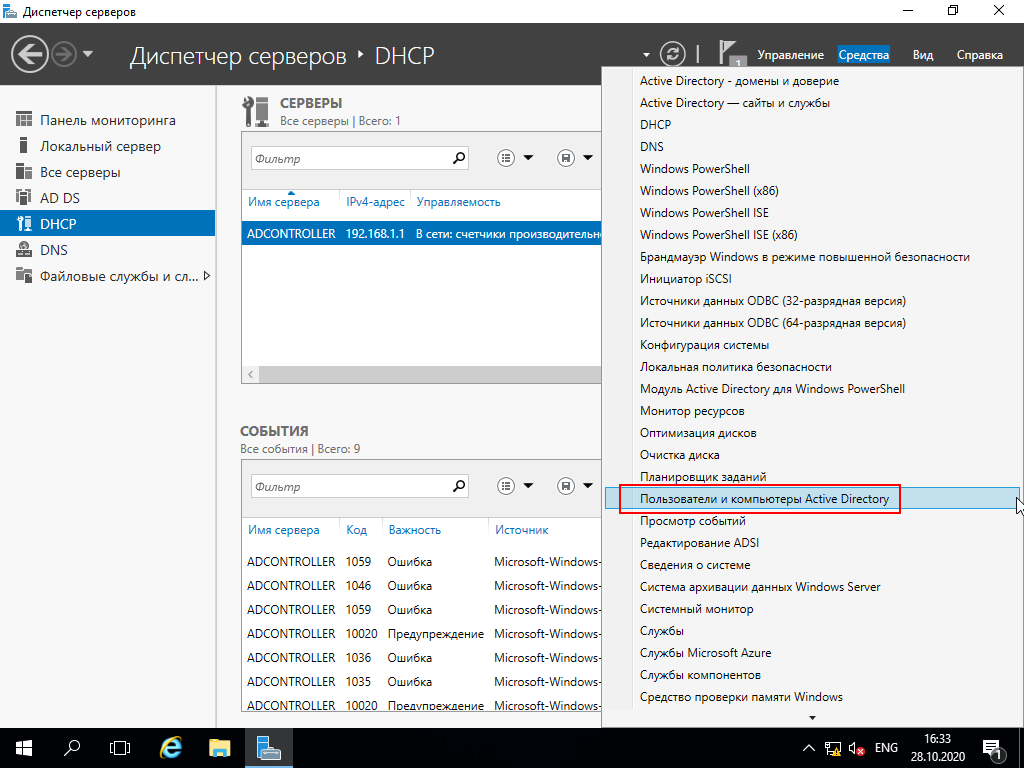
В открывшемся меню можно заметить созданный домен mydomain.com и
его состав. Видно, что помимо пользователей в домене созданы
папочки для Computers, Domain Controllers и других сущностей. Но
нас сейчас интересуют пользователи, поэтому кликаем правой кнопкой
мышки на папке Users и выбираем "Создать" -> "Пользователь"

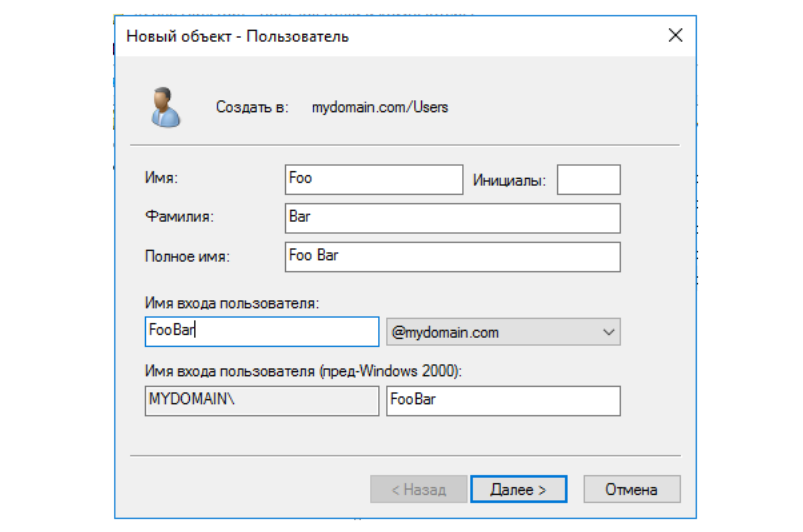
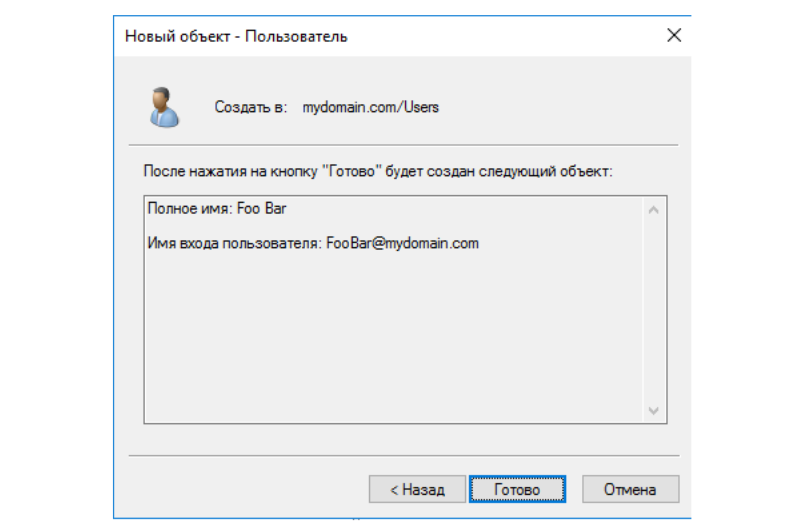
После этого появляется диалоговое окно с преложением ввести
данные нового пользователя. По старой доброй традиции назовём
пользователя Foo Bar. Обратите внимание, что пользователь
отображается лишь как "Объект" в Active Directory наравне с другими
объектами.
Новый объект - Пользователь
Теперь необходимо задать пароль и дополнительные параметры для
пользователя. Пароль должен соответсовать политике паролей
по-умолчанию, которая, в том числе, предписыват паролям в домене
быть довольно сложными (должен использовать числа, буквы верхнего и
нижнего регистра, а также спец символы).
Обычно администратор создаёт простой пароль для пользователя, а
затем требует от пользователя сменить его при первом входе в
систему (первая галочка в списке доступных опций). Это очень
хорошая практика с точки зрения безопасности, ведь таким образом
даже администратор AD не сможет узнать пароль пользователя. Также
хорошей практикой считается ограничивать срок действия пароля. В
этом туториале для простоты мы уберём требование о смене пароля
пользователем при врходе в систему.
Параметры нового пользователя
После этого останется лишь подтвердить создание нового
пользователя.
Подтверждение создания нового пользователя
Ну что ж, вот, кажется, и всё! Осталось лишь проверить ввод
рабочей станции в домен.
Ввод рабочей станции в
домен
Переключаемся на вторую машину workstation под управлением
Windows 7 и заходим в свойства системы. Сейчас видно, что рабочая
станция находится в рабочей группе (не в домене). Кстати говоря,
WORKGROUP это тоже NetBIOS-имя. Только в отличии от имени домена
оно имеет суффикс 1E.

Щелкаем на кнопку "Изменить параметры", затем в появившемся окне
ещё раз "Изменить...".
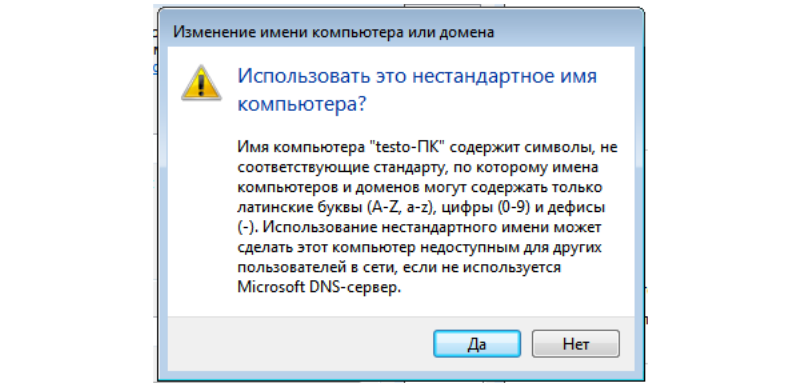
В окне изменения имени компьютера пишем, что он должен
принадлежать домену mydomain.com.
Видим предупреждение о нестандартном имени компьютера (testo-ПК
содержит кириллицу). Это связано с тем, что NetBIOS-имена не могут
содеражать кириллицу. Но мы с вами настроили DNS-сервер (DNS
настройки прилетели на рабочую станцию по DHCP), а DNS-механизм
разрешения имён, как мы знаем, имеет приоритет перед NetBOIS. Так
что в данном случае на работоспособность AD кириллица не влияет. Но
на практике так делать не надо!
Нестандартное имя компьютера
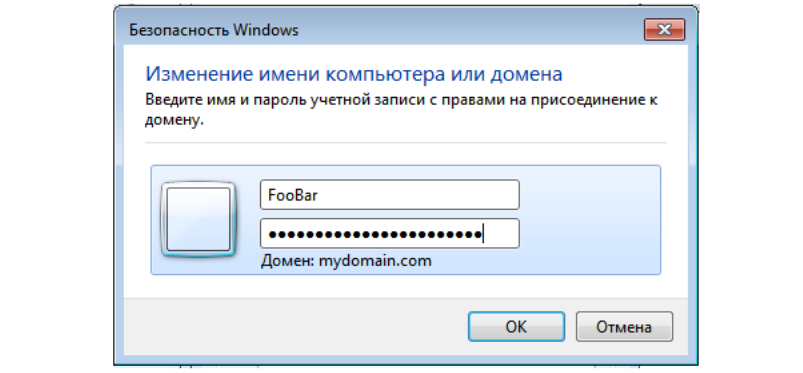
Вводим логин-пароль от новой учетной записи FooBar и, наконец,
видим заветное сообщение "Добро пожаловать в домен"
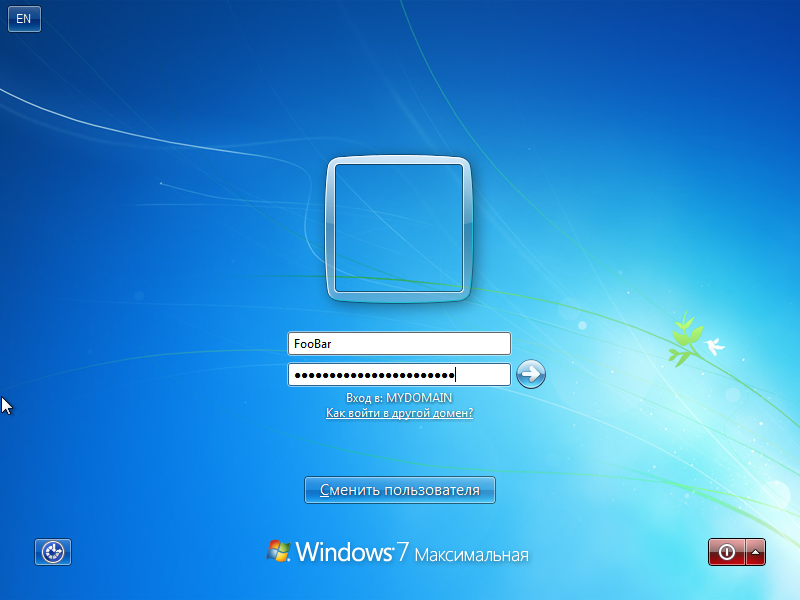
После ввода компьютера в домене необходимо перезагрузить
компьютер, ну а дальше вводим учётные данные пользователя в AD.
И после успешного входа на рабочий стол перепроверяем свойства
системы.
Полное имя компьютера поменялось на testo-ПК.mydomain.com, а это
значит, что мы успешно ввели рабочую станцию в домен
mydomain.com.
Автоматизируем
Как вы могли заметить, весь туториал можно выполнить, пользуясь
исключительно мышкой и клавиатурой. Больше того, нам даже не
пригодились знания PowerShell, который позволяет выполнять бОльшую
часть настройки контроллера домена AD с помощью скриптов.
Так почему бы не автоматизировать все действия с клавиатурой и
мышкой, которые мы предпринимали? И нет, я говорю не об AutoIT, я
говорю о платформе Testo, создателем которой я являюсь. Эта
платформа позволяет фиксировать все действия, проводимые с
виртуальными машинами, в виде скриптов на специальном языке
Testo-lang. Ну а Testo затем превратит эти скрипты обратно в
действия.
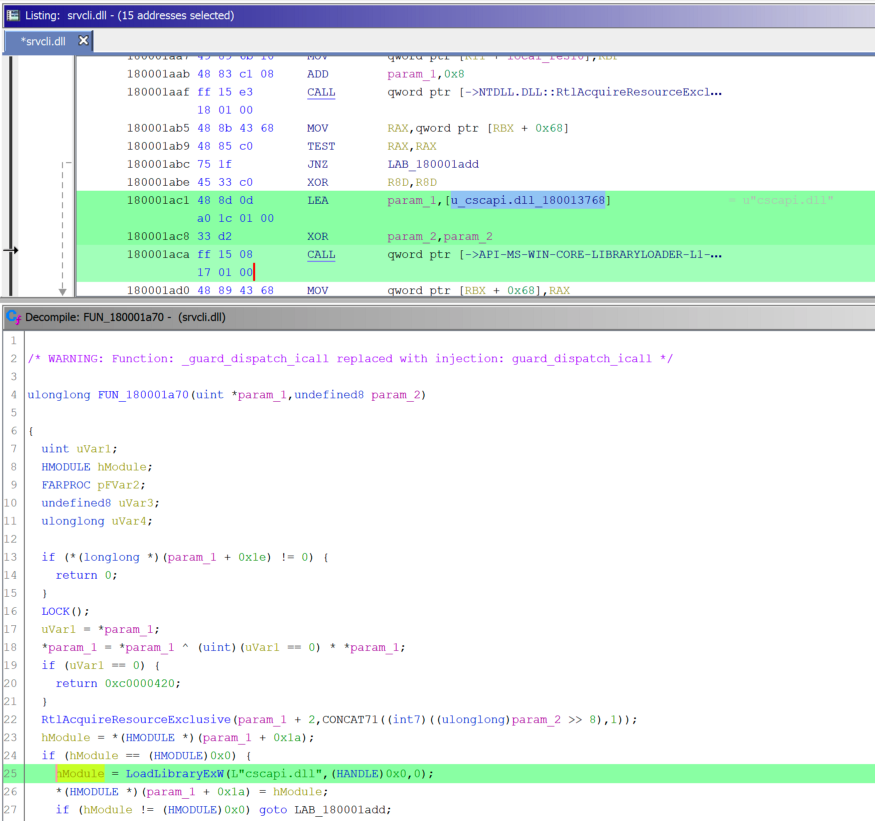
Я приведу лишь один скриншот с кусочком скрипта, чтобы у вас
сложилось представление о том, о чём я говорю (да, именно скриншот,
ведь хабр не умеет подсвечивать скриповый язык Testo-lang). Я даже
не буду комментировать этот скрипт, т.к. верю, что код говорит сам
за себя.
Секция скрипта на языке Testo-lang
Я не буду сейчас рассказывать о платформе Testo и о её
возможностях. Для этого есть отдельная статья на хабре.
Вместо этого предлагаю просто увидеть своими глазами, как это
работает:
Всё, что Вам потребуется для создания собственного стенда с
настроенной Active Directory это:
- Установочный
iso-образ Windows Server 2016 русской версии;
- Установочный iso-образ Windows 7 (придётся поискать
самим);
-
Скрипты на языке Testo-lang;
- Установленная платформа Testo
(бесплатно);
- Выполнить команду.
sudo testo run ./tests.testo --param ISO_DIR /path/to/your/iso/dir
И всё. Как и я обещал всего одна команда. Через пол часа час
(зависит от шустрости вашего компьютера) вы сможете наслаждаться
своим готовым стендом.
Итоги
Надеюсь, вам понравился туториал, и вы нашли его полезным.
Возможно, вас заинтересовала платформа Testo, в этом случае вот
несколько полезных ссылок:
- сайт платформы
Тесто.
-
youtube-канал, где можно найти много примеров.
- основная статья на хабре
- статья, где я автоматизировал несколько системных тестов
для Dr. Web
-
скрипты на языке Testo-lang для этого туториала


































 https://bit.ly/34tRpwZ
https://bit.ly/34tRpwZ




































 Должен появиться
Должен появиться
 Должен пропасть
Должен пропасть
 Не должен появиться
Не должен появиться
 Не должен пропасть
Не должен пропасть

 Тестовый пользователь
Тестовый пользователь
 Примеры диалоговых окон
Примеры диалоговых окон















 Простой шаг-предусловие
Простой шаг-предусловие












