
Существует мнение, что разработка через тестирование, или по канонам Test Driven Development (TDD) для фронтенда не применима. В данной статье я постараюсь развенчать этот миф и покажу, что это не только возможно, но и очень удобно и приятно.
Сам по себе React достаточно понятен любому разработчику, чего не скажешь про Redux. На первый взгляд может показаться, что это какой-то монструозный и непонятный инструмент. Прочитав данную статью, вы узнаете как разрабатывать приложения через тестирование на React, используя Redux, поймёте преимущества его использования, научитесь не открывать браузер при разработке фронтенд-приложений и экономить время на дебаге. Возможно, найдёте что-то новое для себя про написание фронтовых тестов.

Про TDD вообще и частный случай тестирования React-компонентов можно прочитать в статье моего коллеги Андрея, в данном материале я не буду заострять внимания на нюансах, но целиком и полностью пройду весь путь создания приложения через написание тестов.
Любой фронтенд-компонент продукта сам по себе делится на несколько составляющих. Для простоты можно считать, что в браузерном приложении есть свой фронтенд и свой бэкенд. Первый отвечает за непосредственный пользовательский интерфейс, а второй за бизнес-логику. React нам помогает с интерфейсами, а Redux представляет собой очень удобный инструмент для обработки бизнес-логики.
Поскольку, мы в ManyChat в начале 2020 года полностью перешли на TypeScript, будем писать код сразу с использованием строгой типизации.
Redux
Что такое Redux? Redux это паттерн и библиотека для управления и обновления состоянием приложения с использованием специальных событий, называемых Action. Он предоставляет централизованное хранилище состояния, которое используется во всём приложении с правилами, гарантирующими предсказуемое изменение этого состояния. Если посмотреть на диаграмму потока данных в Redux для приложений на React, мы увидим примерно следующее:

При необходимости изменения состояния, например, при клике на элемент в DOM, вызывается Action creator, который создаёт определенный Action. Этот Action c помощью метода Dispatch отправляется в Store, где он передаётся на обработку в Reducers. Редьюсеры, в свою очередь, на основании текущего состояния и информации, которая находится в экшене, возвращают новое состояние приложения, которое принимает React с помощью Selectors для нового рендера DOM. Более подробно о каждом компоненте Redux будет рассказано ниже по ходу разработки приложения.
Такой однонаправленный поток данных даёт множество преимуществ, таких как ослабление связанности компонентов, один источник информации о том, как должно выглядеть и действовать приложение, плюс разделение бизнес-логики и отображения, что приводит к значительному упрощению тестирования кода.
Задача
Создадим форму принятия какого-то пользовательского соглашения. Форма должна содержать чекбокс, который следует отметить пользователем, в случае, если он принимает соглашение, а так же кнопку Submit, которая становится активной только при активации чекбокса. Выглядеть это должно примерно вот так:

Воспользуемся шаблоном create-react-app:
npx create-react-app my-app --template typescriptcd my-appnpm start
Запустили, убедились, что приложение работает.

Можем остановить сборщик, поскольку он понадобится нам ещё очень не скоро. Можем даже закрыть браузер.
Теперь приступим к самому вкусному подключению Redux в наш проект. Т.к. приложение у нас совершенно пустое, мы не знаем структуру стора, оставим его напоследок.
Установим нужные пакеты:
npm i redux react-redux redux-mock-store @types/redux @types/react-redux @types/redux-mock-store
Actions
Что такое Action? Это обычный Javascript объект, у которого есть обязательное свойство type, в котором содержится, как правило, осознанное имя экшена. Создатели Redux рекомендуют формировать строку для свойства type по шаблону домен/событие. Также в нём может присутствовать дополнительная информация, которая, обычно, складывается в свойство payload. Экшены создаются с помощью Action Creators функций, которые возвращают экшены.
Раз у нас всего лишь чекбоксы, кажется, достаточно одного экшена, отрабатывающего изменение его состояния, нам нужно только придумать ему название или
type.Напишем первый тест. Для тестирования используем уже ставший стандартным фреймворк Jest. Для запуска тестов в следящем режиме, достаточно в корне проекта выполнить команду
npm test.
// actions/actions.test.tsimport { checkboxClick } from '.'describe('checkboxClick', () => { it('returns checkboxClick action with action name in payload', () => { const checkboxName = 'anyCheckbox' const result = checkboxClick(checkboxName) expect(result).toEqual({ type: 'checkbox/click', payload: checkboxName }) })})
Здесь мы проверяем, Action Creator вернёт экшн с нужным типом и правильными данными, а именно с названием чекбокса. И больше нам здесь нечего проверять.
Само собой, тест у нас красный (сломанный), т.к. код ещё не написан:

Пора написать код:
// actions/package.json{ "main": "./actions"}// actions/actions.tsexport const checkboxClick = (name: string) => ({ type: 'checkbox/click', payload: name })
Проверяем:

Тест пройден, можем приступить к рефакторингу. Здесь мы видим явное дублирование константы с типом экшена, вынесем её в отдельный модуль.
// actionTypes.tsexport const CHECKBOX_CLICK = 'checkbox/click'
Поправим тест:
// actions/actions.test.tsimport { CHECKBOX_CLICK } from 'actionTypes'import { checkboxClick } from '.'describe('checkboxClick', () => { it('returns checkboxClick action with action name in payload', () => { const checkboxName = 'anyCheckbox' const result = checkboxClick(checkboxName) expect(result).toEqual({ type: CHECKBOX_CLICK, payload: checkboxName }) })})
Тест не проходит, потому что мы не использовали относительный путь к
actionTypes. Чтобы это исправить, добавим в
tsconfig.json в секцию compilerOptions
следующий параметр "baseUrl": "src". После этого
понадобится перезапустить тесты вручную.Убедимся, что тест позеленел, теперь поправим сам код:
// actions/actions.tsimport { CHECKBOX_CLICK } from 'actionTypes'export const checkboxClick = (name: string) => ({ type: CHECKBOX_CLICK, payload: name })
Ещё раз убеждаемся, что тест проходит, и можем двигаться дальше.
Reducers
Напишем обработчик события изменения состояния чекбокса, т.е. Reducer. Редьюсеры это специальные чистые функции, которые принимают на вход текущий state и action, решают как нужно изменить состояние, если это требуется, и возвращают новый state. Редьюсеры должны содержать всю бизнес-логику приложения, насколько это возможно.
Хранить состояние чекбоксов (отмечены они или нет) мы будем простым объектом, где ключом будет выступать название чекбокса, а в булевом значении непосредственно его состояние.
{ checkboxName: true}
Приступим. Первый тест будет проверять, что мы получаем исходное состояние, т.е. пустой объект.
// reducers/reducers.test.tsimport { checkboxReducer } from '.'describe('checkboxReducer', () => { it('creates default state', () => { const state = checkboxReducer(undefined, { type: 'anyAction' }) expect(state).toEqual({}) })})
Т.к. у нас даже нет файла с редьюсером, тест сломан. Напишем код.
// reducers/package.json{ "main": "./reducers"}// reducers/reducers.tsconst initialState: Record<string, boolean> = {}export const checkboxReducer = (state = initialState, action: { type: string }) => { return state}
Первый тест редьюсера починили, можем написать новый, который уже проверит, что получим в результате обработки экшена с информацией о нажатом чекбоксе.
// reducers/reducers.test.tsimport { CHECKBOX_CLICK } from 'actionTypes'import { checkboxReducer } from '.'describe('checkboxReducer', () => { it('creates default state', () => { const state = checkboxReducer(undefined, { type: 'anyAction' }) expect(state).toEqual({}) }) it('sets checked flag', () => { const state = checkboxReducer(undefined, { type: CHECKBOX_CLICK, payload: 'anyName' }) expect(state.anyName).toBe(true) })})
Минимальный код для прохождения данного теста будет выглядеть следующим образом:
// reducers/reducers.tsimport { CHECKBOX_CLICK } from 'actionTypes'const initialState: Record<string, boolean> = {}export const checkboxReducer = ( state = initialState, action: { type: string; payload?: string },) => { if (action.type === CHECKBOX_CLICK && action.payload) { return { ...state, [action.payload]: true } } return state}
Мы убедились, что при обработке экшена, в котором содержится имя чекбокса, в
state будет состояние о том, что он
отмечен. Теперь напишем тест, который проверит обратное поведение,
т.е. если чекбокс был отмечен, то отметка должна быть снята,
свойство должно получить значение false.
// reducers/reducers.test.ts it('sets checked flag to false when it was checked', () => { const state = checkboxReducer({ anyName: true }, { type: CHECKBOX_CLICK, payload: 'anyName' }) expect(state.anyName).toBe(false) })
Убеждаемся, что тест красный, т.к. у нас всегда устанавливается значение в
true, ведь до сего момента у нас не было
других требований к коду. Исправим это.
// reducers/reducers.tsimport { CHECKBOX_CLICK } from 'actionTypes'const initialState: Record<string, boolean> = {}export const checkboxReducer = ( state = initialState, action: { type: string; payload?: string },) => { if (action.type === CHECKBOX_CLICK && action.payload) { return { ...state, [action.payload]: !state[action.payload] } } return state}
Отлично! Мы описали всю необходимую бизнес-логику в тестах, написали код, который этим тестам удовлетворяет.
Selectors
Чтобы получить состояние чекбокса, нам понадобится Selector. Селекторы это функции, которые умеют извлекать требуемую информацию из общего состояния приложения. Если в нескольких частях приложения требуется одинаковая информация, используется один и тот же селектор.
Напишем первый тест для селектора.
// selectors/selectors.test.tsimport { getCheckboxState } from './selectors'describe('getCheckboxState', () => { const state = { checkboxes: { anyName: true }, } it('returns current checkbox state', () => { const result = getCheckboxState('anyName')(state) expect(result).toBe(true) })})
Теперь заставим его позеленеть.
Так как селектор должен знать, откуда извлекать информацию, определим структуру хранения.
// types.tsexport type State = { checkboxes: Record<string, boolean>}
Теперь напишем код селектора. Здесь используется функция высшего порядка из-за особенностей хука
useSelector пакета
react-redux, который принимает на вход функцию,
принимающую один аргумент текущее состояние стора, а нам требуется
сообщить ещё дополнительные параметры название чекбокса.
// selectors/package.json{ "main": "./selectors"}// selectors/selectors.tsimport { State } from 'types'export const getCheckboxState = (name: string) => (state: State) => state.checkboxes[name]
Кажется, мы всё сделали правильно, тест теперь зелёный. Но что произойдёт, если у нас ещё не было информации о состоянии чекбокса? Напишем ещё один тест.
// selectors/selectors.test.ts it('returns false when checkbox state is undefined', () => { const result = getCheckboxState('anotherName')(state) expect(result).toBe(false) })
Получим вот такую картину:

И это правильно, мы получили на выходе
undefined, т.е.
state ничего не знает об этом чекбоксе. Исправим код.
// selectors/selectors.tsimport { State } from 'types'export const getCheckboxState = (name: string) => (state: State) => state.checkboxes[name] ?? false
Вот теперь селектор работает, как и требуется.
Store
Давайте теперь создадим сам Store, т.е. специальный объект Redux, в котором хранится состояние приложения.
// store.tsimport { AnyAction, createStore, combineReducers } from 'redux'import { State } from 'types'import { checkboxReducer } from 'reducers'export const createAppStore = (initialState?: State) => createStore<State, AnyAction, unknown, unknown>( combineReducers({ checkboxes: checkboxReducer, }), initialState, )export default createAppStore()
Этот код мы отдельно тестировать не будем, т.к. мы используем стороннюю библиотеку, которая уже протестирована. Но далее мы напишем интеграционный тест, который проверит всю связку React + Redux.
React Components
Т.к. всю необходимую бизнес-логику мы уже описали, можем приступить к слою отображения.
Для более удобной работы мы написали небольшую утилиту для тестов. В ней несколько больше функциональности, чем требуется для нашего первого теста, но далее мы всё это применим. Используем удобную библиотеку
react-test-renderer, которая позволяет не
производить рендер в настоящий DOM, а получать его JS
представление. Установим пакет:
npm i react-test-renderer @types/react-test-renderer
Приступим к написанию тестов на компоненты. Начнём непосредственно с чекбокса.
Checkbox
// components/Checkbox/Checkbox.test.tsximport { create } from 'react-test-renderer'import Checkbox from '.'describe('Checkbox', () => { it('renders checkbox input', () => { const checkboxName = 'anyName' const renderer = create(<Checkbox />) const element = renderer.root.findByType('input') expect(element.props.type).toBe('checkbox') })})
Первый тест компонента проверяет, что внутри
Checkbox
рендерится стандартный input с типом
checkbox.Сделаем тест зелёным.
// components/Checkbox/package.json{ "main": "Checkbox"}// components/Checkbox/Checkbox.tsximport React from 'react'const Checkbox: React.FC = () => { return ( <div> <input type="checkbox" /> </div> )}export default Checkbox
Отлично, теперь добавим свойство
label, содержащее
текст для html элемента label, который должен
отображаться рядом с чекбоксом.
// components/Checkbox/Checkbox.test.tsxit('renders label', () => { const labelText = 'anyLabel' const renderer = create(<Checkbox label={labelText} />) const element = renderer.root.findByType('label') expect(element.props.children).toBe(labelText) })
Заставим тест пройти.
// components/Checkbox/Checkbox.tsxconst Checkbox: React.FC<{ label: string }> = ({ label }) => { return ( <div> <input type="checkbox" /> <label>{label}</label> </div> )}
Осталась небольшая деталь чекбокс как-то должен себя идентифицировать, кроме того, для корректной работы клика по
label, нужно прописать id чекбокса в свойство
htmlFor. Напишем тест, проверяющий установку свойства
id:
// components/Checkbox/Checkbox.test.tsx it('sets name prop as input id', () => { const checkboxName = 'anyCheckbox' const renderer = create(<Checkbox name={checkboxName} label={'anyLabel'} />) const element = renderer.root.findByType('input') expect(element.props.id).toBe(checkboxName) })
Убедившись, что он красный, исправим код:
// components/Checkbox/Checkbox.tsxconst Checkbox: React.FC<{ name: string; label: string }> = ({ name, label }) => { return ( <div> <input id={name} type="checkbox" /> <label>{label}</label> </div> )}
Тест зеленый, можем написать ещё один, который проверит установку свойства name в свойство
htmlFor элемента
label.
// components/Checkbox/Checkbox.test.tsx it('sets name prop as label htmlFor', () => { const checkboxName = 'anyCheckbox' const renderer = create(<Checkbox name={checkboxName} label={'anyLabel'} />) const element = renderer.root.findByType('label') expect(element.props.htmlFor).toBe(checkboxName) })
Тест красный, нужно снова поправить код.
// components/Checkbox/Checkbox.tsxconst Checkbox: React.FC<{ name: string; label: string }> = ({ name, label }) => { return ( <div> <input id={name} type="checkbox" /> <label htmlFor={name}>{label}</label> </div> )}
Пора бы подключить Store к компоненту. Напишем тест, который покажет, что состояние чекбокса (свойство
checked)
соответствует тому, что хранится в Store.
// components/Checkbox/Checkbox.test.tsximport { Provider } from 'react-redux'import { create } from 'react-test-renderer'import { createAppStore } from 'store'import Checkbox from '.'// omit old code it('sets checked flag from store when it`s checked', () => { const store = createAppStore({ checkboxes: { anyName: true } }) const renderer = create( <Provider store={store}> <Checkbox name="anyName" label="anyLabel" /> </Provider>, ) const element = renderer.root.findByType('input') expect(element.props.checked).toBe(true) })
Тест пока красный, т.к. компонент ничего не знает о сторе. Заставим тест позеленеть.
// components/Checkbox/Checkbox.tsximport React from 'react'import { useSelector } from 'react-redux'import { getCheckboxState } from 'selectors'const Checkbox: React.FC<{ name: string; label: string }> = ({ name, label }) => { const checked = useSelector(getCheckboxState(name)) return ( <div> <input id={name} type="checkbox" checked={checked} /> <label htmlFor={name}>{label}</label> </div> )}export default Checkbox
Тест пройден. Наконец-то, мы задействовали Redux! Мы использовали ранее написанный селектор
getCheckboxState, который
вызвали с помощью хука useSelector, получили значение
и передали его в свойство checked элемента
input. Но сейчас произошла другая проблема сломались
остальные тесты на компонент.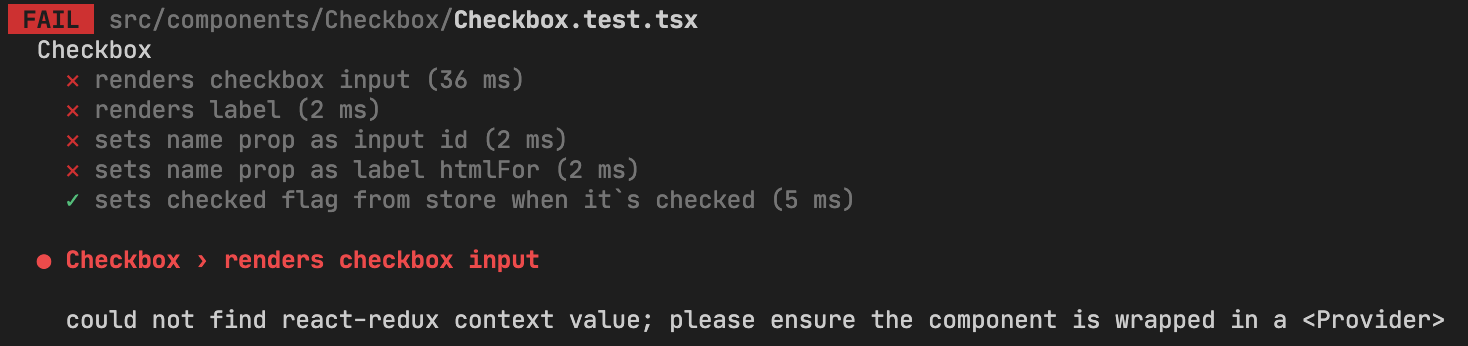
Дело в том, что ранее в тестах мы не передавали стор в компонент. Выделим часть с провайдером стора в функцию и перепишем наши тесты.
// components/Checkbox/Checkbox.test.tsximport { ReactElement } from 'react'import { Provider } from 'react-redux'import { create } from 'react-test-renderer'import { createAppStore } from 'store'import { State } from 'types'import Checkbox from '.'export const renderWithRedux = (node: ReactElement, initialState: State = { checkboxes: {} }) => { const store = createAppStore(initialState) return create(<Provider store={store}>{node}</Provider>)}describe('Checkbox', () => { it('renders checkbox input', () => { const checkboxName = 'anyName' const renderer = renderWithRedux(<Checkbox />) const element = renderer.root.findByType('input') expect(element.props.type).toBe('checkbox') }) it('renders label', () => { const labelText = 'anyLabel' const renderer = renderWithRedux(<Checkbox label={labelText} />) const element = renderer.root.findByType('label') expect(element.props.children).toBe(labelText) }) it('sets name prop as input id', () => { const checkboxName = 'anyCheckbox' const renderer = renderWithRedux(<Checkbox name={checkboxName} label={'anyLabel'} />) const element = renderer.root.findByType('input') expect(element.props.id).toBe(checkboxName) }) it('sets name prop as label htmlFor', () => { const checkboxName = 'anyCheckbox' const renderer = renderWithRedux(<Checkbox name={checkboxName} label={'anyLabel'} />) const element = renderer.root.findByType('label') expect(element.props.htmlFor).toBe(checkboxName) }) it('sets checked flag from store when it`s checked', () => { const initialState = { checkboxes: { anyName: true } } const renderer = renderWithRedux(<Checkbox name="anyName" label="anyLabel" />, initialState) const element = renderer.root.findByType('input') expect(element.props.checked).toBe(true) })})
Функция renderWithRedux выглядит достаточно полезной, вынесем её в отдельный модуль и импортируем в тестах.
// utils.tsximport { ReactElement } from 'react'import { Provider } from 'react-redux'import { create } from 'react-test-renderer'import { Store } from './types'import { createAppStore } from './store'export const renderWithRedux = (node: ReactElement, initialState: Store = { checkboxes: {} }) => { const store = createAppStore(initialState) return create(<Provider store={store}>{node}</Provider>)}
В итоге, шапка тестового файла будет выглядеть вот так:
// components/Checkbox/Checkbox.test.tsximport { renderWithRedux } from 'utils'import Checkbox from '.'describe('Checkbox', () => {
Для полной уверенности напишем ещё один тест, который проверит, что
checked бывает и false.
// components/Checkbox/Checkbox.test.tsx it('sets checked flag from store when it`s unchecked', () => { const initialState = { checkboxes: { anyName: false } } const renderer = renderWithRedux(<Checkbox name="anyName" label="anyLabel" />, initialState) const element = renderer.root.findByType('input') expect(element.props.checked).toBe(false) })
Тест пройден, но у нас теперь появилось два теста с похожими описаниями и почти идентичным кодом, давайте немного модифицируем наши тесты, создав табличный тест. Последние два теста превратятся в один:
// components/Checkbox/Checkbox.test.tsx test.each` storedState | state ${true} | ${'checked'} ${false} | ${'unchecked'} `('sets checked flag from store when it`s $state', ({ storedState }) => { const initialState = { checkboxes: { anyName: storedState } } const renderer = renderWithRedux(<Checkbox name="anyName" label="anyLabel" />, initialState) const element = renderer.root.findByType('input') expect(element.props.checked).toBe(storedState) })
Так уже лучше. А теперь самое вкусное напишем интеграционный тест, который проверит, что при нажатии на чекбокс, он изменит своё состояние, т.е. свойство checked.
// components/Checkbox/Checkbox.test.tsximport { act } from 'react-test-renderer'// omit old code it('changes it`s checked state when it`s clicked', () => { const initialState = { checkboxes: { anyName: false } } const renderer = renderWithRedux(<Checkbox name="anyName" label="anyLabel" />, initialState) const element = renderer.root.findByType('input') act(() => { element.props.onChange() }) expect(element.props.checked).toBe(true) })
Здесь мы воспользовались функцией
act, пакета
react-test-renderer, выполняя которую, мы убеждаемся в
том, что все сайд-эффекты уже произошли и мы можем продолжить
проверки. И далее проверяем, что когда будет вызвано событие
onChange на нашем чекбоксе, он изменит свойство
checked на true. Пока этого не
происходит, требуется написать код. Окончательный вариант
компонента примет вот такой вид.
// components/Checkbox/Checkbox.tsximport React from 'react'import { useDispatch, useSelector } from 'react-redux'import { getCheckboxState } from 'selectors'import { checkboxClick } from 'actions'const Checkbox: React.FC<{ name: string; label: string }> = ({ name, label }) => { const dispatch = useDispatch() const checked = useSelector(getCheckboxState(name)) const handleClick = React.useCallback(() => { dispatch(checkboxClick(name)) }, [dispatch, name]) return ( <div> <input id={name} type="checkbox" checked={checked} onChange={handleClick} /> <label htmlFor={name}>{label}</label> </div> )}export default Checkbox
В коде мы навесили обработчик на событие
change,
который отправляет action в store, создаваемый функцией
checkboxClick. Как видим, тест позеленел. Не открывая
браузера и даже не запуская сборку приложения, мы имеем
протестированный компонент с отдельным слоем бизнес-логики,
заключенной в Redux.AgreementSubmitButton
Нам требуется ещё один компонент непосредственно кнопка Submit, создадим его. Конечно, вначале тест:
// components/AgreementSubmitButton/AgreementSubmitButton.test.tsximport { renderWithRedux } from 'utils'import AgreementSubmitButton from '.'describe('AgreementSubmitButton', () => { it('renders button with label Submit', () => { const renderer = renderWithRedux(<AgreementSubmitButton />) const element = renderer.root.findByType('input') expect(element.props.type).toBe('button') expect(element.props.value).toBe('Submit') })})
Теперь заставим тест позеленеть:
// components/AgreementSubmitButton/package.json{ "main": "./AgreementSubmitButton"}// components/AgreementSubmitButton/AgreementSubmitButton.tsximport React from 'react'const AgreementSubmitButton: React.FC = () => { return <input type="button" value="Submit" />}export default AgreementSubmitButton
Тест зелёный, начало положено. Напишем новый тест, проверяющий зависимость свойства disabled новой кнопки от состояния чекбокса. Т.к. может быть два состояния, вновь используем табличный тест:
// components/AgreementSubmitButton/AgreementSubmitButton.test.tsx test.each` checkboxState | disabled | agreementState ${false} | ${true} | ${'not agreed'} ${true} | ${false} | ${'agreed'} `( 'render button with disabled=$disabled when agreement is $agreementState', ({ checkboxState, disabled }) => { const initialState = { checkboxes: { agree: checkboxState } } const renderer = renderWithRedux(<AgreementSubmitButton />, initialState) const element = renderer.root.findByType('input') expect(element.props.disabled).toBe(disabled) }, )
Имеем двойной красный тест, напишем код для прохождения этого теста. Компонент станет выглядеть вот так:
// components/AgreementSubmitButton/AgreementSubmitButton.tsximport React from 'react'import { useSelector } from 'react-redux'import { getCheckboxState } from 'selectors/selectors'const AgreementSubmitButton: React.FC = () => { const checkboxName = 'agree' const agreed = useSelector(getCheckboxState(checkboxName)) return <input type="button" value="Submit" disabled={!agreed} />}export default AgreementSubmitButton
Ура, все тесты зелёные!
Следует обратить внимание, что в табличном тесте мы намеренно использовали два различных параметра
checkboxState и
disabled, хотя может показаться, что достаточно только
первого, а в тесте написать вот так
expect(element.props.disabled).toBe(!disabled).
Но это плохой паттерн закладывать какую-то логику внутри тестов.
Вместо этого мы явно описываем входные и выходные параметры. Так
же, мы здесь немного ускорились, т.к., фактически написали два
теста за раз. Такое допустимо, когда чувствуешь в себе силы и
понимаешь, что реализация достаточно очевидная. Когда уровень
владения TDD ещё не совершенный, лучше создавать по одному тесту за
раз. В нашем случае это писать по одной строчке в таблице.LicenseAgreement
Оформим нашу работу в то, ради чего мы всё это затевали в форму принятия лицензионного соглашения. Какие имеются требования к форме:
- Содержится заголовок и непосредственно текст лицензионного соглашения. Эта часть компонента не требует тестирования.
- На форме имеется компонент
Checkboxс определеннымиlabelиname. Это можно и нужно тестировать. - На форме имеется кнопка
AgreementSubmitButton. Это тоже прекрасно поддаётся тестированию.
Приступим, первый тест на то, что на форме есть
Checkbox:
// components/LicenseAgreement/LicenseAgreement.test.tsximport { renderWithRedux } from 'utils'import Checkbox from 'components/Checkbox'import LicenseAgreement from '.'jest.mock('components/Checkbox', () => () => null)describe('LicenseAgreement', () => { it('renders Checkbox with name and label', () => { const renderer = renderWithRedux(<LicenseAgreement />) const element = renderer.root.findByType(Checkbox) expect(element.props.name).toBe('agree') expect(element.props.label).toBe('Agree') })})
На что тут стоит обратить внимание мы использовали тестовый дублёр для компонента
Checkbox в строчке
jest.mock('components/Checkbox', () => () =>
null). Это делает наш тест изолированным, таким образом он
не зависит от реализации Checkbox, возможные ошибки в
этом компоненте не повлияют на результат выполнения данного теста.
Дополнительно это экономит вычислительные ресурсы и время
выполнения тестов. Тест красный, требуется написать правильный
код:
// components/LicenseAgreement/package.json{ "main": "./LicenseAgreement"}// src/components/LicenseAgreement/LicenseAgreement.tsximport React from 'react'import Checkbox from 'components/Checkbox'const LicenseAgreement: React.FC = () => { return ( <div> <Checkbox name="agree" label="Agree" /> </div> )}export default LicenseAgreement
Получили зеленый тест, можем написать второй для этого компонента. Файл с тестами изменится:
// components/LicenseAgreement/LicenseAgreement.test.tsximport { renderWithRedux } from 'utils'import Checkbox from 'components/Checkbox'import AgreementSubmitButton from 'components/AgreementSubmitButton'import LicenseAgreement from '.'jest.mock('components/Checkbox', () => () => null)jest.mock('components/AgreementSubmitButton', () => () => null)describe('LicenseAgreement', () => { it('renders Checkbox with name and label', () => { const renderer = renderWithRedux(<LicenseAgreement />) const element = renderer.root.findByType(Checkbox) expect(element.props.name).toBe('agree') expect(element.props.label).toBe('Agree') }) it('renders SubmitAgreementButton', () => { const renderer = renderWithRedux(<LicenseAgreement />) expect(() => renderer.root.findByType(AgreementSubmitButton)).not.toThrow() })})
Чтобы он позеленел, добавим
AgreementSubmitButton в
компонент:
// src/components/LicenseAgreement/LicenseAgreement.tsximport React from 'react'import Checkbox from 'components/Checkbox'import AgreementSubmitButton from 'components/AgreementSubmitButton'const LicenseAgreement: React.FC = () => { return ( <div> <Checkbox name="agree" label="Agree" /> <AgreementSubmitButton /> </div> )}export default LicenseAgreement
Заметим, что
Checkbox и
AgreementSubmitButton не зависят друг от друга. Каждый
компонент зависит только от стора и больше ни от чего.Ключ на старт!
Вставим над компонентами сам текст соглашения, далее можем добавлять компонент в приложение. В сгенерированном приложении имеется корневой компонент
App, модифицируем его тесты
на проверку рендера LicenseAgreement:
// App.test.tsximport { renderWithRedux } from 'utils'import LicenseAgreement from 'components/LicenseAgreement'import App from 'App'jest.mock('components/LicenseAgreement', () => () => null)test('renders LicenseAgreement', () => { const renderer = renderWithRedux(<App />) expect(() => renderer.root.findByType(LicenseAgreement)).not.toThrow()})
Заставим тест позеленеть:
// App.tsximport React from 'react'import LicenseAgreement from 'components/LicenseAgreement'const App: React.FC = () => { return <LicenseAgreement />}export default App
Мы получили зелёный тест, можно, наконец, запустить сборку приложения с помощью
npm start. Сборка пройдёт
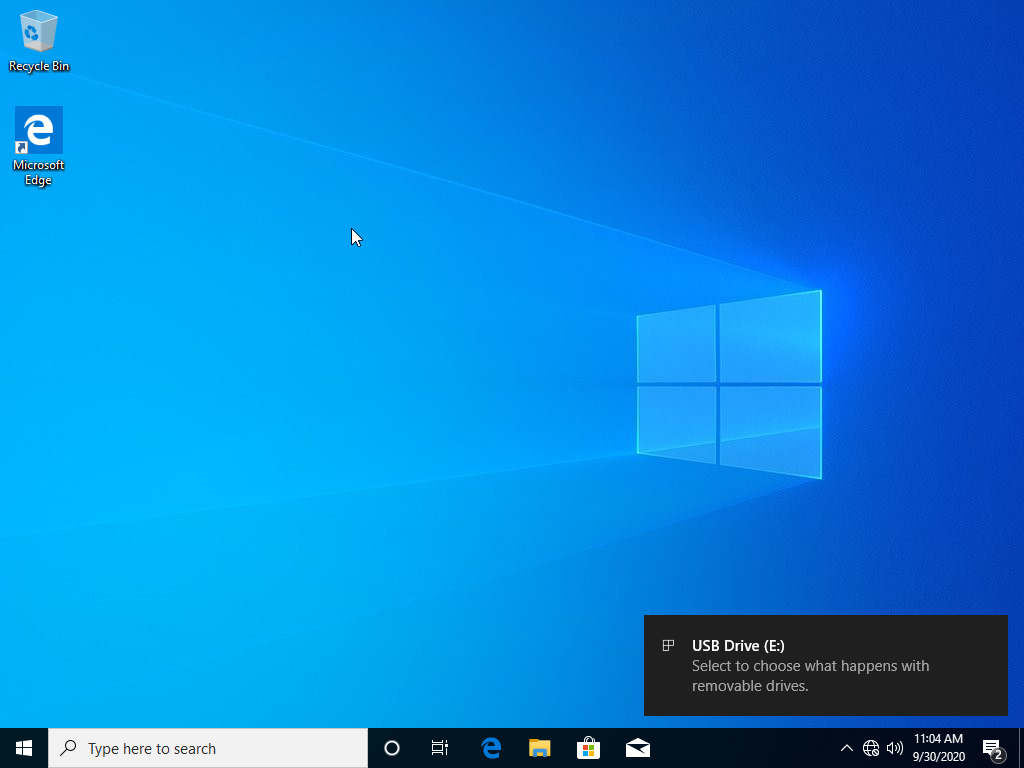
успешно, но в браузере мы увидим следующую картину:
Это говорит о том, что мы не подключили Redux store в само приложение. Сделаем это в файле
index.tsx:
// index.tsximport React from 'react'import ReactDOM from 'react-dom'import { Provider } from 'react-redux'import 'index.css'import store from 'store'import App from 'App'ReactDOM.render( <React.StrictMode> <Provider store={store}> <App /> </Provider> </React.StrictMode>, document.getElementById('root'),)
Теперь приложение запускается, всё работает, как ожидается, кроме внешнего вида:

Исправим это, поправив вёрстку, и получим конечный результат:

Заключение
Я намеренно выбрал максимально простой пример, чтобы не перегружать статью текстом и кодом. Конечно, здесь можно было обойтись и без Redux, а хранить состояние чекбокса в локальном стейте компонента, и на мелких компонентах это может быть оправдано. Но по мере роста приложения, преимущества Redux будут становиться всё более очевидными, особенно когда появляется более сложная бизнес-логика, которую потребуется тестировать. Redux позволяет избавиться от прокидывания свойств через множество компонентов, каждый компонент либо достает необходимую информацию из стора самостоятельно, либо сам же диспатчит экшены.
Во второй части данной статьи предполагался рассказ о библиотеке Redux Tookilt, которая значительно упрощает использование Redux в разработке фронтенд-приложений, но я решил в следующей статье показать, как можно написать настоящее полезное приложение, хоть и очень простое, на React, Redux и Redux Toolkit.
Исходные коды полученного приложения доступны на GitHub.
Дополнительные источники информации:







































 Шон
Престридж старший инженер по применению (FAE), руководитель группы
FAE американского подразделения IAR Systems в своей статье Move
fast and break things? Not so fast in embedded, рассказывает о
специфике разработки программного обеспечения для встраиваемых
систем, уделяя особое внимание вопросам качества кода и
тестирования.
Шон
Престридж старший инженер по применению (FAE), руководитель группы
FAE американского подразделения IAR Systems в своей статье Move
fast and break things? Not so fast in embedded, рассказывает о
специфике разработки программного обеспечения для встраиваемых
систем, уделяя особое внимание вопросам качества кода и
тестирования.



