Прим перев.: месяц назад Povilas
Versockas, CNCF Ambassador и software engineer из Литвы, написал
очень подробную статью о том, как работает и как использовать VPA в
Kubernetes. Рады поделиться её переводом для русскоязычной
аудитории!
Это полное руководство по вертикальному автомасштабированию
pod'ов (Vertical Pod Autoscaling, VPA) в Kubernetes. Вот его
краткое содержание:
-
Зачем нам VPA?
-
Модель ресурсных требований Kubernetes;
-
Что такое вертикальное автомасштабирование pod'ов?
-
Работа с рекомендациями;
-
Когда использовать VPA?
-
Ограничения VPA;
-
Реальные примеры использования;
-
Как работает VPA?
-
Модель рекомендаций VPA;
-
Дополнительная информация.

Схема работы Kubernetes VPA от Banzai Cloud
Что ж, давайте приступим.
Зачем нам VPA?
При развертывании приложения в Kubernetes необходимо указывать
его ресурсные запросы. Обычно инженеры начинают с некоторого
случайного числа, взятого с потолка. Дальнейшая работа над
приложениями и их деплой в кластер будут приводить к росту этих
взятых с потолка заявок на ресурсы. И разница между заявленным и
реальным потреблением ресурсов будет только расти.
Дело в том, что разработчикам довольно тяжело угадать правильный
объем ресурсов. Им сложно оценить, сколько требуется приложению для
оптимальной работы, установить правильную комбинацию CPU-мощностей,
памяти и числа параллельно работающих реплик.
Кроме того, со временем модель использования приложения может
меняться. Некоторым приложениям потребуется больше CPU и памяти. У
других, менее популярных, требования к ресурсам, наоборот,
снизятся.
-
С недостатком заявленных ресурсов обычно разбираются DevOps- или
SRE-инженеры при поступлении соответствующих оповещений.
SRE-инженеры видят, что приложение отбрасывает запросы конечных
пользователей из-за убийств pod'ов, вызванных ошибкой
Out-of-Memory, или оно начинает медленно работать из-за троттлинга
процессора.
-
С другой стороны, избыток заявленных ресурсов не приводит к
проблемам сразу, но вносит свой вклад в масштабный перерасход
ресурсов. В результате команда по обслуживанию
инфраструктуры/платформы вынуждена добавлять новые K8s-узлы, хотя
реальная потребность в ресурсах невелика.
Решением этих проблем и занимается автомасштабирование.
Горизонтальное масштабирование определяет оптимальное число реплик
для приложения. Например, у вас может быть завышено количество
pod'ов, что приводит к ненужному расходованию ресурсов.
В свою очередь, вертикальное масштабирование определяет
оптимальные требования к CPU и памяти. В этой статье пойдет речь
исключительно о вертикальном автомасштабировании pod'ов.
Но сначала давайте поговорим о модели ресурсных требований
Kubernetes.
Модель ресурсных требований Kubernetes
Kubernetes требует от пользователей указывать заявки на ресурсы
с помощью resource requests (запросов на ресурсы) и
resource limits (лимитов на ресурсы). Давайте начнем с
запросов:
Запросы на ресурсы резервируют некоторое количество
ресурсов за приложением. Можно определять запросы для
контейнеров в pod'е. Планировщик использует эту информацию, чтобы
определить, куда разместить pod. Запросы можно представить как
некоторый минимальный объем ресурсов, который требуется pod'у для
нормальной работы.
Тут важно отметить, что приложение может задействовать больше
ресурсов, если узел располагает свободными мощностями. А
максимальный объем ресурсов, которыми может воспользоваться
контейнер, устанавливается в лимитах. Если потребление памяти
окажется больше указанного предела, pod будет убит. Если контейнер
использует больше процессорной мощности, чем позволяет лимит,
начинается троттлинг.
Лимиты фактически выступают этаким предохранительным
клапаном. Они препятствуют потреблению приложением
неограниченного объема памяти, если в нем имеется ее утечка. Точно
так же они спасают вас от приложений, стремящихся захватить
процессор целиком. Представьте, что кто-то развернул
биткоин-майнеры: это вызовет процессорный голод для всех остальных
приложений в кластере.
Важно, что если на узле нет свободных ресурсов, вы не сможете их
получить. Таким образом, гарантия для запрашиваемых ресурсов
обеспечивается только в случае их фактического наличия.
Кроме того, если вы не определите запросы, Kubernetes
автоматически приравняет их к лимитам pod'а.
Многие ограничиваются заданием запросов на ресурсы, и
это распространенная ошибка. Пользователи надеются, что в
этом случае приложение будет располагать неограниченными ресурсами
и ему не придется иметь дело с нехваткой памяти или троттлингом.
Однако Kubernetes этого не допустит. Поэтому обязательно задавайте
как запросы на ресурсы (resource requests), так и лимиты
(limits).
Более того, эту ресурсную модель можно расширить. Могут быть и
другие вычислительные ресурсы, такие как эфемерное хранилище, GPU,
huge pages в Linux.
В статье же мы ограничимся процессорными мощностями и памятью,
поскольку на данный момент Vertical Pod Autoscaler работает только
с ними. Тем, кто желает узнать больше, рекомендую обратиться к
соответствующему разделу документации Kubernetes (Managing
Resources for Containers).
Что такое вертикальное автомасштабирование pod'ов?
Как следует из названия, вертикальное автомасштабирование pod'ов
(VPA) позволяет автоматически устанавливать запросы на
ресурсы и лимиты для контейнеров. Решения принимаются на
основе прошлых данных об использовании CPU и памяти.
Основная цель VPA уменьшить потери ресурсов и
минимизировать риск снижения производительности из-за троттлинга
CPU или ошибок, вызванных убийством pod'ов из-за Out Of
Memory.
Поддержкой VPA занимаются инженеры Google. Система называется
Autopilot и основана на опыте создания соответствующей внутренней
системы для оркестратора контейнеров Borg. Результаты Google от
использования Autopilot в production следующие:
На практике избыток ресурсов для заданий под управлением
Autopilot составил всего 23% по сравнению с 46% для заданий,
управляемых вручную. Кроме того, Autopilot на порядок сократил
количество заданий, пострадавших от OOM.
Autopilot: workload autoscaling at Google
Дополнительную информацию можно почерпнуть из самой публикации
(Autopilot:
workload autoscaling at Google).
VPA вводит несколько Custom Resource Definitions (CRD) для
управления поведением автоматических рекомендаций. Как правило,
разработчикам требуется добавить объект VerticalPodAutoscaler в
свои deploymentы.
Давайте разберемся, как его использовать.
Как использовать VPA?
Ресурс VPA предоставляют массу возможностей для управления
рекомендациями. Чтобы получить лучшее представление об
использовании VPA, посмотрим на сам объект
VerticalPodAutoscaler:
apiVersion: autoscaling.k8s.io/v1kind: VerticalPodAutoscalermetadata: name: prometheus-vpaspec: targetRef: apiVersion: "apps/v1" kind: StatefulSet name: prometheus updatePolicy: updateMode: "Recreate" containerPolicies: - containerName: "*" minAllowed: cpu: 0m memory: 0Mi maxAllowed: cpu: 1 memory: 500Mi controlledResources: ["cpu", "memory"] controlledValues: RequestsAndLimits
Настройка VerticalPodAutoscaler начинается с задания
targetRef, указывающего на некий контроллер-объект
Kubernetes, отвечающий за управление pod'ами.
VPA поддерживает все распространенные типы контроллеров:
Deployment, StatefulSet, DaemonSet, CronJobs. Он также должен
работать с любыми кастомными типами, реализующими
подресурс scale. VPA получает набор pod'ов с помощью
метода контроллера ScaleStatus. В примере выше мы
автомасштабируем StatefulSet с именем prometheus.
Поле updateMode позволяет выбрать режим работы
контроллера. Есть несколько вариантов:
-
Off VPA не будет автоматически изменять ресурсные
требования. Autoscaler подсчитывает рекомендации и хранит их в поле
status объекта VPA;
-
Initial VPA устанавливает запросы на ресурсы только
при создании pod'а и не меняет их потом;
-
Recreate VPA устанавливает запросы на ресурсы при
создании pod'ов и обновляет их для существующих pod'ов, вытесняя
(evict) в случаях, когда запрашиваемые ресурсы значительно
отличаются от новой рекомендации;
-
Auto в настоящее время делает то же самое, что и
Recreate. В будущем возможно использование обновлений
без перезапуска (restart-free updates), когда этот
механизм станет доступен (подробнее о нем рассказывается,
например, в этом
видео прим. перев.).
Далее для каждого контейнера в pod'е нужно определить
resourcePolicy. Эти политики позволяют выбрать
контейнеры, для которых будут приводиться рекомендации по ресурсам,
и задать способ, которым это будет осуществляться.
Вы определяете список resource policies, которые фильтруются по
containerName. Можно выбрать конкретный контейнер в
pod'е и сопоставить его с некой resource policy. Также можно
указать * в качестве значения
containerName этим вы определите resource policy по
умолчанию (на случай, если ни одна другая resource policy не
соответствует containerName).
Resource policies позволяют ограничить ресурсные рекомендации
диапазоном, лежащем между minAllowed и
maxAllowed. В случае, если minAllowed и
maxAllowed не заданы, ресурсы не ограничены.
С помощью controlledResources можно выбрать ресурсы
для рекомендаций. Пока поддерживаются только CPU и память. Если
типы ресурсов не указаны, то VPA будет давать рекомендации как по
использованию процессора, так и по использованию памяти.
Наконец, controlledValues позволяет выбрать, какие
параметры будут контролироваться: RequestsOnly (только
запросы на ресурсы) или RequestsAndLimits (запросы на
ресурсы и лимиты). Значение по умолчанию
RequestsAndLimits.
Если выбрать RequestsAndLimits, то запросы будут
вычисляться на основе фактического использования. Тем временем,
лимиты будут вычисляться на основе текущего соотношения между
запросами и лимитами pod'а. Например, если pod изначально
запрашивает 1 CPU, а его лимит установлен на 2 CPU, то VPA будет
устанавливать лимит таким образом, чтобы тот всегда в два раза
превышал запрос. Аналогичный способ расчета применяется и к памяти.
Поэтому в режиме RequestsAndLimits рассматривайте
изначально заданные для приложения запросы на ресурсы и лимиты как
некий шаблон.
Объект VPA можно упростить, используя режим Auto и
вычисляя рекомендации для CPU и памяти. А именно:
apiVersion: autoscaling.k8s.io/v1kind: VerticalPodAutoscalermetadata: name: vpa-recommenderspec: targetRef: apiVersion: "apps/v1" kind: Deployment name: vpa-recommender updatePolicy: updateMode: "Auto" resourcePolicy: containerPolicies: - containerName: "*" controlledResources: ["cpu", "memory"]
Теперь давайте посмотрим на рекомендации, которые VPA записывает
в поле status соответствующего CRD.
Работа с рекомендациями
Как только вы примените (apply) объект
VeritcalPodAutoscaler, VPA начнет собирать данные об
использовании ресурсов и вычислять рекомендации по ним. Спустя
некоторое время в поле status объекта
VerticalPodAutoscaler должны появиться
рекомендации.
Просмотреть их можно с помощью:
kubectl describe vpa NAME
Давайте проанализируем пример отчета о состоянии:
Status: Conditions: Last Transition Time: 2020-12-23T08:03:07Z Status: True Type: RecommendationProvided Recommendation: Container Recommendations: Container Name: prometheus Lower Bound: Cpu: 25m Memory: 380220488 Target: Cpu: 410m Memory: 380258472 Uncapped Target: Cpu: 410m Memory: 380258472 Upper Bound: Cpu: 704m Memory: 464927423
Как видно, для контейнера prometheus предлагаются
четыре различные оценки. При этом оценки объема памяти приводятся в
байтах. Оценки CPU в миллиядрах (m, millicores). Давайте
разберемся, что означают эти оценки:
-
Lower bound (нижняя граница) минимальная оценка для
контейнера. Это значение не гарантирует, что приложение сможет
стабильно работать. Такие минимальные запросы на CPU и память,
скорее всего, окажут значительное влияние на производительность и
доступность.
-
Upper bound (верхняя граница) это максимальный
рекомендованный объем ресурсов для контейнера. Запросы выше этих
значений, скорее всего, будут приводить к тому, что ресурсы будут
расходоваться впустую.
-
Оценку Target (цель) мы будем использовать для задания
запросов на ресурсы.
Все эти оценки ограничены значениями minAllowed /
maxAllowed в containerPolicies.
Зачем нам четыре оценки? Vertical Pod Autoscaler использует
Lower и Upper bound для вытеснения (eviction) pod'ов. Если
текущий resource request ниже, чем lower bound, или выше, чем upper
bound, и происходит 10%-ное изменение ресурсных запросов по
сравнению с target-оценкой, то может произойти вытеснение.
Классно то, что VPA добавляет аннотации к pod'у при изменении
требований к ресурсам. Если сделать describe pod'а,
контролируемого VPA, то можно увидеть аннотации вроде
vpaObservedContainers (перечисление отслеживаемых
контейнеров) или vpaUpdates (описание предпринятых
действий). Также здесь можно увидеть, ограничена ли рекомендация
параметрами minAllowed/maxAllowed или
Kubernetes-объектом LimitRange. Вот пример аннотаций
pod'а:
apiVersion: v1kind: Podmetadata: annotations: vpaObservedContainers: recommender vpaUpdates: 'Pod resources updated by vpa-recommender: container 0: cpu request, memory request, cpu limit, memory limit'
Давайте разберемся, в каких случаях следует использовать
Vertical Pod Autoscaler.
Когда использовать VPA?
Во-первых, можно добавить VPA к базам данных и
stateful-нагрузкам при их запуске в Kubernetes. Как
правило, stateful-нагрузки тяжелее поддаются горизонтальному
масштабированию, поэтому автоматический способ, позволяющий
отмасштабировать потребляемые ресурсы или точно оценить потребность
в них, помогает решить многие проблемы с недостатком мощностей.
Если база данных не настроена как высокодоступная или не готова к
перерывам в работе, можно включить режимы Initial или Off. В этом
режиме VPA не будет вытеснять pod'ы и ограничится рекомендациями
запросов или их обновлением при перевыкате приложения.
Во-вторых, VPA хорошо подходит для CronJobs.
Vertical Pod Autoscaler способен проанализировать потребление
ресурсов повторяющимися заданиями и применить рекомендации,
полученные на основе этих данных, к очередному запланированному
запуску. Для этого нужно установить режим рекомендаций в
Initial. В таком случае каждое только что запущенное
задание будет получать рекомендации, подсчитанные на основе
прошлого запуска того же задания. Важно отметить, что это не
работает для кратковременных (менее 1 минуты) заданий.
В-третьих, stateless-нагрузки отличный кандидат для
Vertical Pod Autoscaling. Stateless-приложения обычно
менее чувствительны к перерывам в работе и вытеснению, так что это
отличный кандидат для старта. На них можно протестировать режимы
Auto и Recreate. Одно существенное
ограничение состоит в том, что VPA не будет работать совместно с
горизонтальным автомасштабированием, если оно производится по тем
же самым метрикам: CPU или памяти. Как правило, VPA используют с
приложениями с предсказуемым потреблением ресурсов, а также в том
случае, если запуск более чем нескольких реплик не имеет смысла.
Подобный тип приложений не имеет смысла масштабировать
горизонтально, и для них VPA правильный выбор.
Важно знать, что на данный момент VPA имеет некоторые
ограничения, из-за которых его не всегда хорошо использовать.
Ограничения VPA
-
Прежде всего, не используйте VPA с рабочими нагрузками на базе
JVM. Дело в том, что JVM не позволяет установить объем фактически
используемой памяти, поэтому рекомендации могут сильно отклоняться
от адекватных значений.
-
Также не стоит использовать VPA совместно с горизонтальным
автомасштабированием (HPA), основанном на тех же метриках (CPU или
памяти). В то же время два этих типа можно применять совместно,
если HPA работает с кастомными метриками.
-
Рекомендации VPA могут превысить доступные ресурсы, такие как
ресурсы кластера или квота вашей команды. Недостаток ресурсов может
привести к тому, что pod'ы окажутся в состоянии
Pending. С помощью объектов LimitRange
можно ограничивать запросы ресурсов для конкретного пространства
имен. Также можно устанавливать максимальные допустимые
рекомендации по ресурсам для pod'а в объекте
VerticalPodAutoscaler.
-
VPA в режиме Auto или Recreate не
будет выселять pod'ы с единственной репликой, так как это приведет
к простою в работе. Однако желающие включить автоматические
рекомендации для приложений с единственной репликой могут изменить
такое поведение. Для этого в компоненте updater имеется флаг
--min-replicas.
-
При работе в режиме RequestsAndLimits
устанавливайте первичные лимиты для CPU таким образом, чтобы они
многократно превышали request'ы. Связано это с
известной проблемой Kubernetes/ядра Linux, которая в
некоторых случаях может приводить к излишнему троттлингу
(ситуация подробно разобрана в этой
статье прим. перев.). Многие пользователи
Kubernetes либо полностью отключают троттлинг, либо устанавливают
огромные лимиты CPU, чтобы обойти проблему. Как правило, это не
приводит к плохим последствиям, поскольку использование CPU на
узлах кластера обычно невелико.
-
Не все рекомендации VPA достигают своей цели. Предположим, что у
вас имеется высокодоступная система из двух реплик, и один из
контейнеров решает быстро нарастить объем используемой памяти.
Такое стремительное увеличение потребляемой памяти может привести к
тому, что контейнер будет убит из-за Out of Memory. Поскольку
pod'ы, убитые Out Of Memory, не планируются заново, VPA не сможет
применить новые рекомендации для ресурсов. Вытеснение pod'а также
не произойдет, поскольку один pod всегда либо Not
Ready, либо попал в crash loop. То есть вы оказались в
тупике. Единственный способ разрешить эти ситуации убить pod и
позволить новым рекомендациям вступить в силу.
Теперь давайте рассмотрим несколько примеров из реальной
жизни.
Реальные примеры использования
Кластер MongoDB
Давайте начнем с кластера MongoDB, состоящего из трех реплик.
Первоначальные требования StatefulSet'а к ресурсам таковы:
resources: limits: memory: 10Gi requests: memory: 6Gi
Pod Disruption Budget допускает отключение только одной
реплики.
Далее мы разворачиваем StatefulSet без Vertical Pod Autoscaling
и даем ему поработать некоторое время.

На этом графике показано использование памяти кластером MongoDB.
Каждая из линий соответствует отдельной реплике. Видно, что
фактическое использование памяти для двух реплик близко к 3 Гб, а
для одной около 1,5 Гб.
Спустя некоторое время мы включаем автоматизацию ресурсных
требований, устанавливая объект Vertical Pod Autoscaler в режим
Auto (автоматическое масштабирование ресурсов CPU и памяти). VPA
рассчитывает рекомендацию и последовательно выселяет pod'ы. Вот как
может выглядеть рекомендация:
Container Recommendations: Container Name: mongodb Lower Bound: Cpu: 12m Memory: 3480839981 Target: Cpu: 12m Memory: 3666791614 Uncapped Target: Cpu: 12m Memory: 3666791614 Upper Bound: Cpu: 12m Memory: 3872270071
VPA установил запросы на память на 3,41 Гб, лимит на 5,6 Гб
(такое же отношение, как у 6 Гб и 10 Гб), запросы и лимиты для CPU
на 12 миллиядер.
Давайте посмотрим, как это соотносится с первоначальными
оценками. Мы запросили на 1,6 Гб меньше памяти на каждый pod. Таким
образом, в общей сложности мы сэкономили 4,8 Гб памяти. Разница
может показаться не особо существенной, но в случае большого числа
кластеров MongoDB объем сэкономленной памяти стремительно
возрастает.
etcd
Другой пример etcd. Это высокодоступная база данных,
использующая Raft в качестве алгоритма выбора лидера. Первоначально
запрашиваются только ресурсы CPU:
limits: cpu: 7requests: cpu: 10m
Далее мы разворачиваем StatefulSet без Vertical Pod Autoscaling
и даем ему поработать некоторое время:

На графике показано использование памяти кластером etcd. Каждая
из линий соответствует отдельной реплике. Как видно, одна реплика
использует около 500 Мб, две другие по 300 Мб.

А этот график показывает использование CPU. Видно, что оно
относительно постоянно и равно 0,03 ядра процессора.
Вот как выглядит рекомендация VPA:
Recommendation: Container Recommendations: Container Name: etcd Lower Bound: Cpu: 25m Memory: 587748019 Target: Cpu: 93m Memory: 628694953 Uncapped Target: Cpu: 93m Memory: 628694953 Upper Bound: Cpu: 114m Memory: 659017860
VPA запросил 599 Мб памяти (без лимитов) и 93 миллиядра CPU
(0.093 ядра) с лимитом в 65 ядер (придерживаясь первоначально
установленного соотношения запрос/лимит 1 к 700).
Таким образом, VPA зарезервировал предостаточно ресурсов для
полноценной работы etcd. Изначально мы не запрашивали память для
данного pod'а, что может привести к его планированию на слишком
загруженный узел и вызвать проблемы. Аналогичным образом,
запрошенные ресурсы CPU оказались недостаточны для работы etcd.
В нашем случае интересным открытием стало то, что текущий лидер
использует значительно больше памяти, чем остальные реплики. Как
видно, VPA рекомендовал одинаковый объем памяти всем репликам.
Таким образом, существует разрыв между запрошенным и используемым
объемом памяти. Поскольку вторичные узлы не будут использовать
более 300 Мб памяти, пока не станут первичными, на каждом из этих
узлов будут оставаться невостребованные ресурсы.
Хотя в данном примере разрыв вполне адекватен. В случае, если
один из вторичных узлов станет лидером, он сможет воспользоваться
зарезервированными ресурсами. Если бы мы их не зарезервировали,
данный узел мог бы быть убит из-за OOM, что привело бы к
простою.
Резервирование с CronJob
В заключительном примере пойдет речь о простом задании, которое
запускается по расписанию, снимает копию базы MongoDB и сохраняет
ее в S3. Задание запускается ежедневно и обычно занимает около 12
минут.
Изначально запросы на ресурсы установлены не были. Объект VPA
установлен в режим Initial, автомасштабируются память
и CPU.
Первая пара запусков прошла без запросов на ресурсы: VPA собирал
данные об их использовании. В это время VPA выводил ошибку No
pods match this VPA object. Для третьего запуска VPA предложил
следующие рекомендации:
Recommendation: Container Recommendations: Container Name: backupjob Lower Bound: Cpu: 25m Memory: 262144k Target: Cpu: 25m Memory: 262144k Uncapped Target: Cpu: 25m Memory: 262144k Upper Bound: Cpu: 507m Memory: 530622257
И при очередном запуске задания был создан pod с запросами на
25m CPU и 262144k памяти. Главный плюс всего этого в том, что
поскольку VPA работает в режиме Initial, никаких
вытеснений или перебоев в работе не происходит.
Теперь давайте разберемся, как работает Vertical Pod
Autoscaling.
Как работает VPA?
Vertical Pod Autoscaler состоит из трех различных
компонентов:
-
Recommender использует некоторые эвристики для подсчета
рекомендаций;
-
Updater отвечает за вытеснение pod'ов в случае, когда
происходит значительное изменение ресурсных требований;
-
Компонент Admission Controller задает ресурсные
требования pod'а.
Теоретически любой из компонентов можно заменить кастомным. И
все должно по-прежнему работать. Давайте рассмотрим компоненты
подробнее:
Recommender
Recommender содержит основную логику для оценки требующихся
ресурсов. Он отслеживает их фактическое потребление и события
out-of-memory, выдает рекомендации для запросов на ресурсы CPU и
памяти для контейнеров. Текущие рекомендации хранятся в поле
status объекта VerticalPodAutoscaler.
Можно выбрать, как именно Recommender будет получать начальную
статистику по использованию CPU и памяти. Он поддерживает
контрольные точки (checkpoints; установлены по умолчанию)
и Prometheus. Изменить это можно с помощью флага
--storage.
Контрольные точки хранят агрегированные метрики для CPU и памяти
в CRD-объектах VerticalPodAutoscalerCheckpoint.
Просмотреть сохраненные значения можно с помощью describe.
Recommender поддерживает контрольные точки на основе сигналов,
поступающих в реальном времени, которые он начинает собирать после
загрузки исторических метрик.
При работе с Prometheus Recommender выполняет запрос на PromQL,
в котором используются метрики cAdvisor. Recommender позволяет
настроить лейблы, используемые в запросе. Можно менять пространство
имен, имена pod'ов/контейнеров, лейблы имен заданий Prometheus. В
общем, он будет посылать запросы, похожие на этот:
rate(container_cpu_usage_seconds_total{job="kubernetes-cadvisor"}[8d]
и на этот:
container_memory_working_set_bytes{job="kubernetes-cadvisor"}
Результатом таких запросов станет информация об использовании
CPU и памяти. Recommender проанализирует результаты и будет
использовать их для рекомендаций ресурсов.
После загрузки исторических метрик он начнет в реальном времени
собирать метрики с API-сервера Kubernetes через Metrics API
(аналогично команде kubectl top). Кроме того, он будет
следить за событиями Out Of Memory, чтобы сразу адаптироваться к
таким ситуациям. Далее VPA подсчитывает рекомендации, сохраняет их
в объекты VPA и отслеживает контрольные точки. Интервал опроса
можно настроить с помощью флага
--recommender-interval.
О том, как VPA подсчитывает рекомендации, рассказано в следующем
разделе (Модель рекомендаций VPA).
Updater
Updater отвечает за соответствие ресурсных требований pod'ов
рекомендациям. Если VerticalPodAutoscaler работает в режиме
Recreate или Auto, Updater может
вытеснить pod, чтобы пересоздать его с новыми ресурсами. В будущем
режим Auto скорее всего воспользуется преимуществами
обновлений на месте (in-place updates), что позволит
избежать вытеснения. Впрочем, работа над этой функцией пока не
завершена. За ходом работ можно последить в этом
issue на GitHub.
При этом в Updater встроен ряд защитных механизмов,
ограничивающих вытеснение pod'ов:
-
Он не будет вытеснять pod, у которого нет по крайней мере двух
реплик. Изменить такое поведение можно с помощью флага
--min-replicas.
-
Поскольку используется API Kubernetes для вытеснения, Updater
соблюдает Pod Disruption Budgets. PDB позволяют задать требования к
доступности, чтобы предотвратить вытеснение слишком большого числа
pod'ов. Например, если установить максимальное число недоступных
(max unavailable) pod'ов равным единице, то компонент сможет
вытеснять только один pod. Подробнее о PDB
здесь.
-
По умолчанию вытесняется не более 50% pod'ов одного ReplicaSet.
Даже если PDB не используются, Updater все равно будет вытеснять
pod'ы медленно. Изменить это можно с помощью флага
--eviction-tolerance.
-
Также можно настроить глобальный ограничитель скорости
вытеснения с помощью флагов --eviction-rate-limit и
--eviction-rate-burst. По умолчанию они отключены.
Updater принимает решение о вытеснении podов на основе нижней и
верхней границ. Он вытеснит pod, если запрос на ресурсы меньше
нижней границы или больше верхней, а также присутствует
значительное изменение запросов на ресурсы по сравнений с целевой
оценкой. В настоящее время пороговая разница составляет 10%.
После вытеснения pod'а в игру вступает последний компонент
Admission Controller. Он отвечает за создание pod'а и применение
рекомендаций.
Admission Controller
Компонент Admission Controller задает ресурсные требования
pod'а.
Перед планированием pod'а Admission Controller получает
webhook-запрос от API-сервера Kubernetes на обновление спецификации
pod'а. Admission Controller делает это через конфигурацию mutating
webhookа (подробнее в
документации к Kubernetes Admission Control).
Просмотреть mutating webhookи можно с помощью следующей
команды:
kubectl get mutatingwebhookconfigurations
Если VPA установлен правильным образом, вы увидите конфигурацию
mutating webhookа для Admission Controller'а VPA.
Как только Admission Controller получает запрос, он сопоставляет
его с объектом VerticalPodAutoscaler. Если они не
совпадают, pod остается без изменений. Если pod соответствует
объекту VPA, Admission Controller (в зависимости от настроек
объекта VPA) может обновить или только запросы на ресурсы pod'а,
или запросы вместе с лимитами. Обратите внимание, что изменения в
ресурсные требования pod'а не будут вноситься, если режим
обновления установлен в Off.
Давайте теперь разберемся, как VPA рекомендует ресурсы.
Модель рекомендаций VPA для CPU
Предположим, у нас есть контейнер, и мы снимали данные об
использовании CPU каждую минуту в течение 48 часов. График загрузки
CPU выглядит следующим образом:

Для подсчета рекомендации для CPU мы создаем гистограмму с
экспоненциально растущими границами интервалов. Первый интервал
начинается от 0,01 ядра (1 миллиядра) и заканчивается примерно на
1000 ядрах CPU. Каждый интервал растет экспоненциально со скоростью
5%.
При добавлении данных об использовании CPU в гистограмму мы
находим интервал, в который попадает фактическое использование
процессора, и добавляем вес, зависящий от текущего запрошенного
значения для контейнера.
Когда запрос на CPU увеличивается, растет и вес интервала. Это
свойство делает предыдущие наблюдения менее значимыми, что помогает
быстро реагировать на троттлинг процессора.
Кроме того, мы уменьшаем вес со временем (по умолчанию период
его полураспада равен 24 часам). Таким образом, при добавлении в
гистограмму данных, с получения которых прошли сутки, их вес
составит половину от запрошенных контейнером ресурсов в то время.
Подобный распад позволяет увеличить значимость более поздних
выборок (то есть они оказывают большее влияние на предсказания,
нежели ранние данные). Период полураспада можно изменить с помощью
флага --cpu-histogram-decay-half-life.
Давайте превратим график использования CPU, приведенный выше, в
подобную гистограмму (с экспоненциальным ростом интервалов и
данными, взвешенными с учетом распада). Предположим, что в течение
всех 48 часов запрос на мощности CPU составляет 1 ядро.
Гистограмма будет выглядеть следующим образом:
. 37-й интервал имеет значение 1,016. Поскольку наш график никогда не достигает этого значения, он пуст.")
Примечание: мы построили график только
для первых 36 интервалов, поскольку остальные интервалы пусты.
Значения интервалов варьируются в диапазоне от 0 до 0,958 ядра CPU
(округленно). 37-й интервал имеет значение 1,016. Поскольку наш
график никогда не достигает этого значения, он пуст.
Далее VPA подсчитывает три различных оценки: target (цель),
lower bound (нижняя граница), upper bound (верхняя граница). Мы
используем 90-й процентиль для цели, 50-й процентиль для нижней
границы и 95-й процентиль для верхней.
Давайте подсчитаем значения для примера, приведенного на первом
рисунке:
|
Нижняя граница
|
0,5467
|
|
Цель
|
1,0163
|
|
Верхняя граница
|
1,0163
|

Примечание: красная линия показывает, где
проходит нижняя граница; зеленая линия показывает на местоположение
цели и верхней границы. В нашем примере два последних значения
оказались одинаковыми.
После подсчета к начальным границам прибавляется некоторых
резерв, чтобы оставить контейнеру пространство для маневра, если
тот, например, внезапно решит съесть больше ресурсов, чем раньше.
VPA добавляет некоторую долю от рассчитанной рекомендации. По
умолчанию она равна 15%. Скорректировать ее можно с помощью флага
--recommendation-margin-fraction.
Затем к обеим границам добавляется доверительный множитель.
Доверительный множитель зависит от того, сколько дней собирались
данные. Для верхней границы подсчет производится следующим
образом:
оценка = оценка * (1 + 1/продолжительность сбора данных в
днях)
Из формулы видно, что чем дольше мы ведем статистику, тем ниже
множитель. То есть со временем верхняя граница будет приближаться к
цели. Чтобы лучше разобраться в формуле, ниже приведены значения
множителей для различных периодов:
|
5 минут
|
289
|
|
1 час
|
25,4
|
|
1 день
|
2
|
|
2 дня
|
1,5
|
|
1 неделя
|
1,14
|
|
1 неделя и 1 день
|
1,125
|
В нашем примере статистика велась в течение двух дней, поэтому
доверительный множитель для верхней границы равен 1,5.
Аналогичным образом нижнюю границу мы умножаем на доверительный
интервал. Однако в этот раз формула немного другая:
оценка = оценка * (1 + 0.001/продолжительность сбора
данных в днях)^-2
Из формулы видно, что чем дольше мы ведем статистику, тем выше
множитель. Таким образом, со временем нижняя граница будет
приближаться к целевому уровню. Чтобы лучше разобраться в формуле,
ниже приведены значения множителей для различных периодов:
|
5 минут
|
0,6
|
|
1 час
|
0,9537
|
|
1 день
|
0,9980
|
|
2 дня
|
0,0990
|
Как видно, он стремительно приближается к 1. В нашем примере
статистика велась в течение двух дней. Поэтому доверительный
множитель для нижней границы почти равен единице.
Далее VPA проверяет, превысили ли оценки некоторое минимальное
пороговое значение. Если нет, VPA установит их на минимум. В
настоящее время минимум для CPU равен 25 миллиядрам, но его можно
изменить с помощью флага
--pod-recommendation-min-cpu-millicores.
После добавления резерва к нашим оценкам и учета доверительных
множителей конечные значения выглядят следующим образом:
|
Нижняя граница
|
0,626
|
|
Цель
|
1,168
|
|
Верхняя граница
|
1,752
|

Окончательные оценки
Наконец, VPA масштабирует границы таким образом, чтобы вписаться
в диапазон minAllowed/maxAllowed,
заданный в объекте VerticalPodAutoscaler. Кроме того,
если pod находится в пространстве имен с настроенным
LimitRange, рекомендация корректируется в соответствии
с его правилами.
Модель рекомендаций VPA для памяти
Хотя большинство шагов одинаковы, существуют и значительные
отклонения от алгоритма для CPU. Начнем с потребления памяти. Оно
выглядит следующим образом:

Обратите внимание, что на графике показано использование памяти
за семь дней. Более длительный интервал в данном случае имеет
принципиальное значение, поскольку оценка требуемой памяти
начинается с вычисления пикового значения для каждого интервала.
Используется пиковое значение, а не все распределение, поскольку
обычно стараются выделить объем памяти, близкий к пиковому
потреблению: ведь ее недостаток приведет к прекращению задач по
OOM. В то же время алгоритм выделения CPU-мощностей не так
чувствителен к данной проблеме, поскольку при недостатке ресурсов
pod'ы сталкиваются с троттлингом, а не убиваются.
По умолчанию интервал агрегации равен 24 часам. Его можно
изменить с помощью флага
--memory-aggregation-interval. Кроме того, мы
сохраняем только восемь интервалов (этот параметр можно изменить с
помощью --memory-aggregation-interval-count). Таким
образом, у нас имеется информация о пиковом спросе на память за 8 *
24 часа = 8 суток.
Давайте посмотрим, как эти пиковые агрегации выглядят в нашем
примере:

Агрегация пиковых нагрузок на память
Кроме того, если в течение этого времени возникает событие Out
Of Memory, мы анализируем использование памяти данным pod'ом, берем
максимальное значение и прибавляем к нему 20% или 100 Мб (в
зависимости от того, что больше). Этот метод позволяет VPA быстро
адаптироваться к OOM-инцидентам.
После того, как пиковые значения установлены, их можно свести в
гистограмму. VPA создает гистограмму с экспоненциально растущими
границами интервалов. Первый интервал начинается с 10 Мб и
заканчивается примерно на 1 Тб. Каждый интервал растет
экспоненциально со скоростью 5%.
Как и в случае CPU, вес данных уменьшается со временем (по
умолчанию его период полураспада равен 24 часам). Если добавить
новые данные в гистограмму, которым 24 часа, их вес будет равен
0,5. Подобный распад позволяет увеличить значимость более поздних
выборок (то есть они оказывают большее влияние на предсказания,
нежели ранние данные). Период полураспада можно скорректировать с
помощью флага --memory-histogram-decay-half-life.
Давайте посмотрим, как выглядит гистограмма для пиковых значений
из нашего примера:
. Значение 39-го интервала составляет 1088,10. Он пуст, так как наш график никогда не достигает этого значения.")
Примечание: мы построили график только для
интервалов с 16 по 38, поскольку остальные интервалы пусты.
Значения интервалов варьируются от 225,62 Мб до 969,20 Мб
(округленно). Значение 39-го интервала составляет 1088,10. Он пуст,
так как наш график никогда не достигает этого значения.
Далее VPA подсчитывает три различных оценки: target (цель),
lower bound (нижняя граница), upper bound (верхняя граница). Мы
использует 90-й процентиль для цели, 50-й процентиль для нижней
границы и 95-й процентиль для верхней.
В нашем примере все три оценки одинаковы: 1027,2 Мб.

Оценки после вычисления 50-го, 90-го и
95-го процентиля
После подсчета к начальным границам добавляется некоторых
резерв, чтобы оставить контейнеру пространство для маневра. Если,
например, он внезапно решит съесть больше ресурсов, чем раньше. VPA
добавляет некоторую долю от рассчитанной рекомендации. По умолчанию
она равна 15%. Скорректировать ее можно с помощью флага
--recommendation-margin-fraction.
Затем к обеим границам добавляется доверительный множитель.
Доверительный множитель зависит от того, сколько дней собирались
данные. Формулы те же, что и при выведении оценок для CPU.
Далее VPA проверяет, превысили ли оценки некоторое минимальное
пороговое значение. Если нет, VPA установит их на минимум. В
настоящее время минимальный объем памяти составляет 250 Мб. Его
можно изменить с помощью флага
--pod-recommendation-min-memory-mb.
После добавления резерва и учета доверительных множителей
конечные значения выглядят следующим образом:
|
Нижняя граница
|
1237422043 байт = 1,15 Гб
|
|
Цель
|
1238659775 байт = 1,15 Гб
|
|
Верхняя граница
|
1857989662 байт = 1,73 Гб
|

Обратите внимание, что зеленая линия это верхняя граница,
красная нижняя. Цель не видна, так как она близка к красной линии
(разница между ними составляет всего 1,18 Мб)
Наконец, VPA масштабирует границы таким образом, чтобы вписаться
в диапазон minAllowed/maxAllowed,
заданный в объекте VerticalPodAutoscaler. Кроме того,
если pod находится в пространстве имен с настроенным
LimitRange, рекомендация корректируется в соответствии
с его правилами.
Полезные ссылки
P.S. от переводчика
Читайте также в нашем блоге:








 Общая сводная таблица по кластерам с
Terraform-состояниями
Общая сводная таблица по кластерам с
Terraform-состояниями Распределение кластеров по облачным
провайдерам
Распределение кластеров по облачным
провайдерам Разбивка по используемым Inlet в Nginx
Ingress-контроллерах
Разбивка по используемым Inlet в Nginx
Ingress-контроллерах Количество podов Nginx
Ingress-контроллеров с разбивкой по версиям
Количество podов Nginx
Ingress-контроллеров с разбивкой по версиям
 XKCD в тему. Комментарий в коде гласит:
Получено подбрасыванием кости. Это гарантированно случайное
значение
XKCD в тему. Комментарий в коде гласит:
Получено подбрасыванием кости. Это гарантированно случайное
значение














 Как работает kex в fubectl
Как работает kex в fubectl







 Вообще говоря, конечно, бывают и другие причины для
миграции (например, многочисленные удобства в последующем
обслуживании инфраструктуры и её масштабирования), но не буду
заострять на этом внимание.
Вообще говоря, конечно, бывают и другие причины для
миграции (например, многочисленные удобства в последующем
обслуживании инфраструктуры и её масштабирования), но не буду
заострять на этом внимание.



 Список пользователей и возможные действия с
ними
Список пользователей и возможные действия с
ними Окно добавления кастомных маршрутов для
пользователя
Окно добавления кастомных маршрутов для
пользователя Пример панели на основе метрик,
полученных от ovpn-admin
Пример панели на основе метрик,
полученных от ovpn-admin




 Матрица
критичности алертов
Матрица
критичности алертов

 Где мы
были около 2 лет назад
Где мы
были около 2 лет назад
 Так выглядит кластер после добавления новых хостов
Так выглядит кластер после добавления новых хостов
 Постепенно переключаем операции чтения на
partition-кластер
Постепенно переключаем операции чтения на
partition-кластер
") Мгновенное переключение операций чтения с
мастера основного кластера на мастер partition-кластера (для
первичных ключей с автоинкрементом)
Мгновенное переключение операций чтения с
мастера основного кластера на мастер partition-кластера (для
первичных ключей с автоинкрементом) Конечный результат
Конечный результат
 оказались бы для нас очень веселыми.") Отвечаю: если бы мы не разбили наши базы,
то последние два месяца (минимум) оказались бы для нас очень
веселыми.
Отвечаю: если бы мы не разбили наши базы,
то последние два месяца (минимум) оказались бы для нас очень
веселыми.
. Как видно, нам удалось сократить число запросов, хотя трафик продолжал расти.") Число команд MySQL (мы начали работать над
разделением данных в марте). Как видно, нам удалось сократить число
запросов, хотя трафик продолжал расти.
Число команд MySQL (мы начали работать над
разделением данных в марте). Как видно, нам удалось сократить число
запросов, хотя трафик продолжал расти. Статистика I/O диска. В июле нам удалось
добиться того, что запросы почти не приводили к дисковым операциям
(благодаря разбиению и оптимизации запросов, которые ранее
приводили к появлению временных таблиц на диске
Статистика I/O диска. В июле нам удалось
добиться того, что запросы почти не приводили к дисковым операциям
(благодаря разбиению и оптимизации запросов, которые ранее
приводили к появлению временных таблиц на диске Использование диска выглядит прелестно, не так
ли?
Использование диска выглядит прелестно, не так
ли? Использование диска
Использование диска

 Николай Сивко выступает на одной из
конференций HighLoad++
Николай Сивко выступает на одной из
конференций HighLoad++
 на HighLoad++ Весна 2021") Андрей Колаштов (в центре) на HighLoad++ Весна 2021
Андрей Колаштов (в центре) на HighLoad++ Весна 2021
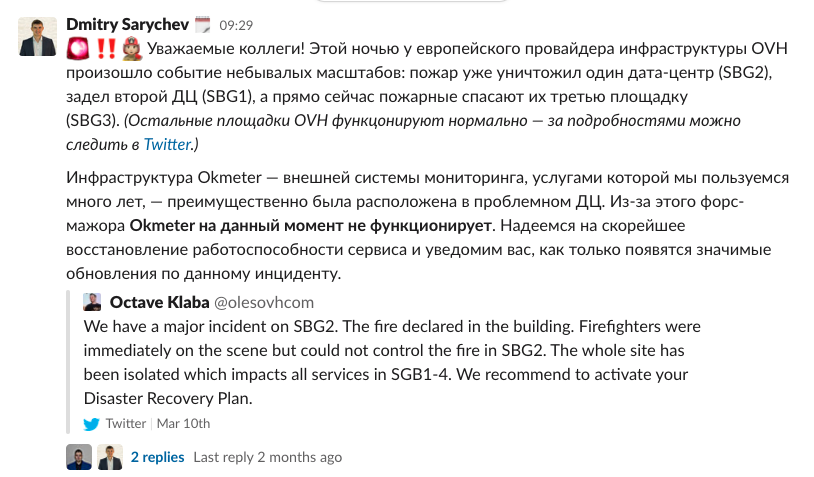
 Пожар в дата-центрах OVH в марте этого
года; автор фото Xavier Garreau
Пожар в дата-центрах OVH в марте этого
года; автор фото Xavier Garreau
 Наша детальная статистика потребления
трафика по конкретному пространству имен Kubernetes-кластера
Наша детальная статистика потребления
трафика по конкретному пространству имен Kubernetes-кластера