Вот в чём вопрос! Что лучше - держать всё в одном процессе, или
создавать отдельный процесс на каждый кусок состояния, которым нам
нужно управлять? В этой статье я немного расскажу об использовании
или неиспользовании процессов. Я также расскажу, как отделить
сложную логику с отслеживанием состояния от таких проблем, как
временное (темпоральное) поведение и межпроцессное
взаимодействие.
Но перед тем, как начать, т. к. статья будет длинной, я хотел бы
обозначить основные моменты:
-
Используйте функции и модули для разделения мыслительных
сущностей.
-
Используйте процессы для разделения сущностей времени
выполнения.
-
Не используйте процессы (даже агентов) для разделения сущностей
мышления.
Конструкция "мыслительные сущности" здесь относится к идеям,
которые есть в нашем разуме, таким как "заказ", "позиция в заказе",
"продукт" и т. д. Если эти концепции слишком сложны, то стоит
реализовать их в отдельных модулях и функциях для разделения
различных сущностей и держать каждую часть нашего кода
сфокусированной и целостной.
Использование для этого процессов (например агентов) - это
ошибка, которую люди часто допускают. Такой подход существенно
упускает функциональную составляющую Elixir и вместо этого пытается
имитировать объекты процессами. Реализация, скорее всего, будет
хуже, чем простой функциональный подход (или даже эквивалент на
языке объектно-ориентированного программирования). Поэтому стоит
обращаться к процессам, только когда есть ощутимые выгоды от этого.
Организация кода не входит в число этих преимуществ, так что это не
лучший повод для использования процессов.
Процессы используются для решения проблем времени выполнения -
свойств, которые можно наблюдать в работающей системе. Например,
вам нужно задействовать несколько процессов, если вы хотите, чтобы
сбой одного задания не повлиял на другие функции системы. Еще одна
мотивация - когда вы хотите ввести потенциал для распараллеливания,
позволяя одновременно запускать несколько заданий. Это может
улучшить производительность вашего приложения и открыть потенциал
для масштабирования в обоих направлениях. Есть и другие, менее
распространенные случаи использования процессов, но опять же -
разделение мыслительных сущностей не входит в их число.
Пример
Но как же тогда управлять сложным состоянием, если не с помощью
агентов и процессов? Позвольте мне проиллюстрировать эту идею на
простой предметной модели сокращенной и слегка модифицированной
версии игры в блэкджек. Код, который я вам покажу (доступен
здесь), запускает один раунд
на столе для блэкджека.
Раунд - это, по сути, последовательность раздач, каждая из
которых принадлежит отдельному игроку. Раунд начинается с первой
руки. Игроку сначала выдают две карты, а затем он делает ход: берет
еще одну карту (хит) или останавливается (стоп). В первом случае
игроку дается еще одна карта. Если счет игрока больше 21, игрок
вылетает из игры. В противном случае игрок может сделать еще один
ход (взять карту или остановиться).
Счет руки - это сумма всех достоинств карт, при этом числовые
карты (2-10) имеют свои соответствующие значения, а валет, дама и
король имеют значение 10. Туз может быть оценен как 1 или как 11, в
зависимости от того, что дает лучший (но не проигранный) счет.
Раздача считается законченной, если игрок останавливается или
вылетает из игры. Когда ход руки закончен, раунд переходит к
следующей руке. После того, как все руки сыграны, победителями
становятся не вылетевшие руки с наибольшим количеством очков.
Для простоты я не рассматривал такие понятия, как дилер, ставки,
страхование, разделение(), несколько раундов, люди,
присоединяющиеся к столу или покидающие его.
Границы процесса
Итак, нам нужно отслеживать различные типы состояний, которые
меняются с течением времени: колода карт, руки каждого игрока и
состояние раунда. Наивный подход к этому - использование нескольких
процессов. У нас может быть один процесс для каждой руки, другой
процесс для колоды карт и главный процесс, который управляет всем
раундом. Я вижу, что люди иногда используют аналогичный подход, но
я совершенно не уверен, что это правильный путь. Основная причина в
том, что игра по своей природе очень синхронизирована. Все
происходит одно за другим в четко определенном порядке: я получаю
свои карты, делаю один или несколько ходов, и когда я закончу, вы
будете следующим. В любой момент времени в одном раунде происходит
только одно действие.
Следовательно, использование нескольких процессов для запуска
одного раунда принесет больше вреда, чем пользы. В нескольких
процессах все происходит одновременно, поэтому вам нужно приложить
дополнительные усилия для синхронизации всех действий. Вам также
необходимо обратить внимание на правильное завершение и очистку
процесса. Если вы остановите процесс раунда, вам также необходимо
остановить все связанные процессы. То же самое должно происходить и
в случае сбоя: исключение в раунде или процессе колоды, вероятно,
должно завершить все (потому что состояние повреждено и не подлежит
восстановлению). Возможно, сбой одной руки можно было бы
изолировать, и это могло бы немного улучшить отказоустойчивость, но
я думаю, что это слишком тонкий уровень, чтобы беспокоиться об
изоляции сбоев.
Итак, в этом случае я вижу много потенциальных недостатков и не
очень много преимуществ от использования нескольких процессов для
управления состоянием одного раунда. Однако разные раунды взаимно
независимы. У них есть свои отдельные потоки, они держат свои
отдельные состояния, у них нет ничего общего. Таким образом,
управление несколькими раундами в одном процессе контрпродуктивно.
Это увеличит нашу поверхность ошибок (сбой в одном раунде приведет
к отключению всего) и, возможно, приведет к снижению
производительности (мы не используем несколько ядер) или узким
местам (длительная обработка в одном раунде парализует все
остальные). Если мы будем запускать разные раунды в разных
процессах, есть очевидные выигрыши, так что это решение не составит
труда :-) (прим. переводчика: Как же нет ничего общего, а состояние
кошельков игроков?)
В своих выступлениях я часто говорю, что в сложных системах
существует огромный потенциал параллелизма, поэтому мы будем
использовать множество процессов. Но чтобы воспользоваться этими
преимуществами, нам нужно использовать процессы там, где они имеют
смысл.
Итак, учитывая все обстоятельства, я почти уверен, что
единственный процесс для управления всем состоянием одного раунда -
это правильный путь. Было бы интересно посмотреть, что изменится,
если мы введем концепцию стола, где раунды играются постоянно, а
игроки меняются со временем. Я не могу сказать наверняка на данный
момент, но я думаю, что это интересное упражнение на случай, если
вы захотите его изучить :-)
Функциональное моделирование
Итак, как же мы можем разделить разные сущности без
использования нескольких процессов? Конечно, используя функции и
модули. Если мы распределим разные части логики по разным функциям,
дадим этим функциям собственные имена и, возможно, организуем их в
правильно названные модули, мы сможем прекрасно представить наши
идеи без необходимости имитировать объекты с помощью агентов.
Позвольте мне показать вам, что я имею в виду, проведя вас через
каждую часть моего решения, начиная с самого простого.
Колода карт
Первое, что я хочу запечатлеть - это колода карт. Мы хотим
смоделировать стандартную колоду из 52 карт. Мы хотим начать с
перетасованной колоды, а затем иметь возможность брать из нее карты
одну за другой.
Это, безусловно, концепция с сохранением состояния. Каждый раз,
когда мы берем карту, состояние колоды меняется. Несмотря на это,
мы можем реализовать колоду с чистыми функциями.
Позвольте показать вам код. Я решил представить колоду в виде
списка карт, каждая из которых представляет собой карту с рангом и
мастью. Я могу сгенерировать все карты во время компиляции:
@cards ( for suit <- [:spades, :hearts, :diamonds, :clubs], rank <- [2, 3, 4, 5, 6, 7, 8, 9, 10, :jack, :queen, :king, :ace], do: %{suit: suit, rank: rank})
Теперь я могу добавить функцию shuffle/0 для
создания перемешанной колоды:
def shuffled(), do: Enum.shuffle(@cards)
И наконец, take/1, которая берёт верхнюю карту из
колоды:
def take([card | rest]), do: {:ok, card, rest}def take([]), do: {:error, :empty}
Функция take/1 возвращает либо {:ok,
card_taken, rest_of_the_deck}, либо {:error,
:empty}. Такой интерфейс заставляет клиента (пользователя
абстракции колоды) явно решать, как поступать в каждом случае.
Как мы можем это использовать:
deck = Blackjack.Deck.shuffled()case Blackjack.Deck.take(deck) do {:ok, card, transformed_deck} -> # do something with the card and the transform deck {:error, :empty} -> # deck is empty -> do something elseend
Это пример того, что я люблю называть функциональной
абстракцией, что является причудливым названием для:
Для меня это то, что соответствует классам и объектам в
объектно-ориентированном пространстве. В объектно-ориентированном
языке у меня может быть класс Deck с соответствующими
методами, здесь у меня есть модуль Deck с
соответствующими функциями. Предпочтительно (хотя и не всегда стоит
затраченных усилий), чтобы функции только преобразовывали данные,
не имея дело с темпоральной логикой или побочными эффектами (обмен
сообщениями между процессами, база данных, сетевые запросы,
тайм-ауты и т. д.)
Не так важно, находятся ли эти функции в выделенном модуле. Код
этой абстракции довольно прост и используется только в одном месте.
Поэтому я мог бы также определить приватные функции
shuffled_deck/0 и take_card/1 в
клиентском модуле. Фактически, это то, что я часто делаю, если код
достаточно мал. Я всегда могу выделить это позже, если что-то
усложнится. (прим. переводчика: не совсем уловил здесь мысль,
которую хотел донести автор)
Важным моментом является то, что концепция колоды основана на
чистых функциях. Не нужно обращаться к агенту, чтобы управлять
колодой карт.
Полный код модуля доступен здесь.
Рука
Эту же технику можно использовать для управления рукой. Эта
абстракция отслеживает карты в руке. Она также умеет подсчитывать
очки и определять статус руки (:ok или
:busted). Реализация находится в модуле Blackjack.Hand.
Модуль выполняет две функции. Мы используем new/0
для создания экземпляра руки, а затем deal/2, чтобы
раздать карту руке. Вот пример комбинации руки и колоды:
# create a deckdeck = Blackjack.Deck.shuffled()# create a handhand = Blackjack.Hand.new()# draw one card from the deck{:ok, card, deck} = Blackjack.Deck.take(deck)# give the card to the handresult = Blackjack.Hand.deal(hand, card)
Результат deal/2 вернётся в форме
{hand_status, transformed_hand}, где
hand_status это или :ok или
:busted.
Раунд
Эта абстракция, реализованная в модуле Blackjack.Round, связывает
всё воедино. Она имеет следующие обязанности:
-
сохранять состояния колоды
-
держать состояние всех рук в раунде
-
решать, кому переходит следующий ход
-
получать и интерпретировать ход игрока (хит / стоп)
-
брать карты из колоды и передавать их текущей руке
-
вычислять победителя после того, как все руки разыграны
Абстракция раунда будет следовать тому же функциональному
подходу, что и колода с рукой. Однако здесь есть дополнительный
поворот, который касается выделения темпоральной логики. Раунд
занимает некоторое время и требует взаимодействия с игроками.
Например, когда начинается раунд, первый игрок должен быть
проинформирован о первых двух картах, которые он получил, а затем
он должен быть проинформирован о том, что пришла его очередь
сделать ход. Затем раунду нужно дождаться, пока игрок сделает ход,
и только после этого он сможет пойти дальше.
У меня сложилось впечатление, что многие люди, включая опытных
эрлангистов/эликсирщиков, реализовали бы концепцию раунда
непосредственно в GenServer или в
:gen_statem. Это позволит им управлять состоянием
раунда и темпоральной логикой (например, общением с игроками) в
одном месте.
Однако я считаю, что эти два аспекта необходимо разделить,
поскольку оба они потенциально сложны. Логика одного раунда уже в
некоторой степени запутана, и она может только ухудшиться, если мы
захотим поддержать дополнительные аспекты игры, такие как ставки,
сплиты или раздающего игрока. Общение с игроками имеет свои
проблемы, если мы хотим иметь дело с расщеплениями сети(netsplits),
сбоями, медленными или недоступными клиентами. В этих случаях нам
может потребоваться поддержка повторных попыток, возможно, добавить
некоторую персистентность, event sourcing или что-то еще.
Я не хочу объединять эти две сложные задачи вместе, потому что
они запутаются, и с кодом будет труднее работать. Я хочу перенести
временные проблемы в другое место и получить чистую
предметную модель раунда блэкджека.
Поэтому вместо этого я выбрал подход, с которым не часто
сталкиваюсь. Я уловил концепцию раунда в простой функциональной
абстракции.
Позвольте показать вам код. Чтобы создать новый раунд, мне нужно
вызвать start/1:
{instructions, round} = Blackjack.Round.start([:player_1, :player_2])
Аргумент, который мне нужно передать, - это список
идентификаторов игроков. Это могут быть произвольные термы, которые
будут использоваться абстракцией для различных целей:
-
создание руки для каждого игрока
-
отслеживание текущего игрока
-
отправка уведомлений игрокам
Функция возвращает кортеж. Первый элемент кортежа - это список
инструкций. Пример:
[{:notify_player, :player_1, {:deal_card, %{rank: 4, suit: :hearts}}},{:notify_player, :player_1, {:deal_card, %{rank: 8, suit: :diamonds}}},{:notify_player, :player_1, :move}]
Инструкции - это способ, которым абстракция информирует своего
клиента о том, что необходимо сделать. Как только мы начинаем
раунд, в первую руку передаются две карты, а затем экземпляр раунда
ожидает хода игрока. Итак, в этом примере абстракция инструктирует
нас:
-
уведомить игрока 1, что он получил четвёрку червей
-
уведомить игрока 1, что он получил восьмёрку бубён
-
уведомить игрока 1, что ему нужно сделать ход
Фактическая доставка этих уведомлений заинтересованным игрокам
является ответственностью клиентского кода. Клиентским кодом может
быть, скажем, GenServer, который будет отправлять
сообщения процессам игроков. Он также будет ждать, пока игроки не
сообщат, когда они захотят взаимодействовать с игрой. Это
временная(темпоральная) логика, и она полностью хранится
за пределами модуля Round.
Второй элемент возвращённого кортежа, называется
round, это состояние самого раунда. Стоит отметить,
что эти данные типизированы как
непрозрачные. Это значит, что клиент не может читать эти данные
внутри переменной round. Всё, что нужно клиенту, будет
доставлено в списке instruction.
Давайте продвинемся на шаг вперед в этом раунде, взяв следующую
карту игроком 1:
{instructions, round} = Blackjack.Round.move(round, :player_1, :hit)
Мне нужно передать идентификатор игрока, чтобы абстракция могла
проверить, правильный ли игрок делает ход. Если я передам неверный
идентификатор, абстракция попросит меня уведомить игрока, что
сейчас не его ход.
Вот инструкции, которые я получил:
[ {:notify_player, :player_1, {:deal_card, %{rank: 10, suit: :spades}}}, {:notify_player, :player_1, :busted}, {:notify_player, :player_2, {:deal_card, %{rank: :ace, suit: :spades}}}, {:notify_player, :player_2, {:deal_card, %{rank: :jack, suit: :spades}}}, {:notify_player, :player_2, :move}]
Этот список говорит мне, что игрок 1 получил десятку пик.
Поскольку раньше у него было 4 червы и 8 бубён, игрок вылетает из
игры, и раунд немедленно переходит к следующей руке. Клиенту
предлагается уведомить игрока 2 о том, что у него есть две карты, и
что он должен сделать ход.
Сделаем ход от имени игрока 2:
{instructions, round} = Blackjack.Round.move(round, :player_2, :stand)# instructions:[ {:notify_player, :player_1, {:winners, [:player_2]}} {:notify_player, :player_2, {:winners, [:player_2]}}]
Игрок 2 не взял другую карту, поэтому его рука завершена.
Абстракция немедленно определяет победителя и инструктирует нас
проинформировать обоих игроков о результате.
Давайте посмотрим, как Round прекрасно сочетается с
абстракциями Deck и Hand. Следующая
функция из модуля Round берет карту из колоды и
передает ее текущей руке:
defp deal(round) do {:ok, card, deck} = with {:error, :empty} <- Blackjack.Deck.take(round.deck), do: Blackjack.Deck.take(Blackjack.Deck.shuffled()) {hand_status, hand} = Hand.deal(round.current_hand, card) round = %Round{round | deck: deck, current_hand: hand} |> notify_player(round.current_player_id, {:deal_card, card}) {hand_status, round}end
Берём карту из колоды, используя новую колоду, если текущая
закончилась. Затем мы передаем карту в текущую руку, обновляем
раунд новой рукой и статусом колоды, добавляем инструкцию по
уведомлению о данной карте и возвращаем статус руки
(:ok или :busted) и обновленный раунд.
Никаких дополнительных процессов в этом процессе не задействовано
:-)
Вызов notify_player - это простой однострочник,
который избавляет этот модуль от многих сложностей. Без него нам
нужно было бы отправить сообщение другому процессу (например,
другому GenServer или каналу Phoenix). Пришлось бы как-то найти
этот процесс и рассмотреть случаи, когда этот процесс не запущен.
Вместе с кодом, который моделирует ход раунда, пришлось бы связать
много дополнительных сложностей.
Но благодаря механизму инструкций, ничего из этого не случилось,
и модуль Round остался сфокусированным на правилах
игры. Функция notify_player будет сохранять инструкцию. Позже,
перед выходом, функция take_instructions из
Round будет забирать все ожидающие
инструкции, и возвращать их по отдельности, вынуждая клиентский
код интерпретировать их.
В качестве бонуса, этот код теперь может быть использован
разными типами клиентов. В примерах выше, я дёргал его вручную из
сессии. Другой пример - вызывать этот код в тестах.
Эта абстракция теперь может быть легко протестирована, без
необходимости производить сайд эффекты или наблюдать их.
Организация процесса
После завершения работы над базовой чистой моделью пришла пора
обратить наше внимание на процессную сторону вещей. Как я уже
говорил ранее, я буду проводить каждый раунд в отдельном процессе.
Я считаю, что в этом есть смысл, поскольку разные раунды не имеют
ничего общего. Следовательно, их запуск по отдельности дает нам
лучшую эффективность, масштабируемость и изоляцию ошибок.
Сервер раунда
Каждый раунд управляется модулем Blackjack.RoundServer,
который есть GenServer. Agent также мог
бы подойти для этих целей, но я не фанат агентов, так что я
остановлюсь на GenServer. Ваши предпочтения могут
отличаться, конечно, и я полностью уважаю ваше мнение :-)
Чтобы запустить процесс, нам нужно вызвать функцию
start_playing/2. Это имя выбрано вместо более
распространенного start_link, поскольку
start_link по соглашению ссылается на вызывающий
процесс. Напротив, start_playing начнет раунд где-то
еще в дереве надзора, и процесс не будет связан с вызывающим.
Функция принимает два аргумента: идентификатор раунда и список
игроков. Идентификатор раунда - это произвольный уникальный терм,
который должен быть выбран клиентом. Серверный процесс будет
зарегистрирован во внутреннем реестре с использованием этого
идентификатора.
Каждая запись в списке игроков представляет собой словарь,
описывающий клиентскую часть игрока:
@type player :: %{id: Round.player_id, callback_mod: module, callback_arg: any}
Игрок описывается его идентификатором, модулем обратного вызова
и аргументом обратного вызова. Идентификатор будет передан
абстракции раунда. Всякий раз, когда абстракция инструктирует
сервер уведомить некоторого игрока, сервер вызывает
callback_mod.some_function (some_arguments), где
some_arguments будет включать идентификатор раунда,
идентификатор игрока, callback_arg и дополнительные
аргументы, специфичные для уведомления.
Подход callback_mod позволяет нам поддерживать
различные типы игроков, такие как:
-
игроков, подключенных через HTTP
-
игроков, подключенных через настраиваемый протокол TCP
-
игрок в сеансе оболочки iex
-
автоматических игроков (ботов)
Мы легко справимся со всеми этими игроками в одном раунде.
Сервер не заботится ни о чём из этого, он просто вызывает функции
обратного вызова модуля обратного вызова и позволяет реализации
выполнять работу.
Функции, которые должны быть реализованы в модуле обратного
вызова, перечислены здесь:
@callback deal_card(RoundServer.callback_arg, Round.player_id, Blackjack.Deck.card) :: any@callback move(RoundServer.callback_arg, Round.player_id) :: any@callback busted(RoundServer.callback_arg, Round.player_id) :: any@callback winners(RoundServer.callback_arg, Round.player_id, [Round.player_id]) :: any@callback unauthorized_move(RoundServer.callback_arg, Round.player_id) :: any
Эти сигнатуры показывают, что реализация не может управлять
своим состоянием в серверном процессе. Это намеренное решение,
которое практически вынуждает игроков выходить за пределы раунда.
Это помогает нам изолировать состояние раунда. Если игрок выходит
из строя или отключается, сервер раунда продолжает работать и может
справиться с ситуацией, например, исключить игрока из игры, если он
не сможет сходить в течение заданного времени.
Другое приятное следствие такого дизайна - это то, что
тестирование этого сервера довольно просто. Тест реализует
уведомления путём отправки сообщений самому себе
из каждого колбека. Затем тестирование сводится к asserting/refuting определённых
сообщений, и вызову RoundServer.move/3, чтобы
сделать ход от имени игрока.
Отправка сообщений
Когда функция модуля Round возвращает список
инструкций серверному процессу, тот пройдёт по этому списку, и
интерпретирует инструкции.
Сами уведомления отправляются из отдельных процессов. Это
пример, в котором мы можем получить преимущество от дополнительного
параллелизма. Отправка уведомлений - это задача, отдельная от
задачи управления состоянием раунда. Логика уведомлений может быть
перегружена такими задачами, как медленные или отключенные клиенты,
поэтому стоит делать это вне раунда. Более того, уведомления разным
игрокам не имеют ничего общего, поэтому их можно отправлять из
разных процессов. Однако нам нужно сохранить порядок уведомлений
для каждого игрока, поэтому нам нужен отдельный процесс уведомления
для каждого игрока.
Это реализовано в модуле Blackjack.PlayerNotifier,
процессе на основе GenServer, чья роль - отправлять
уведомление отдельному игроку. Когда мы стартуем сервер раунда
функцией start_playing/2, запускается небольшое поддерево надзора
в котором размещается сервер раунда вместе с одним сервером уведомлений на
каждого игрока в раунде.
Когда сервер раунда делает ход, он получает список инструкций от
абстракции раунда. Затем он перенаправляет каждую инструкцию
соответствующему серверу уведомлений, который интерпретирует эту инструкцию и
вызывает соответствующий модуль/функцию/аргументы(M/F/A) для
уведомления игрока.
Следовательно, если нам нужно уведомить нескольких игроков, мы
сделаем это отдельно (и, возможно, параллельно). Как следствие,
общий порядок сообщений не сохраняется. Рассмотрим следующую
последовательность инструкций:
[ {:notify_player, :player_1, {:deal_card, %{rank: 10, suit: :spades}}}, {:notify_player, :player_1, :busted}, {:notify_player, :player_2, {:deal_card, %{rank: :ace, suit: :spades}}}, {:notify_player, :player_2, {:deal_card, %{rank: :jack, suit: :spades}}}, {:notify_player, :player_2, :move}]
Может случиться так, что сообщения player_2 придут
до того, как player_1 будет проинформирован о том, что
он остановлен. Но это нормально, ведь это два разных игрока.
Порядок сообщений для каждого игрока, конечно же, сохраняется,
благодаря процессу сервера уведомлений, зависящему от конкретного
игрока.
Прежде чем закончить, я хочу еще раз подчеркнуть свою точку
зрения: благодаря дизайну и функциональному характеру модуля
Round, вся эта сложность уведомлений находится за
пределами модели предметной области. Точно так же часть уведомления
не связана с логикой домена.
Сервис блэкджека
Картинка завершается в виде приложения OTP
:blackjack (модуль Blackjack). Когда вы
запускаете приложение, запускается пара локально зарегистрированных
процессов: экземпляр внутреннего реестра Registry
(используется для регистрации серверов раунда и уведомлений) и
супервизор :simple_one_for_one, который будет
размещать поддерево процесса для каждого раунда.
Это приложение теперь в основном представляет собой сервис
блэкджека, который может управлять несколькими раундами. Сервис
является универсальным и не зависит от конкретного интерфейса. Вы
можете использовать его с Phoenix, Cowboy, Ranch (для простого
TCP), elli или любым другим, подходящим для ваших целей. Вы
реализуете модуль обратного вызова, запускаете клиентские процессы
и запускаете сервер раунда.
Вы можете посмотреть примеры в модуле Demo, который реализует
простого автоигрока,
модуль обратного вызова сервиса
уведомлений, основанного на GenServer, и логику старта, которая стартует
раунд с пятью игроками:
$ iex -S mixiex(1)> Demo.runplayer_1: 4 of spadesplayer_1: 3 of heartsplayer_1: thinking ...player_1: hitplayer_1: 8 of spadesplayer_1: thinking ...player_1: standplayer_2: 10 of diamondsplayer_2: 3 of spadesplayer_2: thinking ...player_2: hitplayer_2: 3 of diamondsplayer_2: thinking ...player_2: hitplayer_2: king of spadesplayer_2: busted...
Вот как выглядит дерево надзора, когда у нас есть пять
одновременных раундов, в каждом по пять игроков:
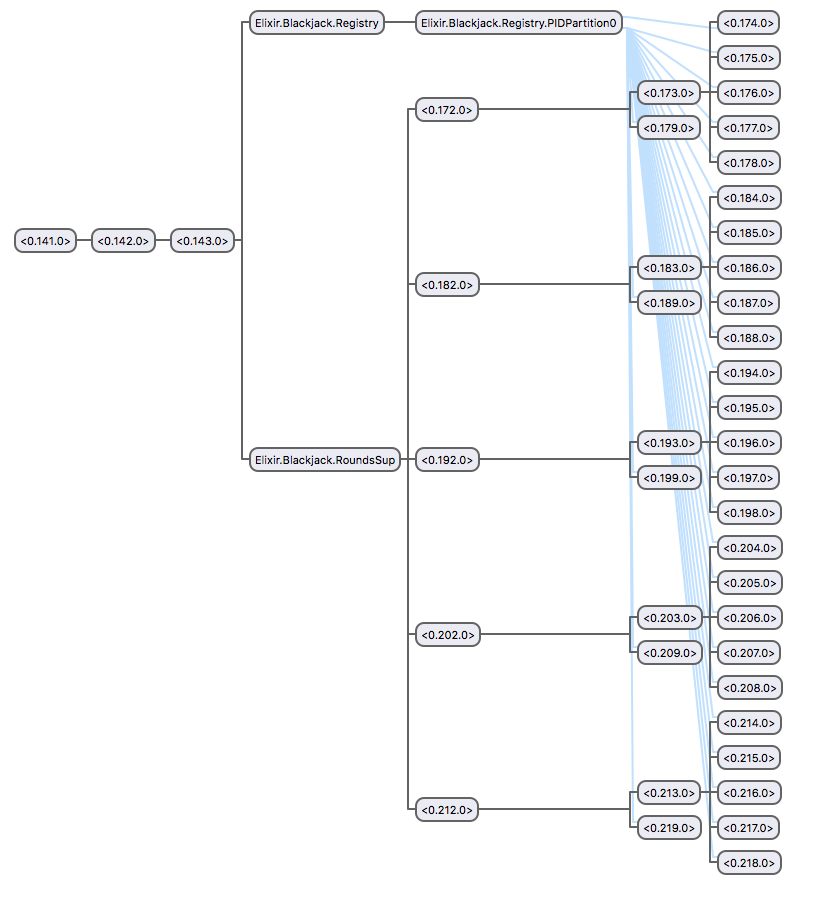
Заключение
Итак, можем ли мы управлять сложным состоянием в одном процессе?
Конечно, можем! Простые функциональные абстракции, такие как
Deck and Hand, позволили мне разделить
проблемы более сложного состояния раунда без необходимости
прибегать к помощи агентов.
Однако это не означает, что мы должны быть консервативными в
отношении процессов. Используйте процессы везде, где они имеют
смысл и приносят очевидные преимущества. Выполнение различных
раундов в отдельных процессах улучшает масштабируемость,
отказоустойчивость и общую производительность системы. То же самое
касается процессов уведомления. Это разные задачи среды выполнения,
поэтому нет необходимости запускать их в одном контексте времени
выполнения.
Если временная логика и/или логика предметной области
сложны, рассмотрите возможность их разделения. Подход, который я
использовал, позволил мне реализовать более сложное поведение во
время выполнения (одновременные уведомления), не усложняя
бизнес-процесс раунда. Это разделение также ставит меня в удобное
положение, поскольку теперь я могу развивать оба аспекта по
отдельности. Добавление поддержки бизнес-концепций дилера, сплита,
страхования и других не должно существенно влиять на аспект
выполнения. Точно так же поддержка расщеплений сети(netsplits),
повторных подключений, сбоев игрока или тайм-аутов не должна
требовать изменений в логике домена.
Наконец, стоит помнить о конечной цели. Хотя я туда не ходил
(пока), я всегда планировал, что этот код будет размещен на
каком-то веб-сервере. Так что некоторые решения принимаются в
поддержку этого сценария. В частности, реализация
RoundServer, которая принимает модуль обратного вызова
для каждого игрока, позволяет мне подключаться к различным типам
клиентов, использующим различные технологии. Это делает сервис
блэкджека независимым от конкретных библиотек и фреймворков (за
исключением стандартных библиотек и OTP, конечно) и делает его
полностью гибким.








