

Математика верстальщику не нужна!, говорили они. Арифметики за 2 класс школы хватит!, говорили они. Верстальщик не программист, так что нечего себе голову забивать точными науками!, чего только не услышишь на просторах интернета на тему нужности тех или иных знаний при разработке сайтов. И на самом деле в большинстве случаев человеку, который делает интерфейсы, и правда хватает умения складывать числа. Что-то более сложное встречается редко и обычно уже есть готовый алгоритм где-то в недрах NPM. Но сайты понятие растяжимое, и иногда все же нужно включить голову, и разобраться в каком-то вопросе. И один из таких вопросов это траектории в 2D анимациях.
Наблюдая за людьми, которые осваивают JS, и, в частности, покадровые анимации в вебе, я заметил, что у многих возникают сложности, когда нужно сделать движение какого-то объекта на странице по определенной траектории. И, если эта траектория не нарисована заранее заботливым дизайнером в виде path в SVG-картинке, а формулируется какими-то общими словами и ссылками на референсы из сети, или, что еще хуже, должна генерироваться на лету, то задача приводит их в полный ступор. По всей видимости все упирается в тотальное непонимание того, как получить кривую той или иной формы в рамках JS. Об этом мы сегодня и поговорим в формате своеобразной лекции о временных функциях для анимаций в самых разных их проявлениях.
Мы постараемся избежать излишней теоретизации, отдавая предпочтение картинкам и объяснению всего на пальцах, с акцентом на практическое использование в вопросах 2D анимаций на сайтах. Так что местами формулировки могут быть не совсем точными с точки зрения математики или не совсем полными, цель этой статьи дать общее представление о том, что бывает, и откуда можно начать в случае чего.
Немного определений
Школьная программа имеет свойство выветриваться из готовы после покидания этой самой школы, но все же такое понятие, как декартова система координат должно остаться. В работе с HTML и CSS мы постоянно к ней обращаемся. Две перпендикулярных оси, которые обычно обозначаются буквами X и Y, одинаковый масштаб по обеим осям это именно она. Декартова система координат это частный случай прямоугольной системы координат, у которой масштаб по осям может быть разным. Такие системы координат в вебе тоже встречаются, правда чаще в вопросах, связанных с канвасом и WebGL. Вопросы переходов между системами координат в общем случае мы пока отложим, так как это не будет нужно для решения текущих задач. Сейчас нам важно научиться делать кривые определенной формы.
Второе понятие, которое нам пригодится это график функции. В нашем случае функция это зависимость чего-то одного от чего-то другого. Дали что-то на вход получили что-то на выходе. Давая функции на вход разные значения получаем разные значения на выходе. А может и не разные. А может она вообще определена только для определенного набора значений. Всякое может быть. В любом случае такие наборы значений можно отобразить в виде графиков в той или иной системе координат на наш вкус.
Вы конечно спросите, каким образом связаны графики и анимации? Представьте себе канвас. Вы рисуете на нем точку. И начинаете ее двигать, в каждом кадре очищая канвас и рисуя ее в новом месте. Или еще лучше, если это будет кружочек, имитирующий мячик. Он будет подпрыгивать, отскакивая от пола. Представьте это. А теперь представьте, что получится, если между кадрами не очищать канвас? Там будет оставаться след от мячика, причем он будет не совсем случайным, а в виде кривой линии, напоминующей много парабол, соединенных между собой. Так вот, нам нужно решить обратную задачу сначала сделать эту кривую линию, график некоторой функции, а потом уже вдоль нее двигать мячик, постепенно меняя параметры функции и получая каждый раз новое положение для него. А этим мячиком уже может быть что угодно HTML-элемент, что-то в SVG-картинке, что-то на канвасе не важно.
I. Простые функции вида y = f(x) и коэффициенты
Начнем мы с простых функций. Из школьной тригонометрии вы должны помнить такие слова, как синус, косинус, тангенс, котангенс, и.т.д. В примерах будет часто использоваться синус, но все идеи и приемы будут универсальными их можно использовать с чем угодно и как угодно.
Давайте посмотрим на график синуса:
(x) => { return Math.sin(x);}
Примеры функций-зависимостей в виде кода будут на условном JS.
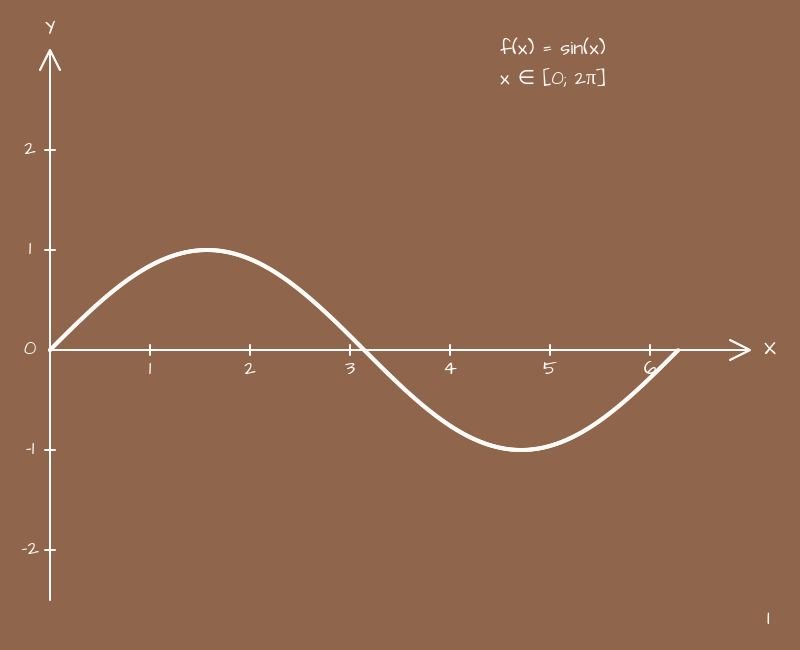
Здесь у нас две оси, X и Y, и Y зависит от X. Если мы будем менять X от 0 до 10 (условно), то Y будет плавать туда-сюда, туда-сюда, туда-сюда Если нужно сделать покачивание чего-то на странице это то, что нужно. Мы можем использовать requestAnimationFrame и в каждом кадре слегка увеличивать x, использовать нашу пока еще простую функцию для вычисления y, и таким образом каждый раз получать новые координаты для какого-то объекта. И, разумеется, никто не мешает оставить объект на одном месте по оси X, а менять только его положение по Y здесь уже все зависит от задачи.
Но тут есть нюанс обычно мы мыслим в пикселях, десятках и сотнях пикселей, а здесь координаты будут слишком маленькими. Нужно будет весь этот график подвинуть куда-то по экрану, или растянуть, или еще что-то с ним сделать. Будет очень полезно разобраться с тем, как те или иные коэффициенты влияют на конечный результат, чтобы потом добавлять их на уровне интуиции.
Первым делом будут множители:
(x) => { return 2 * Math.sin(x);}(x) => { return 0.5 * Math.sin(5 * x);}
Они будут растягивать или сжимать наш график.

Умножая параметр (x в наших примерах) на какой-то коэффициент, мы получаем растяжение или сжатие по оси X. Умножая всю функцию на коэффициент получаем растяжение или сжатие по оси Y. Здесь все просто.
Добавим еще коэффициентов, только на этот раз не в виде множителей, а в виде слагаемых:
(x) => { return Math.sin(x) + 1;}(x) => { return Math.sin(x + 1);}
Что же там получилось?
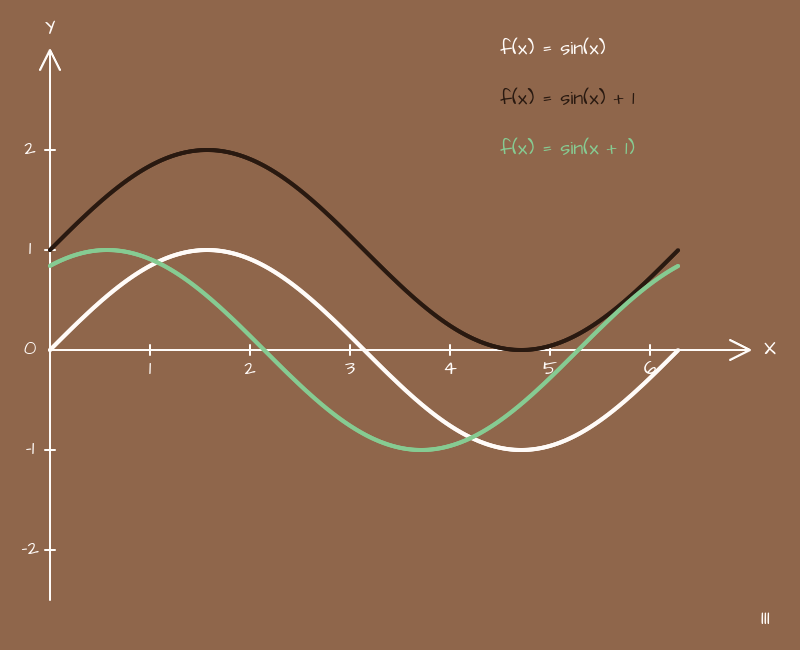
Очевидно график смещается. Добавляем коэффициент к параметру x получаем смещение по X, добавляем коэффициент ко всей функции получаем смещение по Y. Тоже, ничего сложного.
Эти же соображения действуют для всех подобных функций, не только для синуса.
Здесь у нас останется еще вопрос поворота всего графика. Для этого нам понадобится матрица поворота, но тема матриц и преобразований координат достойна отдельной статьи, так что сейчас мы лишь упомянем это ключевое слово и пойдем дальше.
Что будет, если сложить две синусоиды с разными коэффициентами? Давайте посмотрим!
(x) => { return Math.sin(x) + 0.2 * Math.sin(5 * x);}
Получается что-то такое:
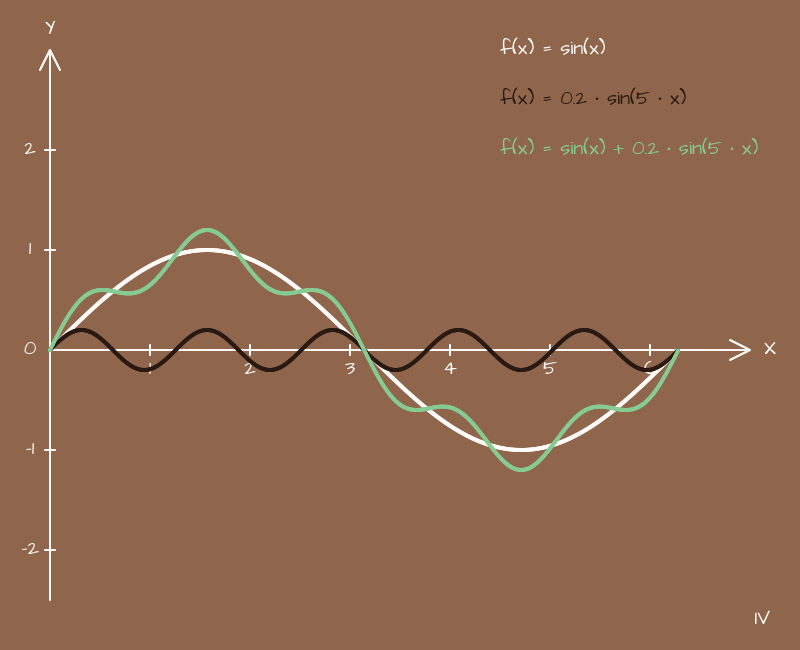
Если вы когда-то работали со звуковыми файлами или даже осциллографом в виде отдельного прибора, то наверное уже заметили, что намечается знакомая картинка. И ассоциация более, чем верная. Две волны накладываются друг на друга и получается более сложная волнообразная структура.
Но синусом мир не ограничивается. Никто не мешает поскладывать и другие функции. И поумножать тоже. И поделить. Для примера возьмем косинус и степенную функцию:
(x) => { return 2 * Math.cos(3 * x) / Math.pow(x + 1, 2);}

Получилась штука, которую во фронтенде ассоциируют со словом bounce (зеленая на графике). Заготовка для анимаций, построенная подобным образом, часто используется и в CSS-библиотеках, и встречается во всех более-менее популярных JS библиотеках для анимаций.
Можно подумать, что зеленая кривая здесь отображает график колебания пружины, но это не совсем так. Просто очень похоже на нее. Настолько похоже, что пользователь скорее всего не заметит разницы.
Но к вопросам физики мы еще вернемся.
Промежуточные итоги
Прежде, чем идти дальше, отметим самое важное, что нужно запомнить:
- Графики функций вида y = f(x) можно использовать как траектории для анимаций.
- Коэффициенты позволяют подвинуть траекторию в нужное место и растянуть до нужного размера.
- Иногда можно сымитировать физический процесс с достаточной точностью путем сочетания простых функций.
II. Полярная система координат
Переход из одной системы координат в другую часто может сделать что-то сложное чем-то простым, либо напротив что-то очень простое превратить во что-то, ломающее мозг. Полярная система координат не очень часто встречается в работе верстальщика, так что у многих возникают сложности с ее пониманием. И действительно, мы привыкли задавать положение чего-то в виде координат (X, Y), а здесь нужно брать угол (направление) и радиус (расстояние) до точки. Это очень непривычно.
В целом связь между координатами (X, Y) и (R, ) простая, но от этого само преобразование не становится очевидным:
const x = r * Math.cos(p);const y = r * Math.sin(p);
Здесь и дальше мы будем использовать букву p вместо стандартной , чтобы примеры кода не наполнялись unicode-символами.
На пальцах разница между полярной и прямоугольной системами координат примерно такая же, как между выражением идите отсюда 5 километров на северо-восток, а там увидите и вот вам GPS-координаты по широте и долготе.
На самом деле самый толковый способ понять, как все это работает это посмотреть на практике, чем мы и займемся.
Возьмем простую функцию:
(p) => { return p / 5;}
Она будет теперь отображать зависимость расстояния от направления, от угла (в радианах), который это направление задает. Постепенно увеличивая угол мы будем крутиться, как маленький человечек на стрелке на часах, и дальше останется рисовать линию там, где мы едем. Если бы функция каждый раз возвращала одно и то же значение, то длина стрелки бы не менялась, а мы бы рисовали окружность. Но наша функция дает прямую зависимость расстояния от угла, соответственно стрелка становится все длиннее, мы уезжаем дальше от центра и радиус круга, который мы рисуем, увеличивается. Получается спираль.
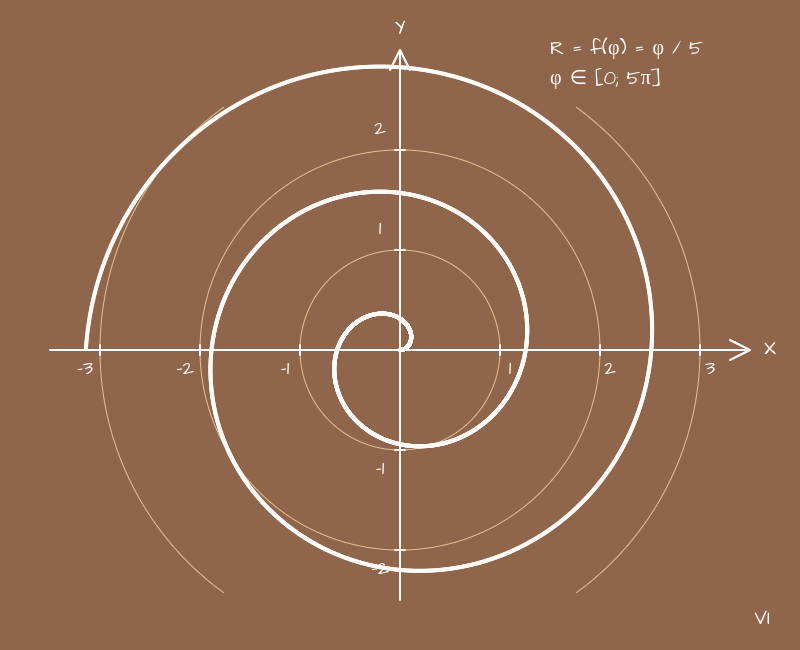
Но линейные зависимости это слишком скучно. Вернем нашу синусоиду на место и нарисуем ее одновременно в декартовой системе координат, используя как зависимость Y от X, и в полярной, как зависимость расстояния от угла.

Стоп. Что? Именно такая мысль должна здесь вас посетить. Почему синусоида стала круглой? Может даже показаться, что здесь что-то нечисто, что рисовалка графиков сломалась, но нет. Все так и должно быть. И на самом деле это небольшое наблюдение дает широкий простор для творчества.
Давайте произведем все те же манипуляции с коэффициентами, что мы делали с функциями в самом начале, и посмотрим, как они влияют на графики в полярной системе координат.
(p) => { return Math.sin(5 * p);}(p) => { return 2 * Math.sin(5 * p + 1);}

Цветочки! Конечно, что же еще здесь могло получиться?
Очень полезно воспользоваться одной из множества рисовалок графиков в сети и поэкспериментировать с разными функциями и коэфффициентами самостоятельно. Личный опыт в таких вопросах всегда дает лучшее понимание происходящего, чем отдельно взятые примеры от других людей.
Можно заметить, что теперь коэффициенты работают немного по-другому. Коэффициенты при параметре функции (теперь это угол) вращают график по кругу, а при всей функции растягивают его от центра.
Можно также заметить, что количество лепестков связано с коэффициентом при угле, так что очень легко делать цветочки с разным количеством лепестков.
Продолжим:
(p) => { return Math.sin(p) + 0.2 * Math.sin(2 * p);}(p) => { return 2 * Math.sin(p) + 0.2 * Math.sin(10 * p);}(p) => { return Math.sin(3 * p - Math.PI / 2) * Math.sin(4 * p);}

Человечек! Начинает казаться, что комбинации графиков можно использовать как замену для пятен Роршаха.
Продолжая комбинировать функции мы получим своеобразные кляксы:
(p) => { return (Math.sin(p) + Math.sin(p * 2) + 2) / 4;}(p) => { return (Math.sin(p) + Math.sin(p * 3) + 2) / 2;}(p) => { return Math.sin(p) + Math.sin(p * 4) + 2;}

Таким образом можно сделать вывод, что комбинируя функции и делая графики в полярной системе координат, мы можем с легкостью получать сложные циклические траектории, которые могут быть очень кстати, если нужно заставить какой-то объект в анимации колебаться у определенной точки или вокруг нее. При работе с абстрактной генеративной графикой стоит помнить о такой возможности.
Промежуточные итоги
Повторим некоторые моменты:
- Полярная система координат помогает строить сложные абстрактные траектории вокруг одной точки.
- Полезно экспериментировать с комбинациями функций и коэффициентов, чтобы при необходимости получить определенный характер движения, примерно знать, из чего можно сформировать нужную траекторию.
III. Параметрическое представление функций
Мы начали с использования функций вида y = f(x). Но мы также можем сделать x зависящим от чего-то еще. Это приведет к заданию координат в виде системы:
x = f1(t)y = f2(t)
В нашем случае это может быть очень кстати. Дело в том, что все предыдущие примеры были очень предсказуемыми, ограниченными. Мы не могли синусоиду развернуть, полетать туда-сюда или еще что-то такое сделать. Каждому x соответствовал один y. Ну или, в терминах полярной системы координат каждому углу соответствовал один радиус. С добавлением нового параметра мы снимаем эти ограничения.
В контексте анимаций подход с использованием дополнительного параметра органично вписывается в идею использовать в качестве этого параметра время. Или, если выражаться точнее, то локальное время с начала анимации. Идем по времени вперед анимация происходит в прямую сторону, идем по времени назад анимация проигрывается в обратную сторону. Это очень гибкий подход.
На самом деле мы можем представить все предыдущие примеры так, что была зависимость:
x = ty = f(t)
Или, в терминах кода, как вариант:
x: (t) => { return t;},y: (t) => { return (t / 2) - 1;}
Наши простые прямые выглядели бы как-то так:

Это было бы усложнением примеров на ровном месте, т.к. параметр t не играл бы никакой практической роли, мы меняли координату x напрямую, но дальше мы будем его везде подразумевать.
Сейчас мы не будем подробно останавливаться на этом вопросе, но отметим, что некоторые стандартные геометрические фигуры можно легко получить именно используя параметрическое представление:

Полезно об этом помнить.
Что будет, если мы возьмем для разнообразия косинус, и модуль от него? Получится что-то похожее на траекторию полета подпрыгивающего резинового мячика. Но реальный мячик будет подпрыгивать все меньше и меньше. Мы можем попытаться выразить изменения в движении по каждой из координат (X, Y) в виде отдельных функций, используя опыт, полученный ранее из экспериментов с ними. Вариантов там будет бесконечно много, но допустим наугад получилось что-то такое:
x: (t) => { return 5 * t / (t + 1);},y: (t) => { return 2 * Math.abs(Math.cos(5 * t)) / (t*t + 1);}
Что будет выглядеть как-то так:

Мы попытались угадать комбинации простейших функций, которые бы дали в результате что-то похожее на подпрыгивание мячика. Но насколько это на самом деле похоже на него? Можем ли мы вообще вот так взять и угадать траекторию такого сложного с точки зрения физики движения?
На самом деле вот так по графику мы не сможем оценить субъективную реалистичность движения, его нужно будет посмотреть в динамике. Но я вам скажу по секрету, что это не будет похоже на настоящее подпрыгивание. Ну то есть если мы запустим точку летать по этой траектории, то формально это подойдет под описание подпрыгивающего объекта, но где-то глубоко в подсознании будет казаться, что что-то здесь не так, что движение неестественное. Да, оно похоже на то, что нужно, но не совсем. Все же физические законы и наша попытка угадать их это не одно и то же. Отсюда можно сделать важное замечание:
Если у вас в проекте нужны достаточно реалистичные движения не гадайте, а возьмите готовые формулы из учебника физики.
Давайте попробуем это сделать на примере все этого же мячика.
Немного физики
Как только мы откроем учебник, нас встретят формулы для скорости и положения тела в зависимости от времени. Ну и также в них есть сопуствующие коэффициенты вроде ускорения свободного падения.
Мы сразу обнаружим, что нельзя так просто посчитать всю траекторию сразу, нам нужно находить моменты падения и считать каждое подпрыгивание по отдельности. Это мгновенно приведет к увеличению кодовой базы и перестанет быть похожим на простую математическую функцию:
x: (t) => { return t;},y: (() => { let y0 = 2; // Изначальное положение по Y let v0 = 0; // Изначальная скорость let localT = 0; // Локальное время полета от последнего отскока let g = 10; // Ускорение свободного падения let k = 0.8; // Условный коэффициент для не совсем упругого отскока return (t) => { let y = y0 + v0 * localT - g * localT * localT / 2; if (y <= 0) { y = 0; y0 = 0; v0 = (-v0 + g * localT) * k; localT = 0; } localT += 0.005; return y; };})()
Но зато результат будет и более реалистичным, и более практичным в плане адаптации его под разные условия использования.

Удобство здесь вещь не самая бесполезная. Обратите внимание, как меняется график, когда мы меняем коэффициенты. Пусть ускорение свободного падения станет равным 1.62, как на Луне. Что произойдет? Траектория сохранила характер, но условный мячик теперь дольше висит в воздухе после каждого подпрыгивания. Или поменяем коэффициент, условно определяющий насколько упругое отталкивание происходит и у нас уже не резиновый мячик, а деревянный карандаш. Стандартные формулы дают предсказуемое поведение при изменении отдельных коэффициентов. Если бы мы имели чисто на глазок угаданную закономерность, было бы очень сложно ее адаптировать таким же образом, особенно при редактировании кода, написанного несколько лет назад.
Такая проблема часто встречается в разных экспериментальных примерах с CodePen, когда оригинальный автор угадал что-то под свою задачу, сильно похожую на нашу, и мы попадаем в ловушку, говоря да там работы на пару минут, сейчас все будет двигаться как нужно, а потом, спустя час, решаем, что переписать это решение проще, чем доработать. Будьте внимательны!
В качестве упражнения вы можете попробовать смоделировать аналогичное падение мячика, но уже по наклонной поверхности, это может быть хорошей практикой по этой теме.

Подобные относительно сложные с точки зрения физики процессы, связанные с кинематикой, магнетизмом или моделированием жидкостей редко встречаются в обычной верстке. Здесь, конечно, речь идет о дизайнерских сайтах с генеративной графикой или какими-то интерактивными физическими моделями. Но тем не менее, если вы стремитесь развиваться в своей области это может быть неплохой темой для ознакомления на пару вечеров. Специалистом по моделированию физических процессов вы не станете, но кругозор в вопросах анимирования расширится, а это очень здорово. Когда встанет задача сделать что-то с этими темами связанное, вы уже будете знать, куда смотреть.
Промежуточные итоги
На последних примерах мы увидели следующее:
- Время в анимациях можно использовать в качестве параметра в параметрическом представлении функций. Да и в целом привязывать анимацию ко времени удобно.
- При использовании параметрического представления функций у нас нет ограничений вида одному X соответствует один Y. Можно усложнить траектории.
- Параметрическое представление подталкивает к моделированию физических процессов, но, если вам нужна реалистичность и универсальность имеет смысл запастить справочником по физике и брать готовые формулы оттуда.
IV. Кривые Безье
С кривыми Безье сталкивался, наверное, каждый верстальщик. Мы их постоянно используем в CSS. Но на самом деле то, что мы там используем это очень частный случай их применения. Мы же посмотрим на все это в более общем случае.
Если пойти на википедию и почитать о том, что же такое кривая Безье, то мы увидим страшные формулы с большим знаком суммы, который так и отдает высшей матиматикой и всех пугает. Но можно это все сформулировать на пальцах.
У нас есть набор точек. Две. Три. Пять. Десять. Сколько угодно. Для этих точек по определенной закономерности строятся выражения, которые мы потом складываем в одно и получаем супер-мега-параметрическую функцию, где координаты этих точек играют роль коэффициентов.
В зависимости от количества точек кривая будет иметь соответствующее название. Кубическая кривая безье будет иметь 4 точки, а наш параметр t (в контексте анимаций время) будет максимум в третьей степени поэтому она и кубическая. Если будет больше точек, то степени будут увеличиваться. Это все приведет к увеличению нагрузки на процессор, снижению производительности в большинстве случаев, и широкое практическое применение имеют только кубические кривые Безье. В CSS используются именно они. А еще они используются в SVG для создания path. Но об этом чуть дальше.
Здесь стоит сказать, что чем больше точек, тем более сложную кривую можно построить. Из двух точек получится просто прямая. Из трех дуга (возможно ассимметричная). Из четырех загогулька в виде буквы S, либо дуга с двойным перегибом. Из пяти загогулька с еще одним перегибом, и.т.д.
Но вернемся к четырем точкам, пропустим все расчеты и сразу перейдем к нужной нам форме двум функциям для X и Y от t:
x: (t) => { return ((1-t)*(1-t)*(1-t)*x0) + (3*(1-t)*(1-t)*t*x1) + (3*(1-t)*t*t*x2) + (t*t*t*x3);},y: (t) => { return ((1-t)*(1-t)*(1-t)*y0) + (3*(1-t)*(1-t)*t*y1) + (3*(1-t)*t*t*y2) + (t*t*t*y3);}
Здесь (x0, y0) координаты первой точки, (x1, y1) второй и.т.д. Они, как мы уже отметили, выполняют роль коэффициентов.
Давайте построим график, взяв первую точку в координатах (0, 0), а последнюю, четвертую, в (1, 1). Для удобства первая и вторая, а также третья и четвертая точки будут соединяться отрезками, чтобы было понятно, в каком порядке они идут.

На графике можно заметить, что меняя параметр t от 0 до 1 мы получаем знакомую кривую, вписанную в квадрат, которую мы привыкли видеть в CSS. Это она и есть.
Вы можете спросить, а зачем так все усложнять? Та кривая на картинке это же почти график корня x, неужели нельзя ее получить более простым способом?
Все дело в том, что это очень частный случай. Мы не обязаны фиксировать точки в координатах (0, 0) или (1, 1). Мы можем брать вообще любые точки. Что, собственно, и сделаем:

Как вы можете видеть, получаемые траектории плавные, могут самопересекаться, и, что самое главное прогнозируемые. Немного экспериментов и вы будете четко понимать, куда пойдет кривая, если подвинуть ту или иную точку. Это очень удобно.
Вы можете также обратить внимание, что график начинает идти точками. Это особенность работы конкретной программы, но это не баг, а фича. Расстояние во времени (параметре t в нашем случае) между точками одинаковое. Эти графики строятся по принципу мячика, оставляющего след, о котором мы говорили в самом начале. Этот пунктир показывает, где анимация будет идти быстрее, где скорость движения увеличится. В поворотах скорость меньше, на относительно прямых участках больше. Это добавляет определенную физику в движение, делает его более разнообразным, что часто бывает очень кстати.
Такого рода кривые хорошо использовать при анимациях появления или улетания объектов.
Но что-то мы совсем забыли о синусе. Почему бы его не добавить к имеющимся выражениям?
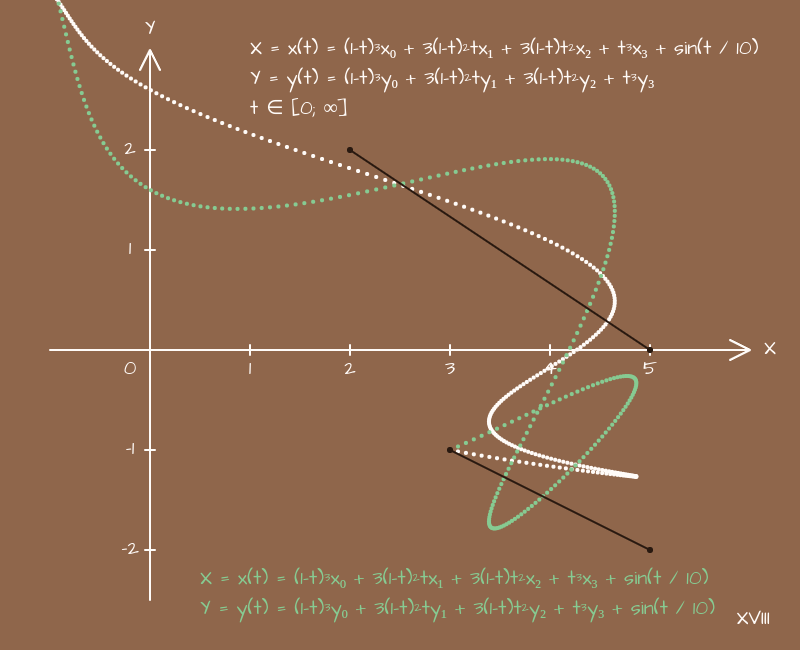
Ооо Небольшой шум в виде синуса делает траекторию менее предсказуемой, но с другой стороны она сохраняет общее направление и стала даже более интересной. Полезно это запомнить.
Последовательности кривых Безье
В примере с мячиком мы уже столкнулись с сочетанием нескольких функций. Движение идет сначала по одной, потом по другой и.т.д. Мы можем сочетать все, что угодно, но наверное самые интереные и полезные результаты будут, если начать комбинировать кривые Безье. В SVG именно последовательности этих кривых используются для того, чтобы делать path сложной формы. Там, конечно, они разбавляются еще прямыми, получается более запутанная структура, но общий смысл мы постараемся воспроизвести.
У кривых Безье есть одна особенность, которая нам в этом поможет. Часть кривой, соответствующая значениям параметра от 0 до 1 начинается в первой точке и заканчивается в четверной (мы все еще говорим про кубические кривые). Этот факт позволяет ограничить траекторию, и мы будем точно знать, где она начнется, и где закончится.
А дальше самое интересное: если угол наклона отрезка между третьей и четвертой точками одной кривой и первой и второй точками у второй кривой будет одинаковым, то они сольются в одну. Там не будет стыка, острого угла, резкого перехода. А если их длина будет совпадать, то это сыграет нам на руку, нормализовав разницу в скорости движения, если мы будем использовать время как параметр в наших функциях.
Такое сочетание лучше посмотреть на картинке:

Здесь мы видим 4 кривых Безье, которые слились в одну. Если убрать вспомогательные точки и отрезки, то никто и не догадается, что это не одна кривая, а несколько.
Таким образом возможно на ходу делать плавные траектории, огибающие какие-то объекты на условной сцене, где происходит анимация.
Пусть точки, где кривые соединяются, будут называться опорными. Что будет, если эти опорные точки будут стоять на месте, а соседние с ними мы начнем двигать, симметрично относительно друг друга (если одна движется вверх вторая вниз, одна влево другая вправо)?
У нас получится набор кривых, схожих по направлению, но как бы слегка колеблющихся:

Это может быть хорошей базой для создания разного рода желейных эффектов, когда какой-то контур немного плавает туда-сюда, а в контексте траекторий можно сделать так, чтобы она каждый раз немного менялась, сохраняя свою плавность и общее направление движения. Иногда это очень полезно.
Промежуточные итоги
Давайте обобщим сказанное.
- Кривые Безье это очень мощный инструмент, позволяющий делать сложные, но предсказуемые траектории для абстрактных анимаций.
- Любые кривые можно соединить в более сложную траекторию, если проявить некоторую аккуратность.
Заключение
Не так страшен черт, как его малюют. Генерирование траекторий определенной формы для движений в покадровых анимациях кажется сложной задачей, но имея общие представления о том, что можно делать с графиками функций, она становится вполне доступной. Дальше останется только вопрос оптимизаций, но он индивидуален для каждого проекта, да и редко на самом деле подобные функции становятся узким местом в производительности. Надеюсь, что данный набор иллюстраций поможет начинающим разработчикам составить представление о том, что можно делать, и где примерно искать ответы на свои вопросы, если встанет вопрос о сложных движениях в 2D анимациях.





































 . Очевидно, что, хотя
наблюдаемые могут быть записаны в терминах этих координат, они
должны быть инвариантны при изменениях координат
. Очевидно, что, хотя
наблюдаемые могут быть записаны в терминах этих координат, они
должны быть инвариантны при изменениях координат  . В конце концов, координаты изначально
произвольны. Простым примером (локального) изменения координат
является растяжение/масштабирование:
. В конце концов, координаты изначально
произвольны. Простым примером (локального) изменения координат
является растяжение/масштабирование:
 по всем возможным состояниям
i, каждое из которых имеет энергию
по всем возможным состояниям
i, каждое из которых имеет энергию  , через время t. таким
образом,
, через время t. таким
образом,
 . Благодаря этому
хорошему свойству мы можем сначала сосредоточиться на вычислении
Z струны, колеблющейся в одном поперечном измерении, а
затем возвести ее в степени D-2, чтобы заставить ее
колебаться в поперечных измерениях D-2.
. Благодаря этому
хорошему свойству мы можем сначала сосредоточиться на вычислении
Z струны, колеблющейся в одном поперечном измерении, а
затем возвести ее в степени D-2, чтобы заставить ее
колебаться в поперечных измерениях D-2.



 . Однако энергии
нулевого уровня произвольны, и это был просто полезный
традиционный выбор. В конечном счете существует двусмысленность в
построении квантового ГО из классического ГО, называемая
упорядочивающей двусмысленностью, поскольку вам нужно
преобразовать коммутирующие переменные p, q в
некоммутирующие операторы
. Однако энергии
нулевого уровня произвольны, и это был просто полезный
традиционный выбор. В конечном счете существует двусмысленность в
построении квантового ГО из классического ГО, называемая
упорядочивающей двусмысленностью, поскольку вам нужно
преобразовать коммутирующие переменные p, q в
некоммутирующие операторы  , и нет никакого
предпочтительного квантования таких вещей, как pq. Нужно
квантование
, и нет никакого
предпочтительного квантования таких вещей, как pq. Нужно
квантование 


 , наша
, наша  становится
становится


 , и она останется
инвариантной, если
, и она останется
инвариантной, если
 для сестринских колебаний. К
счастью, я просто махну рукой, что
для сестринских колебаний. К
счастью, я просто махну рукой, что  так, чтобы общая
амплитуда была произведением
так, чтобы общая
амплитуда была произведением  .
. . Таким образом, позвольте
мне предположить, что амплитуда для центра масс примерно такова
. Таким образом, позвольте
мне предположить, что амплитуда для центра масс примерно такова






 (наш завершающий ход будет
заключаться в том, чтобы устремить его в бесконечность), мы строим
комбинацию
(наш завершающий ход будет
заключаться в том, чтобы устремить его в бесконечность), мы строим
комбинацию

 .
.

 , кажется,
первообразную сходу не отгадаешь. Итак, возьмем предел . Нетрудно
заметить, что f(vw) сходится к константе
(1,-1,1,-1) соответственно на четырех отрезках (если вы ее
не видите, запишите ее с помощью комплексных экспонент). Таким
образом, в пределе интеграл равен
, кажется,
первообразную сходу не отгадаешь. Итак, возьмем предел . Нетрудно
заметить, что f(vw) сходится к константе
(1,-1,1,-1) соответственно на четырех отрезках (если вы ее
не видите, запишите ее с помощью комплексных экспонент). Таким
образом, в пределе интеграл равен









 во что надо,
замечаем, что оно должно быть самим (), и поэтому r=1/24,
и поэтому, наконец
во что надо,
замечаем, что оно должно быть самим (), и поэтому r=1/24,
и поэтому, наконец
 является модулярной формой веса 12. Теория струн тесно связана с
этой областью математики; на самом деле я надеюсь, что для тех, кто
уже знает этот материал, это послужило беглым взглядом на то, что
струны даже имеют отношение к модульным формам. В любом случае, я
не думаю, что могу судить предмет, который я на самом деле едва
знаю по-верхам, так что тут попримолкну.
является модулярной формой веса 12. Теория струн тесно связана с
этой областью математики; на самом деле я надеюсь, что для тех, кто
уже знает этот материал, это послужило беглым взглядом на то, что
струны даже имеют отношение к модульным формам. В любом случае, я
не думаю, что могу судить предмет, который я на самом деле едва
знаю по-верхам, так что тут попримолкну.


 используя
используя 
 до
до  где
где  а
а  .
. или что тоже самое при всё большом увеличении числа отрезков
(числа
или что тоже самое при всё большом увеличении числа отрезков
(числа  обозначающего индекс-номер последнего отрезка)
обозначающего индекс-номер последнего отрезка)

 Обозначим её
Обозначим её 
 существует
значение функции
существует
значение функции  , а в точке
, а в точке  значение
значение 
 ,
, 
 и
и  и продолжим наши рассуждения.
и продолжим наши рассуждения.




 до
до  , где первое и второе некоторые произвольные значения переменной,
то необходимо вычислить разность
, где первое и второе некоторые произвольные значения переменной,
то необходимо вычислить разность

 может
быть любое обозначение, к примеру,
может
быть любое обозначение, к примеру,  это не имеет значения. Буква
это не имеет значения. Буква всего
лишь обозначает имя для функции, а скобки отделяют имя от сущностей
обычно числовых переменных над которыми совершаются те или иные
операции, дающие в результате значение функции.
всего
лишь обозначает имя для функции, а скобки отделяют имя от сущностей
обычно числовых переменных над которыми совершаются те или иные
операции, дающие в результате значение функции. одна и таже, то есть иными словами значения переменной-аргумента в
точках
одна и таже, то есть иными словами значения переменной-аргумента в
точках  для
для  и
и  одно и тоже. Далее, мы покажем, что
одно и тоже. Далее, мы покажем, что  производная
производная  , то есть можно записать
, то есть можно записать  или
или  .
. . К примеру, пусть функция задана выражением
. К примеру, пусть функция задана выражением  . Тогда, при
. Тогда, при  ,
,  , а значение
, а значение  . Если
. Если .
Тогда, при
.
Тогда, при  ,
,  , а значение
, а значение  .
.
 ,
,  ,
,  обозначают вероятности перехода
из одного состояния в другое. Так,
обозначают вероятности перехода
из одного состояния в другое. Так, 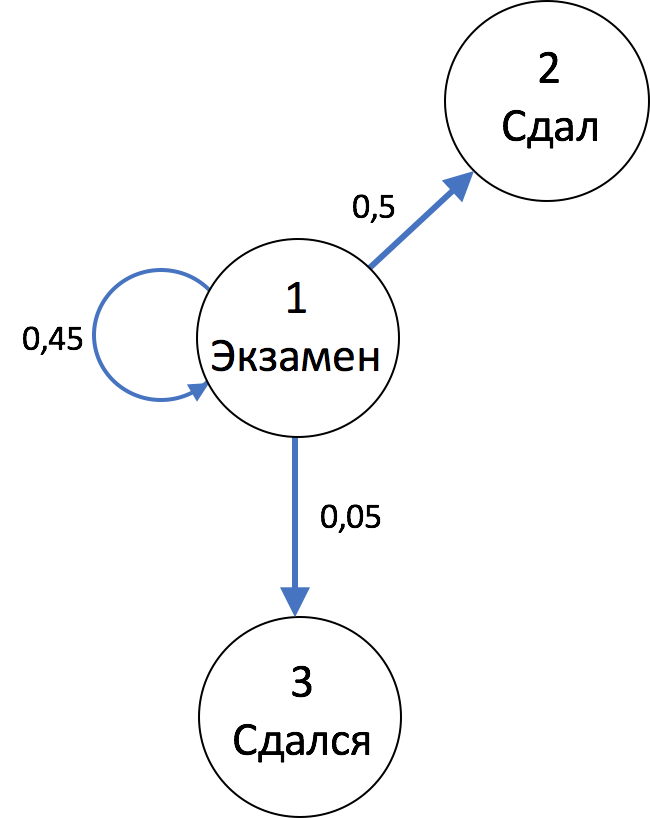

 , обозначают вероятности перехода
из одного состояния в другое. Если нет перехода между состояниями,
то это значит, что вероятность перехода равна 0.
, обозначают вероятности перехода
из одного состояния в другое. Если нет перехода между состояниями,
то это значит, что вероятность перехода равна 0.



 .
Т.к. мы не исследуем вероятность нахождения в состояниях 3 и 4, и
нас интересуют только состояния 1 и 2 и вероятности перехода ИЗ
них, то этот несколько искусственный прием допустим в данном
случае. Эти добавленные переходы отражают тот факт, что на экзамене
постоянно присутствует одинаковое количество претендентов: сколько
убыло (сдало/сдалось) столько и добавилось. При этом коэффициент
0,5 обеспечивает выполнение последнего условия:
.
Т.к. мы не исследуем вероятность нахождения в состояниях 3 и 4, и
нас интересуют только состояния 1 и 2 и вероятности перехода ИЗ
них, то этот несколько искусственный прием допустим в данном
случае. Эти добавленные переходы отражают тот факт, что на экзамене
постоянно присутствует одинаковое количество претендентов: сколько
убыло (сдало/сдалось) столько и добавилось. При этом коэффициент
0,5 обеспечивает выполнение последнего условия:

 вероятности
нахождения в состоянии 1,2,3,4 и
вероятности
нахождения в состоянии 1,2,3,4 и

 мы получаем следующий
собственный вектор:
мы получаем следующий
собственный вектор:
 находится из условия
находится из условия



 оставим таким же, равным 5%. Это
не сильно повлияет на результат, но это будет отражать тот факт,
что шок от попытки сдать экзамен из состояния 1 будет достаточно
большим (причины мы обсудим позже), и разумно предположить, что это
будет чаще приводить к разочарованию.
оставим таким же, равным 5%. Это
не сильно повлияет на результат, но это будет отражать тот факт,
что шок от попытки сдать экзамен из состояния 1 будет достаточно
большим (причины мы обсудим позже), и разумно предположить, что это
будет чаще приводить к разочарованию. и
и 


 и
и  . Логика такая же,
как и в предыдущем случае. Таким образом мы возвращаем убывших
претендентов и обеспечиваем следующее условие:
. Логика такая же,
как и в предыдущем случае. Таким образом мы возвращаем убывших
претендентов и обеспечиваем следующее условие:

 при этом находится исходя из условия
нормировки вероятности
при этом находится исходя из условия
нормировки вероятности




 не совсем корректен. Дело в том,
что наше условие опыт уменьшает вероятность несдачи экзамена на 30%
искусственно ограничивает снизу вероятность
не совсем корректен. Дело в том,
что наше условие опыт уменьшает вероятность несдачи экзамена на 30%
искусственно ограничивает снизу вероятность 

 %
% %
% %. Но этого может быть
недостаточно, поэтому экзамен все усложняется и усложняется,
появляются разные варианты, делается так, что даже с дампом
требуется интенсивная тренировка.
%. Но этого может быть
недостаточно, поэтому экзамен все усложняется и усложняется,
появляются разные варианты, делается так, что даже с дампом
требуется интенсивная тренировка.
 Вектор AB в осях координат
Вектор AB в осях координат


 Смещенная ось координат
Смещенная ось координат

 Трехмерный вектор AB
Трехмерный вектор AB



 4х мерный куб Тессеракт
4х мерный куб Тессеракт