И снова привет! В прошлом посте мы начали рассматривать процесс управления зависимостями в JavaScript, разобрали основы: что такое npm-пакет; как выглядит манифест пакета; в каких полях прописываются зависимости; что такое дерево зависимостей; а также основы семантического версионирования (semver). Если вы пропустили предыдущий пост, то рекомендую начать с него.
Сегодня мы пойдем немного дальше и подробнее рассмотрим, как работает semver, как правильно прописывать диапазоны зависимостей, а также устанавливать и обновлять их.
npm shell autocomplete
В моих постах я буду часто упоминать npm и различные команды с его использованием. Чтобы сделать набор команд в терминале чуточку удобнее, предлагаю установить автодополнения в ваш shell.
Сделать это достаточно легко, достаточно выполнить следующие команды:
-
Для Bash:
npm completion >> ~/.bashrcsource ~/.bashrc -
Для Z shell:
npm completion >> ~/.zshrcsource ~/.zshrc
Это добавит в конфигурационный файл shell-а необходимый скрипт. После этого, если вы напишите
npm smth, а затем нажмете[TAB], shell автоматически дополнит вашу команду или предложит варианты дополнения.
Инициализация проекта
Как мы уже успели обсудить, проектом в npm является любая
директория, в которой находится манифест (файл
package.json). Вы можете создать манифест вручную в любом
редакторе кода, либо выполнить команду npm
init. Она по умолчанию задаст вам серию вопросов в
интерактивном режиме и сгенерирует простейший манифест в текущей
директории на основе ваших ответов.
Однако я предпочитаю вызывать команду следующим образом:
npm init -y, а затем править манифест в редакторе. При
таком вызове npm не будет задавать вопросов, а просто сгенерирует
минимальный манифест со значениями по умолчанию.
Использование инициализаторов
Говоря про npm init нельзя не упомянуть про
возможность использования специальных пакетов инициализаторов (npm
initializers). Они облегчают создание новых проектов, генерируя
необходимый boilerplate-код.
Используются пакеты так: npm init
<initializer>, где <initializer>
это название инициализатора (например, esm или
react-app).
Инициализатор, по сути, это специальный npm-пакет с префиксом
create-, который загружается из npm registry в момент
вызова команды и выполняется. У каждого инициализатора могут быть
свои аргументы, настройки и поведение.
Например, можно создать React-приложение с помощью
инициализатора `create-react-app: npm init react-app
-- my-react-app. Два минуса позволяют разделить аргументы
CLI, которые передаются в команду npm init от тех, что
передаются в сам инициализатор. Особенность инициализатора React,
например, в том, что проект будет создан не в текущей директории, а
в поддиректории с названием, которое вы укажете при вызове (в
примере: my-react-app).
Вы можете сами написать свой инициализатор и опубликовать его в registry. Это может быть особенно удобно в корпоративной среде, где существует множество стандартов и соглашений вы можете оформить их все в виде инициализатора и опубликовать его в закрытом npm registry. Таким образом, разработчики внутри компании смогут быстро создавать новые проекты.
Добавление зависимостей в проект
Как мы выяснили ранее, зависимости прописываются в манифесте
проекта в полях dependencies,
devDependencies, peerDependencies или
optionalDependencies. Чтобы добавить новую зависимость
в проект, необходимо использовать команду: npm install
<package-name>, или сокращенно: npm i
<package-name>.
Пример: npm i lodash.
Эта команда установит lodash самой свежей стабильной версии и
добавит эту зависимость в поле dependencies манифеста
проекта.
Аналогично можно устанавливать сразу несколько зависимостей
одновременно: npm i lodash express passport.
Команда install с флагами также позволяет выбрать,
в какое поле будет добавлена зависимость:
-P, --save-prod
установка вdependencies(работает по умолчанию)-D, --save-dev
установка вdevDependencies-O, --save-optional
установка вoptionalDependencies
Если вам нужно установить зависимость в
peerDependencies, то придётся сделать это вручную т.
к. npm не предусматривает для этого специальной команды. Как
вариант, можно сначала установить зависимость в
dependencies при помощи команды npm
install, а потом перенести ее вручную в
peerDependencies. В этом случае вам не придется
угадывать свежую версию пакета (если вдруг ваш IDE не поддерживает
автоматическую интеграцию с npm).
Конечно, зависимость можно добавить в список и самостоятельно в редакторе кода, но я всегда рекомендую использовать команды npm для добавления зависимостей, т. к. это дает более надежный результат: вы гарантированно получаете последнюю версию нужного пакета, а список зависимостей будет корректно отсортирован в лексикографическом порядке (что позволит избежать конфликтов при мерже в Git).
Команда npm install является многоцелевой командой, т. к. одновременно решает сразу несколько задач: установку уже прописанных зависимостей в проект и добавление новых зависимостей с их прописыванием в манифесте.
Добавление зависимости старой версии
Если по какой-то причине вы хотите добавить зависимость не самой
свежей версии, то вы можете указать нужную версию через символ
@:
npm i lodash@3.9.2npm i lodash@3
Однако делать это рекомендуется только в самом крайнем случае. Об этом я расскажу подробнее чуть позже.
Установка зависимостей
Выше мы рассмотрели варианты добавления зависимостей в проект.
Но как установить зависимости, которые уже прописаны в манифесте,
если вы, к примеру, только сделали git clone?
Для этого достаточно просто выполнить команду npm
install или npm i без аргументов. Npm прочитает
содержимое манифеста, найдет указанные зависимости и установит их в
проект.
Существует возможность установить только одну категорию зависимостей:
--only=prod[uction]--only=dev[elopment]
Это может быть полезно, если вы хотите, к примеру, только запустить программу на Node.js, но не работать над ней.
Просмотр установленных зависимостей
Прежде чем мы поговорим про обновление зависимостей, было бы
полезно научиться просматривать их. Для этой цели в npm также
предусмотрена специальная команда: npm ls.
Синтаксис команды выглядит следующим образом: npm ls
[<package-name>], где
<package-name> опциональное название пакета,
который вы хотите найти в дереве зависимостей.
Если вызвать команду без аргументов, то она выведет полное дерево зависимостей (не ослепните, дерево может быть огромным):

Крошечная порция результата выдачи команды npm ls
в большом проекте.
Иногда бывает необходимо найти ту или иную транзитивную
зависимость в дереве проекта, чтобы понять, какие пакеты тянут ее,
для этого можно передать название пакета в команду: npm ls
lodash.

Результат поиска пакета lodash в дереве зависимостей крупного
проекта при помощи команды npm ls lodash.
Нужно заметить, что команда npm ls позволяет ограничивать
глубину поиска при помощи опции depth. Например,
следующая команда выведет только список прямых зависимостей
проекта:
npm ls --depth=0
Как вы уже догадались, по умолчанию команда работает со всем деревом целиком.
Также вы можете использовать опции dev или
prod для того, чтобы вывести только зависимости из
полей dependencies или
devDependencies:
npm ls --dev[elopment]npm ls --prod[uction]
Использование же опции json позволяет получить
дерево зависимостей в формате. пригодном для машинной обработки. В
этом режиме npm выводит более подробную информацию о пакетах, а не
только название и версию. Режим может быть также полезен для
отладки и сравнения двух деревьев (например, в разных ветках
проекта):
npm ls --json
Обновление зависимостей
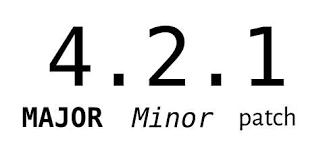
Как мы уже рассмотрели в предыдущем посте, в npm для
управления зависимостями используется система семантического
версионирования (semver). Благодаря ей вы можете обновлять
зависимости в своем проекте с предсказуемыми результатами: к
примеру, если зависимость обновилась с версии 1.2.3 до
версии 1.2.4 (patch update) или
1.3.0 (minor update), то это не сломает ваш
проект, т. к. по правилам semver такие обновления не должны
нарушать обратной совместимости. А если обновление производится с
версии 1.2.3 до версии 2.0.0 или выше, то
здесь вам следует обязательно заглянуть в журнал изменений
(changelog) данного пакета, чтобы убедиться, что обновление ничего
не сломает. Возможно, вам придется внести изменения в свой код,
чтобы восстановить совместимость.
Несмотря на то, что semver гарантирует достаточно высокий уровень безопасности при обновлении, бывают случаи, когда разработчики какого-то пакета могут нарушать правила и вносить критические изменения в patch- или minor-обновлениях (в первую очередь это касается непопулярных пакетов, которыми управляют менее опытные разработчики).
В моей практике такое случается очень редко, но никто не застрахован от ошибок. Поэтому после любого обновления зависимостей в проекте необходимо обязательно проводить полный цикл сборочных и тестовых мероприятий, чтобы убедиться, что всё работает как нужно, особенно перед выкаткой в эксплуатацию (надеюсь, это происходит у вас автоматически).
Версии зависимостей
Давайте теперь рассмотрим, как именно прописываются версии зависимостей в манифесте проекта и какие механизмы дает нам semver для управления процессом обновления. Как я уже упомянул выше, при установке зависимости npm автоматически устанавливает самую свежую версию и включает наиболее свободный режим обновления для этой зависимости: разрешает как patch-, так и minor-обновления.
В package.json это выглядит следующим образом:
{ "dependencies": { "lodash": "^4.17.17" }}
Символ ^ (caret, hat или крышечка) указывается
перед номером версии и имеет особое значение в semver. В данном
случае это означает, что версия зависимости lodash должна
обновляться до максимально доступной, но не выше
5.0.0, т. е. разрешает patch- и minor-обновления, но
запрещает обновления, нарушающие обратную совместимость.
Помимо крышечки существует еще довольно много способов задать диапазон версии, все их можно посмотреть в описании пакета semver, который и реализует эту функциональность в npm. Однако в 99 % случаев зависимости стоит указывать именно через крышечку (как делает npm по умолчанию), т. к. это дает наибольшую гибкость при обновлении зависимостей, и в то же время защищает вас от критических изменений.
Фиксация версий зависимостей
Такое случается крайне редко, но иногда может возникнуть ситуация, когда вам нужно зафиксировать версию зависимости в вашем проекте. Для этого достаточно указать номер версии без указания диапазона и использования специальных символов, например, так:
{ "dependencies": { "lodash": "4.17.17" }}
Это гарантирует, что lodash будет установлен именно версии
4.17.17, ни больше, ни меньше.
Однако фиксация версий зависимостей имеет ряд существенных недостатков:
- такие зависимости перестают обновляться, вы перестанете автоматически получать исправления багов, а самое главное улучшения безопасности,
- если в дереве зависимостей вашего проекта этот пакет встречается более одного раза, то это приведет к тому, что он будет установлен несколько раз (несколько разных версий). Про дублирование зависимостей мы подробнее поговорим в будущем, но пока поверьте мне на слово, это может приводить к существенным сложностям.
По этим причинам использовать фиксацию зависимостей нужно в очень редких исключительных случаях и только в качестве временной меры.
Просмотр устаревших зависимостей
Новые версии пакетов выходят регулярно. Поэтому пакеты,
установленные в вашем проекте, могут устаревать и их необходимо
регулярно обновлять. Команда npm outdated
позволяет вывести список устаревших пакетов.

Результат команды npm outdated в проекте, где
установлены две устаревшие зависимости.
Эта команды выводит таблицу со следующими колонками:
| Колонка | Описание |
|---|---|
| Package | Название пакета |
| Current | Текущая установленная версия |
| Wanted | Максимальная версия, которая удовлетворяет диапазону semver, прописанному в манифесте проекта |
| Latest | Версия пакета, которую автор указал в качестве самой свежей (как правило, максимально доступная версия пакета) |
| Location | Место расположения зависимости в дереве |
По умолчанию команда npm outdated выводит список
прямых зависимостей вашего пакета. Однако, если использовать
аргумент depth с указанием глубины просмотра, то npm
покажет устаревшие зависимости, в том числе и на заданной глубине
дерева зависимости:
npm outdated --depth=10
Чтобы просмотреть полный список всех устаревших зависимостей, можно использовать следующую команду:
npm outdated --depth=9999
Обновление устаревших зависимостей
Обновить устаревшие зависимости в npm можно при помощи команды
npm update.
Команда проверяет версии установленных зависимостей по отношению
к версиям, доступным в npm registry, с учётом диапазонов версий
semver, указанных в манифесте вашего проекта. Если установленная
версия того или иного пакета отличается от максимальной версии,
доступной в registry (учитывая ограничение semver), то более свежая
версия будет загружена и установлена, а манифест будет обновлен,
чтобы минимальная версия в диапазоне соответствовала установленной.
Важно заметить, что весь этот процесс протекает без нарушения
semver, т. е. вызов npm update никогда не приведет к
нарушению диапазонов версий, указанных в вашем манифесте.
Приведем пример: допустим, в вашем проекте указан диапазон
версий пакета lodash: ^4.16.4. Вызов npm
update приведет к тому, что пакет будет обновлен до версии
4.17.19, а манифест будет автоматически изменен, чтобы
содержать диапазон ^4.17.19.
По аналогии с командой npm outdated, команда
npm update также поддерживает аргумент
depth и по умолчанию обновляет только прямые
зависимости проекта, не трогая зависимости в глубине дерева.
Поэтому, чтобы обновить все зависимости в проекте необходимо
вызывать команду следующим образом:
npm update --depth=9999
Это гарантирует. что абсолютно все зависимости в дереве (включая транзитивные) будут обновлены до самых последних версий. Такую процедуру рекомендуется делать регулярно, чтобы в вашем проекте всегда был самый свежий код с последними исправлениями багов и проблем безопасности.
npm-check
В качестве альтернативы командам npm outdated и
npm update хочу предложить интересный инструмент под
названием npm-check.
Вы можете установить его при помощи следующей команды:
npm i -g npm-check
Инструмент поддерживает интерактивный режим, позволяя вам выбрать галочками те пакеты, которые вы хотите обновить. Кроме того, он позволяет обновлять пакеты не только в рамках ограничений semver, но и игнорируя их, перепрыгивая с одной мажорной версии зависимости на другую. Разумеется, делать это нужно осмысленно: тщательно изучая журнал изменений каждого мажорно-обновляемого пакета на наличие нарушений обратной совместимости. И никогда не забывайте тестировать ваш код после любых обновлений!

Результат вызова npm-check в проекте: доступно два
обновления, одно мажорное и одно минорное.

Также результат вызова npm-check, но уже в
интерактивном режиме: галочками можно выбрать зависимости, которые
вы хотите обновить.
В качестве очень полезного бонуса: npm-check
позволяет обнаружить, если какая-то из зависимостей не используется
в проекте:

npm-check сообщает о том, что пакет lodash,
возможно, не используется в проекте.
Рекомендую всегда держать этот незаменимый инструмент (или аналогичный) в своем арсенале.
Удаление зависимостей
Ну и наконец давайте рассмотрим, как мы можем удалять ранее
добавленные зависимости в проект. Для этого существует команда
npm uninstall, или сокращенно rm,
r или un. Чтобы удалить один или
несколько проектов, мы можем вызвать команду следующим образом:
npm rm lodash express
Будут удалены указанные пакеты как из файловой системы проекта, так и из его манифеста.
Workflow работы с npm-проектом
Мы уже рассмотрели несколько полезных команд и инструментов, давайте попробуем обобщить наши знания для того, чтобы выработать некий workflow для работы над JavaScript-проектами. Не переживайте, потом мы его доработаем, когда углубимся в другие важные вопросы.
- Инициализация проекта:
npm init
(интерактивно)npm init -y
(с последующим редактированием в IDE)
- Добавление зависимостей:
npm install <dependency>npm install <dependency-1> <dependency-2>npm install -D <dev-dependency>
- Проверка и обновление зависимостей:
npm outdated
(просмотр прямых устаревших зависимостей)npm outdated --depth=9999
(просмотр всех устаревших зависимостей)npm update
(обновление прямых устаревших зависимостей с учетом semver)npm update --depth=9999
(обновление всех устаревших зависимостей с учетом semver)npm-check
(просмотр прямых устаревших зависимостей)npm-check -u
(интерактивное обновление прямых устаревших зависимостей)
- Удаление зависимостей:
npm rm <dependency>
Продолжение следует
Мы подробнее рассмотрели процесс инициализации проекта, добавления, установки и обновления зависимостей. Рассмотрели, как semver работает на практике при обновлении зависимостей.
В следующей статье мы детально поговорим про такую важную концепцию, как lock-файлы npm (shrinkwrap), и научимся пользоваться этими механизмами для повышения стабильности при работе с зависимостями. Увидимся через неделю, а пока подписывайтесь и следите за обновлениями!