Здравствуйте! Меня зовут Александр, я работаю
инженером-программистом микроконтроллеров.
Пишу на С/С++, причем предпочитаю плюсы, ибо верую в их
эволюционную неизбежность в embedded.
Мир встроенного ПО, язык С++ динамично развиваются, поэтому
разработчикам важно не отставать и поддерживать свои скиллы и
наработки актуальными моменту.
Я стараюсь следовать этому очевидному посылу, благо
небожители ведущие С++ программисты и консультанты щедро
делятся своим опытом и идеями на разных площадках (например
здесь, или здесь).
Некоторое время назад я посмотрел мощный доклад Сергея Федорова про
построение конечного автомата с таблицей переходов на шаблонах.
Если внезапно: "а что такое конечный автомат?"
Конечный автомат, или FSM(finite state maсhine) - один из самых
востребованных и популярных приемов в программировании на МК. В
свое время за кратким и практическим руководством по готовке FSM я
ходил заброшенные, земли.
Одна из идей доклада - определить состояния, эвенты и действия
через пользовательские типы, а таблицу переходов реализовать через
шаблонный параметр, меня очень
впечатлила
// Transition table definitionusing transitions = transition_table< /* State Event Next */ tr< initial, start, running >, tr< running, stop, terminated >>;};// State machine objectusing minimal = state_machine<transitions>;minimal fsm;//...and then callfsm.process_event(start{});fsm.process_event(stop{});
А если добавить к этому перенос части функциональности кода в
компайл тайм, заявленную автором потокобезопасность, улучшенные по
сравнению с Boost::MSM выразительность, читаемость кода и скорость
сборки, header only модель библиотеки, то - надо брать, решил я.
Вот только попытка собрать и запустить даже простейший пример на STM-ке закончилась
матерком компилятора: "cannot use 'typeid' with "-fno-rtti" и
"exception handling disabled".
Да, все так. Более того, помимо отключенной поддержки RTTI и
исключений, у меня также выставлены флаги -fno-cxa-atexit,
-fno-threadsafe-static. А еще в линкере применены настройки
--specs=nano.specs (используем урезанную версию стандартной
библиотеки с++ newlib-nano), --specs=nosys.specs (применяем
легковесные заглушки для системных вызовов).
Зачем же таскать на себе вериги?
Embedded разработчикам хорошо известны особенности и ограничения
при разработке встроенного ПО, а именно:
-
лимитированная память с недопустимостью фрагментации;
-
детерменированность времени выполнения;
-
штатно исполняющаяся программа никогда не выходит из main
С++ имеет в своем могучем арсенале средства и методы,
неосторожное использование которых может войти в критическое
противоречие с указанными выше условиями.
Как закружить в гармоничном танце С++ и bare metal отлично
разъяснено у этого автора. Также порекомендую
этот доклад.
Исходники проекта докладчика, включая зависимости, - это
двадцать файлов со смертоноснейшей шаблонной магией. Перекроить их
так, чтобы не юзать typeid и exceptions, простому смертному в моем
лице - too much.
Делать нечего, поступимся принципами, включим поддержку RTTI, а
вместо throw в исходниках автора проставим заглушки.
На этот раз все собралось. Вот только при использовании тулчейна
gcc-arm-none-eabi-9-2020-q2-update и
уровне оптимизации -O3, размер исполняемого файла превысил
200Кб.
Это несколько огорчительно, хотя какие могут быть претензии -
библиотека изначально разрабатывалась под "большого брата".
И хотя старшие камни, например у STM, имеют на борту флеш от
1Мб, отдавать почти четверть только под конечный автомат, пусть и
на закиси азота, как у докладчика, согласитесь, довольно
расточительно.
Итак, с наскоку взять высоту не удалось, и я на некоторое время
переключился на другие задачи. Но красота идеи меня не отпускала, и
на днях я все-таки решился "достучаться до небес" - написать extra
light embedded версию FSM из упомянутого доклада
самостоятельно.
Уточню свои хотелки:
-
Оперировать состояниями, эвентами и действиями как
пользовательскими типами.
-
Таблицу переходов реализовать в виде шаблонного параметра
-
Перетащить что возможно в компайл тайм
-
Асинхронно и атомарно постить эвенты
-
Переключать состояния за константное время
-
Выйти в итоге на приемлемый по меркам встроенного ПО размер
кода
-
Повторить header only модель библиотеки
Забегая вперед, скажу, что в итоге что-то получилось и даже
взлетело.
А вот как - не сочтите за труд, давайте посмотрим вместе. И не
сдерживайте себя в метании тухлых яиц, ибо лучшей питательной среды
для самосовершенстования трудно представить.
Первым делом опишем базовые сущности:
Состояние/State
struct StateBase{};template <base_t N, typename Action = void>struct State : StateBase{ static constexpr base_t idx = N; using action_t = Action; };
Здесь и далее base_t - платформозависимый тип, машинное
слово. В моем случае это unsigned int.
Состояния пусть будут двух типов - пассивное, в котором никаких
действий не происходит, и активное - при нахождении в котором будет
выполнятся переданный шаблонным параметром функтор,
action_t.
Цель статического члена idx уточню далее по тексту.
Событие/Event
struct EventBase{};template <base_t N>struct Event : EventBase{ static constexpr base_t idx = N;};
Элементарная структура, все ясно.
Действие при наступлении события и смене состояний:
Action
struct action{ void operator()(void){ // do something};
Безусловно, сигнатура operator() может и должна
варьироваться от задач приложения, пока же для упрощения
остановимся на самом легковесном варианте.
Сторож состояния:
Guard
enum class Guard : base_t{ OFF, CONDITION_1, CONDITION_2, //etc.};
Идея сторожа - допустить переход в новое состояние, только если
в данный момент выполнения программы текущее значение сторожа
соответствует заданному пользователем значению в типе
перехода/transition-a. Если такого соответствия нет, то переход в
новое состояние не происходит. Но тут возможны варианты. Например,
все же переходить, но не выполнять действие, переданное в
состояние. Up to you.
Итак, пока все тривиально. Идем дальше.
Переход:
Transition
struct TrBase{};template <typename Source, typename Event, typename Target, typename Action, Guard G, class = std::enable_if_t<std::is_base_of_v<StateBase, Source>&& std::is_base_of_v<EventBase, Event> && std::is_base_of_v<StateBase, Target>> > struct Tr : TrBase{ using source_t = Source; using event_t = Event; using target_t = Target; using action_t = Action; static constexpr Guard guard = G;};
Структура Tr тоже элементарна. Она параметризуется
типом исходного состояния - Source, типом события
Event, по наступлению которого произойдет переход в
целевое состояние Target, и типом Guard.
Также прояснилась причина наследования рассмотренных сущностей
от базового типа. Страхуем себя от передачи в шаблон некорректного
параметра через отлов ошибки на этапе компиляции.
Таблица переходов:
Transition table
struct TransitionTableBase{};template<typename... T>struct TransitionTable : TransitionTableBase{ using test_t = typename NoDuplicates<Collection<T...>>::Result; static_assert(std::is_same_v<test_t, Collection<T...>>, "Repeated transitions"); using transition_p = type_pack<T...>; using state_collection = typename NoDuplicates <Collection<typename T::source_t... ,typename T::target_t...> >::Result; using event_collection = typename NoDuplicates <Collection<typename T::event_t...> >::Result; using state_v = decltype(get_var(state_collection{})); using event_v = decltype(get_var(event_collection{})); using transition_v = std::variant<T...>;};
Нуу, тут я набросил на вентилятор, конечно. Хотя все не
настолько пугающе, как выглядит.
Структура TransitionTable параметризуется списком
переходов/transition-ов, которые собственно и описывают всю логику
конечного автомата.
Первым делом нам необходимо подстраховать себя от копипаста и
просигналить при компиляции, что у нас повторы в списке. Исполняем
это с помощью алгоритма NoDuplicates из всем известной библиотеки
Loki. Результирующий тип под
псевдонимом test_t сравниваем в static_assert-e с
исходным списком переходов.
Далее, допуская что static_assert пройден,
параметризуем некую структуру type_pack списком переходов и
выведенному типу назначаем псевдоним transition_p.
Структура type_pack, а также современные алгоритмы и методы по
работе со списками типов собраны в файле typelist.h. Данный хедер
написан под чутким руководством этого продвинутого парня.
Тип transition_p понадобится нам далее в конструкторе
класса StateMachine.
Следом проходим по списку переходов, вытаскиваем, очищаем от
повторов и сохраняем в отдельные коллекции состояния и эвенты. Эти
коллекции alias-им как state_collection и
event_collection соответственно.
К чему эта эквилибристика?
Нам необходимо как-то хранить и процессировать в ходе работы
программы информацию о событиях, эвентах, действиях и их
взаимодействии при переходах, выраженную в типах.
Удобным вариантом для этой цели является std::variant
(тафтология умышленна).
Последовательно параметризуем std::variant списком
переходов (выведенному типу назначим псевдоним
transition_v); списком состояний и списком эвентов и
назначаем для удобства псевдонимы state_v и
event_v соответственно.
Тут нюанс. Чтобы вывести transition_v нам достаточно
пробросить в шаблонный параметр std::variant variadic pack
(T...) из шаблонного параметра класса
TransitionTable.
А вот чтобы вывести state_v и event_v мы используем
вспомогательную constexpr функцию
template<typename... Types>constexpr auto get_var (th::Collection<Types...>){return std::variant<Types...>{};}
Далее мы инстанцируем получившиеся типы в конструкторе класса
StateMachine и сохраним их для дальнейшего использования в
подходящих контейнерах, о чем совсем скоро.
Оставшихся к этому моменту читателей я не обрадую - начинается
основной замес.
Целиком приводить класс StateMachine не буду, он
громоздок, прокомментирую его для удобства восприятия по
частям.
Контейнер transitions
template<typename Table>class StateMachine{//other stuffprivate:using map_type =std::unordered_map < Key, transition_v, KeyHash, KeyEqual>;Key key;map_type transitions;};
Основной контейнер, в котором мы храним информацию о переходах.
Unordered - потому что мы хотим константное время для переключения
между событиями. Память под контейнер выделяем стандартным
аллокатором из кучи, но делаем это единожды, на этапе
инициализации, до входа в основной цикл.
Объект типа Key хранит у себя значения индексов состояния и
эвента:
Key
struct Key{ base_t state_idx = 0; base_t event_idx = 0;};
Теперь стало понятно назначение статических членов idx
в базовых сущностях. Я просто не знаю, как писать хэшеры для пустых
структур. Тащить в строку название самого типа через
typeid и _cxa_demangle для нас не вариант, мы же
условились, что не пользуем RTTI.
Контейнер events
template<typename Table>class StateMachine{//other stuffprivate:using queue_type = RingBufferPO2 <EVENT_STACK_SIZE, event_v, Atomic>; queue_type events;};
events - очередь, в которую будут прилетать эвенты. Так
как это чисто рантаймовая история, необходимо избежать динамических
аллокаций. Поэтому реализуем ее на базе статического кольцевого
буффера RingBufferPO2, который я позаимствовал здесь (отличная для своего
времени работа!).
Помимо указанных контейнеров, в объекте типа
StateMachine мы будем хранить текущее состояние/state и
значение сторожа/guard:
state and guard
template<typename Table>class StateMachine{//other stuffprivate:state_v current_state;Guard guard = Guard::OFF;};
Саспенс уже не за горами.
Конструктор
template<typename Table>class StateMachine{public:using transition_pack = typename Table::transition_p;StateMachine(){ set(transition_pack{});} // other stuff};
В конструкторе метод set принимает аргументом объект с
информацией о списке переходов, пробегается по нему, достает инфо о
каждом состоянии и эвенте, заполняет контейнер
transitions, а также запоминает начальные состояние и
значение сторожа:
Метод set
template <class... Ts>void set (type_pack<Ts...>){(set_impl(just_type<Ts>{}), ...);};template <typename T>void set_impl (just_type<T> t){using transition = typename decltype(t)::type;using state_t = typename transition::source_t;using event_t = typename transition::event_t;Guard g = transition::guard;Key k;k.state_idx = state_t::idx;k.event_idx = event_t::idx;transitions.insert( {k, transition{}} );if (0 == key.state_idx) {key.state_idx = k.state_idx;guard = g;current_state = state_t{};}}
Итак, объект StateMachine сконструирован, пора его
как-то шевелить.
Но перед этим забудем как страшный сон суммируем что уже
рассмотрели к этому моменту:
-
Определили типы компонентов конечного автомата: состояние/state,
событие/event, действие/action, сторож/guard
-
Определили тип переход/transition, который должен
параметризоваться типами source state, event, target state,
guard.
-
Определили тип таблицы переходов. В качестве шаблонных
параметров ему передается список переходов/transition-ов, который и
определяет алгоритмы работы автомата.
-
При компиляции в классе TransitionTable, на основе
std::variant выводятся типы-коллекции переходов, состояний
и эвентов, которые впоследствии при конструировании объекта
StateMachine инстанцируются и сохраняются в контейнеры, с
которыми уже можно работать в рантайме.
Стержневая идея моей имплементации автомата такова (вдохнули):
при наступлении события, мы достаем из его типа индекс
(idx), объединяем его с индексом текущего состояния в
объекте Key, по которому в контейнере transitions
находим нужный нам переход, где получаем знания о целевом
состоянии, стороже и действии, которое требуется выполнить в этом
переходе, а также сверяем значения сторожа с текущим, для
подтверждения или отмены перехода/действия(выдохнули).
Теперь рассмотрим методы API нашего автомата, реализующие эту
логику.
Переключать состояния мы можем двумя способами: вызывать
немедленный переход методом fsm.on_event(event{})
(шаблонная версиия fsm.on_event<Event>() если тип
события известен на этапе проектирования), или можем
складывать события в очередь методом
fsm.push_event(event{}), чтобы потом, например в основном
цикле, разобрать ее методом fsm.process(). Также, если в
состояние передано какое-то действие, то мы можем вызывать его
методом fsm.state_action().
Рассмотрим их детальнее, начиная с последнего
Метод state action
template <typename... Args>void state_action (const Args&... args){state_v temp_v{current_state}; auto l = [&](const auto& arg){ using state_t = std::decay_t<decltype(arg)>; using functor_t = typename state_t::action_t; if constexpr (!std::is_same_v<functor_t, void>){ functor_t{}(args...); } }; std::visit(l, temp_v);}
В методе мы создаем локальную переменную типа
std::variant<State...> temp_v и инициализируем ее
текущим состоянием. Далее определяем лямбду, которая послужит
аргументом в методе std::visit.
"Нырнув" с ее помощью в variant, мы выведем тип текущего
состояния, из него в свою очередь вытащим тип переданного функтора,
инстанцируем его (проверив, если его тип не void) и вызовем с паком
аргументов, захваченных лямбдой по ссылке, и проброшенных с
головного вызова.
Знаю, что иногда лямбда может юзать кучу, но похоже, это не мой
случай. Поправьте меня, пожалуйста, если я заблуждаюсь. В этом
случае не сложно будет заменить лямбду на callable object.
Метод on_event
template <typename Event,class = std::enable_if_t<std::is_base_of_v<EventBase, Event>>>void on_event(const Event& e){Key k; k.event_idx = e.idx; k.state_idx = key.state_idx; on_event_impl(k);}void on_event_impl (Key& k){transition_v tr_var = transitions[k]; Key &ref_k = key; Guard &ref_g = guard; state_v &ref_state = current_state; auto l = [&](const auto& arg){ using tr_t = std::decay_t<decltype(arg)>; using functor_t = typename tr_t::action_t; if ( GuardEqual{}(ref_g, tr_t::guard) ){ using target_t = typename tr_t::target_t; ref_k.state_idx = target_t::idx; ref_state = target_t{}; functor_t{}(); } }; std::visit(l, tr_var);}
Здесь, как я уже описывал, мы достаем индекс из эвента,
объединяем его в Key с индексом текущего состояния, и в качестве
ключа передаем в приватный метод on_event_impl(Key&
k).
Там мы по принятому ключу достаем из контенера transitions
объект типа std::variant<Tr...> и инициализируем им
локальную переменную tr_var. Ну а далее - логика, схожая с
предыдущим примером. Вызываем std::visit c tr_var
и лямдой l, в которой из типа Tr получаем
сведения о состоянии, в которое нужно перейти (target_t),
стороже (tr_t::guard)и типе действия (functor_t)
к исполнению.
Сверив значение сторожа перехода с текущим сторожем, мы или
оcуществляем переход, инстанцируя и вызывая functor_t, и
сохраняя target_t в переменную с текущим
состоянием(current_state), или возвращаемся в исходное
состояние. Где ждем смены значения сторожа и нового события.
Метод push_event
template <unsigned int N>void push_event (const Event<N>& e){ events.push_back(e);}
Тут все просто.
Метод set_guard
void set_guard (const Guard& g){ guard = g;}
Вызываем, когда в программе сложились условия для перехода в
следующее состояние.
Метод process
void process (void){ state_action(); auto it = transitions.begin(); Key k; k.state_idx = key.state_idx; for (uint32_t i = 0; i != events.size(); ++i){ auto v = events.front(); auto l = [&](const auto& arg){ using event_t = std::decay_t<decltype(arg)>; k.event_idx = event_t::idx; it = transitions.find(k); } std::visit(l, v); if ( it != transitions.end() ){ events.pop_front(); on_event_impl(k); return; } else { events.push_back(v); events.pop_front(); } }}
При вызове метода мы первым делом выполняем некое полезное
действие (если не void), переданное в состояние,
state_action().
Ну а далее пробегаемся по очереди эвентов и просто воспроизводим
логику, уже описанную для метода
fsm.on_event(event{}).
Разумеется, работу с событиями можно значительно ускорить, при
этом расширив функционал автомата. Тип Event модернизируем
так
template <base_t N, base_t Priority>struct Event : EventBase{ static constexpr base_t idx = N; static constexpr base_t pri = Priority;};
Теперь мы можем не пушить все события в одну очередь, а завести,
скажем, std::array<queue_t, PRIRITY_NUM>, где
индексом ячейки будет служить приоритет события. Тогда у нас
получится приняв эвент, вытащить его приоритет, по нему, как по
индексу за константное время попасть в нужную очередь событий,
которая будет гораздо меньше, чем общая и быстрее в обработке.
И, что не менее важно, так мы сможем прыгать между состояниями
не по очередности принятых эвентов, но по их приоритету.
На самом деле в следующей версии своего FSM у меня так и
реализовано, но здесь я привожу упрощенный вариант.
Хорошо, каков же будет практический результат этой разнузданной
шаблонной вакханалии?
Детектор нейтрино(нет)
struct green_a {/*toogle green led every 50ms*/}struct yellow_a {/*toogle yellow led every 50ms*/}struct red_a {/*toogle red led every 50ms*/}struct green_f {/*toogle green led every 150ms*/}struct yellow_f {/*toogle yellow led every 150ms*/}struct red_f {/*toogle red led every 150ms*/}using STATE_A(green_s, green_f);using STATE_A(yellow_s, yellow_f);using STATE_A(red_s, red_f);using EVENT(green_e);using EVENT(yellow_e);using EVENT(red_e);using fsm_table = TransitionTable < Tr<green_s, yellow_e, yellow_s, yellow_a, Guard::NO_GUARD>, Tr<yellow_s, red_e, red_s, red_a, Guard::NO_GUARD>, Tr<red_s, green_e, green_s, green_a, Guard::NO_GUARD> >;int main(void){ //some other stuff StateMachine<fsm_table> fsm; fsm.push_event(red_e{}); fsm.push_event(yellow_e{}); fsm.push_event(green_e{}); while (1){ fsm.process(); }}
В этом примере структуры типа color_a(ction) - это
действия при переходе; color_f(unctor) - функторы, которые
будут выполняться каждый раз при заходе в стейт, ну и
далее понятно.
Объявляем стейты, эвенты, переходы, таблицу переходов.
Конструируем из класса StateMachine<fsm_table> наш конечный
автомат fsm. Пушим события, заходим в while и наблюдаем
аквасветодискотеку на нашей
отладке.
Обращу еще ваше внимание на макросы, через которые организована
декларация состояний и событий. Задача была исхитриться и не делать
так:
using even_t = Event<1, 15>;
using state_t = State<1, state_functor>;
Очевидно, почему это плохо. Ручная индексация - практически
неизбежные ошибки и очепятки.
Что ж, реализуем constexpr функцию, которая
будет преобразовывать переданное ей желаемое название типа в число,
которым и будем параметризовать шаблон. Ну и спрячем это все в
удобную обертку.
Как-то так
#define STATE_A(str, act) str = State<name(#str), act>#define EVENT(str) str = Event<name(#str)>constexpr base_t name (const char* n){ base_t res = 0; for (base_t i = 0; n[i] != '\0'; i++){ char data = n[i]; for (base_t j = sizeof (char) * 8; j > 0; j--){ res = ((res ^ data) & 1) ? (res >> 1) ^ 0x8C : (res >> 1); data >>= 1; } } return res;};
После крайнего проекта на работе у меня на руках осталась
отладка NUCLEO-H743ZI2, на ней я и запилил тестовый вариант
(забирайте здесь).
С оптимизацией -O3 реализация приведенного примера (только сам
FSM) заняла 6,8Кб, с HAL-ом и моргалками - 14,4Кб.
Конечно же, пока это не более чем эксперимент, проверка
концепции. Но агрегат завелся, черт его дери.
Будет очень здорово, если сообщество укажет на неизбежные факапы
и укажет путь к улучшениям. Также смею надеяться, что кто-то
выделит из материала и что-то полезное для себя.
Спасибо за внимание!

 Минимальный аниматор главного героя в платформере
Минимальный аниматор главного героя в платформере





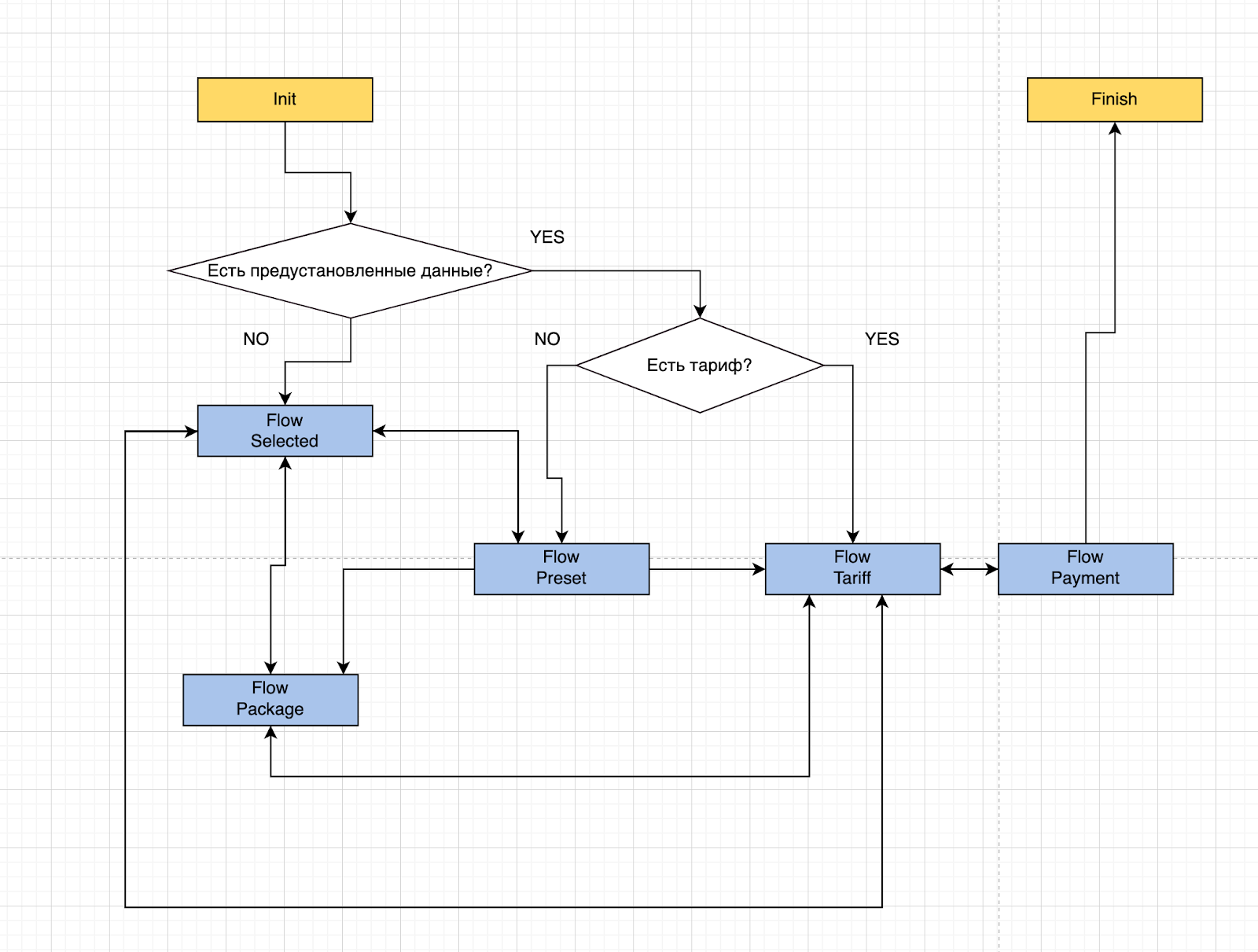




 Структурно-функциональная схема цифрового
конечного автомата
Структурно-функциональная схема цифрового
конечного автомата




 Схема
генетического алгоритма
Схема
генетического алгоритма
 Граф цифрового автомата, описывающий поведение пчелы
Граф цифрового автомата, описывающий поведение пчелы



