Привет, Хабр! Меня зовут Сергей Бевзенко, я ведущий разработчик
Delivery Club в команде Discovery. Наша команда занимается
навигацией пользователя по приложению Delivery Club: мы отвечаем за
основную выдачу ресторанов, поиск и всё, что с этим связано.
Я расскажу про Kafka Connect: что это такое, какова общая концепция
и как работать с этим фреймворком. Это будет полезно тем, кто
использует Kafka, но не знаком с Kafka Connect. Если у вас огромный
монолит и вы хотите перейти на событийную модель, но сталкиваетесь
со сложностью написания продюсеров, то вы тоже найдёте здесь ответы
на свои вопросы. В комментариях можем сравнить ваш опыт
использования Kafka Connect с нашим и обсудить любые вопросы,
которые с этим связаны.
План
1.
Предпосылки
2.
Как используется Kafka Connect
2.1.
Как запустить Kafka Connect
3.
Запуск коннекторов
4.
Настройка коннекторов
4.1.
Причины выбора коннекторов
4.2.
Jdbc и Debezium
4.3.
Debezium Connector
4.4.
JdbcSinkConnector
4.5.
Трансформеры
5.
Deploy
5.1.
Deploy Kafka Connect Delivery Club
6.
Что нам дало использование Kafka Connect
Предпосылки
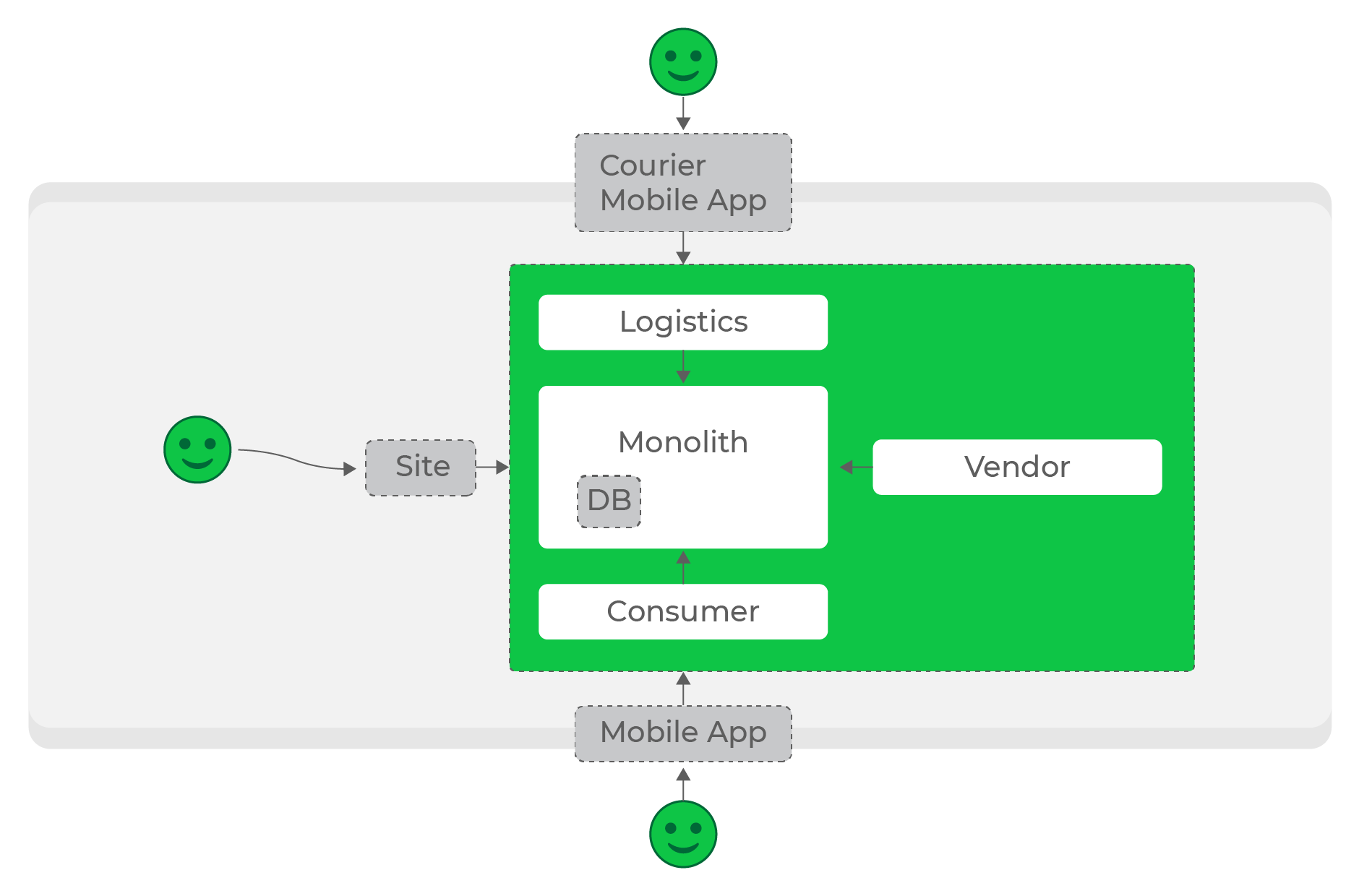
Delivery Club не молодая компания. Она основана в сентябре 2009
года. Мы постоянно развиваемся и улучшаем наши сервисы, без этого
рост невозможен.
У нас есть 10-летний Legacy-монолит. Он служит основой многих
процессов. Да, новые сервисы мы, конечно же, пишем. Делаем это на
Go, и иногда на PHP. Это два основных языка backend-разработки в
Delivery Club. Также мы переходим на событийную модель с
использованием шины событий: все изменения данных в системе это
события, попадающие в шину, и любой сервис может подписаться на
них.
Какие это события?
В компании есть множество интеграции с различными ресторанами,
магазинами, аптеками и т.д. Также у нас есть служба логистики,
которая работает с курьерами, их маршрутами, заказами,
распределением. Есть и отличный отдел R&D, который занимается
различными исследованиями и околонаучной разработкой. И, конечно,
есть другие отделы. У каждого направления множество сервисов, и все
они генерируют огромное количество событий. В качестве шины для них
мы используем Apache Kafka. Но десятилетний Legacy никуда не делся.
Внутри него множество админок, которые являются источниками данных.
Без крайней нужды трогать их не рекомендуется.
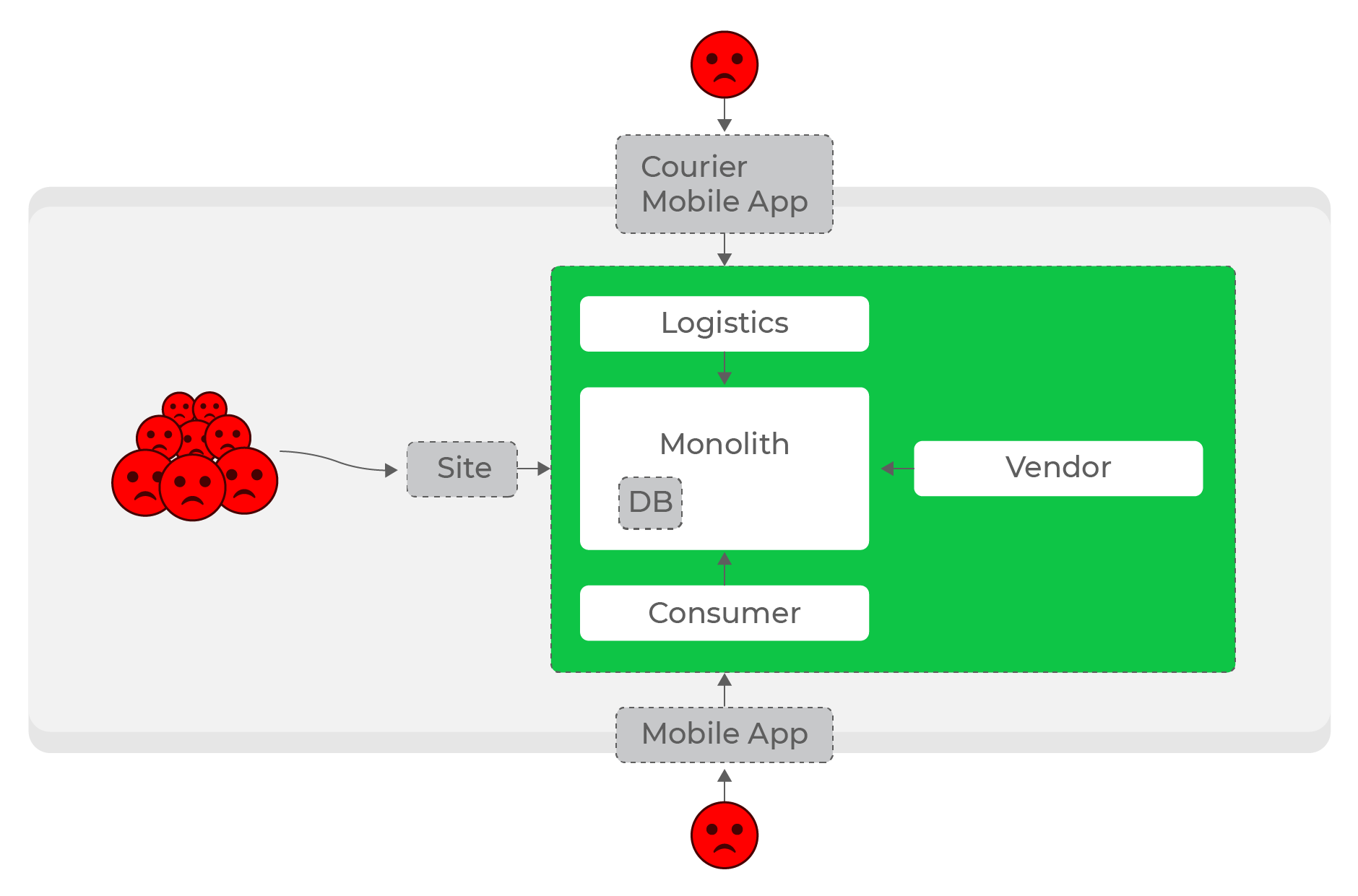
Сервис Каталог
Как один из этапов развития, перед нашей командой стояла задача
переписать основную выдачу приложения. За неё отвечал монолит, как
и за большую часть функциональности. И наступил момент, когда
вносить какие-либо изменения в эту функциональность стало
невероятно долго.
В нашем случае всё началось с небольшой задачи: отображать в
основной выдаче дополнительные ярлыки у ресторанов, в которых есть
какие-то акции. Решений было несколько, но большинство из них
сильно повышало нагрузку на базу и увеличивало время ответа. Но,
надо признаться, выдача и так была не особо быстрой.
Единственным оптимальным решением было написать на Go новый сервис,
который помог бы решить все проблемы, имевшиеся в монолите. К тому
же мы смогли сильно (в три раза) сократить время ответа.
Но наш монолит является мастером данных для основной выдачи, и
новый сервис должен иметь к ним доступ.
Как писать продюсеры в условиях 10-летнего Legacy
В самой первой версии Catalog MVP мы ходили в реплику монолита,
чтобы быстро запуститься (для нас важен Time to market). Но
оставлять так мы не хотели, поэтому нужно было денормализовать
данные из монолита. А для этого необходимо начать продьюсить
данные.
Есть несколько подходов:
- Переписать монолит. Тут вспоминаем все те статьи,
доклады и книги о том, как переписывать монолит. Это сложный и
долгий процесс. Он связан с большим количеством рисков. Конечно, мы
выносим функциональность из монолита, но делаем это постепенно,
аккуратно. Не в ущерб бизнесу.
- Писать свои продюсеры в монолите. Надо найти все места в
коде, где происходит изменения в базе. В этих местах добавлять
также отправку событий в шину. Если у вас хорошая архитектура
монолита, с выделенным слоем репозитория, то сделать это лишь
вопрос времени. Но Legacy не будет Legacy, если там всё хорошо с
архитектурой. Так что этот вариант тоже очень сложен и
трудозатратен.
- Использовать готовые решения для интеграции базы данных и
Kafka. Можно использовать фреймворк Kafka Connect.
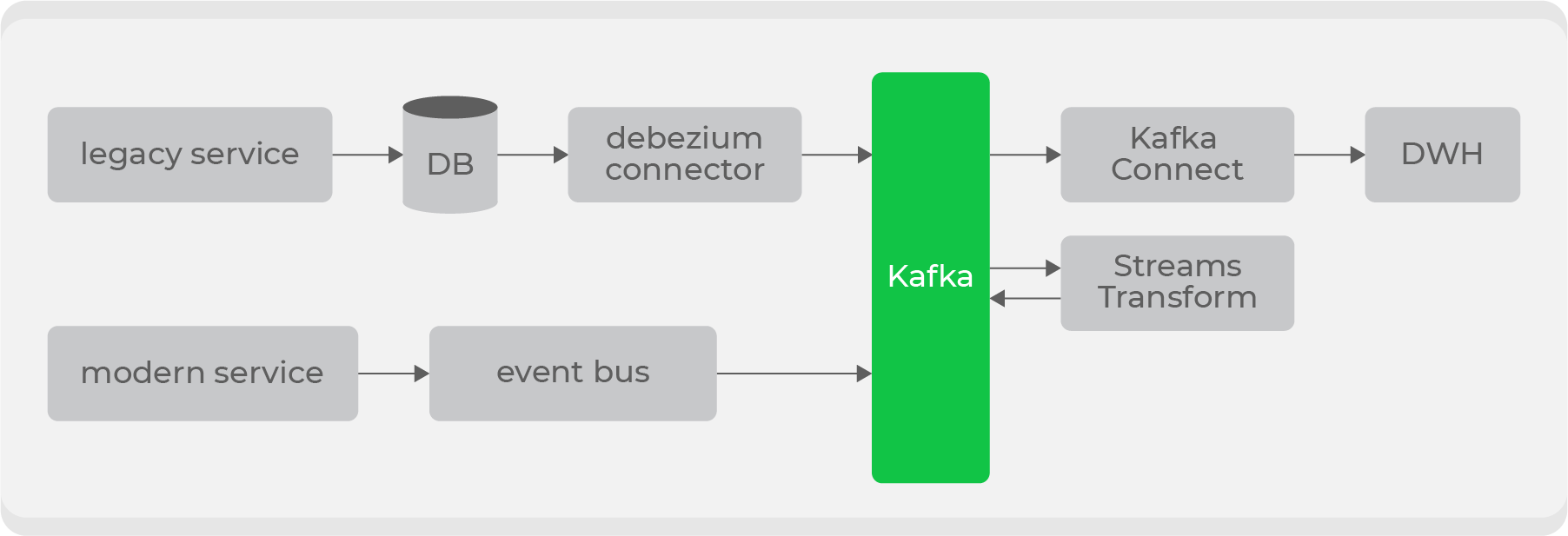
Kafka Connect
Как он используется
Чаще всего Kafka используют так:
Source => Kafka
Kafka => Kafka
Kafka => Storage
Kafka => App

То есть нам приходится писать собственные консьюмеры и продюсеры и
решать однообразные задачи при их разработке:
- Прописывать правила подключения к источникам.
- Обрабатывать ошибки.
- Прописывать правила ретраев.
Наиболее полно API Kafka поддерживается только в языках Java и
Scala. В других языках поддержка не всегда полная. Поэтому
разработчики Kafka предложили свои инструменты для решения таких
задач: фреймворки Kafka Connect и Kafka Streams:
Source => Kafka (connect)
Kafka => Kafka (streams)
Kafka => Storage (connect)
Kafka => App

Когда говорят, что Kafka Connect поставляется вместе с Kafka, это
не какая-то скрытая функциональность Kafka-брокеров. Это именно
отдельное приложение, которое имеет настройки подключения к Kafka и
источнику/приёмнику. Работу с Kafka Connect мы рассмотрим ниже.
Но сначала нужно ввести три важных термина:
- worker инстанс/сервер Kafka Connect;
- connector Java class + пользовательские настройки;
- task один процесс connector'a.
Worker экземпляр Kafka Connect. Kafka Connect можно
запускать в двух режимах: standalone и distributed, на нескольких
нодах или виртуальных машинах. То есть можно просто запустить один
worker или собрать кластер workerов. Рекомендуется использовать
standalone-режим при локальной разработке, настройке и отладке
коннекторов, а distributed в боевых условиях.
Преимущество distributed mode
Предположим, мы запустили четыре worker'а Kafka Connect и создали
три connector'а с разным количеством task'ов.
- Во-первых, Kafka Connect автоматически распределит таски
коннекторов по разным воркерам.
- Во-вторых, Kafka Connect отслеживает своё состояние в кластере.
Если обнаружит, что один из воркеров недоступен, выполнит
перебалансировку и перераспределит недоступные таски по работающим
воркерам.
Какие ещё задачи решает Kafka Connect:
- отказоустойчивость (fault tolerance);
- принцип только один раз (exactly once);
- распределение (distribution);
- упорядочивание (ordering).

Как я говорил выше, фреймворк используется для передачи данных из
источника в Kafka либо из Kafka в приёмник. В соответствии с этим
коннекторы делятся на два вида:
- Source Connectors;
- Sink Connectors.

Коннекторов уже очень много написано. Например, на сайте
confluent
их сейчас 163, а на просторах интернета ещё больше.
Вы можете написать свой коннектор на Java и Scala. Для этого нужно
создать подключаемый jar-файл, реализовав простой интерфейс
коннектора.
Как запустить Kafka Connect
Локально
Поставляется вместе с Kafka
Идём на сайт Kafka и скачиваем нужную нам версию:
http://kafka.apache.org/downloads.
Binary downloads:
Scala 2.12 - kafka_2.12-2.6.0.tgz (asc,
sha512)Scala 2.13 - kafka_2.13-2.6.0.tgz (asc,
sha512)
Например, выберем версию
Scala 2.12
(kafka_2.12-2.6.0.tgz). Распакуем архив и посмотрим в
директорию
kafka_2.12-2.6.0/bin. Там будут скрипты для
запуска Apache Kafka (
kafka-server-start.sh,
kafka-server-stop.sh) и утилиты для работы с ней. Например,
kafka-console-consumer.sh,
kafka-console-producer.sh. А также там будут скрипты
для запуска Kafka Connect (
connect-distributed.sh,
connect-standalone.sh), и многое другое.
Рекомендую зайти в директорию
kafka_2.12-2.6.0/config
там вы увидите настройки по умолчанию запуска и Kafka-брокера, и
Kafka Connect.
connect-distributed.propertiesconnect-standalone.properties
Вот так выглядит конфигурация по умолчанию
config/connect-distributed.properties:
bootstrap.servers=localhost:9092rest.port=8083group.id=connect-clusterkey.converter=org.apache.kafka.connect.json.JsonConvertervalue.converter=org.apache.kafka.connect.json.JsonConverterkey.converter.schemas.enable=truevalue.converter.schemas.enable=trueinternal.key.converter=org.apache.kafka.connect.json.JsonConverterinternal.value.converter=org.apache.kafka.connect.json.JsonConverterinternal.key.converter.schemas.enable=falseinternal.value.converter.schemas.enable=falseoffset.storage.topic=connect-offsetsconfig.storage.topic=connect-configsstatus.storage.topic=connect-statusoffset.flush.interval.ms=10000plugin.path=/opt/kafka/plugins
Kafka Connect можно запускать в режиме standalone. Это удобно для
локальной разработки и тестирования, но в боевых условиях
рекомендуется использовать connect-distributed (причины были
описаны выше).
Режим standalone чаще всего используется для локальной разработке и
тестирования.
Чтобы запустить Kafka Connect, выполните команду:
cd kafka_2.12-2.6.0bin/connect-standalone.sh config/connect-standalone.properties
Docker
Во многих Docker-образах используется этот же подход, поэтому вам
достаточно переопределить CMD в Dockerfile, чтобы получить образ с
Kafka Connect.
Например:
CMD ["bin/connect-distributed.sh", "cfg/connect-distributed.properties"]
Конечно, есть и готовые образы. Я рекомендую использовать варианты
от компании Confluent:
Запуск коннекторов
После того, как вы запустите Kafka Connect, вы можете запускать на
нём свои коннекторы.
Для управления Kafka Connect используется REST API. Полную
документацию по нему можно посмотреть на
сайте. Я опишу лишь те методы, которые нам понадобятся для
демонстрации работы Kafka Connect.
Запросим список классов коннекторов, которые добавлены в ваш Kafka
Connect:
curl -X GET "${KAFKA_CONNECT_HOST}/connector-plugins" -H "Content-Type: application/json"
В ответ мы получим нечто подобное:
HTTP/1.1 200 OK
[ { "class": "io.debezium.connector.mysql.MySqlConnector" }, { "class": "io.confluent.connect.jdbc.JdbcSinkConnector" }]
То есть вы можете создавать коннекторы только этих классов. Если
хотите добавить новый класс, нужно скачать jar этого коннектора и
добавить в директорию
plugin.path из настройки Kafka
Connect. См. файл
connect-distributed.properties.
Запросим список запущенных коннекторов:
curl -X GET "${KAFKA_CONNECT_HOST}/connectors" -H "Content-Type: application/json"
В ответ получим:
HTTP/1.1 200 OK
Content-Type: application/json ["my-source-debezium", "my-sink-jdbc"]
Видим, что у нас создано два коннектора с именами
my-source-debezium и
my-sink-jdbc.
Получение информации о запущенном коннекторе
Общая информация:
curl -X GET "${KAFKA_CONNECT_HOST}/connectors/my-sink-jdbc" -H "Content-Type: application/json"
Конфигурация запущенного коннектора (config):
curl -X GET "${KAFKA_CONNECT_HOST}/connectors/my-sink-jdbc/config" -H "Content-Type: application/json"
Состояние запущенного коннектора (status):
curl -X GET "${KAFKA_CONNECT_HOST}/connectors/my-sink-jdbc/status" -H "Content-Type: application/json"
Создание коннектора
Пример:
curl -X POST "${KAFKA_CONNECT_HOST}/connectors" -H "Content-Type: application/json" -d '{ \ "name": "my-new-connector", \ "config": { \ "connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector", \ "tasks.max": 1, "topics": "mysql-table01,mysql-table02", \ "connection.url": "jdbc:postgresql://postgres:5432/catalog", \ "connection.user": "postgres", \ "connection.password": "postgres", \ "auto.create": "true" \ } \ }'
То есть необходимо методом POST отправить конфигурацию
коннектора.
Обратите внимание, что имя коннектора должно быть уникальным в
вашем кластере Kafka Connect. Но вы можете создавать несколько
коннекторов одного класса с разными настройками.
Также у любого коннектора есть три обязательных параметра:
name уникальное имя;connector.class класс коннектора;tasks.max максимальное количество потоков, в
которых может работать коннектор.
Настройка коннекторов
Я хотел бы рассказать про настройку коннекторов на примере
DebeziumMysqlConnector и
JdbcSinkConnector. С этих классов мы в Delivery Club
начали работу. Но сначала я расскажу, почему вы выбрали именно
их.
Причины выбора коннекторов
Как я рассказывал, мы выносили функциональность из нашего монолита.
Сделали новый сервис Каталог, который отвечает за основную выдачу
ресторанов.
Но для этой функциональности были необходимы данные, мастером
которых был монолит. Эти данные ещё не отправлялись в шину
событий.
Для MVP Каталога решили использовать Shared Database. То есть наш
новый сервис обращался в базу монолита.

Таким образом мы сняли нагрузку с монолита, но нагрузка на старую
базу осталась. После создания MVP нужно закрыть технический долг и
отказаться от этого антипаттерна.

Две главные задачи, которые мы решали:
- переход на событийную модель (первый этап);
- разгрузка базы данных.
Jdbc и Debezium
Когда ищешь коннекторы для баз данных, первое, что находишь
JdbcSourceConnector и
JdbcSinkConnector.
Нам отлично подходит
JdbcSinkConnector в качестве
sink-коннектора. Он подписывается на топик Kafka и выполняет
запросы на добавление, изменение и удаление данных в базе.
Но в качестве Source-коннектора он нам не подходит, так как делает
SQL-запросы в базу по таймеру, а это создает ещё большую нагрузку
на базу-источник. Мы как раз хотим от этого уйти.
Но нам подходит
DebeziumMysqlConnector. Он делает одну
классную вещь: подключается к MySQL-кластеру как обычная
MySQL-реплика и умеет читать бинлог. Таким образом, мы не создаём
дополнительную нагрузку на базу (за исключением встроенных
механизмов MySQL-репликации).

Помимо этого, у Debezium-коннектора есть ещё одно преимущество
перед Jdbc. Так как Debezium отслеживает бинлог, он может
определять моменты удаления записей в базе данных. У Jdbc нет такой
возможности, так как он берёт текущее состояние базы и ничего не
знает о предыдущем состоянии.
Debezium Connector

Все настройки коннектора можно посмотреть на
сайте.
Давайте рассмотрим настройки коннектора и обсудим выбор некоторых
параметров.
Файл
debezium-config.json:
{ "name": "my-debezium-mysql-connector", "config": { "tasks.msx": 1, "connector.class": "io.debezium.connector.mysql.MySqlConnector", "database.hostname": "${MYSQL_HOST}", "database.serverTimezone": "Europe/Moscow", "database.port": "${MYSQL_PORT}", "database.user": "${MYSQL_USER}", "database.password": "${MYSQL_PASS}", "database.server.id": "223355", "database.server.name": "monolyth_db", "table.whitelist": "${MYSQL_DB}.table_name1", "database.history.kafka.bootstrap.servers": "${KAFKA_BROKER}", "database.history.kafka.topic": "monolyth_db.debezium.history", "database.history.skip.unparseable.ddl": true, "snapshot.mode": "initial", "time.precision.mode": "connect" }}
Подключения к базе данных:
"database.hostname": "${MYSQL_HOST}", "database.serverTimezone": "Europe/Moscow", "database.port": "${MYSQL_PORT}", "database.user": "${MYSQL_USER}", "database.password": "${MYSQL_PASS}",
Следует иметь в виду, что этот пользователь должен иметь права:
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'user' IDENTIFIED BY 'password';
ID реплики, под которым будет зарегистрирован коннектор, и его имя
сервера:
"database.server.id": "223355", "database.server.name": "monolyth_db",
Список таблиц для синхронизации:
"table.whitelist": "${MYSQL_DB}.table_name1,${MYSQL_DB}.table_name2",
Имена базы и таблицы необходимо указывать через запятую.
Настройки создания snapshot'а:
"database.history.kafka.bootstrap.servers": "${KAFKA_BROKER}", "database.history.kafka.topic": "debezium.db.history", "snapshot.mode": "initial",
Для чего нужен snapshot
Когда ваш коннектор
Debezium MySQL запускается в
первый раз, он выполняет начальный согласованный снимок вашей базы
данных и сохраняет его в топик Kafka. Даже если вы будете
отслеживать только несколько таблиц из базы, в
database.history будет записана вся схема. Но можно не
переживать из-за размера этого топика, он будет очень маленьким
(менее 1 Мб).
Пропуск определений в снимке, которые по каким-то причинам не
удалось распарсить:
"database.history.skip.unparseable.ddl": true,
Эту опцию мы включили, потому что сталкивались с такими ошибками,
когда определения в бинлоге использовали неверный синтаксис. Сервер
MySQL более-менее интерпретирует эти инструкции и потому не падает.
Но анализатор SQL-запросов в
DebeziumConnector'е с
ними не справляется и падает с ошибкой. Чтобы не падать, а
игнорировать нечитаемые запросы, необходимо включить эту опцию.
Точность типа данных time:
"time.precision.mode": "connect",
Эта настройка уменьшает точность типа данных time с микросекунд до
миллисекунд.
Описанную конфигурацию уже можно использовать для
production-окружения. А в документации есть полный перечень
настроек с подробным описанием.
Также нашу конфигурацию можно дополнить различными трансформерами
по преобразованию данных и маршрута топиков. И один из важнейших
трансформеров в проекте Debezium
io.debezium.transforms.ExtractNewRecordState. Почитать
подробнее о нём можно в
документации. Если кратко: вам потребуется его использовать для
преобразования формата Debezium в формат Jdbc.
В целом, все трансформации рекомендуется использовать на стороне
Sink-коннектора, а Source-коннекторы должны отправлять данные в
топик Kafka без изменений.
Создание Debezium MySqlConnector:
curl -X POST ${KAFKA_CONNECT_HOST}/connectors -H "Content-Type: application/json" -d @debezium-config.json
При создании коннектора вы можете получить ошибку:
Connector configuration is invalid and contains the following
1 error(s):
Configuration is not defined: database.history.connector.id
Configuration is not defined: database.history.connector.class
Unable to connect: Communications link failure
The last packet sent successfully to the server was 0
milliseconds ago. The driver has not received any packets from the
server.
You can also find the above list of errors at the endpoint
`/connector-plugins/{connectorType}/config/validate````
Эта ошибка говорит о том, что у вас указаны некорректные параметры
подключения к MySQL. Проверьте ваши логин/пароль, а также
убедитесь, что у пользователя есть права на репликацию (см.
выше).
После создания коннектора можно проверить его состояние. Этот метод
также используется в качестве метрики.
curl -X GET ${KAFKA_CONNECT_HOST}/connectors/my-debezium-mysql-connector/status
Мы увидим такой ответ:
{ "name": "my-debezium-mysql-connector", "connector": { "state": "RUNNING", "worker_id": "connect:8080" }, "tasks": [ { "id": 0, "state": "RUNNING", "worker_id": "connect:8080" } ], "type": "source"}
После того, как мы запустили source connector, можно убедиться, что
топики были созданы и можно прочитать из них данные. Для работы с
Kafka будем использовать удобную утилиту
kafkacat.
Какие топики были созданы нашим коннектором:
kafkacat -b ${KAFKA_BROKER} -L | grep 'monolyth_db'
Чтение данных из топика
monolyth_db.debezium.history:
kafkacat -b ${KAFKA_BROKER} -t monolyth_db.debezium.history -C -f 'Offset: %o\nKey: %k\nPayload: %s\n--\n'
Чтение данных из топика
monolyth_db.table_name1
(${MYSQL_DB} имя вашей базы данных):
kafkacat -b ${KAFKA_BROKER} -t monolyth_db.${MYSQL_DB}.table_name1 -C -f 'Offset: %o\nKey: %k\nPayload: %s\n--\n'
В топиках вы увидите сообщения в формате avro (если вы использовали
JsonSerializer для key, value серилизаторов). Вид и
описание формата лучше прочитать в
документации.
JdbcSinkConnector
В качестве Sink коннектора будем использовать
JdbcSinkConnector.

Рассмотрим его конфигурацию
Создадим файл
my-jdbc-sink-connector.json:
{ "name": "my-jdbc-sink-connector", "config": { "connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector", "tasks.max": "2", "connection.url": "jdbc:postgresql://${POSTGRES_HOST}:${POSTGRES_PORT}/${POSTGRES_DB}", "connection.user": "${POSTGRES_USER}", "connection.password": "${POSTGRES_PASS}", "topics": "monolyth_db.${MYSQL_DB}.table_name1,monolyth_db.${MYSQL_DB}.table_name2", "pk.fields": "id", "pk.mode": "record_key", "auto.create": "false", "auto.evolve": "false", "insert.mode": "upsert", "delete.enabled": "true", "transforms": "route,unwrap,rename_field,ts_updated_at,only_fields", "transforms.route.type": "org.apache.kafka.connect.transforms.RegexRouter", "transforms.route.regex": "([^.]+)\\.([^.]+)\\.([^.]+)", "transforms.route.replacement": "${PG_DB}.public.$3", "transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState", "transforms.unwrap.drop.tombstones": "false", "transforms.rename_field.type": "org.apache.kafka.connect.transforms.ReplaceField$Value", "transforms.rename_field.renames": "isDeleted:is_deleted,isActive:is_active", "transforms.ts_updated_at.type": "org.apache.kafka.connect.transforms.TimestampConverter$Value", "transforms.ts_updated_at.target.type": "Timestamp", "transforms.ts_updated_at.field": "updated_at", "transforms.ts_updated_at.format": "yyyy-MM-dd'T'HH:mm:ssXXX", "transforms.only_fields.type": "org.apache.kafka.connect.transforms.ReplaceField$Value", "transforms.only_fields.whitelist": "id,title,url_tag,sort,hide,created_at,updated_at" }}
Тут, конечно, три обязательных для любого коннектора параметра:
"name": "my-jdbc-sink-connector","connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector","tasks.max": "2",
Настройки подключения:
"connection.url": "jdbc:postgresql://${POSTGRES_HOST}:${POSTGRES_PORT}/${POSTGRES_DB}","connection.user": "${POSTGRES_USER}","connection.password": "${POSTGRES_PASS}",
Потом перечисление топиков, на которые будем подписываться:
"topics": "monolyth_db.${MYSQL_DB}.table_name1,monolyth_db.${MYSQL_DB}.table_name2",
JdbcConnector использует один топик для одной таблицы.
Сопоставление топика и таблицы происходит по имени. Для коррекции
используется route-трансформер. О трансформерах поговорим чуть
ниже.
Если вы указываете несколько топиков, то у них у всех должны быть
одинаковые
pk.fields.
Сообщения в Kafka имеют ключ, создаваемый на основании первичного
ключа (Primary Key) таблицы. Какой именно PR в таблице, необходимо
указать в параметрах
pk.fields, чаще всего это просто
id:
"pk.fields": "id","pk.mode": "record_key",
Ключ может быть составной. Например, для кросс-таблиц:
"pk.fields": "user_id,service_id",
Следующие параметры очень красноречивые. Мы отключаем
автоматическое создание и удаление таблиц, и разрешаем удалять
данные:
"auto.create": "false","auto.evolve": "false","insert.mode": "upsert","delete.enabled": "true",
Трансформеры
Последний блок настроек касается трансформеров.
"transforms": "route, unwrap, rename_field, ts_updated_at, only_fields",
Этот параметр указывает, какие трансформеры и в каком порядке
выполнять. Они расположены в этой же конфигурации коннектора.
Каждый трансформер имеет type (класс) и параметры.
Например, трансформер route отвечает за сопоставление имени топика
и имени таблицы:
"transforms.route.type": "org.apache.kafka.connect.transforms.RegexRouter","transforms.route.regex": "([^.]+)\\.([^.]+)\\.([^.]+)","transforms.route.replacement": "${PG_DB}.public.$3",
Он используется в Debezium MySqlConnector: отправляет данные в
Kafka топики с именами
{server_name}.{database_name}.{table_name}, а
JdbcSinkConnector принимает
{database_name}.{schema_name}.{table_name}. Так как
целевая база и таблица могут отличаться по именам (и у вас вряд ли
имя базы будет public), то этот коннектор изменяет целевое имя
топика.
Второй важный трансформер unwrap:
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState","transforms.unwrap.drop.tombstones": "false",
Он преобразует формат Debezium в формат, с которым прекрасно
работает JdbcSinkConnector.
Трансформеры
rename_field,
ts_updated_at
и
only_fields используются для переименования полей,
преобразования дат и указания списка тех полей, которые необходимо
синхронизировать. Так указывается конфигурация трансформера
ts_updated_at:
"transforms.ts_updated_at.type": "org.apache.kafka.connect.transforms.TimestampConverter$Value","transforms.ts_updated_at.target.type": "Timestamp", "transforms.ts_updated_at.field": "updated_at", "transforms.ts_updated_at.format": "yyyy-MM-dd'T'HH:mm:ssXXX",
Deploy
В каждой компании деплой происходит по-разному: где-то используют
Jenkins, где-то Gitlab CI или Bitbucket Pipelines, а кто-то пишет
скрипты.
С Kafka Connect вы будете деплоить точно так же, как и в случае с
другими сервисами в вашей компании.
Как я отмечал, Kafka Connect это отдельное stateless-приложение.
Оно не зависит от Kafka-брокера и даже от версии Kafka. Если у вас
уже есть Kafka старой версии, можно использовать новую версию Kafka
Connect. Я рекомендую это и сделать. Например, мы использовали
последнюю на тот момент версию Kafka Connect 2.5.0 с Kafka-брокером
0.10.х.
Поэтому нет каких-то общих советов и нюансов, как деплоить сервисы.
Расскажу, как это происходит у нас.
Deploy Kafka Connect в Delivery Club
Kubernetes
Перед запуском в стейдж мы экспериментировали локально. Создавали
свой Docker-образ на основе cp-kafka-connect, куда просто добавляли
свои коннекторы.
Для стейджа было достаточно из этого образа собрать контейнер и
выложить в Kubernetes, что мы и сделали.
Отмечу только, что 2 Гб памяти поду под Kafka Connect не хватает, и
у нас поды по 4 Гб.
Production
На проде у нас внедрение совпало с внедрением нового кластера
Kafka-брокеров. Мы приняли специфическое решение поднимать Kafka
Connect на тех же серверах, где будут находиться Kafka-брокеры. Для
этого использовали rpm-пакет от Confluent.
Сами настройки конфигов мы храним в репозитории. У нас есть
несколько скриптов, которые позволяют управлять коннекторами:
создавать, останавливать, перезапускать их.
Но это уже отдельная история как работать с Kafka Connect в проде,
которая зависит от инфраструктуры компании.
Что нам дало использование Kafka Connect
Мы не стали писать множество продьюсеров в монолите для более чем
600 таблиц. По приблизительным подсчётам, это сэкономило нам более
месяца работы пары разработчиков. И, конечно же, снизило
возможность наделать множество ошибок в монолите. То есть мы
избавились от потенциальных падений приложения.
Это позволило написать новый сервис выдачи ресторанов силами одной
команды за один месяц.
Другие команды в компании тоже пользуются нашими топиками. Оценить
выгоду очень сложно, но точно ясно: это позволило нам разрабатывать
новую функциональность, не завязываясь на данные, источником
которых является только монолит.
Мы сняли нагрузку с самой нагруженной нашей части база данных
монолита. Это примерно 150 RPS запросов к базе. И синхронизируем
более 40 таблиц со скоростью 300 RPS.
Также мы разделил ответственность сервисов, что является первым
шагов к разделению доменной области.
Резюме
Я очень рад, что вам удалось добраться до конца. В этой статье
вы:
- познакомились с общими принципами работы с Kafka Connect;
- узнали, как запустить приложение Kafka Connect в разных
режимах;
- разобрались, как запускать и настраивать коннекторы для работы
с базой и Kafka.
И я рад, что вас не испугал внушительный размер статьи, и
рассчитываю, что вы будете обращать к ней в качестве примера работы
с Kafka Connect и краткого справочника.





 Мария:
Мария:










 время, которое будет затрачено на
отрисовку всех зон доставки партнера,
время, которое будет затрачено на
отрисовку всех зон доставки партнера, количество ресторанов,
количество ресторанов, время на отрисовку одной зоны.
время на отрисовку одной зоны.








 функция ошибки
минимизации времени доставки с фиксированным покрытием,
функция ошибки
минимизации времени доставки с фиксированным покрытием, время от ресторана i до
клиента,
время от ресторана i до
клиента, количество клиентов в зоне
доставки.
количество клиентов в зоне
доставки.



 Низкие нагрузки, синхронные запросы, всё работает круто.
Низкие нагрузки, синхронные запросы, всё работает круто.