
Тема конвейеризации и распараллеливания машинного обучения давно фигурирует у нас в проработке. В частности, интересно, достаточно ли для этого специализированной книги с акцентом на Python, либо нужна более обзорная и, возможно, сложная литература. Мы решили перевести вводную статью об устройстве конвейеров для машинного обучения, содержащую как архитектурные, так и более прикладные соображения. Давайте обсудим, актуальны ли поиски в этом направлении.
Вы когда-нибудь писали конвейер машинного обучения, на прогон которого требовалось много времени? Или хуже того: доходили ли до этапа, когда требуется сохранить на диске промежуточные части конвейера, чтобы можно было изучить этапы конвейера по одному, опираясь на контрольные точки? Или еще хуже: вы когда-нибудь пытались рефакторить такой отвратительный код для машинного обучения перед пуском этого кода в продакшен и обнаруживали, что на это нужны месяцы? Да, с подобным приходилось сталкиваться каждому, кто достаточно долго работал над конвейерами машинного обучения. Так почему бы не построить хороший конвейер, который обеспечит нам достаточную гибкость и возможность легко рефакторить код для последующей отправки в продакшен?
Сначала давайте дадим определение конвейерам машинного обучения и обсудим идею использования контрольных точек между этапами конвейера. Затем посмотрим, как можно реализовать такие контрольные точки, чтобы не выстрелить себе в ногу при переводе конвейера в продакшен. Мы также обсудим потоковую передачу данных и компромиссы, связанные с инкапсуляцией в духе объектно-ориентированного программирования (ООП), на которые приходится идти в конвейерах при указании гиперпараметров.
ЧТО ТАКОЕ КОНВЕЙЕР?
Конвейер это последовательность шагов при преобразовании данных. Он создается в соответствии со старинным паттерном проектирования канал и фильтр (вспомните, например, команды unix bash с каналами | или операторами редиректа >). Однако конвейеры это объекты в коде. Следовательно, у вас может быть класс для каждого фильтра (то есть, для каждого этапа конвейера), а также еще один класс для комбинации всех этих этапов в готовый конвейер. Некоторые конвейеры могут объединять другие конвейеры последовательно или параллельно, иметь много входов или выходов и т.д. Конвейеры машинного обучения удобно рассматривать как:
- Канал и фильтры. На этапах конвейера обрабатываются данные, причем, этапы управляют своим внутренним состоянием, которое можно узнать из данных.
- Компоновка. Конвейеры можно вкладывать друг в друга; например, целый конвейер можно трактовать как один этап в рамках другого конвейера. Эта конвейера не обязательно является конвейером, но конвейер как таковой по определению не менее чем этап конвейера.
-
Ориентированные ациклические графы (DAG). Вывод этапа конвейера
может направляться множеству других этапов, после чего
результирующие выводы могут рекомбинироваться и так далее. Отметим:
несмотря на то, что конвейеры ацикличны, они могут обрабатывать
множество элементов один за другим, и, если их состояние меняется
(например, при использовании метода
fit_transformна каждом этапе), то их можно считать рекуррентно разворачивающимися во времени, сохраняющими при этом свои состояния (по образцу RNN).Это интересный ракурс, позволяющий рассматривать конвейеры как средство для онлайнового машинного обучения, после чего конвейеры можно переводить в продакшен и обучать на более обширных данных.
Методы конвейера
Конвейеры (или этапы конвейера) обязательно должны обладать следующими двумя методами:
- fit для обучения на данных и приобретения состояния (напр., таким состоянием являются веса нейронной сети)
- transform (или predict) для фактической обработки данных и генерации прогноза.
- Примечание: если этапу конвейера не требуется один из этих методов, то этап может унаследовать от NonFittableMixin или NonTransformableMixin, где будет по умолчанию предоставляться такая реализация одного из этих методов, чтобы он ничего не дела.
На этапах конвейера также могут опционально определяться следующие методы:
- fit_transform для подгонки и последующего преобразования данных, но в один проход, что допускает потенциальную оптимизацию кода в случаях, когда два метода должны выполняться непосредственно один после другого.
- setup который будет вызывать метод setup на каждом из таких этапов конвейера. Например, если на этапе конвейера содержится нейронная сеть TensorFlow, PyTorch или Keras, то на этих этапах могли бы создаваться собственные нейронные графы и регистрироваться для работы с GPU в методе setup до подгонки. Не рекомендуется создавать графы прямо в конструкторах этапов до подгонки; на то есть несколько причин. Например, до запуска этапы могут многократно копироваться с разными гиперпапарметрами в рамках работы алгоритма Automatic Machine Learning, который подыскивает для вас наилучшие гиперпараметры.
- teardown, этот метод функционально противоположен setup: он сносит ресурсы.
Следующие методы предоставляются по умолчанию, обеспечивая управление гиперпараметрами:
-
get_hyperparams возвращает словарь гиперпараметров. Если
конвейер содержит другие (вложенные) конвейеры, то ключи
гиперпараметров сцепляются при помощи двойных нижних подчеркиваний
__. - set_hyperparams позволяет задавать новые гиперпараметры в том же формате, в каком вы их получаете.
-
get_hyperparams_space позволяет вам получить пространство
гиперпараметра, которое будет непустым, если вы определили
гиперпараметр. Поэтому, все отличие от
get_hyperparamsв данном случае таково, что вы получаете в качестве значений статистические распределения, а не точное значение. Например, один гиперпараметр, для количества слоев, может бытьRandInt(1, 3)то есть, предусматривать от 1 до 3 слоев. Можно вызватьcall .rvs()с этим словарем, чтобы случайным образом выбрать значение и отправить его кset_hyperparams, попытавшись таким образом организовать обучение. -
set_hyperparams_space может использоваться для задания нового
пространства при помощи тех же классов для распределения
гиперпараметров, что и в случае с
get_hyperparams_space.
Переподгонка конвейера, мини-батчинг и онлайновое обучение
Для алгоритмов, использующих мини-батчинг, например, при обучении глубоких нейронных сетей (DNN) или для алгоритмов, обучающихся онлайн, например, при обучении с подкреплением (RL), для конвейеров или их этапов идеально подходит сцепление нескольких вызовов так, чтобы они следовали точно друг за другом, и на лету происходила их подгонка под размеры мини-батчей. Такая возможность поддерживается в некоторых конвейерах и на некоторых этапах конвейеров, но на определенном этапе достигнутая подгонка может сброситься из-за того, что метод fit будет вызван заново. Все зависит от того, как вы запрограммировали ваш этап конвейера. В идеале этап конвейера должен сбрасываться только после вызова метода teardown, а затем повторного вызова метода
setup до следующей подгонки,
и данные не сбрасывались ни между подгонками, ни в процессе
преобразования.ИСПОЛЬЗОВАНИЕ КОНТРОЛЬНХ ТОЧЕК В КОНВЕЙЕРАХ
Целесообразно использовать в конвейерах контрольные точки до тех пор, пока этот код не понадобится использовать для других целей и изменить данные. Если вы не применяете в коде нужных абстракций, то, возможно, стреляете себе в ногу.
За и против использования контрольных точек в конвейерах:
- Расстановка контрольных точек может ускорить процесс работы, если этапы программирования и отладки расположены в середине или в конце конвейера. Так отпадает необходимость каждый раз заново вычислять первые этапы конвейера.
- При выполнении оптимизации гиперпараметров (либо путем настройки вручную, либо с использованием метаобучения), вы будете только рады обойтись без пересчета первых этапов конвейера, пока занимаетесь настройкой следующих. Например, если начало вашего конвейера не содержит гиперпараметров, то оно всякий раз может быть одинаковым или почти одинаковым если гиперпараметров всего несколько. Следовательно, при работе с контрольными точками целесообразно возобновлять работу именно с тех мест, где они расставлены, если гиперпараметры и исходный код этапа, предшествующего контрольной точке, не изменились с момента последнего выполнения.
- Возможно, вы располагаете ограниченными вычислительными ресурсами, и единственный приемлемый вариант для вас прогонять по одному этапу за раз на имеющемся аппаратном обеспечении. Можно использовать контрольную точку, затем добавить после нее еще несколько этапов, а потом данные будут использоваться с того места, на котором вы остановились, если вы захотите повторно выполнить всю структуру.
Недостатки использования контрольных точек в конвейерах:
- При этом используются диски, поэтому, если действовать неправильно, то выполнение вашего кода может замедляться. Чтобы ускорить работу, можно, как минимум, воспользоваться RAM Disk или монтировать папку кэша к вашей RAM.
- Для этого может потребоваться много дискового пространства. Либо много пространства RAM, при использовании каталога, монтированного к RAM.
- Состоянием, сохраненным на диске, управлять тяжелее: для вашей программы возникает дополнительная сложность, нужная, чтобы код работал быстрее. Обратите внимание, что, с точки зрения функционального программирования, ваши функции и код больше не будут чистыми, поскольку необходимо управлять побочными эффектами, связанными с использованием дисков. Побочные эффекты, связанные с управлением состоянием диска (вашим кэшем) могут становиться почвой для возникновения всевозможных страннейших багов
Известно, что одни из самых сложных багов в программировании возникают из-за проблем, связанных с инвалидацией кэша.
В Computer Science есть всего две по-настоящему сложные вещи: инвалидация кэша и именование сущностей. Фил Карлтон
Совет о том, как правильно управлять состоянием и кэшем в конвейерах.
Известно, что фреймворки для программирования и паттерны проектирования могут выступать ограничивающим фактором по той простой причине, что регламентируют определенные правила. Остается надеяться, что это делается ради максимального упрощения задач по управлению кодом, чтобы вы сами избегали ошибок, а ваш код не получался грязным. Вот мои пять копеек по поводу проектирования в контексте конвейеров и управления состоянием:
ЭТАП КОНВЕЙЕРА НЕ ДОЛЖН УПРАВЛЯТЬ РАССТАНОВКОЙ КОНТРОЛЬНХ ТОЧЕК В ТЕХ ДАННХ, КОТОРЕ ВДАЮТ
Для управления этим должна применяться специальная библиотека конвейеризации, которая сможет все это сделать за вас сама.
Почему?
Почему же этапы конвейера не должны управлять расстановкой контрольных точек в тех данных, которые выдают? По тем же веским причинам, по которым вы пользуетесь при работе библиотекой или фреймворком, а не воспроизводите соответствующий функционал самостоятельно:
- У вас будет простой выключатель, который позволит с легкостью полностью активировать или отменить расстановку контрольных точек перед развертыванием сделанного в продакшен.
- Когда требуется переучить систему на новых данных, окажется, что управление кэшированием поставлено настолько хорошо, что система сама заметит: ваши данные изменились и, следовательно, имеющийся кэш следует игнорировать. Вашего вмешательства при этом совершенно не потребуется, что позволит не допустить возникновения серьезных багов.
- Вам не придется самостоятельно иметь дело с дисками и писать операции ввода/вывода (I/O) на каждом этапе конвейера. Большинство программистов предпочитают пользоваться алгоритмами машинного обучения и строить конвейеры, а не заниматься созданием методов сериализации данных. Будем честны: вы же хотите просто запрограммировать готовенькие алгоритмы, а все остальное чтобы было сделано за вас. Верно?
- Теперь вы можете придумывать названия для каждого из ваших конвейерных экспериментов или каждой итерации, так, чтобы при каждом рестарте в кэше создавался новый подкаталог строго на данный случай даже если вы собираетесь переиспользовать одни и те же этапы конвейера. Причем, именовать этапы экспериментов даже не требуется, поскольку с изменением данных меняется и кэширование.
- Внутренний код классов, описывающих этапы вашего конвейера, хэшируется, после чего хэши сравниваются, чтобы посмотреть, нужно ли заново выполнить кэширование для того класса, в котором вы только что изменили код. Именно так избегаются баги, связанные с инвалидацией кэша. Ура.
- Теперь вы можете хэшировать промежуточные результаты обработки данных и пропускать этап вычисления конвейера на этих данных, если гиперпраметры не изменились, а ваш конвейер уже преобразовал (и, следовательно, хэшировал) данные ранее. Это может упростить тонкую настройку гиперпараметров в случаях, когда некоторые этапы конвейера (в том числе, промежуточные) могут меняться. Например, первые этапы конвейера могут оставаться кэшированными, поскольку изменения их не затрагивают, а, если у вас появятся дополнительные гиперпараметры, которые потребуется настроить на дальнейших этапах конвейера, то вы всегда сможете добавить нужное количество контрольных точек после этих этапов. Тогда полученные в результате многократного кэширования этапы сохраняются с уникальным именем, вычисленным на основе хэша. Можете считать такую систему блокчейном, так как это и есть блокчейн.
Это круто. Грамотно подбирая абстракции, вы теперь можете запрограммировать конвейеры для машинного обучения так, чтобы этап настройки гиперпараметров радикально ускорился; для этого нужно кэшировать промежуточный результат каждого испытания, пропуская этапы конвейера раз за разом, когда гиперпараметры промежуточных этапов конвейера остаются без изменений. Более того, когда вы будете готовы вывести код в продакшен, вы сможете сразу целиком отключить кэширование, а не рефакторить для этого код на протяжении целого месяца.
Не врезайтесь в эту стену.
ПОТОКОВАЯ ПЕРЕДАЧА ДАННХ В КОНВЕЙЕРАХ ДЛЯ МАШИННОГО ОБУЧЕНИЯ
Теория параллельной обработки гласит, что конвейеры это инструмент потоковой передачи данных, позволяющий распараллеливать этапы конвейера. Пример с прачечной хорошо иллюстрирует как эту проблему, так и ее решение. Например, на втором этапе конвейера может приступить к обработке частичной информации, полученной с первого этапа конвейера, в то время как первый этап продолжает вычислять новые данные. Причем, для работы второго этапа конвейера не требуется, чтобы первый этап полностью завершил свой этап обработки всех данных. Давайте назовем такие особые конвейеры потоковыми (см. здесь и здесь).
Не поймите меня неправильно, работать с конвейерами scikit-learn очень приятно. Но они не рассчитаны на потоковую передачу. Не только scikit-learn, но и большинство существующих конвейерных библиотек не используют возможностей потоковой передачи данных, тогда как могли бы. В масштабах всей экосистемы Python есть проблемы с многопоточностью. В большинстве конвейерных библиотек каждый этап является полностью блокирующим и требует преобразования всех данных сразу. Найдутся лишь считанные библиотеки, обеспечивающие потоковую обработку.
Активировать потоковую обработку может быть совсем просто: использовать класс
StreamingPipeline вместо
Pipeline для сцепления этапов одного за другим. При
этом указывается размер мини-батча и размер очереди (во избежание
чрезмерного потребления RAM, так обеспечивается более стабильная
работа в продакшене). В идеале такая структура также потребовала бы
многопоточных очередей с
семафорами, как это описано в задаче поставщика и потребителя:
чтобы организовать передачу информации от одного этапа конвейера к
другому.В нашей компании Neuraxle уже удается делать одну вещь лучше, чем она реализована в scikit-learn: речь идет о последовательных конвейерах, которыми можно пользоваться при помощи класса MiniBatchSequentialPipeline. Пока эта штука не многопоточная (но это в планах). Как минимум, она уже передает данные в конвейер в виде мини-батчей в процессе подгонки или преобразования, до сбора результатов, что позволяет работать с большими конвейерами точно как в scikit-learn, но на этот раз с применением мини-батчинга, а также с многочисленными другими возможностями, среди которых: пространства гиперпараметров, установочные методы, автоматическое машинное обучение и так далее.
Наше решение параллельной потоковой обработки данных на Python
- Метод подгонки и/или преобразования можно вызывать много раз подряд, чтобы улучшить подгонку при помощи новых мини-батчей.
- Многопоточные очереди внутри конвейера используются так, как в проблеме поставщика-потребителя. Между любыми двумя этапами конвейера, передаваемыми по потоковому принципу, нужна одна очередь.
- Можно обеспечить параллельную репликацию этапов конвейера, чтобы на каждом этапе параллельно преобразовывать множество элементов. Это можно делать до того, как по всему конвейеру будут вызваны методы setup. В противном случае конвейер необходимо сериализовать, клонировать и перезагрузить с использованием механизмов, сохраняющих этапы. Код, использующий TensorFlow, и иной импортированный код, написанный на других языках, например, на C++, сложно распределить на потоки в Python, особенно если он использует память GPU. Даже joblib не так легко справляется с некоторыми из таких проблем. Поэтому благоразумно избегать подобных проблем при помощи грамотной сериализации.
- Параметр конвейера может быть важен, а может быть и не важен для поддержания данных в правильном порядке перед отправкой их на следующий этап. По умолчанию он важен, а если нет то конвейер может продолжать обработку данных в произвольном порядке, по мере поступления, причем, так и бывает, если на разные этапы требуется разное количество времени.
- Будет можно использовать барьерные объекты между этапами конвейера. Они будут представлять собой не настоящие этапы, а указания конвейеру, как обращаться с данными между этапами; например, должны или нет данные сохранять определенный порядок в заданных ключевых местах. Например, можно использовать барьеры, предусматривающие соблюдение порядка, не предусматривающие соблюдения порядка, либо дожидающиеся всех данных блокирующие барьеры (мы назвали такой барьер Joiner). Эти барьеры добавляют информацию о том, как обрабатывать данные между этапами или группами этапов. Например, на конкретном этапе я могу задавать или переопределять длину очереди и указывать, сколько раз нужно параллельно прогнать этап конвейера, как распараллелить этот этап.
Более того, мы хотим обеспечить возможность разделения между потоками любого объекта в Python: так он будет поддаваться сериализации и перезагрузке. В таком случае код можно будет динамически отправлять на обработку на любом воркере (это может быть другой компьютер или процесс), даже если сам нужный код на этом воркере отсутствует. Это делается при помощи цепочки сериализаторов, специфичных для каждого класса, воплощающего этап конвейера. По умолчанию на каждом из этих этапов есть сериализатор, позволяющий обрабатывать обычный код на Python, а для более заковыристого кода применять GPU и импортировать код на других языках. Модели просто сериализуются при помощи своих сейверов, а затем заново загружаются в воркер. Если воркер локальный, то объекты могут быть сериализованы на диск, расположенный в RAM, или в каталог, монтированный в RAM.
КОМПРОМИСС ПРИ ИНКАПСУЛЯЦИИ
Остается еще одна досадная вещь, присущая большинству библиотек для конвейерного машинного обучения. Речь о том, как обрабатываются гиперпараметры. Возьмем для примера scikit-learn. Пространства гиперпараметров (они же статистические распределения значений гиперпараметров) часто должны указываться вне конвейера с нижними подчеркиваниями в качестве разделительных знаков между этапами конвейера (конвейеров). Тогда как Случайный Поиск и Поиск по сетке позволяют исследовать сетки гиперпараметров или пространства вероятностей гиперпараметров, как это определяется в дистрибутивах scipy, сама scikit-learn не предоставляет пространства гиперпараметров по умолчанию для каждого классификатора и преобразователя. Ответственность за выполнение этих функций можно возложить на каждый из объектов конвейера. Таким образом, объект будет самодостаточен и будет содержать собственные гиперпараметры. Так не нарушается принцип единственной ответственности, принцип открытости/закрытоcти и принципы SOLID объектно-ориентированного программирования.
СОВМЕСТИМОСТЬ И ИНТЕГРАЦИЯ
Программируя конвейеры для машинного обучения, полезно держать в уме, что они должны сохранять совместимость со множеством других инструментов, в частности, scikit-learn, TensorFlow, Keras, PyTorch и многими другими библиотеками машинного и глубокого обучения.
Например, мы написали метод
.tosklearn() позволяющий
превращать этапы конвейера или целый конвейер в
BaseEstimator базовый объект библиотеки scikit-learn.
Что касается других библиотек машинного обучения, задача сводится к
написанию нового класса, который наследует от нашего
BaseStep и к переопределению в конкретном коде
операций подгонки и преобразования, а также, возможно, установки и
сноса. Также нужно определить сейвер, который будет сохранять и
загружать вашу модель. Вот
документация по классу BaseStep и примеры к
ней.ЗАКЛЮЧЕНИЕ
Резюмируя, отметим, что код конвейеров машинного обучения, готовый к выходу в продакшен, должен соответствовать множеству критериев качества, которые вполне достижимы, если придерживаться нужных паттернов проектирования и хорошо структурировать код. Отметим следующее:
- В коде для машинного обучения целесообразно использовать конвейеры, и каждый этап конвейера определять как экземпляр класса.
- Затем вся такая структура может быть оптимизирована при помощи контрольных точек, помогающих найти наилучшие гиперпараметры и многократно выполнять код над одними и теми же данными (но, возможно, с разными гиперпараметрами или с измененным исходным кодом).
- Также целесообразно выполнять подгонку и преобразование данных последовательно, чтобы не раздувать RAM. Затем всю такую структуру можно распараллелить, когда переключаешься с последовательного конвейера на потоковый.
- Наконец, можно программировать собственные этапы конвейеров для
этого достаточно наследовать от класса
BaseStep, показанного в этой статье, и реализовать нужные вам методы.

 Пример работы нейронной сети ARShadowGAN-like
Пример работы нейронной сети ARShadowGAN-like
 Схема генератора
Схема генератора
 Полная схема обучения ARShadowGAN-like
Полная схема обучения ARShadowGAN-like
 Пример Style Transfer
Пример Style Transfer
 Пример Shadow-AR датасета.
Пример Shadow-AR датасета.





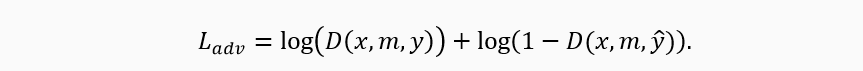
 Визуализация процесса обучения
Визуализация процесса обучения
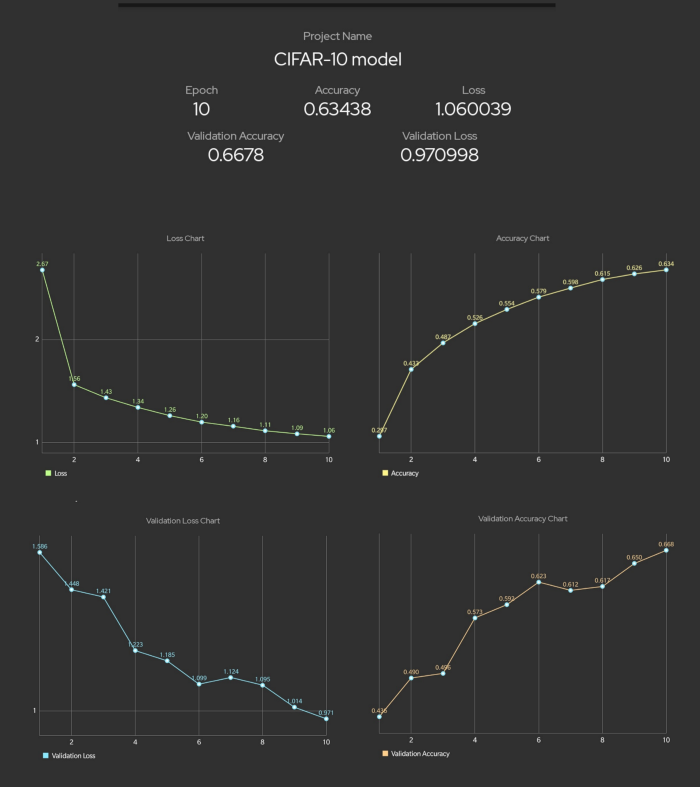
 Графики обучения тренировочная выборка
Графики обучения тренировочная выборка
 Графики обучения валидационная выборка
Графики обучения валидационная выборка



? - Вспоминаем размер изображения") - Пиксели(срезы слева)? - Вспоминаем
размер изображения
- Пиксели(срезы слева)? - Вспоминаем
размер изображения
") Конечный вариант маски. Smooth 0.5.
(сглаживание в обучении не использовалось)
Конечный вариант маски. Smooth 0.5.
(сглаживание в обучении не использовалось)
 2D U-Net
2D U-Net
![Эксп.12D U-Net, подача изображений покадрово, плоскость [x, z]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/d24/21a/246/d2421a24672cfc2928bf98a22ebd3bc7.gif "Эксп.12D U-Net, подача изображений покадрово, плоскость [x, z]") Эксп.12D U-Net, подача изображений
покадрово, плоскость [x, z]
Эксп.12D U-Net, подача изображений
покадрово, плоскость [x, z]
![Слева на право:1. Не видно[x, y]. 2. Немного лучше[x, z]. 3.Ещё лучше[y, z]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/75b/d08/ffb/75bd08ffbdeac83181abf79355378872.png "Слева на право:1. Не видно[x, y]. 2. Немного лучше[x, z]. 3.Ещё лучше[y, z]") Слева на право:1. Не видно[x, y]. 2.
Немного лучше[x, z]. 3.Ещё лучше[y, z]
Слева на право:1. Не видно[x, y]. 2.
Немного лучше[x, z]. 3.Ещё лучше[y, z]
![Эксп.2Каскад 2-ух 2D U-Net, подача изображений покадрово, плоскость [y, z]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/eef/335/e4e/eef335e4ebb6f3a3d23709cf81948e40.png "Эксп.2Каскад 2-ух 2D U-Net, подача изображений покадрово, плоскость [y, z]") Эксп.2Каскад 2-ух 2D U-Net, подача
изображений покадрово, плоскость [y, z]
Эксп.2Каскад 2-ух 2D U-Net, подача
изображений покадрово, плоскость [y, z]
![Эксп.3Каскад 2-ух 2D U-Net, подача изображений покадрово плоскость [y, z]с увеличением времени обучения на 50%](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/3ce/fc5/3d5/3cefc53d5fee0fdf2693b95e6db91152.png "Эксп.3Каскад 2-ух 2D U-Net, подача изображений покадрово плоскость [y, z]с увеличением времени обучения на 50%") Эксп.3Каскад 2-ух 2D U-Net, подача
изображений покадрово плоскость [y, z]с увеличением времени
обучения на 50%
Эксп.3Каскад 2-ух 2D U-Net, подача
изображений покадрово плоскость [y, z]с увеличением времени
обучения на 50%
![Эксп.43D U-Net, подача объемом, плоскость [y, z],время*0,38](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/618/cdd/83d/618cdd83db3c6855c2f916a11303c960.png "Эксп.43D U-Net, подача объемом, плоскость [y, z],время*0,38") Эксп.43D U-Net, подача объемом, плоскость
[y, z],время*0,38
Эксп.43D U-Net, подача объемом, плоскость
[y, z],время*0,38
![Эксп.53D U-Net, подача объемом, плоскость [y, z], 65 epochs ~ 1,5 часа](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/7c7/e67/19a/7c7e6719a026fb11df22cd32eab03620.png "Эксп.53D U-Net, подача объемом, плоскость [y, z], 65 epochs ~ 1,5 часа") Эксп.53D U-Net, подача объемом, плоскость
[y, z], 65 epochs ~ 1,5 часа
Эксп.53D U-Net, подача объемом, плоскость
[y, z], 65 epochs ~ 1,5 часа
![Эксп.63D U-Net, подача объемом, плоскость [x, z], 105 epochs ~ 2,1 часа](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/bc8/372/a07/bc8372a07b3aa13e874b0f9abfc4d21a.png "Эксп.63D U-Net, подача объемом, плоскость [x, z], 105 epochs ~ 2,1 часа") Эксп.63D U-Net, подача объемом, плоскость
[x, z], 105 epochs ~ 2,1 часа
Эксп.63D U-Net, подача объемом, плоскость
[x, z], 105 epochs ~ 2,1 часа
![Эксп.73D U-Net, подача объемом, плоскость [x, z],Маска (слева) и готовая сегментация (справа),оптимизированные параметры сети,время обучения(65 epochs) ~ 14мин.](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/9d5/497/b04/9d5497b04c3c3a80a2c6275e5148cb2c.png "Эксп.73D U-Net, подача объемом, плоскость [x, z],Маска (слева) и готовая сегментация (справа),оптимизированные параметры сети,время обучения(65 epochs) ~ 14мин.") Эксп.73D U-Net, подача объемом, плоскость
[x, z],Маска (слева) и готовая сегментация
(справа),оптимизированные параметры сети,время обучения(65 epochs)
~ 14мин.
Эксп.73D U-Net, подача объемом, плоскость
[x, z],Маска (слева) и готовая сегментация
(справа),оптимизированные параметры сети,время обучения(65 epochs)
~ 14мин.

 Выглядит это так же бредово, как и звучит
Выглядит это так же бредово, как и звучит



 Пример неориентированного графа на 28
категорий с "разделителями"
Пример неориентированного графа на 28
категорий с "разделителями"




 меш объекта на сцене,
меш объекта на сцене,  модель камеры,
модель камеры,  модель источника освещения,
модель источника освещения,  модель текстуры,
модель текстуры,  карта нормалей для меша,
карта нормалей для меша,  карта глубины получаемого изображения,
карта глубины получаемого изображения,
 матрица преобразования 3D в 2D для
получения плоского изображения,
матрица преобразования 3D в 2D для
получения плоского изображения,  растеризованное изображение,
растеризованное изображение,  вероятностные карты метода Soft
Rasterizer,
вероятностные карты метода Soft
Rasterizer,  изображения полученные
традиционным рендерингом и методом SoftRas соответственно. Красные
блоки недифференцируемые операции, синии дифференцируемые.
изображения полученные
традиционным рендерингом и методом SoftRas соответственно. Красные
блоки недифференцируемые операции, синии дифференцируемые.



 , которая каждой внутренней или
внешней точки пространства
, которая каждой внутренней или
внешней точки пространства  ставит в соответствие число от 0 до
1 вероятности принадлежности к данному полигону
ставит в соответствие число от 0 до
1 вероятности принадлежности к данному полигону  (чем-то похоже на подход нечеткой
логики). Здесь
(чем-то похоже на подход нечеткой
логики). Здесь  параметр размытия (чем больше
параметр размытия (чем больше
 кратчайшее расстояние в
проекционной плоскости от проекции точки
кратчайшее расстояние в
проекционной плоскости от проекции точки  также подходит для их метода),
также подходит для их метода),
 функция, которая равна 1 если
точка находится внутри полигона и -1 если вне (на границе полигона
можно доопределить значение
функция, которая равна 1 если
точка находится внутри полигона и -1 если вне (на границе полигона
можно доопределить значение  нулем, однако это все равно
приводит к тому, что на границе полигона данная функция разрывна,
поэтому для точек границ она не применяется),
нулем, однако это все равно
приводит к тому, что на границе полигона данная функция разрывна,
поэтому для точек границ она не применяется),  сигмоидная функция активации,
которая часто применяется в глубоком обучении.
сигмоидная функция активации,
которая часто применяется в глубоком обучении.
 -го пикселя
-го пикселя  , производят нормированное
суммирование цветовых карт
, производят нормированное
суммирование цветовых карт  для k ближайших полигонов
для k ближайших полигонов
 , причем цветовые карты
получают путем интерполяции барицентрических координат цвета вершин
данных полигонов. Индекс
, причем цветовые карты
получают путем интерполяции барицентрических координат цвета вершин
данных полигонов. Индекс  в формуле отвечает за фоновый цвет
(background colour), а оператор
в формуле отвечает за фоновый цвет
(background colour), а оператор  оператор агрегирование
цвета.
оператор агрегирование
цвета.  глубина
глубина  -го полигона, а
-го полигона, а  параметр смешивания (чем он
меньше, тем сильнее превалирует цвет ближайшего полигона).
параметр смешивания (чем он
меньше, тем сильнее превалирует цвет ближайшего полигона).




























































 .
.







































 Конфигурации ВМ A2 доступные в сервисе Compute
Engine
Конфигурации ВМ A2 доступные в сервисе Compute
Engine
 Новая ВМ A2-MegaGPU: 16 графических
процессоров A100 со скоростью передачи данных 9,6 ТБ/с по
интерфейсу NVIDIA NVLink
Новая ВМ A2-MegaGPU: 16 графических
процессоров A100 со скоростью передачи данных 9,6 ТБ/с по
интерфейсу NVIDIA NVLink



















{kind=link}