Сап, котятки.
Я пришёл рассказать о проекте UAVCAN новом сетевом стандарте для
организации взаимодействия узлов и компонентов современных
транспортных средств с высоким уровнем автономности/автоматизации.
Название является акронимом от Uncomplicated
Application-level Vehicular
Communication And
Networking (несложные бортовые сети и
коммуникации уровня приложения).
В этой публикации объясняется текущее положение дел и тренды в
области сложных бортовых систем, существующие и грядущие проблемы,
как мы их решаем, и каких успехов добились. Во второй части,
которая будет опубликована позднее, наши коллеги из Университета
Иннополис подробно осветят практическую сторону внедрения UAVCAN на
примере конкретных проектов.

Конъюнктура
Первый блин проекта был заложен в 2014-м. С самого начала это
был эксперимент в минимализме: возможно ли в разработке сложных
распределённых бортовых систем опираться на мощные абстракции,
избегая при этом роста сложности реализации и связанных с ним
трудностей валидации и верификации.
Мы наблюдаем быстрый рост сложности бортовых систем, связанный с
развитием функциональных возможностей транспортных средств
(особенно беспилотных) в целом, и систем автоматического управления
в частности. Когда мы говорим
"бортовая система", мы подразумеваем совокупность автоматики,
необходимой для реализации базовых функций транспорта; например,
БСУ/ЭДСУ летательных аппаратов, всевозможные
ЭБУ в автомобиле, полётный контроллер в дроне
или космическом аппарате, сенсоры (радары, камеры), датчики,
исполнительные механизмы, и т.п.
Бортовая электроника (электрика) автомобиля конца 20-го века
может быть исчерпывающе описана довольно тривиальной схемой; вот,
например, схема ВАЗ 21099:
Схема демонстрирует нам довольно непосредственный подход к
организации внутрисистемных взаимодействий: есть компонент вот к
нему провод. Поведения, выходящие по сложности за рамки простейших
аналоговых или дискретных соотношений (нагрелась вода в системе
охлаждения включился вентилятор; коленчатый вал достиг
определённого угла сработало зажигание в цилиндре), не могут быть
эффективно описаны и созданы на столь низком уровне ввиду
когнитивных ограничений человеческого мозга. Приведённую схему
легко понять, но будет ли это верно, если мы добавим электронное
зажигание, круиз-контроль, а то и автопилот пятого уровня?
Сегодняшние транспортные средства являются в значительной мере
программно-определяемыми в том смысле, что существенная часть
функциональности и поведений задаётся не столько
электрической/механической конфигурацией, сколько программным
обеспечением (ПО), что порождает соответствующий перекос
концептуальной сложности в сторону бортового ПО. В контексте
космических аппаратов это обстоятельство было подмечено ещё
инженерным коллективом NASA, работающим над программой Аполлон. В
равной мере это применимо и к современным автомобилям (показательна
известная история ранней Tesla Model 3, где проблемы
антиблокировочной системы были исправлены удалённым накатыванием
обновлений без участия владельцев), и к летательным аппаратам (в
особенности с ЭСДУ).
Абстракции позволяют нам обойти когнитивное ограничение на
количество сущностей, единовременно удерживаемых в сознании. В
теории систем этот принцип известен как "чёрный ящик". Любой человек, хоть раз державший
в руках компилятор, знает, как это работает: сложные подсистемы
описываются не непосредственно, а в виде ограниченных
функциональных блоков со строго определённым интерфейсом,
скрывающим их реализацию. В рамках дискурса общих информационных
технологий безусловно делается предположение, что человеку,
мыслящему на определённом уровне абстракции, нет нужды вникать в
специфику реализации задействованных на данном уровне блоков, иначе
нарушается принцип чёрного ящика. Это предположение не является
безусловно корректным если речь идёт о критических системах, где
необходима высокая живучесть/отказоустойчивость. Объясняется это
тем, что второстепенные функциональные особенности различных
компонентов в совокупности могут порождать потенциально опасные
непредусмотренные поведения (как это демонстрируют былинные отказы
Mars Climate Orbiter, Airbus A400M в Севилье, Ariane 5, и т.п.).
Растущая сложность бортового оборудования отражается в развитии
стандартов безопасности. Более сложные системы создаются
композицией более сложных подсистем, что формирует спрос на
конкретные гарантии поведенческих характеристик компонентов (если у
нас есть, скажем, радар, мы хотим точно знать, в каких условиях и
как он будет работать, как его характеристики коррелируют с
параметрами среды, и вообще неплохо бы убедиться, что его
разработчики мышей ловят). Примером ответа индустрии на этот запрос
будет концепция Safety Element out of Context (SEooC), введённая
в новом автомобильном стандарте ISO 26262. Строго говоря, тема
стандартизации не имеет прямого отношения к нашему сугубо
техническому проекту, но она отражает общие тренды в индустрии к
переходу к композициям более сложных компонентов и как следствие,
более сложных интерфейсов.
Холистический анализ сложных систем невозможен по очевидным
причинам; фрагментарные же подходы в области высокой надёжности
усложняются необходимостью детальной формализации и верификации
поведений функциональных блоков с целью минимизации рисков
возникновения непредусмотренных поведений при их интеграции. В этом
свете выглядит целесообразным поиск методов построения чёрных
ящиков, который предоставлял бы удобные инструменты создания
абстрактных интерфейсов, и в то же время привносил бы минимальные
накладные расходы на формализацию/верификацию блоков и их
композиций.
Здесь следует внести разъяснения касательно специфики реального
времени и высокой надёжности для читателя, не являющегося
специалистом в этой области. Разработчик прикладного ПО,
веб-сервера или типичной бытовой встраиваемой системы (вроде
компьютерной периферии) сочтёт покрытие тестами достаточной
гарантией адекватности ПО. Проблемы реального времени в сложных системах такого рода
возникают редко, а когда они возникают, цена временных отклонений
обычно достаточно мала, чтобы можно было пренебречь жёстким
ресурсным планированием или формальным анализом планировки задач
(schedulability analysis). Процессы жёсткого реального времени
обычно либо просты, либо цена ошибки несущественна (в качестве
примера бытового жёсткого реального времени можно принять логику
работы печатающей головки струйного принтера, привод экструдера 3D
печати или аудиокодек). Эмпирические методы в целом преобладают над
формальными; повсеместно применяется бенчмаркинг и амортизационный анализ. Если продукт показывает
приемлемые результаты в подавляющем числе случаев, он принимается
соответствующим требованиям; более строгие подходы обычно
нецелесообразны финансово.
Разработчик критических систем транспортного средства имеет дело
с иным балансом стоимости создания ПО и потенциального ущерба от
последствий его сбоев (это верно даже в случае средств микромобильности и малых БПЛА).
Большинство таких систем работают в реальном времени, где
несвоевременное исполнение задачи эквивалентно неисполнению.
Изменение баланса стоимости оправдывает увеличение вложений в
средства обеспечения функциональной безопасности с целью снижения
эксплуатационных рисков. Как следствие, доказательные методы,
верификация и валидация, широко распространены.

Говоря о балансе проектировочных затрат и рисков, интересная
тенденция сейчас имеет место в космической отрасли: как метко отмечает Casey Handmer, наблюдаемое ныне
снижение стоимости вывода космических аппаратов (КА) сдвигает
оптимальный баланс в сторону решений с менее строгими гарантиями
безопасности и менее затратной разработкой. В случае же БПЛА
наблюдается обратный тренд ввиду распространения более
ответственных применений и увеличения числа аппаратов в
эксплуатации.
Различные исходные предпосылки при создании систем разного
уровня функциональной безопасности проявляются в, порою, радикально
различных технических свойствах их компонентов и предпочитаемых
методах их создания. Скажем, бортовая коммутируемая сеть
современного авиалайнера (как AFDX) предоставляет гарантированные минимальные кривые обслуживания, и, как
следствие, для хорошо спланированного трафика отсутствует
потребность в подтверждении доставки. Для типичной коммерческой
системы эта логика чужда, ведь свойства сети и её загрузку никто не
гарантирует. Асимптотический анализ в рамках жёсткого реального
времени сфокусирован на худшем случае нежели амортизированном
случае, что порою может радикально менять подходы на всех уровнях
проектирования.
Различия в предпосылках также объясняют, почему прекрасно
зарекомендовавшие себя в ИКТ решения (тысячи их: очереди сообщений,
фреймворки, сетевые стеки с TCP/IP во главе, распределённые БД,
операционные системы, etc.) обычно непригодны для ответственных
применений и почему безопасные системы часто отдают предпочтение
специализированным технологиям.
Резюмируя: современные тренды радикального усложнения бортовых
систем при сохранении требований отказоустойчивости и
предсказуемости порождают неудовлетворённый спрос на решение,
позволяющее проектировщику конструировать интерфейсы с
гарантированными свойствами на высоком уровне абстракции, которое
при этом было бы компактным и простым в реализации, валидации и
верификации. Поскольку мы имеем дело с узко ограниченной областью
применения, то имеют смысл оптимизации с учётом местной
специфики.
Обычный порошок
Картина положения дел в индустрии будет неполной без хотя бы
поверхностного рассмотрения существующих технологий построения
отказоустойчивых распределённых систем реального времени. Решения
эти обычно интересны технически, созданы с оглядкой на многолетний
опыт и проверены временем в реальных продуктах. Однако, тем не
менее, горшки CiA/SAE/RTCA/EUROCAE/AUTOSAR/OMG/etc. обжигают отнюдь
не боги.
Технологии мы поделим на категории по уровню абстракции
коммуницируемых состояний и потенциала к созданию сложных систем.
Эта модель игнорирует тонкости и в граничных случаях может быть
некорректна, но она справляется с главной задачей: объяснением
общего положения дел и демонстрацией рассогласования между
запросами индустрии и доступными решениями. Пойдём от простого к
сложному.
1. Аналоговые схемы
Просто и прямолинейно. Электрические, пневматические,
гидравлические, механические средства непосредственного
взаимодействия между узлами и компонентами попадают в эту
категорию. Приведённая ранее схема ВАЗ 21099 тоже отсюда.
Базовым примитивом межкомпонентного взаимодействия здесь будет
аналоговый или дискретный сигнал представленный напряжением/током в
электрической цепи, давлением в линии, натяжением троса, и т.п.
2. Логическая шина
Шина данных есть довольно общий термин. Мы здесь под
этим подразумеваем модель взаимодействия, где атомарной единицей
данных является структура из логически связанных
сигналов/параметров, и внимание проектировщика в значительной мере
сосредоточено на определении этих структур и логики их обмена.
Следует разделять топологию физическую и логическую: методы
соединения узлов и пересылки пакетов не имеют отношения к потокам
данных на уровне приложения. На физическом уровне мы выделяем три
ключевые топологии: точка-(много)точка, физическая шина и коммутируемая сеть, любая из которых может
использоваться для построения логической шины.
Начнём с первого. Если компонент А непрерывно сообщает
компоненту Б больше одного параметра, имеет смысл временное разделение (мультиплексирование)
сигналов. Такое уплотнение позволяет наращивать число параметров
при постоянном числе физических межкомпонентных соединений, что
удешевляет/облегчает конструкцию. Практическим примером будет
ARINC 429 древний и незамысловатый авиационный
протокол, реализующий обмен фиксированными 18-битными словами с
щепоткой метаданных по выделенным (некоммутируемым) линиям.
Типичная топология выглядит так:

Диаграмма адаптирована из "The Evolution of Avionics Networks
From ARINC 429 to AFDX", Fuchs, 2012.
ARINC 429 довольно атипичен как бортовая шина тяжело привести
другой пример использования физической топологии точка-многоточка
(хотя причастные к малым дронам могли бы вспомнить здесь DShot и MAVLink; последний изначально предназначен для
беспроводной связи с наземной станцией, но иногда применяется для
внутрибортовой коммуникации). Этот подход имеет особый смысл в
простых критических системах жёсткого реального времени, потому что
временные свойства процесса доставки сигнала от отправителя к
получателю абсолютно очевидны и не требуют сложного анализа. Среда
передачи не разделяется с другими компонентами, поэтому нет нужды
оценивать вклад каждого в загрузку среды и результирующие побочные
эффекты. Однако, этот метод не масштабируется и делает логику
взаимодействия сильно зависимой от физических параметров сети (если
к компоненту не потрудились пробросить кабель при проектировании,
соответствующих данных он никогда не получит).
Широкое распространение получила шинная топология (мы говорим о
физическом уровне, не забывайте). Вероятно, CAN не нуждается в представлении; на нём
основано множество протоколов и стандартов верхнего
уровня. Здесь же FlexRAY, LIN, MIL-STD-1553 и ранние стандарты Ethernet
(современный Ethernet используется только в коммутируемой
конфигурации).
CAN показателен в контексте реакции отрасли на рост сложности
продукции. Введённая в 1986 первая версия стандарта предлагала
крайне ограниченный MTU в 8 байт на пакет. В 2012 появился CAN FD с MTU в целых 64 байта и увеличенной
пропускной способностью. С конца 2018 года в активной разработке
находится CAN XL с MTU 2 КиБ и ещё чуть более высокой скоростью
(начало ISO стандартизации запланировано на 2021 год).
Говоря о физических шинах, нельзя не вспомнить интереснейшее
начинание под названием Wireless Avionics Intra-Communications (WAIC). WAIC
предлагает повысить отказоустойчивость бортовых критических сетей
введением гетерогенной избыточности, где резервным каналом станет
беспроводной. В целом, беспроводные бортовые сети можно считать
фундаментально менее надёжными, чем бортовые проводные/оптические,
ввиду слабого контроля за состоянием среды обмена (эфир один на
всех). Однако, в совокупности с традиционными сетями, беспроводные
позволяют поднять отказоустойчивость из-за устранения отказов общего вида, свойственных проводным
сетям, ведь механическое повреждение элемента конструкции может с
высокой вероятностью повредить все избыточные проводные
соединения:
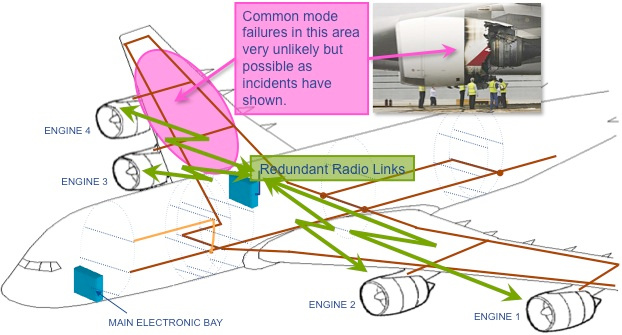
Диаграмма с сайта WAIC.
Физическая шина размещает всех участников на едином сегменте
сети, что создаёт проблемы масштабируемости, ведь все узлы
вынуждены организовывать обмен внтутри общего домена коллизий. Сложные транспортные средства
на острие прогресса (скажем, современные авиалайнеры и космические
аппараты) не в состоянии организовать работу систем в пределах
ограничений существующих физических шин, поэтому в ход идут
коммутируемые сети. Из значимых следует вспомнить SpaceWire (чрезвычайно узкоспециализированная
технология; насколько мне известно, совершенно не представлена вне
КА) и, конечно, Ethernet.
В современном аэрокосмосе широко применяется коммутируемый
Avionics Full-Duplex Switched Ethernet (AFDX)
как на стомегабитной медной паре, так и на оптике (см. Boeing 787).
Несмотря на передовой физический уровень, логически это всё тот же
ARINC 429, где физические соединения точка-точка заменены их
виртуальными репрезентациями. Это решает проблемы масштабируемости,
но не предоставляет новых инструментов проектирования логики. Сети
AFDX проектируются со статическим планированием обмена с
применением автоматических доказательств, что позволяет
получить гарантированные временные характеристики
доставки несмотря на привнесённые коммутацией сложности. Широко
применяется полное дублирование сетевого аппаратного обеспечения
(коммутаторов и кабельной системы) для отказоустойчивости. Ниже
показан пример физической топологии AFDX подсети космического
аппарата с дублированием; при этом логическая сеть ARINC 429,
построенная поверх (не показана), определяется конфигурацией ПО
коммутаторов вместо физической конфигурации кабельной системы:
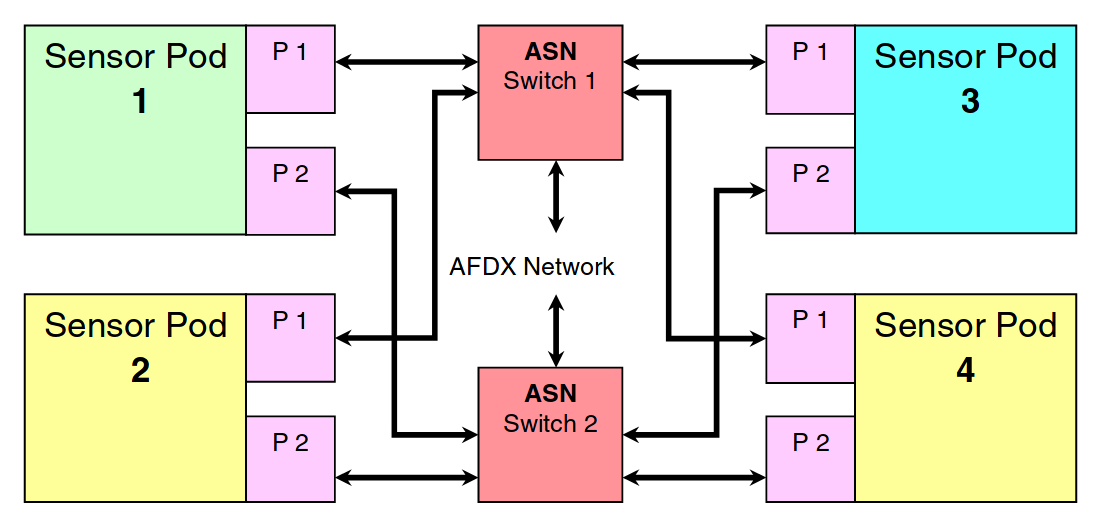
Диаграмма из "Communications for Integrated Modular Avionics",
Alena, 2007.
Гарантированные параметры сети объясняют почему в сетях жёсткого
реального времени редко применяется подтверждение доставки. Вторая
причина в том, что процессы реального времени часто предполагают
сторого периодический обмен данными, где затраты времени и ресурсов
сети (которые, замечу, под строгим учётом) на отправку
подтверждения или второй копии данных оказываются неоправданными
из-за скорой отправки очередного пакета с более новыми данными в
рамках естественного течения процесса. Поэтому, в частности, AFDX
построен на (слегка модифицированном) протоколе UDP/IPv4.
Использование классических "надёжных" протоколов вроде TCP/IP в
подобной среде было бы не просто излишним, а контрпродуктивным они
несовместимы с особенностями процессов реального времени.
Общая характеристика рассмотренных технологий и построенных на
их основе высокоуровневых протоколов заключается в их
ориентированности на организацию низкоуровневых сценариев
взаимодействия, где фокус внимания проектировщика сосредоточен на
группах определённых параметров и их пересылке между конкретными
аппаратными и программными компонентами. На логическом уровне мы
всё так же имеем дело со жгутами виртуальных проводов, как на схеме
ВАЗ 21099. Подобно тому, как рост сложности решений заставил
индустрию ИКТ пережить несколько смен парадигмы за последние
десятилетия, подходы к построению архитектуры распределённых
бортовых систем претерпевают изменения под давлением спроса на
автономность и автоматизацию транспортных средств. В 2020 мы
наблюдаем первые симптомы несостоятельности традиционных методов и
попытки к переходу на качественно более мощные средства, о чём
будет следующий раздел.
3. Распределённые
вычисления
Рассматриваемые здесь распределённые системы создаются из
множества компонентов, которые реализуют сложные поведения и
манипулируют большим числом внутренних состояний. Принцип чёрного
ящика, чьё применение необходимо в силу когнитивных ограничений
человека-проектировщика, предписывает сокрытие конкретики
внутренних состояний и процессов за абстрактными межкомпонентными
интерфейсами. Возникающая потребность в нетривиальной трансляции и
интерпретации между моделью интерфейса и внтуренними состояниями
является фундаментальным отличием концепции распределённых
вычислений от логической шины.
Если в случае логической шины процесс проектирования
распределённой системы сосредоточен на пакетах данных и их обмене
между конкретными узлами, в данном случае ключевыми сущностями
являются сетевые сервисы и объекты предметной области, зачастую без жёсткой
привязки к физической реализации. Это можно рассматривать как
частный случай сервис-ориентированного проектирования.
Пожалуй, наиболее значимым на сегодня примером такого подхода
будет граф распределённых вычислений из Robot Operating System (ROS) (строго говоря, ROS
не является операционной системой, это скорее высокоуровневый
фреймворк). Изначально ROS был создан в качестве SDK для
окологуманоидного робота PR2 от Willow Garage, но исследователи
быстро увидели потенциал фреймворка в других робототехнических
системах (от пылесосов и манипуляторов до БПЛА и робоавтомобилей),
и он превратился в самостоятельный проект. За несколько лет вокруг
ROS развилась богатая экосистема программного обеспечения,
решающего многие типовые задачи вроде компьютерного зрения,
локализации и картографирования, взаимодействия с аппаратным
обеспечением, и т.п. Если изначально фреймворк создавался для
исследовательских задач, то интенсивное развитие его экосистемы (и
отрасли в целом) со временем поставило вопрос о продуктизации и
трансфере наработок из лабораторий в полевые условия, с чем
возникли значительные трудности.
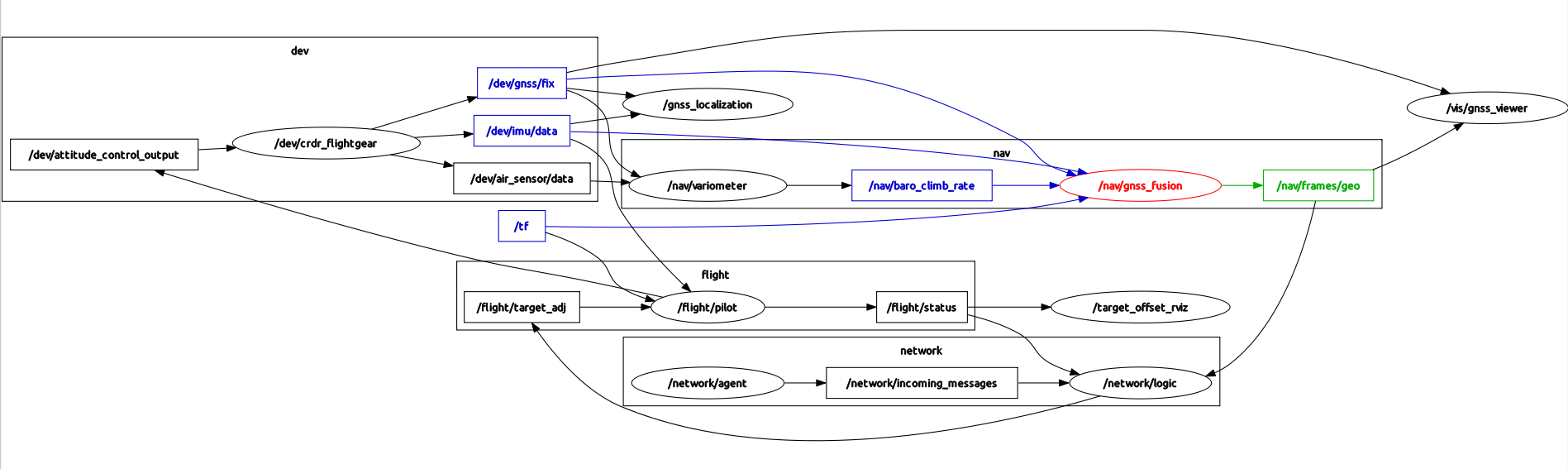
Пример визуализации распределённых процессов на ROS. На схеме
показан фрагмент системы управления автономного БПЛА в режиме
программно-аппаратного моделирования. Овалы
обозначают процессы, прямоугольники и стрелки обозначают связи
издатель-подписчик.
Описание полного спектра проблем продуктизации основанных на ROS
изделий приведёно в статье Why ROS 2 [Gerkey], которая, как нетрудно
догадаться из названия, решительно предлагает выпустить вторую
версию с оглядкой на новые потребности индустрии. Одной из ключевых
проблем здесь является неспособность изначально исследовательского
фреймворка удовлетворить радикально более жёсткие требования
продуктовых систем к предсказуемости и гарантиям безопасности,
которые зачастую обусловлены не только коммерческим интересом, но и
законодательным регулированием (особенно в случае автомобильной или
аэрокосмической отрасли). Коммуникационная подсистема ROS,
обеспечивающая межкомпонентные взаимодействия, является одной из
наиболее критических и сложных частей фреймворка. В первой версии
использовалась собственная реализация, созданная с нуля,
принципиально несовместимая с ответственными применениями, из-за
чего во второй версии в роли коммуникационной подсистемы
использовали популярное готовое решение Data Distribution Services (DDS).
DDS является сильно отдалённым потомком CORBA, ориентированным на реальное время и модель
издатель-подписчик (с недавних пор предлагается
также встроенная поддержка клиент-серверных взаимодействий, но на
практике первый тип наиболее востребован). DDS широко применяется
не только в транспорте и робототехнике, но и в промышленности
вообще, зачастую выступая в роли выделенного коммуникационного слоя
(собственно, как в случае ROS 2) для вышележащих технологий.
Особого упоминания здесь заслуживает Future Airborne Capability Environment (DDS FACE)
для критической авионики; однако, на сегодняшний день, большая
часть реальных применений DDS в аэрокосмосе приходится на
немногочисленные военные системы, которые не следуют гражданским
стандартам безопасности.
Как было упомянуто, DDS дальними корнями уходит в CORBA оба
стандарта поддерживаются одной
организацией. Последняя изначально не предназначалась для
систем реального времени, но отраслевые реалии заставили
исследователей начать рассматривать вопросы её адаптации для
реального времени ещё в конце прошлого века. В работе "The Design
of the TAO Real-Time Object Request Broker" [Schmidt et al, 1999]
большое внимание уделяется тому факту, что проектирование
адекватной сети реального времени самой сетью не ограничивается
обязательному анализу подлежат вопросы реализации логики протокола
на конечных узлах с соблюдением временных гарантий. В разрезе CORBA
синопсис рассматриваемых проблем приведён ниже; эти же принципы
легко переносятся на практически любую современную технологию того
же толка:
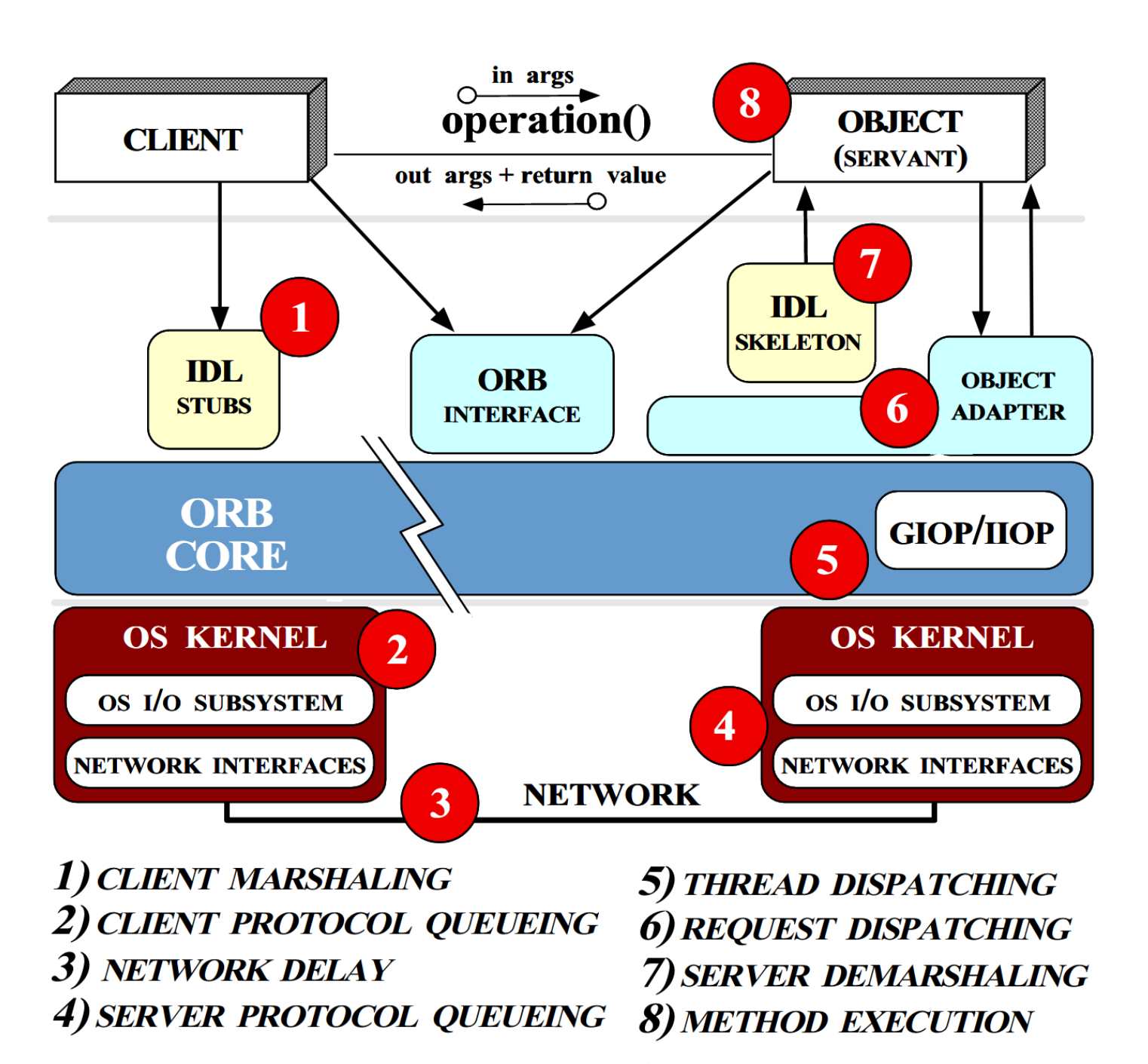
Цифрами обозначены ключевые аспекты реализации, где предписан
анализ временных характеристик внутренних алгоритмов протокола.
Диаграмма из "The Design of the TAO Real-Time Object Request
Broker", Schmidt et al, 1999.
Шмидт с коллегами воплотил идеи в популярной ныне C++ библиотеке TAO (The ACE ORB), которая легла в основу некоторых
современных реализаций DDS. Сама по себе TAO насчитывает более
двухсот тысяч строк кода без учёта специфики DDS, которая привносит
ещё дополнительный код сверху. Из более современных и независимых
от TAO инкарнаций DDS упомяну, пожалуй, наиболее многообещающую на
сегодня eProsima Fast-DDS (это оценочное суждение, а не
реклама) без сторонних зависимостей и тестов она занимает
более трёхсот тысяч строк C++ кода (и реализует при этом не все
опциональные возможности стандарта). Эти сведения приведены с целью
иллюстрации порядка концептуальной сложности DDS.
Как нетрудно догадаться из вышеизложенного, DDS также отличается
высокими требованиями к вычислительной платформе, что помимо
прочего ограничивает использование во встраиваемых системах.
Конкретно эта проблема отчасти решается специализированным
подмножеством DDS For Extremely Resource Constrained Environments
(DDS-XRCE). Но, согласно нашей модели, это решение уже выходит
далеко за пределы концепции распределённых вычислений в силу своей
глубокой зависимости от центрального координирующего агента и
ограниченной функциональности. Для рассматриваемого здесь вопроса
эта технология большой ценности не представляет и рассматривать мы
её не будем, равно как мы обойдём стороной и связанный проект
micro-ROS.
Из других решений есть смысл поверхностно упомянуть SOME/IP часть автомобильного стандарта AUTOSAR v4+, предлагающую сервисы построения
распределённых систем поверх стека IP. В отличие от DDS, SOME/IP сфокусирован
исключительно на автомобильных применениях и оперирует существенно
более низкоуровневыми концепциями со слабой сегрегацией по уровням
абстракции. В совокупности с довольно вольготным обращением с
распределёнными состояниями (об этом поговорим далее) и
значительным логическим зацеплением между коллабораторами это
вызывает вопросы о будущем SOME/IP при наличии сильного конкурента
в лице DDS.
Распространённые в ИКТ альтернативы вроде MQTT и разнообразных
специализированных фреймворков не учитывают аспекты реального
времени и гарантий поведенческих характеристик, поэтому в наших
приложениях встретить их можно редко и рассматривать их здесь не
имеет смысла.
Высокая внутренняя сложность существующих технологий
распределённых вычислений обусловлена широким спектром
поддерживаемых сценариев и типов взаимодействия, лишь малая часть
которых актуальна для интересующей нас области применений. Мы
полагаем, что это утверждение верно даже для специализированных
решений (как SOME/IP), чья архитектура может подлежать улучшениям
путём целостного пересмотра подходов к проектированию бортовых
распределённых систем. Аккуратное переосмысление основных
требований к коммуникационной подсистеме позволило нам достичь
более взвешенного баланса между внутренней сложностью (и, как
следствие, стоимостью валидации и верификации и обеспечения
гарантированных характеристик) и доступными инструментами
построения мощных абстракций.
Наш подход
Мы едим нашу собаку уже не первый год, и только сейчас
подобрались к выпуску первой долгосрочно стабильной версии
стандарта, которую мы называем UAVCAN v1. Этому
эпохальному для нас событию предшествовали исследования и
экспериментальные развёртывания в реальных системах, на протяжении
которых менялись наши методы, но не менялись ключевые цели:
-
Простота понимания и реализации. Как было
показано выше, это исключительно важно для критических систем.
Протокол масштабируется согласно сложности использующего его
компонента распределённой системы (т.е., аппаратного узла или
программы): в простых компонентах совместимая реализация протокола
должна умещаться в одну тысячу строк; в очень сложных она может
расти до пары десятков тысяч строк.
-
Высокоуровневые абстракции. Протокол позволяет
разработчику конструировать абстрактные робастные интерфейсы с
учётом ограничений реального времени. Спецификации таких
интерфейсов сосредоточены исключительно на нуждах приложения и не
включают в себя сущности из нижних уровней вроде конечных автоматов
сетевого обмена, ручное управление распределённым состоянием или
сериализацию битовых полей.
-
Отказоустойчивость. Протокол реализует
одноранговую децентрализованную сеть со встроенной поддержкой
избыточности. Обеспечивается совместимость с ненадёжными сетями
реального времени, где возможны потери пакетов в результате
деструктивных воздействий среды (например, электромагнитная
интерференция), но не самой сети (например, переполняющийся
буфер).
-
Предсказуемость. Протокол изначально
спроектирован для задач реального времени и для использования во
встраиваемых системах от младших однокристалок без ОС с единицами
КиБ памяти до мощных компьютеров под управлением сложных ОС, причём
не обязательно реального времени. Поддерживаются средства
высокоточной синхронизации времени в пределах сети для нужд
распределённых контуров управления. Ресурсный потолок всегда
тривиально предсказуем и доказуем.
-
Открытость. Это не техническое требование, а
юридическое, но это не делает его менее значимым. Невозможно
обеспечить серьёзные внедрения закрытой технологии, если
существенная часть отрасли живёт открытыми стандартами и открытым
ПО. Этот пункт подразумевает свободное распространение всей
документации и кода под разрешительными лиценизиями (CC BY, MIT)
без обязательных членских взносов.
В части погони за простотой как одной из ключевых характеристик
можно усмотреть реминисценции известного в определённых кругах
алгоритма распределённого консенсуса Raft, чьи
создатели точно так же, как и мы, начали с вопроса о том, как
сделать сложные вещи простыми. Хотя область их деятельности не
имеет ничего общего с нашей, они, как и мы, в конечном итоге решали
проблему восприятия, где единственной гарантированно достоверной
метрикой является человеческий опыт. В отличие от авторов Raft, мы
не проверяли трудность понимания наших спецификаций на больших
массах людей (N.B.: они показали видео-лекцию 43-м студентам и
потом оценили понимание при помощи теста, сравнив результаты с
конкурирующей технологией). Однако, у нас есть вот такое
практическое свидетельство, где господин зашёл с улицы и сделал
минимальную реализацию UAVCAN с нуля за "пару недель" (с его
слов):

Желающие увидеть код найдут его на гитхабе как libuavesp. Я, обратите внимание, умываю руки мы к
этой реализации отношения не имеем. Заявление автора о том, что
"UAV" в названии "UAVCAN" имеет отношение к БПЛА, не соответствует
действительности и вызвано банальным недоразумением.
Как нетрудно догадаться из предваряющей этот раздел вводной,
UAVCAN широко заимствует ценные принципы из флагманов современной
индустрии, в первую очередь опираясь на ROS, DDS, AFDX, WAIC и
множество высокоуровневых CAN протоколов, которые даже нет смысла
здесь перечислять. Однако, вопросы организации распределённых
вычислений одними транспортными протоколами, очевидно, не
ограничиваются, особенно если учесть заявленную в ключевых целях
потребность в "высокоуровневых абстракциях". UAVCAN удобно
рассматривать в виде трёхуровневой модели (мы намеренно игнорируем
семиуровневую модель OSI ввиду её чрезмерной детализации):
-
Уровень приложения. На этом уровне представлены
общие для всех бортовых систем функции: мониторинг состояния,
логирование, передача файлов, управление конфигурацией, телеметрия,
и т.п. На этом же уровне создаются специализированные сервисы
согласно потребностям конкретного приложения. В распоряжении
пользователя два вида взаимодействий: анонимный статически
типизированный издатель-подписчик и статически же типизированный
удалённый вызов процедур с явной адресацией (т.е. не
анонимный).
-
Уровень представления отвечает за маршалинг
доменных объектов в связях издатель-подписчик и при удалённом
вызове процедур. Этот уровень реализован средствами специального
предметно-ориентированного языка, на котором даётся строгое
определение типов данных для сетевого обмена: Data Structure
Description Language (DSDL). На основе DSDL-дефиниций можно
автоматически генерировать код (можно и не автоматически).
-
Транспортный уровень занимается доставкой
объектов согласно связям издатель-подписчик и удалённым вызовам
процедур. Этот уровень намеренно сильно изолирован от вышележащих
двух, что позволяет нам определить несколько транспортов поверх
различных нижележащих протоколов:
- UAVCAN/CAN работает поверх классического CAN и
CAN FD. Вероятно, в будущем также появится поддержка CAN XL, но это
не точно.
- UAVCAN/UDP работает поверх UDP/IP. По
состоянию на 2020-й год, спецификация этого транспорта ещё
находится в стадии ранней альфы и может быть изменена до
стабилизации (хотя предпосылок к этому нет).
- UAVCAN/serial работает поверх любого
байт-ориентированного протокола (UART, RS-232/422/485, USB CDC ACM)
и ещё подходит для хранения дампов в неструктурированных бинарных
файлах. Этот транспорт тоже ожидает стабилизации.
- Поскольку интерфейс между транспортом и верхними уровнями
хорошо определён, в будущем возможно добавление новых транспортных
протоколов. В числе таковых рассматривается, например, беспроводной
IEEE 802.15.4.
У нас есть несколько безусловных исходных предположений, которые
довольно однозначно очерчивают область применимости протокола.
Строгий фокус на бортовых сетях реального времени означает, что
попытки использования UAVCAN в любых других областях скорее всего
приведут к посредственным результатам, что мы, однако, не
расцениваем как недостаток.
Первое из исходных предположений таково: нижележащая
транспортная сеть (например, CAN или Ethernet, в зависимости от
выбранного транспорта) предлагает хорошо охарактеризованную
минимальную кривую обслуживания и нулевую вероятность потерь
пакетов при отсутствии неблагоприятных воздействий внешней среды.
Последнее означает, что потери не могут возникнуть в результате
процессов, протекающих внутри сети, как, например, переполнение
буфера на сетевом узле; однако, допускаются кратковременные
нарушения, вызванные внешними факторами, как, например,
электромагнитная интерференция. Это предположение полностью
совместимо с реалиями настоящих бортовых систем, и оно позволяет
нам существенно упростить логику протокола. Компенсация потерь
ввиду внешних воздействий выполняется путём превентивной отправки
дубликатов (только в тех случаях, где требуется). Рассмотрение
этого метода даётся в статье Idempotent interfaces and deterministic data loss
mitigation. Хотя описанные особенности выглядят чуждыми для
традиционных систем, они вполне оправданы для нашей области.
Крайне аккуратное обращение с разделяемым состоянием позволяет
нам сильно сократить пространство состояний сетевых узлов в
сравнении со схожими решениями. В результате сокращается
техническая сложность реализации, упрощается её анализ и
тестирование, о чём подробно сказано в официальном руководстве.
Сетевой узел UAVCAN делает минимум предположений о состоянии своих
коллабораторов; например, если в случае традиционного
фреймворка издатель-подписчик обычно выделяется явная процедура
установления подписки, где подписчик сообщает издателю о своей
заинтересованности в конкретных данных (см. SOME/IP, DDS, ROS,
практически все MQ*, etc.), в UAVCAN издатель слепо отправляет
данные в сеть, позволяя заинтересованным агентам их принять или
проигнорировать.
Последнее обстоятельство создало бы существенные преграды для
масштабирования, если бы не широкое использование аппаратной
фильтрации пакетов в обязательном порядке. Известные нам другие
протоколы (кроме AFDX) необоснованно игнорируют тот факт, что всё
современное аппаратное обеспечение для высокоскоростной
коммуникации, за исключением лишь некоторых маргинальных
представителей, предоставляет мощные аппаратные инструменты
автоматической фильтрации. Разумная эксплуатация этого факта
позволила нам ввести радикальные упрощения без ущерба
функциональности, о чём говорится в статье Alternative transport protocols in UAVCAN.
Очередное исходное предположение заключается в том, что сеть и
её участники имеют, в целом, статическую природу. Это следует
трактовать трояко. Во-первых, конфигурация бортовых систем редко
подлежит радикальным изменениям в полевых условиях, что позволяет
нам сэкономить на сложности динамической автоконфигурации в
большинстве случаев; это, впрочем, не означает, что полевая
реконфигурация невозможна в принципе (она полезна в
исследовательских и экспериментальных окружениях), но это означает,
что средства реконфигурации вынесены в опциональные части
протокола, которые могут быть удалены в интересах упрощения
валидации и верификации сертифицируемых отказоустойчивых
систем.
Например, динамическое выделение адреса в сети поддерживается
опциональным механизмом plug-and-play (впрочем, конкретно для
UAVCAN/UDP он не определён ввиду наличия стандартного DHCP).
Механизм этот также поддерживает избыточные аллокаторы для
отказоустойчивых систем, где консенсус реплик обеспечивается при
помощи упомянутого ранее алгоритма Raft.
Второй аспект статичности заключается в предоставлении
ресурсного потолка для любой части системы на этапе проектирования.
Так, определяемые при помощи упомянутого ранее DSDL типы всегда
имеют верхний предел размера любого поля переменной длины, из чего
следует, что максимальное время передачи, максимальное время
сериализации/десериализации, и, в общем случае, максимальное время
обработки всегда можно определить статически. Ниже показано
DSDL-определение стандартного типа журнальной записи под именем
uavcan.diagnostic.Record, где можно
видеть, что максимальная длина сообщения задана явно и ограничена
112-ю байтами (кодировка всегда UTF-8):
# Generic human-readable text message for logging and displaying purposes.# Generally, it should be published at the lowest priority level.uavcan.time.SynchronizedTimestamp.1.0 timestamp# Optional timestamp in the network-synchronized time system; zero if undefined.# The timestamp value conveys the exact moment when the reported event took place.Severity.1.0 severityuint8[<=112] text# Message text.# Normally, messages should be kept as short as possible, especially those of high severity.@assert _offset_ % 8 == {0}@assert _offset_.max <= (124 * 8) # Two CAN FD frames max
В конце определения видно вспомогательные конструкции,
добавленные с целью статической проверки способности двух CAN FD
фреймов нести сообщение максимального размера.
В предшествующей секции было отмечено, что протокол реального
времени должен проектироваться с учётом доступных средств
реализации с соблюдением временных характеристик. Если
представление данных в гарантированное время в целом делается
возможным благодаря свойствам DSDL, своевременность их обработки на
нижних уровнях протокола (на транспортном, то есть) достигается
благодаря явно определённому потолку для всех ресурсов протокола.
Например, максимальное количество каналов издатель-подписчик в
системе ограничено (этот максимум, однако, очень высок десятка
тысяч каналов достаточно каждому), равно как и максимальное
количество узлов в сети. В спецификации рассматриваются
практические подходы к реализации транспортной логики (а именно,
демультиплексирования пакетов и реконструкции полезной нагрузки из
мультикадровых передач) с оценкой влияния различных методов на
асимптотическую сложность.
Третий аспект статичности следует из нашего крайне осторожного
обращения с распределённым состоянием (однажды я сделаю себе
татуировку на лицо с предупреждением о том, что все болезни идут от
взаимодействий с чрезмерным сохранением состояния). Отсутствие
явно синхронизируемых состояний между коллабораторами (между
издателем и подписчиком или между клиентом и сервером в случае
удалённого вызова процедур) позволяет вновь подключенному участнику
приступить к выполнению своих задач немедленно, без предварительных
процедур регистрации, обнаружения служб, и т.п. Это имеет значение
при анализе сценариев отказа, где критическое устройство
кратковременно отключается (например, в результате
непреднамеренного перезапуска) с последущим повторным
присоединением к сети.
Для примера я продемонстрирую сериализацию и публикацию
сообщения, определённого ниже, содержащего три константы и два
поля. Константы не участвуют в обмене, поскольку они и так известны
всем узлам, имеющим доступ к соответствующему определению типа.
Поля сериализуются в плоский остроконечный бинарный формат (младший
байт идёт первым) примерно как в ASN.1 UPER (другой порядок байт), но с местной
спецификой (ценители сериализации данных должны посмотреть мою
заметку, где я рассматриваю популярные форматы и сравниваю их с
DSDL).
uint16 VALUE_LOW = 1000uint16 VALUE_HIGH = 2000uint16 VALUE_MID = (VALUE_HIGH + VALUE_LOW) / 2# Рациональная арифметика произвольной точности!uint16 valueuint8[<=100] key # Динамический массив от 0 до 100 элементов.
Если мы, скажем, присвоим полям значения value=1234 и
key=Hello world!, результат в шестнадцатиричной
нотации будет следующим:
D2 04 0C 48 65 6C 6C 6F 20 77 6F 72 6C 64 21
Где D2 04 соответствует 1234, 0C длина
массива (если бы максимальная длина была более 255 элементов, тут
было бы два или четыре байта), и остаток приходится на
приветствие.
Публикация сообщения через классический CAN будет выглядеть
предельно незамысловато все счастливые CAN протоколы похожи друг на
друга (надо ли говорить, что в случае CAN FD всё вошло бы в один
кадр):
$ candump -decaxta any(7.925) vcan2 TX - - 1013373B [8] D2 04 0C 48 65 6C 6C A0 '...Hell.'(7.925) vcan2 TX - - 1013373B [8] 6F 20 77 6F 72 6C 64 00 'o world.'(7.925) vcan2 TX - - 1013373B [4] 21 F9 02 60 '!..`'
Лишний подозрительный байт в конце каждого кадра содержит
метаданные транспорта. В конце последнего кадра есть два байта
циклического избыточного кода для проверки корректности
декадрирования.
Колонка со значением 0x1013373B здесь представляет CAN ID, что
является битовой маской из нескольких полей с метаданными. Наиболее
интересным здесь является значение 0x1337 (4919 в десятичной
системе), которое называется идентификатором темы
(subject-identifier) в отличие от некоторых более сложных
протоколов (как DDS), UAVCAN не поддерживает именованные топики,
предлагая вместо них нумерованные темы (похоже на SOME/IP и
практически любой протокол поверх CAN). Это значение проектировщик
выбирает произвольно, сообразно своим представлениям о системе.
Теперь мы можем повторить упражнение для UAVCAN/UDP на
localhost. Wireshark, к сожалению, пока не имеет диссектора для
UAVCAN, да и пёс с ним, ведь и так всё ясно:
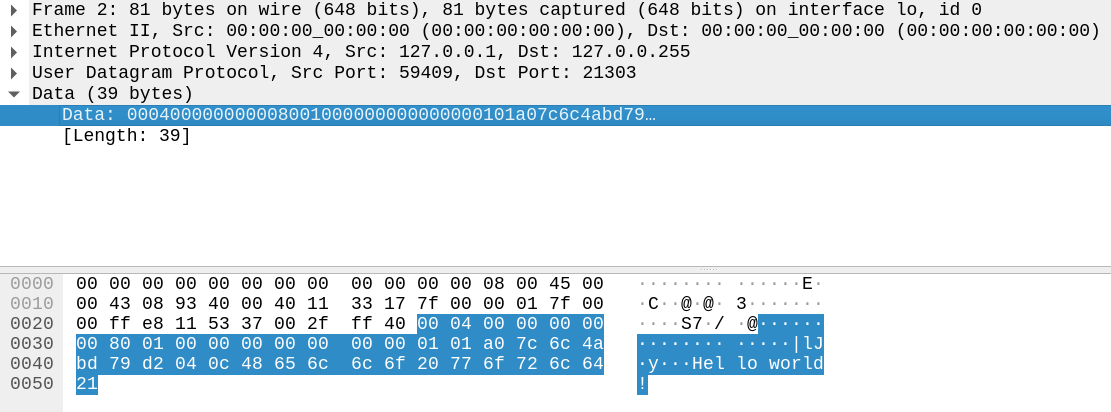
Дотошный читатель спросит, откуда взялся порт назначения 21303,
на что я отвечу, что он вычисляется как сумма идентификатора темы
(4919 у нас) и фиксированного смещения 16384. Смещение выбрано
таким образом, чтобы сдвинуть порты UAVCAN в эфемерный диапазон с целью минимизации
конфликтов. Исходный порт полезной информации не несёт и выбирается
произвольно. Нашу полезную нагрузку (D2 04 0C ...)
предваряют 24 байта метаданных, добавленных стеком UAVCAN; там
содержится информация о приоритете, фрагментах (тут их нет) и
последовательном номере сообщения.
Будет ошибкой думать, что внедрение UAVCAN/UDP в обязательном
порядке требует полного IP стека. Когда на практике поднимается
вопрос об IP стеке, обычно подразумевается TCP/IP, сложность
которого несопоставима с UDP/IP. Последний можно собрать с нуля на
C в несколько сотен строк, как наглядно продемонстрировал Lifelover в 2011-м году в серии публикаций "Подключение микроконтроллера к локальной
сети".
Здесь практические упражнения мы заканчиваем, потому что
публикация не об этом. Желающим закатать рукава следует пройти в
библиотеку с говорящим названием PyUAVCAN, при помощи которой эти
примеры были получены (не будет лишним также заглянуть в руководство).
Нельзя обойти вниманием встроенную поддержку как гомогенной, так
и гетерогенной избыточности транспорта. Первый тип достаточно часто
встречается на практике, но особенно интересен последний в
предыдущей секции я отметил потенциал разнородной избыточности к увеличению
отказоустойчивости сети благодаря устранению отказов общего вида.
На транспортном уровне встроена логика дедупликации и
автоматического переключения между избыточными сетевыми
интерфейсами прозрачно для приложения. С практической стороной
реализации можно также ознакомиться в документации к PyUAVCAN.
Последним заслуживает рассмотрения уровень приложения.
Техническая сторона вопроса прозрачна: пользователь определяет
собственные типы с использованием DSDL, затем создаёт
соответствующие темы (топики) по мере надобности. Для
распространённых задач (мониторинг узлов, файлообмен, логирование,
управление конфигурацией, и т.п.) нет нужды конструировать
собственные сетевые сервисы, потому что соответствующие определения
предоставляются стандартным набором сервисов UAVCAN, из которого
можно свободно выбрать необходимые.
Поверх UAVCAN предполагается создание специализированных
отраслевых стандартов уровня приложения, примерно как стандартные
классы USB существуют поверх ядра USB, как профили CANopen или
Bluetooth, или как DDS FACE поверх DDS. Схематически мы это
изображаем следующим образом:
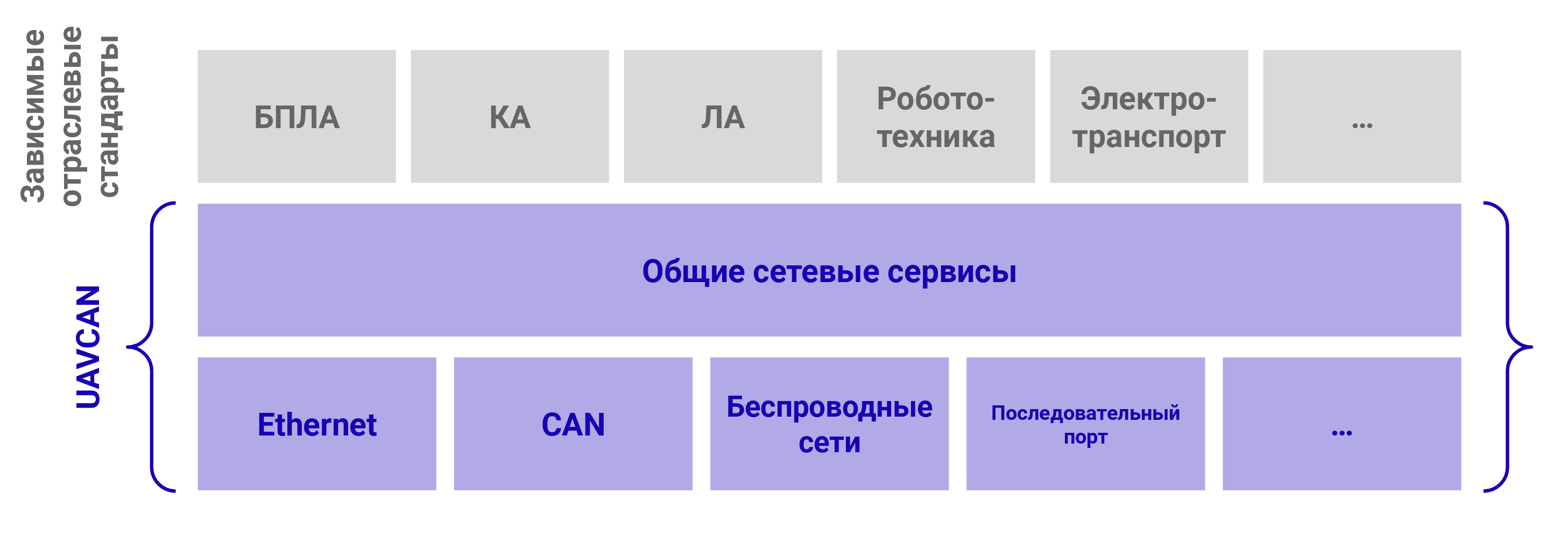
Из отраслевых стандартов сейчас в работе один так называемый
Drone Standard 15, или DS-015, к которому
активно прикладывают руки, среди прочих, компании из Dronecode Foundation. Мы предвидим появление других
отраслевых спецификаций в будущем, поскольку UAVCAN сегодня можно
встретить далеко за пределами одних только дронов но об этом
позже.
Техническая сторона здесь прозрачна, но есть и другая. Сложные
распределённые системы требуют дисциплинированного подхода к
проектированию сетевых сервисов и их интерфейсов. Контакты с
сообществом разработчиков встраиваемых систем показали, что эта
аудитория может глубоко разбираться в вопросах, традиционно
характерных для их области деятельности (реальное время,
операционные системы, связующее ПО, и т.п.), но при этом иметь
очень ограниченное представление о проектировании адекватных
сетевых сервисов. Накопленный опыт работы с несколько более
низкоуровневыми технологиями, по-видимому, подталкивает людей к
неуместному заимствованию практик, что неоднократно на нашем опыте
приводило к появлению дефектных интерфейсов, работа с которыми
наполовину состоит из страдания. Решение этой нетехнической
проблемы является столь же нетехническим мы опубликовали учебный
материал, где подробно объясняется, как выглядит сетевой сервис
здорового человека. Материал этот опубликован в официальном руководстве UAVCAN в главе Interface
Design Guidelines.
Внедрение
Прогресс в области вычислительной техники, элементов питания,
машинного обучения, генеративного проектирования и других передовых
областей порождает новые проекты транспортных систем, которые
зачастую реализуются малыми предприятиями при минимальном
финансировании и низкой стартовой вовлечённостью в релевантные
отрасли. Практические примеры автономных дронов и роботов,
электрических конвертопланов, кубсатов, робоавтомобилей, и т.п. в
изобилии присутствуют в новостных лентах, так что приводить их
здесь нет смысла. Каждое такое средство, будучи передовым продуктом
21-го века, критически зависимо от грамотной огранизации бортовых
вычислительных систем, и часто также несёт груз правового
регулирования и доказательства функциональной безопасности. Такие
проекты неспособны подняться без широкого применения именно
открытых стандартов и свободных решений, потому что как
коммерческие альтернативы, так и доморощенные велосипеды рискуют не
вписаться в бюджет. Стартап, скажем, с летательным аппаратом,
намеревающийся следовать стандартам консервативной аэрокосмической
отрасли на первом же шаге выложит десятки тысяч евро за PDF
документы; в то же время будет ошибкой думать, что внедрение этих
стандартов является необходимым или даже желательным условием для
успеха.
UAVCAN полностью открыт для распространения и внедрения, не
предписывает никаких лицензионных ограничений: вся документация
распространяется под CC BY 4.0, а исходный код референсных реализаций
под MIT. Вероятно, любой другой подход к лицензированию сегодня
обрёк бы проект на забвение.
Однако, несмотря на это, мы не исключаем появления в будущем
опционального платного членства с целью предоставления
дополнительных гарантий совместимости и функциональной безопасности
для заинтересованных членов. По состоянию на 2020 эта инициатива
находится в стадии вялого переливания из пустого в порожнее,
желающие могут причаститься на форуме.
Согласно принципам открытости, вся разработка ведётся в
полностью публичной манере на
форуме и на GitHub оба этих ресурса вместе содержат не меньше
90% дискуссий разработчиков по существу, так что любое
просочившееся в спецификацию решение оставляет перманентный
бумажный след. Этот подход радикально отличается от традиционных
практик, где обычно предполагается платное членство и участие в
закрытых сессиях, закрытых ревью стандартов и закрытых же списках
рассылок.
На гитхабе поддерживаются референсные библиотеки, среди которых
Libcanard минимальная реализация UAVCAN/CAN для
однокристалок на C11, объём кода которой фигурирует в названии этой
статьи. Также там базируется uavcan.rs мультитранспортная реализация на
Rust, которая по состоянию на июль 2020 ищет нового мейнтейнера.
Там же поддерживается Yukon десктопная программа на питоне-электроне для
разработки, отладки и диагностики UAVCAN сетей, представляющая
собой смесь RViz, Wireshark и LabView. Раньше у нас была ещё
утилита на PyQt для предыдущей экспериментальной версии протокола,
но теперь она устарела безнадёжно, и усилия сосредоточены на Yukon.
На форуме есть бесконечно длинные треды с обсуждениями, но
дальше обсуждений мы практически не продвинулись из-за острой
недостачи фронтендеров. На сегодня последнее демо выглядит так:
Некоторый интерес представляет использование API ROS
поверх UAVCAN вместо DDS. Смысл здесь в том, чтобы сделать
развитую экосистему пакетов ROS доступной в системах реального
времени и младших микроконтроллерах с использованием UAVCAN,
обеспечив при этом также нативную совместимость с обычными UAVCAN
устройствами, ничего не знающими о ROS. Краткая вводная дана в
заметке на форуме "An exploratory study: UAVCAN as a middleware for
ROS"; разыскиваются коллабораторы.
Среди множества компаний и учреждений, принимающих участие
развитии стандарта, следует особо выделить NXP Semiconductors. На недавней конференции они
представили неплохой доклад "Getting started using UAVCAN v1 with PX4 on the NXP
UAVCAN Board", демонстрирующей, в том числе, кое-какие их
новые референсы для UAVCAN приложений.
Не менее ценным партнёром является Amazon Prime Air со своим
крутейшим автономным доставочным дроном. Эти
господа производят не железо, а код копирайты Амазона щедро
разбросаны по нашим исходникам.
Законченное UAVCAN-совместимое железо вроде сервоприводов,
приводов электромоторов, системы воздушных сигналов, автопилотов,
систем впрыска топлива, всевозможных датчиков и отладочных плат
сегодня предлагают многие вендоры, чьё перечисление тут вряд ли
оправданно.
Согласно опросу, проведённому в конце 2019 года, а также
основываясь на наших личных контактах с интеграторами, UAVCAN
сегодня применяется в пилотируемых (~10% компаний) и беспилотных
(~80% компаний) летательных аппаратах, в малых космических
аппаратах (~5% компаний, на 2020 год на орбите есть около 20
кубсатов, согласно доступным нам данным), в микро транспорте (вроде
электросамокатов) и разнообразных робототехнических системах. Наша
выборка, впрочем, подвержена систематической ошибке и приводится
только в общеинформативных целях; распределение может не
соответствовать действительности. Краткая сводка по опросу доступна отдельно.
Статус и будущее проекта
Наша глобальная амбициозная цель-максимум: стать полноценной
альтернативой технологиям класса DDS для отказоустойчивых
высоконадёжных систем реального времени; стать стандартом де-факто
для новых видов интеллектуального транспорта.
Согласно опросу, главным препятствием на пути к цели являются
проблемы не технические, а социальные: 47% респондентов в последнем
опросе указало, что главным препятствием на пути внедрения UAVCAN в
новых разработках является низкая представленность технологии в
профессиональном дискурсе. Вероятно, просветительские публикации
вроде этой проекту помогут.
uavcan.org
Источники и материалы
- Digital Avionics Handbook (3rd edition) Spitzer, Ferrell,
2017
- Computers in Spaceflight: The NASA Experience Kent, Williams,
2009
- The Evolution of Avionics Networks From ARINC 429 to AFDX
Fuchs, 2012
- Communications for Integrated Modular Avionics Alena, 2007
- Safety and Certification Approaches for Ethernet-Based Aviation
Databuses Yann-Hang Lee et al, 2005
- The Design of the TAO Real-Time Object Request Broker Schmidt,
Levine, Mungee, 1999
- In Search of an Understandable Consensus Algorithm Ongaro,
Ousterhout, 2014
- Starlink is a very big deal Handmer, 2019
- Why ROS 2? Gerkey, 2015
- ROS on DDS Woodall, 2015
- Safe Micromobility Santacreu, 2020
- Understanding Service-Oriented Architecture Sprott, Wilkes,
2009
Документация и спецификации рассмотренных технологий в списке
источников не указаны.
Также см. наши публикации по теме:






