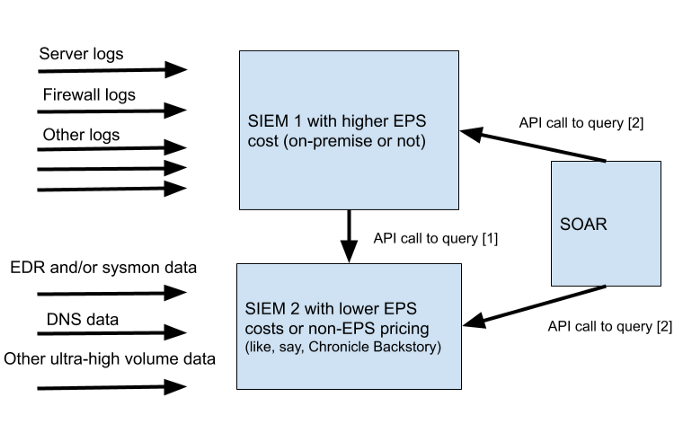
Современная корпоративная ИТ-инфраструктура состоит из множества
систем и компонентов. И следить за их работой по отдельности может
быть довольно сложно чем больше предприятие, тем обременительнее
эти задачи. Но есть инструменты, которые собирают в одном месте
отчеты о работе всей корпоративной инфраструктуры системы SIEM
(Security information and event management). О лучших из таких
продуктов по версии экспертов Gartner читайте в нашем обзоре, а об
основных возможностях узнайте из нашей
сравнительной таблицы.
Современная корпоративная ИТ-инфраструктура состоит из множества
систем и компонентов. И следить за их работой по отдельности может
быть довольно сложно чем больше предприятие, тем обременительнее
эти задачи. Но есть инструменты, которые собирают в одном месте
отчеты о работе всей корпоративной инфраструктуры системы SIEM
(Security information and event management). О лучших из таких
продуктов по версии экспертов Gartner читайте в нашем обзоре, а об
основных возможностях узнайте из нашей
сравнительной таблицы.
Если говорить в двух словах, технология SIEM дает администраторам
обзор того, что происходит в сети. Такие системы в реальном времени
обеспечивают анализ событий безопасности, а также активности
устройств и пользователей, что позволяет реагировать на них до
того, как будет нанесен существенный ущерб.
Программы SIEM собирают информацию с серверов, контроллеров
доменов, файрволов и многих других сетевых устройств и
предоставляют ее в виде удобных отчетов. Эти данные не обязательно
связаны с безопасностью. С их помощью, например, можно понять, как
функционирует сетевая инфраструктура и разработать план по ее
оптимизации. Но главное, конечно, это обнаружение потенциальных
брешей, а также локализация и ликвидация существующих угроз. Такие
данные предоставляются благодаря сбору и объединению данных
журналов сетевых устройств.
После сбора информации (эта процедура происходит автоматически с
заданными интервалами) происходит идентификация и классификация
событий. Затем (опять же, в соответствии с заданными настройками)
отправляются оповещения, что те или иные действия оборудования,
программы или пользователи могут быть потенциальными проблемами
безопасности.
Какие возможности открываются?
SIEM помогает решать целый ряд задач. Среди них: своевременное
обнаружение целенаправленных атак и непреднамеренных нарушений
информационной безопасности со стороны пользователей, оценка
защищенности критически важных систем и ресурсов, проведение
расследований инцидентов и многое другое.
При этом у SIEM-платформ есть ряд ограничений. Они, например, не
умеют классифицировать данные, зачастую плохо работают с
электронной почтой, имеют слепые пятна в отношении собственных
событий. И, конечно, не могут полностью покрыть вопросы
информационной безопасности на предприятии. Но вместе с этим они
являются важной частью защитной системы предприятия, пусть и не
критически важной. Тем более развитие SIEM-платформ не стоит на
месте. Например, в некоторых современных продуктах есть
аналитические функции, то есть они не просто выдают отчеты и
указывают на потенциальные проблемы, но и умеют сами анализировать
события и принимать решения об информировании о тех или иных
событиях.
В любом случае, при выборе конкретного продукта следует
ориентироваться на множество параметров, среди которых выделим
централизованный сбор, обработку и хранение информации, оповещение
об инцидентах и анализ данных (корреляция), а также ширину охвата
корпоративной сети. И, конечно, по возможности, перед покупкой
стоит запустить пробную/демо версию и посмотреть, насколько она
подходит для компании.

SIEM-платформа от технологического гиганта
IBM является одной из самых продвинутых на рынке: даже в
квадранте лидеров Gartner она стоит выше конкурентов, причем
попадает туда уже 10 лет подряд. Продукт состоит из нескольких
интегрированных между собой систем, которые вместе обеспечивают
максимальный охват происходящих в сети событий, а множество функций
работают прямо из коробки. Инструмент умеет собирать данные из
разнообразных источников, например, операционных систем, устройств
безопасности, баз данных, приложений и многих других.
QRadar Security Intelligence умеет сортировать события по
приоритетности и выделять те, которые несут наибольшую угрозу
безопасности. Это происходит благодаря функциям анализа аномального
поведения объектов (пользователей, оборудования, служб и процессов
в корпоративной сети). В том числе определяются действия, связанные
с обращением к подозрительным IP-адресам или запросам от них.
Касательно всех подозрительных действий предоставляются подробные
отчеты, что, например, дает возможность обнаружить подозрительные
действия в нерабочее время. Подобный подход в комбинации с
функциями мониторинга пользователей и наглядным представлением сети
на уровне приложений позволяет бороться с угрозами инсайдеров.
Кроме того, при обычных кибератаках информация поступает очень
быстро и позволяет предотвратить их до того, как они достигнут цели
и нанесут существенный ущерб.

Одна из главных особенностей IBM QRadar Security Intelligence
обнаружение и расстановка приоритетов на основе рисков с
использованием расширенного анализа и корреляции между активами,
пользователями, сетевой активностью, имеющимися уязвимостями,
анализом угроз и т. д. IBM Qradar может связывать события в одну
цепочку, создавая для каждого инцидента отдельный процесс.
Благодаря тому, что информация собирается и выводится на экран в
одном месте, администратор может видеть все связанные
подозрительные действия, которые были обнаружены системой. А новые
связанные события добавляются в единую цепочку, так что аналитики
не должны переключаться между несколькими оповещениями. А для более
глубоких расследований специальный инструмент IBM QRadar Incident
Forensics может восстановить все сетевые пакеты связанные с
инцидентом и пошагово воссоздать действия злоумышленника.

Одна из ведущих в отрасли платформ, отличительной чертой которой
является широкий перечень источников информации, с которыми она
работает.
Splunk
Enterprise Security умеет собирать журналы событий с традиционных
компонентов сети (серверов, устройств безопасности, шлюзов, баз
данных и т. д.), мобильных устройств (смартфонов, ноутбуков,
планшетов), веб-сервисов и распределенных источников. Собираемая
информация: данные о действиях пользователей, журналы, результаты
диагностики и др. Это позволяет проводить удобный поиск и анализ в
автоматическом и ручном режиме. Решение имеет множество
настраиваемых уведомлений, которые на основе собранной информации
предупреждают об имеющихся угрозах и заблаговременно сообщают о
потенциальных проблемах.
Продукт состоит из нескольких модулей, которые отвечают за
проведение расследований, логических схем защищаемых ресурсов и
интеграцию со множеством внешних сервисов. Такой подход дает
возможность проводить детальный анализ по множеству параметров и
устанавливать взаимосвязь между событиями, которые, на первый
взгляд, никак не соотносятся друг с другом. Splunk Enterprise
Security позволяет сопоставлять данные по времени, расположению,
создаваемым запросам, подключением к разнообразным системам и
другим параметрам.

Инструмент также умеет работать с большими массивами данных и
является полноценной Big Data платформой. Большие массивы данных
могут обрабатываться как в реальном времени, так и в в режиме
исторического поиска, причем, как уже было сказано выше,
поддерживается огромное количество источников данных. Splunk
Enterprise Security может индексировать сотни ТБ данных в день,
поэтому его можно применять в корпоративных сетях даже очень
больших масштабов. Специальный инструмент MapReduce позволяет
быстро масштабировать систему горизонтально и равномерно
распределять нагрузки, благодаря чему производительность системы
всегда остается на приемлемом уровне. При этом пользователям
доступны конфигурации для кластеризации и аварийного
восстановления.

Решение от компании
McAfee
поставляется как в качестве физических и виртуальных устройств, а
также программного обеспечения. Оно состоит из нескольких модулей,
которые могут применяться как вместе, так и по отдельности.
Enterprise Security Manager обеспечивает постоянный мониторинг
корпоративной ИТ-инфраструктуры, собирает информацию об угрозах и
рисках, позволяет приоритезировать угрозы и быстро проводить
расследования. Для всей поступающей информации решение рассчитывает
базовый уровень активности и заранее создает уведомления, которые
поступят администратору, если рамки данной активности будут
нарушены. Также средство умеет работать с контекстом, что
существенно расширяет возможности анализа и обнаружения угроз, а
также снижает количество ложных сигналов.
McAfee ESM хорошо интегрируется с продуктами сторонних
производителей без использования API, что делает продукт
совместимым со многими другими популярными решениями в области
безопасности. Также у него есть поддержка платформы McAfee Global
Threat Intelligence, которая расширяет традиционную
функциональность SIEM. Благодаря ей, ESM получает постоянно
обновляющуюся информацию об угрозах со всего мира. На практике это
дает, например, возможность обнаруживать события связанные с
подозрительными IP-адресами.

Для повышения производительности системы разработчик предлагает
своим клиентам набор инструментов McAfee Connect. Эти средства
содержат готовые конфигурации, помогающие выполнять сложные
сценарии использования SIEM-системы. Например, пакет материалов по
анализу поведения пользователей позволяет лучше и быстрее находить
скрытые угрозы, делает операции по обеспечению безопасности более
точными и существенно сокращает сроки расследований инцидентов. А
пакет для Windows позволяет мониторить службы этой ОС для оценки их
надлежащего использования и обнаружения угроз. Всего доступно более
50 пакетов для разных сценариев, продуктов и соответствия
стандартам.

Компания
AlienVault недавно объединилась с AT&T Business под брендом
AT&T Security, но ее ведущий продукт пока продается под старым
названием. Этот инструмент, как и большинство других платформ из
обзора, имеет более широкую функциональность, чем традиционный
SIEM. Так, в AlienVault USM есть разнообразные модули, отвечающие
за контроль активов, полный захват пакетов и т. д. Платформа также
умеет проводить тестирование сети на наличие уязвимостей, причем
это может быть как разовая проверка, так и непрерывный мониторинг.
В последнем случае, уведомления о наличии новой уязвимости
поступают практически одновременно с их появлением.
Среди других возможностей платформы проведение оценки уязвимости
инфраструктуры, которое показывает, насколько сеть защищена, а ее
настройка соответствует стандартам безопасности. Платформа также
умеет определять атаки на сеть и своевременно оповещать о них. В
таком случае администраторы получают подробную информацию о том,
откуда идет вторжение, какие части сети подверглись атаке и какие
методы используют злоумышленники, а также, что необходимо
предпринять для отражения в первую очередь. Кроме того система
умеет определять инсайдерские атаки изнутри сети и оповещать о
них.

При помощи фирменного решения AlienApps платформа USM умеет
интегрироваться с решениями безопасности многих сторонних
производителей и эффективно дополнять их. Эти средства также
расширяют возможности AlienVault USM в сфере настройки безопасности
и автоматизации реагирования на угрозы. Так, практически вся
информация о состоянии безопасности корпоративной сети становится
доступна непосредственно через интерфейс платформы. Эти инструменты
также дают возможность автоматизировать и организовывать ответные
действия при обнаружении угроз, что значительно упрощает и ускоряет
их обнаружение, а также реагирования на инциденты. Например, при
обнаружении связи с фишинговым сайтом, администратор может
отправить данные сторонней службе защиты DNS для автоматической
блокировки этого адреса таким образом, он станет недоступным для
посещения с компьютеров внутри организации.

SIEM-платформа от компании
Micro Focus, которую до 2017 года разрабатывала HPE, это
комплексный инструмент для обнаружения, анализа и управления
рабочими процессами в режиме реального времени. Средство
предоставляет широкие возможности по сбору информации относительно
состояния сети и происходящих в ней процессов, а также большой
набор готовых наборов правил безопасности. Множество функций в
ArcSight Enterprise Security Manager работают в автоматическом
режиме, среди которых, например, определение угроз и расстановка
приоритетов. Для проведения расследований данный инструмент может
интегрироваться с другим фирменным решением ArcSight Investigate. С
его помощью можно обнаруживать неизвестные угрозы и производить
быстрый интеллектуальный поиск, а также визуализировать данные.
Платформа умеет обрабатывать информацию с самых разнообразных типов
устройств, по заявлению разработчиков, таких насчитывается более
500. Ее механизмы поддерживают все распространенные форматы
событий. Собранная из сетевых источников информация преобразуется в
универсальный формат для использования на платформе. Такой подход
позволяет быстро выявлять ситуации, которые требуют расследования
или немедленных действий и помогает администраторам сосредоточить
свое внимание на наиболее неотложных угрозах с высокой степенью
риска.

Для компаний с разветвленными сетями офисов и подразделений,
ArcSight ESM позволяет использовать модель работы SecOps, когда
удаленные группы безопасности объединяются и могут в режиме
реального времени обмениваться отчетностью, процессами,
инструментами и информацией. Так, для всех подразделений и офисов
они могут применять централизованные наборы настроек, политик и
правил, использовать унифицированные матрицы ролей и прав доступа.
Такой подход позволяет быстро реагировать на угрозы в какой части
компании они не появлялись бы.

Платформа от компании
RSA
(одного из подразделений Dell) представляет из себя набор модулей,
которые обеспечивают видимость угроз опираясь на данные от
разнообразных сетевых источников: конечных точек, NetFlow, защитных
устройств, информации из передаваемых пакетов и т. д. Для этого
используется комбинация из нескольких физических и/или виртуальных
устройств, которые в режиме реального времени обрабатывают
информацию и выдают на ее основе предупреждения, а также хранят
данные для возможности проведения расследований в будущем. Причем
разработчик предлагает архитектуру как для небольших компаний, так
и для крупных распределенных сетей.
NetWitness Platform умеет определять инсайдерские угрозы и работает
с контекстной информацией о конкретной инфраструктуре, что
позволяет расставить приоритетность предупреждений и оптимизировать
работу в соответствии со спецификой организации. Также платформа
умеет сопоставлять информацию об отдельных инцидентах, что
позволяет определить весь масштаб атак на сеть и настроить ее таким
образом, чтобы минимизировать подобные риски в будущем.

Разработчики много внимания уделяют работе с конечными точками.
Так, в RSA NetWitness Platform для этого есть отдельный модуль,
который обеспечивает их видимость как на уровне пользователя, так и
на уровне ядра. Средство умеет обнаруживать аномальную активность,
блокировать подозрительные процессы и оценивать степень уязвимости
конкретного устройства. А собранные данные учитываются в работе
всей системы и также влияют на общую оценку защищенности сети.

Облачная платформа от компании
FireEye
позволяет организациям контролировать любые инциденты, начиная от
оповещения о них и заканчивая исправлением ситуации. Она объединяет
в себе множество фирменных инструментов и может интегрироваться со
сторонними средствами. В Helix Security Platform широко применяется
аналитика поведения пользователей, которая распознает инсайдерские
угрозы и атаки, не связанные с вредоносными программами.
Для противодействия угрозам, средство не только использует
оповещения администраторов, но и применяет предустановленные наборы
правил, которых насчитывается около 400. Это позволяет
минимизировать количество ложных срабатываний и освободить
администраторов от постоянных проверок сообщений об угрозах. Кроме
того, система предлагает возможность проведения расследований и
поиска угроз, поведенческий анализ, поддержку множества ресурсов
для получения информации и удобное управление всем комплексом
безопасности.

Средство хорошо справляется с обнаружением продвинутых угроз. В
арсенале Helix Security Platform есть возможность интеграции более
300 инструментов безопасности как от FireEye, так и от сторонних
производителей. При помощи анализа контекста других событий, данные
инструменты обеспечивают высокий уровень обнаружения скрытых и
замаскированных атак.

Компания
Rapid7 предлагает клиентам облачную SIEM-платформу, заточенную
под анализ поведения. Система проводит глубокий анализ по логам и
журналам, а также расставляет специальные ловушки для выявления
нелегальных вторжений в сеть. Инструменты insightIDR постоянно
ведут наблюдения за деятельностью пользователей и соотносят их с
событиями в сети. Это не только помогает выявить инсайдеров, но и
предотвратить умышленные нарушения безопасности.
Rapid7 insightIDR постоянно мониторит конечные точки. Это дает
возможность увидеть необычные процессы, нетипичное поведение
пользователей, странные задачи и т. д. При обнаружении подобных
действий система позволяет проверить, повторяются ли они на других
компьютерах или остаются локальной проблемой. А при возникновении
проблем и расследовании инцидентов применяется визуальный
инструмент, который удобно систематизирует накопленные данные по
времени и существенно упрощает проведение расследований.

Для лучшего противодействия угрозам эксперты разработчика могут
самостоятельно оценить степень защищенности корпоративную среду,
начиная от оборудования и заканчивая текущими процессами и
политиками. Благодаря этому можно выстроить оптимальную схему
защиты сети с нуля при помощи Rapid7 insightIDR или же
усовершенствовать имеющиеся схемы работы.
Fortinet FortiSIEM

Комплексное и масштабируемое решение от
Fortinet
является частью платформы Fortinet Security Fabric. Решение
поставляется в виде физических устройств, но может использоваться
также на базе облачной инфраструктуры или в качестве виртуального
устройства. Средство обеспечивает широкий охват источников
информации поддерживаются более чем 400 устройства других
производителей. Среди них конечные точки, устройства интернета
вещей, приложения, средства безопасности и многое другое.
Платформа умеет собирать и обрабатывать информацию с конечных
точек, в том числе о целостности файлов, изменениях реестра и об
установленных программах и других подозрительных событий. FortiSIEM
имеет средства глубокого анализа, среди которых поиск событий в
реальном времени, а также прошедших событий, поиск по атрибутам и
ключевым словам, динамически изменяющиеся списки отслеживания,
которые используются для обнаружения критических нарушений и многое
другое.

Средство предоставляет администраторам полнофункциональные
настраиваемые панели мониторинга, которые существенно повышают
удобство работы с системой. У них есть возможность воспроизведения
слайд-шоу для демонстрации показателей работы систем, есть
возможность генерации разнообразных отчетов и аналитики, а для
выделения критических событий используется цветовая маркировка.
Вместо послесловия
На рынке есть очень большое количество SIEM-решений, большинство из
которых весьма функциональны. Зачастую их возможности выходят за
пределы стандартного определения SIEM и предлагают клиентам самые
разнообразные инструменты сетевого менеджмента. Причем многие
работают прямо из коробки, требуя минимального вмешательства при
установке и первоначальной настройке. Но тут есть и заковырка: они
могут различаться по десятками мелких параметров, рассказать о
которых в пределах одного обзора не представляется возможным.
Поэтому в каждом конкретном случае нужно подбирать решение не
только опираясь на главные потребности предприятия, но и учитывать
мелкие детали и будущий рост организации.
Мы обратили ваше внимание на основные моменты, а скрупулезно
разобраться в тонкостях и нюансах поможет тестирование пробных
версий продуктов. Благо, такую возможность предоставляют
практически все вендоры.
Автор: Дмитрий Онищенко