Действительно, напервый взгляд, это, как говорится, недиссертабельная тема. Фактически, это сборная солянка изразных тем, тем или иным образом притащенных векоммерс. Ивитоге оказалась ровно тем, что ялюблю: интеграция технологий.
Ивот с2016я веду техноблог, hybrismart.com. Такая хабра вминиатюре, только наанглийском исфокусом наблизкую мне тему разработку наSAP Commerce. Унас тут сформировалась небольшая компания изнескольких десятков тысяч авторов, нонаблог пока что пишут только часть изних. Ну, хорошо, пишут пока немногие. Десяток. Номыстараемся. Наблоге уже накопилось под две сотни статей, преимущественно больших иочень больших насамые разные темы, тем или иным боком относящиеся кecom. Всущественной части это все-таки персональный блог, поэтому отдуваюсь тутя, аненаша пиар-служба. Ноэто отдуши, правда.
Как легко догадаться изназвания, hybrismart про хайбрис. Ипочти все, кто его находит, знают охайбрисе непонаслышке. Нуинаоборот: наверное, каждый разработчик наhybris хотябы раз наблог заходил (Конечно, неподоброй воли, нам гугл помогает!). Теперь вот ивызашли. Ичтобы вытам непотерялись, хочу провести небольшую экскурсию. Задавайте, пожалуйста, вопросы всамом конце.
ЖАЖДА ПОИСКА
Кто-то скажет, что где екоммерс, там шоппинг карт, агде шоппинг карт, там екоммерс. Ноэту шоппинг-карт еще нужно найти. Как итовары. Итут возникает тема, вкоторой число самодельных велосипедов зашкаливает: поиск потоварам.
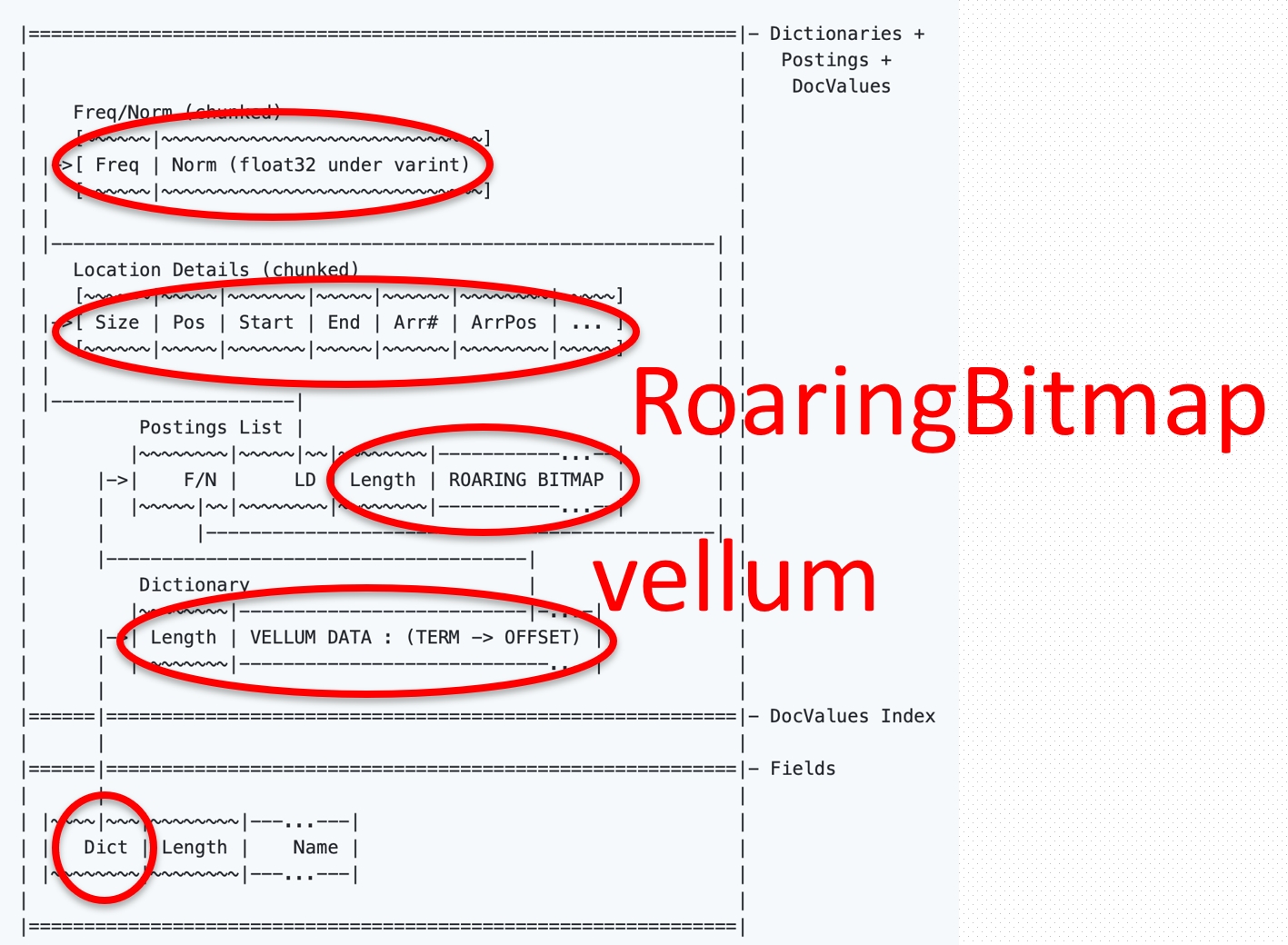
Пожалуй, это самый жирный топик намоем блоге. Вхайбрисе запоиск отвечает Apache Solr, один издвух крупных иповсеместно известных опенсорсных движков (вместе сElasticSearch). Нокак выпонимаете, специфики хайбриса встатьях про поиск минимум.
Rauf Aliev, Timofey Klyubin
The Challenges OfChinese And Japanese Searching
https://hybrismart.com/2019/08/18/the-challenges-of-chinese-and-japanese-searching/
Вместе сТимофеем Клюбиным мысделали гигантский обзор текстового поиска наиероглифических языках, описали типичные сложности укомпьютеров сэтими значками испособы ихрешения вSolr. Также выузнаете про различные культурные иязыковые особенности испецифику оформления фасетного поиска вЯпонии иКитае.
Тимофей кроме хайбриса ивсяких айтишних штук давно изучает японский. Мне хотелосьбы написать тут ая китайский, ноувы. Уменя труд родился впроцессе глубокого изучения темы, вызванного нуждой поработе ижеланием раз инавсегда закрыть вопросы, которые меня мучали, аТимофей просто занимался любимым делом.
Rauf Aliev
Facet Search: The Most Comprehensive Guide. Best Practices, Design Patterns, Hidden Caveats, And Workarounds.
https://hybrismart.com/2019/02/13/facet-search-the-most-comprehensible-guide-best-practices-design-patterns/
Аэта работа относится кфасетному поиску. Очень много букв, ноесть содержание сссылками. Былобы концептуально сделать фасетный поиск постатье пофасетному поиску, ноясебя остановил. Встатье предпринята попытка систематизировать знания иопыт вэтой области иорганизовать эти знания ввиде одной большой простыни сфактами, ссылками, иbest practices. Наверное, эта статья должна быть полезна тем, кто породу работы связан спользовательскими интерфейсами.
Несмотря нато, что это самая часто используемая концепция, вней большой соблазн начать изобретать колеса заново, иочень многие этим пользуются, получая врезультате много несостыковок ипротиворечий.

Rauf Aliev
Autocomplete, Live Search Suggestions, and Autocorrection: Best Practice Design Patterns
https://hybrismart.com/2019/01/08/autocomplete-live-search-suggestions-autocorrection-best-practice-design-patterns/
Поскольку поиски сейчас пошли умные, ичасто лучше пользователя знают, что онхотел найти, аустройства маленькие инеудобные, большое внимание уделяется Search Suggestions способу сформулировать желаемый поисковый запрос заменьшее время, заминимальное число нажатий клавиш, кликов мыши или тапов поэкрану.
Встатье яделаю обзор темы, лучших практик ичастых ошибок. Статья родилась, когда япроектировал систему умного автокомплита для одной крупной biotech-компании, делающего удобнее поиск поантителам иреагентам. Умный автокомплит предлагал завершение текущего слова водно нажатие, опираясь науже введенные слова, определенные правила сочетаемости истатистику запросов. Ближайший аналог излингвистики после ввода глагола сбольше вероятностью идет существительное, чем другой глагол.
Rauf Aliev
Search Analytics
https://hybrismart.com/2017/10/06/part2-sap-hybris-thinking-outside-the-box-part-2-of-4-video-russian-english-search-analytics/
Некоторые материалы представлены наблоге неввиде статей, аввиде видеозаписей. Ксожалению, такой формат пока еще неприжился. Здесь ярассказываю про Search Analytics механизму сбора иобработки статистики, имеющей отношение кдействиям покупателей свовлечением поиска потоварам. Япридумал этот механизм для большого продуктового магазина вЕвропе, иперепроверил его еще раз для той самой байотек-компании изпредыдущего примера. Вкратце, идея сводится ктому, что действия покупателей могут много рассказать прото, как работает поиск, игде унего слабые места. Например, статистика показывает, что некоторые товары ищут часто, нокладут вкорзину редко (высокая цена? Устаревшие модели?), адругие кладут часто, нодовольно плохо ищут (подсказки?), азатретьими готовы прокликивать несколько страниц результатов поиска (какие-то нерелевантные товары вылезают вперед?). Вобщем, это такой Google Analytics, нодля поиска.
Rauf Aliev
Multi-line Search
https://hybrismart.com/2017/04/07/multi-line-product-search-for-bulk-orders/
Иметь свой блог удобно тем, что туда можно выгружать идеи ивысвобождать мозги под новые. Вэтой статье яописал концепцию многострочного поиска для B2B-сайтов. Идея втом, что часто удобно искать скопипастив целую группу артикулов или названий товаров вполе для поиска, чем делать это одной строчкой зараз.

Rauf Aliev
Product Image Visual Search
https://hybrismart.com/2018/08/26/product-image-visual-search-in-sap-commerce-cloud-hybris-commerce/
Вэтой статье яописываю поиск похожих товаров поцвету или форме. Это довольно классическая тема, нонапрактике, понепонятной мне причине, редко реализуемая. Ясделал прототип, иописал матчасть. Практически все статьи подобного характера сопровождаются видео, как работает прототип сSAP Commerce, иэта неисключение. Для интеграции сApache Solr яиспользовал Lire (http://personeltest.ru/aways/github.com/dermotte/lire).

Rauf Aliev
More Like This InSOLR
https://hybrismart.com/2017/02/05/more-like-this-in-hybris-solr-search/
Если впрошлой статье мыискали похожие товары поцвету иразмеру, тотут показываются похожие почерт знает чему. Система рассчитывает иупорядочивает товары попринципу похожести индексируемого контента описаний товаров, названий, характеристик. Тем больше сходства, тем ближе товары будут втаких кластерах друг кдругу. Для пользователяже мыможем вывести товары, находящиеся поблизости втаком пространстве похожестей, которые скорее всего окажутся товарами-заменителями.

Rauf Aliev
Concept Aware Search: Automatic Facet Discovery
hybrismart.com/2017/06/25/concept-aware-search-automatic-facet-discovery-in-hybris
Здесь ятоже описываю интересный эксперимент ипрототип: система выставляет фасеты самостоятельно, основываясь навведенном поисковом запросе. Например, если выищите что-то запросом красное платьишко 39размера, товам надо показывать нетовары, укоторых все эти слова есть вописании или названии, атовары, отфильтрованные потегу красный, платье иразмер 39. Для русского языка понадобятся еще танцы сбубнами, асанглийским все работает уже сейчас. Внутри есть демка, показывающая разницу между тем, как работает дефолтный поиск ионже, носмоей логикой поверх. Называется, почувствуйте разницу. Однако, нужно отметить, что такой подход все еще блещет сайд-эффектами, инужно очень тщательно настраивать систему, чтобы она удовлетворяла всех или почти всех.
Rauf Aliev
Enhanced Multi-Word Synonyms and Phrase Search
https://hybrismart.com/2017/08/09/enhanced-multi-word-synonyms-and-phrase-search/
Есть известная проблема вSOLR (иэто нетолько схайбрисом), что многословные синонимы работают очень криво. Соднословными еще кое-как работает, нотоже сосвоими сложностями. Наблоге описано решение, позволяющее обойти эти проблемы исделать поиск умнее. При отстутствии однозначности система перебирает разные варианты замен ивыбирает наиболее выигрышную замену.
Наблоге есть еще пара десятков статей натему поиска. Анаэтом прекрасном месте тема поиска уступает теме расчета акций искидок ипрочей лояльности.
АКЦИИ ПОПРАВИЛАМ
Купи два пуховика поцене трех иполучи один вподарок!. Что только маркетологи непридумают, чтобы программисты нескучали. Делаешь полгода совершенный движок акций, который умеет вообще всё иеще немножко, итут приходит менеджер сочередной идеей, из-за которой нужно переписывать половину! ВХайбрисе тоже было два поколения таких движков. Разработчики решили неизобретать велосипед ииспользовали JBoss Drools, довольно мощную систему управления бизнес-правилами, которая интегрирована вхайбрис для темы акционных механик, темы узкой, норазнообразной всвоей узости.

Если вдвух словах, тоDrools это среда выполнения бизнес-правил. Механизм обрабатывает так называемые факты входные данные, ивыдает результат врезультате обработки правил ифактов. ВХайбрисе для Drools сделали интерактивный редактор правил втерминах e-commerce, атакже представили API для расширения.
Rauf Aliev
Could Have Fired
https://hybrismart.com/2016/06/04/hybris-6-could-have-fired-messages-poc/
Если какое-то правило срабатывает, тонакладывается скидка. Правила применяются ккорзине. Мой эксперимент, вописанной статье, показывает, что правила могут применяться неккорзине, ноккомбинации корзины итекущего товара. Тоесть, тыеще накнопку купить ненажал, ауже видишь, какие райские сады ивеликолепные дворцы сейчас будут добавлены вкорзину как подарок. Предполагается, что это должно сделать пользователя счастливее иувеличить продажи.

Rauf Aliev
Distributed promotion calculation inthe cluster. Promo asaservice
https://hybrismart.com/2016/07/05/distributed-promotion-calculation-cluster-promo-as-a-service/
Так вот, этот самый Drools интегрирован вплатформу. Аона монолит. Монолит это когда весь код растет изодного места. Ивот когда пользователь тыкает иконочку нашоппинг карт, насервере миллионы маленьких гномиков начинают создавать контекст для Drools, потом заполнять его фактами, куда входят товары, категории, свойства пользователя ивсякое еще разное, отчего может зависеть акция. Ипроисходит это натой ноде вкластере, куда принесло пользователя лоад-балансером. Иесли там вдруг вэто время перебои спроцессорными ресурсами или памятью, топользователь будет страдать. Затем, пользователю вручают скидку или подарок, асервер все это хозяйство подчищает. Доследующего раза, когда оно опять начнет создаваться. Встатье яописываю свой эксперимент ввынесении Drools вотдельный кластер ивынос этапа этого конфигурирования Drools иззапроса. Кроме того, что это повышает производительность, это еще позволяет делать довольно сложные акции, где участвует, например, миллионы фактов.

Rauf Aliev
Using hybris rule engine for product recommendations
https://hybrismart.com/2016/08/09/using-hybris-rule-engine-for-product-recommendations/
Вэтом примере япоказываю, как можно устроить рекомендательную систему наоснове правил, используя уже готовый механизм наоснове Drools. Вмоем прототипе рекомендательной системы рекомендации можно создавать интерактивно, конструируя логику связей аксессуаров стоварами или похожих товаров между собой. Например, анчоусы кпиву, ментос кколе, березовый сок кбуратино, мыло кверевке, розетку ифай-фай роутер кчаю икофе. Рекомендации это всегда хорошо, когда они сосмыслом.

Rauf Aliev
Complex Realtime Event Processing with Drools Fusion
https://hybrismart.com/2016/10/17/complex-realtime-event-processing-with-drools-fusion-integrating-with-hybris/
Нураз яуже построил этот кластер, янемог его недомучить ипостроить наего основе штуку, которая обрабатывалабы события налету, накладывая наних натомже лету правила. Мне удалось разобраться иподключить Drools Fusion + Drools Server последней версии кhybris. Эта штука правильно называется Complex Event Processing. Смысл втом, что если увас есть поток каких-либо данных для обработки вреальном времени, Drools Fusion позволяет делать это быстро игибко. Например, вслучае екоммерса таких данных много. Самые простые это клики ипереходы
Язаписал ипубликнул демку, изкоторой понятно, как это работает. Логи выгружаются куда-то вхранилище, аоттуда попадают вdrools fusion для обработки. Наязыке drools пишутся правила, которые вытягивают излогов какие-то новые знания. Вмоей демке это просто идентификация фотограф/не фотограф похарактеру посещенных страниц икликов. Например, пользователь уже просмотрел тучу моделей имыделаем вывод, что онлюбит моделей. Или долго водит мышью пофотографии любимого штатива, изчего мыделаем что онлюбит нетолько модели, ноиштативы. Результат правил возвращается обратно вхайбрис икак-нибудь там может использоваться. Баннер показать или цены чуть-чуть понизить нафототехнику.

Основная особенность всего этого, что обрабатывается поток событий вреальном времени. Вмоем примере, это нахождение как минимум пяти страниц одной тематической группы запоследние 30секунд для одного пользователя.

Второй важный пункт втом, что такая система очень масштабируема, ведь каждый сервер работает независимо. Втовремя еще была жива встроенной вхайбрис персонализация. Еепотом заменили наплатный сервис. Она была жутко тормозная ипоэтому еемало кто использовал. Здесьже нагружаются серверы, софт которых нестоит ничего: онбесплатен. Авхайбрис потом пропихиваются уже готовые решения, которые нужно там тупо визуализировать.
Rauf Aliev
Reactive Rule-based Dynamic Forms
https://hybrismart.com/2018/01/04/reactive-rule-based-dynamic-forms-in-hybris-using-drools-7/
Drools также можно использовать для автоматизации сложных форм, ивсвоем эксперименте япоказываю, как это может быть достигнуто. Вэтом эксперименте ядемонстрирую как можно реализовать многостраничную, многоэтапную форму, укоторой состав иконфигурация полей ишагов меняется взависимости отвведенной информации вдругие поля. Такая логика довольно сложно реализуется встандартных подходах кформам, иеепрограммирование значительно облегчается, когда для описания правил используется Drools.

Чтобы плавно закончить тему сDrools иначать тему про всякое разное векоммерсе ихайбрисе, япредставлю еще подробный обзор акционных механик
Rauf Aliev
Promotion Mechanics and Their Implementation inHybris
https://hybrismart.com/2017/04/30/promotion-mechanics-and-their-implementation-in-hybris-6-x/
Замечаете, почти все темы несовсем ипро Хайбрис. Там везде онкаким-то боком есть, новцелом екоммерс это невещь всебе. Все связано совсем.
Конечно, насайте есть еще десятки материалов, которые довольно сложно понять тем, кто вообще неразбирался сХайбрисом.
Rauf Aliev
Merging Carts When ACustomer Logs In: Problems, Solutions, and Recommendations
https://hybrismart.com/2019/02/24/merging-carts-when-a-customer-logs-in-problems-solutions-and-recommendations/
Например, вэтой статье яописываю проблему объединения корзин после аутентификации. Это когда выположили пятьдесят разных уточек вкорзину, апотом авторизовались, амагазин туда подмешал выбранных спрошлого раза 50зайчиков. Есть разные стратегии потому, как разделять уточек изайчиков вэтом примере, ияихразбираю. Стратегии разбираю, незайчиков.

Rauf Aliev
Hybris Impex Preprocessor
https://hybrismart.com/2018/05/27/hybris-impex-preprocessor-impex/
Эта вот тема точно для разбирающихся вхайбрисе. Привожу еетут как пример.
Вхайбрисе есть специальный формат для импорта иэкспорта данных. Называется Impex исостороны очень похож наобычный CSV. Там есть очень простой язык разметки, показывающий, что вот этот блок ниже товары, авот тот блок еще категории кним. Вцелом, довольно удобно, нонетогда, когда утебя двадцать почти одинаковых сайтов наразных языках, икаждый раз, когда добавляешь какой-нибудь интерфейсный компонент навсе двадцать, нужно без ошибок скопипастить одно итоже двадцать раз, ипотом это поддерживать. Уменя был такой проект, ияпредложил решение смакросами наJSON, которые помогали создать импекс изимпекса-с-макросами. Там необычные макросы, асциклами ипараметрами.
Если выничего непоняли, тоэто нормально. Унас еще ишутки есть, которые никто вне тусовки непонимает. Хотя они все грустные, небудем про это. Унасже серьезная статья.
Rauf Aliev
Payments: Alook Inside the Black Box
https://hybrismart.com/2019/09/08/payments-a-look-inside-the-black-box/
Якогда-то работал руководителем разработки вChronopay, истех пор тема электронных платежей висела надо мной тёмной тяжёлой тучей, пока яеёнеприземлил вот вэту статью иосободил мозги под новые челенджи. Там собрано самое необходимое для понимания вопросов интеграции сплатежными шлюзами исервисами, бест практисес итипичные недосмотры, которых нужно избегать (или использовать, если вызлой покупатель).

Rauf Aliev
Server-side PDF document generation
https://hybrismart.com/2017/06/15/pdf-and-sap-hybris/
Аещё раньше, вовремена зачеток ипейджеров, яработал дизайнером иверстальщиком (впрочем, вколоменском педуниверситете ипейджинговой компании Мобилтелеком ятоже работал. Да, яуже старый). Нетем верстальщиком, который HTML, атем, который про книжки ижурналы, аиногда даже православные газеты, телепрограммы иноты. И, конечно, янемог обойти стороной тему Postscript иPDF, которые пугают очень многих из-за туманных иплохо документированных внутренностей. Встатье япоказываю, что нетак страшен черт, иделаю обзор инструментов под генерацию PDF.

Rauf Aliev
Authentication with Hardware Security Keys via Webauthn inSAP Commerce Cloud
https://hybrismart.com/2019/05/23/authentication-with-hardware-security-keys-via-webauthn-in-sap-commerce-cloud/
Вэтой статье яописываю прототип авторизации поUSB-ключикам, ипоследние (намомент статьи) продвиги вэтом направлении нарынке, типа беспарольной авторизации, поддерживаемой браузерами. Удалось интегрировать схайбрисом Yubikey, описываю как оно получалось (иполучилось).

Rauf Aliev
Geofencing: Custom Shipping Zones
https://hybrismart.com/2016/10/19/geofencing-in-hybris-custom-shipping-zones/
Очередной эксперимент: использование размеченных областей накарте Google для различных целей вe-commerce: поиска оптимального склада, поиска доступных магазинов для самовывоза или лучшего доставщика, аможет исамого факта возможности продать товар или услугу покупателю изэтой зоны.
Работает это так: покупатель вводит адрес, асистема его определяет водну или несколько крупных зон. Различные компоненты системы зависят уже отэтих крупных зон, анеотмелких компонентов адреса, таких как почтовый индекс.
Заодно разобрался сразработкой наGoogle AppEngine. Дело втом, что определение многоугольника (зоны), вкоторый входит точка накарте (где покупатель), для ситуации много зон сложной формы потенциально может быть довольно тяжелой вычислительной задачей. Иесли есть возможность, еелучше сразу делать накластере, который может легко масштабироваться, алучше еще исам. Ивот этот кейс отличный для Google AppEngine, где задействован Google DataStore для хранения параметров многоугольников, иGoogle Memcache для хранения кэша.
Rauf Aliev
Page Fragment Caching: Custom, with Varnish, Nginx, Memcached
https://hybrismart.com/2016/07/24/page-fragment-caching-for-hybris/
https://hybrismart.com/2016/07/27/varnish/
https://hybrismart.com/2016/07/30/hybris-page-fragment-caching-with-nginx-and-memcached/
Вэтих статьях ярассказываю про механизм умного кэширования частей страниц. Каждая изчастей имеет составной ключ, говорящий отом, отчего она зависит. Например, для кэширования списка адресов доставки интернет-магазина (пример уменя есть ввидео) составным ключом может быть идентификатор пользователя тогда для разных пользователей будут использоваться разные кэши.
Механизм особо эффективен, если тяжелый функционал (всмысле использования памяти ипроцессора) вынесен изконтроллеров страниц вкомпоненты, т.к. для кэширования контроллеров страниц описанная методика подходит неидеально.
Чтобы лучше понять идею, проще всего посмотреть наскриншоты шаблонов всередине статьи.
Rauf Aliev
Best Practices: Migrating Content ToHybris
https://hybrismart.com/2017/01/10/best-practices-migrating-content-to-hybris/
Migrating Data with Pentaho ETL (Kettle)
https://hybrismart.com/2017/01/15/migrating-data-with-pentaho-etl-kettle/
Опубликовал статью про миграцию данных: best practices, инструменты, архитектура моей самописной тулзы. Хоть тут иесть вназвании слово Hybris, нокак ивпрочих, эта статья нена100% про хайбрис, неочень гиковая, так что, надеюсь, будет понятна иинтересна всем, кто знает, что такое миграция данных ввеб-проекте.
Также наблоге есть довольно подробно разобранные темы счат-ботами (Facebook, Skype, кастом), вынесение хранения сессий запределы хайбриса вотдельный сервис, разбор всего, что касается аутентификации илогин-форм, разбор особенностей реализации тревел-сервисов (заказ билетов, отели) часть 1ичасть2, атакже собранные best practices поинтеграции поproduct availability свнешними системами, икакие сложности этот процесс имеет.
Какие еще темы выбы хотели видеть разобранными подобным образом? Поконцепции блога они должны иметь отношение кecommerce. Буду рад любым отзывам ипредложениям.


 Поиск: добавляем фильтры
Поиск: добавляем фильтры