
Холивар...
Одни умные люди говорят: "эксепшены - это зло, используйте монады!", другие кричат: "коды ошибок ещё никто не отменял!", а третьи включают механизм исключений в языки программирования.. Однако, у большинства статей, который попадались мне на глаза, есть (при всём уважении к авторам!) два проблемных момента:
-
Некоторая... академичность. Разобрано много и интересно, но заканчивается всё стандартным: "ваш выбор зависит от вашей ситуации".
-
Абсолютно отсутствуют упоминания о бюджете. Никто же не будет спорить, что теоретически мерседес лучше, чем восьмёрка по всем показателям кроме.. цены.
Задача этого поста - поделиться выработанным практическим рецептом. В конкретном фреймворке и с конкретными границами применимости. Без претензий на уникальность, универсальность и, тем более, академическую "правильность".
Прежде, чем перейти собственно к подходу, важно понять, что обработка ошибок - не самоцель. Это все лишь способ достижения цели. А цель в том, чтобы наше приложение работало стабильно и предсказуемо. При этом, необходимо уложиться в бюджет и, крайне желательно, нанести минимально возможный ущерб другим ценностям: поддерживаемости, читаемости и проч.

Стартовые условия.
Выделим основные: язык, фреймворк, тип приложения. Раскроем кратко каждый пункт:
ЯЗК
Платформа и ЯП, очень сильно влияют на выбор подходов по работе с ошибками.
К примеру, в go не стоит вопрос, использовать ли исключения - там их нет. В функциональных языках, в частности в F#, было бы очень странно не использовать монады или discriminated union'ы (возврат одного из нескольких возможных типов значений), т. к. это там это реализовано очень удобным и естественным образом. В C#, монады тоже можно сделать, но получается намного больше букв. А это не всем нравится, мне например - не очень. Правда, последнее время всё чаще упоминается библиотека https://www.nuget.org/packages/OneOf/, которая фактически добавляет в язык discriminated union'ы.
А к чему нас подталкивает javascript/typescript?... К анархии! Можно много за что ругать JS и вполне по делу, но точно не за отсутствие гибкости.
Скорее уж за сверхгибкость )). В общем, мы вольны делать так, как нам хочется. Но тут есть, небольшая проблема - когда у вас в команде 10 человек и каждый делает как ему хочется.. получается не очень. Даже если каждый подход в отдельности - неплох.
ФРЕЙМВОРК
С nestjs уже интереснее. Выброс исключений из прикладного кода предлагается нам в документации как основной механизм возврата неуспешных ответов. То есть, если взять обычное http приложение, то чтобы клиенту вернулся статус 404 нам надо бросить NotFoundException..
На самом деле, довольно спорная концепция. И это можно обойти, причём разными способами. Убеждённые сторонники монад вполне могут делать что-то такое:
@Controller()class SomeController { @Post() do (): Either<SomeResult, SomeError> { ... }}
Для этого, правда придётся написать кое-какой обвязочный код, но можно. Мы не стали.
Важно также, что Фреймворк делает практически всё для того, чтобы нам не приходилось заботиться об устойчивости процесса приложения . Nest сам выстраивает для нас "конвейер" обработки запроса и оборачивает всё это в удобный глобальный "try/catch", который ловит всё.
Правда иногда случаются казусыНапример в одной из старых версий nest'а мы столкнулись с тем, что ошибка, вылетевшая из функции переданной в декоратор @Transform() (из пакета class-transformer) почему-то клала приложение насмерть. В версии 7.5.5 это не воспроизводится, но от подобных вещей, конечно никто не застрахован.
ТИП ПРИЛОЖЕНИЯ
Самое важное. Мы не пишем софт для спутников. Там вряд ли можно было бы себе позволить что-то в стиле "сервис временно недоступен, попробуйте позже". Для нас же - это вполне ожидаемая ситуация. Нежелательная, конечно, но и не фатальная.
Мы пишем веб-сервисы. Есть http-сервисы, есть rpc (на redis и RabbitMQ, смотрим в сторону gRPC), гибридные тоже есть. В любом случае, мы стараемся внутреннюю логику приложения абстрагировать от транспорта, чтобы в любой момент можно было добавить новый.
Мы фокусируемся на том, что у нас есть запрос, есть его обработчик и есть ответ (который иногда void). И мы допускаем, что обработка запроса может по каким-то причинам оказаться неудачной. В этом случае, либо запрос будет повторён (успешно), либо будет зафиксирован и затем исправлен баг.
При таком подходе, важно, чтобы ошибки не могли привести данные в неконсистентное состояние. Помогают нам в этом две вещи:
-
Транзакционность. То есть, либо получилось всё, либо не получилось ничего.
-
Идемпотентность. Повторное выполнение одной и той же команды не ломает и не меняет состояние системы.
Транзакции (особенно распределённые) и идемпотентность выходят за рамки данной статьи. Но во многом, эти вещи являются основой надёжности.
Ближе к делу.
Наши принципы обработки ошибок базируются на следующих соглашениях:
КОНФИГУРАЦИЯ ПРИЛОЖЕНИЯ.
Конфигурация всегда считывается и валидируется только при старте приложения. Соответственно, об отсутствии каких-то переменных окружения или ещё чего-то, мы узнаём сразу, а не когда-нибудь потом. Достигается это вполне тривиально. Каждый модуль приложения, которому требуется конфигурация включает в себя класс примерно такого вида:
@Injectable()export class SomeModuleConfig { public readonly someUrl: URL;public readonly someFile: string;public readonly someArrayOfNumbers: number[]; constructor (source: ConfigurationSource) { // Бросит ConfigurationException если не удастся распарсить Url. Можно // также проверять его доступность, например, при помощи пакета is-reachable this.someUrl = source.getUrl('env.SOME_URL');// Бросит ConfigurationException если файл не существует или на него нет прав.this.someFile = source.getFile('env.SOME_FILE_PATH');// Бросит ConfigurationException если там не перечисленные через запятую числаthis.someArrayOfNumbers = source.getNumbers('env.NUMBERS') }}
Значения из конфигурации считываются только в конструкторах подобных классов и валидируются максимально строго.
Подход к валидацииМы написали свои валидаторы. Их преимущетсво в том, что мы не только валидируем данные, но в ряде случаев, можем сделать дополнительные проверки (доступность файла или удалённого ресурса, как в примере выше, например).
Однако, вполне можно использовать joi или json-схемы (может ещё есть варианты) - кому что больше нравится.
Неизменным должно быть одно - всё валидируется на старте.
УРОВНИ АБСТРАКЦИИ.
Мы максимально чётко разделяем бизнес-код и инфраструктурный код. И всё инфраструктурное выносим в библиотеки. Более менее очевидно, но всё же приведу пример:
// Задача: скачать файл по ссылке.const response = await axios.get(url, { responseType: 'stream' });const { contentType, filename } = this.parseHeaders(response);const file = createWriteStream(path);response.data.pipe(file);file.on('error', reject);file.on('finish', () => resolve({ contentType, filename, path }));
Такому коду не место не только в бизнес-логике, но вообще в приложении. В нём нет ничего уникального, привязывающего его к какому-то контексту. Ему место в библиотеке, скажем в классе NetworkFile. Вызывающий же код может выглядеть примерно так:
const file: NetworkFile = await NetworkFile.download('https://download.me/please', { saveAs: 'path/to/directory'});
Фактически, мы заворачиваем в подобные переиспользуемые "смысловые" абстракции почти все нативные нодовские вызовы и вызовы сторонних библиотек. Стратегия обработки ошибок в этих обёртках: "поймать -> завернуть -> бросить". Пример простейшей реализации такого класса:
export class NetworkFile {private constructor ( public readonly filename: string, public readonly path: string, public readonly contentType: string, public readonly url: string ) {} // В примере выше у нас метод download принимает вторым аргументов объект опций // Таким образом мы можем кастомизировать наш класс: он может записывать файл на диск // или не записывать, например. // Но тут для примера - самая простая реализация. public static async download (url: string, path: string): Promise<NetworkFile> { return new Promise<NetworkFile>(async (resolve, reject) => { try { const response = await axios.get(url, { responseType: 'stream' }); const { contentType, filename } = this.parseHeaders(response); const file = createWriteStream(path); response.data.pipe(file);// Здесь мы отловим и завернём все ошибки связанную с записью данных в файл. file.on('error', reject(new DownloadException(url, error)); file.on('finish', () => { resolve(new NetworkFile(filename, path, contentType, url)); }) } catch (error) { // А здесь, отловим и завернём ошибки связанные с открытием потока или скачиванием // файла по сети. reject(new DownloadException(url, error)) } }); }private static parseHeaders ( response: AxiosResponse ): { contentType: string, filename: string } { const contentType = response.headers['content-type']; const contentDisposition = response.headers['content-disposition']; const filename = contentDisposition// parse - сторонний пакет content-disposition ? parse(contentDisposition)?.parameters?.filename as string : null; if (typeof filename !== 'string') { // Создавать здесь специальный тип ошибки нет смысла, т. к. на уровень выше // она завернётся в DownloadException. throw new Error(`Couldn't parse filename from header: ${contentDisposition}`); } return { contentType, filename }; }}
Promise constructor anti-pattern
Считается не круто использовать new Promise() вообще, и async-коллбэк внутри в частности. Вот и вот - релевантные посты на stackoverflow по этому поводу.
Но мне кажется, что данный код - одно из встречающихся исключений. По крайней мере, мне не известно другого способа "промисифицировать" работу с потоками.
Уследить за потоком управления в таком маленьком классе (на самом деле, его боевая версия лишь немногим больше) - не проблема. А в итоге, вызывающий код работает только с одним типом исключений: DownloadException, внутрь которого завёрнута причина, по которой файл скачать не удалось. И причина носит исключительно информативный характер и не влияет на дальнейшую работу приложения, т. к.:
В БИЗНЕС-КОДЕ НИГДЕ НЕ НАДО ПИСАТЬ TRY / CATCH.
Серьёзно, о таких вещах, как закрытие дескрипторов и коннектов не должна заботиться бизнес-логика! Если вам прям очень надо написать try / catch в коде приложения, подумайте.. либо вы пишете то, что должно быть вынесено в библиотеку. Либо.. вам придётся объяснить товарищам по команде, почему именно здесь необходимо нарушить правило (хоть и редко, но такое всё же бывает).
Так почему не надо в сервисе ничего ловить? Для начала:
ЧТО М СЧИТАЕМ ИСКЛЮЧИТЕЛЬНОЙ СИТУАЦИЕЙ?

Откровенно говоря, в этом месте мы сломали немало копий. В конце концов, копья кончились, и мы пришли к концепции холивар-agnostic. Зачем нам отвечать на этот провокационный вопрос? В нём очень легко утонуть, причём мы будем не первыми утопленниками )
Наша концепция проста - при возникновении любой ошибки мы, без споров о её исключительности, завершаем работу обработчика. Никакого геройства - никто не пытается спасать положение!
Не смогли считать файл - до свиданья. Не смогли распарсить ответ от стороннего API - до свидания. В базе duplicate key - до свидания. Не можем найти указанную сущность - до свидания. Максимально просто. И механизм throw, даёт нам удобную возможность осуществить этот быстрый выход без написания дополнительного кода.
В основном исключения ругают за две вещи:
-
Плохой перформанс. Нас это не очень волнует, т. к. мы не highload. Если он нас всё же в какой-то момент настигнет, мы, пересмотрим подходы там, где это будет реально критично. Сделаем бенчмарки... Хотя, готов поспорить, оверхед на исключения будет не главной нашей проблемой.
-
Запутывание потока управления программы. Это как оператор goto который уже давно не применяется в высокоуровневых программах. Вот только в нашем случае, goto бывает только в одно место - к выходу. А ранний return из функции - отнють не считается анти-паттерном. Напротив - это очень широко используемый способ уменьшить вложенность кода.
ВИД ОШИБОК
Говорят, что надо обрабатывать исключения там, где мы знаем, что с ними делать. В нашем слое бизнес-логики ответ будет всегда один и тот же: откатить транзакцию, если она есть (автоматически), залогировать всё что можно залогировать и вернуть клиенту ошибку. Вопрос в том, какую?
Мы используем 5 типов рантайм-исключений (про конфигурационные уже говорил выше):
abstract class AuthenticationException extends Exception { public readonly type = 'authentication';}abstract class NotAllowedException extends Exception {public readonly type = 'authorization';}abstract class NotFoundException extends Exception { public readonly type = 'not_found';}abstract class ClientException extends Exception { public readonly type = 'client';}abstract class ServerException extends Exception { public readonly type = 'server';}
Эти классы семантически соответствуют HTTP-кодам 401, 403, 404, 400 и 500. Конечно, это не вся палитра из спецификации, но нам хватает. Благодаря соглашению, что всё, что вылетает из любого места приложения должно быть унаследовано от указанных типов, их легко автоматически замапить на HTTP ответы.
А если не HTTP? Тут надо смотреть конкретный транспорт. К примеру один из используемых у нас вариантов подразумевает получения сообщения из очереди RabbitMQ и отправку ответного сообщения в конце. Для сериализации ответа мы используем.. что-то типа either:
interface Result<T> {data?: T; error?: Exception}
Таким образом, есть всё необходимое, чтобы клиентский код мог интерпретировать ошибку принятым у нас способом.
Базовый класс Exception выглядит примерно так:
export abstract class Exception { abstract type: string; constructor ( public readonly code: number, public readonly message: string, public readonly inner?: any ) {}toString (): string { // Здесь логика сериализации, работа со стек-трейсами, вложенными ошибками и проч... }}
Коды ошибок
Коды ошибок - это то, что мы начали внедрять буквально месяц назад, поэтому пока не могу уверенно говорить об их практической пользе. Мы надеемся на то, что они послужат двум целям:
-
Бывает такое, что клиентское приложение должно предпринять различные действия в зависимости от пришедшей от сервера ошибки. С кодами мы можем решить это не добавляя новых http статусов и без, прости Господи, парсинга сообщений.
-
Мы сможем автоматически сформировать и поддерживать индексированный справочник ошибок, которым потом будет пользоваться наша служба технической поддержки. Там будет более подробное описание ошибок, с указанием возможных способов их исправления, паролями и явками - куда бежать.
Насколько это всё нужно и полезно - жизнь покажет
Поле inner - это внутренняя ошибка, которая может быть "завёрнута" в исключение (см. пример с NetworkFile).
Реализации абстрактных дочерних классов содержат в себе только значение поля type. Это удобно для сериализации, но можно обойтись и без него. В буквальном смысле - тип ради типа.
ПРИМЕР ИСПОЛЬЗОВАНИЯ
Опустим AuthenticationException - он используется у нас только в модуле контроля доступа. Разберём более типовые примеры и начнём ошибок валидации:
import { ValidatorError } from 'class-validator';// ....export interface RequestValidationError { // Массив - потому что ошибка может относиться к нескольким полям. properties: string[]; errors: { [key: string]: string };nested?: RequestValidationError[]}// Небольшая трансформация стандартной ошибки class-validator'а в более удобный// "наш" формат.const mapError = (error: ValidationError): RequestValidationError => ({ properties: [error.property], errors: error.constraints, nested: error.children.map(mapError)});// Сами цифры не имеют значения.export const VALIDATION_ERROR_CODE = 4001;export class ValidationException extends ClientException { constructor (errors: ValidationError[]) { const projections: ValErrorProjection[] = ; super( VALIDATION_ERROR_CODE, 'Validation failed!', errors.map(mapError) ); }}
Иногда валидация производится в пайпе, иногда где-то в обработчике, но мы всегда хотим, чтобы на выходе был единообразный, удобный для нас формат. Заставить стандартный нестовый ValidationPipe выбрасывать то, что нам хочется можно просто передав функцию-фабрику в конструктор:
app.useGlobalPipes(new ValidationPipe({ exceptionFactory: errors => new ValidationException(errors); });)
Соответственно, на выходе наш ValidationException замапится на BadRequestException с кодом 400 - потому что он ClientException.
Другой пример, с NotFoundException:
export const EMPLOYEE_NOT_FOUND_ERROR_CODE = 50712;export class EmployeeNotFoundException extends NotFoundException { constructor (employeeId: number) { super( EMPLOYEE_NOT_FOUND_ERROR_CODE, `Employee id = ${employeeId} not found!` ); }}
Не очень приятно писать такие классы - всегда возникает лёгкое чувство... бойлерплейта ) Но зато, как приятно их потом использовать!
// Вместо, что не даст нам ни кодов, ни типа - ничего:throw new Error('...тут мы должны сформировать внятное сообщение...')// Простоthrow new EmployeeNotFoundException(id);
Сценарий использования NotAllowedException похож на предыдущий. Пользовать может иметь доступ к роуту getEmployeeById, но не иметь права запрашивать определённые категории работников. Соответственно, мы в сервисе можем проверить его доступ и выкинуть ошибку такого вида:
export const EMPLOYEE_NOT_ALLOWED_ERROR_CODE = 40565;export class EmployeeNotAllowedException extends NotAllowedException { constructor (userId: number, employeeId: number) { super( EMPLOYEE_NOT_ALLOWED_ERROR_CODE, `User id = ${userId} is not allowed to query employee id = ${employeeId}!` ); }}
Ну и наконец, все ошибки, в которых клиент не виноват: он имеет нужный доступ, запросил существующий ресурс и нигде не напутал с полями, и всё-таки облом - значит ServerException. Здесь я даже не буду особо приводить примеров - их множество. Но для клиента они всё одно - ошибка на сервере.
МАППИНГ
Мапятся внутренние ошибки на транспорто-специфичные в едином GlobalExceptionFilter, фильтр этот на вход получает один или несколько форматтеров. Задача форматтеров - преобразование вылетевшей ошибки в её конечный вид, можно сказать сериализация.
export interface IExceptionsFormatter { // Verbose - флаг, который мы держим в конфигурации. Он используется для того, // чтобы в девелоперской среде всегда на клиент отдавалась полная инфа о // ошибке, а на проде - нет. format (exception: unknown, verbose: boolean): unknown; // При помощи этого метода можно понять, подходит ли данных форматтер // для этого типа приложения или нет. match (host: ArgumentsHost): boolean;}@Module({})export class ExceptionsModule { public static forRoot (options: ExceptionsModuleOptions): DynamicModule { return { module: ExceptionsModule, providers: [ ExceptionsModuleConfig, { provide: APP_FILTER, useClass: GlobalExceptionsFilter }, { provide: 'FORMATTERS', useValue: options.formatters } ] }; }}const typesMap = new Map<string, number>().set('authentication', 401).set('authorization', 403).set('not_found', 404).set('client', 400).set('server', 500);@Catch()export class GlobalExceptionsFilter implements ExceptionFilter { constructor ( @InjectLogger(GlobalExceptionsFilter) private readonly logger: ILogger, @Inject('FORMATTERS') private readonly formatters: IExceptionsFormatter[], private readonly config: ExceptionsModuleConfig ) { } catch (exception: Exception, argumentsHost: ArgumentsHost): Observable<any> { this.logger.error(exception); const formatter = this.formatters.find(x => x.match(argumentsHost)); const payload = formatter?.format(exception, this.config.verbose) || 'NO FORMATTER'; // В случае http мы ставим нужный статус-код и возвращаем ответ.if (argumentsHost.getType() === 'http') { const request = argumentsHost.switchToHttp().getResponse(); const status = typesMap.get(exception.type) || 500; request.status(status).send(payload); return EMPTY; }// В случае же RPC - бросаем дальше, транспорт разберётся. return throwError(payload); }}
Бывает конечно, что мы где-то напортачили и из сервиса вылетело что-то не унаследованное от Exception. На этот случай у нас есть ещё интерцептор, который все ошибки, не являющиеся экземплярами наследников Exception, заворачивает в new UnexpectedException(error) и прокидывает дальше. UnexpectedException естественно наследуется от ServerException. Для нас возникновение такой ошибки - иногда некритичный, но всё же баг, который фиксируется и исправляется.
В принципе, это всё. Для 95% наших задач этого вполне хватает. Способ может и не "канонический", но удобный и вполне рабочий - то, к чему мы и стремились.
И всё же бывают ситуации
КОГДА ВСЁ НЕ ТАК ЯСНО.
Приведу два примера:
Первый. Операции допускающие частичный успех. Мы стараемся избегать таких вещей, но как избежать, если нам нужно реализовать загрузку данных из csv-файла а бизнес требует, чтобы при возникновении ошибок в отдельных строках, остальные всё же были загружены?
В таких случаях всё-таки приходится проявлять "фантазию", например, обернуть в try/catch обработку каждой строки csv-файла. И в блоке catch писать ошибку в "отчёт". Тоже не бином Ньютона )
Второй. Я сознательно не написал выше реализацию DownloadException.
export class DOWNLOAD_ERROR_CODE = 5506;export class DownloadException extends ServerException { constructor (url: string, inner: any) { super( DOWNLOAD_ERROR_CODE, `Failed to download file from ${url}`, inner ); }}
Почему ServerException? Потому что, в общем случае, клиенту всё равно почему сервер не смог куда-то там достучаться. Для него это просто какая-то ошибка, в которой он не виноват.
Однако, теоретически может быть такая ситуация, что мы пытаемся скачать файл по ссылке, предоставленной клиентом. И тогда, в случае неудачи, клиент должен получить 400 или может быть 404, но не 500.
Э... ну да, мы не будем так делать - т. к. это как минимум не очень безопасно ) Это лишь иллюстрация того, что подход не идеален и можно в нём найти такого рода нестыковки.
ЗАКЛЮЧЕНИЕ
Большое спасибо всем, кто дочитал до конца. Не думаю, что я в этой статье кому-то "открыл Америку". И я, конечно, далёк от навязывания кому-либо, чего-либо. И всё же, надеюсь, что эта попытка структурировать работу с ошибками для кого-то послужит отправной точкой в разработке собственного подхода под собственные задачи.
P. S. К сожалению, опенсорс в нашей компании в процессе согласования, поэтому привести реальный используемый код я не могу. Когда будет такая возможность, мы выложим на github библиотеку, при помощи которой работаем с исключениями. А за одно и некоторые другие пакеты, которые могут оказаться кому-то полезными.
P. P. S. Буду очень благодарен, за комментарии, особенно если в них будут практические примеры ситуаций, в которых у нас могут возникнуть трудности при использовании данного подхода. С удовольствием, поучаствую в обсуждении.




























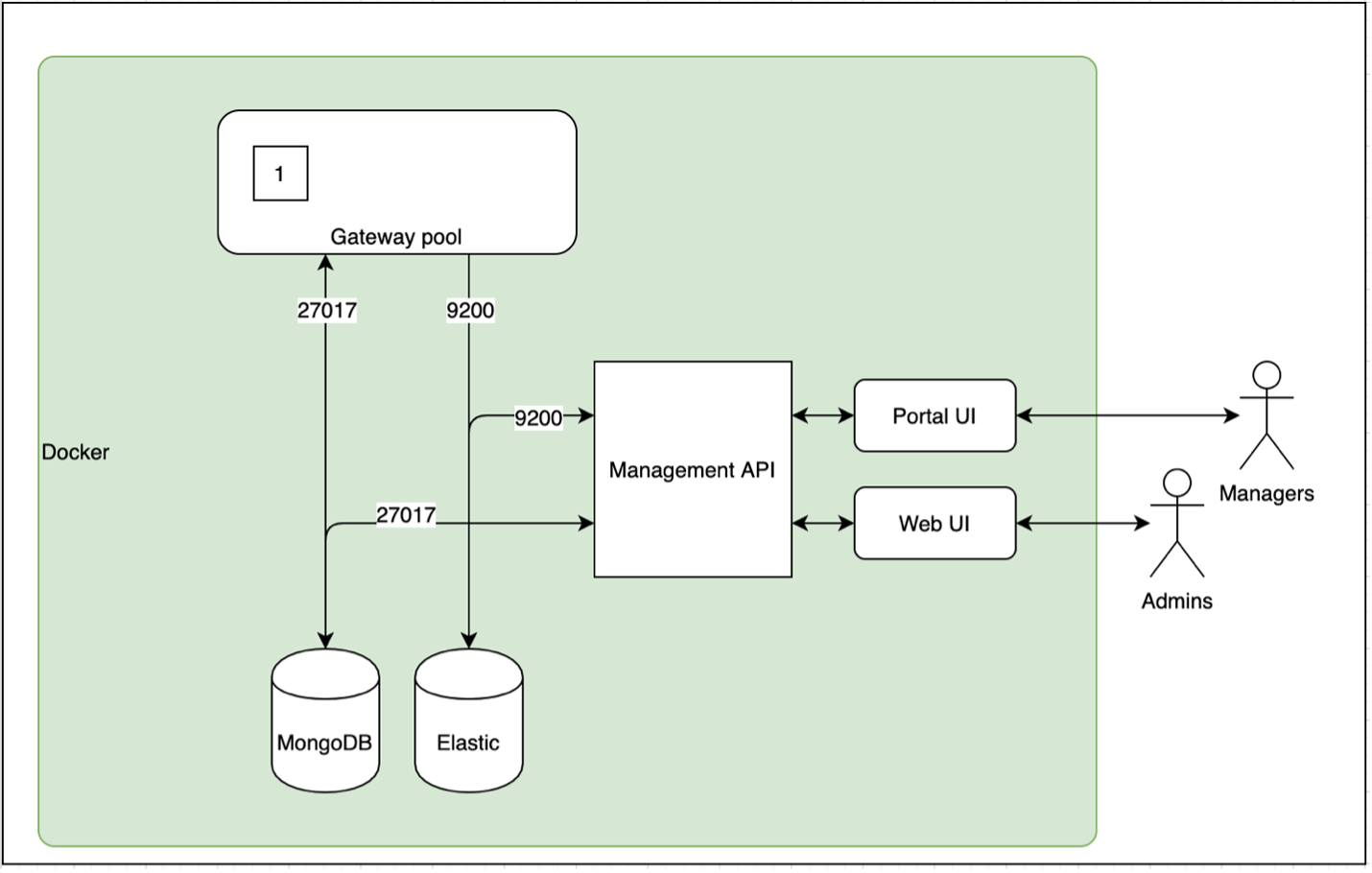


































 Формирование фида по схеме push on change
Формирование фида по схеме push on change
 Формирование фида по схеме pull on demand
Формирование фида по схеме pull on demand
 Распределение данных по уровням в Cassandra
Распределение данных по уровням в Cassandra
 Формирование фида на основе модуля с ZREVMERGE
Формирование фида на основе модуля с ZREVMERGE







