Этот текст предназначен для начинающих тестировщиков, желающих
понять как делать отчеты на allure с историей тестов, также
разъяснить где их хранить, чтобы в отчет мог заглянуть любой
участник вашей команды.
Когда я хотел добавить в gitlab автотесты в стеке python,
allure, docker, то я выяснил, что толковых статей на эту тему нет.
Пришлось разбираться самостоятельно и как результат проб и ошибок
появилась эта статья, которая скорее является гайдом, частично
затрагивающим написание тестов, но наибольший фокус именно на
выстраивании инфраструктуры. Если у вас уже написаны тесты на
allure, то вы сразу можете переходить к разделу настройки
инфраструктуры. Отмечу, что текст НЕ затрагивает написание UI
тестов, но я затрону инфраструктуру для них в отдельном блоке.
Здесь не описаны лучшие практики по написанию тестов и
выстраиванию инфраструктуры. Скорее ознакомление с тем, как можно
все это организовать. Примеры выполнены на windows, на других
системах подход примерно такой же.
Этот гайд предполагает, что у вас уже установлен python,
настроен пустой репозиторий, куда вы будете отправлять свой код.
При чтении статьи не обязательно знать pytest, но очень желательно
знать что из себя представляет фикстура, как ей пользоваться, а так
же параметризация тестов. Для тестирования будет использован
Dog
API. Если вас интересует локальный запуск тестов через gitlab,
то вам необходимо установить docker.
Если у вас не установлено вышеперечисленное ПО, то ниже вы
можете найти полезные ссылки:
Содержание
- Подготовка к написанию тестов
- Написание фикстуры и небольшого клиента для API тестов
- Пишем тесты
- Добавляем allure в тесты
- Делаем инфраструктуру для тестов
- Настройка репозитория
- Установка и настройка Gitlab Runner
- Настройка пайплайна в .gitlab-ci.yml
- Запуск тестов и просмотр отчета
- Настройка пайплайна для UI тестов
- Полезные ссылки
Подготовка к написанию
тестов
Я назвал свой репозиторий для этой статьи
allure_pages и скопировал его на свой компьютер.
Нужно создать такую структуру в директории с репозиторием:

conftest.py будет использован для написания
фикстурrequirements.txt для установки необходимых модулей
в контейнере с pythontest_dog_api.py внутри отдельной директории tests
для написания самих тестов
Далее создаем виртуальное окружение, которое будет
использоваться для локального запуска тестов. В папке с проектом
создаем его через командную строку с помощью следующей команды:
python -m venv venv
Открываем папку с репозиторием как проект в PyCharm

Удобнее всего, на мой взгляд устанавливать нужные нам пакеты
через встроенный в PyCharm терминал. Для этого нужно добавить
интерпретатор, и открыть терминал.
- Жмем на
Add Interpreter и если вы ранее создали в
директории с проектом виртуальное окружение, то PyCharm сразу
найдет нужный интерпретатор, который будет использован в
проекте
- Открываем терминал по этой кнопке

Устанавливаем нужные пакеты для наших тестов в
виртуальном окружении:
Для этого введите в терминал следующие команды.
pip install requests для запросов, которые мы
будем делать к сервису Dog Apipip install pytest для тестов, само собойpip install pytest-xdist для параллелизации
тестовpip install allure-pytest для генерации отчетов в
allure
Очень важно после этого написать в терминале
pip freeze > requirements.txt.
Файл requirements.txt нам понадобится для
запуска тестов внутри докер контейнера.
Написание фикстуры и небольшого клиента для API тестов
Для того, чтобы упростить наши тесты создадим небольшой клиент
для GET и POST запросов. Далее будет подробное описание этого
клиента. Если вам это не нужно или кажется сложным, то пропустите
эту часть статьи и переходите к следующей. На примере её
использования станет ясно как пользоваться клиентом.
Сама фикстура
@pytest.fixturedef dog_api(): return ApiClient(base_address="http://personeltest.ru/aways/dog.ceo/api/")
Ниже конструктор класса для клиента. При инициализации объекта
класс принимает в себя аргумент base_address, на его место нужно
записать в фикстуре общий адрес для всех запросов в нашем случае
будет использован https://dog.ceo/api/. Обратите
внимание, что фикстура возвращает объект с базовым адресом для
дальнейших GET и POST запросов.
class ApiClient: def __init__(self, base_address): self.base_address = base_address
Добавим в класс метод GET для отправки запросов.
def get(self, path="/", params=None, headers=None): url = f"{self.base_address}{path}" return requests.get(url=url, params=params, headers=headers)
Здесь можно заметить, что наш клиент является оберткой над
библиотекой requests. В классе ApiClient аргументы
path, params, headers метода
get выступают в роли аргументов, которые передаются в
requests.get(url=url, params=params, headers=headers).
Именно эта строчка и отвечает за выполнение запросов. Из адреса,
использованного при инициализации объекта и пути, который мы
передадим в дальнейшем в ходе теста, будет складываться полный
адрес, который и будет использоваться в
requests.get.
Добавим в класс метод POST. Его логика идентична, просто
добавляется несколько аргументов, которые при желании можно
заполнить данными.
def post(self, path="/", params=None, data=None, json=None, headers=None): url = f"{self.base_address}{path}" return requests.post(url=url, params=params, data=data, json=json, headers=headers)
В итоге у нас получается такой файл conftest.py:
import pytestimport requestsclass ApiClient: def __init__(self, base_address): self.base_address = base_address def post(self, path="/", params=None, data=None, json=None, headers=None): url = f"{self.base_address}{path}" return requests.post(url=url, params=params, data=data, json=json, headers=headers) def get(self, path="/", params=None, headers=None): url = f"{self.base_address}{path}" return requests.get(url=url, params=params, headers=headers)@pytest.fixturedef dog_api(): return ApiClient(base_address="http://personeltest.ru/aways/dog.ceo/api/")
Пишем тесты
В самом сервисе Dog API есть много разных запросов. Если у вас
есть опыт в написании тестов, то можете самостоятельно написать
несколько тестов. Так как акцент в этой статье заключается в
постройке инфраструктуры для тестов, я не буду вдаваться в
подробности тестов. Ранее я это сделал, чтобы мой код был более
менее понятен. Несколько параметризованных тестов специально
сломаны, чтобы показать как они будут показаны в отчете. Так
выглядит мой файл с тестами test_dog_api.py
import pytestdef test_get_random_dog(dog_api): response = dog_api.get("breeds/image/random") with allure.step("Запрос отправлен, посмотрим код ответа"): assert response.status_code == 200, f"Неверный код ответа, получен {response.status_code}" with allure.step("Запрос отправлен. Десериализируем ответ из json в словарь."): response = response.json() assert response["status"] == "success" with allure.step(f"Посмотрим что получили {response}"): with allure.step(f"Вложим шаги друг в друга по приколу"): with allure.step(f"Наверняка получится что-то интересное"): pass@pytest.mark.parametrize("breed", [ "afghan", "basset", "blood", "english", "ibizan", "plott", "walker"])def test_get_random_breed_image(dog_api, breed): response = dog_api.get(f"breed/hound/{breed}/images/random") response = response.json() assert breed in response["message"], f"Нет ссылки на изображение с указанной породой, ответ {response}"@pytest.mark.parametrize("file", ['.md', '.MD', '.exe', '.txt'])def test_get_breed_images(dog_api, file): response = dog_api.get("breed/hound/images") response = response.json() result = '\n'.join(response["message"]) assert file not in result, f"В сообщении есть файл с расширением {file}"@pytest.mark.parametrize("breed", [ "african", "boxer", "entlebucher", "elkhound", "shiba", "whippet", "spaniel", "dvornyaga"])def test_get_random_breed_images(dog_api, breed): response = dog_api.get(f"breed/{breed}/images/") response = response.json() assert response["status"] == "success", f"Не удалось получить список изображений породы {breed}"@pytest.mark.parametrize("number_of_images", [i for i in range(1, 10)])def test_get_few_sub_breed_random_images(dog_api, number_of_images): response = dog_api.get(f"breed/hound/afghan/images/random/{number_of_images}") response = response.json() final_len = len(response["message"]) assert final_len == number_of_images, f"Количество фото не {number_of_images}, а {final_len}"
Добавляем allure в тесты
Есть много разных подходов к написанию тестов с помощью allure.
Так как сейчас рассматривается больше инфраструктура, то добавим
совсем простые шаги. Для понимания написанного мною кода, я все же
прокомментирую несколько моментов.
with allure.step('step 1'): с помощью этого
контекстного менеджера тело теста делится на шаги, понятные в
отчете.
@allure.feature('Dog Api') @allure.story('Send few
requests') декораторы, с помощью которых сами тесты или
тестовые наборы будут структурированы в отчете
Это лишь малая часть возможностей allure, но для
выстраивания инфраструктуры и дальнейшей доработки тестов этого
хватит. Если вы хотите во всей полноте пользоваться возможностями
allure, то рекомендую ознакомиться с документацией
Добавим в наш API клиент несколько allure шагов.
class ApiClient: def __init__(self, base_address): self.base_address = base_address def post(self, path="/", params=None, data=None, json=None, headers=None): url = f"{self.base_address}{path}" with allure.step(f'POST request to: {url}'): return requests.post(url=url, params=params, data=data, json=json, headers=headers) def get(self, path="/", params=None, headers=None): url = f"{self.base_address}{path}" with allure.step(f'GET request to: {url}'): return requests.get(url=url, params=params, headers=headers)
Добавим декораторы в тесты и снабдим их шагами. Так же добавлю
излишние шаги, чтобы показать зависимость генерации отчета от кода.
Здесь не описаны лучшие практики по написанию текста для шагов.
Текст намеренно неформальный для простоты восприятия кода и
отчета.
@allure.feature('Random dog')@allure.story('Получение фото случайной собаки и вложенные друг в друга шаги')def test_get_random_dog(dog_api): response = dog_api.get("breeds/image/random") with allure.step("Запрос отправлен, посмотрим код ответа"): assert response.status_code == 200, f"Неверный код ответа, получен {response.status_code}" with allure.step("Запрос отправлен. Десериализируем ответ из json в словарь."): response = response.json() assert response["status"] == "success" with allure.step(f"Посмотрим что получили {response}"): with allure.step(f"Вложим шаги друг в друга по приколу"): with allure.step(f"Наверняка получится что-то интересное"): pass
Сходным образом заполним шагами и декораторами остальные тесты.
Финальный файл test_dog_api.py
import pytestimport allure@allure.feature('Random dog')@allure.story('Получение фото случайной собаки и вложенные друг в друга шаги')def test_get_random_dog(dog_api): response = dog_api.get("breeds/image/random") with allure.step("Запрос отправлен, посмотрим код ответа"): assert response.status_code == 200, f"Неверный код ответа, получен {response.status_code}" with allure.step("Запрос отправлен. Десериализируем ответ из json в словарь."): response = response.json() assert response["status"] == "success" with allure.step(f"Посмотрим что получили {response}"): with allure.step(f"Вложим шаги друг в друга по приколу"): with allure.step(f"Наверняка получится что-то интересное"): pass@allure.feature('Random dog')@allure.story('Фото случайной собаки из определенной породы')@pytest.mark.parametrize("breed", [ "afghan", "basset", "blood", "english", "ibizan", "plott", "walker"])def test_get_random_breed_image(dog_api, breed): response = dog_api.get(f"breed/hound/{breed}/images/random") with allure.step("Запрос отправлен. Десериализируем ответ из json в словарь."): response = response.json() assert breed in response["message"], f"Нет ссылки на фото с указанной породой, ответ {response}"@allure.feature('List of dog images')@allure.story('Список всех фото собак списком содержит только изображения')@pytest.mark.parametrize("file", ['.md', '.MD', '.exe', '.txt'])def test_get_breed_images(dog_api, file): response = dog_api.get("breed/hound/images") with allure.step("Запрос отправлен. Десериализируем ответ из json в словарь."): response = response.json() with allure.step("Соединим все ссылки в ответе из списка в строку"): result = '\n'.join(response["message"]) assert file not in result, f"В сообщении есть файл с расширением {file}"@allure.feature('List of dog images')@allure.story('Список фото определенных пород')@pytest.mark.parametrize("breed", [ "african", "boxer", "entlebucher", "elkhound", "shiba", "whippet", "spaniel", "dvornyaga"])def test_get_random_breed_images(dog_api, breed): response = dog_api.get(f"breed/{breed}/images/") with allure.step("Запрос отправлен. Десериализируем ответ из json в словарь."): response = response.json() assert response["status"] == "success", f"Не удалось получить список изображений породы {breed}"@allure.feature('List of dog images')@allure.story('Список определенного количества случайных фото')@pytest.mark.parametrize("number_of_images", [i for i in range(1, 10)])def test_get_few_sub_breed_random_images(dog_api, number_of_images): response = dog_api.get(f"breed/hound/afghan/images/random/{number_of_images}") with allure.step("Запрос отправлен. Десериализируем ответ из json в словарь."): response = response.json() with allure.step("Посмотрим длину списка со ссылками на фото"): final_len = len(response["message"]) assert final_len == number_of_images, f"Количество фото не {number_of_images}, а {final_len}"
Делаем инфраструктуру
для тестов
Здесь есть несколько моментов, о которых стоит написать:
.gitlab-ci.yml файл, где на языке разметки yaml
описаны инструкции что нужно делать gitlab runnergitlab-runner это проект, написанный на языке Go.
Он будет выполнять инструкции. Есть несколько вариантов его
использования. Мы будем писать инструкцию для gitlab runner, где он
в свою очередь будет использовать docker для запуска тестов и всего
остального. Далее по тексту он будет обозначаться просто "раннер".
Что
это за сущность и с чем её едят можно найти здесь.
Если у вас в компании уже настроена инфраструктура и вы можете
попросить своего devops выделить вам раннер где-то в облаке, то
сделайте это. Раннер можно использовать и локально на своем
компьютере. В этом случае вам нужен установленный docker desktop на
windows. В этом гайде мы будем использовать локальный раннер, но
для облачного запуска вам нужно будет просто указать в .gitlab-ci
нужный раннер.
Если у вас нет docker desktop, то здесь инструкция как его
заиметь.
Настройка репозитория
Нужно зайти в настройки репозитория Settings -> General
-> Visibility, project features, permissions,
активировать Pipelines и сохранить изменения.

После этого в разделе настроек появится раздел CI /
CD. Переходим Settings -> CI / CD ->
Runners

Здесь переходим по ссылке
в пункте 1 и согласно инструкции ставим себе на компьютер Gitlab
Runner. Далее в статье адаптация инструкции на русском.
Установка и настройка
Gitlab Runner
Ниже инструкция, которую вы можете найти здесь.
Можете пройтись по ней самостоятельно. Далее в тексте будет сделано
все по инструкции.
- Создайте папку где-нибудь в системе, например:
C:\GitLab-Runner.
- Скачайте бинарник для x86 или amd64 и положите его в созданную
папку. Переименуйте скачанный файл в gitlab-runner.exe. Вы можете
скачать бинарник для любой доступной версии
здесь
- Запустите командную строку
с правами администратора. (Сам я буду использовать обычный
powershell с правами администратора)
-
Зарегестрируйте раннер
- Установите раннер как сервис и запустите его. Вы можете
запустить службу, используя встроенную системную учетную запись
(рекомендуется) или учетную запись пользователя.
С первыми тремя пунктами инструкции все понятно. Создаем папку,
кладем в неё переименованный раннер и запускаем в директории
powershell, то с четвертым и пятым пунктом могут возникнуть
проблемы и недопонимание, если не потратить некоторое время на
чтение документации. Далее простыми словами описаны шаги, которые
нужно сделать, чтобы раннер заработал.
Я создал папку C:\gitlab_runners и сохранил туда скачанный для
моей системы раннер, предварительно переименовав в
gitlab-runner.exe
Как только вы справились с первыми тремя пунктами, то нужно
сделать следующее:
- Ввести команду:
./gitlab-runner.exe register
- Ввести url, указанный на странице настроек раннеров в
репозитори в пункте 2. Например, у меня так:
https://gitlab.somesubdomain.com/
- Ввести токен указанный на странице настроек раннеров в
репозитори в пункте 3. Например, у меня так:
tJTUaJ7JxfL4yafEyF3k
- Вводим описание раннера. Его потом можно будет изменить через
UI в настроках раннера в репозитории. Например так:
Runner on windows for autotests
- Добавляем теги для раннера, для того, чтобы описывать нужный
раннер в .gitlab-ci.yml, используя определенные теги. Это в
основном нужно, когда раннеров больше одного.
docker, windows
- Выбираем тип раннера, который нам нужен. Здесь выберем
docker
docker
- Вводим дефолтный image, который будет использоваться раннером.
Его можно будет изменить в конфиге раннера или указать конкретый в
.gitlab-ci.yml
python:3.8-alpine
Скрншот с выполнеными шагами

Наш раннер зарегистрирован, теперь его нужно запустить.
Проверить статус раннера можно так:
.\gitlab-runner.exe status
Запустите раннер с помощью:
.\gitlab-runner.exe run
Теперь, если вы зайдете в настроки раннеров в репозитории
Settings -> CI / CD -> Runners, то увидите
что-то такое:

Это означает, что у репозитория есть линк с раннером и он видит
его статус. Осталось добавить чекбокс в раннере. Для этого нужно
нажать на карандаш рядом с именем раннера в гитлабе.

Все хорошо, теперь можно перейти к пайплайну.
Настройка пайплайна в
.gitlab-ci.yml
Инструкции для раннера описываются в
.gitlab-ci.yml. Полная документация описана здесь.
Первым делом нам нужно описать stages. Шаги пайплайна. Их будет
4. Каждый stage отдельный job, который будет выполнять раннер.
stages: - testing # Запуск тестов - history_copy # Копирование результата тестов из предыдущего запуска тестов - reports # Генерация отчета - deploy # Публикация отчета на gitlab pages
Шаг первый. Testing
docker_job: # Название job stage: testing # Первый stage, который нужно выполнить tags: - docker # С помощью этого тега gitlab поймет, какой раннер нужно запустить. Он запустит докер контейнер, из образа, который мы указывали в 6 шаге регистрации раннера. before_script: - pip install -r requirements.txt # Устанавливаем пакеты в поднятом контейнере перед запуском самих тестов script: - pytest -n=4 --alluredir=./allure-results tests/test_dog_api.py # Запускаем тесты параллельно(-n=4 обеспечивает нам это), указав папку с результатами тестов через --alluredir= allow_failure: true # Это позволит нам продолжить выполнение пайплайна в случае, если тесты упали. artifacts: # Сущность, с помощью которой, мы сохраним результат тестирования. when: always # Сохранять всегда paths: - ./allure-results # Здесь будет сохранен отчет expire_in: 1 day # Да, он будет удален через день. Нет смысла хранить его в течение длительного срока.
Шаг второй. history_copy
history_job: # Название job stage: history_copy # Это второй stage, который нужно выполнить tags: - docker # Пользуемся тем же самым раннером image: storytel/alpine-bash-curl # Но теперь укажем раннеру использовать другой образ, для того чтобы скачать результаты теста из предыдущего пайплайна. Нам же нужна история тестов, верно? script: - 'curl --location --output artifacts.zip "https://gitlab.smarthead.ru/api/v4/projects/(АЙДИ ВАШЕГО РЕПОЗИТОРИЯ)/jobs/artifacts/master/download?job=pages&job_token=$CI_JOB_TOKEN"' # С помощью api гитлаба скачиваем файлы из job, который будет указан ниже. Обратите внимание на текст на русском в ссылке. Очень важно указать вместо текста и скобок номер вашего репозиториия - unzip artifacts.zip # Распаковываем файлы - chmod -R 777 public # Даем права любые манипуляции с содержимым - cp -r ./public/history ./allure-results # Копируем историю в папку с результатами теста allow_failure: true # Так как при первом запуске пайплайна истории нет, это позволит нам избежать падения пайплайна. В дальнейшем эту строчку можно спокойно удалить. artifacts: paths: - ./allure-results # Сохраняем данные expire_in: 1 day rules: - when: always # Сохранять всегда
Шаг третий. reports
allure_job: # Название job stage: reports # Третий stage, который будет выполнен tags: - docker # Пользуемся тем же самым раннером image: frankescobar/allure-docker-service # Указываем раннеру использовать образ с allure. В нем мы будем генерировать отчет. script: - allure generate -c ./allure-results -o ./allure-report # Генерируем отчет из ./allure-results внутрь папки ./allure-report artifacts: paths: - ./allure-results # Примонтируем две этих директории для получения результатов тестирования и генерации отчетов соответственно - ./allure-report expire_in: 1 day rules: - when: always
Шаг четвертый. deploy
pages: # Названием этой job говорим гитлабу, чтобы захостил результат у себя в pages stage: deploy # Четвертый stage, который будет выполнен script: - mkdir public # Создаем папку public. По умолчанию гитлаб хостит в gitlab pages только из папки public - mv ./allure-report/* public # Перемещаем в папку public сгенерированный отчет. artifacts: paths: - public rules: - when: always
Финальный .gitlab-ci.yml
stages: - testing # Запуск тестов - history_copy # Копирование результата тестов из предыдущего запуска тестов - reports # Генерация отчета - deploy # Публикация отчета на gitlab pagesdocker_job: # Название job stage: testing # Первый stage, который нужно выполнить tags: - docker # С помощью этого тега gitlab поймет, какой раннер нужно запустить. Он запустит докер контейнер, из образа, который мы указывали в 6 шаге регистрации раннера. before_script: - pip install -r requirements.txt # Устанавливаем пакеты в поднятом контейнере перед запуском самих тестов script: - pytest -n=4 --alluredir=./allure-results tests/test_dog_api.py # Запускаем тесты параллельно(-n=4 обеспечивает нам это), указав папку с результатами тестов через --alluredir= allow_failure: true # Это позволит нам продолжить выполнение пайплайна в случае, если тесты упали. artifacts: # Сущность, с помощью которой, мы сохраним результат тестирования. when: always # Сохранять всегда paths: - ./allure-results # Здесь будет сохранен отчет expire_in: 1 day # Да, он будет удален через день. Нет смысла хранить его в течение длительного срока.history_job: # Название job stage: history_copy # Это второй stage, который нужно выполнить tags: - docker # Пользуемся тем же самым раннером image: storytel/alpine-bash-curl # Но теперь укажем раннеру использовать другой образ, для того чтобы скачать результаты теста из предыдущего пайплайна. Нам же нужна история тестов, верно? script: - 'curl --location --output artifacts.zip "https://gitlab.smarthead.ru/api/v4/projects/(АЙДИ ВАШЕГО РЕПОЗИТОРИЯ)/jobs/artifacts/master/download?job=pages&job_token=$CI_JOB_TOKEN"' # С помощью api гитлаба скачиваем файлы из job, который будет указан ниже. Обратите внимание на текст на русском в ссылке. Очень важно указать вместо текста и скобок номер вашего репозиториия - unzip artifacts.zip # Распаковываем файлы - chmod -R 777 public # Даем права любые манипуляции с содержимым - cp -r ./public/history ./allure-results # Копируем историю в папку с результатами теста allow_failure: true # Так как при первом запуске пайплайна истории нет, это позволит нам избежать падения пайплайна. В дальнейшем эту строчку можно спокойно удалить. artifacts: paths: - ./allure-results # Сохраняем данные expire_in: 1 day rules: - when: always # Сохранять всегдаallure_job: # Название job stage: reports # Третий stage, который будет выполнен tags: - docker # Пользуемся тем же самым раннером image: frankescobar/allure-docker-service # Указываем раннеру использовать образ с allure. В нем мы будем генерировать отчет. script: - allure generate -c ./allure-results -o ./allure-report # Генерируем отчет из ./allure-results внутрь папки ./allure-report artifacts: paths: - ./allure-results # Примонтируем две этих директории для получения результатов тестирования и генерации отчетов соответственно - ./allure-report expire_in: 1 day rules: - when: alwayspages: # Названием этой job говорим гитлабу, чтобы захостил результат у себя в pages stage: deploy # Четвертый stage, который будет выполнен script: - mkdir public # Создаем папку public. По умолчанию гитлаб хостит в gitlab pages только из папки public - mv ./allure-report/* public # Перемещаем в папку public сгенерированный отчет. artifacts: paths: - public rules: - when: always
Запуск тестов и просмотр
отчета
Осталось отправить в репозиторий все необходимые файлы, а
именно:
conftest.py- Директорию
tests
requirements.txt (Убедитесь, что там есть все
нужные зависимости).gitlab-ci.yml
Отправляем и смотрим что получилось.
В первый раз пайплайн будет запускаться немного дольше, чем в
следующие разы. Потому что ему нужно будет скачать нужные образы,
запустить их и все такое. Заходим в репозиторий и через сайдбар
переходим в CI / CD -> Pipelines
Здесь вы сможете увидеть статус пайплайна, а также перейти к Ci
линтеру, где можете проверить конкретно свой .gitlab-ci.yml.


Когда пайплайн пройдет, увидеть ссылку и сам отчет можно через
Settings -> Pages. При первом использовании pages в
репозитории для просмотра страницы может понадобиться до 30 минут.
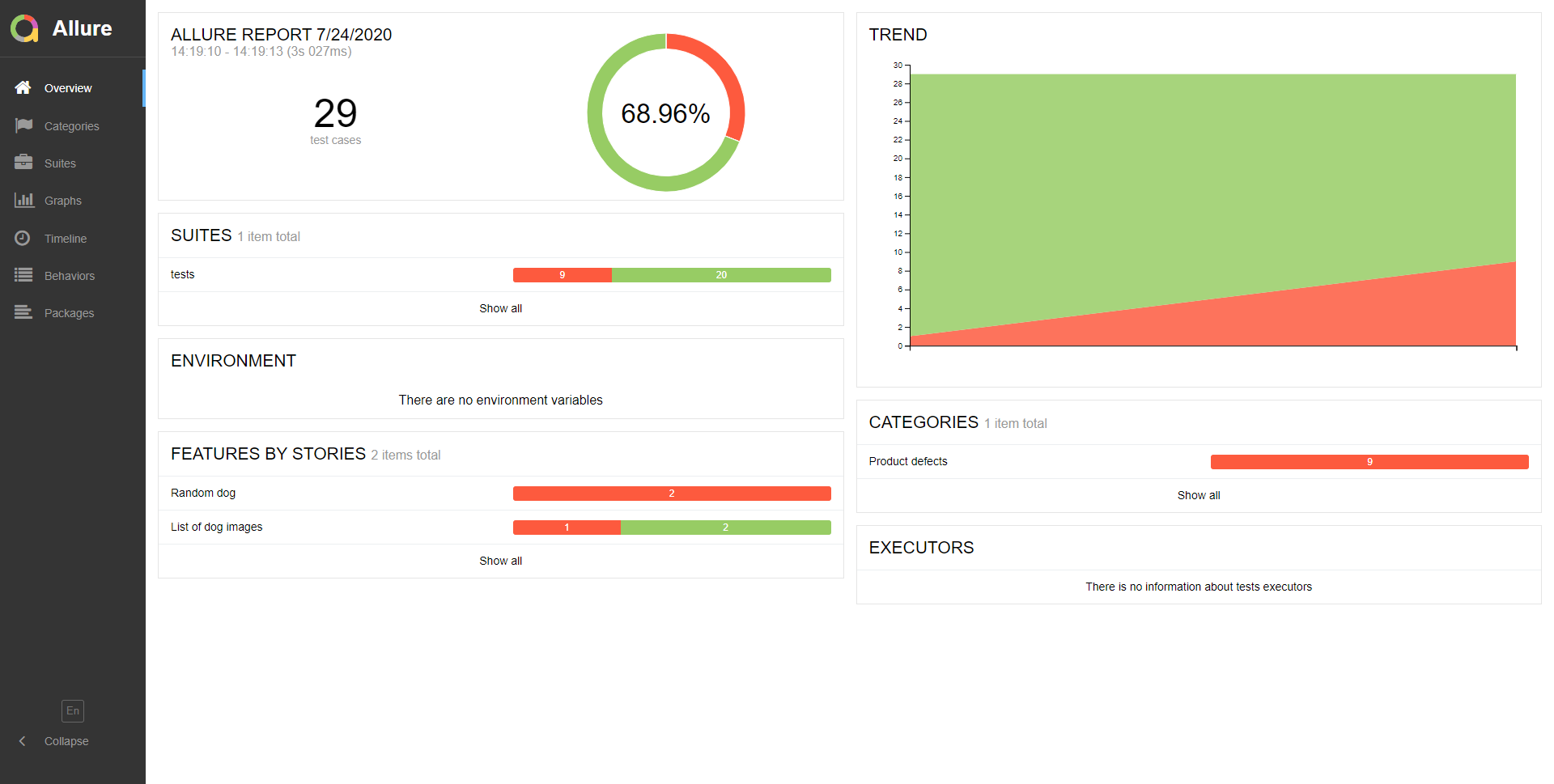
Проходим по ссылке и смотрим отчет.

Получаем результат. Советую побродить по отчету и посмотреть
результаты.

Сломаем несколько тестов, чтобы посмотреть, как будет
отображаться история тестов. Затем подождем окончания
пайплайна.

Как видите второй шаг в этот раз выполнился без ошибок. Это
потому, на stage history_job проблем с копированием истории
предыдущих пайплайнов не возникло. Теперь посмотрим результат
тестов.

Видна динамика, количество упавших тестов и все остальное. Для
просмотра подробностей по тестам рекомендую посмотреть отчет
самостоятельно.

Настройка пайплайна для
UI тестов
Реализовать их можно с помощью специальной сущности гитлаба
[services](http://personeltest.ru/aways/docs.gitlab.com/ee/ci/services/).
Это ключевое слово для использования докер образов, которые будут
запущены до хода шагов в script. Для UI тестов нужно
добавить в job пайплайна следующее:
services: - selenium/standalone-chrome:latest
Так как нам нужно обращаться к контейнеру, который поднимет
гитлаб по определенному url, то он каким-то образом назначает этому
сервису url, по которому можно слать запросы.
Логика здесь такая:
- Все после
: отбрасывается
- Слеш
/ заменяется двойным подчеркиванием
__ и создается главный алиас
- Слеш
/ заменяется одиночным дефисом -
и создается дополнительный алиас (Необходим Gitlab Runner v1.1.0 и
выше)
И теперь нужно изменить в фикстуре executor (по умолчанию
используется chromedriver на вашей машине, но сейчас мы все это
запускаем в контейнерах) для запуска ui тестов:
browser = webdriver.Remote(command_executor="http://personeltest.ru/away/selenium__standalone-chrome:4444/wd/hub")
Обратите внимание, что было в .gitlab-ci.yml:
selenium/standalone-chrome:latest
И по какому адресу нужно обращаться фикстуре для запуска
тестов:
selenium__standalone-chrome
Для запуска моих тестов у меня получился такой job. Если
добавить к нему три следующих job из примера с api тестами, то
можно прогнать все тесты и получить отчет.
chrome_job: stage: testing services: - selenium/standalone-chrome image: python:3.8 tags: - docker before_script: - pip install -r requirements.txt script: - pytest --alluredir=./allure-results tests/ allow_failure: true artifacts: when: always paths: - ./allure-results expire_in: 1 day
Полезные ссылки
Помимо ссылок в статье, хочется поделиться еще несколькими,
которые немного разъяснять вам что такое allure и как писать gitlab
ci.
Статья об allure на хабре
Введение в gitlab ci





