
Привет, Хабр! В преддверии старта курса "Экосистема Hadoop, Spark, Hive" подготовили для вас перевод полезной статьи. А также предлагаем посмотреть бесплатную запись демо-урока по теме: "Spark 3.0: Что нового?".
Ищем наиболее оптимальную конфигурацию исполнителей для вашего узла
Количество ЦП на узел
Первый этап в определении оптимальной конфигурации исполнителей (executor) - это выяснить, сколько фактических ЦП (т.е. не виртуальных ЦП) доступно на узлах (node) в вашем кластер. Для этого вам необходимо выяснить, какой тип инстанса EC2 использует ваш кластер. В этой статье мы будем использовать r5.4xlarge, который, согласно прейскуранту на инстансы AWS EC2, насчитывает 16 процессоров.
Когда мы запускаем наши задачи (job), нам нужно зарезервировать один процессор для операционной системы и системы управления кластерами (Cluster Manager). Поэтому мы не хотели бы задействовать под задачу сразу все 16 ЦП. Таким образом, когда Spark производит вычисления, на каждом узле у нас остается только 15 доступных для аллоцирования ЦП.

Количество ЦП на исполнителя
Теперь, когда мы узнали, сколько ЦП доступно для использования на каждом узле, нам нужно определить, сколько ядер (core) Spark мы хотим назначить каждому исполнителю. С помощью базовой математики (X * Y = 15), мы можем посчитать, что существует четыре различных комбинации ядер и исполнителей, которые могут подойти для нашего случая с 15 ядрам Spark на узел:
 Возможные конфигурации исполнителей
Возможные конфигурации исполнителей
Давайте исследуем целесообразность каждой из этих конфигураций.
Один исполнитель с пятнадцатью ядрами

Самое очевидное решение, которое приходит на ум, - создать одного исполнителя с 15 ядрами. Проблема с большими жирными исполнителями, подобными этому, заключается в том, что исполнитель, поддерживающий такое количество ядер, обычно будет иметь настолько большой пул памяти (64 ГБ+), что задержки на сборку мусора будут неоправданно замедлять вашу работу. Поэтому мы сразу исключаем эту конфигурацию.
Пятнадцать одноядерных исполнителей

Следующее очевидное решение, которое приходит на ум создать 15 исполнителей, каждый из которых имеет только одно ядро. Проблема здесь в том, что одноядерные исполнители неэффективны, потому что они не используют преимуществ параллелизма, которые обеспечивают несколько ядер внутри одного исполнителя. Кроме того, найти оптимальный объем служебной памяти для одноядерных исполнителей может быть достаточно сложно. Давайте немного поговорим о накладных расходах памяти.

Накладные расходы памяти для исполнителя по умолчанию составляют
10% от размера выделенной вашему исполнителю памяти или 384 MB (в
зависимости от того, что больше). Однако на некоторых big data
платформах, таких как Qubole, накладные расходы зафиксированы на
определенном значении по умолчанию, вне зависимости от размера
вашего исполнителя. Вы можете проверить ваш показатель накладных
расходов, перейдя во вкладку Environments в логе Spark и выполнив
поиск параметра spark.executor.memoryOverhead.
Накладные расходы памяти по умолчанию в Spark будут очень маленьким, что результирует в проблемах с вашими задачами. С другой стороны, фиксированное значение накладных расходов для всех исполнителей приведет к слишком большому объему служебной памяти и, следовательно, оставит меньше места самим исполнителям. Выверить идеальный размер служебной памяти сложно, поэтому это еще одна причина, по которой одноядерный исполнитель нам не подходит.
Пять исполнителей с тремя ядрами или три исполнителя с пятью ядрами

Итак, у нас осталось два варианта. Большинство руководств по настройке Spark сходятся во мнении, что 5 ядер на исполнителя это оптимальное количество ядер с точки зрения параллельной обработки. И я тоже пришел к выводу, что это правда, в том числе, на основании моих собственных изысканий в оптимизации. Еще одно преимущество использования пятиядерных исполнителей по сравнению с трехъядерными заключается в том, что меньшее количество исполнителей на узел требует меньшее количество служебной памяти. Поэтому мы остановимся на пятиядерных исполнителях, чтобы минимизировать накладные расходы памяти на узле и максимизировать параллелизм внутри каждого исполнителя.
--executor-cores 5
Объем памяти на узел
Наш следующий шаг определить, сколько памяти назначить каждому исполнителю. Прежде чем мы сможем это сделать, мы должны определить, сколько физической памяти на нашем узле нам вообще доступно. Это важно, потому что физическая память это жесткое ограничение для ваших исполнителей. Если вы знаете, какой инстанс EC2 используете, значит, вы знаете и общий объем памяти, доступной на узле. Про наш инстанс r5.4xlarge AWS сообщает, что у него 128 ГБ доступной памяти.

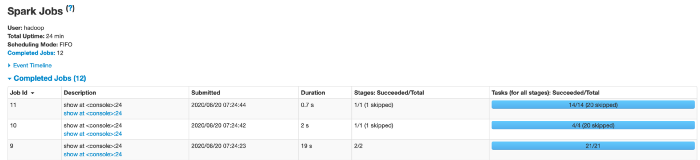
Однако доступными для использования вашими исполнителями будут не все 128 ГБ, так как память нужно будет выделить также и для вашей системы управления кластерами. На рисунке ниже показано, где в YARN искать сколько памяти доступно для использования после того, как память была выделена для системы управления кластерами.

Мы видим, что на узлах этого кластера исполнителям доступно 112 ГБ.
Объем памяти на исполнителя
Если мы хотим, чтобы три исполнителя использовали 112 ГБ доступной памяти, то нам следует определить оптимальный размер памяти для каждого исполнителя. Чтобы вычислить объем памяти доступной исполнителю, мы попросту делим доступную память на 3. Затем мы вычитаем накладные расходы на память и округляем до ближайшего целого числа.
Если служебная память у вас фиксированная (как в случае с Qubole), вы будете использовать эту формулу. (112/3) = 372,3 = 34,7 = 34.
Если вы используете дефолтный метод Spark для расчета накладных расходов на память, вы будете использовать эту формулу. (112/3) = 37 / 1,1 = 33,6 = 33.
В оставшейся части этой статьи мы будем использовать фиксированный объем накладных расходов памяти для Qubole.
--executor-memory 34G
Чтобы по настоящему начать экономить, опытным тюнерам Spark необходим следующий сдвиг в парадигме. Я рекомендую вам в ваших исполнителях для всех задач использовать фиксированные размер памяти и количество ядер. Понимаю, что использование фиксированной конфигурации исполнителей для большинства задач Spark кажется противоречащим надлежащей практике тюнинга Spark. Даже если вы настроены скептически, я прошу вас опробовать эту стратегию, чтобы убедиться, что она работает. Выясните, как рассчитать затраты на выполнение вашей задачи, как описано в Части 2, а затем проверьте это на практике. Считаю, что если вы это сделаете, вы обнаружите, что единственный способ добиться эффективной экономичности облачных затрат это использовать фиксированные размеры памяти для ваших исполнителей, которые оптимально используют ЦП.
С учетом вышесказанного, если при использовании эффективного объема памяти для ваших исполнителей у вас остается много неиспользуемой памяти, подумайте о переносе вашего процесса на другой тип инстанса EC2, у которого меньше памяти на ЦП узла. Этот инстанс обойдется вам дешевле и, следовательно, поможет снизить стоимость выполнения вашей задачи.
Наконец, будут моменты, когда эта экономичная конфигурация не будет обеспечивать достаточную пропускную способность для ваших данных в вашем исполнителе. В примерах, приведенных во второй части, было несколько задач, в которых мне приходилось уходить от использования оптимального размера памяти, потому что нагрузка на память была максимальной во время всего выполнения задачи.
В этом руководстве я все же рекомендую вам начинать с оптимального размера памяти при переносе ваших задач. Если при оптимальной конфигурации исполнителей у вас возникают ошибки памяти, я поделюсь конфигурациями, которые избегают этих ошибок позже в Части 5.
Количество исполнителей на задачу
Теперь, когда мы определились с конфигурацией исполнителей, мы готовы настроить количество исполнителей, которые мы хотим использовать для нашей задачи. Помните, что наша цель - убедиться, что используются все 15 доступных ЦП на узел, что означает, что мы хотим, чтобы каждому узлу было назначено по три исполнителя. Если мы установим количество наших исполнителей кратное 3, мы добьемся своей цели.
Однако с такой конфигурацией есть одна проблема. Нам также нужно назначить драйвер для обработки всех исполнителей в узле. Если мы используем количество исполнителей, кратное 3, то наш одноядерный драйвер будет размещен в своем собственном 16-ядерном узле, что означает, что аж 14 ядер на этом последнем узле не будут использоваться в течение всего выполнения задачи. Это не очень хорошая практика использования облака!
Мысль, которую я хочу здесь донести, заключается в том, что идеальное количество исполнителей должно быть кратным 3 минус один исполнитель, чтобы освободить место для нашего драйвера.
--num-executors (3x - 1)
В Части 4 я дам вам рекомендации о том, сколько исполнителей вы должны использовать при переносе существующей задачи в экономичную конфигурацию исполнителей.
Объем памяти на драйвер
Обычной практикой для data-инженеров является выделение относительно небольшого размера памяти под драйвер по сравнению с исполнителями. Однако AWS на самом деле рекомендует устанавливать размер памяти вашего драйвера таким же, как и у ваших исполнителей. Я обнаружил, что это также очень помогает при оптимизации затрат.
--driver-memory 34G
В редких случаях могут возникать ситуации, когда вам нужен драйвер, память которого больше, чем у исполнителя. В таких случаях устанавливайте размер памяти драйвера в 2 раза больше памяти исполнителя, а затем используйте формулу (3x - 2), чтобы определить количество исполнителей для вашей задачи.
Количество ядер на драйвер
По умолчанию количество ядер на драйвер равно одному. Однако я обнаружил, что задачи, использующие более 500 ядер Spark, могут повысить производительность, если количество ядер на драйвер установлено в соответствии с количеством ядер на исполнителя. Однако не стоит сразу менять дефолтное количество ядер в драйвере. Просто протестируйте это на своих наиболее крупных задачах, чтобы увидеть, ощутите ли вы прирост производительности.
--driver-cores 5
Конфигурация универсальна?
Таким образом, конфигурация исполнителей, которую я рекомендую для узла с 16 процессорами и 128 ГБ памяти, будет выглядеть следующим образом.
--driver-memory 34G --executor-memory 34G --num-executors (3x - 1) --executor-cores 5
Но помните:
Не существует универсальных конфигураций просто продолжайте экспериментировать и рано или поздно вы найдете конфигурацию, идеально подходящую для ваших задач.
Как я уже упоминал выше, эта конфигурация может выглядеть не подходящей для ваших конкретных нужд. Я рекомендую вам использовать эту конфигурацию в качестве отправной точки в процессе оптимизации затрат. Если в этой конфигурации у вас возникают проблемы с памятью, в следующих частях этой серии я порекомендую вам конфигурации, которые позволят вам решить большинство проблем с памятью, возникающих при переходе на экономичные конфигурации.
Поскольку конфигурация узла, используемая в этой статье, достаточно распространена в Expedia Group , я буду ссылаться на нее в остальной части серии. Если ваши узлы имеют другой размер, вам следует использовать метод, который я изложил здесь, чтобы определить идеальную конфигурацию.
Теперь, когда у вас есть оптимальная экономичная конфигурация исполнителей, вы можете попробовать перенести на нее текущие задачи. Но какие задачи вам следует перенести в первую очередь? И сколько исполнителей вы должны запустить с этой новой конфигурацией? А что произойдет, если задача с оптимизированной стоимостью выполняется дольше, чем неоптимизированная задача? И уместно ли когда-либо избыточное использование ЦП? Я отвечу на эти вопросы в Части 4: Как перенести существующие задачи Apache Spark на экономичные конфигурации исполнителей.
Подробнее о курсе "Экосистема Hadoop, Spark, Hive" можно узнать здесь. Также можно посмотреть запись открытого урока "Spark 3.0: что нового?".



















































 классификация изображения моделью на Jetson Nano 2GB
классификация изображения моделью на Jetson Nano 2GB







































