
Вот интерфейс типичного генератора паролей:

Обратите внимание на ползунок Length: здесь он может менять длину пароля от 8 до 100 символов, а в других инструментах гораздо больше. Какое же значение оптимально для паролей?
Хороший пароль это всё, что у вас есть, когда вас взламывают
Чтобы понять, что такое хороший пароль, посмотрим, что происходит в стане врага!
Когда вы создаёте аккаунт, сервис сохраняет пароль в одном из многочисленных форматов. Сервис может положить пароль прямо в базу данных (в виде простого текста) или сгенерировать из него хэш с помощью одного из многочисленных алгоритмов. Самые популярные:
- MD5
- SHA-1
- Bcrypt
- Scrypt
- Argon2
Преимущество хранения хэшей вместо самих паролей заключается в том, что паролей в БД нет. И это правильно, потому что вам нужно только доказать, что вы знаете свой пароль, но сам он не имеет значения. Когда вы логинитесь, введённый пароль хэшируется с помощью того же алгоритма, и если результат совпадает с записанным в базе значением, то вы доказали, что знаете пароль. А если базу взломают, то восстановить пароли не удастся.

Хранение хэшей.
Взлом пароля
Взлом пароля это когда злоумышленник пытается обратить вспять хэш-функцию и восстановить пароль из хэша. В случае с хорошим алгоритмом хэширования сделать это невозможно. Но ничто не мешает злоумышленнику пробовать вводить разные значения в надежде получить такой же хэш. Если совпадение произойдёт, значит, пароль восстановлен из хэша.

Взлом пароля.
И здесь важен выбор хорошего алгоритма. SHA-1 разрабатывался с учётом быстрого хэширования, это облегчает жизнь взломщикам. Bcrypt, Scrypt и Argon2 разрабатывались с учётом высоких вычислительных затрат, чтобы как можно больше замедлить взлом, особенно на специально выделенных машинах. И это очень важный аспект.
Если ориентироваться только на скорость, то пароль SHA-1, который невозможно взломать, выглядит так:
0OVTrv62y2dLJahXjd4FVg81.А безопасный пароль, созданный с помощью правильно сконфигурированного Argon2, выглядит так:
Pa$$w0Rd1992.Как видите, выбор правильного алгоритма хэширования превращает слабый пароль в не поддающийся взлому.
И не забывайте, что это зависит только от реализации сервиса, в котором вы регистрируетесь. И вы не можете узнать качество реализации. Спросить можно, но вам либо не ответят, либо отпишутся, что мы серьёзно подходим к безопасности.
Думаете, в компаниях серьёзно относятся к безопасности и используют хорошие алгоритмы хэширования? Посмотрите на список взломанных баз данных, особенно на использованные в них хэши. Во многих случаях применялся MD5, чаще всего SHA-1, и кое-где использовали bcrypt. Некоторые хранили пароли в виде простого текста. Такова реальность, которую нужно учитывать.
Причём мы знаем лишь, какие хэши использовались во взломанных базах, и высока вероятность, что компании, применявшие слабые алгоритмы, не смогли защитить и свою инфраструктуру. Взгляните на список, уверен, вы найдёте знакомые названия. То, что компания выглядит большой и респектабельной, ещё не означает, что всё делает правильно.
Пароль выбираете вы
Что вы можете сделать как пользователь? Если пароли хранятся в виде простого текста, тогда ничего не поделаешь. Когда базу украдут, сложность вашего пароля не будет иметь значения.
При правильно сконфигурированных алгоритмах сложность вашего пароля тоже не важна, он может быть
12345 или
asdf.Однако в промежуточных случаях, особенно при использовании SHA-1, сложность пароля имеет значение. Функции хэширования в целом не предназначены для паролей, но если вы используете сложный пароль, то это компенсирует недостатки алгоритмов.

Зависит от конфигурации. У этих алгоритмов есть различные компоненты, влияющие на защищённость, и при правильной конфигурации они способны предотвратить взлом.
Вывод: с сильным паролем вы защищены от большего количества взломов, чем со слабым паролем. А поскольку вы не знаете, насколько защищено хранилище паролей, вы не можете знать, насколько будет достаточно безопасно для этого сервиса. Так что предполагайте худшее, когда ваш выбор пароля ещё имеет значение.
Уникальности пароля недостаточно
Ладно, но с какой стати вам думать о том, чтобы использовать менеджер паролей и генерировать уникальный пароль для каждого сайта? В этом случае вы неуязвимы для credential stuffing когда известная пара почтового ящика и пароля проверяется на разных сервисах в надежде, что человек использовал эти данные в разных местах. Это серьёзная угроза, потому что повторное использование паролей одна из главных проблем безопасности. От этого вас защитит генерирование уникального пароля для каждого сайта.

Credential stuffing.
А если базу украдут и всё её содержимое станет известно хакерам, то зачем вам всё ещё защищать свой пароль?
Дело в том, что вы не знаете, взломана ли база, и продолжаете пользоваться сервисом. Тогда хакеры получат доступ ко всей вашей будущей активности на этом сайте. Позднее вы можете добавить данные банковской карты, и они об этом узнают. А сильный пароль означает, что хакеры не смогут войти под вашим аккаунтом и не смогут скомпрометировать ваши будущие действия.

Использование сервиса после взлома.
Как оценить силу пароля с помощью энтропии
Сила пароля характеризуется энтропией числовым представлением количества случайности, которая содержится в пароле. Поскольку речь идёт о больших числах, то вместо
1 099 511 627 776
(2^40) нам проще сказать 40 бит энтропии. И поскольку взлом
пароля это перебор вариантов, то чем их больше, тем больше времени
нужно затратить на взлом.Для случайных символов, сгенерированных менеджером паролей, энтропия считается по формуле:
log2(<количество разных
символов> ^ <длина>).С длиной понятно, а что такое количество разных символов? Оно зависит от классов символов, входящих в пароль.

Например, пароль из 10 случайных строчных и прописных букв имеет
log2(52 ^ 10) = 57 бит энтропии.Чтобы вычислить удельную энтропию (её количество в одном символе заданного класса), можно использовать уравнение
log2(n ^ m) =
m * log2(n). Получаем: <длина> *
log2(<количество разных символов>), где вторая часть
является удельной энтропией. Пересчитаем по этой формуле предыдущую
таблицу:
Для вычисления силы пароля нужно взять классы символов, которые входят в пароль, взять значения энтропии для этих классов и умножить на длину. Для приведённого выше примера пароля из 10 строчных и прописных букв мы получили
5.7 * 10 = 57
бит. Но если увеличить длину до 14, то энтропия скакнёт до
79,8 бит. А если оставить 10 символов, но добавить класс
специальных символов, то общая энтропия будет равна 64 бит.Приведённое уравнение позволяет быстро вычислить энтропию пароля, но тут есть подвох. Формула верна лишь в том случае, если символы не зависят друг от друга. А это относится только к сгенерированным паролям. Сочетание
H8QavhV2gu
удовлетворяет этому критерию и имеет 57 бит энтропии.Но если использовать более лёгкие для запоминания пароли вроде
Pa$$word11, то энтропия у них будет гораздо ниже при
том же количестве символов. Взломщику не придётся перебирать все
возможные комбинации, достаточно лишь перебрать слова из словаря с
некоторыми изменениями.Таким образом, все вычисления с умножением длины на удельную энтропию верны только для сгенерированных паролей.
Руководство по энтропии
Чем больше в пароле энтропии, тем сложнее его взломать. Но сколько энтропии будет достаточно? В целом, около 16 символов будет за глаза, у такого пароля 95102 бита энтропии, в зависимости от классов символов. А какой минимальный порог? 80 бит? 60? Или даже 102 бита слишком мало?
Есть алгоритм, который по скорости соперничает с плохим алгоритмом хэширования, но зато изучен гораздо лучше: это AES.
Он используется во всех правительственных и военных организациях, а значит его стойкости вполне достаточно. И работает быстро. Так что если AES-ключ с определённым количеством энтропии нельзя взломать, то это пойдёт на пользу паролю с плохим (но не взломанным) хэшем.
Национальный институт стандартов и технологий определил размеры ключей, которые будут достаточны в обозримом будущем. Там рекомендуют использовать AES-128 в период 20192030 и позже. Как понятно из названия, речь идёт о 128 битах энтропии.
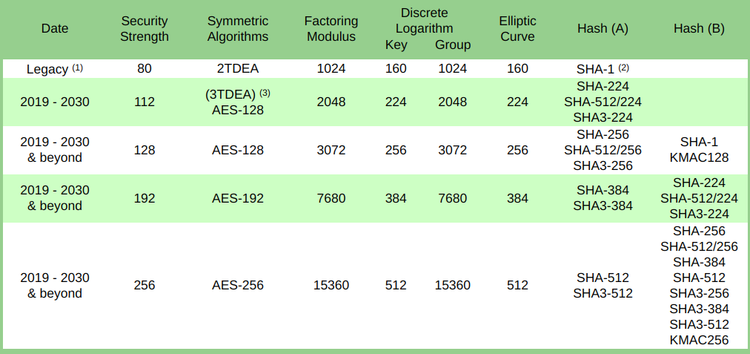
В другой рекомендации советуют делать ключи размером не меньше 112 бит:
Для обеспечения криптографической стойкости для нужд Федерального правительства сегодня требуется не меньше 112 бит (например, для шифрования или подписи данных).
Чтобы получить 128 бит энтропии с использованием прописных и строчных букв, а также чисел, нужен пароль длиной
22 символа
((5.95 * 22 = 131 бит).Другие соображения
Почему бы не использовать специальные символы? Я стараюсь их не применять, потому что они ломают границы слова. То есть для выбора спецсимвола нужно три клика вместо двух, и это может привести к ошибке, если я случайно не вставлю в поле оставшуюся часть пароля.
А если использовать только буквы и цифры, то при двойном клике выделится весь пароль.
Что делать, если есть ограничение по длине? На некоторых сайтах длина пароля не может достигать 22 символов. Иногда пароли могут быть только очень короткими, например, не больше 5 цифр. Тогда остаётся только использовать пароль максимально возможной длины.
Также есть рекомендации для сайтов по работе с паролями, и ограничение длины явно противоречит этим рекомендациям. Вот что говорит Национальный институт стандартов и технологий:
Нужно поддерживать пароли длиной хотя бы до 64 символов. Поощряйте пользователей делать удобные для запоминания секреты любой длины, с использованием любых символов (в том числе пробелов), что будет способствовать запоминанию.
И помните, что степень защиты паролей на сайтах варьируется от ужасной до превосходной, и они не скажут вам, каково реальное положение вещей. Если максимально допустимая длина пароля невелика, то создаётся впечатление, что такой сайт находится на плохой части шкалы.
Заключение
Пароли должны быть сильными, даже если вы не используете одни и те же сочетания в разных местах. Сила пароля измеряется энтропией, и нужно стремиться к значению в 128 бит. Для этого достаточно паролей длиной 22 символа, состоящих из прописных и строчных букв, а также цифр.
Это защитит вас в том случае, если сервис взломают и применялся слабый, но не взломанный алгоритм хэширования.

















