
Привет, Хабр!
В этой статье мы создадим готовый шаблон-монолит, который можно брать за основу нового fullstack приложения как скелет для навешивания функционала.
Эта статья будет полезна, если вы:
Почему выбрал такой стек:
- Angular: имею много опыта в нем, люблю строгую архитектуру и Typescript из коробки, выходец из .NET
- NestJS: тот-же язык, та-же архитектура, быстрое написание REST API, возможность в дальнейшем пересесть на Serverless (дешевле виртуалки)
- PostgreSQL: Собираюсь хоститься в Яндекс.Облаке, на минималках дешевле на 30% чем MongoDB

Прежде чем написать статью, поискал на хабре статьи про подобный кейс, нашел следующее:
- Angular и SEO: как их подружить?
- Firebase + Angular Universal = невозможное возможно
- Дружим Angular с Google (Angular Universal)
- Удивительный Angular
Из этого ничего не описывает "скопировал и вставил" или дает ссылки на то что еще нужно дорабатывать.
Оглавление:
1. Создаем Angular приложение и добавляем
библиотеку компонентов ng-zorro
2. Устанавливаем NestJS и решаем проблемы с
SSR
3. Делаем API на NestJS и подключаем к
фронту
4. Подключаем базу данных PostgreSQL
1. Создаем Angular приложение
Установим Angular-CLI чтобы создавать SPA-сайты на Ангуляре:
npm install -g @angular/cli
Создадим Angular приложение с помощью следующей команды:
ng new angular-habr-nestjs
Далее переходим в папку приложения и запускаем, чтобы проверить работоспособность:
cd angular-habr-nestjsng serve --open

Приложение создалось. Подключаем библиотеку NG-Zorro:
ng add ng-zorro-antd
Далее выбираем следующие конфигурации библиотеки:
? Enable icon dynamic loading [ Detail: https://ng.ant.design/components/icon/en ] Yes? Set up custom theme file [ Detail: https://ng.ant.design/docs/customize-theme/en ] No? Choose your locale code: ru_RU? Choose template to create project: sidemenu
Эта конфигурация заменит содержимое app.component на дизайн с менюшкой слева, футером и хедером и подключит локализацию на русском языке:

В данной статье мы отобразим список данных для наглядности,
поэтому добавим простенькую табличку в компоненте
src/app/pages/welcome, который сгенерил NG-Zorro:
Пример взят отсюда:
https://ng.ant.design/components/table/en
// welcome.component.html<nz-table #basicTable [nzData]="items$ | async"> <thead> <tr> <th>Name</th> <th>Age</th> <th>Address</th> </tr> </thead> <tbody> <tr *ngFor="let data of basicTable.data"> <td>{{ data.name }}</td> <td>{{ data.age }}</td> <td>{{ data.address }}</td> </tr> </tbody></nz-table>
// welcome.module.tsimport { NgModule } from '@angular/core';import { WelcomeRoutingModule } from './welcome-routing.module';import { WelcomeComponent } from './welcome.component';import { NzTableModule } from 'ng-zorro-antd';import { CommonModule } from '@angular/common';@NgModule({ imports: [ WelcomeRoutingModule, NzTableModule, // Добавили для таблицы CommonModule // Добавили для пайпа async ], declarations: [WelcomeComponent], exports: [WelcomeComponent]})export class WelcomeModule {}
// welcome.component.tsimport { Component, OnInit } from '@angular/core';import { Observable, of } from 'rxjs';import { HttpClient } from '@angular/common/http';import { share } from 'rxjs/operators';@Component({ selector: 'app-welcome', templateUrl: './welcome.component.html', styleUrls: ['./welcome.component.scss']})export class WelcomeComponent implements OnInit { items$: Observable<Item[]> = of([ {name: 'Вася', age: 24, address: 'Москва'}, {name: 'Петя', age: 23, address: 'Лондон'}, {name: 'Миша', age: 21, address: 'Париж'}, {name: 'Вова', age: 23, address: 'Сидней'} ]); constructor(private http: HttpClient) { } ngOnInit() { } // Сразу напишем метод к бэку, понадобится позже getItems(): Observable<Item[]> { return this.http.get<Item[]>('/api/items').pipe(share()); }}interface Item { name: string; age: number; address: string;}
Получилось следующее:

2. Устанавливаем NestJS
Далее установим NestJS таким образом, чтобы он предоставил Angular Universal (Server Side Rendering) из коробки и напишем пару ендпоинтов.
ng add @nestjs/ng-universal
После установки, запускаем наш SSR с помощью команды:
npm run serve
И вот уже первый косяк :) У нас появляется следующая ошибка:
TypeError: Cannot read property 'indexOf' of undefined at D:\Projects\angular-habr-nestjs\node_modules\@nestjs\ng-universal\dist\utils\setup-universal.utils.js:35:43 at D:\Projects\angular-habr-nestjs\dist\server\main.js:107572:13 at View.engine (D:\Projects\angular-habr-nestjs\node_modules\@nestjs\ng-universal\dist\utils\setup-universal.utils.js:30:11) at View.render (D:\Projects\angular-habr-nestjs\node_modules\express\lib\view.js:135:8) at tryRender (D:\Projects\angular-habr-nestjs\node_modules\express\lib\application.js:640:10) at Function.render (D:\Projects\angular-habr-nestjs\node_modules\express\lib\application.js:592:3) at ServerResponse.render (D:\Projects\angular-habr-nestjs\node_modules\express\lib\response.js:1012:7) at D:\Projects\angular-habr-nestjs\node_modules\@nestjs\ng-universal\dist\angular-universal.module.js:60:66 at Layer.handle [as handle_request] (D:\Projects\angular-habr-nestjs\node_modules\express\lib\router\layer.js:95:5) at next (D:\Projects\angular-habr-nestjs\node_modules\express\lib\router\route.js:137:13)
Чтобы решить косяк, зайдем в файл server/app.module.ts и поменяем значение liveReload на false:
import { Module } from '@nestjs/common';import { AngularUniversalModule } from '@nestjs/ng-universal';import { join } from 'path';@Module({ imports: [ AngularUniversalModule.forRoot({ viewsPath: join(process.cwd(), 'dist/browser'), bundle: require('../server/main'), liveReload: false }) ]})export class ApplicationModule {}
Также подтюним конфиг тайпскрипта, так-как эта конфигурация не взлетает с использованием Ivy рендера:
// tsconfig.server.json{ "extends": "./tsconfig.app.json", "compilerOptions": { "outDir": "./out-tsc/server", "target": "es2016", "types": [ "node" ] }, "files": [ "src/main.server.ts" ], "angularCompilerOptions": { "enableIvy": false, // Добавили флажок "entryModule": "./src/app/app.server.module#AppServerModule" }}
После пересоберем приложение командой ng run serve чтобы SSR заработал.

Ура! SSR подрубился, но как видимо в devtools он приходит с кривыми стилями.
Добавим extractCss: true, который позволит выносить стили не в styles.js, а в styles.css:
// angular.json..."architect": { "build": { "builder": "@angular-devkit/build-angular:browser", "options": { "outputPath": "dist/browser", "index": "src/index.html", "main": "src/main.ts", "polyfills": "src/polyfills.ts", "tsConfig": "tsconfig.app.json", "aot": true, "assets": [ "src/favicon.ico", "src/assets", { "glob": "**/*", "input": "./node_modules/@ant-design/icons-angular/src/inline-svg/", "output": "/assets/" } ], "extractCss": true, // Добавили флажок "styles": [ "./node_modules/ng-zorro-antd/ng-zorro-antd.min.css", "src/styles.scss" ], "scripts": [] },...
Также подключим стили библиотеки в app.component.scss:
// app.component.scss@import "~ng-zorro-antd/ng-zorro-antd.min.css"; // Подключили стили:host { display: flex; text-rendering: optimizeLegibility; -webkit-font-smoothing: antialiased; -moz-osx-font-smoothing: grayscale;}.app-layout { height: 100vh;}...
Теперь стили подключены, SSR отдает страничку со стилями, но мы видим что сначала у нас грузится SSR, потом страница моргает и отрисовывается CSR (Client Side Rendering). Это решается следующим способом:
import { NgModule } from '@angular/core';import { Routes, RouterModule } from '@angular/router';const routes: Routes = [ { path: '', pathMatch: 'full', redirectTo: '/welcome' }, { path: 'welcome', loadChildren: () => import('./pages/welcome/welcome.module').then(m => m.WelcomeModule) }];@NgModule({ imports: [RouterModule.forRoot(routes, {initialNavigation: 'enabled', scrollPositionRestoration: 'enabled'})], // Добавили initialNavigation, scrollPositionRestoration exports: [RouterModule]})export class AppRoutingModule { }
- initialNavigation: 'enabled' дает инструкцию роутингу не отрисовывать страницу, если уже загружена через SSR
- scrollPositionRestoration: 'enabled' скролит страницу наверх при каждом роутинге.
3. Сделаем пару ендпоинтов на NestJS
Перейдем в папку server и создадим первый контроллер items:
cd servernest g module itemsnest g controller items --no-spec
// items.module.tsimport { Module } from '@nestjs/common';import { ItemsController } from './items.controller';@Module({ controllers: [ItemsController]})export class ItemsModule {}
// items.controller.tsimport { Controller } from '@nestjs/common';@Controller('items')export class ItemsController {}
Контроллер и модуль создались. Создадим метод на получение списка items и на добавление объекта в список:
// server/src/items/items.controller.tsimport { Body, Controller, Get, Post } from '@nestjs/common';class Item { name: string; age: number; address: string;}@Controller('items')export class ItemsController { // для простоты данные взял из Angular private items: Item[] = [ {name: 'Вася', age: 24, address: 'Москва'}, {name: 'Петя', age: 23, address: 'Лондон'}, {name: 'Миша', age: 21, address: 'Париж'}, {name: 'Вова', age: 23, address: 'Сидней'} ]; @Get() getAll(): Item[] { return this.items; } @Post() create(@Body() newItem: Item): void { this.items.push(newItem); }}
Попробуем вызвать GET в Postman:

Отлично, работает! Обратите внимание, вызываем метод GET items с префиксом api, который ставится автоматически в файле server/main.ts при установке NestJS:
// server/main.tsimport { NestFactory } from '@nestjs/core';import { ApplicationModule } from './app.module';async function bootstrap() { const app = await NestFactory.create(ApplicationModule); app.setGlobalPrefix('api'); // Это префикс await app.listen(4200);}bootstrap();
Теперь прикрутим бэк к фронту. Возвращаемся к файлу welcome.component.ts и делаем запрос списка к бэку:
// welcome.component.tsimport { Component, OnInit } from '@angular/core';import { Observable, of } from 'rxjs';import { HttpClient } from '@angular/common/http';import { share } from 'rxjs/operators';@Component({ selector: 'app-welcome', templateUrl: './welcome.component.html', styleUrls: ['./welcome.component.scss']})export class WelcomeComponent implements OnInit { items$: Observable<Item[]> = this.getItems(); // прикрутили вызов бэка constructor(private http: HttpClient) { } ngOnInit() { } getItems(): Observable<Item[]> { return this.http.get<Item[]>('/api/items').pipe(share()); }}interface Item { name: string; age: number; address: string;}
Можно увидеть что апиха на фронте дергается, но также дергается и в SSR, причем с ошибкой:

Ошибка при запросе в SSR решается следующим способом:
// welcome.component.tsimport { Component, OnInit } from '@angular/core';import { Observable, of } from 'rxjs';import { HttpClient } from '@angular/common/http';import { share } from 'rxjs/operators';@Component({ selector: 'app-welcome', templateUrl: './welcome.component.html', styleUrls: ['./welcome.component.scss']})export class WelcomeComponent implements OnInit { items$: Observable<Item[]> = this.getItems(); // прикрутили вызов бэка constructor(private http: HttpClient) { } ngOnInit() { } getItems(): Observable<Item[]> { return this.http.get<Item[]>('http://localhost:4200/api/items').pipe(share()); // Прописали полный путь к апихе чтобы SSR не ругался }}interface Item { name: string; age: number; address: string;}
Чтобы исключить двойной запрос к апихе (один на SSR, другой на фронте), нужно проделать следующее:
- Установим библиотеку @nguniversal/common:
npm i @nguniversal/common
- В файле app/app.module.ts добавим модуль для запросов из SSR:
// app.module.tsimport { BrowserModule } from '@angular/platform-browser';import { NgModule } from '@angular/core';import { AppRoutingModule } from './app-routing.module';import { AppComponent } from './app.component';import { IconsProviderModule } from './icons-provider.module';import { NzLayoutModule } from 'ng-zorro-antd/layout';import { NzMenuModule } from 'ng-zorro-antd/menu';import { FormsModule } from '@angular/forms';import { HttpClientModule } from '@angular/common/http';import { BrowserAnimationsModule } from '@angular/platform-browser/animations';import { NZ_I18N } from 'ng-zorro-antd/i18n';import { ru_RU } from 'ng-zorro-antd/i18n';import { registerLocaleData } from '@angular/common';import ru from '@angular/common/locales/ru';import {TransferHttpCacheModule} from '@nguniversal/common';registerLocaleData(ru);@NgModule({ declarations: [ AppComponent ], imports: [ BrowserModule.withServerTransition({ appId: 'serverApp' }), TransferHttpCacheModule, // Добавили AppRoutingModule, IconsProviderModule, NzLayoutModule, NzMenuModule, FormsModule, HttpClientModule, BrowserAnimationsModule ], providers: [{ provide: NZ_I18N, useValue: ru_RU }], bootstrap: [AppComponent]})export class AppModule { }
Схожую операцию проделаем с app.server.module.ts:
// app.server.module.tsimport { NgModule } from '@angular/core';import { ServerModule, ServerTransferStateModule } from '@angular/platform-server';import { AppModule } from './app.module';import { AppComponent } from './app.component';@NgModule({ imports: [ AppModule, ServerModule, ServerTransferStateModule, // Добавили ], bootstrap: [AppComponent],})export class AppServerModule {}
Хорошо. Теперь получаем данные из апи в SSR, отрисовываем на форме, отдаем на фронт и тот не делает повторных запросов.

4. Подключим базу PostgreSQL
Подключим библиотеки для работы с PostgreSQL, также будем использовать TypeORM для работы с базой:
npm i pg typeorm @nestjs/typeorm
Внимание: у вас уже должна быть установлена PostgreSQL с базой внутри.
Описываем конфиг подключения к базе в server/app.module.ts:
// server/app.module.tsimport { Module } from '@nestjs/common';import { AngularUniversalModule } from '@nestjs/ng-universal';import { join } from 'path';import { ItemsController } from './src/items/items.controller';import { TypeOrmModule } from '@nestjs/typeorm';@Module({ imports: [ AngularUniversalModule.forRoot({ viewsPath: join(process.cwd(), 'dist/browser'), bundle: require('../server/main'), liveReload: false }), TypeOrmModule.forRoot({ // Конфиг подключения к базе type: 'postgres', host: 'localhost', port: 5432, username: 'postgres', password: 'admin', database: 'postgres', entities: ['dist/**/*.entity{.ts,.js}'], synchronize: true }) ], controllers: [ItemsController]})export class ApplicationModule {}
Немного про поля конфига:
- type: указываем название типа базы данных, к которой подключаемся
- host и port: место где база хостится
- username и password: аккаунт для этой базы
- database: название базы
- entities: путь, откуда будем брать сущности для схемы нашей базы
По последнему пункту, нужно создать сущность Item для мапинга полей в базу:
// server/src/items/item.entity.tsimport { Column, CreateDateColumn, Entity, PrimaryGeneratedColumn } from 'typeorm/index';@Entity()export class ItemEntity { @PrimaryGeneratedColumn() id: number; @CreateDateColumn() createDate: string; @Column() name: string; @Column() age: number; @Column() address: string;}
Далее свяжем эту сущность с нашей базой.
// items.module.tsimport { Module } from '@nestjs/common';import { TypeOrmModule } from '@nestjs/typeorm';import { ItemEntity } from './item.entity';import { ItemsController } from './items.controller';@Module({ imports: [ TypeOrmModule.forFeature([ItemEntity]) // Подключаем фича-модуль и указываем сущности базы ], controllers: [ItemsController]})export class ItemsModule {}
Теперь укажем в контроллере, что хотим работать с базой, а не кешем:
// items.controller.tsimport { Body, Controller, Get, Post } from '@nestjs/common';import { ItemEntity } from './item.entity';import { InjectRepository } from '@nestjs/typeorm';import { Repository } from 'typeorm/index';interface Item { name: string; age: number; address: string;}@Controller('items')export class ItemsController { constructor(@InjectRepository(ItemEntity) private readonly itemsRepository: Repository<ItemEntity>) { // Подключили репозиторий } @Get() getAll(): Promise<Item[]> { return this.itemsRepository.find(); } @Post() create(@Body() newItem: Item): Promise<Item> { const item = this.itemsRepository.create(newItem); return this.itemsRepository.save(item); }}
Проверим работу апихи в Postman:

Работает. Потыкали несколько раз постман, посмотрим что записалось в базе с помощью DBeaver:

Отлично! В базе есть, посмотрим как выглядит на фронте:
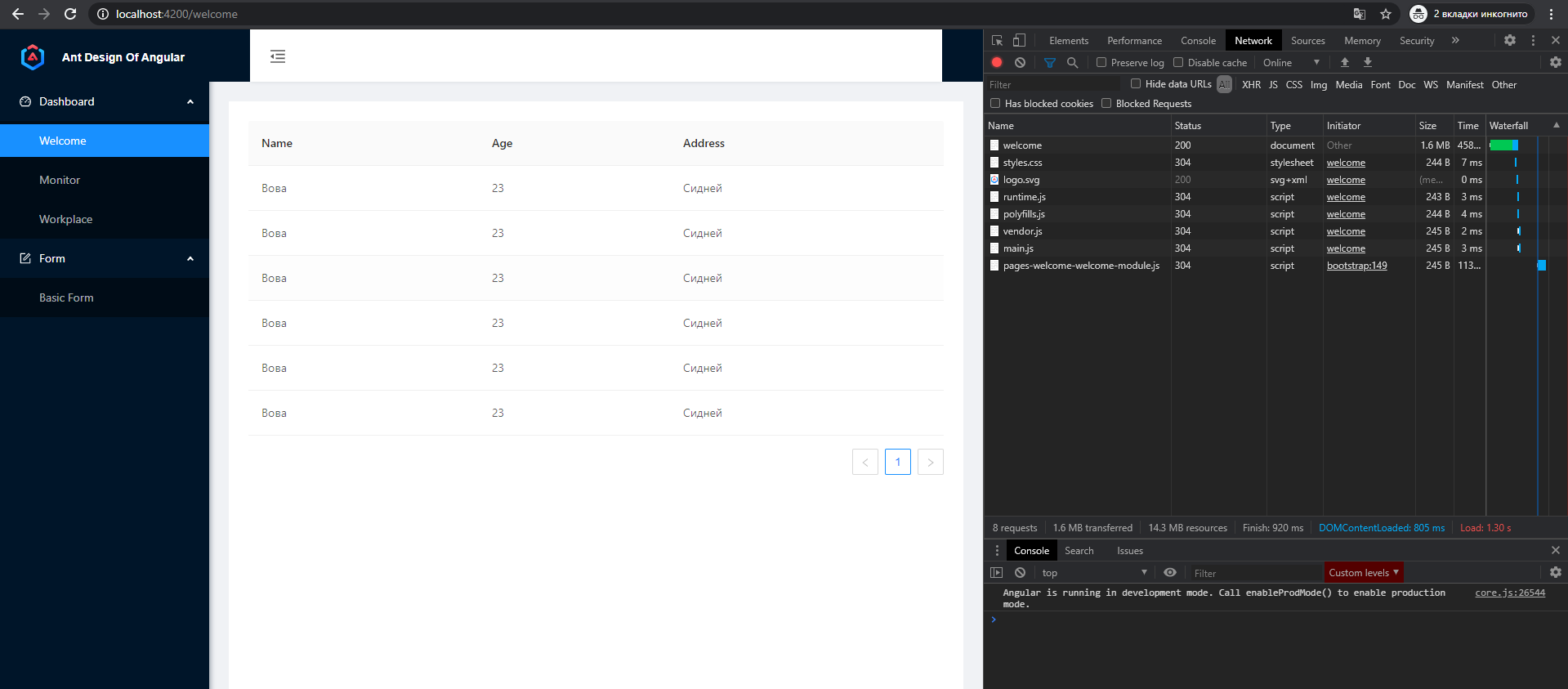
Готово! Мы сделали fullstack приложение, с которым можно работать дальше.
P.S. Сразу поясню следующее:
- Вместо Ng-Zorro вы можете использовать любую другую библиотеку, например Angular Material. Мне она лично не зашла из-за сложности разработки;
- Я знаю, что нужно на бэке использовать сервисы, а не напрямую дергать базу в контроллерах. Эта статья о том, как решив проблемы "влоб" получить MVP с которым можно работать, а не про архитектуру и паттерны;
- Вместо вписывания на фронте http://localhost:4200/api возможно лучше написать интерсептор и проверять откуда мы стучимся

