Зачем всё это нужно?
Долгое время я терпел ограничения РосКомНадзора и
соответствующие действия провайдеров по различным ограничениям
доступа к сайтам - но с определённого момента устал, и начал думать
как бы сделать так, чтобы было и удобно, и быстро, и при этом с
минимумом заморочек после настройки... Хочу оговориться, что цель
анонимизации не ставилась.
Какие вообще уже есть методы решения?
Вообще, эта проблема имеет несколько решений. Кратко перечислю
самые известные и их минусы:
-
Заворачивание всего трафика в VPN-туннель либо какой-то прокси -
как вариант, TOR. В случае с TOR-ом о скорости можно забыть, в
остальных случаях скорость и время отклика также страдают,
поскольку необходимо проксировать через удалённый сервер. Поскольку
РосКомНадзор у нас действует на всей территории России, получается
что весь трафик придётся проксировать через зарубежный сервер, а
значит время отклика (или "пинг") будет сильно страдать. Сразу
отрезается весь пласт, например, игровых приложений.
-
"Гибридный" вариант с использованием списков. Основной трафик
идёт напрямую, но часть IP-адресов перенаправляются через
VPN/прокси/TOR. Списки можно забирать, например, отсюда. Минусы - приходится
периодически обновлять эти списки, и какими бы они не были
актуальными есть вероятность всё же наткнуться на заблокированный
сайт. На самом деле, один из лучших способов для комфортного
пользования интернетом без ограничений. Но можно лучше!
-
Использование "чёрной магии", связанной с особенностями
применяемого провайдерами DPI-софта. Я, в общем и целом, про "дыры"
в обработке трафика (например, блокирование только на уровне DNS,
или пропуск необычно сформированных пакетов), и, в частности, про
GoodbyeDPI уважаемого @ValdikSS.
Самый большой минус - работает далеко не везде. И чем дальше, тем
хуже работает. Рост вычислительных мощностей скорее упрощает жизнь
провайдерам, чем нам в этом вопросе...
-
...и наконец, использование DPI для обхода DPI! На самом деле
этот способ является подвариантом "гибридного", но безо всяких
списков. Мы анализируем пришедшие пакеты от провайдера, делаем
вывод, заблокировал ли он нам что-то, и на этом основании либо
пускаем дальше трафик к запросившему, либо перенаправляем трафик
через VPN/прокси/TOR. Всё ещё требует конфигурации VPN/прокси/TOR,
но уже не требует никаких списков, а также позволяет принимать
решения на основании теоретически сколь угодно сложной логики!
Про последний способ дальше и пойдёт речь. И поможет нам в этом
NGINX.
Во многом идея была вдохновлена Squid-овским механизмом HTTPS
Peek and Splice, но его возможностей к сожалению не хватило.
Так ведь NGINX - это веб-сервер, а не инструмент для DPI?
NGINX - это весьма продвинутый мультипротокольный сервер, и его
возможности в качестве HTTP-сервера - лишь верхушка айсберга. При
этом он кроссплатформенен, имеет мало зависимостей и при этом
бесконечно расширяем.
И самым лучшим расширением NGINX является проект OpenResty -
который добавляет практически ко всем аспектам NGINX-а поддержку
Lua.
Мне могут сейчас возразить, что современный NGINX поддерживает
"изкаробки" возможность скриптинга на JavaScript (njs), и будет
прав, но, во-первых, OpenResty гораздо более развитый проект и его
API имеет гораздо больше возможностей, а во-вторых, OpenResty
использует LuaJit с поддержкой FFI, что позволяет вызывать C-методы
напрямую из Lua-мира - и это создаёт такую возможность для
расширения, которая njs даже и не снилась. Во всяком случае пока
что...
При этом, NGINX имеет возможность проксировать и "сырой"
TCP-трафик (теоретически и UDP тоже, но я реализовал "DPI" только
TCP).
О деталях реализации
Конкретно у меня по причине отсутствия кабельного интернета дома
сейчас используется 4G-интернет от Мегафона, поэтому описание будет
происходить с точки зрения именно Мегафона.
Подробнее как именно всё сконфигурировать будет дальше. Здесь
только общее описание и логика, которой я следовал при
реализации.
Прежде всего, мы поднимаем NGINX в режиме stream на каком-то
порту... Пусть будет 40443. Но сам по себе nginx не знает что
делать с трафиком, что туда приходит. Именно это мы и будем
разруливать с помощью Lua.
Прежде всего, мы перенаправляем весь трафик с 80 и 443 порта на
этот самый 40443 порт при помощи iptables и его команды REDIRECT.
Эта команда интересна тем, что прописывает в свойства сокета опцию
SO_ORIGINAL_DST, в которой сохраняет оригинальный IP и порт, куда
пакет изначально направлялся, до того как iptables над ним зверски
поиздевался, переписав destination... Кхм, я отвлёкся. Эту
информацию можно извлечь при помощи getsockopt... Правда из коробки
обёртки над ним не было, так что пришлось написать простенький
C-модуль для nginx.
Теоретически можно было бы использовать TPROXY, и пропатчить
NGINX для поддержки SO_TRANSPARENT сокетов, но хотелось не
прибегать к прямому патчу исходников NGINX-а и обойтись модулями,
поэтому REDIRECT.
Итак, мы запрашиваем заблокированный сайт... Пусть будет,
например, rutracker.org.
...И сразу надо определиться, по HTTP или HTTPS. Несмотря на то,
что HTTP постепенно умирает, всё же есть ещё сайты, использующие
его. Так что обработка HTTP реализована.
HTTP - тут всё просто
Итак, мы запрашиваем http://rutracker.org. И видим, что нас
перенаправило на http://m.megafonpro.ru/rkn, где Мегафон услужливо
сообщает, что, мол, так и так, сайт заблокирован, просим извинить,
а пока посмотрите на нашу рекламу.
Да, Мегафон просто напросто отправил 307 Temporary Redirect с
Location на свой собственный сайт для отображения этого сообщения.
А значит мы вполне можем отследить ровно это - 307 редирект с
Location в котором http://m.megafonpro.ru/rkn.
Для этого мы вычитываем первые данные, пришедшие от клиента
(вплоть до 16 кбайт, но по факту первые пакеты весьма маленькие),
перенаправляем их серверу и читаем ответ от него. Если находим в
нём этот редирект - это означает сразу две вещи:
-
Сайт блокируется, значит этот коннект надо редиректить.
-
Запрос скорее всего не дошёл до сервера, а значит переотправять
его повторно - безопасно. Это необязательно верно, но верно
наверное в 99% случаев. Правда, если это неверно, и вы отправляете
запросы, что-то меняющие на удалённом сервере, то тут беда...
Прилетит по итогу два запроса - один - тот на который заблокирован
ответ, и второй - спроксированный. И узнать мы это никак не сможем.
Хорошо, что HTTP без SSL становится всё меньше, правда? =)
Если редиректа нету, значит мы просто отправляем этот запрос
дальше клиенту и дальше просто проксируем трафик, не вмешиваясь в
него.
HTTPS вплоть до TLSv1.2 - посложнее
С SSL/TLS всё гораздо сложнее... Но есть и хорошие новости.
Перед любым HTTP-запросом мы сначала должны выполнить Handshake, а
значит первый пакет точно не вызовет выполнение команды на сервере
в случае, если нас заблокировали, но исходный пакет таки ушёл на
сервер.
Мы запрашиваем https://rutracker.org и получаем в браузере...
Ошибку. Сертификат недействительный, потому что выпущен даже не для
этого домена, беда-беда...
Анализируем сам сертификат... И что же мы видим? CN=megafon.ru.
Получается, что для того, чтобы понять, что сайт блокируется,
достаточно вычитать полученный от сервера сертификат, и если мы
запрашиваем что угодно кроме megafon.ru, а получили сертификат с
CN=megafon.ru - нас блокируют, и надо проксировать.
Осталось только понять, как понять, куда именно мы изначально
обращались, и как получить этот сертификат.
И здесь нам поможет SNI - дело в том, что (современный, мы не
говорим про эпоху IE6, она ушла и слава богу) клиент отправляет
домен, к которому обращается, в составе незашифрованных данных
ClientHello. Самое интересное, что эти данные умеет вычитывать даже
сам NGINX из коробки - модуль ssl_preread поставляется вместе с
ним. Ну а Lua-биндинги позволяют получить эту информацию и для
наших целей...
Итак, что мы делаем? Процедура во многом аналогична HTTP - мы
отправляем первый пакет от клиента серверу (который как раз
содержит ClientHello) и ждём от сервера ответа с сертификатом.
После чего убеждаемся что SNI не megafon.ru, парсим сертификат
(спасибо человеку, написавшему биндинги к OpenSSL для Lua), и
принимаем решение - проксировать или нет.
И всё было бы хорошо, если бы не TLSv1.3, который всю эту
историю сильно обламывает...
TLSv1.3 наносит ответный удар
Во-первых, в TLSv1.3 SNI может быть зашифрованным. Хорошая
новость в том, что зашифрованный SNI не расшифрует и сам провайдер,
а значит он будет блокировать любые TLS-запросы к IP точно также.
Вторая особенность в том, что сертификат сервер клиенту теперь тоже
отправляет в зашифрованном виде...
Проблема усугубляется ещё и тем, что Мегафон отправляет свой
сертификат как раз таки по TLSv1.3, то есть зашифрованным, в случае
если клиент поддерживает TLSv1.3. А все основные браузеры сейчас
его поддерживают. Проблема...
На этом этапе я уже даже думал о том, чтобы патчить ClientHello,
убирая из него поддержку TLSv1.3, осуществляя по сути атаку на
downgrade до TLSv1.2, но вовремя почитал описание TLSv1.3. В нём
реализовано аж ДВА механизма по предотвращению подобных
даунгрейдов, поэтому вариант плохой.
...И здесь приходится прибегать к экстренным мерам. На самом
деле этот метод я реализовал даже первым, и он по сути и является
сутью метода peek and splice у Squid-а.
Мы не можем просто взять и вычитать сертификат. Поэтому мы
просто открываем свой собственный коннект к серверу и пытаемся сами
совершить tls-handshake. Получаем из него сертификат с
CN=megafon.ru? Значит нас блокируют. Нет? Значит всё в порядке. И
нам не сильно важно какой другой - да пусть даже мы дисконнект
получим. Главное, что мы не получили сертификат, который является
флагом блокировки.
Единственным минусом такого подхода является то, что в случае,
если Мегафон начнёт поддерживать eSNI, то коннекты к его сайту
будут проксироваться, но пока что SNI у него вполне
незашифрованный. Да и, на самом деле, сертификат там
самоподписанный отдаётся, так что можно и углубить проверку.
А что дальше с заблокированным трафиком-то делать?
Итак, мы понимаем, что сайт блокируется. Что делать? Лучшее и
наиболее универсальное что я придумал - это SOCKS5 прокси. Протокол
проще некуда, к нему есть удобная клиентская реализация, которую
чуть доработать - и можно пользоваться. Вдобавок, SOCKS5 реализован
в Tor и SSH. Поднять SOCKS5-сервер - дело пяти минут.
Особенности некоторых сайтов и приятный бонус
Во время тестов я натолкнулся на весьма странное поведение
linkedin.com. Дело в том, что при его запросе почему-то я вообще не
получал никакого ответа, коннект просто уходил в таймаут. Я решил,
что если коннект таймаутится, есть смысл попробовать его тоже
перенаправить через VPN - хуже точно не будет.
Каково же было моё удивление, когда точно такое же поведение
было и через VPN. Причём, с подключением через VPN IPv4 не
соединялся, а по IPv6 вполне всё работало.
Тут я вспомнил, что у SOCKS5 есть два режима подключения к
удалённому хосту - по IP и по хосту. Поэтому я реализовал следующую
обработку соединения (Hostname мы получаем из SNI):
direct IP => direct Hostname => socks5 IP => socks5
Hostname
С таймаутом на соединение в 2 секунды. В чём смысл? Если вдруг
оказывается, что наша машина, на котором развёрнут NGINX
оказывается IPv6-capable, а изначальный клиент нет, то мы сможем
спроксировать трафик через IPv6, при том, что клиент будет думать
что соединяется по IPv4. Аналогично и с прокси-сервером.
А что насчёт производительности?
Конкретно в моём случае, основные затраты на производительность
- при первичном подключении к серверу. Но, честно говоря, даже они
минимальны. После соединения потребление что CPU, что RAM остаётся
почти незаметным. Конечно, Netgear R7000 достаточно мощная машинка
- двухядерник с 1 GHz ядрами и 256 МБ оперативки - но он даже не
нагружается на 10% во время обычного использования (активного
сёрфинга, просмотра видео на YouTube). При прогоне спидтеста
потребление вообще остаётся на уровне 5% CPU. Самую большую
нагрузку составил как ни странно сайт по проверке замедления t.co
(https://speed.gulag.link/) - вот
там ядра напрягаются до 80% на одном ядре (и около 25% на другом),
но при этом так и не достигают 100%.
Итак, переходим к практике - что нам для этого
потребуется?
В качестве железа подойдёт почти что всё что угодно, на чем
можно запустить Linux. В моём случае, я запускаю это всё на Netgear
R7000 с ARM-процессором внутри, и кастомной прошивкой с версией
ядра всего лишь 2.6.36. В общем и целом теоретически запустится на
практически любом Linux-е с версией ядра хотя бы 2.6.32.
Поскольку решение не совсем стандартное, придётся пересобирать
NGINX/OpenResty из исходников. Я успешно собирал прямо на самом
роутере - занимает некоторое время, но не так чтобы
бесконечное.
Конкретно нужно:
-
OpenResty - это NGINX с LuaJit и основными Lua модулями. Я
скачивал релизный тарболл из их раздела загрузок.
-
lua-resty-openssl и его
C-модуль к NGINX lua-resty-openssl-aux-module.
Нужен для получения и разбора сертификатов SSL-сессий.
-
Мой самописный C-модуль к NGINX и Lua-биндинг lua-resty-getorigdest-module
для получения информации об IP и порте того, куда изначально
обращался клиент.
-
lua-struct для парсинга бинарных
пакетов (в частности, поиска сертификата после ServerHello).
-
Мой форк SOCKS5 Lua-клиента lua-resty-socks5 уважаемого
@starius,
которому была добавлена возможность соединяться через SOCKS5 не
только по хостнейму, но и по IP-адресу.
-
SOCKS5 прокси-сервер для проксирования заблокированного трафика
- например, socks-прокси TOR-а, либо обыкновенный ssh
-D. Для VPN-сервера - надо установить его на самом
VPN-сервере и проксировать через него. Настройка socks-прокси
выходит за рамки этой статьи.
Также я исхожу из того, что запускаете вы это на устройстве,
маршрутизирующем ваш доступ к интернету - в моём случае это роутер.
Оно должно завестись в том числе и на локалхосте, но для этого
придётся садаптировать правила iptables. Также, исхожу из того, что
трафик от клиентов приходит с br0 устройства.
Подготовка и сборка
Предполагаю, что сборку осуществляем в /home/username/build.
Устанавливать будем в /opt/nginxdpi
-
Разархивируем тарболл openresty, делаем git clone всем указанным
выше дополнениям. Для удобства переименовываем папку
openresty-X.Y.Z.V в openresty.
-
Переходим в /home/username/build/openresty, выполняем:
./configure --prefix=/opt/nginxdpi --with-cc=gcc \
--add-module=/home/username/build/lua-resty-openssl-aux-module
\
--add-module=/home/username/build/lua-resty-openssl-aux-module/stream
\
--add-module=/home/username/build/lua-resty-getorigdest-module/src
-
Выполняем make -j4 && make install, ждём пока
всё соберётся...
-
После сборки копируем:
cp -r /home/username/build/lua-resty-getorigdest-module/lualib/* /opt/nginxdpi/lualib/ cp -r /home/username/build/lua-resty-openssl/lib/resty/* /opt/nginxdpi/lualib/resty/cp -r /home/username/build/lua-resty-openssl-aux-module/lualib/* /opt/nginxdpi/lualib/cp /home/username/build/lua-resty-socks5/socks5.lua /opt/nginxdpi/lualib/resty/cp /home/username/build/lua-struct/src/struct.lua /opt/nginxdpi/lualib/
Готово! Можно приступать к конфигурированию.
Конфигурация
Вся логика содержится в следующем конфигурационном файле:
nginx.conf
user root;worker_processes auto;events { worker_connections 1024;}stream { preread_buffer_size 16k; server { listen 30443 so_keepalive=on; tcp_nodelay on; #error_log /opt/nginxdpi/cfg/nginx/error.log info; error_log off; lua_socket_connect_timeout 2s; ssl_preread on; content_by_lua_block { local prefer_hosts = false; local prefer_socks_hosts = true; local host = nil; local socket = ngx.req.socket(true); socket.socktype = "CLIENT"; local god = require("resty.getorigdest"); local dest = god.getorigdest(socket); local sni_name = ngx.var.ssl_preread_server_name; ngx.log(ngx.DEBUG, dest); ngx.log(ngx.DEBUG, sni_name); local openssl = require("resty.openssl"); openssl.load_modules(); local ngx_re = require("ngx.re"); local cjson = require("cjson"); local socks5 = require("resty.socks5"); local struct = require("struct"); local dests = ngx_re.split(dest, ":"); local dest_addr = dests[1]; local dest_port = tonumber(dests[2]); local connect_type_last = nil; local socket_create_with_type = function(typename) local target = ngx.socket.tcp(); target.socktype = typename; return target; end local socket_connect_dest = function(target) local ok = nil; local err = nil; if (prefer_hosts == true and host ~= nil) then ok, err = target:connect(host, dest_port); connect_type_last = "host"; if (err ~= nil) then local socktype = target.socktype; target = socket_create_with_type(socktype); ok, err = target:connect(dest_addr, dest_port); connect_type_last = "ip"; end else ok, err = target:connect(dest_addr, dest_port); connect_type_last = "ip"; if (err ~= nil and host ~= nil) then local socktype = target.socktype; target = socket_create_with_type(socktype); ok, err = target:connect(host, dest_port); connect_type_last = "host"; end end if (ok == nil and err == nil) then err = "failure"; end return target, err; end local intercept = false; local connected = false; local upstream = socket_create_with_type("UPSTREAM"); local bufsize = 1024*16; local peek, err, partpeek = socket:receiveany(bufsize); if (peek == nil and partpeek ~= nil) then peek = partpeek; elseif (err ~= nil) then ngx.log(ngx.WARN, err); end if (dest_port == 80 or ngx.re.match(peek, "(^GET \\/)|(HTTP\\/1\\.0[\\r\\n]{1,2})|(HTTP\\/1\\.1[\\r\\n]{1,2})") ~= nil) then local http_host_find, err = ngx.re.match(peek, "[\\r\\n]{1,2}([hH][oO][sS][tT]:[ ]?){1}(?<host>[0-9A-Za-z\\-\\.]+)[\\r\\n]{1,2}"); local http_host = nil; if (http_host_find ~= nil and http_host_find["host"] ~= false) then http_host = http_host_find["host"]; end if (http_host ~= nil and host == nil) then host = http_host; end upstream = socket_connect_dest(upstream); local ok, err = upstream:send(peek); if (err ~= nil) then ngx.log(ngx.WARN, err); end local data, err, partdata = upstream:receiveany(bufsize); if (data == nil and partdata ~= nil) then data = partdata; elseif (err ~= nil) then ngx.log(ngx.WARN, err); end if (data ~= nil) then local match = "HTTP/1.1 307 Temporary Redirect\r\nLocation: http://m.megafonpro.ru/rkn"; local match_len = string.len(match); local extract = data:sub(1, match_len); if (match == extract) then upstream:close(); upstream = socket_create_with_type("UPSTREAM"); intercept = true; else connected = true; local ok, err = socket:send(data); if (err ~= nil) then ngx.log(ngx.WARN, err); end peek = nil; end end elseif (dest_port == 443 or sni_name ~= nil) then local serv_host = nil; if (sni_name ~= nil and host == nil) then host = sni_name; end local err = nil; upstream, err = socket_connect_dest(upstream); ngx.log(ngx.DEBUG, err); local ok, err = upstream:send(peek); if (err ~= nil) then ngx.log(ngx.WARN, err); end -- Parsing the ServerHello packet to retrieve the certificate local offset = 1; local data = ""; local size = 0; local servercert = nil; upstream:settimeouts(2000, 60000, 1000); while (servercert == nil) do if (size == 0 or offset >= size) then local data2, err, partdata = upstream:receiveany(bufsize); if (data2 ~= nil) then data = data .. data2; elseif (data2 == nil and partdata ~= nil) then data = data .. partdata; elseif (err ~= nil) then ngx.log(ngx.WARN, err); break; end size = data:len(); ngx.log(ngx.DEBUG, "UPSTREAM received for ServerHello certificate retrieval! "..size); end ngx.log(ngx.DEBUG, offset); if (offset < size) then local contenttype, version, length, subtype = struct.unpack(">BHHB", data, offset); if (contenttype ~= 22) then -- We got something other than handshake before we retrieved the cert, probably the server is sending the cert encrypted, fallback to legacy cert retrieval break; elseif (subtype ~= 11) then offset = offset + 5 + length; else local suboffset = offset + 5; local _, _, _, _, certslength, _, firstcertlength = struct.unpack(">BBHBHBH", data, suboffset); -- We need only the first cert, we don't care about the others in the chain local firstcert = data:sub(suboffset + 1 + 3 + 3 + 3, firstcertlength); servercert = firstcert; end end end upstream:settimeouts(2000, 60000, 60000); local cert = nil; if (servercert ~= nil) then cert = openssl.x509.new(servercert, "DER"); ngx.log(ngx.DEBUG, "Cert retrieved from ServerHello peeking"); else -- We employ a legacy method of gathering the certificate, involving connecting to the server and doing a SSL handshake by ourselves local serv = socket_create_with_type("TLSCHECK"); local err = nil; serv, err = socket_connect_dest(serv); ngx.log(ngx.DEBUG, err); local session, err = serv:sslhandshake(false, sni_name, false, false); ngx.log(ngx.DEBUG, err); local sslsess, err = openssl.ssl.from_socket(serv); ngx.log(ngx.DEBUG, err); if (sslsess ~= nil) then cert = sslsess:get_peer_certificate(); ngx.log(ngx.DEBUG, "Cert retrieved from secondary handshake"); end serv:close(); end -- Parsing the certificate if (cert ~= nil) then local sub = cert:get_subject_name(); local alt = cert:get_subject_alt_name(); for k, obj in pairs(sub) do ngx.log(ngx.DEBUG, k.." "..cjson.encode(obj)); if (serv_host == nil and k == "CN" and obj.blob:find("*", 1, true) == nil) then serv_host = obj.blob; end if (k == "CN" and obj.blob == "megafon.ru" and (sni_name == nil or sni_name:find("megafon.ru", 1, true) == nil)) then ngx.log(ngx.DEBUG, k.." "..obj.blob); upstream:close(); upstream = socket_create_with_type("UPSTREAM"); intercept = true; end end for k, obj in pairs(alt) do ngx.log(ngx.DEBUG, k.." "..cjson.encode(obj)); if (serv_host == nil and k == "DNS" and obj:find("*", 1, true) == nil) then serv_host = obj; end end end if (serv_host ~= nil and host == nil) then host = serv_host; end if (intercept ~= true) then connected = true; local ok, err = socket:send(data); if (err ~= nil) then ngx.log(ngx.WARN, err); end peek = nil; end end if (connected == false and intercept == false) then local err = nil; upstream, err = socket_connect_dest(upstream); if (err ~= nil) then intercept = true; upstream = socket_create_with_type("UPSTREAM"); end end if (intercept == true) then local ok, err = upstream:connect("192.168.120.1", 45213); ngx.log(ngx.DEBUG, err); ok, err = socks5.auth(upstream); ngx.log(ngx.DEBUG, err); local ok = nil; local err = nil; if (prefer_socks_hosts == true and host ~= nil) then ok, err = socks5.connect(upstream, host, dest_port); connect_type_last = "socks_host"; if (err ~= nil) then upstream = socket_create_with_type("UPSTREAM"); upstream:connect("192.168.120.1", 45213); ok, err = socks5.auth(upstream); ok, err = socks5.connect_ip(upstream, dest_ip, dest_port); connect_type_last = "socks_ip"; end else ok, err = socks5.connect_ip(upstream, dest_addr, dest_port); connect_type_last = "socks_ip"; if (err ~= nil and host ~= nil) then upstream = socket_create_with_type("UPSTREAM"); upstream:connect("192.168.120.1", 45213); ok, err = socks5.auth(upstream); ok, err = socks5.connect(upstream, host, dest_port); connect_type_last = "socks_host"; end end ngx.log(ngx.DEBUG, err); end upstream:setoption("keepalive", true); upstream:setoption("tcp-nodelay", true); upstream:setoption("sndbuf", bufsize); upstream:setoption("rcvbuf", bufsize); ngx.log(ngx.INFO, "RESULT: "..tostring(host).."/"..dest_addr..":"..dest_port.." intercept:"..tostring(intercept).." connecttype:"..connect_type_last); local ok = false; if (peek ~= nil and peek:len() > 0) then ok, err = upstream:send(peek); if (err ~= nil) then ngx.log(ngx.WARN, err); end else ok = true; end local pipe = function(src, dst) while true do local data, err, partial = src:receiveany(bufsize); local errs = nil; local ok = false; if (data ~= nil) then ok, errs = dst:send(data) elseif (data == nil and partial ~= nil) then ok, errs = dst:send(partial) elseif (err == 'closed') then ngx.log(ngx.WARN, src.socktype..":"..err); return; elseif (err ~= nil and err ~= "timeout") then ngx.log(ngx.WARN, src.socktype..":"..err); end if (errs == 'closed') then ngx.log(ngx.WARN, dst.socktype..":"..errs); return; elseif (errs ~= nil) then ngx.log(ngx.WARN, dst.socktypeerr..":"..errs); end end end if (ok ~= false) then local co_updown = ngx.thread.spawn(pipe, upstream, socket); local co_downup = ngx.thread.spawn(pipe, socket, upstream); ngx.thread.wait(co_updown); ngx.thread.wait(co_downup); end upstream:close(); ngx.flush(true); socket:shutdown("send"); } }}
Можно было бы наверное разделить lua код от конфига, но мне
было немного лень =)
Замените 192.168.120.1 и 45213 на хост и порт вашего
SOCKS5-сервера!
Размещаем его в /opt/nginxdpi/cfg/nginx.conf
Создаём файл /opt/nginxdpi/cfg/start.sh со следующим
содержимым:
start.sh
#!/bin/sh/opt/nginxdpi/bin/openresty -c /opt/nginxdpi/cfg/nginx.confiptables -t nat -A PREROUTING -i br0 -p tcp -m tcp --dport 80 -j REDIRECT --to-ports 30443iptables -t nat -A PREROUTING -i br0 -p tcp -m tcp --dport 443 -j REDIRECT --to-ports 30443
Обратите внимание, что br0 - это интерфейс локальной
сети, с которого подключаются клиенты!
Даём start.sh права на выполнение chmod +x
/opt/nginxdpi/cfg/start.sh, и наконец запускаем всё это
добро (от рута! В принципе теоретически может заработать и без
рута, но я не пробовал...):
/opt/nginxdpi/cfg/start.sh
После этого весь ваш HTTP и HTTPS трафик будет проксироваться
через этот сервер.
Что можно сделать ещё?
На самом деле есть несколько вещей, которые можно доработать,
разной степени сложности.
Во-первых, как я уже писал, для того, чтобы исключить проблемы с
ненужным проксированием провайдерского сайта в случае если они
начнут использовать eSNI, есть смысл проверять сертификат на
самоподписанность - это несложно средствами OpenSSL.
Во-вторых, пока что совершенно не поддерживается IPv6. Добавить
поддержку на самом деле несложно... С другой стороны, как правило
IPv6 трафик сейчас фильтруется редко (если вообще где-то
фильтруется).
В-третьих, опять таки не поддерживается UDP. И если на текущем
этапе это не столь критично (мало что по UDP сейчас блокируется),
то с развитием HTTP3/QUIC эта проблема будет гораздо более
критичной. Правда как проксировать QUIC я пока понятия не имею, да
и DTLS отличается от TLS... Там будет хватать своих проблем. Это,
наверное, самая сложная задача.
И в завершение...
На самом деле этот механизм можно использовать и для
полноценного DPI. По сути мы получаем полноценную TCP-сессию,
которую можем инспектировать "на лету" - достаточно, по сути,
пропатчить pipe-функцию. С другой стороны, смысла в анализе сырых
данных после завершения SSL-handshake нынче мало, а зашифрованного
трафика становится только больше...
Этот же метод в принципе позволяет и записывать трафик - закон
Яровой исполнять, например. Надеюсь я не открыл сейчас ящик
Пандоры... =)
...вдруг кому-то из провайдеров этот метод позволит сэкономить
на DPI-софте и уменьшить цену тарифов? =) Кто знает.
Скажу честно, местами мне было лень обрабатывать ошибки, поэтому
возможно странное поведение. Если обнаружите какие-то ошибки
пишите, попробую поправить - но в принципе я сижу через этот DPI
сейчас сам, и проблем особых не заметил (а те что заметил -
пофиксил).
Желаю удачи в адаптации под своих провайдеров!













 Создаем аккаунт.
Создаем аккаунт. Меняем домашний сервер. Придумываем логин
и пароль. Дальше надо будет создать ключи шифрования, просто
следуйте инструкциям riot.
Меняем домашний сервер. Придумываем логин
и пароль. Дальше надо будет создать ключи шифрования, просто
следуйте инструкциям riot.
 Искать пользователя надо в данном формате.
Искать пользователя надо в данном формате.

 Пример фильтрации логов. Выполнена
фильтрация по значению поля "status", так же выбраны только
необходимые в данный момент поля.
Пример фильтрации логов. Выполнена
фильтрация по значению поля "status", так же выбраны только
необходимые в данный момент поля.












 Анимация manual mode
Анимация manual mode
 Анимация API mode
Анимация API mode

 Анимация alias mode
Анимация alias mode











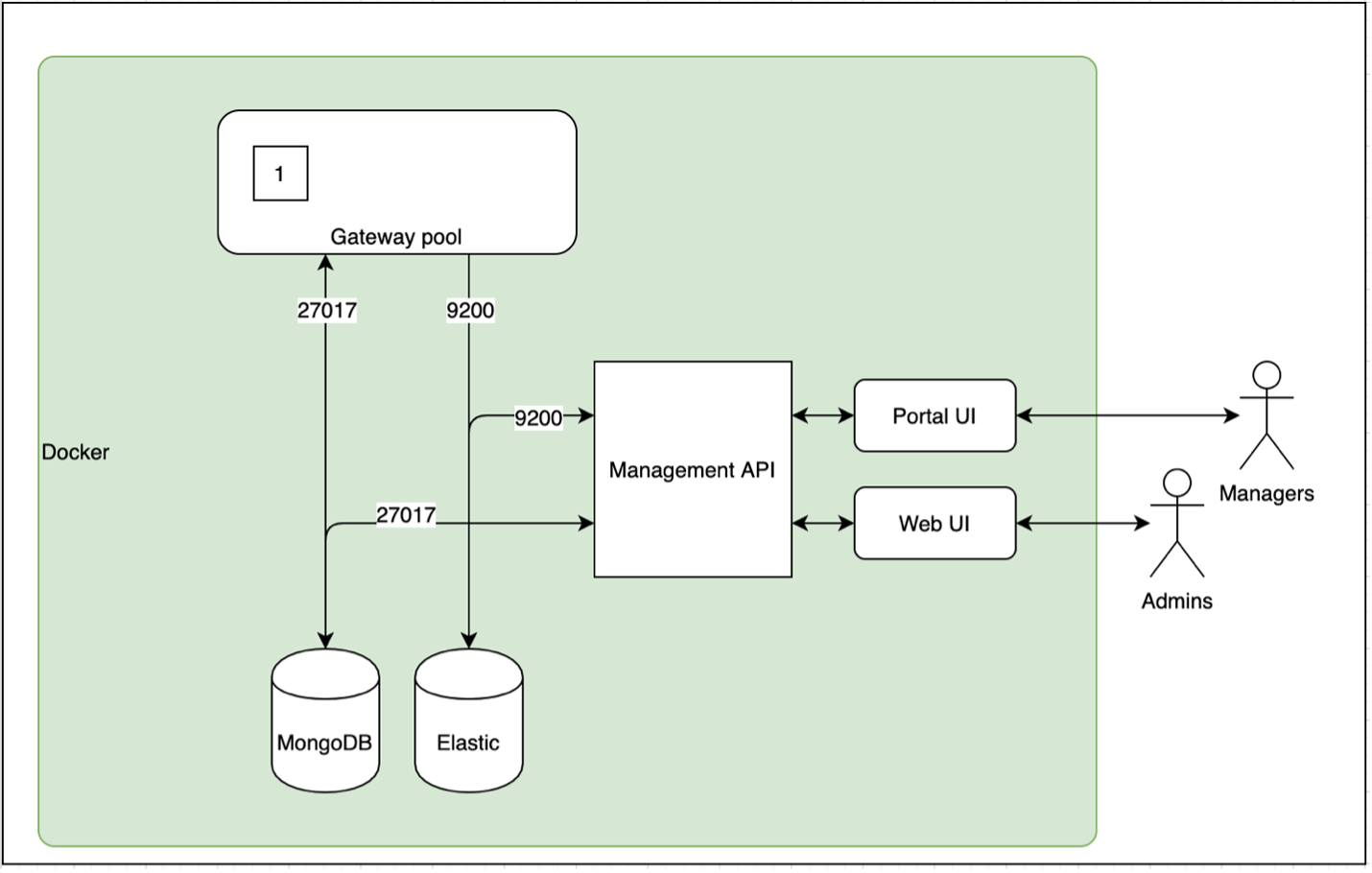


































 Упрощенная схема взаимодействия между
пользователями и серверами
Упрощенная схема взаимодействия между
пользователями и серверами

 Управление доступами по паролю и по IP-адресу
Управление доступами по паролю и по IP-адресу
 Форма аутентификации для сотрудников
Форма аутентификации для сотрудников

 web-интерфейс transmission
web-интерфейс transmission
 Приветственное сообщение от Nginx
Приветственное сообщение от Nginx
 html страница скачанная из интернета
html страница скачанная из интернета
 transmission-daemon просит X-Transmission-Session-Id
transmission-daemon просит X-Transmission-Session-Id
 transmission заработал
transmission заработал


 Каин послеубийства своего брата
Авелявзгляда на российское айти в 2020 коллаж автора
Каин послеубийства своего брата
Авелявзгляда на российское айти в 2020 коллаж автора