
История о том, как мы оказались на грани банкротства, не успев даже
запустить первый продукт, как нам удалось выжить и какие уроки мы
извлекли.
В марте 2020 года, когда COVID поразил весь мир, наш стартап Milkie
Way тоже сильно пострадал и почти закрылся. Мы сожгли 72 000
долларов во время изучения и внутреннего тестирования Cloud Run с
Firebase в течение нескольких часов.
Я начал разработку сервиса
Announce в ноябре 2019 года. Главная цель состояла в
выпуске минимально функциональной первой версии продукта, поэтому
код работал на простом стеке. Мы использовали JS, Python и
развернули наш продукт на Google App Engine.
С очень маленькой командой мы сосредоточились на написании кода,
разработке пользовательского интерфейса и подготовке продукта. Я
практически не тратил времени на управление облаком потратил ровно
столько, чтобы поднять систему и обеспечить базовый процесс
разработки (CI/CD).
 Десктопный Announce
Десктопный Announce
Первая версия была не очень удобной, но мы просто хотели выпустить
версию для экспериментов, а потом уже работать над нормальной. В
связи с COVID мы подумали, что сейчас хорошее время для запуска,
поскольку государственные службы по всему миру могут использовать
Announce для публикации оповещений.
Разве не здорово сгенерировать на платформе немного данных, когда
пользователи ещё не закачали свою информацию? Эта мысль привела к
появлению другого проекта
Announce-AI для генерации
контента. Богатые данные это различные события, такие как
оповещения о землетрясениях и, возможно, релевантные местные
новости.
Некоторые технические детали
Для начала разработки Announce-AI мы использовали Cloud Functions.
Поскольку наш бот для скрапинга был ещё на начальной стадии, мы
решили взять эти легковесные функции. Но при масштабировании
возникли проблемы, потому что у облачных функций тайм-аут около 9
минут.
И вдруг мы узнали о системе Cloud Run, у которой тогда был большой
лимит бесплатного использования! Не разобравшись полностью, я
попросил команду развернуть тестовую функцию Announce-AI в Cloud
Run и оценить её производительность. Цель состояла в том, чтобы
поиграться с Cloud Run для накопления опыта.
 Google Cloud Run
Google Cloud Run
Поскольку у нас очень маленький сайт, то для простоты мы
использовали БД Firebase, так как у Cloud Run нет никакого
хранилища, а деплой SQL Server или другую БД слишком чрезмерен для
теста.
Я создал новый проект GCP ANC-AI Dev, настроил бюджет облачного
биллинга на 7 долларов, сохранил проект Firebase по бесплатному
плану (Spark). Худший вариант, который мы представляли, это
превышение ежедневного лимита Firebase.
После некоторых модификаций мы подготовили код, сделали несколько
запросов вручную, а затем оставили его работать.
Кошмар начинается
В день тестирования всё прошло нормально, и мы вернулись к
разработке Announce. На следующий день после работы ближе к вечеру
я пошёл слегка вздремнуть. Проснувшись, я увидел несколько писем из
Google Cloud, все с интервалом в несколько минут.
Первое письмо: автоматический апгрейд нашего проекта
Firebase
 Второе письмо: бюджет превышен
Второе письмо: бюджет превышен

К счастью, на моей карте был установлен лимит в $100. Из-за этого
платежи не прошли, а Google приостановил обслуживание наших
аккаунтов.
Третье письмо: карта отклонена

Я вскочил с кровати, вошёл в биллинг Google Cloud и увидел счёт
примерно на $5000. В панике начал щёлкать по клавишам, не понимая,
что происходит. В фоновом режиме начал размышлять, как такое могло
произойти и как оплатить счёт на $5000, в случае чего.
Проблема была в том, что с каждой минутой счёт продолжал расти.
Через пять минут он показывал $15000 долларов, через 20 минут
$25000. Я не понимал, когда цифры перестанут увеличиваться. Может,
они будут расти до бесконечности?
Через два часа цифра остановилась на отметке чуть меньше
$72000.
К этому времени мы с командой были на телеконференции, я был в
полном шоке и не имел абсолютно никакого понятия, что делать
дальше. Мы отключили биллинг, закрыли все сервисы.
Поскольку во всех проектах GCP мы рассчитывались одной картой, все
наши учётные записи и проекты были приостановлены.
Кошмар продолжается
Это произошло в пятницу вечером, 27 марта за три дня до того, как
мы планировали запустить первую версию. Теперь разработка
остановилась, потому что Google приостановила все наши проекты,
привязанные к одной карте. Мой боевой дух ниже плинтуса, а будущее
компании казалось неопределённым.
 Все наши облачные проекты приостановлены, разработка
остановлена
Все наши облачные проекты приостановлены, разработка
остановлена
Как только разум смирился с новой реальностью, в полночь я решил
нормально разобраться, что же произошло. Я начал составлять
документ с подробным расследованием инцидента и назвал его Глава 11
[это глава из закона о банкротстве прим. пер.].
Двое коллег, участвовавших в эксперименте, тоже не спали всю ночь,
исследуя и пытаясь понять, что произошло.
На следующее утро, в субботу 28 марта, я позвонил и написал письма
десятку юридических фирм, чтобы записаться на приём или поговорить
с адвокатом. Все они были в отъезде, но я смог получить ответ от
одного из них по электронной почте. Поскольку детали инцидента
настолько сложны даже для инженеров, объяснить это адвокату на
простом английском языке было само по себе непросто.
Для нас как начинающего стартапа не было никакой возможности
возместить $72000.
К этому времени я уже хорошо изучил 7-ю и 11-ю главы закона о
банкротстве и мысленно готовился к тому, что может произойти
дальше.
Некоторая передышка: лазейки GCP
В субботу после рассылки электронных писем юристам я начал дальше
читать и просматривать каждую страницу документации GCP. Мы
действительно совершали ошибки, но не было никакого смысла в том,
что Google позволил нам резко потратить $72000, если раньше мы
вообще не делали никаких платежей!
 GCP и Firebase
GCP и Firebase
1. Автоматический апгрейд аккаунта Firebase на платный
аккаунт
Мы такого не ожидали, и об этом нигде не предупреждалось при
регистрации на Firebase. Наш биллинг GCP был подключён к исполнению
Cloud Run, но Firebase шла под бесплатным планом (Spark). GCP
просто ни с того ни с сего провела апгрейд на платный тариф и взяла
с нас необходимую сумму.
Оказывается, этот процесс у них называется глубокая интеграция
Firebase и GCP.
2. Биллинговых лимитов не существует. Бюджеты запаздывают
минимум на сутки
Выставление счетов GCP фактически задерживается как минимум на
сутки. В большинстве документов Google предлагает использовать
бюджеты и функцию автоматического отключения облака. Но к тому
времени, когда сработает функция отключения или пользователю
пришлют уведомление, ущерб уже будет нанесён.
Синхронизация биллинга занимает около суток, именно поэтому мы
заметили счёт на следующий день.
3. Google должен был взять 100 долларов, а не 72 тысячи!
Поскольку с нашего аккаунта до сих пор не проходило никаких
платежей, GCP должен был сначала взять плату в размере 100 долларов
в соответствии с платёжной информацией, а при неуплате прекратить
услуги. Но этого не произошло. Я понял причину позже, но это тоже
не по вине пользователя!
Первый счёт для нас составил около $5000. Следующий на $72тыс.
 Порог выставления счетов для нашего аккаунта составляет
$100
Порог выставления счетов для нашего аккаунта составляет
$100
4. Не полагайтесь на панель управления Firebase!
Не только биллинг, но и обновление панели управления Firebase
заняло более 24-х часов.
Согласно документации Firebase Console, цифры в панели управления
могут незначительно отличаться от отчётов биллинга.
В нашем случае они отличались на 86585365,85%, или 86 миллионов
процентных пунктов. Даже когда пришёл счёт, панель управления
Firebase Console ещё показывала 42000 операций чтения и записи в
месяц (ниже дневного лимита).
Новый день, новый вызов
Отработав шесть с половиной лет в Google и написав десятки
проектных документов, отчётов с расследованиями событий и много
другого, я начал составлять документ для Google, описывая инцидент
и добавляя лазейки со стороны Google в отчёт. Команда Google
вернётся на работу через два дня.
Поправка: некоторые читатели предположили, что я использовал свои
внутренние контакты в Google. На самом деле я ни с кем не общался и
выбрал путь, по которому пошёл бы любой нормальный разработчик или
компания. Как и любой другой мелкий разработчик, я проводил
бесчисленные часы в чате, за консультациями, составлением длинных
электронных писем и сообщений об ошибках. В одной из следующих
статей, посвящённой составлению отчётов об инцидентах, я покажу
документы, которые отправил в Google.
 Последний день в Google
Последний день в Google
Кроме того, нужно было понять наши ошибки и разработать стратегию
развития продукта. Не все в команде знали об инциденте, но было
совершенно ясно, что у нас большие неприятности.
В Google я сталкивался с человеческими ошибками ценой в миллионы
долларов, но культура Google спасает сотрудников (за исключением
того, что инженерам приходится потом сочинять длинные отчёты). На
этот раз Гугла не было. На карту поставлен наш собственный
маленький капитал и наша тяжёлая работа.
Стойкие Гималаи нам говорят
Такой удар я получил первый раз. Это могло изменить будущее нашей
компании и мою жизнь. Этот инцидент преподал мне несколько уроков
бизнеса, в том числе самый важный держать удар.
В то время у меня работала команда из семи инженеров и стажёров, и
Google требовалось около десяти дней, чтобы ответить нам по поводу
этого инцидента. Тем временем мы должны были возобновить
разработку, найти способ обойти приостановку счетов. Несмотря на
всё, мы должны были сосредоточиться на функциях и нашем
продукте.
 Стихотворение Стойкие Гималаи нам говорят
Стихотворение Стойкие Гималаи нам говорят
Почему-то у меня в голове постоянно крутилось одно стихотворение из
детства. Это была моя любимая книга, и я помнил её слово в слово,
хотя в последний раз читал более 15-ти лет назад.
Что мы на самом деле сделали?
Будучи очень маленькой командой, мы хотели как можно дольше
воздержаться от расходов на аппаратное обеспечение. Проблема Cloud
Functions и Cloud Run заключалась в тайм-ауте.
Один инстанс будет постоянно скрапить URL-адреса со страницы. Но
через 9 минут наступит тайм-аут.
Тогда вскользь обсудив проблему, я за пару минут набросал на доске
сырой код. Теперь понял, что у того кода была масса архитектурных
недостатков, но тогда мы стремились к быстрым циклам исправления
ошибок, чтобы стремительно учиться и пробовать новые вещи.
 Концепт Announce-AI на Cloud Run
Концепт Announce-AI на Cloud Run
Чтобы преодолеть ограничение тайм-аута, я предложил использовать
POST-запросы (с URL в качестве данных) для отправки заданий в
инстанс и запускать параллельно несколько инстансов, а не
составлять очередь для одного. Поскольку каждый инстанс в Cloud Run
скрапит только одну страницу, тайм-аут никогда не наступит, все
страницы будут обрабатываться параллельно (хорошее
масштабирование), а процесс высоко оптимизирован, поскольку
использование Cloud Run происходит с точностью до миллисекунд.
 Скрапер на Cloud Run
Скрапер на Cloud Run
Если присмотреться, в процессе не хватает нескольких важных
деталей.
- Происходит непрерывная экспоненциальная рекурсия: инстансы не
знают, когда остановить работу, потому что оператора break не
предусмотрено.
- У POST-запросов могут быть одни и те же URL. Если есть обратная
ссылка на предыдущую страницу, то сервис Cloud Run застрянет в
бесконечной рекурсии, но хуже всего то, что эта рекурсия умножается
экспоненциально (максимальное количество инстансов было установлено
на 1000!)
Как вы можете себе представить, это привело к ситуации, в которой
1000 инстансов делают запросы и записи в Firebase DB каждые
несколько миллисекунд. Мы увидели, что по операциям чтения Firebase
в какой-то момент проходило около 1 миллиарда запросов в
минуту!
 Сводка транзакций на конец месяца для GCP
Сводка транзакций на конец месяца для GCP
116 миллиардов операций чтения и 33 миллиона записей
Экспериментальная версия нашего приложения на Cloud Run сделала 116
миллиардов операций чтения и 33 миллиона записей в Firestore.
Ох!
Стоимость операций чтения на Firebase:
$ (0.06 / 100,000) * 116,000,000,000 = $ 69,600
16 000 часов работы Cloud Run
После тестирования из остановки логов мы сделали вывод, что запрос
умер, но на самом деле он ушёл в фоновый процесс. Поскольку мы не
удалили сервисы (мы первый раз использовали Cloud Run, и тогда
действительно не понимали этого), то несколько сервисов продолжали
медленно работать.
За 24 часа все эти службы на 1000 инстансах отработали в общей
сложности 16022 часа.
Все наши ошибки
Деплой ошибочного алгоритма в облаке
Уже обсуждалось выше. Мы действительно обнаружили новый способ
использования бессерверного использования POST-запросов, который я
не нашёл нигде в интернете, но задеплоили его без уточнения
алгоритма.
Деплой Cloud Run с параметрами по умолчанию
При создании службы Cloud Run мы выбрали в ней значения по
умолчанию. Максимальное число инстансов 1000, а параллелизм 80
запросов. Мы не знали, что эти значения на самом деле наихудший
сценарий для тестовой программы.
Если бы мы выбрали max-instances=2, затраты были бы в 500 раз
меньше.
Если бы установили concurrency=1, то даже не заметили бы счёт.
Использование Firebase без полного понимания
Кое-что понимаешь только на опыте. Firebase это не язык, который
можно выучить, это контейнерная платформа. Её правила определены
конкретной компанией Google.

Кроме того, при написании кода на Node.js нужно подумать о фоновых
процессах. Если код уходит в фоновые процессы, разработчику нелегко
узнать, что служба работает. Как мы позже узнали, это ещё и стало
причиной большинства таймаутов наших Cloud Functions.
Быстрые ошибки и быстрые исправления плохая идея в облаке
Облако в целом похоже на обоюдоострый меч. При правильном
использовании он может быть очень полезен, но при неправильном
пеняй на себя.
Если посчитать количество страниц в документации GCP, то можно
издать несколько толстенных томов. Чтобы всё понять, в том числе
тарификацию и использование функций, требуется много времени и
глубокое понимание, как работают облачные сервисы. Неудивительно,
что для этого нанимают отдельных сотрудников на полный рабочий
день!
Firebase и Cloud Run действительно мощны
На пике Firebase обрабатывает около миллиарда считываний в минуту.
Это исключительно мощный инструмент. Мы играли с Firebase уже
два-три месяца и всё ещё открывали новые аспекты, но до того
момента я понятия не имел, насколько мощная это система.
То же самое относится и к Cloud Run! Если установить количество
параллельных процессов 60, max_containers== 1000, то при запросах
по 400мс Cloud Run может обрабатывать 9 миллионов запросов в
минуту!
60 * 1000 * 2.5 * 60 = 9 000 000 запросов в минуту
Для сравнения, поиск Google обрабатывает 3,8 миллиона запросов в
минуту.
Используйте мониторинг
Хотя
Google Cloud Monitoring не остановит биллинг, он
отправляет своевременные оповещения (задержка 3-4 минуты). Поначалу
не так просто освоить терминологию Google Cloud, но если вы
потратите время, то панель мониторинга, оповещения и метрики
немного облегчат вашу жизнь.
Эти метрики доступны только в течение 90 дней, у нас они уже не
сохранились.
Мы выжили
 Фух, пронесло
Фух, пронесло
Изучив наш длинный отчёт об инциденте, описывающий ситуацию с нашей
стороны, после различных консультаций, бесед и внутренних
обсуждений, Google простила нам счёт!
Спасибо тебе, Google!
Мы схватили спасательный круг и использовали эту возможность, чтобы
завершить разработку продукта. На этот раз с гораздо лучшим
планированием, архитектурой и намного более безопасной
реализацией.
Google, моя любимая технологическая компания, это не
просто отличная компания для работы. Это также отличная компания
для сотрудничества. Инструменты Google очень удобны для
разработчиков, имеют отличную документацию (по большей части) и
постоянно расширяются.
(Примечание: это моё личное мнение как индивидуального
разработчика. Наша компания никоим образом не спонсируется и не
связана с Google).
Что дальше?
После этого случая мы потратили несколько месяцев на изучение
облака и нашей архитектуры. За несколько недель моё понимание
улучшилось настолько, что я мог прикинуть стоимость скрапинга всего
интернета с помощью Cloud Run с улучшенным алгоритмом.
Инцидент заставил меня глубоко проанализировать архитектуру нашего
продукта, и мы отказались от той, что была в первой версии, чтобы
построить масштабируемую инфраструктуру.
Во второй версии Announce мы не просто создали MVP, мы создали
платформу, на которой могли быстрыми итерациями разрабатывать новые
продукты и тщательно тестировать их в безопасной среде.
Это путешествие заняло немало времени
Announce
запущен в конце ноября, примерно через семь месяцев после первой
версии, но он очень масштабируемый, берёт лучшее из облачных
сервисов и высоко оптимизирован.
Мы также запустились на всех платформах, а не только в
интернете.
Более того, мы повторно использовали платформу для создания нашего
второго продукта
Point Address. Он тоже отличается масштабируемостью
и хорошей архитектурой.























 Конфигурации ВМ A2 доступные в сервисе Compute
Engine
Конфигурации ВМ A2 доступные в сервисе Compute
Engine
 Новая ВМ A2-MegaGPU: 16 графических
процессоров A100 со скоростью передачи данных 9,6 ТБ/с по
интерфейсу NVIDIA NVLink
Новая ВМ A2-MegaGPU: 16 графических
процессоров A100 со скоростью передачи данных 9,6 ТБ/с по
интерфейсу NVIDIA NVLink

























 Изначально архитектура Web Portal в нашем
проекте выглядела так
Изначально архитектура Web Portal в нашем
проекте выглядела так
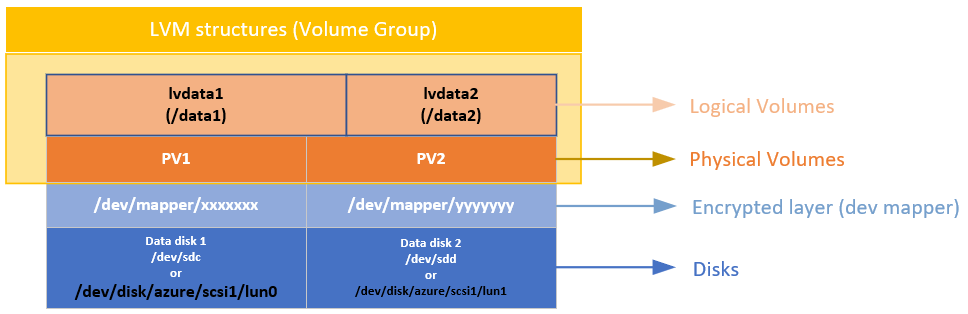
 Архитектура нашей системы после миграции в GCP
Архитектура нашей системы после миграции в GCP