
Что такое Workbox?
Workbox (далее WB) это библиотека
(точнее, набор библиотек), основной целью которой является
"предоставление лучших практик и избавление от шаблонного кода при
работе с сервис-воркерами" (далее СВ).
Если вы впервые слышите о СВ, то перед изучением данного
руководства настоятельно рекомендуется ознакомиться со следующими
материалами:
WB предоставляет следующие возможности:
- предварительное кэширование
- кэширование во время выполнения
- стратегии (кэширования)
- обработка (перехват сетевых) запросов
- фоновая синхронизация
- помощь в отладке
Это вторая часть руководства. Вот ссылка на первую часть.
Модули, предоставляемые
WB
Каждый модуль решает определенную задачу и может быть
использован как совместно с другими модулями, так и
самостоятельно.
workbox-background-sync: фоновая синхронизация,
позволяющая выполнять сетевые запросы в режиме офлайн-
workbox-broadcast-update: отправка уведомлений об
обновлении кэша (через
Broadcast Channel API)
workbox-cacheable-response: фильтрация кэшируемых
запросов на основе статус-кодов или заголовков ответов-
workbox-core: изменение уровня логгирования и
названий кэша. Содержит общий код, используемый другими
модулями
workbox-expiration: установка лимита записей в
кэше и времени жизни сохраненных ресурсов-
workbox-google-analytics: фиксация действий
пользователей на странице в режиме офлайн
-
workbox-navigation-preload: предварительная
загрузка запросов, связанных с навигацией
workbox-precaching: предварительное кэширование
ресурсов и управление их обновлением-
workbox-range-request: поддержка частичных
ответов
workbox-recipes: общие паттерны использования
WBworkbox-routing: обработка запросов с помощью
встроенных стратегий кэширования или колбэковworkbox-strategies: стратегии кэширования во время
выполнения, как правило, используемые совместно с
workbox-routing-
workbox-streams: формирование ответа на основе
нескольких источников потоковой передачи данных
workbox-window: регистрация, управление
обновлением и обработка событий жизненного цикла СВ
workbox-background-sync
Иногда запрос на отправку данных на сервер проваливается. Это
может произойти из-за потери соединения или из-за "упавшего"
сервера. В любом случае, было бы здорово иметь возможность
автоматически повторять выполнение такого запроса.
Новый
BackgroundSync API отличное решение для такой
ситуации. Когда СВ обнаруживает провалившийся запрос, он может
регистрировать возникновение события sync,
отправляемого брузером при восстановлении соединения. Данное
событие отправляется даже если пользователь вышел из приложения,
что делает этот подход гораздо более эффективным, чем традиционные
способы повторного выполнения провалившихся запросов.
Браузеры, поддерживающие BackgroundSync API,
автоматически отправляют повторный запрос от вашего имени через
интервал, определяемый браузером. В браузерах, которые не
поддерживают указанную технологию, рассматриваемый модуль отправит
повторный запрос при очередном запуске СВ.
Базовое использование
Простейший способ использования фоновой синхронизации
заключается в применении плагина, который автоматически помещает
провалившиеся запросы в очередь и выполняет их повторную отправку
при регистрации события sync:
import { BackgroundSyncPlugin } from 'workbox-background-sync'import { registerRoute } from 'workbox-routing'import { NetworkOnly } from 'workbox-strategies'const bgSyncPlugin = new BackgroundSyncPlugin('myQueueName', { maxRetentionTime: 24 * 60, // Попытка выполнения повторного запроса будет выполнена в течение 24 часов (в минутах)})registerRoute( /\/api\/.*\/*.json/, new NetworkOnly({ plugins: [bgSyncPlugin], }), 'POST')
Продвинутое использование
Рассматриваемый модуль предоставляет класс Queue,
который, после инстанцирования, может использоваться для хранения
провалившихся запросов. Такие запросы записываются в
IndexedDB и извлекаются из нее при восстановлении
соединения.
Создание очереди
import { Queue } from 'workbox-background-sync'const queue = new Queue('myQueueName') // название очереди должно быть уникальным
Название очереди используется как часть названия "тега", который
получает
register() глобального
SyncManager. Оно также используется как название
"объектного хранилища" IndexedDB.
Добавление запроса в очередь
import { Queue } from 'workbox-background-sync'const queue = new Queue('myQueueName')self.addEventListener('fetch', (event) => { // Клонируем запрос для безопасного чтения // при добавлении в очередь const promiseChain = fetch(event.request.clone()).catch((err) => { return queue.pushRequest({ request: event.request }) }) event.waitUntil(promiseChain)})
После добавления в очередь, запрос будет автоматически выполнен
повторно при получении СВ события sync (или при
следующем запуске СВ в браузерах, которые не поддерживают фоновую
синхронизацию).
workbox-cacheable-response
При кэшировании ресурсов во время выполнения не существует
общего правила для определения валидности таких ресурсов, т.е.
того, подлежат ли эти ресурсы сохранению с целью повторного
использования.
Рассматриваемый модуль позволяет определять пригодность ответа
для кэширования на основе статус-кода или присутствия заголовка с
определенным значением.
Кэширование на основе
статус-кода
import { registerRoute } from 'workbox-routing'import { CacheFirst } from 'workbox-strategies'import { CacheableResponsePlugin } from 'workbox-cacheable-response'registerRoute( ({ url }) => url.origin === 'https://example.com' && url.pathname.startsWith('/images/'), new CacheFirst({ cacheName: 'image-cache', plugins: [ new CacheableResponsePlugin({ statuses: [0, 200] }) ] }))
Данная настройка указывает WB кэшировать любые
ответы со статусом 0 или 200 при
обработке запросов к https://example.com.
Кэширование на основе
заголовка
import { registerRoute } from 'workbox-routing'import { StaleWhileRevalidate } from 'workbox-strategies'import { CacheableResponsePlugin } from 'workbox-cacheable-response'registerRoute( ({ url }) => url.pathname.startsWith('/path/to/api/'), new StaleWhileRevalidate({ cacheName: 'api-cache', plugins: [ new CacheableResponsePlugin({ headers: { 'X-Is-Cacheable': 'true' } }) ] }))
При обработке ответов на запросы к URL,
начинающемуся с /path/to/api/, проверяется,
присутствует ли в ответе заголовок X-Is-Cacheable
(который добавляется сервером). Если заголовок присутствует и имеет
значение true, такой ответ кэшируется.
При определении нескольких заголовков, для кэширования ответа
достаточно совпадения с одним из них.
Разумеется, указанные техники определения пригодности ответов
для кэширования можно комбинировать:
import { registerRoute } from 'workbox-routing'import { StaleWhileRevalidate } from 'workbox-strategies'import { CacheableResponsePlugin } from 'workbox-cacheable-response'registerRoute( ({ url }) => url.pathname.startsWith('/path/to/api/'), new StaleWhileRevalidate({ cacheName: 'api-cache', plugins: [ new CacheableResponsePlugin({ statuses: [200, 404], headers: { 'X-Is-Cacheable': 'true' } }) ] }))
При использовании встроенной стратегии без явного определения
cacheableResponse.CacheableResponsePlugin, для
проверки валидности ответа используются следющие критерии:
staleWhileRevalidate и networkFirst:
ответы со статусом 0 (непрозрачные ответы) и
200 считаются валиднымиcacheFirst: только ответы со статусом
200 считаются валидными
По умолчанию заголовки ответа для определения его валидности не
используются.
Продвинутое использование
Для определения логики кэширования за пределами стратегии можно
использовать класс CacheableResponse:
import { CacheableResponse } from 'workbox-cacheable-response'const cacheable = new CacheableResponse({ statuses: [0, 200], headers: { 'X-Is-Cacheable': 'true' }})const response = await fetch('/path/to/api')if (cacheable.isResponseCacheable(response)) { const cache = await caches.open('api-cache') cache.put(response.url, response)} else { // Ответ не может быть кэширован}
workbox-expiration
Данный плагин позволяет ограничивать количество ресурсов,
сохраняемых в кэше, а также время их хранения.
Ограничение
количества записей в кэше
import { registerRoute } from 'workbox-routing'import { CacheFirst } from 'workbox-strategies'import { ExpirationPlugin } from 'workbox-expiration'registerRoute( ({ request }) => request.destination === 'image', new CacheFirst({ cacheName: 'image-cache', plugins: [ new ExpirationPlugin({ // ограничиваем количество записей в кэше maxEntries: 20 }) ] }))
При достижении лимита удаляются самые старые записи.
Ограничение времени хранения ресурсов в кэше
import { registerRoute } from 'workbox-routing'import { CacheFirst } from 'workbox-strategies'import { ExpirationPlugin } from 'workbox-expiration'registerRoute( ({ request }) => request.destination === 'image', new CacheFirst({ cacheName: 'image-cache', plugins: [ new ExpirationPlugin({ // ограничиваем время хранения ресурсов в кэше maxAgeSeconds: 24 * 60 * 60 }) ] }))
Проверка записей на соответствие этому критерию и, при
необходимости, их удаление осуществляется после каждого запроса или
обновления кэша.
Продвинутое использование
Класс CacheExpiration позволяет отделять логику
ограничения от других модулей. Для установки ограничений создается
экземпляр названного класса:
import { CacheExpiration } from 'workbox-expiration'const cacheName = 'my-cache'const expirationManager = new CacheExpiration(cacheName, { maxAgeSeconds: 24 * 60 * 60, maxEntries: 20})
Затем, при обновлении записи в кэше, вызывается метод
updateTimestamp() для обновления "возраста"
записи.
await openCache.put(request, response)await expirationManager.updateTimestamp(request.url)
Для проверки всех записей в кэше на предмет их соответствия
установленным критериям вызывается метод
expireEntries():
await expirationManager.expireEntries()
workbox-precaching
СВ позволяет записывать файлы в кэш во время установки. Это
называется предварительным кэшированием, поскольку контент
кэшируется перед использованием СВ.
Предварительное кэширование позволяет приложению работать в
режиме офлайн без выполнения сетевых запросов на получение
ресурсов, используемых приложением.
WB предоставляет простой и понятный
API для реализации этого паттерна и эффективной
загрузки ресурсов.
При первом запуске приложения workbox-precaching
"смотрит" на загружаемые ресурсы, удаляет дубликаты и регистрирует
соответствующие события СВ для загрузки и хранения ресурсов.
URL, которые содержат информацию о версии (версионную
информацию) (например, хэш контента) используются в качестве ключей
кэша без дополнительной модификации. К ключам кэша
URL, которые не содержат такой информации, добавляется
параметр строки запроса, представляющий хэш контента, генерируемый
WB во время выполнения.
workbox-precaching делает все это при обработке
события install СВ.
При повторном посещении приложения пользователем, при наличии
нового СВ с другими предварительно кэшируемыми ресурсами
workbox-precaching оценивает новый список и
определяет, какие ресурсы являются новыми, а какие нуждаются в
обновлении на основе версионной информации. Добавление новых
ресурсов или обновление существующих выполняется при обработке
следующего события install.
Новый СВ не будет использоваться для ответов на запросы до его
активации. В событии activate
workbox-precaching определяет кэшированные ресурсы,
отсутствующие в новом списке URL, и удаляет их из
кэша.
Обработка
предварительно кэшированных ответов
Вызов precacheAndRoute() или
addRoute() создает маршрутизатор, который определяет
совпадения запросов с предварительно кэшированными
URL.
В этом маршрутизаторе используется стратегия "сначала кэш".
Порядок вызова названных методов имеет важное значение. Обычно,
они вызываются в начале файла с кодом СВ, перед регистрацией и
дополнительными маршрутизаторами, определяемыми с помощью
registerRoute(). Если вызвать сначала
registerRoute(), то любой маршрутизатор, совпавший с
входящим запросом, независимо от стратегии, определенной в этом
маршрутизаторе, будет использован для формирования ответа.
Список
предварительно кэшируемых ресурсов
workbox-precaching ожидает получения массива
объектов со свойствами url и revision.
Данный массив иногда называют "манифестом предварительного
кэширования":
import { precacheAndRoute } from 'workbox-precaching'precacheAndRoute([ { url: '/index.html', revision: '383676' }, { url: '/styles/app.0c9a31.css', revision: null }, { url: '/scripts/app.0d5770.js', revision: null }, // другие записи])
Свойства revision второго и третьего объектов имеют
значения null. Это объясняется тем, что версионная
информация этих объектов является частью значений их свойств
url.
В отличие от JavaScript и CSS
URL, указывающие на HTML-файлы, как
правило, не включают в себя версионную информацию по той причине,
что ссылки на такие файлы должны быть статическими.
Версионирование позволяет рассматриваемому модулю определять
необходимость обновления кэшированного ресурса.
Обратите внимание: для генерации списка предварительно
кэшируемых ресурсов следует использовать один из встроенных
инструментов WB: workbox-build,
workbox-webpack-plugin или workbox-cli.
Создавать такой список вручную очень плохая идея.
Автоматическая обработка входящих запросов
При поиске совпадения входящего запроса с кэшированным ресурсом
workbox-precaching автоматически выполняет некоторые
манипуляции с URL.
Например, запрос к / оценивается как запрос к
index.html.
Игнорирование параметров строки запроса
По умолчанию игнорируются параметры поиска, которые начинаются с
utm_ или точно совпадают с fbclid. Это
означает, что запрос к /about.html?utm_campaign=abcd
оценивается как запрос к /about.html.
Игнорируемые параметры указываются в настройке
ignoreURLParametersMatching:
import { precacheAndRoute } from 'workbox-precaching'precacheAndRoute( [ { url: '/index.html', revision: '383676' }, { url: '/styles/app.0c9a31.css', revision: null }, { url: '/scripts/app.0d5770.js', revision: null } ], { // Игнорируем все параметры ignoreURLParametersMatching: [/.*/] })
Основной файл директории
По умолчанию основным файлом директории считается
index.html. Именно поэтому запросы к /
оцениваются как запросы к /index.html. Это поведение
можно изменить с помощью настройки directoryIndex:
import { precacheAndRoute } from 'workbox-precaching'precacheAndRoute( [ { url: '/index.html', revision: '383676' }, { url: '/styles/app.0c9a31.css', revision: null }, { url: '/scripts/app.0d5770.js', revision: null }, ], { directoryIndex: null })
"Чистые" URL
По умолчанию к запросу добавляется расширение
.html. Например, запрос к /about
оценивается как /about.html. Это можно изменить с
помощью настройки cleanUrls:
import { precacheAndRoute } from 'workbox-precaching'precacheAndRoute([{ url: '/about.html', revision: 'b79cd4' }], { cleanUrls: false})
Кастомные манипуляции
Настройка urlManipulation позволяет кастомизировать
логику определения совпадений. Эта функция должна возвращать массив
возможных совпадений:
import { precacheAndRoute } from 'workbox-precaching'precacheAndRoute( [ { url: '/index.html', revision: '383676' }, { url: '/styles/app.0c9a31.css', revision: null }, { url: '/scripts/app.0d5770.js', revision: null } ], { urlManipulation: ({ url }) => { // Логика определения совпадений return [alteredUrlOption1, alteredUrlOption2] } })
workbox-routing
СВ может перехватывать сетевые запросы. Он может отвечать
браузеру кэшированным контентом, контентом, полученным из сети, или
контентом, генерируемым СВ.
workbox-routing это модуль, позволяющий "связывать"
поступающие запросы с функциями, формирующими на них ответы.
При отправке сетевого запроса возникает событие
fetch, которое регистрирует СВ для формирования ответа
на основе маршрутизаторов и обработчиков.
Обратите внимание на следующее:
- важно указывать метод запроса. По умолчанию перехватываются
только
GET-запросы
- маршрутизаторы должны регистрироваться в правильном порядке.
При наличии нескольких "роутов" для одного запроса, сработает
только первый из них
Определение
совпадений и обработка запросов
В WB "роут" это две функции: функция "определения
совпадения" и функция "обработки запроса".
WB предоставляет некоторые утилиты для помощи в
реализации названных функций.
Функция определения совпадения принимает
ExtendableEvent, Request и объект
URL. Возврат истинного значения из этой функции
означает совпадение. Например, вот пример определения совпадения с
конкретным URL:
const matchCb = ({ url, request, event }) => { return (url.pathname === '/special/url')}
Функция обработки запроса принимает такие же параметры +
аргумент value, который имеет значение, возвращаемое
из первой функции:
const handlerCb = async ({ url, request, event, params }) => { const response = await fetch(request) const responseBody = await response.text() return new Response(`${responseBody} <!-- Глядите-ка! Новый контент. -->`, { headers: response.headers })}
Обработчик должен возвращать промис, разрешающийся
Response.
Регистрация колбэков выглядит следующим образом:
import { registerRoute } from 'workbox-routing'registerRoute(matchCb, handlerCb)
Единственным ограничением является то, что функция определения
совпадения должна возвращать истинное значение синхронно. Это
связано с тем, что Router должен синхронно
обрабатывать событие fetch или передавать его другим
обработчикам.
Как правило, в функции обработки запроса используется одна из
встроенных стратегий, например:
import { registerRoute } from 'workbox-routing'import { StaleWhileRevalidate } from 'workbox-strategies'registerRoute( matchCb, new StaleWhileRevalidate())
Определение совпадений с помощью регулярного выражения
Вместо функции определения совпадения, можно использовать
регулярное выражение:
import { registerRoute } from 'workbox-routing'registerRoute( new RegExp('/styles/.*\\.css'), handlerCb)
Для запросов из одного источника данная "регулярка" будет
регистрировать совпадения для следующих URL:
Однако, в случае с запросами к другим источникам, регулярка
должна совпадать с началом URL. Поэтому
совпадение для следующих URL обнаружено не будет:
Для решения этой проблемы можно использовать такое регулярное
выражение:
new RegExp('https://cdn\\.third-party-site\\.com.*/styles/.*\\.css')
Для регистрации совпадений как с локальными, так и со сторонними
URL можно использовать wildcard, но при
этом следует проявлять особую осторожность.
Роут для навигации
Если ваше приложение это одностраничник, для обработки всех
запросов, связанных с навигацией, можно использовать
NavigationRoute.
import { createHandlerBoundToURL } from 'workbox-precaching'import { NavigationRoute, registerRoute } from 'workbox-routing'// Предположим, что страница `/app-shell.html` была предварительно кэшированаconst handler = createHandlerBoundToURL('/app-shell.html')const navigationRoute = new NavigationRoute(handler)registerRoute(navigationRoute)
При посещении пользователем вашего сайта, запрос на получение
страницы будет считаться навигационным, следовательно, ответом на
него будет кэшированная страница /app-shell.html.
По умолчанию такой ответ будет формироваться для всех
навигационных запросов. Это поведение можно изменить с помощью
настроек allowList и denyList, определив
набор URL, которые должны обрабатываться этим
роутом.
import { createHandlerBoundToURL } from 'workbox-precaching'import { NavigationRoute, registerRoute } from 'workbox-routing'const handler = createHandlerBoundToURL('/app-shell.html')const navigationRoute = new NavigationRoute(handler, { allowlist: [ new RegExp('/blog/') ], denylist: [ new RegExp('/blog/restricted/') ]})registerRoute(navigationRoute)
Обратите внимание, что denyList
имеет приоритет перед allowList.
Обработчик по умолчанию
import { setDefaultHandler } from 'workbox-routing'setDefaultHandler(({ url, event, params }) => { // ...})
Обработчик ошибок
import { setCatchHandler } from 'workbox-routing'setCatchHandler(({ url, event, params }) => { // ...})
Обработка
не-GET-запросов
import { registerRoute } from 'workbox-routing'registerRoute( matchCb, handlerCb, // определяем метод 'POST')registerRoute( new RegExp('/api/.*\\.json'), handlerCb, // определяем метод 'POST')
workbox-strategies
Стратегия кэширования это паттерн, определяющий порядок
формирования СВ ответа на запрос (после возникновения события
fetch).
Вот какие стратегии предоставляет рассматриваемый модуль.
Stale-While-Revalidate
Данная стратегия возвращает ответ из кэша (при наличии ответа в
кэше) или из сети (при отсутствии кэшированного ответа). Сетевой
запрос используется для обновления кэша. Такой запрос выполняется
независимо от возраста кэшированного ответа.
import { registerRoute } from 'workbox-routing'import { StaleWhileRevalidate } from 'workbox-strategies'registerRoute( ({url}) => url.pathname.startsWith('/images/avatars/'), new StaleWhileRevalidate())
Cache-Fisrt
Данная стратегия отлично подходит для больших статических редко
изменяемых ресурсов.
При наличии ответа в кэше, он просто возвращается, а сеть не
используется совсем. Если ответа в кэше нет, выполняется сетевой
запрос, ответ на который возвращается пользователю и кэшируется для
следующего использования.
import { registerRoute } from 'workbox-routing'import { CacheFirst } from 'workbox-strategies'registerRoute( ({ request }) => request.destination === 'style', new CacheFirst())
Network-First
Данная стратегия подходит для часто обновляемых запросов.
Сначала выполняется сетевой запрос. Если запрос выполняется
успешно, ответ на него возвращается пользователю и записывается в
кэш. Если запрос проваливается, возвращается кэшированный
ответ.
import { registerRoute } from 'workbox-routing'import { NetworkFirst } from 'workbox-strategies'registerRoute( ({ url }) => url.pathname.startsWith('/social-timeline/'), new NetworkFirst())
Network-Only
import { registerRoute } from 'workbox-routing'import { NetworkOnly } from 'workbox-strategies'registerRoute( ({url}) => url.pathname.startsWith('/admin/'), new NetworkOnly())
Cache-Only
import { registerRoute } from 'workbox-routing'import { CacheOnly } from 'workbox-strategies'registerRoute( ({ url }) => url.pathname.startsWith('/app/v2/'), new CacheOnly())
Настройка стратегии
Каждая стратегия позволяет кастомизировать:
- название кэша
- лимит записей в кэше и время их "жизни"
- плагины
Название кэша
import { registerRoute } from 'workbox-routing'import { CacheFirst } from 'workbox-strategies'registerRoute( ({ request }) => request.destination === 'image', new CacheFirst({ cacheName: 'image-cache', }))
Плагины
В стратегии могут использоваться следующие плагины:
workbox-background-syncworkbox-broadcast-updateworkbox-cacheable-responseworkbox-expirationworkbox-range-requests
import { registerRoute } from 'workbox-routing'import { CacheFirst } from 'workbox-strategies'import { ExpirationPlugin } from 'workbox-expiration'registerRoute( ({ request }) => request.destination === 'image', new CacheFirst({ cacheName: 'image-cache', plugins: [ new ExpirationPlugin({ // Хранить ресурсы в течение недели maxAgeSeconds: 7 * 24 * 60 * 60, // Хранить до 10 ресурсов maxEntries: 10 }) ] }))
WB также позволяет создавать и использовать
собственные стратегии.
workbox-recipies
Некоторые паттерны, особенно касающиеся маршрутизации и
кэширования, являются достаточно общими для возможности их
стандартизации в виде переиспользуемых рецептов.
workbox-recipies предоставляет набор таких
рецептов.
Рецепты
Каждый рецепт это комбинация определенных модулей
WB. Ниже приводятся рецепты и паттерны, которые они
используют под капотом, на случай, если вы захотите кастомизировать
тот или иной рецепт.
Резервный контент
Данный рецепт позволяет СВ возвращать резервную страницу,
изображение или шрифт при возникновении ошибки при выполнении
запроса на получения любого из указанных ресурсов.
По умолчанию резервная страница должна иметь название
offline.html.
Резервный контент возвращается при совпадении с определенным
запросом. При использовании рассматриваемого рецепта в отдельности,
необходимо реализовать соответствующие роуты. Простейшим способом
это сделать является использование метода
setDefaultHandler() для создания роута, применяющего
стратегию "только сеть" в отношении всех запросов.
Рецепт
import { offlineFallback } from 'workbox-recipes'import { setDefaultHandler } from 'workbox-routing'import { NetworkOnly } from 'workbox-strategies'setDefaultHandler( new NetworkOnly())offlineFallback()
Паттерн
import { setCatchHandler, setDefaultHandler } from 'workbox-routing'import { NetworkOnly } from 'workbox-strategies'const pageFallback = 'offline.html'const imageFallback = falseconst fontFallback = falsesetDefaultHandler( new NetworkOnly())self.addEventListener('install', event => { const files = [pageFallback] if (imageFallback) { files.push(imageFallback) } if (fontFallback) { files.push(fontFallback) } event.waitUntil(self.caches.open('workbox-offline-fallbacks').then(cache => cache.addAll(files)))})const handler = async (options) => { const dest = options.request.destination const cache = await self.caches.open('workbox-offline-fallbacks') if (dest === 'document') { return (await cache.match(pageFallback)) || Response.error() } if (dest === 'image' && imageFallback !== false) { return (await cache.match(imageFallback)) || Response.error() } if (dest === 'font' && fontFallback !== false) { return (await cache.match(fontFallback)) || Response.error() } return Response.error()}setCatchHandler(handler)
Подготовка кэша
Данный рецепт позволяет записывать определенные URL
в кэш во время установки СВ. Она может использоваться в качестве
альтернативы предварительного кэширования в случае, когда нам
заранее известен список URL для сохранения.
Рецепт
import { warmStrategyCache } from 'workbox-recipes'import { CacheFirst } from 'workbox-strategies'// Здесь может испоьзоваться любая стратегияconst strategy = new CacheFirst()const urls = [ '/offline.html']warmStrategyCache({urls, strategy})
Паттерн
import { CacheFirst } from 'workbox-strategies'// Здесь может использоваться любая стратегияconst strategy = new CacheFirst()const urls = [ '/offline.html',]self.addEventListener('install', event => { // `handleAll` возвращает два промиса, второй промис разрешается после добавления всех элементов в кэш const done = urls.map(path => strategy.handleAll({ event, request: new Request(path), })[1]) event.waitUntil(Promise.all(done))})
Кэширование страницы
Данный рецепт позволяет СВ отвечать на запрос на получение
HTML-страницы с помощью стратегии "сначала сеть". При
этом, СВ оптимизируется таким образом, что в случае отсутствия
подключения к сети, возвращает ответ из кэша менее чем за 4
секунды. По умолчанию запрос к сети выполняется в течение 3 секунд.
Настройка warmCache позволяет подготовить
("разогреть") кэш к использованию.
Рецепт
import { pageCache } from 'workbox-recipes'pageCache()
Паттерн
import { registerRoute } from 'workbox-routing'import { NetworkFirst } from 'workbox-strategies'import { CacheableResponsePlugin } from 'workbox-cacheable-response'const cacheName = 'pages'const matchCallback = ({ request }) => request.mode === 'navigate'const networkTimeoutSeconds = 3registerRoute( matchCallback, new NetworkFirst({ networkTimeoutSeconds, cacheName, plugins: [ new CacheableResponsePlugin({ statuses: [0, 200] }) ] }))
Кэширование статических
ресурсов
Данный рецепт позволяет СВ отвечать на запросы на получение
статических ресурсов, таких как JavaScript,
CSS и веб-воркеры с помощью стратегии "считается
устаревшим после запроса" (ответ возвращается из кэша, после чего
кэш обновляется). Поддерживается разогрев кэша
(warmCache).
Рецепт
import { staticResourceCache } from 'workbox-recipes'staticResourceCache()
Паттерн
import { registerRoute } from 'workbox-routing'import { StaleWhileRevalidate } from 'workbox-strategies'import { CacheableResponsePlugin } from 'workbox-cacheable-response'const cacheName = 'static-resources'const matchCallback = ({ request }) => // CSS request.destination === 'style' || // JavaScript request.destination === 'script' || // веб-воркеры request.destination === 'worker'registerRoute( matchCallback, new StaleWhileRevalidate({ cacheName, plugins: [ new CacheableResponsePlugin({ statuses: [0, 200] }) ] }))
Кэширование изображений
Данный рецепт позволяет СВ отвечать на запросы на получение
изображений с помощью стратегии "сначала кэш". По умолчанию
кэшируется до 60 изображений в течение 30 дней. Поддерживается
разогрев кэша.
Рецепт
import { imageCache } from 'workbox-recipes'imageCache()
Паттерн
import { registerRoute } from 'workbox-routing'import { CacheFirst } from 'workbox-strategies'import { CacheableResponsePlugin } from 'workbox-cacheable-response'import { ExpirationPlugin } from 'workbox-expiration'const cacheName = 'images'const matchCallback = ({ request }) => request.destination === 'image'const maxAgeSeconds = 30 * 24 * 60 * 60const maxEntries = 60registerRoute( matchCallback, new CacheFirst({ cacheName, plugins: [ new CacheableResponsePlugin({ statuses: [0, 200] }), new ExpirationPlugin({ maxEntries, maxAgeSeconds }) ] }))
Кэширование гугл-шрифтов
Данный рецепт кэширует таблицу стилей для шрифтов с помощью
стратегии "считается устаревшим после запроса" и сами шрифты с
помощью стратегии "сначала кэш". По умолчанию кэшируется до 30
шрифтов в течение 1 года.
Рецепт
import { googleFontsCache } from 'workbox-recipes'googleFontsCache()
Паттерн
import { registerRoute } from 'workbox-routing'import { StaleWhileRevalidate } from 'workbox-strategies'import { CacheFirst } from 'workbox-strategies'import { CacheableResponsePlugin } from 'workbox-cacheable-response'import { ExpirationPlugin } from 'workbox-expiration'const sheetCacheName = 'google-fonts-stylesheets'const fontCacheName = 'google-fonts-webfonts'const maxAgeSeconds = 60 * 60 * 24 * 365const maxEntries = 30registerRoute( ({ url }) => url.origin === 'https://fonts.googleapis.com', new StaleWhileRevalidate({ cacheName: sheetCacheName }))// Кэшируем до 30 шрифтов с помощью стратегии "сначала кэш" и храним кэш в течение 1 годаregisterRoute( ({ url }) => url.origin === 'https://fonts.gstatic.com', new CacheFirst({ cacheName: fontCacheName, plugins: [ new CacheableResponsePlugin({ statuses: [0, 200], }), new ExpirationPlugin({ maxAgeSeconds, maxEntries }) ] }))
Быстрое использование
Комбинация рассмотренных рецептов позволяет создать СВ, который
будет отвечать на навигационные запросы с помощью стратегии
"сначала сеть", на запросы на получение статических ресурсов с
помощью стратегии "считается устаревшим после запроса", на
получение изображений с помощью стратегии "сначала кэш". Он также
будет обрабатывать гугл-шрифты и предоставлять резервный контент в
случае возникновения ошибки. Вот как это выглядит:
import { pageCache, imageCache, staticResourceCache, googleFontsCache, offlineFallback} from 'workbox-recipes'pageCache()googleFontsCache()staticResourceCache()imageCache()offlineFallback()
workbox-window
Данный модуль выполняется в контексте window. Его
основными задачами является следующее:
- упрощение процесса регистрации и обновления СВ в наиболее
подходящие для этого моменты жизненного цикла СВ
- помощь в обнаружении наиболее распространенных ошибок,
совершаемых разработчиками при работе с СВ
- облегчение коммуникации между кодом СВ и кодом, запускаемым в
window
Использование CDN
<script type="module">import { Workbox } from 'https://storage.googleapis.com/workbox-cdn/releases/6.1.5/workbox-window.prod.mjs'if ('serviceWorker' in navigator) { const wb = new Workbox('/sw.js') wb.register()}</script>
Использование сборщика
модулей
Установка
yarn add workbox-window# илиnpm i workbox-window
Использование
import { Workbox } from 'workbox-window'if ('serviceWorker' in navigator) { const wb = new Workbox('/sw.js') wb.register()}
Примеры
Регистрация СВ и уведомление пользователя о его
активации
const wb = new Workbox('/sw.js')wb.addEventListener('activated', (event) => { // `event.isUpdate` будет иметь значение `true`, если другая версия СВ // управляет страницей при регистрации данной версии if (!event.isUpdate) { console.log('СВ был активирован в первый раз!') // Если СВ настроен для предварительного кэширования ресурсов, // эти ресурсы могут быть получены здесь }})// Региструем СВ после добавления обработчиков событийwb.register()
Уведомление пользователя о том, что СВ был установлен,
но ожидает активации
Когда на странице, управляемой СВ, региструется новый СВ, по
умолчанию последний не будет активирован до тех пор, пока все
клиенты, контрлируемые первым, не завершат свои сессии.
const wb = new Workbox('/sw.js')wb.addEventListener('waiting', (event) => { console.log( `Новый СВ был установлен, но он не может быть активирован, пока все вкладки браузера не будут закрыты или перезагружены` )})wb.register()
Уведомление пользователя об обновлении кэша
Модуль workbox-broadcast-update позволяет
информировать пользователей об обновлении контента. Для получения
этой информации в браузере используется событие
message с типом CACHE_UPDATED:
const wb = new Workbox('/sw.js')wb.addEventListener('message', (event) => { if (event.data.type === 'CACHE_UPDATED') { const { updatedURL } = event.data.payload console.log(`Доступна новая версия ${updatedURL}!`) }})wb.register()
Отправка СВ списка URL для кэширования
В некоторых приложениях имеет смысл кэшировать только те
ресурсы, которые используются посещенной пользователем страницей.
Модуль workbox-routing принимает список
URL и кэширует их на основе правил, определенных в
маршрутизаторе.
В приведенном ниже примере при каждой активации нового СВ в
роутер отправляется список URL для кэширования.
Обратите внимание, что мы можем отправлять все
URL, поскольку будут кэшированы только те из них,
которые совпадут с роутами.
const wb = new Workbox('/sw.js')wb.addEventListener('activated', (event) => { // Получаем `URL` текущей страницы + все загружаемые страницей ресурсы const urlsToCache = [ location.href, ...performance .getEntriesByType('resource') .map((r) => r.name) ] // Передаем этот список СВ wb.messageSW({ type: 'CACHE_URLS', payload: { urlsToCache } })})wb.register()
Практика
В этом разделе представлено несколько сниппетов, которые можно
использовать в приложениях "как есть", а также краткий обзор
готовых решений для разработки PWA, предоставляемых
такими фреймворками для фронтенда, как React и
Vue.
Для обеспечения работы приложения в режиме офлайн требуется не
только СВ и его регистрация в основной файле приложения, но и так
называемый "манифест".
О том, что такое манифест можно почитать здесь,
здесь и здесь.
Как правило, манифест (и СВ) размещаются на верхнем уровне (в
корневой директории) проекта. Манифест может иметь расширение
.json или .webmanifest (лучше
использовать первый вариант).
Манифест
{ "name": "Название приложения", "short_name": "Краткое название (будет указано под иконкой приложения при его установке)", "scope": "/", // зона контроля СВ, разные страницы могут обслуживаться разными СВ "start_url": ".", // начальный URL, как правило, директория, в которой находится index.html, в котором регистрируется СВ "display": "standalone", "orientation": "portrait", "background_color": "#f0f0f0", "theme_color": "#3c3c3c", "description": "Описание приложения", // этих иконок должно быть достаточно для большинства девайсов "icons": [ { "src": "./icons/64x64.png", "sizes": "64x64", "type": "image/png" }, { "src": "./icons/128x128.png", "sizes": "128x128", "type": "image/png" }, { "src": "./icons/256x256.png", "sizes": "256x256", "type": "image/png", "purpose": "any maskable" }, { "src": "./icons/512x512.png", "sizes": "512x512", "type": "image/png" } ], "serviceworker": { "src": "./service-worker.js" // ссылка на файл с кодом СВ }}
Ручная реализация СВ, использующего стратегию "сначала
кэш"
// Название кэша// используется для обновления кэша// в данном случае, для этого достаточно изменить версию кэша - my-cache-v2const CACHE_NAME = 'my-cache-v1'// Критические для работы приложения ресурсыconst ASSETS_TO_CACHE = [ './index.html', './offline.html', './style.css', './script.js']// Предварительное кэширование ресурсов, выполняемое во время установки СВself.addEventListener('install', (e) => { e.waitUntil( caches .open(CACHE_NAME) .then((cache) => cache.addAll(ASSETS_TO_CACHE)) ) self.skipWaiting()})// Удаление старого кэша во время активации нового СВself.addEventListener('activate', (e) => { e.waitUntil( caches .keys() .then((keys) => Promise.all( keys.map((key) => { if (key !== CACHE_NAME) { return caches.delete(key) } }) ) ) ) self.clients.claim()})// Обработка сетевых запросов/* 1. Выполняется поиск совпадения 2. Если в кэше имеется ответ, он возвращается 3. Если ответа в кэше нет, выполняется сетевой запрос 4. Ответ на сетевой запрос кэшируется и возвращается 5. В кэш записываются только ответы на `GET-запросы` 6. При возникновении ошибки возвращается резервная страница*/self.addEventListener('fetch', (e) => { e.respondWith( caches .match(e.request) .then((response) => response || fetch(e.request) .then((response) => caches.open(CACHE_NAME) .then((cache) => { if (e.request.method === 'GET') { cache.put(e.request, response.clone()) } return response }) ) ) .catch(() => caches.match('./offline.html')) )})
Конфигурация Webpack
Пример настройки вебпака для производственной сборки
прогрессивного веб-приложения.
Предположим, что в нашем проекте имеется 4 директории:
public директория со статическими ресурсами,
включая index.html, manifest.json и
sw-reg.jssrc директория с кодом приложенияbuild директория для сборкиconfig директория с настройками, включая
.env, paths.js и
webpack.config.js
В файле public/sw-reg.js содержится код регистрации
СВ:
if ('serviceWorker' in navigator) { window.addEventListener('load', () => { navigator.serviceWorker .register('./service-worker.js') .then((reg) => { console.log('СВ зарегистрирован: ', reg) }) .catch((err) => { console.error('Регистрация СВ провалилась: ', err) }) })}
В файле config/paths.js осуществляется экспорт
путей к директориям с файлами приложения:
const path = require('path')module.exports = { public: path.resolve(__dirname, '../public'), src: path.resolve(__dirname, '../src'), build: path.resolve(__dirname, '../build')}
Допустим, что в качестве фронтенд-фреймворка мы используем
React, а также, что в проекте используется
TypeScript. Тогда файл webpack.config.js
будет выглядеть следующим образом:
const webpack = require('webpack')// импортируем пути к директориям с файлами приложенияconst paths = require('../paths')// плагин для копирования статических ресурсов в директорию сборкиconst CopyWebpackPlugin = require('copy-webpack-plugin')// плагин для обработки `index.html` - вставки ссылок на стили и скрипты, добавления метаданных и т.д.const HtmlWebpackPlugin = require('html-webpack-plugin')// плагин для обеспечения прямого доступа к переменным среды окруженияconst Dotenv = require('dotenv-webpack')// плагин для минификации и удаления неиспользуемого CSSconst MiniCssExtractPlugin = require('mini-css-extract-plugin')// плагин для сжатия изображенийconst ImageminPlugin = require('imagemin-webpack-plugin').default// плагин для добавления блоков кодаconst AddAssetHtmlPlugin = require('add-asset-html-webpack-plugin')// Плагин для генерации СВconst { GenerateSW } = require('workbox-webpack-plugin')// настройки Babelconst babelLoader = { loader: 'babel-loader', options: { presets: ['@babel/preset-env', '@babel/preset-react'], plugins: [ '@babel/plugin-proposal-class-properties', '@babel/plugin-syntax-dynamic-import', '@babel/plugin-transform-runtime' ] }}module.exports = { // режим сборки mode: 'production', // входная точка entry: { index: { import: `${paths.src}/index.js`, dependOn: ['react', 'helpers'] }, react: ['react', 'react-dom'], helpers: ['immer', 'nanoid'] }, // отключаем логгирование devtool: false, // результат сборки output: { // директория сборки path: paths.build, // название файла filename: 'js/[name].[contenthash].bundle.js', publicPath: './', // очистка директории при каждой сборке clean: true, crossOriginLoading: 'anonymous', module: true }, resolve: { alias: { '@': `${paths.src}/components` }, extensions: ['.mjs', '.js', '.jsx', '.ts', '.tsx', '.json'] }, experiments: { topLevelAwait: true, outputModule: true }, module: { rules: [ // JavaScript, React { test: /\.m?jsx?$/i, exclude: /node_modules/, use: babelLoader }, // TypeScript { test: /.tsx?$/i, exclude: /node_modules/, use: [babelLoader, 'ts-loader'] }, // CSS, SASS { test: /\.(c|sa|sc)ss$/i, use: [ 'style-loader', { loader: 'css-loader', options: { importLoaders: 1 } }, 'sass-loader' ] }, // статические ресурсы - изображения и шрифты { test: /\.(jpe?g|png|gif|svg|eot|ttf|woff2?)$/i, type: 'asset' }, { test: /\.(c|sa|sc)ss$/i, use: [ MiniCssExtractPlugin.loader, { loader: 'css-loader', options: { importLoaders: 1 } }, 'sass-loader' ] } ] }, plugins: [ new CopyWebpackPlugin({ patterns: [ { from: `${paths.public}/assets` } ] }), new HtmlWebpackPlugin({ template: `${paths.public}/index.html` }), // это позволяет импортировать реакт только один раз new webpack.ProvidePlugin({ React: 'react' }), new Dotenv({ path: './config/.env' }), new MiniCssExtractPlugin({ filename: 'css/[name].[contenthash].css', chunkFilename: '[id].css' }), new ImageminPlugin({ test: /\.(jpe?g|png|gif|svg)$/i }), // Добавляем код регистрации СВ в `index.html` new AddAssetHtmlPlugin({ filepath: `${paths.public}/sw-reg.js` }), // Генерируем СВ new GenerateSW({ clientsClaim: true, skipWaiting: true }) ], optimization: { runtimeChunk: 'single' }, performance: { hints: 'warning', maxEntrypointSize: 512000, maxAssetSize: 512000 }}
Здесь вы найдете шпаргалку по настройке вебпака. Пример полной
конфигурации вебпака для JS/React/TS-проекта можно
посмотреть здесь.
React PWA
Для того, чтобы получить готовый шаблон
React-приложения с возможностями PWA,
достаточно выполнить команду:
yarn create react-app my-app --template pwa# илиnpx create-react-app ...
Или, если речь идет о TypeScript-проекте:
yarn create react-app my-app --template pwa-typescript# илиnpx create-react-app ...
Кроме прочего, в директории src создаются файлы
service-worker.ts и
serviceWorkerRegister.ts (последний импортируется в
index.tsx), а в директории public файл
manifest.json.
Затем, перед сборкой проекта с помощью команды yarn
build или npm run build, в файл
src/index.tsx необходимо внести одно изменение:
// доserviceWorkerRegistration.unregister();// послеserviceWorkerRegistration.register();
Подробнее об этом можно прочитать
здесь.
Vue PWA
С Vue дела обстоят еще проще.
Глобально устанавливаем vue-cli:
yarn global add @vue/cli# илиnpm i -g @vue/cli
Затем, при создании шаблона проекта с помощью команды vue
create my-app, выбираем Manually select
features и Progressive Web App (PWA)
Support.
Кроме прочего, в директории src создается файл
registerServiceWorker.ts, который импортируется в
main.ts. Данный файл содержит ссылку на файл
service-worker.js, который, как и
manifest.json, автоматически создается при сборке
проекта с помощью команды yarn build или npm run
build. Разумеется, содержимое обоих файлов можно
кастомизировать.







 Рис.1.
WebRTC Agent Diagram
Рис.1.
WebRTC Agent Diagram


 Иллюстрация работы API Gateway
Иллюстрация работы API Gateway
 Скриншот с множеством ошибок Cancelled by client
Скриншот с множеством ошибок Cancelled by client
 График response time обращения к сервису
аутентификации
График response time обращения к сервису
аутентификации
 Попытка поиска котировки Sberbank of
Russia на сайте https://www.google.com/finance/quote/MCX:SBER
Попытка поиска котировки Sberbank of
Russia на сайте https://www.google.com/finance/quote/MCX:SBER
 Моя таблица с примером получения данных
с Московской биржи
Моя таблица с примером получения данных
с Московской биржи
 Как изменить региональные настройки и
параметры расчетов
Как изменить региональные настройки и
параметры расчетов Гугл таблица с примерами автоматического
получения имени для разных классов активов
Гугл таблица с примерами автоматического
получения имени для разных классов активов
 Гугл таблица с примерами автоматического
получения цен акций и облигаций
Гугл таблица с примерами автоматического
получения цен акций и облигаций
 Гугл таблица с примерами автоматического
получения дат и значений дивидендов для акций
Гугл таблица с примерами автоматического
получения дат и значений дивидендов для акций
 Гугл таблица с примерами автоматического
получения дат купонов и значений для облигаций
Гугл таблица с примерами автоматического
получения дат купонов и значений для облигаций
 Гугл таблица с примерами автоматического
получения дат оферт для облигаций
Гугл таблица с примерами автоматического
получения дат оферт для облигаций
 Экран включения/отключения расширенного
логирования
Экран включения/отключения расширенного
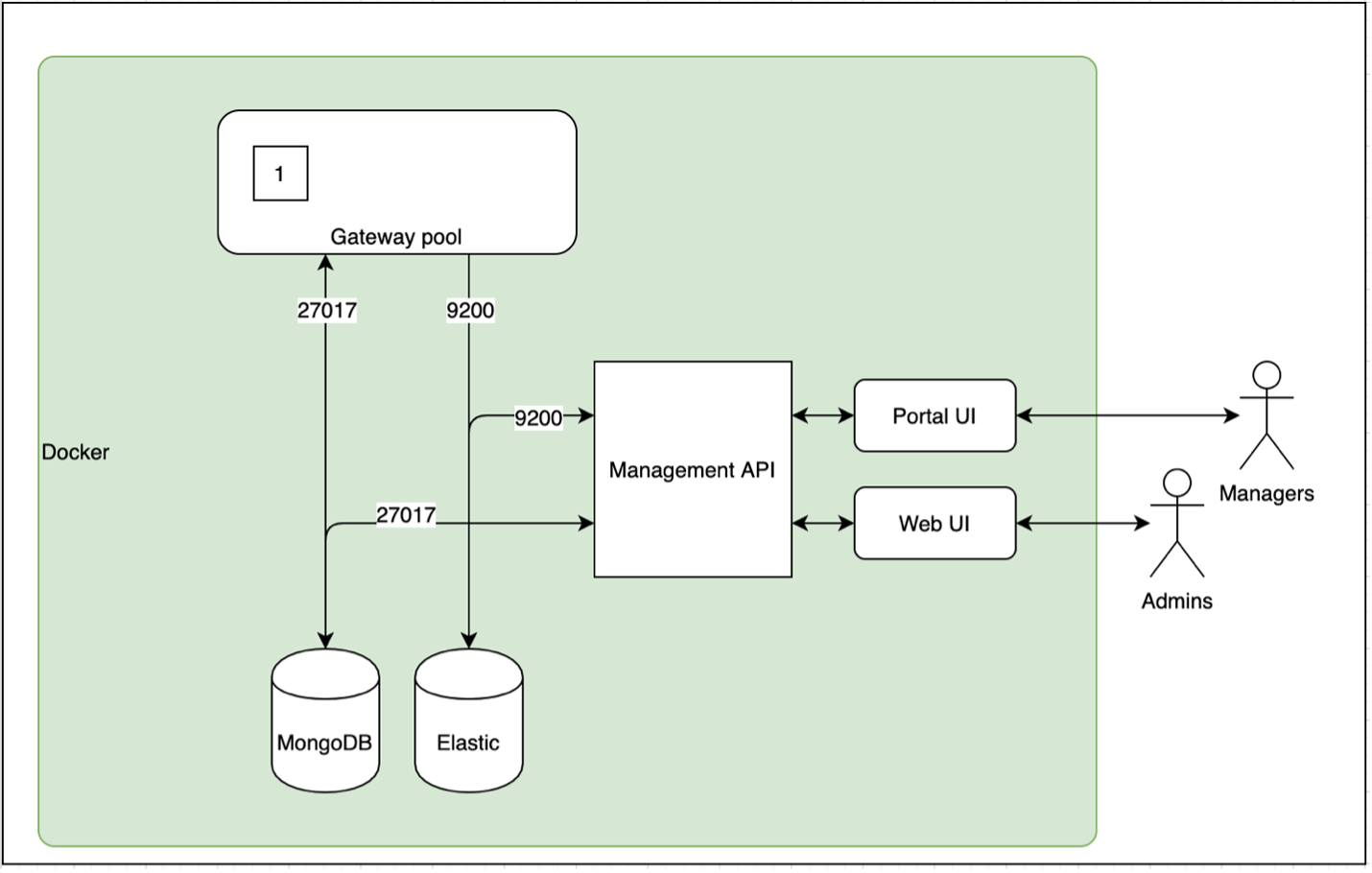
логирования Схема взаимодействия модулей Gravitee
Схема взаимодействия модулей Gravitee
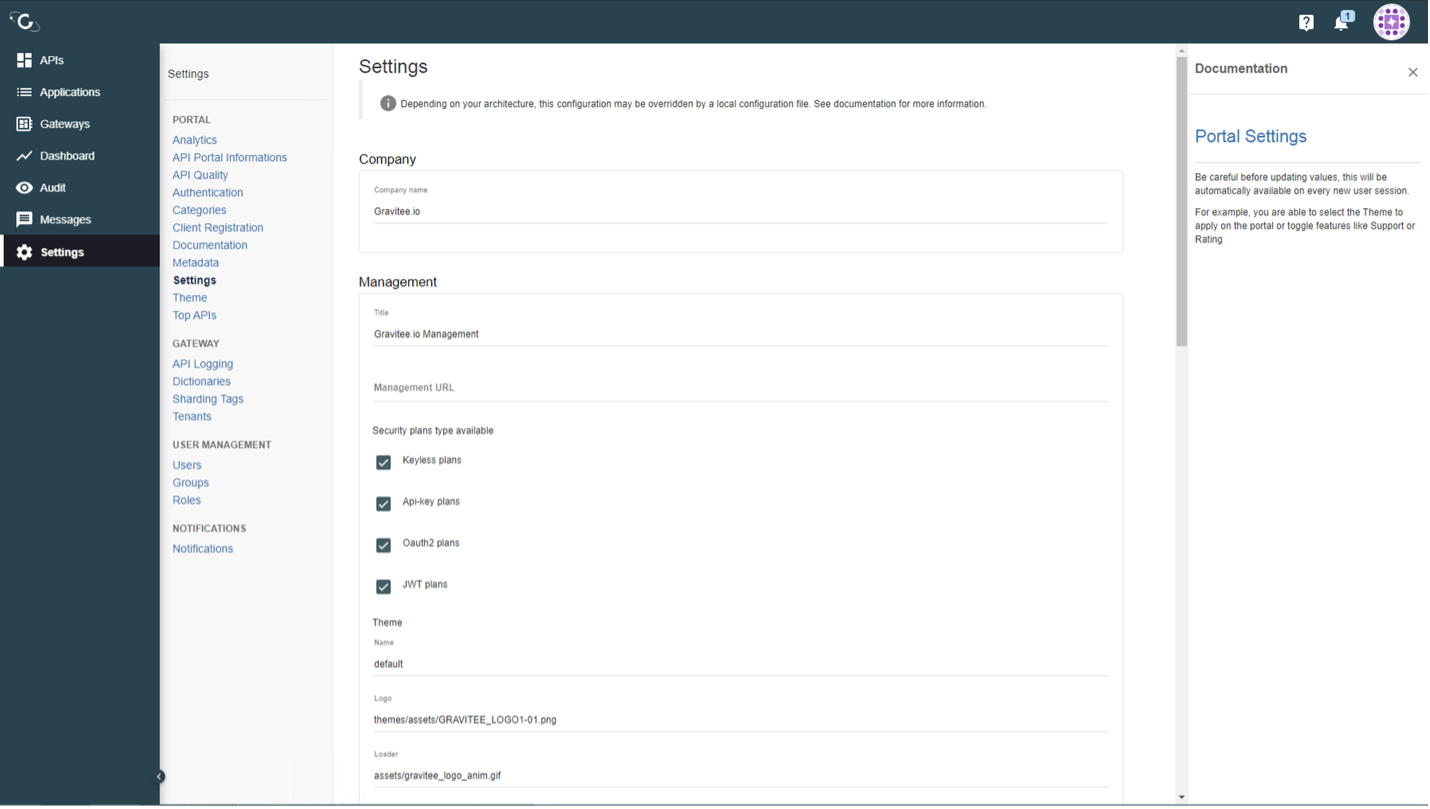
 Раздел Metadata в Gravitee
Раздел Metadata в Gravitee
 Вариант отображения Metadata в Grafana
Вариант отображения Metadata в Grafana
 Вариант
комплексного экрана
Вариант
комплексного экрана
 График распределения запросов по шлюзам
График распределения запросов по шлюзам





























 Батрак предупреждает о том что к гильдии
присоединился игрок
Батрак предупреждает о том что к гильдии
присоединился игрок
 Создание webhook
Создание webhook





















{kind=link}