

При проведении научных и прикладных исследование часто создаются модели, в которых рассматриваются точки и/или векторы определенных пространств. Например, в моделях шифров на эллиптических кривых используются аффинные и проективные пространства. К проективным прибегают тогда, когда необходимо ускорить вычисления, так как в формулах манипулирования с точками эллиптической кривой выводимых в рамках проективного пространства отсутствует операция деления на координату, которую в случае аффинного пространства обойти не удается.
Операция деления как раз одна из самых дорогих операций. Дело в том, что в алгебраических полях, а соответственно и в группах операция деления вообще отсутствует и выход из положения (когда не делить нельзя) состоит в том, что операцию деления заменяют умножением, но умножают не на саму координату, а на обращенное ее значение. Из этого следует, что предварительно надо привлекать расширенный алгоритм Евклида НОД и кое что еще. Одним словом, не все так просто как изображают авторы большинства публикаций о ЕСС. Почти все, что по этой теме опубликовано и не только в Интернете мне знакомо. Мало того, что авторы не компетентны и занимаются профанацией, оценщики этих публикаций плюсуют авторов в комментариях, т. е. не видят ни пробелов, ни явных ошибок. Про нормальную же статью пишут, что она уже 100500-я и от нее нулевой эффект. Так все пока на Хабре устроено, анализ публикаций делается огромный, но не качества содержания. Здесь возразить нечего реклама двигатель бизнеса.
Линейное векторное пространство
Изучение и описание явлений окружающего мира с необходимостью приводит нас к введению и использованию ряда понятий таких как точки, числа, пространства, прямые линии, плоскости, системы координат, векторы, множества и др.
Пусть r<3> = <r1, r2, r3> вектор трехмерного пространства, задает положение одной частицы (точки) относительно начала координат. Если рассматривать N элементов, то описание их положения требует задания 3N координат, которые можно рассматривать как координаты некоторого вектора в 3N-мерном пространстве. Если рассматривать непрерывные функции и их совокупности, то приходим к пространствам, размерность которых равна бесконечности. На практике часто ограничиваются использованием лишь подпространства такого бесконечномерного пространства функции координат, обладающего конечным числом измерений.
Пример 1. Ряд Фурье пример использования пространства функций. Рассмотрим разложение произвольной функции в ряд Фурье
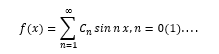
Его можно трактовать как разложение вектора f(x) по бесконечному набору ортогональных базисных векторов sinпх
Это пример абстрагирования и распространения понятия вектора на бесконечное число измерений. Действительно, известно, что при -x

Существо дальнейшего рассмотрения не пострадает, если мы отвлечемся от размерности абстрактного векторного пространства будь то 3, 3N или бесконечность, хотя для практических приложений больший интерес представляет конечномерные поля и векторные пространства.
Набор векторов r1, r2, будем называть линейным векторным пространством L, если сумма любых двух его элементов тоже находится в этом наборе и если результат умножения элемента на число С также входит в этот набор. Оговоримся сразу, что значения числа С могут быть выбраны из вполне определенного числового множества Fр поля вычетов по модулю простого числа р, которое считается присоединенным к L.
Пример 2. Набор из 8 векторов, составленных из n =5 -разрядных двоичных чисел
r0 = 00000, r1 = 10101, r2 = 01111, r3 = 11010, r4 = 00101, r5 = 10110, r6 = 01001, r7 = 11100 образует векторное пространство L, если числа С {0,1}. Этот небольшой пример позволяет убедиться в проявлении свойств векторного пространства, включенных в его определение.
Суммирование этих векторов выполняется поразрядно по модулю два, т. е. без переноса единиц в старший разряд. Отметим, что если все С действительные (в общем случае С принадлежат полю комплексных чисел), то векторное пространство называют действительным.
Формально аксиомы векторного пространства и записываются так:
r1 + r2 = r2 + r1 = r3; r1, r2, r3 L коммутативность сложения и замкнутость;
(r1 + r2) + r3 = r1 + (r2 + r3) = r1 + r2 + r3 ассоциативность сложения;
ri + r0 = r0 + ri = ri; i, ri, r0 Lсуществование нейтрального элемента;
ri +(- ri) = r0, для i существует противоположный вектор (-ri) L;
1 ri = ri 1 = ri существование единицы для умножения;
(ri) = ()ri; , , 1, 0 элементы числового поля F, ri L; умножение на скаляры ассоциативно; результат умножения принадлежит L;
( + ) ri = ri + ri; для i, ri L, , скаляры;
а (ri + rj) = ari + arj для всех а, ri, rj L;
a0 = 0, 0ri = 0; (-1) ri = ri.
Размерность и базис векторного пространства
При изучении векторных пространств представляет интерес выяснение таких вопросов, как число векторов, образующих все пространство; какова размерность пространства; какой наименьший набор векторов путем применения к нему операции суммирования и умножения на число позволяет сформировать все векторы пространства? Эти вопросы основополагающие и их нельзя обойти стороной, так как без ответов на них утрачивается ясность восприятия всего остального, что составляет теорию векторных пространств.
Оказалось, что размерность пространства самым тесным образом связана с линейной зависимостью векторов, и с числом линейно независимых векторов, которые можно выбирать в изучаемом пространстве многими способами.
Линейная независимость векторов
Набор векторов r1, r2, r3 rр из L называют линейно независимым, если для них соотношение
выполняется только при условии одновременного равенства $inline$с_1=с_2==с_р=0$inline$.
Все $inline$с_k$inline$, k = 1(1)p, принадлежат числовому полю вычетов по модулю два
F = {0, 1}.
Если в некотором векторном пространстве L можно подобрать набор из р векторов, для которых соотношение $inline$c_1 r_1+c_2 r_2+...+c_p r_p=0 $inline$ выполняется, при условии, что не все $inline$с_k = 0$inline$ одновременно, т.е. в поле вычетов оказалось возможным выбрать набор $inline$с_k$inline$, k =1(1)р, среди которых есть ненулевые, то такие векторы $inline$r_i$inline$ называются линейно зависимыми.
Пример 3. На плоскости два вектора $inline$е_1$inline$ = <0, 1>T и $inline$е_2$inline$ = <1, 0>T являются линейно независимыми, так как в соотношении (T-транспонирование)

невозможно подобрать никакой пары чисел $inline$с_1, с_2$inline$ коэффициентов не равных нулю одновременно, чтобы соотношение было выполнено.
Три вектора $inline$е_1$inline$ = <0, 1>T, $inline$е_2$inline$ = <1, 0>T, $inline$е_3$inline$ = <1, 1>T образуют систему линейно зависимых векторов, так как в соотношении
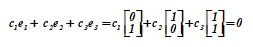
равенство может быть обеспечено выбором коэффициентов $inline$с_1 = с_2 = 1, с_3 = 1$inline$, не равных нулю одновременно. Более того, вектор $inline$ e_3 = е_1 + е_2 $inline$ является функцией $inline$ е_1$inline$ и $inline$ е_2 $inline$ (их суммой), что указывает на зависимость $inline$ e_3 $inline$ от $inline$е_1$inline$ и $inline$е_2 $inline$. Доказательство общего случая состоит в следующем.
Пусть хотя бы одно из значений $inline$с_k$inline$, k = 1(1)р, например, $inline$с_р 0$inline$, а соотношение выполнено. Это означает, что векторы $inline$r_k$inline$, k = 1(1)р, линейно зависимы
Выделим явным образом из суммы вектор rр

Говорят, что вектор rр является л и н е й н о й комбинацией векторов $inline$r_1, r_2 r_р-1$inline$ или rр через остальные векторы выражается линейным образом, т.е. rр линейно зависит от остальных. Он является их функцией.
На плоскости двух измерений любые три вектора линейно зависимы, но любые два неколлинеарных вектора являются независимыми. В трехмерном пространстве любые три некомпланарных вектора линейно независимы, но любые четыре вектора всегда линейно зависимы.
Зависимость/независимость совокупности {$inline${e_1, e_2, e_3, ..., e_n}$inline$} векторов часто определяют, вычисляя определитель матрицы Грама (ее строки скалярные произведения наших векторов). Если определитель равен нулю, среди векторов имеются зависимые, если определитель отличен от нуля векторы в матрице независимы.
Определителем Грама (грамианом) системы векторов
$$display$$ {\displaystyle \mathbf {e} _{1},\;\mathbf {e} _{2},\;\ldots ,\mathbf {e} _{n}}\mathbf{e}_1,\;\mathbf{e}_2,\;\ldots,\mathbf{e}_n$$display$$
в евклидовом пространстве называется определитель матрицы Грама этой системы:$$display$${\displaystyle {\begin{vmatrix}\langle e_{1},\;e_{1}\rangle &\langle e_{1},\;e_{2}\rangle &\ldots &\langle e_{1},\;e_{n}\rangle \\\langle e_{2},\;e_{1}\rangle &\langle e_{2},\;e_{2}\rangle &\ldots &\langle e_{2},\;e_{n}\rangle \\\ldots &\ldots &\ldots &\ldots \\\langle e_{n},\;e_{1}\rangle &\langle e_{n},\;e_{2}\rangle &\ldots &\langle e_{n},\;e_{n}\rangle \\\end{vmatrix}},}\begin{vmatrix} \langle e_1,\;e_1\rangle & \langle e_1,\;e_2\rangle & \ldots & \langle e_1,\;e_n\rangle \\ \langle e_2,\;e_1\rangle & \langle e_2,\;e_2\rangle & \ldots & \langle e_2,\;e_n\rangle \\ \ldots & \ldots & \ldots & \ldots \\ \langle e_n,\;e_1\rangle & \langle e_n,\;e_2\rangle & \ldots & \langle e_n,\;e_n\rangle \\ \end{vmatrix},$$display$$
где $inline${\displaystyle \langle e_{i},\;e_{j}\rangle }\langle e_i,\;e_j\rangle{\displaystyle \langle e_{i},\;e_{j}\rangle }\langle e_i,\;e_j\rangle$inline$ скалярное произведение векторов
$inline${\displaystyle \mathbf {e} _{i}}\mathbf{e}_i$inline$ и $inline${\displaystyle \mathbf {e} _{j}}\mathbf{e}_j$inline$.
Размерность и базис векторного пространства
Размерность s = d (L) пространства L определяется как наибольшее число векторов в L, образующих линейно независимый набор. Размерность это не число векторов в L, которое может быть бесконечным и не число компонентов вектора.
Пространства, имеющие конечную размерность s , называются конечномерными, если
s = , бесконечномерными.
Ответом на вопрос о минимальном числе и составе векторов, которые обеспечивают порождение всех векторов линейного векторного пространства является следующее утверждение.
Любой набор s линейно независимых векторов в пространстве L образует его б а з и с. Это следует из того, что любой вектор $inline$r_k$inline$ линейного s-мерного векторного пространства L может быть представлен единственным способом в виде линейной комбинации векторов базиса.
Зафиксируем и обозначим символом $inline$е_i $inline$, i = 1(1)s, один из наборов, образующих базис пространства L. Тогда

Числа rki, i = 1(1)s называются координатами вектора $inline$r_k $inline$ в базисе $inline$е_i $inline$, i = 1(1)s, причем rki = ($inline$е_i $inline$, $inline$r_k $inline$).
Покажем единственность представления $inline$r_k $inline$. Очевидно, что набор $inline$e_1,e_2,...,e_s$inline$, $inline$ r_k $inline$ является зависимым, так как $inline$е_i$inline$, i = 1(1)s базис. Другими словами, существуют такие $inline$с_1, с_2... с_s, c_k$inline$ не равные одновременно нулю, что $inline$ c_1e_1 + c_2e_2 + ...+ c_se_s + c_kr_k = 0$inline$.
При этом пусть $inline$c_k 0$inline$, ибо если $inline$ c_k = 0 $inline$, то хоть одно из $inline$с_1, с_2 , ... , с_s$inline$, было бы отлично от нуля и тогда векторы $inline$ e_i $inline$, i = 1(1)s, были бы линейно зависимы, что невозможно, так как это базис. Следовательно,
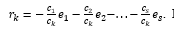


Используя прием доказательства от противного, допустим, что записанное представление $inline$r_k $inline$ не единственное в этом базисе и существует другое

Тогда запишем отличие представлений, что, естественно, выражается как

Очевидно, что правая и левая части равны, но левая представляет разность вектора с самим собой, т. е. равна нулю. Следовательно, и правая часть равна нулю. Векторы $inline$ е_i $inline$, i = 1(1)s линейно независимы, поэтому все коэффициенты при них могут быть только нулевыми. Отсюда получаем, что
 а это возможно только при
а это возможно только при
Выбор базиса. Ортонормированность
Векторы называют нормированными, если длина каждого из них равна единице. Этого можно достичь, применяя к произвольным векторам процедуру нормировки.
Векторы называют ортогональными, если они перпендикулярны друг другу. Такие векторы могут быть получены применением к каждому из них процедуры ортогонализации. Если для совокупности векторов выполняются оба свойства, то векторы называются ортонормированными.
Необходимость рассмотрения ортонормированных базисов вызвана потребностями использования быстрых преобразований как одно , так и многомерных функций. Задачи такой обработки возникают при исследовании кодов, кодирующих информационные сообщения в сетях связи различного назначения, при исследовании изображений, получаемых
посредством автоматических и автоматизированных устройств, в ряде других областей, использующих цифровые представления информации.
Определение. Совокупность n линейно независимых векторов n-мерного векторного
пространства V называется его базисом.
Теорема. Каждый вектор х линейного n-мерного векторного пространства V можно представить, притом единственным образом, в виде линейной комбинации векторов базиса. Векторное пространство V над полем F обладает следующими свойствами:
0х = 0 (0 в левой части равенства нейтральный элемент аддитивной группы поля F; 0 в правой части равенства элемент пространства V, являющийся нейтральным единичным элементом аддитивной группы V, называемый нулевым вектором);
( 1)х = х; 1 F; x V; x V;
Если х = 0V, то при х 0 всегда = 0.
Пусть Vn(F) множество всех последовательностей (х1, х2, , хn) длины n с компонентами из поля F, т.е. Vn(F) ={x, таких, что х = (х1, х2, , хn), хi F;
i =1(1)n }.
Сложение и умножение на скаляр определяются следующим образом:
x + y =(x1 + y1, x2 + y2, , xn + yn);
х = (х1, х2,, хn), где у = (у1, у2,, уn),
тогда Vn(F) является векторным пространством над полем F.
Пример 4. В векторном пространстве rо = 00000, r1 = 10101, r2 = 11010, r3 = 10101 над полем F2 = {0,1} определить его размерность и базис.
Решение. Сформируем таблицу сложения векторов линейного векторного пространства

В этом векторном пространстве V= {rо,r1,r2,r3} каждый вектор в качестве противоположного имеет самого себя. Любые два вектора, исключая rо, являются линейно независимыми, в чем легко убедиться
c1r1 + c2r2 = 0; c1r1 + c3r3 = 0; c2r2 + c3r3 = 0;

Каждое из трех соотношений справедливо только при одновременных нулевых значениях пар коэффициентов сi, сj {0,1}.
При одновременном рассмотрении трех ненулевых векторов один из них всегда является суммой двух других или равен самому себе, а r1+r2+r3=rо.
Таким образом, размерность рассматриваемого линейного векторного пространства равна двум s = 2, d(L) = s = 2, хотя каждый из векторов имеет пять компонентов. Базисом пространства является набор (r1, r2). Можно в качестве базиса использовать пару (r1, r3).
Важным в теоретическом и практическом отношении является вопрос описания векторного пространства. Оказывается, любое множество базисных векторов можно рассматривать как строки некоторой матрицы G, называемой порождающей матрицей векторного пространства. Любой вектор этого пространства может быть представлен как линейная комбинация строк матрицы G ( как, например, здесь).
Если размерность векторного пространства равна k и равна числу строк матрицы G, рангу матрицы G, то очевидно, существует k коэффициентов с q различными значениями для порождения всех возможных линейных комбинаций строк матрицы. При этом векторное пространство L содержит qk векторов.
Множество всех векторов из pn с операциями сложения векторов и умножения вектора на скаляр из p есть линейное векторное пространство.
Определение. Подмножество W векторного пространства V, удовлетворяющее условиям:
Если w1, w2 W, то w1+ w2 W,
Для любых F и w W элемент w W,
само является векторным пространством над полем F и называется подпространством векторного пространства V.
Пусть V есть векторное пространство над полем F и множество W V. Множество W есть подпространство пространства V, если W по отношению к линейным операциям, определенным в V, есть линейное векторное пространство.
Таблица. Характеристики векторных пространств

Компактность матричного представления векторного пространства очевидна. Например, задание L векторов двоичных 50-разрядных чисел, среди которых 30 векторов образуют базис векторного пространства, требует формирования матрицы G[30,50], а описываемое количество векторов превышает 109, что в поэлементной записи представляется неразумным.
Все базисы любого пространства L разбиваются подгруппой Р невырожденных матриц с det G > 0 на два класса. Один из них (произвольно) называют классом с положительно ориентированными базисами (правыми), другой класс содержит левые базисы.
В этом случае говорят, что в пространстве задана ориентация. После этого любой базис представляет собой упорядоченный набор векторов.
Если нумерацию двух векторов изменить в правом базисе, то базис станет левым. Это связано с тем, что в матрице G поменяются местами две строки, следовательно, определитель detG изменит знак.
Норма и скалярное произведение векторов
После того как решены вопросы о нахождении базиса линейного векторного пространства, о порождении всех элементов этого пространства и о представлении любого элемента и самого векторного пространства через базисные векторы, можно поставить задачу об измерении в этом пространстве расстояний между элементами, углов между векторами, значений компонентов векторов, длины самих векторов.
Действительное или комплексное векторное пространство L называется нормированным векторным пространством, если каждый вектор r в нем может быть сопоставлен действительному числу || r || модулю вектора, норме. Единичный вектор это вектор, норма которого равна единице. Нулевой вектор имеет компонентами нули.
Определение. Векторное пространство называется унитарным, если в нем определена бинарная операция, ставящая каждой паре ri, rj векторов из L в соответствие скаляр. В круглых скобках (ri, rj) записывается (обозначается) скалярное или внутреннее произведение ri и rj, причем
1. (ri, rj) = ri rj;
2. (ri, rj) = (ri rj)*, где * указывает на комплексное сопряжение или эрмитову симметрию;
3. (сri, rj) = с(ri rj) ассоциативный закон;
4. (ri + rj, rk) = (ri rk)+ (rj rk) дистрибутивный закон;
5. (ri, rk) 0 и из (ri, rj ) = 0 следует ri = 0.
Определение. Положительное значение квадратного корня
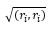 называют нормой (или длиной, модулем) вектора ri. Если
= 1, то вектор ri называют нормированным.
называют нормой (или длиной, модулем) вектора ri. Если
= 1, то вектор ri называют нормированным.Два вектора ri, rj унитарного векторного пространства L взаимно ортогональны, если их скалярное произведение равно нулю, т.е. (ri, rj) = 0.
При s = 3 в линейном векторном пространстве в качестве базиса удобно выбирать три взаимно перпендикулярных вектора. Такой выбор существенно упрощает ряд зависимостей и вычислений. Этот же принцип ортогональности используется при выборе базиса в пространствах и других размерностей s > 3. Использование введенной операции скалярного произведения векторов обеспечивает возможность такого выбора.
Еще большие преимущества достигаются при выборе в качестве базиса векторного пространства ортогональных нормированных векторов ортонормированного базиса. Если не оговорено специально, то далее всегда будем считать, что базис еi, i = 1(1)s выбран именно таким образом, т.е.
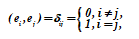
В унитарных векторных пространствах такой выбор всегда реализуем. Покажем реализуемость такого выбора.
Определение. Пусть S = {v1, v2,, vn} есть конечное подмножество векторного пространства V над полем F.
Линейная комбинация векторов из S есть выражение вида а1v1 + а2v2 ++ аnvn, где каждое аi F.
Оболочка для множества S (обозначение {S}) есть множество всех линейных комбинаций векторов из S. Оболочка для S есть подпространство пространства V.
Если U есть пространство в V, то U натянуто на S (S стягивает U), если {S}=U.
Множество векторов S линейно зависимо над F, если в F существуют скаляры а1, а2,, аn, не все нули, для которых а1v1+ а2v2 ++ аnvn = 0. Если таких скаляров не существует, то множество векторов S линейно независимо над F.
Если векторное пространство V натянуто на линейно независимую систему векторов S (или система S стягивает пространство V), то система S называется базисом для V.
Приведение произвольного базиса к ортонормированному
виду
Пусть в пространстве V имеется не ортонормированный базис i, i = 1(1)s. Обозначим норму каждого вектора базиса символом

В основу процедуры приведения базиса к ортонормированному виду положен процесс ортогонализации Грама Шмидта, который в свою очередь, реализуется рекуррентными формулами
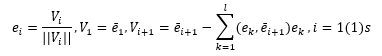
В развернутом виде алгоритм ортогонализации и нормирования базиса содержит следующие условия:
Делим вектор 1, на его норму; получим нормированный вектор i= 1/(|| 1 ||);
Формируем V2 = 2 ( 1, 2)e 1 и нормируем его, получим е 2. Ясно, что тогда
(е1, е2) ~ (е1, е2) (е1, 2)( е1, е1) = 0;
Построив V3 = 3 (e1, 3)e1 (e2, 3) e2 и нормируя его, получим е3.
Для него имеем сразу же (е1, е3) = (е2, е3) = 0.
Продолжая такой процесс, получим ортонормированный набор i, i = 1(1)s. Этот набор содержит линейно независимые векторы, поскольку все они взаимно ортогональны.
Убедимся в этом. Пусть выполняется соотношение

Если набор i, i = 1(1)s зависимый, то хотя бы один сj коэффициент не равен нулю сj 0.
Умножив обе части соотношения на еj, получаем
(ej, c1e1 ) + (ej, c2e2 )+ ...+ ( ej, cjej ) ++ ( ej, csrs ) = 0.
Каждое слагаемое в сумме равно нулю как скалярное произведение ортогональных векторов, кроме (ej ,cjej), которое равно нулю по условию. Но в этом слагаемом
(ej, ej) = 1 0, следовательно, нулем может быть только cj.
Таким образом, допущение о том, что cj 0 неверно и набор является линейно независимым.
Пример 5. Задан базис 3-х мерного векторного пространства:
{<-1, 2 ,3, 0>,<0, 1, 2, 1>,<2,-1,-1,1>}.
Скалярное произведение определено соотношением:
(<x1,x2,x3,x4>,<y1,y2,y3,y4>) = x1y1+x2y2+x3y3+x4y4.
Процедурой ортогонализации Грама Шмидта получаем систему векторов:
а1 = <-1, 2, 3, 0>; a2 = <0, 1, 2, 1>-4<-1, 2, 3,0>/7=<4,-1, 2, 7>/7;
a3 =<2, -1, -1, 1>+<-1, 2, 3, 0> <4, -1, 2, 7>/5 =<7, 2, 1, -4>/10.
(a1,a2)= (1+4+9+0) = 14;
a1 E =a1/14;
a2-(a1E,a2)a1E=a2-(8/14)(a1/14)=a2 4a1/7;
Третий вектор читателю предлагается обработать самостоятельно.
Нормированные векторы получают вид:
a1 E =a1/14;
a2 E =<4, -1, 2, 7>/70;
a3 E =<7, 2, 1,-4>/70;
Ниже в примере 6 дается подробный развернутый процесс вычислений получения ортонормированного базиса из простого (взятого наугад).
Пример 6. Привести заданный базис линейного векторного пространства к ортонормированному виду.
Дано: векторы базиса


Подпространства векторных пространств
Структура векторного пространства
Представление объектов (тел) в многомерных пространствах весьма непростая задача. Так, четырехмерный куб в качестве своих граней имеет обычные трехмерные кубы, и в трехмерном пространстве может быть построена развертка четырехмерного куба. В некоторой степени образность и наглядность объекта или его частей способствует более успешному его изучению.
Сказанное позволяет предположить, что векторные пространства можно некоторым образом расчленять, выделять в них части, называемые подпространствами. Очевидно, что рассмотрение многомерных и тем более бесконечномерных пространств и объектов в них лишает нас наглядности представлений, что весьма затрудняет исследование объектов в таких
пространствах. Даже, казалось бы, такие простые вопросы, как количественные характеристики элементов многогранников (число вершин, ребер, граней, и т. п.) в этих пространствах решены далеко не полностью.
Конструктивный путь изучения подобных объектов состоит в выделении их элементов (например, ребер, граней) и описании их в пространствах меньшей размерности. Так четырехмерный куб в качестве своих граней имеет обычные трехмерные кубы и в трехмерном пространстве может быть построена развертка четырехмерного куба. В некоторой степени
образность и наглядность объекта или его частей способствует более успешному их изучению.
Если L расширение поля К, то L можно рассматривать как векторное (или линейное) пространство над полем К. Элементы поля L (т. е. векторы) образуют по сложению абелеву группу. Кроме того, каждый вектор а L может быть умножен на скаляр r K, и при этом произведение ra снова принадлежит L (здесь ra просто произведение в смысле операции поля L элементов r и а этого поля). Выполняются также законы
r(a+b) = ra+rb, (r+s)a = ra + rs, (rs)a = r(sa) и 1а = а, где r,s K, a,b L.
Сказанное позволяет предположить, что векторные пространства можно некоторым образом расчленять, выделять в них части, называемые подпространствами. Очевидно, что основным результатом при таком подходе является сокращение размерности выделяемых подпространств. Пусть в векторном линейном пространстве L выделены подпространства L1 и L2. В качестве базиса L1 выбирается меньший набор еi, i = 1(1)s1, s1 < s, чем в исходном L.
Оставшиеся базисные векторы порождают другое подпространство L2, называемое ортогональным дополнением подпространства L1. Будем использовать запись L = L1 + L2. Она означает не то, что все векторы пространства L принадлежат либо L1, либо L2,, а то, что любой вектор из L можно представить в виде суммы вектора из L1 и ортогонального ему вектора из L2.
Разбивается не множество векторов векторного пространства L, а размерность d(L) и набор базисных векторов. Таким образом, подпространством L1 векторного пространства L называется множество L1, его элементов (меньшей размерности), само являющееся векторным пространством относительно введенных в L операций сложения и умножения на число.
Каждое линейное векторное подпространство Li содержит нулевой вектор и вместе с любыми своими векторами содержит и все их линейные комбинации. Размерность любого линейного подпространства не превосходит размерности самого исходного пространства.
Пример 7. В обычном трехмерном пространстве подпространствами являются все прямые (размерность s =1) линии, плоскости (размерность s = 2), проходящие через начало координат. В пространстве Рn многочленов степени не выше n подпространствами будут, например, все Рk при k < n, так как складывая и умножая на числа многочлены степени, не выше k, снова будут получаться такие же многочлены.
Однако, каждое из пространств Рп содержится в качестве подпространств в пространстве Р всех многочленов с вещественными коэффициентами, а это последнее является подпространством пространства С непрерывных функций.
Матрицы одинакового типа над полем действительных чисел также образуют линейное векторное пространство, так как для них выполняются все аксиомы векторных пространств. Векторное пространство L2 наборов длины n, каждый из которых ортогонален подпространству L1 наборов длины п, образует подпространство L2, называемое нулевым пространством для L1. Другими словами, каждый вектор из L2 ортогонален каждому вектору из L1 и наоборот.
Оба подпространства L1 и L2 являются подпространствами векторного пространства L наборов длины п. В теории кодирования [4] каждое из подпространств L1 и L2 порождает линейный код, двойственный по отношению к коду, порожденному другими подпространства-ми. Если L1 есть (п, k)-код, то L2 это (п, п k)-код. Если код является векторным пространством строк некоторой матрицы, то двойственный к нему код нулевое пространство этой матрицы и наоборот.
Важным вопросом при изучении векторных пространств Vn является установление их структуры (строения). Другими словами, интерес представляют элементы, их совокупности (подпространства размерности 1<k<п ), а также их отношения (упорядоченность, вложенность и т.п.). Будем считать заданным векторное пространство Vn над конечным полем GF(q), образованным q = р r элементами, где р простое число, r целое.
Известны следующие результаты.
Количества подпространств векторного пространства
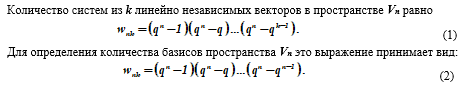
Приведем следующее обоснование. Каждый вектор v1 0 из системы k линейно независимых ( v1,v2,,vk ) векторов может быть выбран qn 1 способами. Следующий вектор v2 0 не может быть выражен линейно через v1, т.е. может быть выбран qn q способами и т.д.
Последний вектор vk 0 также линейно не выражается через предыдущие выбранные векторы v1,v2,,vk и, следовательно, может быть выбран qn qk 1 способами. Общее число способов для выбора совокупности векторов v1,v2,,vk, таким образом, определится как произведение числа выборов отдельных векторов, что и дает формулу (1). Для случая, когда k = п, имеем wп = wn, n и из формулы (I) получаем формулу (2).

Важные обобщающие результаты о размерностях подпространств.
Совокупность всех наборов длины n, ортогональных подпространству V1 наборов длины n, образует подпространство V2 наборов длины n. Это подпространство V2 называется нулевым пространством для V1.
Если вектор ортогонален каждому из векторов, порождающих подпространство V1, то этот вектор принадлежит нулевому пространству для V1.
Примером (V1) может служить множество 7-разрядных векторов порождающей матрицы (7,4)-кода Хемминга, с нулевым подпространством (V2) 7-разрядных векторов, образующих проверочную матрицу этого кода.
Если размерность подпространства (V1) наборов длины n равна k, то размерность нулевого подпространства (V2) равна n k.
Если V2 подпространство наборов длины n и V1 нулевое пространство для V2, то (V2) нулевое пространство для V1.
Пусть UV обозначает совокупность векторов, принадлежащих одновременно U и V, тогда UV является подпространством.
Пусть UV обозначает подпространство, состоящее из совокупности всех линейных комбинаций вида au +bv, где u U, v V, a b числа.
Сумма размерностей подпространств UV и UV равна сумме размерностей подпространств U и V.
Пусть U2 нулевое подпространство для U1, а V2 -нулевое пространство для V1. Тогда U2V2 является нулевым пространством для U1V1.
Заключение
В работе рассмотрены основные понятия векторных пространств, которые часто используются при построении моделей анализа систем шифрования, кодирования и стеганографических, процессов, протекающих в них. Так в новом американском стандарте шифрования использованы пространства аффинные, а в цифровых подписях на эллиптических кривых и аффинные и
проективные (для ускорения обработки точек кривой).
Об этих пространствах в работе речь не идет (нельзя валить все в одну кучу, да и объем публикации я ограничиваю), но упоминания об этом сделаны не зря. Авторы, пишущие о средствах защиты, об алгоритмах шифров наивно полагают, что понимают детали описываемых явлений, но понимание евклидовых пространств и их свойств без всяких оговорок переносится в другие пространства, с другими свойствами и законами. Читающая аудитория вводится в заблуждение относительно простоты и доступности материала.
Создается ложная картина действительности в области информационной безопасности и специальной техники (технологий и математики)
В общем почин мною сделан, насколько удачно судить читателям.
Литература
1. Авдошин С.М., Набебин А.А. Дискретная математика. Модулярная алгебра, криптография, кодирование. М.: ДМК Пресс, 2017. -352 с.
2. Акимов О.Е. Дискретная математика.Логика, группы, графы- М.: Лаб.Баз. Зн., 2001. -352 с.
3. Андерсон Д.А. Дискретная математика и комбинаторика.- М.: Вильямс, 2003. -960 с.
4. Берлекэмп Э. Алгебраическая теория кодирования. -М.: Мир,1971.- 478 с.
5. Ваулин А.Е. Дискретная математика в задачах компьютерной безопасности. Ч 1- СПб.: ВКА им. А.Ф. Можайского, 2015. -219 с.
6. Ваулин А.Е. Дискретная математика в задачах компьютерной безопасности. Ч 2- СПб.: ВКА им. А.Ф. Можайского, 2017. -151 с.
7. Горенстейн Д. Конечные простые группы. Введение в их классификацию.-М.: Мир,1985.- 352 с.
7. Грэхем Р., Кнут Д., Пташник О. Конкретная математика.Основание информатики.-М.: Мир,1998.-703 с.
9. Елизаров В.П. Конечные кольца.- М.: Гелиос АРВ,2006. 304 с.
Иванов Б.Н. Дискретная математика: алгоритмы и программы-М.: Лаб.Баз. Знаний., 2001. -280 с.
10. Ерусалимский Я.М. Дискретная математика: теория, задачи, приложения-М.: Вузовская книга, 2000.-280 с.
11. Корн Г., Корн Т. Справочник по математике для научных работников и инженеров.-М.: Наука, 1973.-832 с.
12. Лидл Р., Нидеррайтер Г. Конечные поля: В 2-х т. Т.1 -М.: Мир,1988. 430 с.
13. Лидл Р., Нидеррайтер Г. Конечные поля: В 2-х т. Т.2 -М.: Мир,1988. 392 с.
14. Ляпин Е.С., АйзенштатА.Я., Лесохин М.М., Упражнения по теории групп.- М.: Наука,1967.-264 с.
15. Муттер В.М. Основы помехоустойчивой телепередачи информации. -Л. Энергоатомиздат,1990.- 288 с.
16. Набебин А.А.Дискретная математика.- М.: Лаб.Баз. Знаний., 2001. -280 с.
17. Новиков Ф.А. Дискретная математика для программистов.- СПб.: Питер, 2000. -304 с.
18. Розенфельд Б.А. Многомерные пространства.-М.: Наука,1966.-648 с.
18. Холл М. Теория групп.-М.: Изд. ИЛ, 1962.- 468 с.
19. Шиханович Ю.А. Группы, кольца, решётки. СПб.: Кирцидели,2006. 368 с.
20. Шнеперман Л.Б. Курс алгебры и теории чисел в задачах и упражнениях: В 2-х ч Ч.2.-Мн.: Выш. шк., 1987. -256 с.
21. Шнеперман Л.Б. Сборник задач по алгебре и теории чисел.- Минск: Дизайн ПРО, 2000. -240 с.





![\begin{array}{ll} A\rightarrow [a] \rightarrow a, \\ \vec{b} \rightarrow (b) \rightarrow b, \\ \vec{x} \rightarrow x, \\ T(x) \rightarrow x' \end{array}](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/6db/081/881/6db081881bca3397f47a1bfc98fd5239.svg)
















.") Увеличение производительности
остановилось, что делает необходимым распараллеливать вычисления
различными способами, либо с помощью многоядерности, либо с помощью
векторизации, либо с помощью исполнения не в порядке очереди
(out-of-order).
Увеличение производительности
остановилось, что делает необходимым распараллеливать вычисления
различными способами, либо с помощью многоядерности, либо с помощью
векторизации, либо с помощью исполнения не в порядке очереди
(out-of-order).
 обрабатывает множество независимых потоков данных (синий цвет).") SIMD-инструкции, в отличие от
SISD-инструкций, каждая инструкция (зелёный цвет) обрабатывает
множество независимых потоков данных (синий цвет).
SIMD-инструкции, в отличие от
SISD-инструкций, каждая инструкция (зелёный цвет) обрабатывает
множество независимых потоков данных (синий цвет).
.") ARM floating point registers are
overlapping in the same register file (memory in CPU holding
registers).
ARM floating point registers are
overlapping in the same register file (memory in CPU holding
registers).
 Регистровый файл RISC-V может быть
скофигурирован так, чтобы иметь меньше 32 регистров. Может быть,
например, 8 регистров или 2 регистра большего размера. Регистры
могут занимать весь объём регистрового файла.
Регистровый файл RISC-V может быть
скофигурирован так, чтобы иметь меньше 32 регистров. Может быть,
например, 8 регистров или 2 регистра большего размера. Регистры
могут занимать весь объём регистрового файла.







 Печать не чувствительна к пространственно
ориентации. В середине находится читаемый двухмерный штриховой код
Печать не чувствительна к пространственно
ориентации. В середине находится читаемый двухмерный штриховой код



