
Связь СЛОВ через словарик
Оригинал текста Июнь 10,
2021 - 38 минут чтения
Программное обеспечение полно своих зависимостей, если смотреть
достаточно глубоко. Компиляторы, написанные на языке, на котором
они компилируются, - самый очевидный, но не единственный пример.
Чтобы скомпилировать ядро, нам нужно работающее ядро. Линкеры,
системы сборки, оболочки. Даже текстовые редакторы, если вы хотите
писать код, а не просто загружать его. Как разорвать этот
цикл?1 С
тех пор как проблема начальной загрузки
впервые привлекла мое внимание, я стал интересоваться этой
уникальной областью программной инженерии. Не из страха, что кто-то
попытается реализовать атаку на доверие, а просто как
интересный вызов.
11 лет назад vanjos72 описал на Reddit
то, что он называет мысленным экспериментом: что если бы вас
заперли в комнате с IBM PC, на котором нет операционной системы?
Какое минимальное количество программного обеспечения вам
понадобилось бы для начала, чтобы вернуться к комфортной
работе?
Так получилось, что в последнее время у меня появилось много
свободного времени, поэтому я решил сделать это больше, чем просто
мысленный эксперимент. Увы, мой компьютер не был оснащен
переключателями на передней панели, поэтому некоторые программы
должны уже присутствовать на компьютере ...
Самым минимальным вариантом может быть простая программа,
которая принимает ввод с клавиатуры, а затем переходит на нее.
Поскольку подпрограммы ввода с клавиатуры в BIOS реализуют
escape-коды alt+numpad, вам даже не нужно писать код преобразования
базы.2Более того, циклу даже не нужно
условие завершения а просто пишите в буфер обратно, пока не
столкнетесь с существующим кодом и не перезапишете точку перехода.
Такой подход занимает всего 14 байт:
6a00 push word 007 pop esfd stdbf1e7c mov di, buffer+16 ; Adjust to taste. Beware of fenceposting. input_loop:b400 mov ah, 0cd16 int 0x16aa stosbebf9 jmp short input_loop buffer:
Однако перспектива вводить код таким образом не кажется мне
привлекательной. Я решил, что, поскольку BIOS в любом случае
загружает целый сектор, любая загрузочная программа, которая
помещается в бутсектор, является честной игрой.3Очевидно, что хочется
максимизировать полезность выбранной программы. Какую самую мощную
вещь мы можем уместить в 510 байт?
Оскар Толедо написал много интересных программ размером с
сектор. Среди них много игр, таких как DooM-подобная игра или шахматный ИИ, а также
базовый интерпретатор BASIC, но самой,
пожалуй, актуальной для нашего случая является bootOS:
bootOS - это монолитная операционная система, которая помещается
в одном загрузочном секторе. Она способна загружать, выполнять и
сохранять программы. Также имеет файловую систему.
Она открывает свои подпрограммы файловой системы с помощью
интерфейса прерываний и включает встроенную команду, которая
позволяет создать файл, набрав его шестнадцатиричное представление.
Очень аккуратно, но, очевидно, в основном предназначена для
переключения между другими программами, имеющими размер
сектора.
Я бы искал решение, которое минимизирует набор текста в машинном
коде ручной сборки. В идеале это должен быть язык программирования,
но такой, который, в отличие от BASIC, может быть расширен во время
выполнения. Если вы прочитали заголовок этого поста, то уже знаете,
на чем я остановился. Оказалось, что в бутсекторе можно разместить
примитивный FORTH. Код можно посмотреть врепозитории Miniforth на GitHub,
но я приведу большую его часть здесь.
Весь FORTH занимает на данный момент 504 байта. Как и следовало
ожидать, процесс разработки включал в себя постоянный поиск
возможностей экономии байтов. Однако, когда я опубликовал, как мне
казалось, достаточно плотно оптимизированный код, появилсяИлья Курдюков и нашел 24 байта,
которые можно сэкономить! Я быстро реинвестировал это сэкономленное
место в новые возможности.
Вводная экскурсия в FORTH
Если вы когда-либо писали что-либо на FORTH, вы можете смело
пропустить этот раздел.
FORTH - это язык, основанный на стеках. Например, число
вталкивает свое значение в стек, а слово + выталкивает два числа и
их сумму. Обычная утилита отладки, но не включенная в Miniforth, -
это слово .s, которое печатает содержимое стека.
1 2 3 + .s <enter><2> 1 5 ok
Примечание: ok - готовность системы к приёму слов языка
Пользователь может определять свои собственные слова с помощью :
и ;. Например:
: double dup + ; <enter>ok 3 double . <enter>6 ок
Это определяет слово double, которое делает то же самое, что и
dup +. dup, кстати, является одним из слов FORTH для работы со
стеком. Оно дублирует верхний элемент в стеке:
42 dup .s <enter><2> 42 42 ok
Это практически весь язык. Есть некоторые стандартные средства
для условий и циклов, но нам пока не нужно ими заниматься, так как
они могут быть построены поверх Miniforth позже.
Чтобы описать влияние слова на состояние стека, мы используем
следующую нотацию:
dup ( a -- a a ) swap ( a b -- b a )
Список до символа -- - это входы , причем вершина стека
перечислена последней. После -- перечислены выходы, которые
начинаются с той же глубины стека. Это позволяет нам кратко описать
общие аспекты слова.
Шитый код
Хотя некоторые системы FORTH включают в себя полноценные
оптимизирующие компиляторы, подобные тем, которые можно увидеть в
обычном языке программирования, существует гораздо более простая
стратегия. В конце концов, все, что может сделать слово в FORTH,
это выполнить другие слова, так что последовательность инструкций
вызова очень близка к этому:
DOUBLE: call DUP call PLUS ret
Однако это связывает аппаратный стек x86 для стека возврата,
заставляя нас вручную обрабатывать отдельный стек для фактического
стека пользовательского уровня (известного как стек параметров).
Поскольку доступ к стеку параметров встречается гораздо чаще, мы
хотели бы использовать для этого инструкции push и pop, а вместо
них можно применить механизм, аналогичный call. Во-первых, давайте
просто сохраним список указателей на слова:
DOUBLE: dw DUP dw PLUS
Это реализуется следующим образом: каждое примитивное слово
извлекает из памяти адрес следующего слова и переходит к нему.
Указатель на эту последовательность указателей хранится в SI, так
что инструкция lodsw позволяет легко обрабатывать этот список:
DUP: pop ax push ax push ax lodsw jmp axPLUS: pop ax pop bx add ax, bx push ax lodsw jmp ax
Этот общий код можно абстрагировать в макрос, который
традиционно называется NEXT:
%macro NEXT 0 lodsw jmp ax%endmacro
Этот механизм, кстати, известен как потоковый код. Никакой связи
с примитивом параллелизма.
Однако что произойдет, если одно скомпилированное слово вызовет
другое? Здесь в дело вступает стек возвратов. Может показаться
естественным использовать регистр BP для указателя стека. Однако в
16-битных x86 не существует режима адресации [bp]. Самый близкий к
нему - [bp+imm8], что означает, что при обращении к памяти по
адресу bp тратится байт, чтобы указать, что вам не нужно смещение.
Вот почему я использую регистр di для стека возврата вместо этого.
В целом, этот выбор экономит 4 байта.
В любом случае, вот как стек возврата используется для обработки
компилированных слов, вызывающих друг друга. Проталкивание в стек
возврата особенно удобно, поскольку это просто инструкция
stosw.
DOUBLE: call DOCOL dw DUP dw PLUS dw EXITDOCOL: ; сокращение от "do colon word". xchg ax, si ; используется здесь как mov ax, si , ; но меняет местами. ; ax - только один байт, а mov - два байта. stosw pop si ; захватить указатель, вытолкнутый call . NEXTEXIT: dec di dec di mov si, [di] NEXT
Это практически та же стратегия выполнения, что и в Miniforth, с
одним простым, но существенным улучшением - значение на вершине
стека хранится в регистре BX. Это позволяет пропустить push и pop
во многих примитивах:
PLUS: pop ax add bx, ax NEXTDROP: pop bx NEXTDUP: push bx NEXT
Однако один случай все еще остается нерешенным. Что произойдет,
если слово содержит число, например : DOUBLE 2 \ ;? С этим
справляется LIT, который извлекает литерал, следующий за ним, из
потока указателей:
DOUBLE: call DOCOL dw LIT, 2 dw MULT dw EXITLIT: push bx lodsw xchg bx , ax NEXT
Словарь
FORTH нужен способ найти реализацию слов, которые набирает
пользователь. Это роль словаря. Я использую структуру, подобную
многим другим небольшим FORTH - односвязный список заголовков слов,
непосредственно предваряющий код каждого слова. По традиции, глава
списка хранится в переменной LATEST.
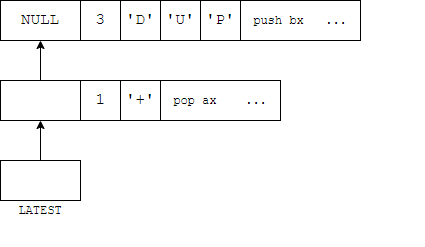
В старших битах поля длины имени также хранятся некоторые
флаги:
F_IMMEDIATE equ 0x80F_HIDDEN equ 0x40F_LENMASK equ 0x1f
Если слово помечено как IMMEDIATE, оно будет выполнено
немедленно, даже если в данный момент мы составляем определение.
Например, это используется для реализации ;. Если слово помечено
как HIDDEN, оно игнорируется при поиске по словарю. Помимо
использования в качестве элементарного механизма инкапсуляции, это
может быть использовано для реализации традиционной семантики
FORTH, когда определение слова может ссылаться на предыдущее слово
с тем же именем (а RECURSE используется, когда вам нужно
определение, которое компилируется в данный момент). Однако, ближе
к концу разработки я удалил код, который действительно делает это,
из стандартной реализации : и ;.
Компрессия
Обычно не стоит использовать сжатие, когда и расжатие , и его
полезная нагрузка должны уместиться всего в 512 байт. Однако в
реализации FORTH есть одна вещь, которая повторяется очень часто, -
это реализация NEXT.
ad lodswffe0 jmp ax
Мы можем попытаться сэкономить несколько байт, заменив их
переходами к общей копии. Однако короткий переход все равно
занимает два байта, что не является существенной экономией. Как
выясняется, специальная схема сжатия, которая может обрабатывать
только этот один повторяющийся паттерн, стоит того, если совместить
ее со следующим наблюдением: За NEXT почти всегда следует словарная
статья следующего примитива, поле ссылки которого предсказуемо.
Я выбрал схему сжатия, в которой каждый байт 0xff заменяется на
NEXT, за которым следует поле ссылки, которое вычисляется на основе
предыдущего появления байта 0xff. Эта стратегия сэкономила 19 байт,
когда я ее внедрил.4
Сначала я использовал для этого байт 0x90, в конце концов, это
опкод nop, который я точно не буду использовать. Однако этот байт
все еще может встречаться в непосредственном байте инструкции.
Сначала это не было проблемой, но когда код перемещался в памяти,
различные адреса и смещения становились 0x90 достаточно часто,
чтобы стать неприятностью. У 0xff, похоже, такой проблемы нет.
Чтобы создать ссылку, мы копируем значение LATEST на выход
декомпрессора и обновляем LATEST, чтобы оно указывало на слово,
которое мы только что написали. Это может быть сделано очень
компактной последовательностью инструкций, но все равно занимает
достаточно байт, чтобы стоило оформить это в виде подпрограммы. Она
также используется в реализации :, которая создает словарные статьи
во время выполнения.
; Создает ссылку словарного связного списка в DI.MakeLink: mov ax , di xchg [LATEST], ax ; AX теперь указывает на старую запись, ; а LATEST и DI указывают на новую. stosw ret
В декомпрессоре использовался интересный прием, когда вместо
короткого перехода вперед опкод размещается так, что
непосредственный аргумент, который он требует, съедает инструкцию,
через которую мы хотим перейти. То есть, вместо
jmp short .after.write: stosb.after:пишим3c db 0x3c ; пропустить stosb ниже, сравнив его опкод с AL .write:aa stosb
Таким образом, если какой-то другой код переходит к .write,
выполняется stosb, но этот кодовый путь просто выполняет cmp al,
0xaa. Сначала я не подумал об инструкции cmp al, и вместо нее
использовал mov в отбрасываемый регистр. Это привело кэффектному отказуиз-за моей
неспособности выбрать регистр, который можно безопасно
перезаписать.
Илья Курдюков затем продемонстрировал , что тот же самый байткоунт
может быть достигнут без подобной "магии". Аналогичная
модификация позволила мне устранить и другое проявление этого
трюка. Суть в том, что вместо того, чтобы пытаться пропустить
stosb, мы выполняем его безоговорочно перед ветвлением кодовых
путей, а затем, по сути, отменяем его с помощью dec di, если это
необходимо:
SPECIAL_BYTE equ 0xff mov si , CompressedData mov di , CompressedBegin mov cx , COMPRESSED_SIZE.decompress: lodsb stosb cmp al , SPECIAL_BYTE jnz short .not_special dec di mov ax , 0xffad ; lodsw / jmp ax stosw mov al , 0xe0 stosb call MakeLink.not_special: loop .decompress
На самом деле генерация сжатого потока более сложна. Поскольку я
хочу, чтобы переходы между сжатой и несжатой частями работали,
ассемблеру нужно верить, что он пишет код в том месте, где он будет
выполняться на самом деле. Сначала я попытался сделать это,
корректируя org после каждого SPECIAL_BYTE, но, к сожалению, yasm
это не понравилось.
boot.s:137: error: program origin redefined
Очевидно, что необходим отдельный этап постобработки. Я написал
макрос для подгонки байтов, которые будет вставлять
декомпрессор:
%macro compression_sentinel 0 db SPECIAL_BYTE dd 0xdeadbeef%endmacro
Это имеет дополнительное преимущество, предoставляя простой
автоматизированный способ проверки того, что никакие SPECIAL_BYTE
не проскочили случайно.
Мне все еще нужно было выделить место для сжатых данных. Я
выбрал следующую схему:
\1. Несжатый код начинается с 7C00 - инициализация, декомпрессия
и внешний интерпретатор.
\2. Сжатые данные немедленно следуют за ним, заполняя бутсектор
вплоть до момента перед 7E00.
\3. Сразу после этого выделяется буфер декомпрессии, в который
yasm выводит содержимое цели.
Чтобы добиться этого, мне нужно было точно знать, сколько места
нужно выделить для сжатых данных. Сначала я подсчитал точное
количество сэкономленных байт, увеличив счетчик в макросе
compression_sentinel:
%assign savings 0%macro compression_sentinel 0%assign savings savings+4 db SPECIAL_BYTE dd 0xdeadbeef%endmacro
Затем я просто вычитаю это значение из размера несжатого
сегмента:
CompressedData: times COMPRESSED_SIZE db 0xccCompressedBegin:; ...CompressedEnd:COMPRESSED_SIZE equ CompressedEnd - CompressedBegin - savings
Постобработка выполняется простым скриптом Python:
SPECIAL_BYTE = b'\xff'SENTINEL = SPECIAL_BYTE + b '\xef\xbe\xad\xde'with open('raw.bin', 'rb') as f: data = f.read()output_offset = data.index( b '\xcc' \ 20)chunks = data[output_offset:].lstrip( b '\xcc').split(SENTINEL)assert SPECIAL_BYTE not in chunks[0]compressed = bytearray (chunks[0])for chunk in chunks[1:]: assert SPECIAL_BYTE not in chunk compressed.extend(SPECIAL_BYTE) compressed.extend(chunk)\# Убедитесь, что для сжатых данных выделено именно то место, которое нужно.\# для сжатых данных.assert b '\xcc' \ len(compressed) in dataassert b '\xcc' \ (len(compressed) + 1) not in dataoutput = data[:output_offset] + compressedprint(len(output), 'bytes used')output += b '\x00' \ (510 - len(output))output += b '\x55\xaa'with open('boot.bin', 'wb') as f: f.write(output)
Этот же сценарий также генерирует расширенный образ диска,
который содержит некоторый код для тестирования в блоке 1:
output += b '\x00' \ 512output += open('test.fth', 'rb').read().replace( b '\n', b ' ')output += b ' ' \ (2048 - len(output))with open('test.img', 'wb') as f: f.write(output)
compression_sentinel чаще всего используется макросом defcode,
который создает словарную статью для примитивного слова. Он
принимает метку (которая затем может быть использована для перехода
к реализации некоторого слова), имя слова в виде строки и, по
желанию, некоторые флаги, которые должны быть включены в поле
длины:
; defcode PLUS, "+"; defcode SEMI, ";", F_IMMEDIATE%macro defcode 2-3 0 compression_sentinel%strlen namelength %2 db %3 | namelength, %2%1:%endmacro
Затем это используется для определения примитивов. Код, по сути,
переходит в defcode:
defcode PLUS, "+" pop ax add bx , ax defcode MINUS, "-" pop ax sub ax , bx xchg bx , ax defcode PEEK, "@" ; ...
Однако DOCOL, EXIT и LIT также используют механизм сжатия для
своих NEXT. Поскольку поле ссылки все еще записывается, это создает
фиктивные словарные статьи. К счастью, первый опкод EXIT и LIT
имеет установленный бит F_HIDDEN, так что это не проблема:
CompressedBegin:
DOCOL: xchg ax , si stosw pop si ; grab the pointer pushed by call compression_sentinelLIT: push bx lodsw xchg bx , ax compression_sentinelEXIT: dec di dec di mov si , [ di ]defcode PLUS, "+" ; ...
Переменные?
Инструкции немедленной загрузки имеют тенденцию иметь более
короткие кодировки, чем загрузки из памяти:
be3412 mov si , 0x12348b363412 mov si , [0x1234]
Именно поэтому Miniforth хранит большинство своих переменных в
непосредственных полях инструкций. Конечно, это означает, что адрес
этих переменных будет меняться при каждом редактировании кода, что
проблематично, поскольку мы захотим получить доступ к этим
переменным в коде FORTH. Типичный способ доступа к переменной - это
создание слова, которое передает ее адрес. Однако это слишком
дорого при наших ограничениях. То, на чем я остановился, это
заталкивание адресов в стек при запуске. Это можно сделать,
используя всего 2 байта для каждого адреса, просто определив
начальное содержимое стека как данные:
org 0x7c00 jmp 0:startstack: dw HERE dw BASE dw STATE dw LATESTstart: ; ... mov sp , stack
Даже когда адрес переменной должен быть помещен в стек, эта
самомодифицирующаяся стратегия кода экономит байты, если переменная
должна быть инициализирована. Лучший способ инициализировать
переменную - просто выделить ее в бутсекторе и поместить туда
начальное значение, что точно выравнивает данные стека и сохраняет
преимущество более короткой кодировки инструкций.
Код инициализации
Первое, что делается после загрузки, это настройкасегментных регистрови стека.
Флаг направления также очищается, чтобы строковые инструкции
работали в правильном направлении.
jmp 0:start ; ...start: push cs push cs push cs pop ds pop es pop ss mov sp , stack cld
В этом коде есть два примечательных момента. Во-первых,
сегментные регистры устанавливаются через стек. Это трюк экономии
байтов, который я перенял из bootBASIC он позволяет
инициализировать регистр общего назначения нулем:
31c0 xor ax , ax ; through AX - 8 bytes8ed8 mov ds , ax 8ec0 mov es , ax 8ed0 mov ss , ax 0e push cs ; through the stack - 6 bytes0e push cs 0e push cs 1f pop ds 07 pop es 17 pop ss
Во-вторых, можно подумать, что во время перенаправления стека
возникает небольшое окно состояния гонки и если прерывание
произошло между pop ss и mov sp, то может возникнуть хаос, если
предыдущее значение SP окажется в неудачном месте памяти. Конечно,
я мог бы просто скрестить пальцы и надеяться, что этого не
произойдет, если бы 2 байта, необходимые для обертывания этого в
пару cli/sti, были слишком большими. Однако оказалось, что этот
компромисс не нужен благодаря одному неясному уголку архитектуры
x86. Процитируем том 2B Руководства разработчика
программного обеспечения x86:
Загрузка регистра SS инструкцией POP5 подавляет или блокирует
некоторые отладочные исключения и блокирует прерывания на границе
следующей инструкции. (Запрет заканчивается после доставки
исключения или выполнения следующей инструкции). Такое поведение
позволяет загрузить указатель стека в регистр ESP со следующей
инструкцией (POP ESP)6 ,прежде чем может быть
доставлено событие.
После установки сегментов, стека и флага направления запускается
декомпрессор. Очень важно, что он не использует регистр DL, который
содержит номер диска BIOS, с которого мы загрузились. Затем он
пихается в реализацию load (которая находится в сжатом сегменте) и
заталкивается в стек для последующего использования
пользовательским кодом:
mov [DRIVE_NUMBER], dl push dx ; for FORTH code
Внешний интерпретатор
На этом этапе мы достигаем внешнего интерпретатора - части
системы FORTH, которая обрабатывает пользовательский ввод. Название
"внешний интерпретатор" отличает его от внутреннего интерпретатора,
который является компонентом, координирующим выполнение в пределах
определенного слова, и состоит из NEXT, DOCOL, EXIT и LIT.
Обычно FORTH представляет строительные блоки своего внешнего
интерпретатора в виде слов в словаре, таких как
В Miniforth этой практике вообще не уделяется никакого внимания.
Заголовки словарей стоят байты, как и общение только через стек.
Фактически, WORD и >NUMBER объединяются в одну процедуру,
которая выполняет работу обеих. Таким образом, цикл может быть
общим, что экономит байты.
Эта монолитная архитектура также позволяет нам решить, что BX и
DI не резервируются для вершины стека и указателя стека возврата,
соответственно, во время выполнения внешнего интерпретатора. Это
значительно помогает справиться с регистровым голоданием в этих
сравнительно сложных частях системы. Эти регистры устанавливаются
непосредственно перед переходом к слову и сохраняются после
возврата.
Ввод с клавиатуры
После завершения инициализации код переходит к ReadLine,
процедуре для чтения строки ввода с клавиатуры. Мы также вернемся
сюда позже, когда текущая строка ввода будет исчерпана. Буфер ввода
находится по адресу 0x500, сразу послеBDA. Хотя идиоматический
формат строк для FORTH использует отдельное поле длины, этот буфер
NULL-терминирован, так как это легче обрабатывать при разборе.
Указатель на неразобранный фрагмент ввода хранится в InputPtr,
которая является единственной переменной, не использующей технику
самомодификации, так как ее не нужно явно инициализировать и она
естественным образом записывается до чтения.
InputBuf equ 0x500 InputPtr equ 0xa02 ; dw
ReadLine: mov di , InputBuf mov [InputPtr], di .loop: mov ah , 0 int 0x16 cmp al , 0x0d je short .enter stosb cmp al , 0x08 jne short .write dec di cmp di , InputBuf ; underflow check je short .loop dec di .write: call PutChar jmp short .loop.enter: call PutChar mov al , 0x0a int 0x10 xchg ax , bx ; write the null terminator by using the BX = 0 from PutChar stosbInterpreterLoop: call ParseWord ; returns length in CX. Zero implies no more input. jcxz short ReadLine
Прерывание BIOS для получения символа с клавиатуры не печатает
клавишу и мы должны сделать это сами. Это делается с помощью
функции "TELETYPE OUTPUT", которая уже обрабатывает специальные
символы, такие как backspace или newline.
PutChar: xor bx , bx mov ah , 0x0e int 0x10 ret
У этой функции есть свои недостатки. Например, необходимы
"грязные" символы окончания строки CRLF (CR для перемещения курсора
в начало строки и LF для перемещения на следующую строку). Кроме
того, символ backspace только перемещает курсор на один символ
назад, но не стирает его. Чтобы получить поведение, которого мы
ожидаем, необходимо напечатать \b \b (справедливости ради, это
также происходит на современных терминалах). Я решил это
пропустить.
Наконец, в "Списке прерываний" Ральфа
Браунаупоминается, что некоторые BIOS сбрасывают BP, когда
печатаемый символ вызывает прокрутку экрана. Это нас не касается,
так как мы вообще не используем этот регистр.
Парсинг
После того как мы прочитали строку, нам нужно разобрать ее на
слова. Это делается по требованию и каждое слово выполняется (или
компилируется, в зависимости от состояния), как только оно
разобрано. Помимо цикла интерпретатора, ParseWord также вызывается
реализацией : (для получения имени определяемого слова).
Как уже упоминалось, эта процедура также вычисляет числовое
значение слова, предполагая, что оно достоверно. В этом отношении
нет никакой проверки ошибок и если слово не найдено в словаре, его
числовое значение выталкивается, что, вероятно, является
бессмыслицей, если это не было задумано.
Для начала мы пропускаем все пробельные символы во входном
буфере:
; returns; DX = pointer to string; CX = string length; BX = numeric value; clobbers SI and BPParseWord: mov si , [InputPtr] ; repe scasb вероятно, сохранит некоторые байты здесь, если бы реестры были разработаны - SCASB ; использует DI вместо SI :( - scasb ; uses DI instead of SI :(.skiploop: mov dx , si ; Если мы выйдем на петлю в этой итерации, DX укажет первую букву слова lodsb cmp al , " " je short .skiploop
Обратите внимание на то, как сохраняется указатель на начало
строки. Цикл проходит на один байт дальше пробела, поэтому
сохранение указателя после цикла потребовало бы отдельного
декремента. Вместо этого мы обновляем регистр при каждой итерации
цикла, но до того, как указатель увеличивается на lodsb.
В этот момент регистр AL загружен первым символом слова. Таким
образом, наш следующий цикл должен будет выполнить lodsb в своем
конце.
xor cx , cx xor bx , bx .takeloop: and al , ~0x20 jz short Return ; jump to a borrowed ret from some other routine
Эта инструкция интересна тем, что делает три вещи одновременно.
Она определяет пробелы и нулевые байты одним махом, а также
отключает бит, различающий заглавные и строчные буквы, что
позволяет работать с шестнадцатеричными числами в обоих случаях без
дополнительных затрат.
Если мы не обнаружили конец слова, мы увеличиваем счетчик длины
и преобразуем цифру в ее числовое значение:
inc cx sub al , "0" &~0x20 cmp al , 9 jbe .digit_ok sub al , "A" - ("0" &~0x20) - 10.digit_ok cbw
cbw - это малоизвестная инструкция, которая преобразует знаковое
число из байта в слово, но для нас это просто более короткое mov
ah, 0. Возможно, аналогичным образом мы используем знаковое
умножение imul, потому что у него больше возможностей для
использования регистров, чем у беззнакового mul. Используемая здесь
форма позволяет умножать на непосредственное значение и не
перезаписывать в DX верхнюю половину произведения.7
Эта конкретная инструкция должна быть закодирована вручную,
чтобы ширина литерала составляла 2 байта.8
; imul bx, bx, <BASE> но yasm настаивает на кодировании непосредственного в один байт... db 0x69, 0xdbBASE equ $ dw 16 add bx , ax ; add the new digit
Наконец, мы настраиваемся на следующую итерацию цикла. Мы
используем аналогичный трюк, как и раньше, где результат указателя
обновляется в каждой итерации, чтобы избежать отдельного декремента
в конце, поскольку нам нужно убедиться, что входной указатель не
указывает после терминатора.
mov [InputPtr], si lodsb jmp short .takeloop
Поиск по словарю
После того как слово разобрано, мы пытаемся найти его в словаре.
Для каждой записи нам нужно сравнить длину имени, а если она
совпадает, то и само имя. Включая F_HIDDEN в маску, мы
автоматически обрабатываем и скрытые записи. То, как мы сравниваем
длину, может выглядеть немного странно. Цель состоит в том, чтобы
сохранить бит F_IMMEDIATE в AL, чтобы нам не пришлось держать рядом
указатель на заголовок этого слова. Это одна из умных оптимизаций
Ильи Курдюкова.
InterpreterLoop: call ParseWord jcxz short ReadLine ; Пытаемся найти слово в словаре.. ; SI = указатель словаря ; DX = указатель строки ; CX = длина строки ; Следим за сохранением BX, в котором хранится числовое значение LATEST equ $+1 mov si , 0 .find: lodsw push ax ; сохранить указатель на следующую запись lodsb xor al , cl ; если длина совпадает, то AL содержит только флаги test al , F_HIDDEN | F_LENMASK jnz short .next mov di , dx push cx repe cmpsb pop cx je short .found .next: pop si or si , si jnz short .find ; Если мы дойдем до этой точки, то это будет число. ; ....found: pop bx ; отбрасываем указатель на следующую запись ; Когда мы дойдем до этого места, SI указывает на код слова, а AL содержит ; флаг F_IMMEDIATE
Эта часть показывает еще одно преимущество отсутствия разбиения
интерпретатора на многократно используемые фрагменты: мы можем
легко выйти на два разных кодовых пути, основываясь на результате
поиска.
Должны ли мы его выполнить?
Система может находиться в двух возможных состояниях:
Другими словами, слово должно быть выполнено, если оно
немедленное, или мы его интерпретируем. Мы храним этот флаг в поле
immediate инструкции or, так как при компиляции он будет установлен
в 0:
; Когда мы сюда попадаем, SI указывает на код слова, а AL содержит ; флаг F_IMMEDIATE STATESTATE equ $+1 or al , 1 xchg ax , si ; оба кодовых пути должны иметь указатель в AX jz short .compile ; Выполняем слово ; ...
Наиболее важными словами, которые должны изменить состояние,
являются : и ;, но они просто переходят в [ и ] слова, которые
позволяют временно вернуться в интерпретируемый режим при
компиляции слова. Типичный случай использования - вычисление
значения постоянного выражения:
: third-foo [ foos 3 cells + ] literal @ ;
Поскольку два значения STATE отличаются только на 1, мы можем
переключаться между ними с помощью inc и dec. Это имеет тот
недостаток, что они больше не являются идемпотентными, но это не
должно иметь значения для хорошо написанного кода:
defcode LBRACK, "[", F_IMMEDIATE inc byte[STATE]defcode RBRACK, "]" dec byte[STATE]
Выполнение слова
Если мы решили выполнить слово, мы извлекаем BX и DI, и
настраиваем SI так, чтобы NEXT перешел обратно к .executed:
; Выполнение слова RetSP RetSP equ $+1 mov di , RS0 pop bx mov si , .return jmp ax .return: dw .executed.executed: mov [RetSP], di push bx jmp short InterpreterLoop
Обработка чисел
Для чисел нет флага F_IMMEDIATE, поэтому для принятия решения
нам нужно просто проверить состояние. Это простое сравнение, но
если мы будем достаточно умны, здесь можно сэкономить байт. Давайте
снова посмотрим на код, который выполняет поиск в словаре. Какое
значение будет иметь AH, когда мы дойдем до регистра чисел?
.find: lodsw push ax ; сохранить указатель на следующую запись lodsb xor al , cl ; если длина совпадает, то AL содержит только флаги test al , F_HIDDEN | F_LENMASK jnz short .next mov di , dx push cx repe cmpsb pop cx je short .found.next: pop si or si , si jnz short .find ; AH = ?
Видите ли вы это? В этот момент AH равен нулю, так как содержит
старшую половину указателя на следующее слово, которое, как мы
знаем, является NULL, поскольку мы только что добрались до конца
списка. Это позволяет нам проверить значение STATE, не загружая его
в регистр или какие-либо непосредственные байты:
; Это число. Вставьте его значение - мы выкинем его позже, если окажется, что нужно скомпилировать ; его вместо этого. push bx cmp byte[STATE], ah jnz short InterpreterLoop ; Иначе скомпилируйте литерал. ; ...
Компиляция вещей
Указатель точки процесса компиляции называется HERE. Он
начинается сразу после распакованных данных. Функция, которая
выписывает слово в эту область, называется COMMA, так как слово
FORTH, которое это делает, - ,.
COMMA:HERE equ $+1 mov [CompressedEnd], ax add word[HERE], 2 ret
Он используется в прямом смысле для составления как чисел, так и
слов. Мы можем разделить хвост, хотя составлении слова он будет
перескакивать на середину составления числа:
; Иначе, компилируем литерал. mov ax , LIT call COMMA pop ax .compile: call COMMA jmp short InterpreterLoop
Последним кусочком головоломки являются : и ;. Давайте сначала
рассмотрим :. Поскольку ParseWord использует BX и SI, нам нужно
сохранить эти регистры. Более того, поскольку мы пишем множество
частей заголовка словаря, мы загрузим HERE в DI, чтобы упростить
работу. Это большое количество регистров, которые нам нужно
переместить. Однако на самом деле нам не нужно изменять ни один
регистр, поэтому мы можем просто сохранить все регистры с помощью
pusha.
defcode COLON, ":" pusha mov di , [HERE] call MakeLink ; link field call ParseWord mov ax , cx stosb ; length field mov si , dx rep movsb ; name field mov al , 0xe8 ; call stosb ; поле длины mov si, dx rep movsb ; поле имени mov al, 0xe8 ; вызов stosb ; Смещение определяется как (цель вызова) - (ip после инструкции вызова) ; Получается DOCOL - (di + 2) = DOCOL - 2 - di mov ax , DOCOL - 2 sub ax , di stosw mov [HERE], di popa jmp short RBRACK ; enter compilation mode ; войти в режим компиляции
; гораздо короче. Нам просто нужно скомпилировать EXIT и
вернуться в режим интерпретации:
defcode SEMI, ";", F_IMMEDIATE mov ax , EXIT call COMMA jmp short LBRACK
То, как эти слова переходят к другому слову в конце, весьма
удобно. Помните, как NEXT записываются как часть кода следующего
слова? Одно из слов должно быть последним в памяти, и тогда после
него не будет никакого "следующего слова". : и ; - идеальные
кандидаты для этого, поскольку им вообще не нужен NEXT.
Загрузка кода с диска
Поскольку мы не хотим вводить дисковые подпрограммы при каждой
загрузке, нам нужно предусмотреть способ запуска исходного кода,
загруженного с диска. Файловая система была бы отдельным зверем, но
в традициях FORTH есть минималистичное решение: диск просто делится
на блоки по 1 КБ, в которых хранится исходный код,
отформатированный как 16 строк по 64 символа. Затем load ( blknum
-- ) выполнит блок с указанным номером.
Мы размещаем блок 0 в LBA 0 и 1, блок 1 в LBA 2 и 3 и так далее.
Это означает, что блок 0 частично занят MBR, а LBA 1 используется
впустую, но меня это не особенно беспокоит.
Поскольку оригинальная служба BIOS по адресу int 0x13 / ah =
0x02 требует адресации CHS, я решил использовать вариант расширения
EDD (ah = 0x42). Это означает, что дискеты не поддерживаются, но я
все равно не планировал их использовать.
Чтобы использовать интерфейс EDD, нам нужно создать пакет адреса
диска, который выглядит следующим образом:
db 0x10 ; размер пакета db 0 ; зарезервировано dw sector_count dw buffer_offset, buffer_segment dq LBA
Мы используем гибридную стратегию для создания этого пакета.
Первая часть сохраняется как данные в бутсекторе, а остальное
записывается во время выполнения, даже если оно не меняется.
Шаблон" должен находиться в таком месте, чтобы мы могли писать
после него, поэтому идеальное место - прямо перед сжатыми
данными:
> > > DiskPacket: db 0x10, 0 .count: dw 2 .buffer:
; остальное заполняется во время выполнения, перезаписывая
сжатые данные,
; которые больше не нужны
CompressedData: times COMPRESSED_SIZE db 0xcc
Первые четыре байта пакета достаточно случайны, чтобы их можно
было жестко закодировать. Однако, когда дело доходит до адреса
буфера, мы можем сделать лучше. В любом случае нам нужно будет
записать этот адрес в InputPtr. Самый прямой способ сделать это
занимает шесть байт:
c706020a0006 mov word[InputPtr], BlockBuf
Однако мы можем получить эту переменную в AX без дополнительных
затрат:
b80006 mov ax , BlockBufa3020a mov [InputPtr], ax
Таким образом, мы можем записать эти два байта дискового пакета
с помощью всего 1 байта кода:
defcode LOAD, "load" pusha mov di , DiskPacket.buffer mov ax , BlockBuf mov word[InputPtr], ax stosw
Далее нам нужно записать сегмент (0000) и LBA (который
заканчивается шестью байтами 00). Мне нравится думать о
соответствующих инструкциях следующим образом:
31c0 xor ax , ax ; LBA zeroesab stosw ; segmentd1e3 shl bx , 1 ; LBA data93 xchg ax , bx ; LBA dataab stosw ; LBA data93 xchg ax , bx ; segmentab stosw ; LBA zeroesab stosw ; LBA zeroesab stosw ; LBA zeroes
То есть, мы записываем шесть нулей LBA за 5 байт кода. Запись
сегмента потребовала только перемещения xor ax, ax ранее, и
дополнительных stosw и xchg ax, bx. Таким образом, он занимает
нейтральные 2 байта (но нам нужно выписать его в коде, чтобы
указатель был правильным для остальной части пакета). Наконец,
конечно, у нас есть фактические данные LBA, которые меняются.
Пока AX равен нулю, воспользуемся случаем и поставим нулевой
терминатор после буфера:
mov [BlockBuf.end], al
Теперь мы готовы вызвать функцию BIOS. Если она выдаст ошибку,
мы просто зациклимся, так как восстановление сложное и самое
неприятное осложнение заключается в том, что счетчик секторов в
пакете перезаписывается количеством успешно прочитанных секторов,
что ломает наш шаблон.
DRIVE_NUMBER equ $+1 mov dl , 0 mov ah , 0x42 mov si , DiskPacket int 0x13 jc short $ popa pop bx
Числа для печати
u. печатает беззнаковое число, за которым следует пробел.
Поскольку при делении числа на разряды с помощью деления первой
получается наименее значащая цифра, мы помещаем цифры в стек, а
затем выводим и печатаем их в отдельном цикле. Пробел печатается
путем выталкивания фальшивой "цифры", которая будет преобразована в
пробел. Это также позволяет нам определить, когда мы вытолкнули все
цифры и цикл печати останавливается, когда он только что напечатал
пробел.
defcode UDOT, "u." xchg ax , bx push " " - "0".split: xor dx , dx div word[BASE] push dx or ax , ax jnz .split.print: pop ax add al , "0" cmp al , "9" jbe .got_digit add al , "A" - "0" - 10.got_digit: call PutChar cmp al , " " jne short .print pop bx
s: Поместить в строку
s: - это функция, которая, как мне кажется, имеет уникальное
значение для бутстраппинга. Это слово принимает адрес буфера и
копирует туда остаток текущей строки ввода. Без этого значительный
объем кода пришлось бы набирать дважды: сначала для того, чтобы
запустить его и загрузить редактор дисковых блоков, а затем еще
раз, чтобы сохранить его на диске.
Реализация представляет собой простой цикл, но установка вокруг
него заслуживает внимания и мы хотим загрузить входной указатель в
SI, но нам также нужно сохранить SI, чтобы мы могли правильно
вернуться. Используя xchg, мы можем сохранить его в [InputPtr] на
время копирования без дополнительных затрат:
;; Копирует остаток строки в buf. defcode LINE, "s:" ; ( buf -- buf+len ) xchg si , [InputPtr].copy: lodsb mov [ bx ], al inc bx or al , al jnz short .copy.done: dec bx dec si xchg si , [InputPtr]
Указатель назначения хранится в BX. Хотя запись в DI займет
всего один стосб, получение указателя в DI и обратно перевешивает
это преимущество. В конце мы оставляем в стеке указатель на нулевой
терминатор. Таким образом, вы можете продолжить строку, просто
используя s: в следующей строке. Поскольку мы не пропускаем
пробельные символы, это даже гарантирует правильную расстановку
символов.
Другие примитивы
Выбор примитивов для включения в Miniforth - это, пожалуй, самый
большой компромисс, который необходимо сделать. Я полностью ожидаю,
что некоторые более примитивные слова нужно будет определять во
время выполнения, вставляя их в опкоды. В конце концов, здесь нет
ни одного слова с ветвлением. Однако я уверен, что эти опкоды можно
будет генерировать простым ассемблером FORTH, а не просто жестко
закодировать.
Такая базовая арифметика, как +, незаменима. Я определяю и +, и
-, хотя, если бы я хотел вписать что-то более важное, я мог бы
оставить только - и позже определить : negate 0 swap - ; и : +
negate - ;.
Как и в любом низкоуровневом языке программирования, нам нужен
способ подглядывать и пихать значения в память. Реализация !
особенно хороша, поскольку мы можем просто заглянуть прямо в
[bx]:
defcode PEEK, "@" ; ( addr -- val ) mov bx, [bx]defcode POKE, "!" ; ( val addr -- ) pop word [bx] pop bx
Существуют также варианты, которые читают и записывают только
один байт:
defcode CPEEK, "c@" ; ( addr -- ch ) movzx bx , byte[ bx ]defcode CPOKE, "c!" ; ( ch addr -- ) pop ax mov [bx], al pop bx
Нам определенно нужны слова для работы со стеком.
dup и drop имеют очень простые
реализации, а swap определенно слишком полезен, чтобы
его пропустить.
defcode DUP, "dup" ; ( a -- a a ) push bx defcode DROP, "drop" ; ( a -- ) pop bx defcode SWAP, "swap" ; ( a b -- b a ) pop ax push bx xchg ax , bx
Я решил также включить >r и r>,
которые позволяют использовать стек возвратов в качестве второго
стека для значений (но, очевидно, только в пределах одного слова).
Это довольно мощный инструмент. Фактически, в сочетании с
dup, drop и swap они
позволяют реализовать любое слово для манипуляции стеком, которое
вы только можете себе представить.9
defcode TO_R, ">r" xchg ax , bx stosw pop bx defcode FROM_R, "r>" dec di dec di push bx mov bx , [ di ]
Наконец, emit печатает символ. Это достаточно
далеко от критического пути bootstrap, чтобы я мог спокойно удалить
его в случае необходимости.
defcode EMIT, "emit" xchg bx , ax call PutChar pop bx
Заключение
Я доволен тем, что получилось. Для системы, ограниченной
загрузочным сектором, я могу назвать ее вполне законченной по
функциям - я не могу придумать ничего, что могло бы значительно
упростить бутстрап, занимая при этом достаточно мало байт, чтобы
это казалось удаленно досягаемым для кодового гольфа. Это во многом
благодаря помощи Ильи Курдюкова - без него я бы не смог вписать
s:.
Я нашел старый ПК, который могу использовать для своих
экспериментов. На нем Miniforth загружается просто отлично:

Я буду документировать свое путешествие по созданию Miniforth в
будущих записях этого блога. Если это похоже на вашу чашку чая (а
если вы дочитали до этого места, то, вероятно, так оно и есть),
подпишитесь на RSS-канал или следите за мной в Twitter, чтобы
получать уведомления о новых статьях.
1
У теоретика графов было бы много сильных слов, чтобы описать
это, а не только цикл.
2
И даже если бы это было не так, есть много, многопримеров кода x86, написанного с
использованием печатаемого подмножества ASCII. Я даже сам однажды сделал этонесколько лет
назад.
3 Если вы, дорогой читатель, считаете это неудовлетворительным,
я хотел бы пригласить вас в собственное путешествие по
бутстрапингу. Это действительно очень весело!
4
Точную экономию на данный момент трудно подсчитать, поскольку
некоторые слова не используют добавляемый NEXT.
5
Хотя в этом отрывке справки говорится только о pop ss,
аналогичное утверждение содержится в документации по
mov.
6
Похоже, это одна из многих ошибок в SDM и использование
pop esp для этого не работает. Раздел 6.8.3
("Маскировка исключений и прерываний при переключении стека") в
томе 3A разъясняет, что все одноинструкционные способы загрузки
SP работают для этого. Я бы процитировал этот раздел,
если бы не тот факт, что, хотя в нем перечислены многие другие типы
событий, которые подавляются, в нем не упоминаются реальные
прерывания как один из них. Однако в этом разделе упоминаются
некоторые интересные крайние случаи. Например, если вы похожи на
меня, вам может быть интересно, что произойдет, если много
инструкций подряд записываются в SS. Ответ заключается
в том, что только первая из них гарантированно подавляет
прерывания.
7
Полагаю, имеет смысл, что эта опция доступна только для
imul, так как по модульной арифметике единственная
разница между знаковым и беззнаковым умножением заключается в
верхней половине произведения, которую мы здесь отбрасываем.
Иммедиаты могли бы быть полезны и для mul, хотя...
8
Вы можете спросить, почему бы просто не объявить, что
BASE - это переменная размером в байт? Ответ
заключается в том, что u., которое является словом,
печатающим число, использует div word[BASE], так что
результат все еще 16-битный.
9
Сюда не входят слова типа PICK, для них нужны
циклы. Однако все, что можно определить как ( <список
имен> -- <список имен>), является честной игрой.
Доказательство этого факта мы оставляем на усмотрение читателя. 10
10
Если серьезно, попробуйте разработать безошибочную стратегию
превращения эффекта стека в последовательность слов, которые его
реализуют. Это хорошая проблема.
github.com/NieDzejkob




























 level_3.html
level_3.html







 Разобранная на слои Atmega328P
Разобранная на слои Atmega328P
 ПЗУ TI TMS5200NL в сравнении с ПЗУ CBM
65CE02 от SiliconPr0n
ПЗУ TI TMS5200NL в сравнении с ПЗУ CBM
65CE02 от SiliconPr0n
 Модель
транзистора в NAND Flash
Модель
транзистора в NAND Flash
 Ячейки транзистора в энергонезависимой памяти
Ячейки транзистора в энергонезависимой памяти
 Изображение
ПЗУ из TMS320C52
Изображение
ПЗУ из TMS320C52
") CH340, припаянная к Arduino Nano (чипы не размечены)
CH340, припаянная к Arduino Nano (чипы не размечены)
 Вскрытие оболочки в вытяжном шкафу
Вскрытие оболочки в вытяжном шкафу
 Чип
обрабатывается в кислотной бане
Чип
обрабатывается в кислотной бане
 Кремниевый кристалл, извлеченный из
эпоксидной оболочки
Кремниевый кристалл, извлеченный из
эпоксидной оболочки
 CH340G, снятый через объектив с линзой,
дающей пятикратное увеличение
CH340G, снятый через объектив с линзой,
дающей пятикратное увеличение
 Картинка в более высоком разрешении
предлагается здесь: https://siliconpr0n.org/map/wch/ch340/mz_20x/
Картинка в более высоком разрешении
предлагается здесь: https://siliconpr0n.org/map/wch/ch340/mz_20x/
 Послойно
препарированная CH340
Послойно
препарированная CH340
 Справа
вверху: МПЗУ в CH340
Справа
вверху: МПЗУ в CH340
 Экран Rompar в инфракрасном спектре.
Экран Rompar в инфракрасном спектре.
 Увеличенное изображение бит в инфракрасном спектре
Увеличенное изображение бит в инфракрасном спектре
 Голубая
сетка для столбцов ПЗУ
Голубая
сетка для столбцов ПЗУ
 Двоичные разряды обведены кружочками
Двоичные разряды обведены кружочками
, Слой подложки (справа)") Металлический слой (слева), Слой подложки (справа)
Металлический слой (слева), Слой подложки (справа)
 Экран, которым открывается Bitviewer
Экран, которым открывается Bitviewer
 Bitview 16-битные столбцы
Bitview 16-битные столбцы
 Инвертированные биты из Bitview
Инвертированные биты из Bitview
 Таблица переходов
Таблица переходов
 Послойно препарированный CH340 с аннотациями
Послойно препарированный CH340 с аннотациями
 Частично дизассемблированное представление кода ch340
Частично дизассемблированное представление кода ch340
 Проверка уровня pH нейтрализованной серной кислоты
Проверка уровня pH нейтрализованной серной кислоты

.") Увеличение производительности
остановилось, что делает необходимым распараллеливать вычисления
различными способами, либо с помощью многоядерности, либо с помощью
векторизации, либо с помощью исполнения не в порядке очереди
(out-of-order).
Увеличение производительности
остановилось, что делает необходимым распараллеливать вычисления
различными способами, либо с помощью многоядерности, либо с помощью
векторизации, либо с помощью исполнения не в порядке очереди
(out-of-order).
 обрабатывает множество независимых потоков данных (синий цвет).") SIMD-инструкции, в отличие от
SISD-инструкций, каждая инструкция (зелёный цвет) обрабатывает
множество независимых потоков данных (синий цвет).
SIMD-инструкции, в отличие от
SISD-инструкций, каждая инструкция (зелёный цвет) обрабатывает
множество независимых потоков данных (синий цвет).
.") ARM floating point registers are
overlapping in the same register file (memory in CPU holding
registers).
ARM floating point registers are
overlapping in the same register file (memory in CPU holding
registers).
 Регистровый файл RISC-V может быть
скофигурирован так, чтобы иметь меньше 32 регистров. Может быть,
например, 8 регистров или 2 регистра большего размера. Регистры
могут занимать весь объём регистрового файла.
Регистровый файл RISC-V может быть
скофигурирован так, чтобы иметь меньше 32 регистров. Может быть,
например, 8 регистров или 2 регистра большего размера. Регистры
могут занимать весь объём регистрового файла.
 первое лого языка
первое лого языка
























 и его ремейк (БК 0010-01)") Buck Rogers: Planet of Zoom(Sega Z80-3D
System) и его ремейк (БК 0010-01)
Buck Rogers: Planet of Zoom(Sega Z80-3D
System) и его ремейк (БК 0010-01)
 и его порт для ZX Spectrum") R-Type (Irem M72) и его порт для ZX Spectrum
R-Type (Irem M72) и его порт для ZX Spectrum
") Contra (NES)
Contra (NES)
 Balloon fight, лицензионная NES версия
Balloon fight, лицензионная NES версия
 Balloon
fight для VS system
Balloon
fight для VS system


 В NES версии задник всех бонус уровней
одинаковый
В NES версии задник всех бонус уровней
одинаковый Аркадная версия игры расставляла разные
трубы для каждой бонусной игры
Аркадная версия игры расставляла разные
трубы для каждой бонусной игры

 Lobby экран VS system
Lobby экран VS system Lobby экран NES порт
Lobby экран NES порт




