

Меня зовут Данил Мухаметзянов, я работаю бэкенд-разработчиком в Badoo уже семь лет. За это время я успел создать и изменить большое количество кода. Настолько большое, что в один прекрасный день ко мне подошёл руководитель и сказал: Квота закончилась. Чтобы что-то добавить, нужно что-то удалить.
Ладно, это всего лишь шутка он такого не говорил. А жаль! В Badoo за всё время существования компании накопилось больше 5,5 млн строк логического бизнес-кода без учёта пустых строк и закрывающих скобок.
Само количество не так страшно: он лежит, есть не просит. Но два-три года назад я начал замечать, что всё чаще читаю и пытаюсь разобраться в коде, который на самом деле не работает в продакшен-окружении. То есть, по сути, мёртв.
Эту тенденцию заметил не только я. В Badoo поняли: наши высокооплачиваемые инженеры постоянно тратят время на мёртвый код.
С этим докладом я выступал на Badoo PHP Meetup #4
Откуда берётся мёртвый код
Мы начали искать причины проблем. Разделили их на две категории:
- процессные те, что возникают в результате разработки;
- исторические легаси-код.
В первую очередь решили разобрать процессные источники, чтобы предотвратить возникновение новых проблем.
A/B-тестирование
Активно использовать A/B-тестирование в Badoo начали четыре года назад. Сейчас у нас постоянно крутится около 200 тестов, и все продуктовые фичи обязательно проходят эту процедуру.
В результате за четыре года набралось около 2000 завершённых тестов, и эта цифра постоянно растёт. Она пугала нас тем, что каждый тест это кусок мёртвого кода, который уже не исполняется и вообще не нужен.
Решение проблемы пришло быстро: мы начали автоматически создавать тикет на выпиливание кода по завершении А/В-теста.

Пример тикета
Но периодически срабатывал человеческий фактор. Мы снова и снова находили код теста, который продолжал исполняться, но никто об этом не задумывался и не завершал тест.
Тогда появились жёсткие рамки: каждый тест должен иметь дату окончания. Если менеджер забывал ознакомиться с результатами теста, он автоматически останавливался и выключался. И, как я уже упомянул, автоматически создавался тикет на его выпиливание с сохранением исходного варианта логики работы фичи.
С помощью такого нехитрого механизма мы избавились от большого пласта работы.
Многообразие клиентов
В нашей компании поддерживаются несколько брендов, но сервер один. Каждый бренд представлен на трёх платформах: веб, iOS и Android. На iOS и Android у нас недельный цикл разработки: раз в неделю вместе с обновлением мы получаем новую версию приложения на каждой платформе.
Нетрудно догадаться, что при таком подходе через месяц у нас оказывается около десятка новых версий, которые необходимо поддерживать. Пользовательский трафик распределён между ними неравномерно: юзеры постепенно переходят с одной версии на другую. На некоторых старых версиях трафик есть, но он настолько мал, что поддерживать его тяжело. Тяжело и бесполезно.
Поэтому мы начали считать количество версий, которое хотим поддерживать. Для клиента появилось два лимита: софт-лимит и хард-лимит.
При достижении софт-лимита (когда вышло уже три-четыре новые версии, а приложение всё ещё не обновлено), пользователь видит скрин с предупреждением о том, что его версия устарела. При достижении хард-лимита (это порядка 10-20 пропущенных версий в зависимости от приложения и бренда) мы просто убираем возможность пропустить этот скрин. Он становится блокирующим: пользоваться приложением с ним нельзя.
Скрин для хард-лимита
В этом случае бесполезно продолжать процессить приходящие от клиента реквесты ничего, кроме скрина, он всё равно не увидит.
Но здесь, как и в случае с A/B-тестами, возник нюанс. Клиентские разработчики тоже люди. Они используют новые технологии, фишки операционных систем и через некоторое время версия приложения перестаёт поддерживаться на следующей версии операционной системы. Однако сервер продолжает страдать, потому что ему приходится продолжать обрабатывать данные запросы.
Отдельное решение мы придумали для случая, когда прекратилась поддержка Windows Phone. Мы подготовили скрин, который сообщал пользователю: Мы тебя очень любим! Ты очень классный! Но давай ты начнёшь пользоваться другой платформой? Тебе станут доступны новые крутые функции, а здесь мы уже ничего сделать не можем. Как правило, в качестве альтернативной платформы мы предлагаем веб-платформу, которая всегда доступна.
С помощью такого простого механизма мы ограничили количество версий клиентов, которое поддерживает сервер: приблизительно 100 разных версий от всех брендов, от всех платформ.
Фиче-флаги
Однако, отключив поддержку старых платформ, мы не до конца понимали, можно ли полностью выпиливать код, который они использовали. Или платформы, которые остались для старых версий ОС, продолжают пользоваться той же функциональностью?
Проблема в том, что наш API был построен не на версионированной части, а на использовании фиче-флагов. Как мы к этому пришли, вы можете узнать из этого доклада.
У нас было два типа фиче-флагов. Расскажу о них на примерах.
Минорные фичи
Клиент говорит серверу: Привет, это я. Я поддерживаю фотосообщения. Сервер смотрит на это и отвечает: Здорово, поддерживай! Теперь я об этом знаю и буду тебе отправлять фотосообщения. Ключевой особенностью здесь является то, что сервер никак не может влиять на клиент он просто принимает от него сообщения и вынужден его слушать.
Такие флаги мы назвали минорными фичами. На данный момент у нас их больше 600.
В чём неудобство использования этих флагов? Периодически встречается тяжёлая функциональность, которую нельзя покрыть только со стороны клиента, хочется контролировать её и со стороны сервера. Для этого мы ввели другие типы флагов.
Аппликейшен-фичи
Тот же клиент, тот же сервер. Клиент говорит: Сервер, я научился поддерживать видеостриминг. Включить его?. Сервер отвечает: Спасибо, я буду это иметь в виду. И добавляет: Отлично. Давай покажем нашему любимому пользователю эту функциональность, он будет рад. Или: Хорошо, но включать пока не будем.
Такие фичи мы назвали аппликейшен-фичами. Они более тяжёлые, поэтому их у нас меньше, но всё равно достаточно: больше 300.
Итак, пользователи переходят с одной версии клиента на другую. Какой-то флаг начинает поддерживаться всеми активными версиями приложениями. Или, наоборот, не поддерживаться. Не до конца понятно, как это контролировать: 100 версий клиентов, 900 флагов! Чтобы с этим разобраться, мы построили дашборд.
Красный квадрат на нём означает, что все версии данной платформы не поддерживают данную фичу; зелёный что все версии данной платформы поддерживают этот флаг. Если флаг может быть выключен и включён, он периодически моргает. Мы можем посмотреть, что в какой версии происходит.
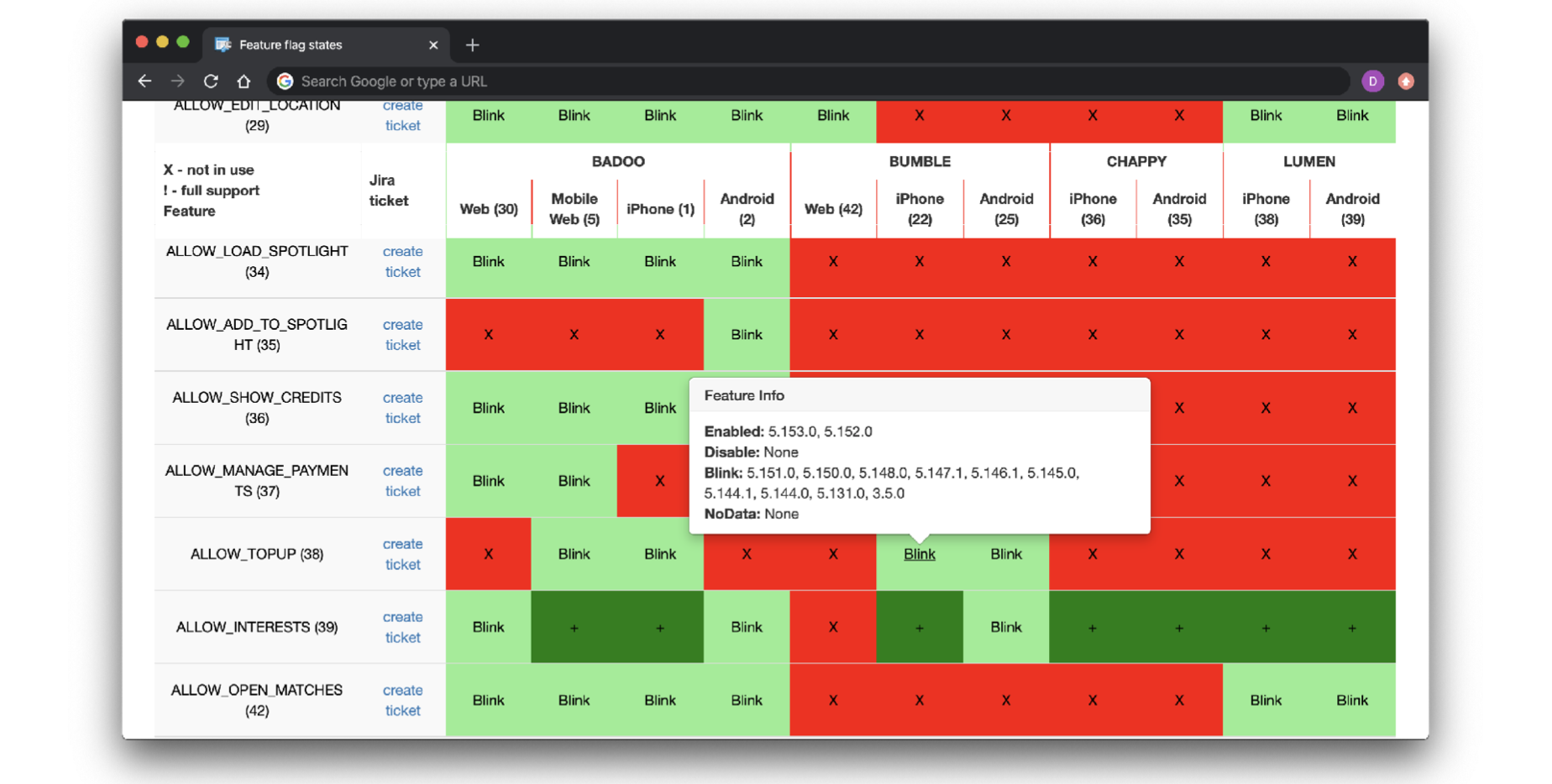
Скрин дашборда
Прямо в этом интерфейсе мы начали создавать задачи на выпиливание функциональности. Стоит отметить, что необязательно все красные или зелёные ячейки в каждой строке должны быть заполнены. Бывают флаги, которые запущены только на одной платформе. Бывают флаги, которые заполнены только для одного бренда.
Автоматизировать процесс не так удобно, но, в принципе, и не нужно достаточно просто ставить задачу и периодически смотреть на дашборд. В первой же итерации нам удалось выпилить 200 с лишним флагов. Это почти четверть флагов, которые мы использовали!
На этом процессные источники закончились. Они появились в результате флоу нашей разработки, и работу с ними мы успешно встроили в этот процесс.
Что делать с легаси-кодом
Мы остановили возникновение новых проблем в процессных источниках. И перед нами встал сложный вопрос: что делать с легаси-кодом, накопленным за долгие годы? К решению мы подошли с инженерной точки зрения, то есть решили всё автоматизировать. Но было непонятно, как найти код, который не используется. Он спрятался в своём уютном мирке: никак не вызывается, о себе никак не даёт знать.
Пришлось зайти с другой стороны: взять весь код, который у нас был, собрать информацию о том, какие куски точно выполняются, а потом сделать инверсию.
Затем мы собрали это воедино и имплементировали на самом минимальном уровне на файлах. Так мы смогли легко получить список файлов из репозитория, выполнив соответствующую UNIX-команду.
Оставалось собрать список файлов, которые используются на продакшене. Это довольно просто: на каждый реквест на шатдауне вызвать соответствующую PHP-функцию. Единственная оптимизация, которую мы здесь сделали, начали запрашивать OPCache вместо запроса каждого реквеста. Иначе количество данных было бы очень большим.
В результате мы обнаружили много интересных артефактов. Но при более глубоком анализе поняли, что недосчитываемся неиспользуемых методов: разница в их количестве была в трисемь раз.
Выяснилось, что файл мог загружаться, исполняться, компилироваться ради только одной константы или пары методов. Всё остальное оставалось бесполезно лежать в этом бездонном море.
Собираем список методов
Впрочем, собрать полный список методов получилось достаточно быстро. Мы просто взяли парсер Никиты Попова, скормили ему наш репозиторий и получили всё, что имеем в коде.
Остался вопрос: как собрать то, что исполняется на продакшене? Нас интересует именно продакшен, потому что тесты могут покрывать и то, что нам совсем не нужно. Недолго думая, мы взяли XHProf. Он уже исполнялся на продакшене для части запросов, и потому у нас были семплы профилей, которые хранятся в базах данных. Было достаточно просто зайти в эти базы, спарсить сгенерированные снепшоты и получить список файлов.
Недостатки XHProf
Мы повторили этот процесс и на другом кластере, где XHProf не запускался, но был крайне необходим. Это кластер запуска фоновых скриптов и асинхронной обработки, который важен для highload в нём исполняется большое количество логики.
И тут мы убедились, что XHProf для нас неудобен.
- Он требует изменения PHP-кода. Нужно вставить код старта трейсинга, закончить трейсинг, получить собранные данные, записать их в файл. Всё-таки это профайлер, а у нас продакшен, то есть запросов много, нужно думать и о семплировании. В нашем случае это усугубилось большим количеством кластеров с разными entry points.
- Дублирование данных. У нас работала оптимизация для файлов. Вместо того чтобы получать список методов на каждый реквест, мы просто опрашивали OPCache. Реквестов много: если использовать XHProf, то нужно на каждый реквест записать некое количество данных и используемые методы. Но большая часть методов вызывается из раза в раз, потому что это core-методы или использование стандартного фреймворка.
- Человеческий фактор. У нас произошла одна интересная ситуация. Мы запустили XHProf на кластере обработки очередей. Запустили в облегчённом режиме (через опции XHProf): выключили сбор метрик потребления CPU, памяти, потому что они были бесполезны и только нагружали сервер. По сути, это был эксперимент, который мы не анонсировали до получения результатов. Но в какой-то момент мейнтейнер XHProf aggregator (наш внутренний компонент на базе XHProf с официальным названием Live Profiler, который мы выложили в open-source) это заметил, подумал, что это баг, и включил все обратно. Включил, проанализировал и сообщил: Ребята, кажется, у нас проблемы, потому что потребление CPU выросло на этом кластере, так как мы включили профилирование для большого числа запросов, о чём Live Profiler не знал. Мы, конечно, быстро заметили это и всё пофиксили.
- Сложность изменения XHProf. Данных собиралось много, поэтому нам хотелось автоматизировать их доставку и хранение. У нас уже был процесс доставки логов для ошибок и статистики. Мы решили использовать ту же самую схему вместо того, чтобы плодить новые. Но она требовала изменения формата данных: например, специфичной обработки переводов строк (стоит отметить, как правильно заметил youROCK, этого не требует lsd, но так было удобнее для поддержки единой обертки над ним). Патчить XHProf это не то, что нам хотелось делать, потому что это достаточно большой профайлер (вдруг что-нибудь сломаем ненароком?).
Была и ещё одна идея исключить определённые неймспейсы, например неймспейсы вендоров из композера, исполняющиеся на продакшене, потому что они бесполезны: мы не будем рефакторить вендорские пакеты и выпиливать из них лишний код.
Требования к решению
Мы ещё раз собрались и посмотрели, какие решения существуют. И сформулировали итоговый список требований.
Первое: минимальные накладные расходы. Для нас планкой был XHProf: не больше, чем требует он.
Второе: мы не хотели изменять PHP-код.
Третье: мы хотели, чтобы решение работало везде и в FPM, и в CLI.
Четвёртое: мы хотели обработать форки. Они активно используются в CLI, на облачных серверах. Делать специфическую логику для них внутри PHP не хотелось.
Пятое: семплирование из коробки. По факту это вытекает из требования не изменять PHP-код. Ниже я расскажу, почему нам было необходимо семплирование.
Шестое и последнее: возможность форсировать из кода. Мы любим, когда всё работает автоматически, но иногда удобнее вручную запустить, подебажить, посмотреть. Нам нужна была возможность включать и выключать все прямо из кода, а не по рандомному решению более общего механизма модуля PHP, задающего вероятность включения через настройки.
Принцип работы funcmap
В результате у нас родилось решение, которое мы назвали funcmap.
По сути funcmap это PHP extension. Если говорить в терминах PHP, то это PHP-модуль. Чтобы понять, как он работает, давайте посмотрим, как работает PHP-процесс и PHP-модуль.
Итак, у вас запускается некий процесс. PHP даёт возможность при построении модуля подписываться на хуки. Запускается процесс, запускается хук GINIT (Global Init), где вы можете инициализировать глобальные параметры. Потом инициализируется модуль. Там могут создаваться и выделяться в память константы, но только под конкретный модуль, а не под реквест, иначе вы выстрелите себе в ногу.
Затем приходит пользовательский реквест, вызывается хук RINIT (Request Init). При завершении реквеста происходит его шатдаун, и уже в самом конце шатдаун модуля: MSHUTDOWN и GSHUTDOWN. Всё логично.
Если мы говорим об FPM, то каждый пользовательский реквест приходит в уже существующий воркер. По сути, RINIT и RSHUTDOWN просто работают по кругу, пока FPM не решит, что воркер своё отжил, пора его пристрелить и создать новый. Если мы говорим о CLI, то это просто линейный процесс. Всё будет вызвано один раз.

Принцип работы funcmap
Из всего этого набора нас интересовали два хука. Первый RINIT. Мы стали выставлять флаг сбора данных: это некий рандом, который вызывался для семплирования данных. Если он срабатывал, значит, мы этот реквест обрабатывали: собирали для него статистику вызовов функций и методов. Если он не срабатывал, значит, реквест не обрабатывался.
Следующее создание хеш-таблицы, если её нет. Хеш-таблица предоставляется самим PHP изнутри. Здесь ничего изобретать не нужно просто бери и пользуйся.
Дальше мы инициализируем таймер. О нём я расскажу ниже, пока просто запомните, что он есть, важен и нужен.
Второй хук MSHUTDOWN. Хочу заметить, что именно MSHUTDOWN, а не RSHUTDOWN. Мы не хотели отрабатывать что-то на каждый реквест нас интересовал именно весь воркер. На MSHUTDOWN мы берём нашу хеш-таблицу, пробегаемся по ней и пишем файл (что может быть надёжнее, удобнее и универсальнее старого доброго файла?).
Заполняется хеш-таблица достаточно просто тем самым PHP-хуком zend_execute_ex, который вызывается при каждом вызове пользовательской функции. Запись содержит в себе дополнительные параметры, по которым можно понять, что это за функция, её имя и класс. Мы её принимаем, считываем имя, записываем в хеш-таблицу, а потом вызываем дефолтный хук.
Данный хук не записывает встроенные функции. Если вы хотите подменить встроенные функции, для этого есть отдельная функциональность, которая называется zend_execute_internal.
Конфигурация
Как это конфигурировать, не изменяя PHP-код? Настройки очень простые:
- enabled: включён он или нет.
- Файл, в который мы пишем. Здесь есть плейсхолдер pid для исключения race condition при одновременной записи в один файл разными PHP-процессами.
- Вероятностная основа: наш probability-флаг. Если вы выставляете 0, значит, никакой запрос записан не будет; если 100 значит, все запросы будут логироваться и попадать в статистику.
- flush_interval. Это периодичность, с которой мы сбрасываем все данные в файл. Мы хотим, чтобы сбор данных исполнялся в CLI, но там есть скрипты, которые могут выполняться достаточно долго, съедая память, если вы используете большое количество функционала.
К тому же если у нас есть кластер, который не так сильно нагружен, FPM понимает, что воркер готов обрабатывать ещё, и не убивает процесс он живёт и съедает какую-то часть памяти. Через определённый промежуток времени мы сбрасываем всё на диск, обнуляем хеш-таблицу и начинаем заполнять всё заново. Если в данный промежуток времени таймаут времени все же не достиг, то срабатывает хук MSHUTDOWN, где мы пишем всё окончательно.
И последнее, что мы хотели получить, возможность вызвать funcmap из PHP-кода. Соответствующее расширение даёт единственный метод, который позволяет включить или выключить сбор статистики независимо от того, как сработало probability.
Накладные расходы
Нам стало интересно, как всё это влияет на наши серверы. Мы построили график, который показывает количество реквестов, приходящих на реальную боевую машину одного из самых нагруженных PHP-кластеров.
Таких машин может быть много, поэтому на графике мы видим количество реквестов, а не CPU. Балансировщик понимает, что машина стала потреблять больше ресурсов, чем обычно, и старается выровнять запросы, чтобы машины были нагружены равномерно. Этого было достаточно для того, чтобы понять, насколько деградирует сервер.
Мы включили наше расширение последовательно на 25%, 50% и 100% и увидели вот такую картину:

Пунктир это количество реквестов, которое мы ожидаем. Основная линия количество реквестов, которое приходит. Мы увидели деградацию ориентировочно в 6%, 12% и 23%: данный сервер начал обрабатывать практически на четверть меньше приходящих реквестов.
Этот график в первую очередь доказывает, что нам важно семплирование: мы не можем тратить 20% ресурсов сервера на сбор статистики.
Ложный результат
Семплирование имеет побочный эффект: какие-то методы не попадают в статистику, но по факту используются. Мы пытались бороться с этим несколькими способами:
- Повышение вероятности. У нас был сервер с небольшим количеством запросов для бэк-офиса, то есть для обработки внутренних реквестов. Мы повысили вероятность сбора статистики, потому что деградация кластера нам не угрожала, и увидели, что количество реквестов, количество ложноположительных результатов уменьшилось.
- Обработка ошибок. Ошибки бывают редко, но они случаются: необходимо их обрабатывать и отдавать клиенту, иначе он не поймёт, что случилось.
Для обработки ошибок мы пробовали два решения. Первое включать сбор статистики принудительно начиная с того момента, когда ошибка была сформирована: собираем error-лог и анализируем. Но здесь есть подводный камень: при падении какого-либо ресурса количество ошибок моментально растёт. Вы начинаете их обрабатывать, воркеров становится гораздо больше и кластер начинает медленно умирать. Поэтому делать так не совсем правильно.
Как сделать по-другому? Мы вычитали, и, используя парсер Никиты Попова, прошлись по стейктейсам, записав, какие методы там вызываются. Таким образом мы исключили нагрузку на сервер и уменьшили количество ложноположительных результатов.
Но всё равно оставались методы, которые вызываются редко и про которые было неясно, нужны они или не нужны. Мы добавили хелпер, который помогает определить факт использования таких методов: если семплирование уже показало, что метод вызывается редко, то можно включить обработку на 100% и не думать о том, что происходит. Любое исполнение этого метода будет залогировано. Вы будете об этом знать.
Если вы точно знаете, что метод используется, это может быть избыточно. Возможно, это нужная, но редкая функциональность. Представьте, что у вас есть опция Пожаловаться, которая используется редко, но она важна выпилить её вы не можете. Для таких случаев мы научились маркировать подобные методы вручную.
Мы создали интерфейс, в котором видно, какие методы используются (они на белом фоне), а какие потенциально не используются (они на красном фоне). Здесь можно и промаркировать нужные методы.
Скрин интерфейса
Интерфейс это здорово, но давайте вернёмся к началу, а именно к тому, какую проблему мы решали. Она заключалась в том, что наши инженеры читают мёртвый код. Читают его где? В IDE. Представляете, каково это заставить фаната своего дела уйти из IDE-мира в какой-то веб-интерфейс и что-то там делать! Мы решили, что надо пойти навстречу коллегам.
Мы сделали плагин для PhpStorm, который загружает всю базу неиспользуемых методов и отображает, используется данный метод или нет. Более того, в интерфейсе можно пометить метод как используемый. Это всё отправится на сервер и станет доступно остальным контрибьюторам кодовой базы.
На этом завершилась основная часть нашей работы с легаси. Мы стали быстрее замечать, что у нас не исполняется, быстрее на это реагировать и не тратить время на поиски неиспользуемого кода вручную.
Расширение funcmap выложено на GitHub. Будем рады, если оно кому-то пригодится.
Альтернативы
Со стороны может показаться, что мы в Badoo не знаем, чем себя занять. Почему бы не посмотреть, что есть на рынке?
Это справедливый вопрос. Мы смотрели и на рынке в тот момент ничего не было. Только когда мы начали активно внедрять своё решение, мы обнаружили, что в то же самое время человек по имени Joe Watkins, живущий в туманной Великобритании, реализовал аналогичную идею и создал расширение Tombs.
Мы не очень внимательно его изучили, потому что у нас уже было своё решение, но тем не менее обнаружили несколько проблем:
- Отсутствие семплирования. Выше я объяснял, почему оно нам необходимо.
- Использование разделяемой памяти. В своё время мы столкнулись с тем, что воркеры начинали упираться в запись конкретного ключа при использовании APCu (модуль кеширования), поэтому в своём решении мы не используем разделяемую память.
- Проблемная работа в CLI. Всё работает, но, если вы одновременно запустите два CLI-процесса, они начнут конфликтовать и публиковать ненужные ворнинги.
- Сложность постобработки. Расширение Tombs, в отличие от нашего, само понимает, что было загружено, что было исполнено, и в конце концов выдаёт то, что инвертировано. Мы же в funcmap делаем инверсию уже после (вычитаем из всего кода тот, который использовался): у нас тысячи серверов, и эти множества нужно правильно пересечь. Tombs отлично сработает, если у вас небольшое количество серверов, вы используете FPM и не используете CLI. Но если вы используете что-то сложнее, попробуйте оба решения и выберите более подходящее.
Выводы
Первое: заранее думайте о том, как вы будете удалять функциональность, которая имплементируется на короткий промежуток времени, особенно если разработка идёт очень активно. В нашем случае это были A/B-тесты. Если вы не подумаете об этом заранее, то потом придётся разгребать завалы.
Второе: знайте своих клиентов в лицо. Неважно, внутренние они или внешние вы должны их знать. В какой-то момент надо сказать им: Родной, стоп! Нет.
Третье: чистите свой API. Это ведёт к упрощению всей системы.
И четвёртое: автоматизировать можно всё, даже поиск мёртвого кода. Что мы и сделали.



