
НСПК сегодня это не просто операционно-клиринговый центр для
карточных операций, но и современная технологическая платформа для
продвижения и развития платёжных инструментов и сервисов, как на
территории России, так и за её пределами. НСПК это платёжная
система Мир, Система быстрых платежей и обработка внутрироссийских
операций по картам международных платёжных систем. Мы обеспечиваем
миллиарды транзакций в год при отказоустойчивости и доступности на
уровне 99,999%.
Для поддержки столь высокого уровня доступности сервисов, помимо
прочего, нужна сильная и внятная концепция мониторинга, способная
решать самые разные задачи, и готовая адаптироваться к любым
условиям.
Меня зовут Липкин Иван, в НСПК я руковожу управлением прикладного
мониторинга, и сегодня я хочу поделиться опытом построения
прикладного и бизнес-мониторинга, полученным нашей командой за
несколько лет развития национальных платёжных сервисов.
Идеология

Идея, которой мы придерживаемся в подходах к построению процессов
мониторинга, состоит в том, что сервис абстрактно раскладывается на
три слоя: бизнес, прикладной и инфраструктурный. С каждого из слоёв
экспортируются метрики, логи (в некоторых случаях данные
трассировок приложений) для комплексного анализа работоспособности
системы, создания аналитических панелей, настройки триггеров
различных состояний и поведения метрик.
Мы считаем, что мониторинг в представленной модели необходимо
выстраивать строго сверху вниз, в первую очередь контролируя
ключевые показатели бизнес-функций сервиса.
Разделение сервиса на уровни происходит по принципу отнесения
снимаемых с него данных к описанным трём категориям:
Бизнес-слой данные, отражающие активность и опыт конечного
пользователя или конечной точки подключения. По ним формируются
количественные и качественные метрики оказания сервиса. Например,
если говорить про платежную систему Мир, то метриками бизнес-уровня
будут объемы успешных или неуспешных авторизационных запросов в
единицу времени, их разбивка по конечным точкам подключения, типам
операций и т.д. Как правило, метрики этого уровня (как и
бизнес-лог) индивидуальны для каждого сервиса, их количество и
состав формируются из потребностей в каждом конкретном случае.
Прикладной слой данные о работе приложений, реализующих
бизнес-логику сервиса. Например, статусы и состояния модулей
системы, получаемые с различных интерфейсов, штатные метрики
эксплуатируемого ПО, различные технические логи и т.д. На этом
уровне уже есть возможность задействовать готовые механизмы
экспорта данных, которые предоставляет поставщик системы
мониторинга для упрощенной интеграции с используемыми в сервисе
технологиями.
Инфраструктурный слой данные о работе приложений и
оборудования опорной инфраструктуры. Помимо аппаратного, этот слой
имеет собственный прикладной подуровень, так как существует целый
пласт приложений, обслуживающих инфраструктуру. Тут так же, как и
на уровне выше, применяются техники готовых интеграций систем
мониторинга с используемым ПО и автоматизация. Мониторинг
инфраструктуры, как отдельную большую тему, в этой статье
рассматривать не будем, речь пойдёт исключительно про два верхних
уровня.
Требования к системе мониторинга
Мониторинг это служебный сервис, который не зарабатывает деньги в
явном виде. При этом все понимают, что без качественного
мониторинга невозможно обеспечить требования по уровню доступности,
времени восстановления после сбоев, различные SLA перед партнёрами,
рынком, регулятором и т.д. Тут и возникает важная задача
максимально покрыть все потребности в мониторинге бизнес-сервисов,
минимизировав при этом расходы на создание такой системы.
Формирование используемого для мониторинга стека приложений
зачастую становится довольно непростой задачей. В общем виде можно
описать следующие требования, характеризующие систему:
Компактность
Конечно, хотелось бы иметь стек, покрывающий все домены обратной
связи с сервисом (метрики, логи, прикладные трассы для
профилирования запросов и мониторинга приложений). На рынке
существуют десятки разных систем, работающих по каждому домену, но
заводить зоопарк не хочется никому. С другой стороны, очевидно, что
не существует универсальных решений, способных одинаково эффективно
работать со всеми видами данных с сервиса.
Эффективность
Система должна решать широкий спектр задач: от самых базовых
триггеров, реагирующих на статичные пороговые значения, до сложных
аналитических концепций, таких как обнаружение аномалий и
прогнозирование с использованием статистического анализа или
машинного обучения.
Гибкость
Система должна уметь получать данные от сервисов в разных режимах
(push\pull), иметь богатый набор экспортёров данных и встроенные
механизмы интеграции с современным ПО. То есть любая поставленная
перед мониторингом задача должна решаться максимально быстро и, по
возможности, штатными средствами, без долгих интеграционных
процессов или разработки.
Открытость
Идеально, если весь используемый стек это open source. Но тут нужно
представить известную картинку с тремя пересекающимися кругами
цена, качество и время. Эта характеристика имеет свои плюсы и
минусы, не всегда имеется время и профессиональный ресурс для
решения всего спектра задач с использованием открытого ПО. Здесь мы
за здравый баланс, но с прицелом на идеал open source и компетенции
его приготовления.
В настоящее время нам удалось достичь определённой гармонии в
совмещении всех этих требований. За последние несколько лет сервис
качественно изменялся по форме, содержанию и задачам, но обо всем
по порядку.
Хронология развития прикладного стека
В 2015 году, когда всё только начиналось, мониторинг представлял
собой всего лишь один элемент Zabbix, функциональных возможностей
которого очень быстро стало не хватать. Во-первых, появилась
потребность в централизованном сборе и хранении логов. Во-вторых,
возникла необходимость визуализации и контроля качества прикладного
авторизационного трафика. Очевидно, что решить такие задачи с
помощью одного только Zabbix было невозможно и в инфраструктуру
мониторинга добавился стек ELK (Elasticsearch, Logstash, Kibana),
который прекрасно решает вопрос с централизованным сбором логов, и
Grafana, хорошо справляющаяся с визуализацией данных. В итоге к
середине 2016 года в стек уже входит: Zabbix, ELK, Grafana и много
Perl-a.
По мере развития сервисов меняются требования и к контролю
операционных процессов. В 2016 году описательной аналитики ELK +
Grafana становится недостаточно. Возникают задачи по анализу тысяч
метрик и не визуально на видео-стенах, а в фоновом режиме системы с
использованием статистических анализаторов с динамическими базовыми
линиями. Так же необходимо было обеспечить возможности быстрого
реагирования на нештатные ситуации и оценки степени их воздействия
на бизнес. Возникает потребность в платформе операционной и
бизнес-аналитики, в которой можно делать сложные параметризованные
отчеты, которыми бы пользовалась дежурная служба, выдавая
коммуникацию с подготовленной по инциденту статистикой как внутри
компании, так и внешним потребителям (на рынок).
В конце 2017 года мы открываем внутренний проект по выбору
платформы операционной аналитики, и в фокусе нашего внимания
оказывается Splunk.
В 2018 году Splunk уже внедрён в систему прикладного мониторинга
НСПК. На текущий момент он по-прежнему остается аналитическим ядром
в стеке, осуществляющим комплексный анализ данных, что позволяет
фиксировать даже незначительные случаи деградации в процессах.
Все бы хорошо, но в начале 2019 года Splunk уходит с российского
рынка, вынуждая нас искать альтернативу. Такой альтернативой
видится ELK++ привычный нам стек, но с определёнными расширениями
(про ++ дальше).
Уход Splunk из России не означает, что им нельзя пользоваться. У
нас имеется постоянная лицензия, ограниченная только объёмом
индексируемых данных в сутки. Понятно, что со временем это станет
проблемой, поэтому у нас имеется стратегия по миграции на
альтернативное решение.
Архитектура и прикладной стек
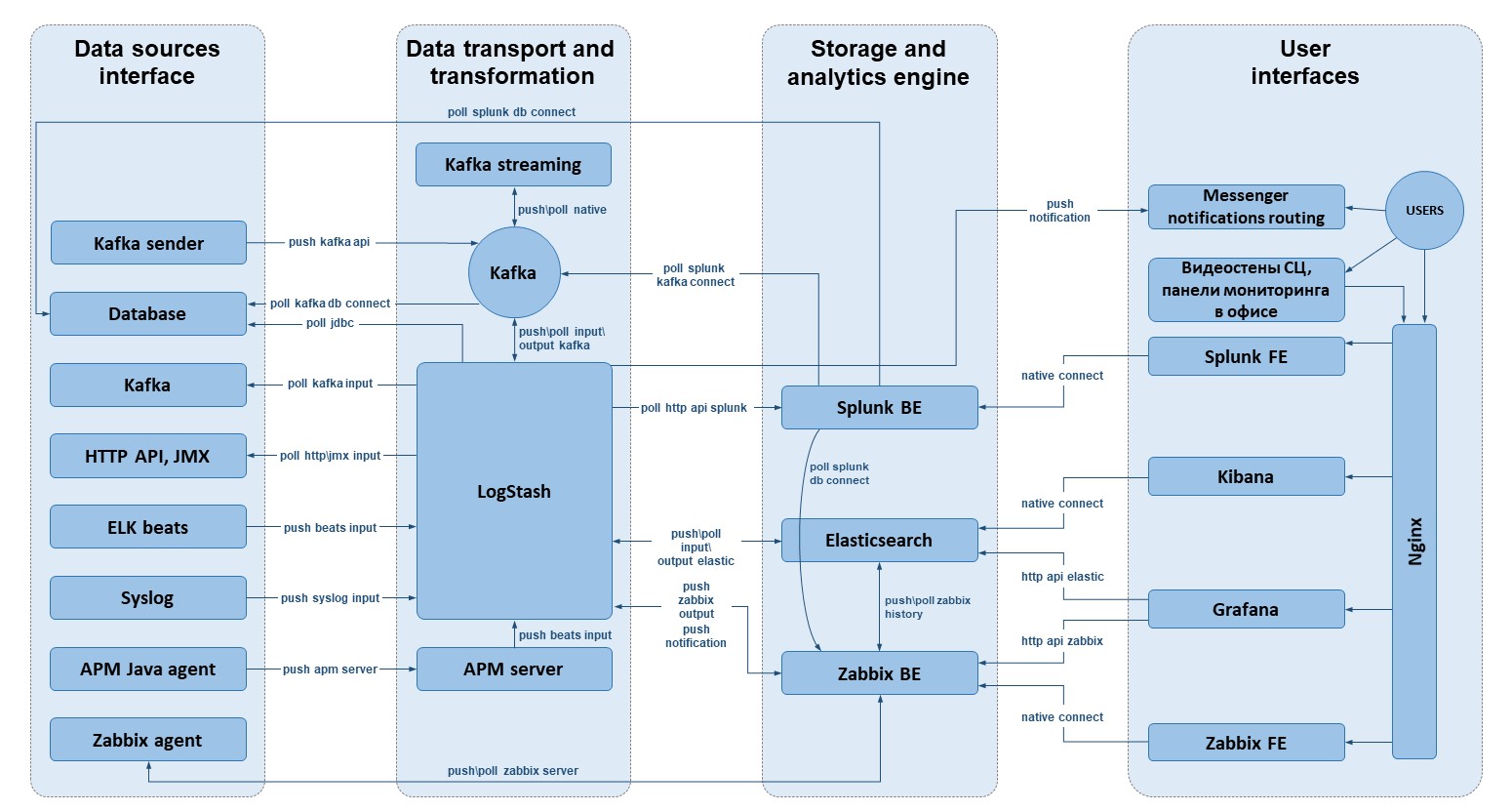
Представленная схема это упрощённый (сутейный) вариант, фактическая
же схема гораздо сложнее. Приложения имеют кластерную архитектуру,
все развёрнуто в нескольких дата-центрах и экземпляров системы тоже
несколько. Но все сигналы и общий контроль выведены на консоли и
видеостены дежурной службы в ситуационных центрах, тем самым
глобальная картина по сервисам и их состояниям формируется в едином
центре управления полётами.
Но вернемся к архитектуре. Как видно на схеме, система условно
раскладывается на четыре слоя: источники данных, транспорт,
хранение\анализ и клиентская часть.
Источники данных и транспорт
Ключевую роль в сборе и транспортировке данных играют компоненты
ELK-stack, Zabbix, а также брокер Kafka с клиентской библиотекой
обработки потоков Kafka Streaming (очень важно, что это полностью
open source). Богатый набор экспортёров данных Beats data shippers
и input\output плагинов Logstash покрывает практически весь набор
потребностей по снятию данных с объектов мониторинга. Также
Logstash выступает в качестве посредника между шиной или конечной
аналитической системой и системой алертинга Zabbix. Таким образом
Logstash выполняет функции агрегатора метрик и планировщика
запросов в сторонние API, откуда получает результаты сложной
аналитики данных (например, из Splunk) для передачи их в
Zabbix.
Zabbix, по такому же принципу, использует готовые шаблоны для
экспорта метрик с сервиса. Иногда одну и туже задачу можно решить,
как средствами ELK, так и Zabbix. В зависимости от ситуации, выбор
делается в пользу того или иного приложения в стеке.
Чтобы отдавать в несколько конечных аналитических систем одни и те
же данные, в транспортном слое присутствует Apache Kafka. Брокер
получает данные как от Logstash, так и через собственные коннекторы
Kafka Connect или напрямую от приложений, которые подключаются к
Producer API Kafka. Использование единой шины решает ряд проблем. В
качестве потребителя можно поставить любое хранилище данных и со
стороны транспорта ничего менять не нужно. Получается своего рода
стандарт, где любая новая потребность в данных решается просто,
используя готовые рельсы.
На слое транспорта происходит ещё и трансформация данных. Несложные
преобразования и обогащения делаются на Logstash формирование новых
вычислительных атрибутов в данных, приклеивание справочников и т.д.
Более сложные концепции обработки потоков реализуются в Kafka
Streaming. Пока у нас имеется только одно приложение,
обрабатывающее поток бизнес-лога авторизационных систем, формируя
на лету модель данных для мониторинга. Но мы активно работаем в
этом направлении, усиливая компетенции в области инженерии
данных.
Как отдельное направление мониторинга, но полностью интегрированное
в стек, Elastic развивает APM (application performance monitoring
профилирование запросов и мониторинг приложений), который мы
пробуем применять под задачи сбора и анализа прикладных трасс. В
транспортном слое этот элемент представлен APM-агентом (в нашем
случае java) и APM-сервером, в задачи которого входит обработка
данных от агентов и подготовка их для передачи в Elasticsearch.
Конечные аналитические системы
Аналитическим ядром системы является Splunk готовое коробочное
решение: база данных, язык взаимодействия с данными и
пользовательский интерфейс.
Это очень гибкий и универсальный инструмент, особенностью которого
можно назвать сильный высокоуровневый язык SPL (search processing
language). Он сочетает в себе возможности SQL и Unix pipeline
syntax. На этом языке можно очень быстро писать аналитические
запросы к данным, а в сочетании с UI конструировать сложнейшие
параметрические отчёты.
Все настраивается так, чтобы дежурный затратил минимум сил и
получил максимум понимания по инциденту. Вот пример панели для
расчёта статистики по инциденту на авторизационном сервисе. На
панели есть вся необходимая информация о затронутых эквайрерах,
эмитентах, платежных системах и т.д. Можно все это фильтровать в
зависимости от ситуации и проблемы.
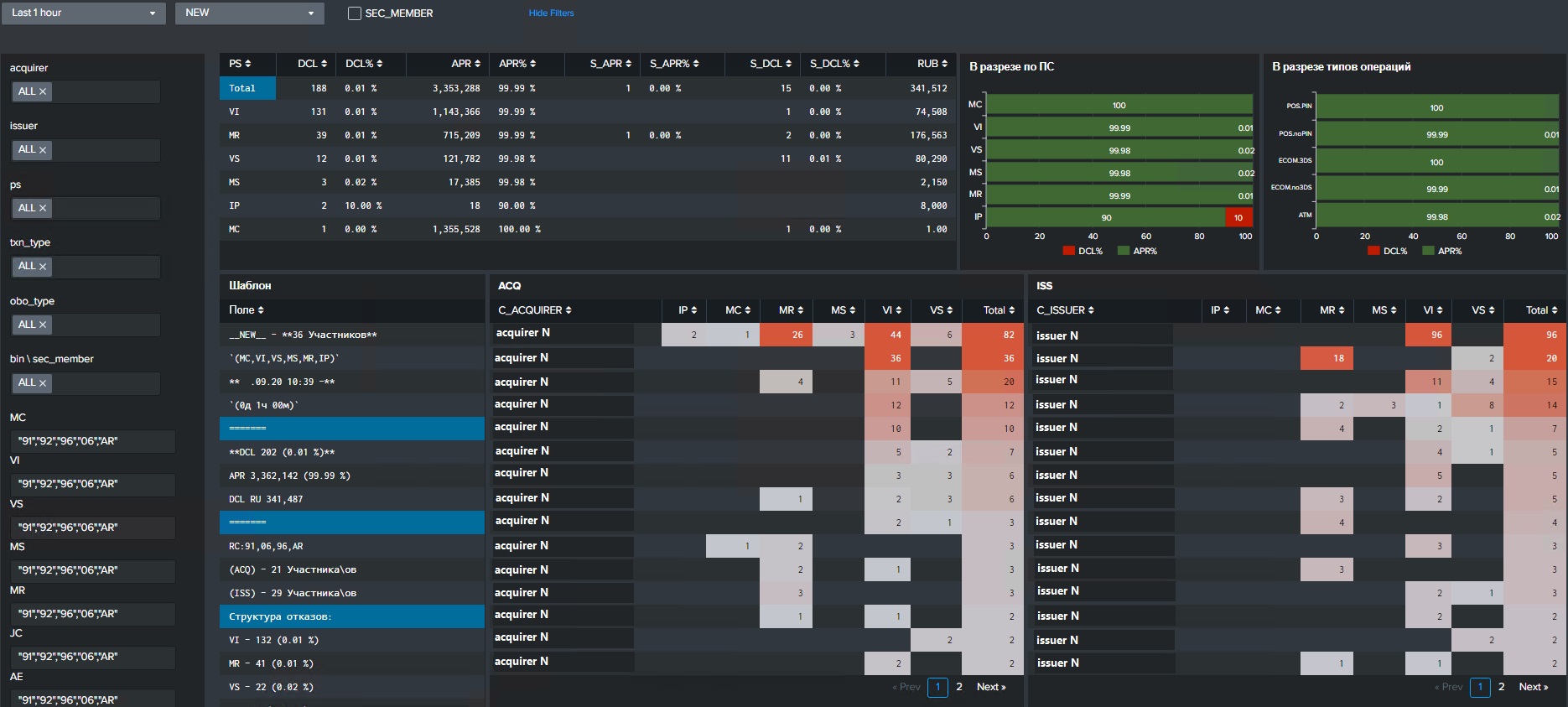
Но действительно важную и сложную аналитическую задачу Splunk
решает в фоновом режиме непрерывное обнаружение аномалий. Постоянно
работающие статистические анализаторы выдают сигналы об аномальном
поведении метрик контролируемого операционного процесса. В основе
лежит алгоритм median absolute deviation, а ключевая особенность
подхода заключается в том, что алгоритм в моменте применяется к
десяткам тысяч метрик, анализируя многомерные временные ряды.
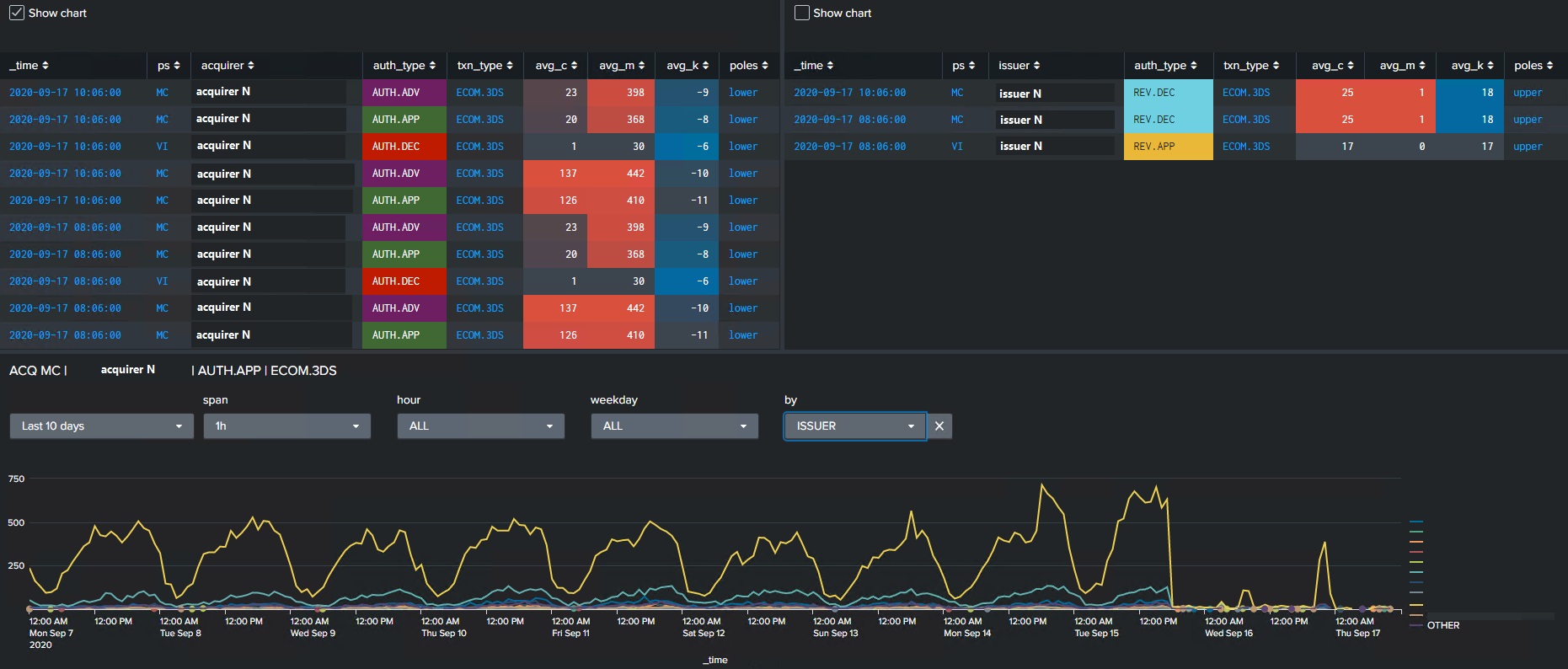
Есть довольно интересные приемы, когда нужно контролировать не
интенсивность сигналов, а окна их отсутствия мы называем этот
подход определение уровня тишины. В его основе также лежат
статистические приемы. По исследуемым метрикам на исторических
данных замеряются максимальные окна отсутствия сигналов внутри
интересующих нас временных диапазонов (сутки или какие-то их
части). Из значений этих окон строится медиана, и дальше мы в
режиме реального времени измеряем уровень тишины. Если он превышает
медиану с определенным коэффициентом, то включается триггер. Такие
же подходы применяются в разных сервисах НСПК, мы отслеживаем
активность участников на предмет получения всего необходимого
объёма данных от них к нам и на качество получения этих данных
конечными точками подключения.
Еще один пример интересного анализа это оценка объёма потерь по
недополученным данным с использованием алгоритма прогнозирования
временного ряда. Представьте ситуацию, когда банк ломается и
перестает отправлять запросы в НСПК. В этом случае на мониторах
видим просадку трафика и нам необходимо оценить количество данных,
которое мы недополучаем, чтобы уведомить об этом участника или
руководство компании (если речь идёт о крупном игроке рынка). В
Splunk есть целое приложение с набором алгоритмов ML (в частности
Forecast time series), которые делают прогноз трафика в системе и
позволяют определить объем потерь.
Алгоритмы прогнозирования временных рядов также используются в
методиках расчёта доступности сервисов. Когда происходит инцидент,
то ключевая метрика (или метрики) производительности сервиса
начинает деградировать, причем деградации бывают двух видов полная
(Рис.1) или частичная (Рис.2). Очевидно, что считать временем
недоступности сервиса весь интервал инцидента при частичной
деградации это неправильно, потому что сервис свою задачу выполнял
(в каком-то процентном отношении). Но деградация была и повлияла на
определённую часть конечных пользователей. Splunk позволяет очень
просто подсчитать область между прогнозом и фактом и
сконвертировать это значение во время полной недоступности
сервиса.
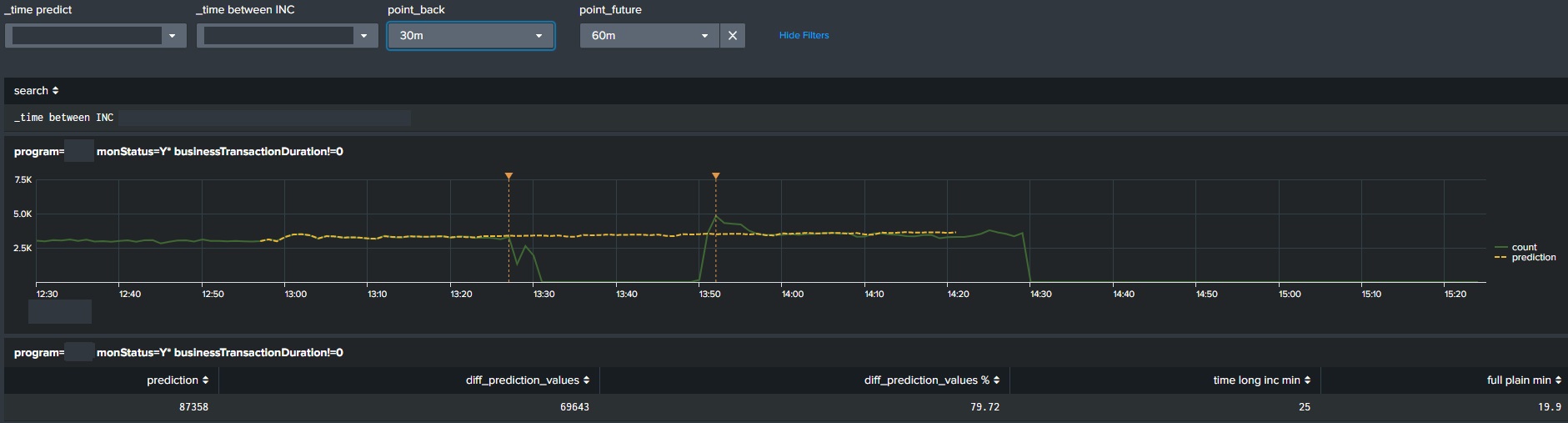
Рис.1
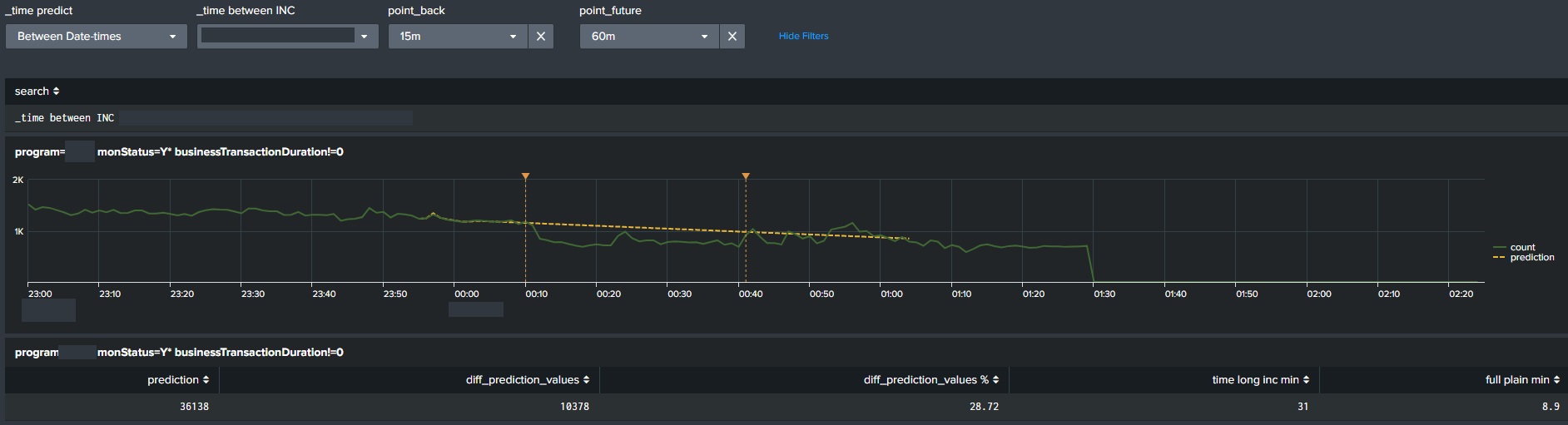
Рис.2
Описанные выше примеры показывают, как быстро и удобно можно делать
сложное в Splunk, но есть с ним и определенные трудности. В паре cо
Splunk работает Elasticsearch, который в стратегическом смысле
видится как альтернатива, а в тактическом смысле имеет определенные
преимущества перед ним. Ещё он выступает в роли резервной системы,
если со Splunk что-то идет не так.
Сначала расскажу про плюсы с точки зрения аналитика и
бизнес-заказчика. Сейчас для меня ключевым преимуществом
Elasticsearch перед Splunk является то, что он умеет делать
обновление документов в индексе. Отсутствие этой возможности в
Splunk порождает на практике ряд трудностей. Например, в сервисе
3-D Secure имеется довольно сложный сценарий прохождения
аутентификационных запросов. За одной бизнес-транзакцией стоит с
десяток событий, предшествующих ей. Чтобы понимать качество
оказания сервиса все события не нужны, только последние те, на
которых конечные пользователи перестали взаимодействовать с
сервисом. Elasticsearch делает обновление документов в индексе по
ключевому полю, что дает на выходе нужный вид данных (последние
статусы) и на порядок меньший объем хранимых данных, следовательно,
быстрее и легче начинают работать статистические выборки. Splunk не
умеет делать обновления записей, такова идеология решения, все
индексируется как отдельные события. Чтобы вернуть только последние
статусы, нужно делать дедупликацию событий по ключевому полю с
сортировкой по времени, что при значительных RPS (количество
запросов в секунду) вычислительно затратно.
Для некоторых сервисов возможность обновления данных крайне важна,
и здесь очевидно преимущество Elasticsearch.
Теперь про недостатки. У Elasticsearch нет гибкого аналитического
языка взаимодействия с данными, такого как SPL в Splunk. Это
ключевая проблема. Elastic предоставляет целую группу языков
запросов (DSL, LQS, SQL, EQL), но все это пока очень далеко от
возможностей SPL. ELK хорош, как инфраструктура сбора, транспорта и
хранения, но мне, как аналитику, нужен язык для работы с
данными.
Какое здесь может быть решение? Внешний framework для аналитики.
Берем Python pandas и пишем в нём любую сложную обработку,
взаимодействуя с Elasticsearch API как с источником данных.
Концепция рабочая, но порог вхождения намного выше чем в случае с
SPL, нужны другие профессиональные навыки для развития и
эксплуатации подобной конструкции.
Когда я писал про альтернативу Splunk, то отметил, что
альтернативой будет ELK++, где первый плюс это аналитика во внешнем
framework. Без этого невозможно решать задачи аналогично тому, как
мы их решаем в Splunk. Вторым плюсом приставки является подписка
платное расширение функциональности, которое существенно усиливает
бесплатный уровень basic. В подписке решаются вопросы ИБ
(интеграция с IDM, ролевая модель доступа), alerting, reporting,
machine learning, расширенный мониторинг стека и управление
pipeline Logstash из Kibana, JDBC\ODBC, cross cluster replication и
т.д. Подписка не снимает первого плюса (аналитика во внешнем
framework), но при несложных аналитических концепциях (не наш
случай) можно обойтись комплектом ELK subscription + BI
Tableau.
В слое хранения и анализа данных та же присутствует Zabbix, который
выполняет роль центральной консоли событий (триггеров) в системе
мониторинга. Как было сказано выше, данные в Zabbix собираются
через собственные агенты и с помощью Logstash, который
взаимодействует с внутренними интерфейсами системы мониторинга и
интерфейсами контролируемых сервисов. Всю активность по триггерам
отслеживает дежурная служба, но для удобства эксплуатации и
поддержки сервисов реализована маршрутизация нотификаций в
корпоративном мессенджере.
Короткий вывод по слою конечных аналитических систем. Вся самая
сложная аналитика делается сейчас в Splunk. Учитывая, что вендор
ушел с российского рынка, мы сосредотачиваем усилия на
альтернативном решении ELK++. Почему же ELK, а не что-то другое?
Ответ в критерии компактности прикладного стека и задачах: Elastic
покрывает все домены обратной связи с сервисом (метрики, логи,
прикладные трассы), он легко масштабируется и конфигурируется,
имеет богатый набор экспортеров данных и плагинов Logstash, что
делает его наиболее универсальным и привлекательным для нас
инструментом.
Интерфейсы пользователя
Пользовательские интерфейсы можно разделить на две части аппаратные
и программные. К аппаратным относятся большие видеостены в
ситуационных центрах НСПК (их у нас два) и отдельные панели,
раскиданные по офисам у руководства в кабинетах, в командах
эксплуатации конкретных сервисов и т.д.
К программным интерфейсам относятся Grafana, Kibana, Splunk, Zabbix
и Telegram. Splunk и Zabbix для дежурной службы являются основными,
Grafana выступает в качестве резерва. Zabbix центральная консоль
событий в системе. Вкладка с триггерами постоянно открыта у каждого
дежурного. В Splunk подготовлены все необходимые визуализации для
анализа ситуаций по любому сервису, также дается возможность всем
линиям работать с данными в режиме ad hoc, так как не всё можно
заранее заложить в подготовленные аналитические панели.
Отдельно хочется сказать про маршрутизацию нотификаций в
мессенджер, поскольку оказалось, что это очень удобная и
эффективная концепция адресной доставки уведомлений по событиям в
системе мониторинга и общего управления инцидентами. Как я писал
ранее, у нас несколько экземпляров систем мониторинга в закрытых
сетевых контурах. Все события, возникающие в Zabbix по разным
сервисам, отстреливают уведомления в офисный контур, откуда всё это
по средствам скрипта Python маршрутизируется в профильные группы
корпмессенджера.
Этот подход сильно сокращает время реакции на инцидент. Было время,
когда дежурная служба передавала информацию вручную. Сейчас первая
линия контролирует, что все нотификации доходят корректно,
отрабатывают инструкции к триггерам (если они определены),
отслеживают поведение бизнес-метрик по сервису, занимаются
коммуникацией между подразделениями компании, связываются с
участниками рынка по инцидентам, эскалируют инциденты на
руководство, взаимодействуют с контрагентами по нарушениям SLA и
т.д.
Заключение
Хотелось бы закончить статью описанием главных качеств инженера SRE
(Site Reliability Engineering). Знакомство с этой концепцией
когда-то меня поразило очень интересная и сильная методология,
снимающая абсолютно все барьеры между разработкой и эксплуатацией.
В своей работе мы стараемся применять важные и полезные для нас
части этой концепции.
Что же это за качества? По версии авторов книги
Site Reliability Engineering. Надежность и безотказность как в
Google это:
- Обратное проектирование
- Статистическое мышление
- Импровизация в сложных\нестандартных ситуациях
Где во всём этом мониторинг? В статистическом мышлении!
Высоконагруженные распределенные системы невозможно мониторить без
этого качества. Десятки, сотни, тысячи хостов и приложений
генерируют о себе какие-то метаданные, понимание которых нельзя
сформировать без техник централизованного сбора и статистики это
как минимум.
Мониторинг современного программного проекта это сам по
себе программный проект
Очень точная формулировка. Техническая и логическая сложность
мониторинга возникает не от того, что нечем заняться, а от того,
что по мере развития задачи становятся всё сложнее. Необходимо
отвечать на эти вызовы, потому что 99.999% доступности не просто
красивая цифра, а тяжёлая работа большого числа специалистов
компании и достичь её можно только максимальной отдачей и
постоянным развитием.

































