
Не так давно в процессе исследования и моделирования общественно-экономических формаций и в свете, не побоюсь этого слова, огромного потока новостей о коррупционных явлениях как в мировых, так и в локальных СМИ, я удивительным образом пришел к интересному умозаключению, которое подвигло меня к написанию данной статьи. Я постараюсь излагать мысли кратко, но емко, прошу не судить строго за стиль. Надеюсь, эта небольшая заметка придется по вкусу тем, кто любит читать что-то интересное за чашечкой кофе.
Все началось с небольшой модели экономических взаимодействий организаций, целью которой было наглядное представление статистически достоверного определения паттерна поведения (стратегии) компаний в развертке их эволюционного состояния. Иными словами я старался смоделировать эволюцию с учетом корреляции между состоянием развития и стратегией игроков в рынке
Маленькие компании ведут себя совершенно не так как большие, но их поведение в рамках соразмерной группы весьма схоже, что показалось мне странным, хотя это совершенно не очевидно с математической точки зрения.

С возрастом при достаточном опыте и детальном понимании процессов складывается определенное мировоззрение, в рамках которого практически все процессы, окружающие нас в повседневной жизни, становятся концептуально однотипными. В какой-то мере отличие между построением сложной информационной системой и чисткой картофеля сводится только к особенностям предметной области, в рамках которой используется порой один и тот же принцип оптимизации. С этой точки зрения, когда за годы жизни привыкаешь к определенной форме мышления, происходит странный эффект абсолютно все наблюдаемое автоматически декомпозируется на отдельные предметные области и связи между ними, и именно опыт позволяет представлять эту топологию в минимально возможной конфигурации (автоматическое стремление к уменьшению уровня сложности).
Именно так происходит при анализе социальных структур и различных схем взаимодействия контрагентов, в частности при анализе бизнес-процессов. Но в этот раз что-то пошло не так
В соответствии с предложенным определением информации Клодом Шенноном прирост информации равен утраченной неопределённости, и в моем случае я столкнулся с тем, что всегда было под носом, но чего я не замечал все эти годы. Разумеется, я не мог просто пройти мимо.
Дело в том, что стратегия оптимизации в замкнутой системе не меняется, если цель ставится абсолютной. Экономика это замкнутая система. Лишь в локальном контексте оптимизация может носить различный характер в зависимости от телеметрии (от параметров и конфигурации системы), но это же утверждение предполагает фундаментальное допущение о том, что экономика представляет собой неопределенность, размеры которой столь велики, относительно размеров предприятия, что условно ее представляют бесконечной. Возможно, я несколько переоцениваю мое представление о видении многих игроков того поля, на котором ведется игра. Мое удивление было основано на том, что многие стратегии, которые я анализировал оказывались контр-продуктивны с точки зрения жизненного цикла предприятий. Но я не понимал, почему?

Представьте себе такую аналогию: допустим, ваша цель выживать в условиях переменчивой и агрессивной среды, пускай это будет засушливая пустыня. У вас есть с собой смартфон, на котором заранее скачаны карты местности с высокой степенью детализации (в хорошем масштабе). Вас все устраивает и вы пересекаете пустыню от источника воды к источнику, прокладывая маршрут, и все идет хорошо, до тех пор, пока по пути вы не встречаете интересные цветущие кактусы. Вы очень быстро понимаете, что это редкое явление (какая-то абстрактная ценность в рамках модели), и вы хотите это запечатлеть на свой смартфон, но быстро обнаруживаете, что вся память забита картами. Парадокс в том, что многие игроки выбирают удалить карты в высоком разрешении, чтобы поместились фоточки цветущего кактуса. На практике это выражается как в форме технического долга, который может быть не столь очевиден, так и в форме деградации анализа больших данных, когда точность намеренно снижается по той или иной причине (наиболее частой из которых является все тот же технический долг в виде архитектурных ограничений на масштабирование, допустим, трудоемкость реализации кластерного анализа данных или перенос логики на оптимизированные вычислители (GPU/TPU/ASIC'и)).
С этой точки зрения процесс эволюции будет казаться вполне закономерным в виде прямой корреляции с совокупным опытом организации, именно как формы уменьшения неопределенности, и, как следствие, уменьшения ошибок при выборе стратегии действий. Но на практике все иначе. И здесь мы подходим к самому интересному.
Для того, чтобы лучше осознать происходящее, я решил декомпозировать на элементарные составляющие само понятие стратегии поведения. В некотором смысле стратегию поведения можно интерпретировать как совокупность действий, обобщенных стремлением к определенной цели. Действия определены выбором. Но чем определен выбор? Как правило выбор определен допустимыми возможностями и оценкой этих возможностей, то есть некоторым множеством, из которого мы вольны выбирать. Если рассмотреть более подробно само это множество, то очевидным образом будет понятно, что оно носит потенциальный характер и в некотором смысле теряет неопределенность в момент выбора, когда выбор становится конкретным одним из....

Но если выбор совершается строго в пользу одного из доступных вариантов, то остальные варианты оказываются нереализованным потенциалом, то есть они не осуществляются как часть стратегии поведения, они так и остаются в фазовом пространстве и не входят в состав причинно-следственной цепи выбора и действий, определяющих стратегию. И здесь мы плавно подходим через определение множества к определению алгоритма совершения выбора. Мы не знаем каков сам алгоритм выбора, но мы видим его следствие, как телеметрию действий по отношению к фазовому пространству возможностей. Иными словами, это представимо функциональной логикой F(P) -> D, где P потенциальное множество выбора, F представляет собой логику с учетом контекста (опыта), а D является следствием выбора, который попадает в контекст логики.
Мы занимаемся этим перманентно, когда читаем, пишем, слушаем, говорим, делаем выбор в пользу спагетти из набора аналогов, или при решении жизненно важных вопросов, зачастую даже автоматически, но тем не менее на основании каких-то причин. Мы постоянно схлопываем фазовое пространство до конкретизированной цепи причинно-следственных связей. Таким образом, все наше поведение фактически сводится к процессу редукции потенциального множества. И это казалось бы весьма обычная штука, нет ничего сложного, но именно это свойство невозможности существования одновременно более одного детерминированного состояния системы при ее измерении (при совершении взаимодействия выбора), приводит нас к интересным последствиям.
Дело в том, что с этой точки зрения понятие выбора ложится в основу самого процесса эволюции. Я намеренно написал выбор в кавычках, так как с этого момента этот термин носит несколько более широкий характер и скорее отображает семантический эквивалент понятию так случилось, то есть понятие выбора раскрывается фразой именно так была детерминирована когерентная суперпозиция состояний (некоторое множество потенциальных состояний фазовое пространство).
На основании процесса выбора подобно процессу кристаллизации или полимеризации в химии, или процесса перехода электрона между орбиталями, эффекта тунеллирования, происходит формирование общественно-экономических формаций, выбора партнеров в отношениях, друзей, построения социальных связей, потенциальных возможностей и т.д. Все это приобретает вид детерминированной системы из потенциально возможных состояний, но дело в том, что любое конкретное состояние отличается от любого потенциального тем, что оно реализовано в качестве выбора, что порождает эффект дискриминации по отношению к нереализованному множеству. Если вы женат, то вы выбрали в качестве супруги ту, которую полюбили, которая оказалась достойной среди прочих равных, но вы тем самым обделили вниманием других, на основании вашего выбора, вашей логики. Когда вы в качестве друзей выбирали определенных людей, вы лишили возможности быть вашими друзьями других людей, даже если вы самый доброжелательный и коммуникабельный человек, вы ограничены ресурсом времени, все люди не смогут быть вашими друзьями чисто физически. И это касается любого выбора.

Я полагаю (на правах исключительно субъективной интерпретации действительности), что понятие выбора отражается также глубоко в системе культурных ценностей, которые так или иначе пронизывают каждого из нас с самого детства, мы получаем и закрепляем некоторые паттерны поведения через импринтинг, даже часть нашей морфологии является следствием выбора в момент формирования ДНК, мы полностью от физической составляющей до ментальной являемся следствием реализации одной конфигурации из множества, и это проявляется в повседневной жизни (на основе эмпирических наблюдений), когда с вами здороваются люди, когда здороваетесь вы с теми, кого вы знаете, так как вы не можете поздороваться со всеми индивидуально, а кричать посреди улицы одновременно всем и никому здравствуйте! будет как минимум странно.
Но причем тут коррупция?
Дело в том, что коррумпированная составляющая по определению, целью которого был весь вышеизложенный текст, является следствием выбора одними людьми определенных решений, которые ущемляют интересы других людей (множества людей), но выбор не может иметь только одну сторону, выбор это всегда реализация только одного состояния из потенциального множества. Среди множества сторонних наблюдателей всегда найдется тот, относительно которого выбор кем-то был совершен в пользу своих людей (факт кумовства) и будет воспринимается как наглая форма ущемления их прав, так как он автоматически становится не своим (не реализованным потенциалом), но каждый субъект наделен программой поведения, которая формирует то, как он детерминирует потенциальное множество выбора F(P) -> D, и эта программа поведения предполагает, что то, что люди называют кумовством и выбор друзей или супруги в основе своей имеет единую природу, а следовательно выбор совершается исключительно субъективно в рамках своей программы поведения, что в глобальном масштабе рождает такую структуру общества, в которой законодательная база фиксирует положения противоречащие понятию выбора, и, фактически, декларирующие ожидание существования в детерминированном виде когерентной суперпозиции состояний, иными словами справедливость как форму равенства.

Неприятными сайд-эффектами таких декларированных положений является порождение клептократии, как формы правления, взяток на местах, выбор в пользу своих, и т.д., либо ортогональная ей форма поведения обструкция (итальянская забастовка) которая предполагает абсолютно строгое выполнение инструкций (намеренную невозможность адаптации по ситуации, что приводит неизбежно к нежелательным последствиям).

Декларированное стремление к невозможной конфигурации системы приводит к формированию мест напряжения, это касается любого общества, любой социальной структуры (от семьи, до корпорации) и является свойством самой структуры, вне зависимости от формы общественно-экономической формации, так как природа этого свойства берет свое начало на значительно более глубоком уровне на уровне самого процесса осуществления выбора.
Все это нивелирует понятие равенства в математически строгом смысле, оставляя термин справедливость лишь сильно контекст-зависимой формой, фактически речевым оборотом по отношению к локальному выбору в рамках заинтересованной группы лиц. Иными словами, выбор коррупционера по отношению к своим является для него и группы заинтересованных лиц субъективно справедливым, а любая форма критики по отношению к субъективному выбору актом агрессии и интерпретируется как попытка нарушить ту самую (изоморфную, контекст-зависимую) справедливость.
Отчасти этим же обуславливается контр-продуктивная форма поведения (помните метафору с пустыней и кактусами), когда карты удаляются, чтобы запечатлеть красивый кактус. Это форма выбора, которая субъективно в рамках ограниченной области видимости сложно организованной социальной структуры приводит к фатальным последствиям для жизненного цикла самой структуры что также является определенной формой коррупции (лат. corruptio подкуп, продажность; порча, разложение; растление).
Как вы считаете, будет ли повышаться степень ошибок в управлении при неизбежном росте уровня сложности систем, обусловленный их эволюцией и ростом?
С этой точки зрения становится очевидным, почему, казавшаяся правильной модель эволюции, основанная на едином принципе оптимизации, на поверку не существует на практике и представляет собой градиент форм и стратегий управления, зачастую губительных Потому что природа формирования стратегии поведения принципиально коррумпирована на основании явления детерминирования когерентной суперпозиции.









 и
и  . Тогда коэффициент
усиления будет равен
. Тогда коэффициент
усиления будет равен
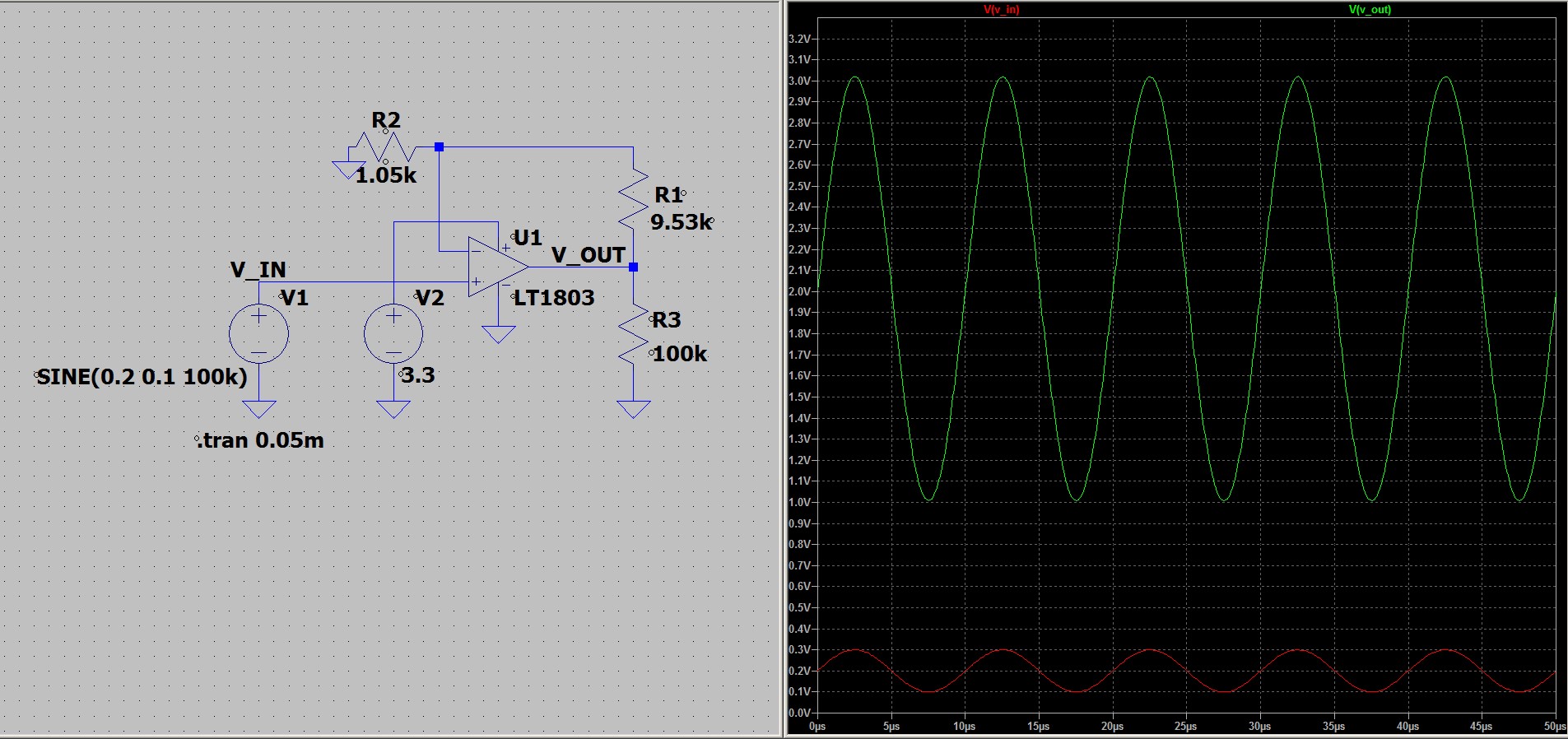
 . При этом мы получим,
что коэффициент усиления будет стремиться к бесконечности. На самом
деле, конечно, это хоть и очень большая, но все-таки конечная
величина, она обычно приводится в документации на микросхему
конкретного операционного усилителя. С другой стороны, величина
выходного напряжения реального операционного усилителя даже при
бесконечно большом коэффициенте усиления не может быть бесконечно
большой: она ограничена напряжением питания микросхемы. На практике
она зачастую даже несколько меньше, за исключением некоторых типов
усилителей, которые отмечены как rail-to-rail. Но в любом случае не
рекомендуется загонять операционные усилители в предельные
состояния: это приводит к насыщению их внутренних выходных
каскадов, нелинейным искажениям и перегрузкам микросхемы. Поэтому
данный предельный случай не несет какой-то практической пользы.
. При этом мы получим,
что коэффициент усиления будет стремиться к бесконечности. На самом
деле, конечно, это хоть и очень большая, но все-таки конечная
величина, она обычно приводится в документации на микросхему
конкретного операционного усилителя. С другой стороны, величина
выходного напряжения реального операционного усилителя даже при
бесконечно большом коэффициенте усиления не может быть бесконечно
большой: она ограничена напряжением питания микросхемы. На практике
она зачастую даже несколько меньше, за исключением некоторых типов
усилителей, которые отмечены как rail-to-rail. Но в любом случае не
рекомендуется загонять операционные усилители в предельные
состояния: это приводит к насыщению их внутренних выходных
каскадов, нелинейным искажениям и перегрузкам микросхемы. Поэтому
данный предельный случай не несет какой-то практической пользы. . Его мы рассмотрим в
следующем разделе.
. Его мы рассмотрим в
следующем разделе.


 напряжение на инвертирующем входе
операционного усилителя.
напряжение на инвертирующем входе
операционного усилителя. , и при заземленном неинвертирующем
входе получаем
, и при заземленном неинвертирующем
входе получаем


 и
и  : их отношение как раз
равно десяти.
: их отношение как раз
равно десяти.













 должно быть больше максимального
входного напряжения с учетом подаваемого на вход напряжения
смещения.
должно быть больше максимального
входного напряжения с учетом подаваемого на вход напряжения
смещения.












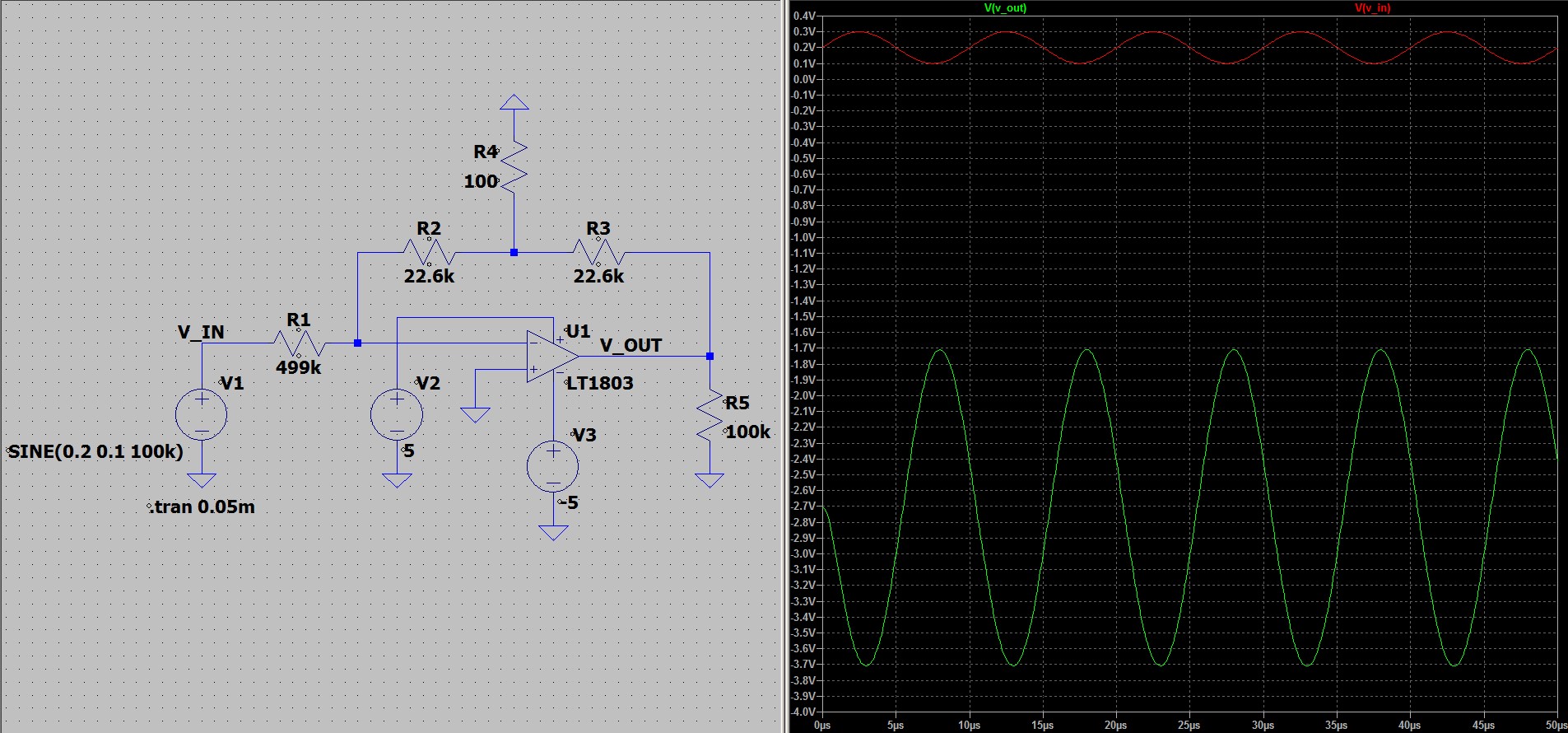
 ,
,  и
и  выберем сведущие номиналы
резисторов из ряда Е96:
выберем сведущие номиналы
резисторов из ряда Е96:

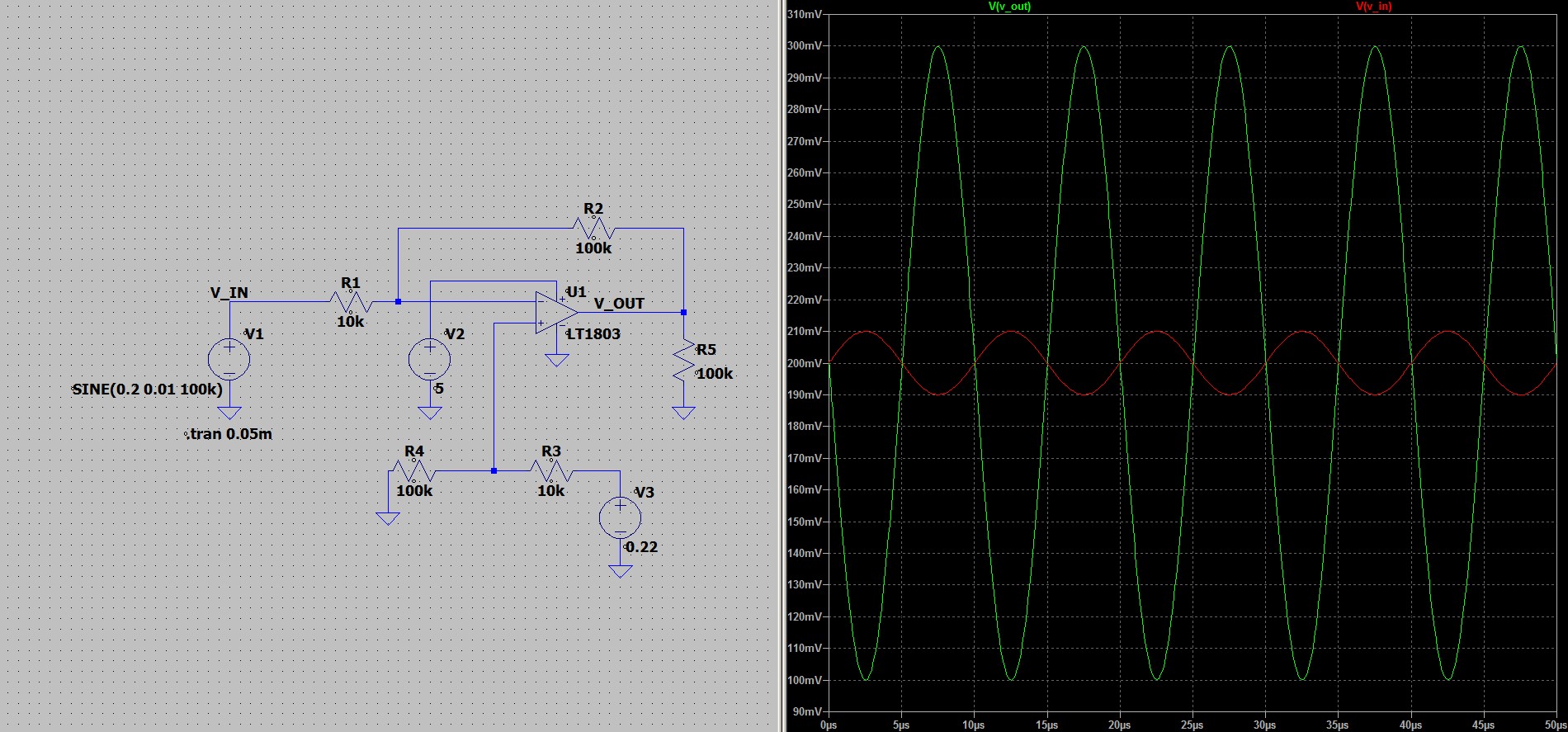
 , а также имеет в начальной части
артефакты, вызванные постепенным появлениями сигналов на
входах.
, а также имеет в начальной части
артефакты, вызванные постепенным появлениями сигналов на
входах.










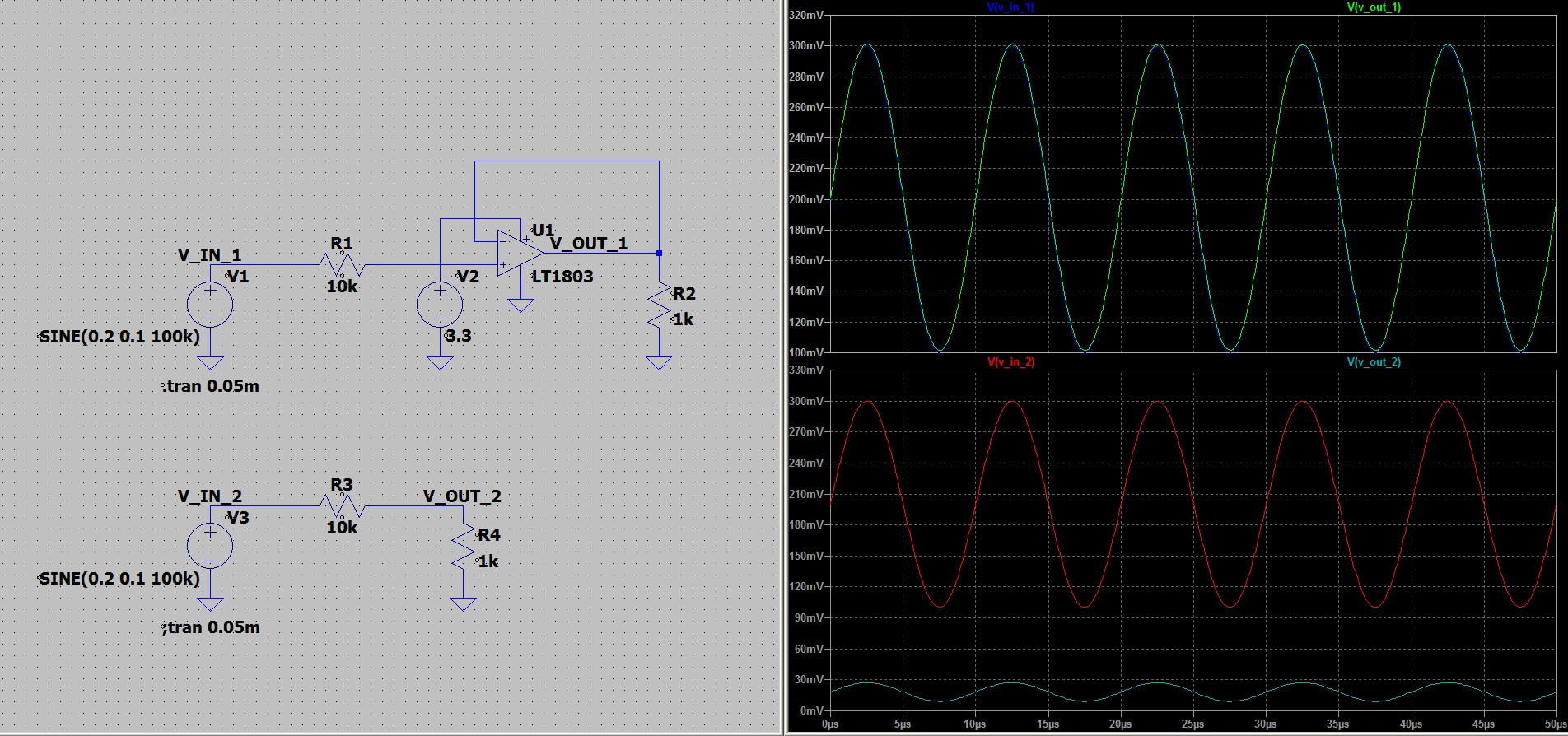
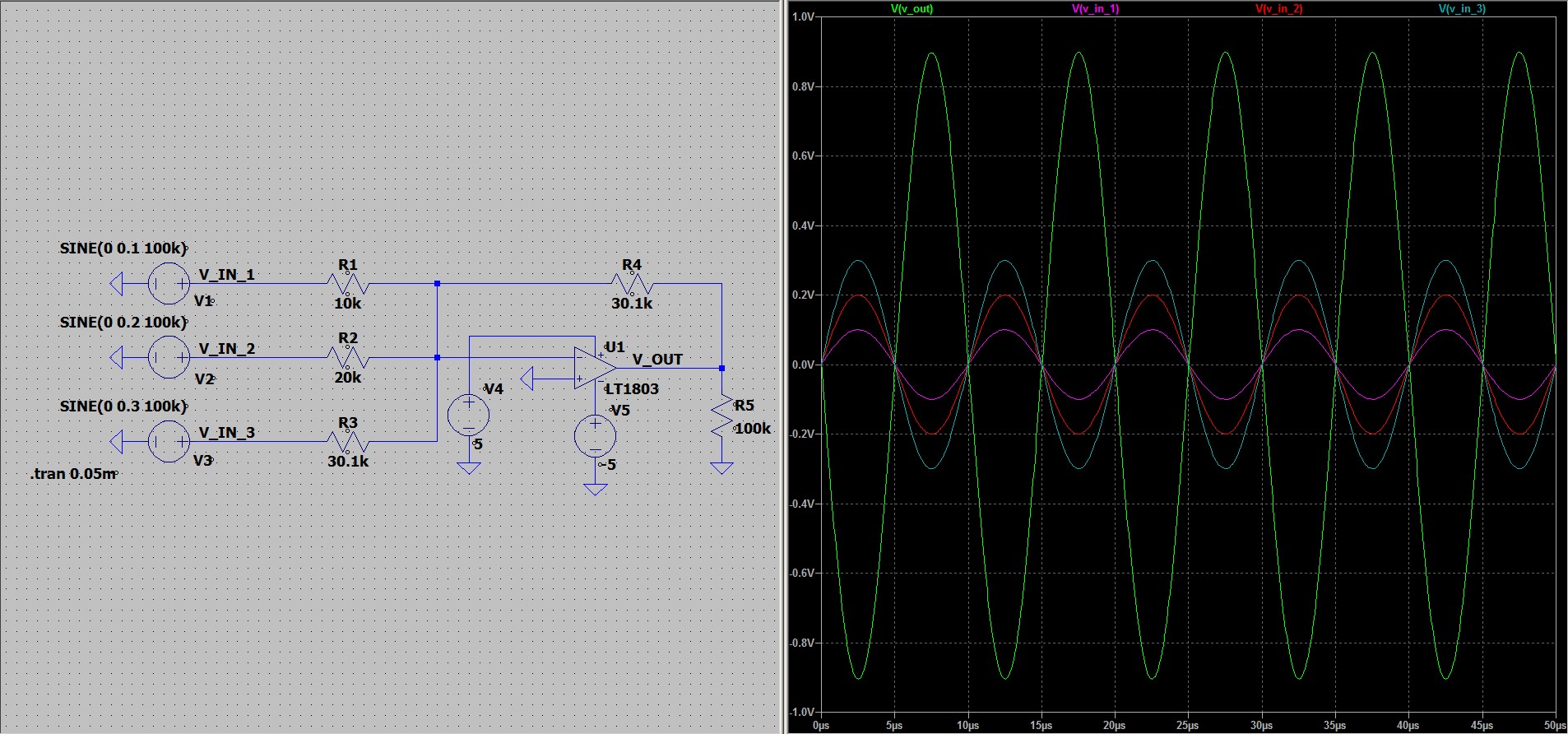
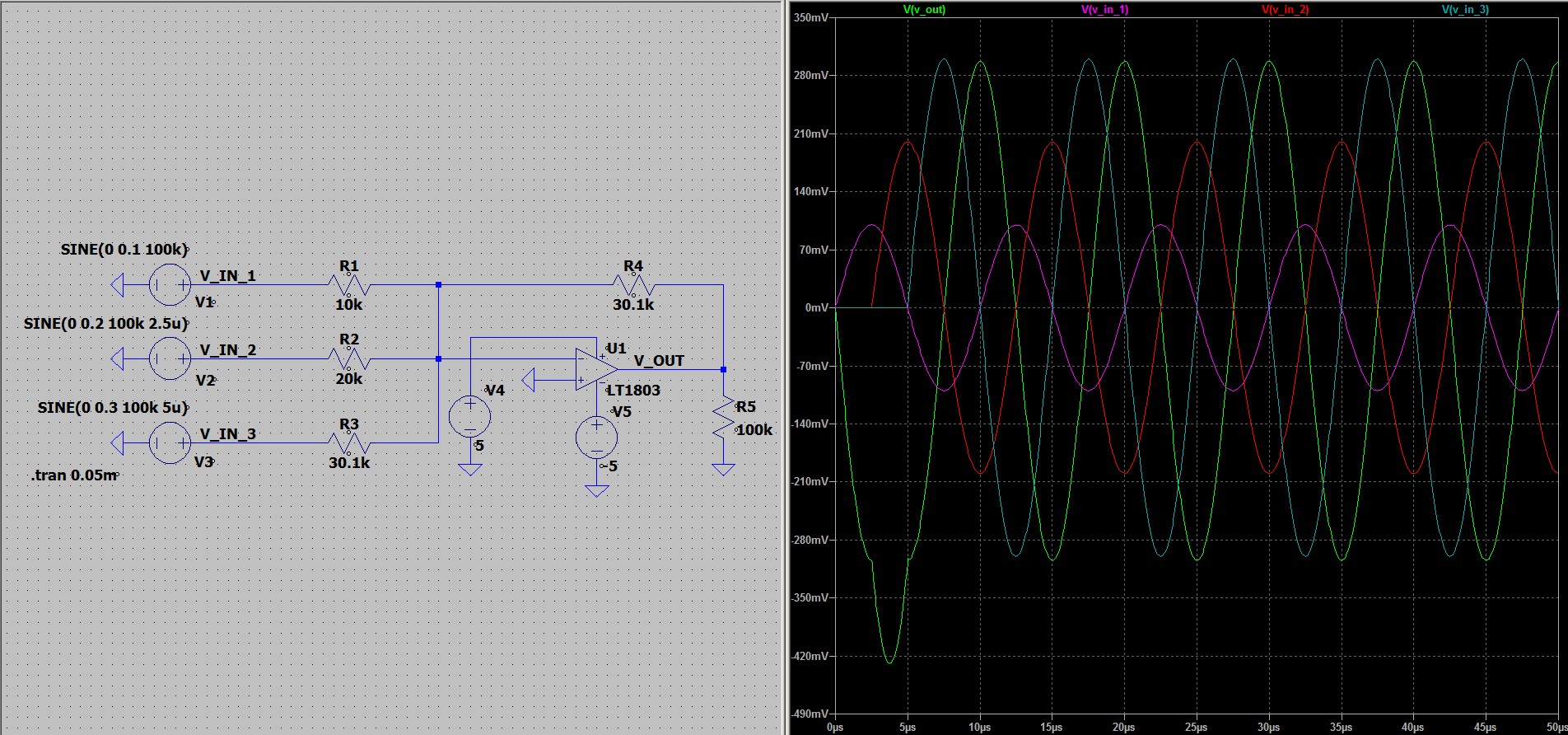
 и
и  в 5 мВ оказалась усиленной в 50
раз и стала 250 мВ.
в 5 мВ оказалась усиленной в 50
раз и стала 250 мВ.









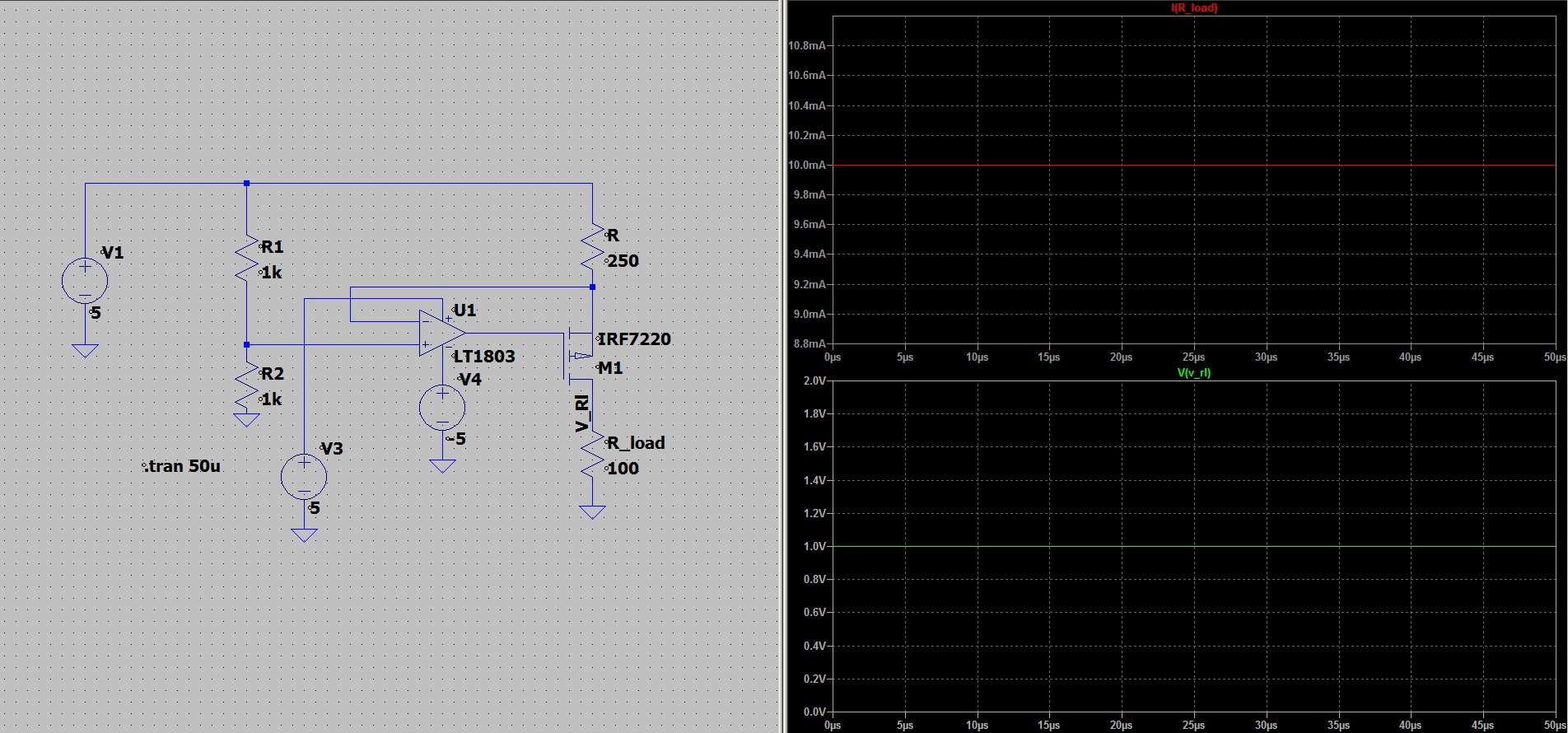
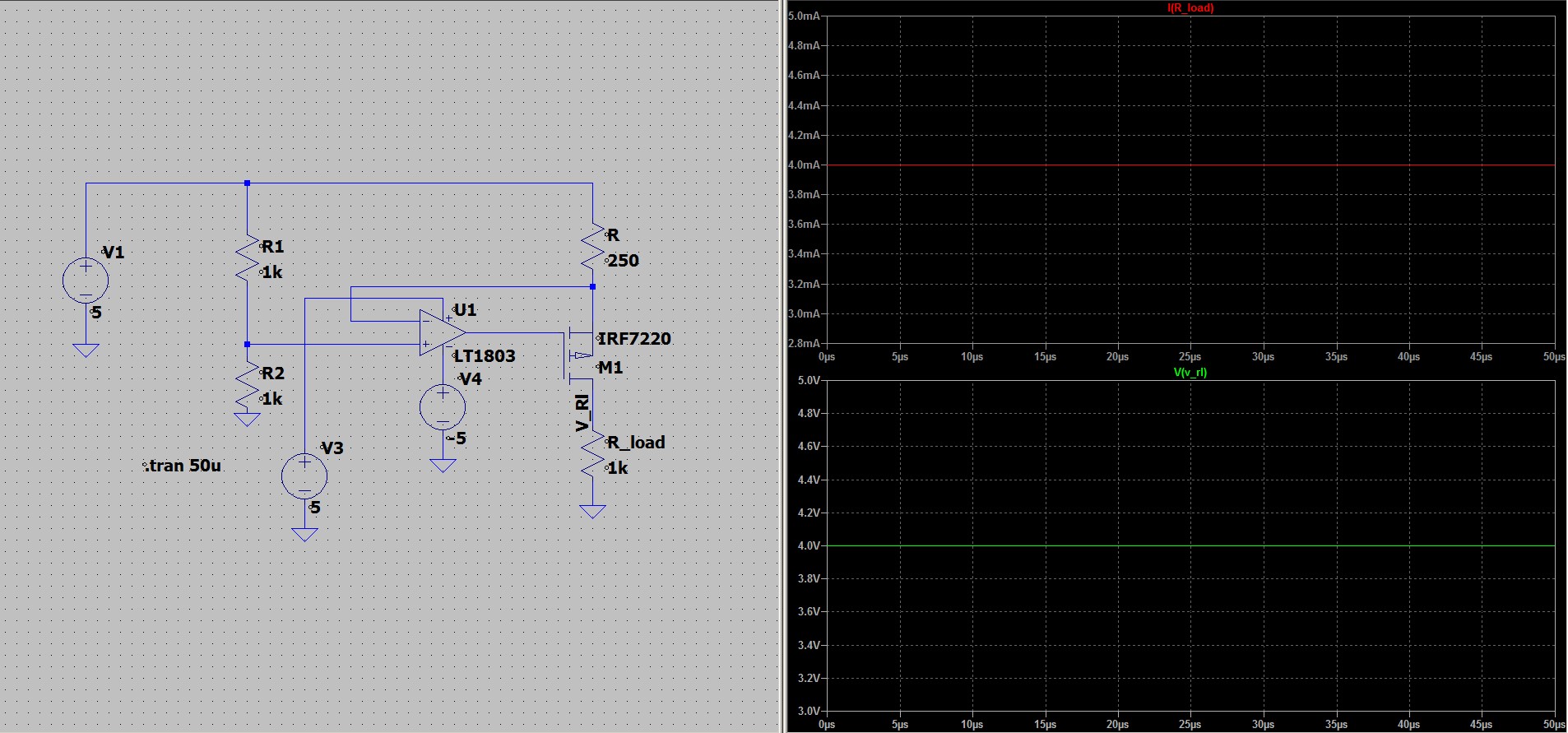
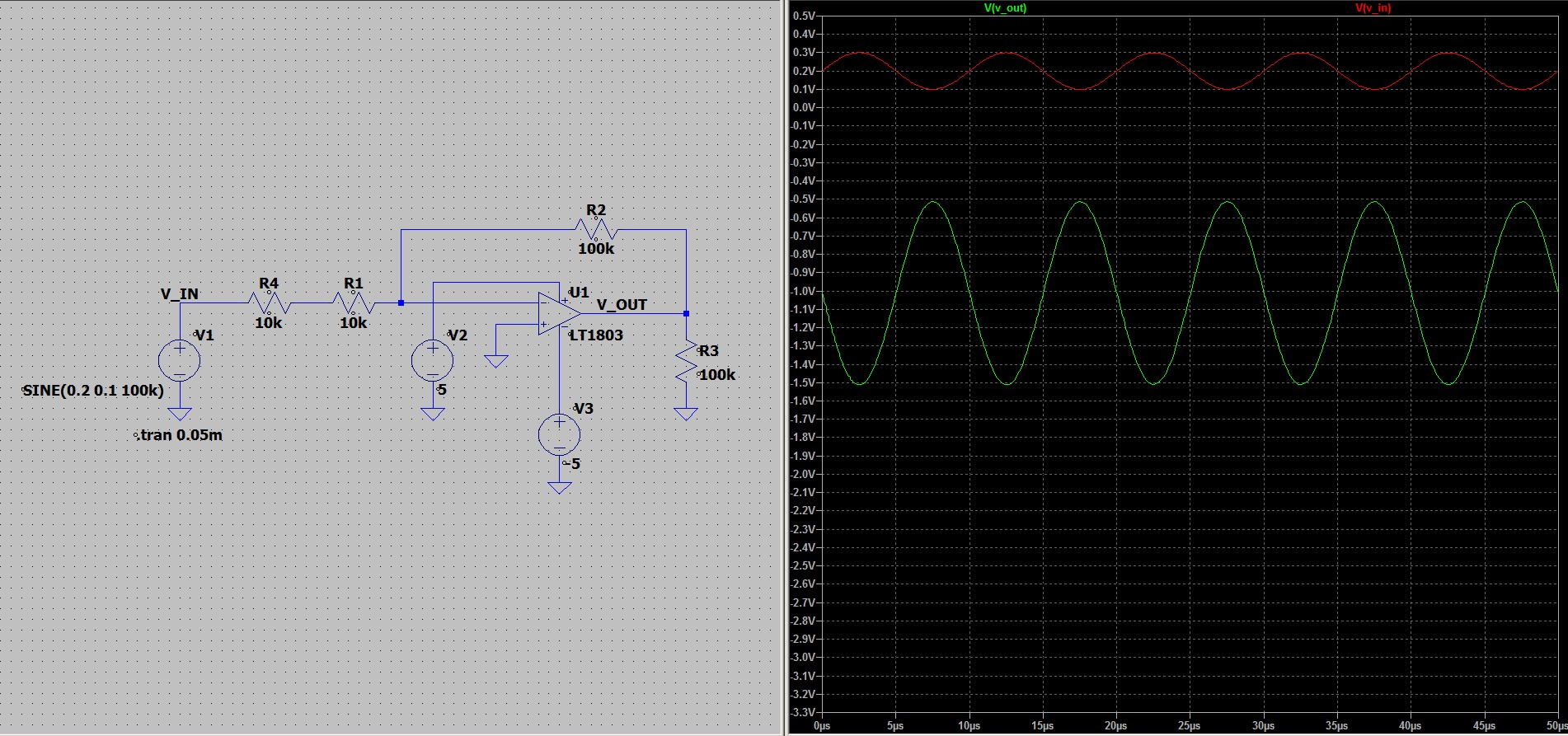
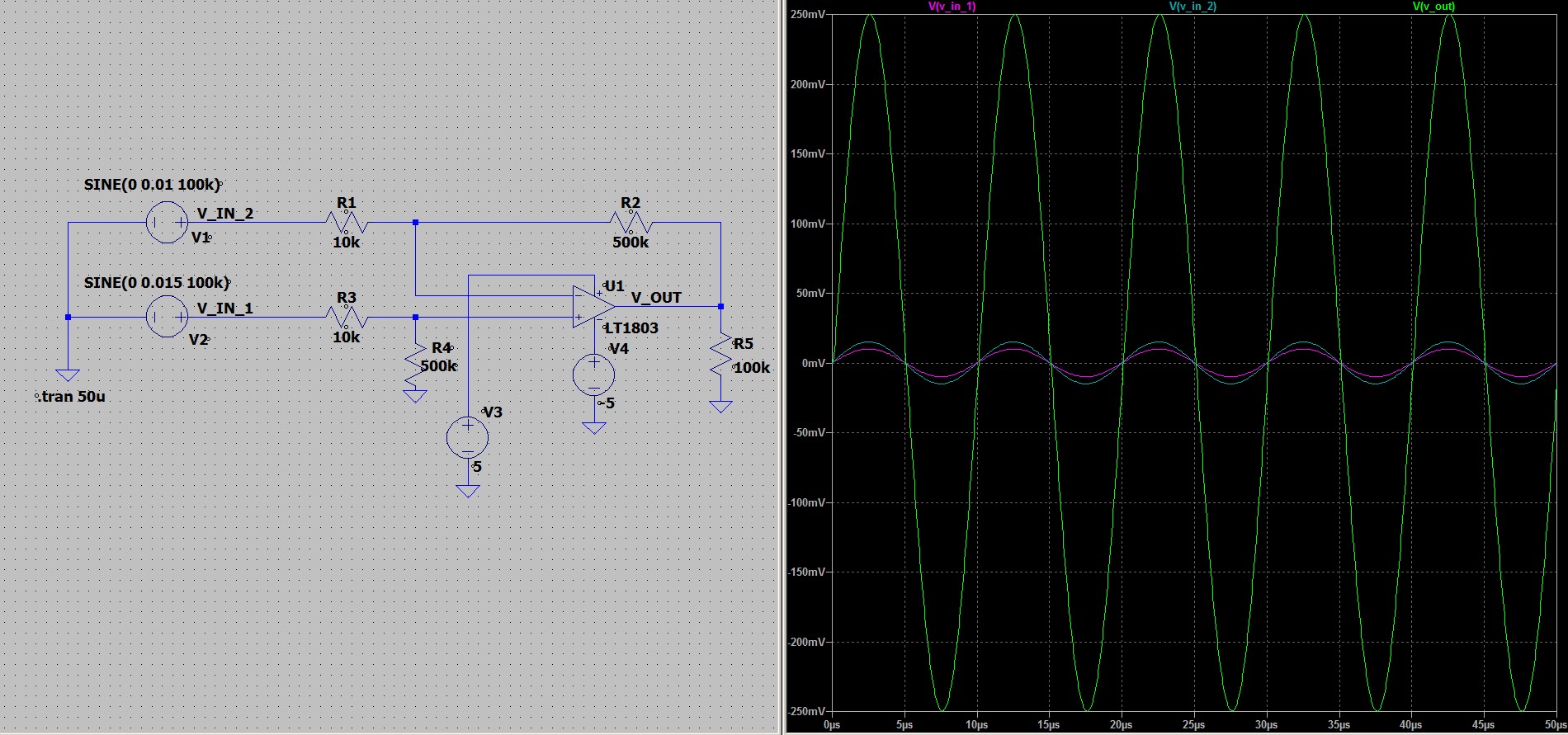
 , в связи с этим оно должно быть
хорошо стабилизированным. Существуют более сложные схемы, которые
позволяют уйти от этой зависимости, но в рамках данной статьи мы их
рассматривать не будем.
, в связи с этим оно должно быть
хорошо стабилизированным. Существуют более сложные схемы, которые
позволяют уйти от этой зависимости, но в рамках данной статьи мы их
рассматривать не будем.






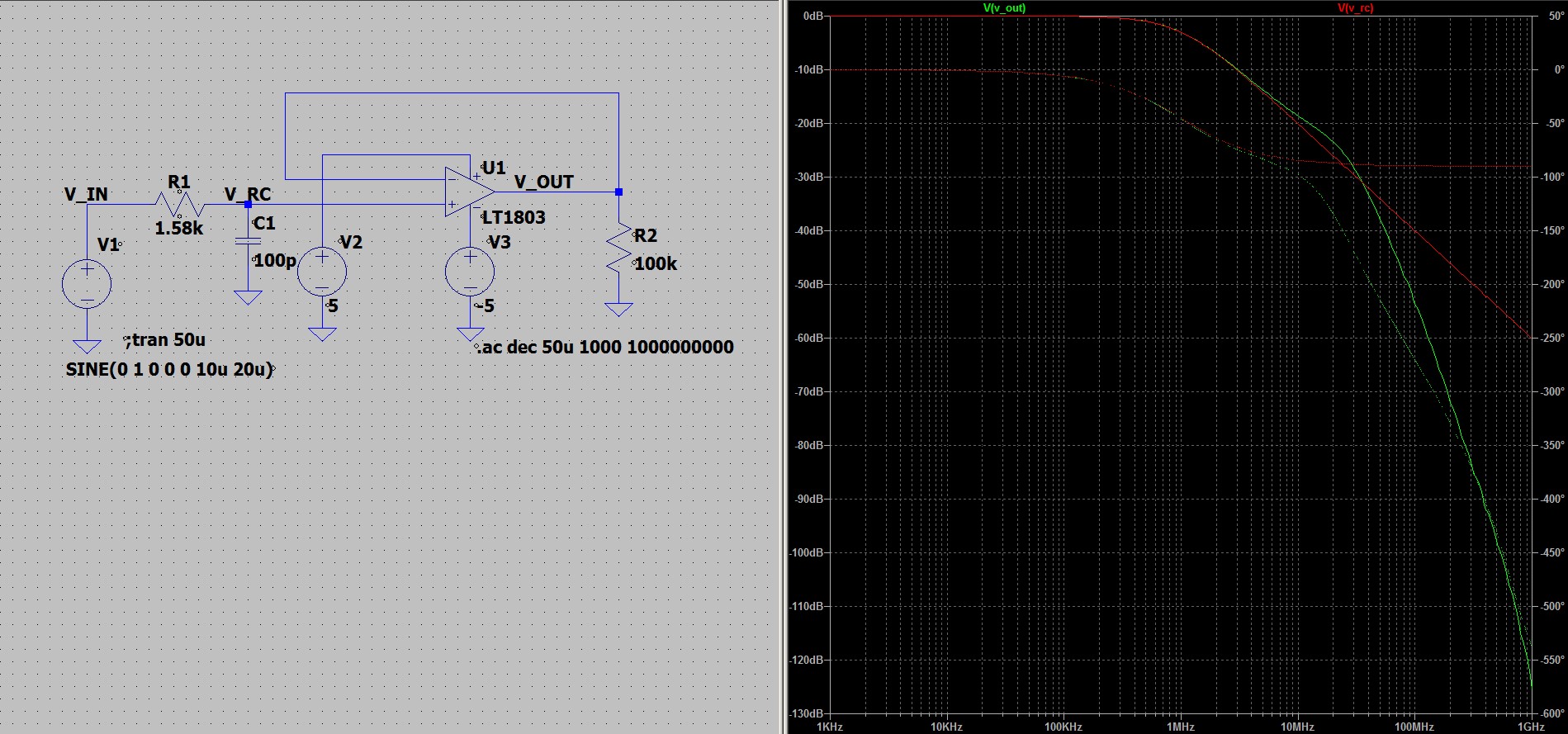
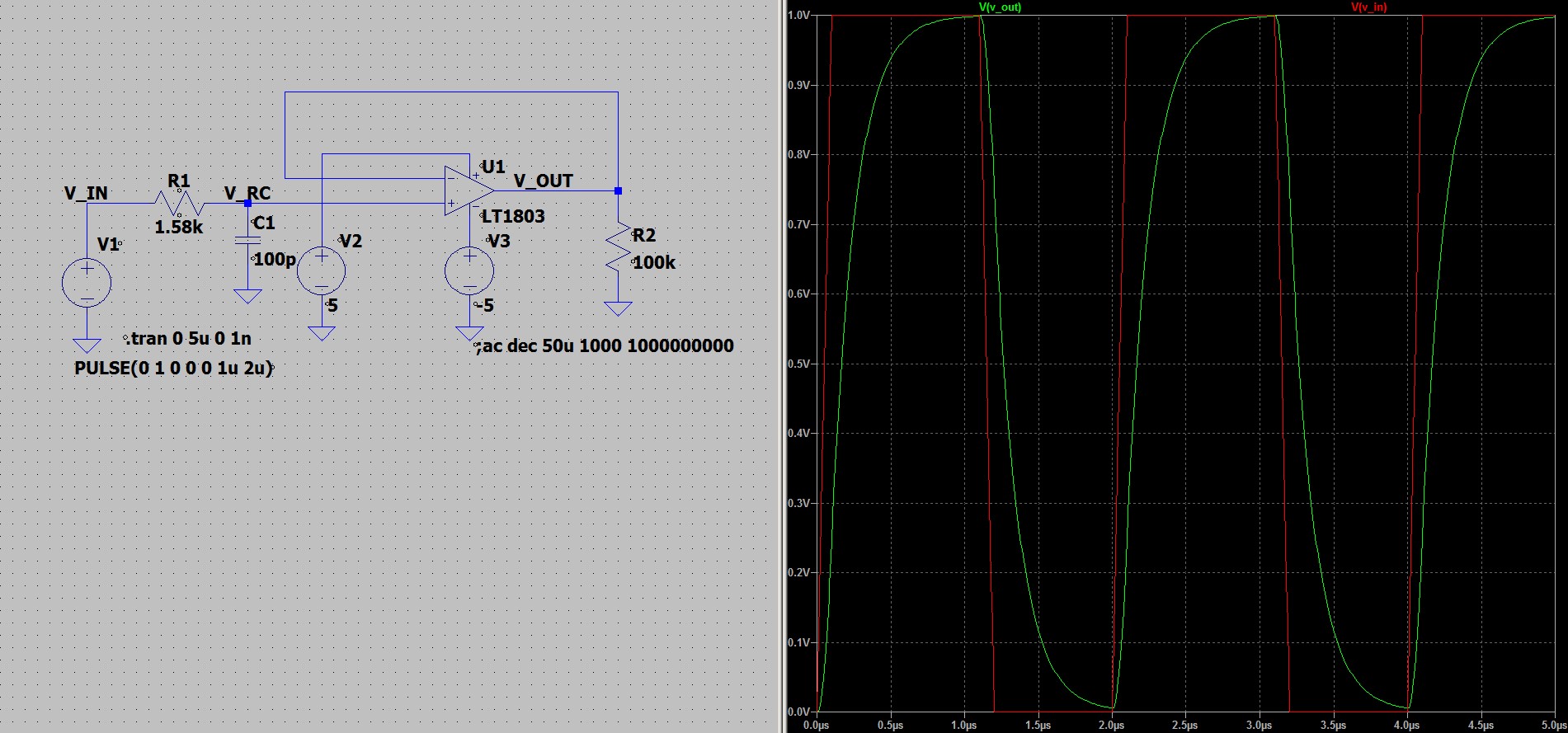

















![флейта Пана [0]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/f95/a6e/345/f95a6e345dd0f05d95dd97cb0eb95776.jpg "флейта Пана [0]") флейта Пана [0]
флейта Пана [0]
![Хранилище бамбуковых трубок на производстве [1]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/d80/bca/8a7/d80bca8a702a6d9d6603cf494e10a835.jpg "Хранилище бамбуковых трубок на производстве [1]") Хранилище бамбуковых трубок на производстве [1]
Хранилище бамбуковых трубок на производстве [1]
![Точение трубок на токарном станке [2]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/ae1/0a3/55f/ae10a355f385a9c99e56c72e27fab0eb.jpg "Точение трубок на токарном станке [2]") Точение трубок на токарном станке [2]
Точение трубок на токарном станке [2]
![Литье пластмасс в пресс-формах [6]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/7e6/480/3c0/7e64803c09c636ed2e8170588bb771b7.jpg "Литье пластмасс в пресс-формах [6]") Литье
пластмасс в пресс-формах [6]
Литье
пластмасс в пресс-формах [6]
 Пример 3д модели
Пример 3д модели
 Фрезерование плоских панфлейт
Фрезерование плоских панфлейт
 Фрезерование изогнутых панфлейт
Фрезерование изогнутых панфлейт
 Неудачный результат фрезерования
Неудачный результат фрезерования
 Нарезка панфлейты поперек
Нарезка панфлейты поперек
 Результаты сборки
Результаты сборки
 Проектирование карбоновых панфлейт
Проектирование карбоновых панфлейт
 Реквизит
для вакуумной инфузии
Реквизит
для вакуумной инфузии
 Результат автоматической расстановки
Результат автоматической расстановки Реализация в дереве
Реализация в дереве
 Стеклопластиковые панфлейты
Стеклопластиковые панфлейты
 Составляющие напечатанных панфлейт
Составляющие напечатанных панфлейт
 Пропаривание: ожидание и реальность
Пропаривание: ожидание и реальность
 Напечатанные панфлейты
Напечатанные панфлейты
 Проект целиком печатаемой панфлейты
Проект целиком печатаемой панфлейты Взрыв-схема
Взрыв-схема
 Сборка трубок с обвязкой и лабиумом
Сборка трубок с обвязкой и лабиумом  Пример целиком напечатанной панфлейты
Пример целиком напечатанной панфлейты
 3д модель
силиконовых пробок
3д модель
силиконовых пробок
 Литье силикона
Литье силикона
 Петли в пробки
Петли в пробки
 Карбоновые трубки
Карбоновые трубки
 Ценные породы древесины
Ценные породы древесины
 Литье металла
Литье металла
 Проект идеальной панфлейты
Проект идеальной панфлейты


























 Схема
распространения туберкулёза
Схема
распространения туберкулёза
 Результаты различных моделей,
реализованных с использованием программы
Результаты различных моделей,
реализованных с использованием программы



 Поведение медленно растущих терранов,
одной из трёх инопланетных рас в StarCraft II, в экосистеме игры
один в один напоминает поведение кактусов.
Поведение медленно растущих терранов,
одной из трёх инопланетных рас в StarCraft II, в экосистеме игры
один в один напоминает поведение кактусов.











 Рисунок 1. Конструкции статорных обмоток
Рисунок 1. Конструкции статорных обмоток
 Рисунок 2. Схема двигател с одной парой
полюсов я в разрезе
Рисунок 2. Схема двигател с одной парой
полюсов я в разрезе
 при
котором вектор потока ротора совпадает по направлению с осью
фазыА(осью обмоткиА).
при
котором вектор потока ротора совпадает по направлению с осью
фазыА(осью обмоткиА).
 -фазные напряжения
-фазные напряжения -потокосцепления
фазных обмоток
-потокосцепления
фазных обмоток -токи
фаз
-токи
фаз -
активное сопротивление фазной обмотки.
-
активное сопротивление фазной обмотки.
 -индуктивность фазных обмоток
-индуктивность фазных обмоток -взаимные индуктивности обмоток
-взаимные индуктивности обмоток -потокосцепления,
наводимые в обмотках магнитом ротора.
-потокосцепления,
наводимые в обмотках магнитом ротора. .
. - индуктивность фазной обмотки,
- индуктивность фазной обмотки, -взаимная индуктивность двух фазных обмоток,
-взаимная индуктивность двух фазных обмоток,
 -
есть не что иное,как наводимая магнитами
-
есть не что иное,как наводимая магнитами
 ),
имеющая единичную амплитуду и повторяющая по форме ЭДС. Для
фазА,В,Собозначим эти функции: обозначим эти функции
),
имеющая единичную амплитуду и повторяющая по форме ЭДС. Для
фазА,В,Собозначим эти функции: обозначим эти функции
 .
.
 -амплитуда
потокосцепления ротора и фазной обмотки
-амплитуда
потокосцепления ротора и фазной обмотки -
скорость вращения поля
-
скорость вращения поля -
скорость вращения ротора
-
скорость вращения ротора -
число пар полюсов двигателя.
-
число пар полюсов двигателя. Рис.
3. Единичные функции форм ЭДС
Рис.
3. Единичные функции форм ЭДС


 -
реактивная мощность обмотки
-
реактивная мощность обмотки -
активная мощность, рассеивающаясяв обмотке
-
активная мощность, рассеивающаясяв обмотке -
мощность,создающая электромагнитный момент.
-
мощность,создающая электромагнитный момент.

 -
электромагнитный момент двигателя
-
электромагнитный момент двигателя - угловая скорость вращения ротора.
- угловая скорость вращения ротора.
 Таблица1. Закон коммутации
Таблица1. Закон коммутации
") Таблица 2. Работа ДПР (определение сектора)
Таблица 2. Работа ДПР (определение сектора)

 - значение тока в фазах.
- значение тока в фазах. Рисунок 4. Система управления моментом БДПТ
Рисунок 4. Система управления моментом БДПТ
 ).
). Рисунок 5. Модель цифровой системы управления
Рисунок 5. Модель цифровой системы управления
 Рисунок 6. Моделирование работы двигателя
Рисунок 6. Моделирование работы двигателя
 Рисунок 7. Часть модели векторного управления.
Рисунок 7. Часть модели векторного управления.
 Рисунок 8. Работа двигателя при векторном управлении
Рисунок 8. Работа двигателя при векторном управлении

 Рисунок 8. Работа двигателя с синусоидальной ЭДС
Рисунок 8. Работа двигателя с синусоидальной ЭДС












 Моделирование численности популяций
нестареющих хищников и жертв.
Моделирование численности популяций
нестареющих хищников и жертв.
 Моделирование численности популяций
хищников и стареющих жертв.
Моделирование численности популяций
хищников и стареющих жертв.













 Светлые кружочки - молодые бактерии,
наполовину черные - старые, полностью черные - мертвые
Светлые кружочки - молодые бактерии,
наполовину черные - старые, полностью черные - мертвые


 Читать далее
Читать далее
 Рис. 1. Вызов команды вставки таблицы
nanoCAD в ленточном интерфейсе и на панели 3D
Рис. 1. Вызов команды вставки таблицы
nanoCAD в ленточном интерфейсе и на панели 3D  Рис. 1.
Рис. 1.
 Рис. 2. Окно создания таблицы nanoCAD
Рис. 2. Окно создания таблицы nanoCAD
 Рис. 3. Создание раздела отчета в таблице nanoCAD
Рис. 3. Создание раздела отчета в таблице nanoCAD
 Рис. 4. Создание раздела данных в
таблице nanoCAD после ячейки А2
Рис. 4. Создание раздела данных в
таблице nanoCAD после ячейки А2
 Рис. 5. Создание раздела данных в
таблице nanoCAD после ячейки А4
Рис. 5. Создание раздела данных в
таблице nanoCAD после ячейки А4
 Рис. 6. Итоговая структура разделов таблицы
Рис. 6. Итоговая структура разделов таблицы
 Рис. 7. Кнопка настройки фильтра объектов
раздела отчета ячейки А2
Рис. 7. Кнопка настройки фильтра объектов
раздела отчета ячейки А2
 Рис. 8. Режим выбора объектов для фильтрации из
набора
Рис. 8. Режим выбора объектов для фильтрации из
набора
 Рис. 9. Выбор объекта для формирования
отчета по геометрическому размеру подшипникового стакана
Рис. 9. Выбор объекта для формирования
отчета по геометрическому размеру подшипникового стакана
 Рис. 10. Кнопка настройки фильтра объектов
раздела отчета ячейки А5
Рис. 10. Кнопка настройки фильтра объектов
раздела отчета ячейки А5
 Рис. 11. Выбор объекта для формирования
отчета по геометрическому размеру крышки стакана
Рис. 11. Выбор объекта для формирования
отчета по геометрическому размеру крышки стакана
 Рис. 12. Выбор объекта для формирования
отчета по геометрическому размеру подшипника
Рис. 12. Выбор объекта для формирования
отчета по геометрическому размеру подшипника
 Рис. 13. Быстрая активация команды вызова
окна построителя выражений для ячейки А2
Рис. 13. Быстрая активация команды вызова
окна построителя выражений для ячейки А2
 Рис. 14. Окно построителя выражений
Рис. 14. Окно построителя выражений
 Рис. 15. Поиск выражения по имени
свойства параметрического размера
Рис. 15. Поиск выражения по имени
свойства параметрического размера
 Рис. 16. Поиск выражения по имени
свойства параметрического объекта
Рис. 16. Поиск выражения по имени
свойства параметрического объекта
 Рис. 17. Итоговый результат формирования таблицы
Рис. 17. Итоговый результат формирования таблицы
 Рис. 18. Установка разделителя страниц
перед ячейкой А4
Рис. 18. Установка разделителя страниц
перед ячейкой А4
 Рис. 19. Установка разделителя страниц
перед ячейкой А7.
Рис. 19. Установка разделителя страниц
перед ячейкой А7.
 Рис.
20. Выделенная таблица nanoCAD
Рис.
20. Выделенная таблица nanoCAD
 Рис. 21. Расположение страниц таблицы в одну строку
Рис. 21. Расположение страниц таблицы в одну строку
 Рис. 22. Активация режима быстрого
редактирования таблицы
Рис. 22. Активация режима быстрого
редактирования таблицы
 Рис. 23. Результат внесения изменений в
режиме быстрого редактирования
Рис. 23. Результат внесения изменений в
режиме быстрого редактирования
 Рост клеточной структуры
Рост клеточной структуры
 Рост
аксона
Рост
аксона
 Рис. 1. Вызов команды управления вкладками
на панели ЕСКДСтандартные и в ленточном интерфейсе
Рис. 1. Вызов команды управления вкладками
на панели ЕСКДСтандартные и в ленточном интерфейсе
 Рис. 2. Открытие/закрытие вкладки База элементов
Рис. 2. Открытие/закрытие вкладки База элементов
 Рис. 3. Вызов вкладки База элементов в
классическом варианте интерфейса
Рис. 3. Вызов вкладки База элементов в
классическом варианте интерфейса
 Рис. 4. Вкладка базы элементов nanoCAD Механика
Рис. 4. Вкладка базы элементов nanoCAD Механика
 Рис. 5. Путь до раздела с шариковыми подшипниками
Рис. 5. Путь до раздела с шариковыми подшипниками
 Рис. 6. Кнопка включения отображения
3D-моделей при вставке деталей избазы nanoCAD Механика
Рис. 6. Кнопка включения отображения
3D-моделей при вставке деталей избазы nanoCAD Механика
 Рис. 7. Выбор подшипника ГОСТ 832-78 Тип
236000 из базы nanoCADМеханика
Рис. 7. Выбор подшипника ГОСТ 832-78 Тип
236000 из базы nanoCADМеханика
 Рис. 8.
Параметры подшипника
Рис. 8.
Параметры подшипника
 Рис. 9. Инструменты 3D-зависимостей на
панели 3D и в ленточном интерфейсе
Рис. 9. Инструменты 3D-зависимостей на
панели 3D и в ленточном интерфейсе
 Рис. 10. Скрытие объекта
Рис. 10. Скрытие объекта
 Рис. 11. Зависимость 3D вставка на панели
3D и в ленточном интерфейсе
Рис. 11. Зависимость 3D вставка на панели
3D и в ленточном интерфейсе
 Рис. 12. Выбор окружности подшипника для
указания 3D-зависимости Вставка
Рис. 12. Выбор окружности подшипника для
указания 3D-зависимости Вставка
 Рис. 13. Выбор окружности стакана для
создания 3D-зависимости Вставка
Рис. 13. Выбор окружности стакана для
создания 3D-зависимости Вставка
 Рис. 14. Изменение направления векторов нормали
Рис. 14. Изменение направления векторов нормали
 Рис. 15. Включение отображения объектов в
Истории 3D Построений
Рис. 15. Включение отображения объектов в
Истории 3D Построений
 Рис. 16. Выбор окружности крышки для
указания 3D-зависимости Вставка
Рис. 16. Выбор окружности крышки для
указания 3D-зависимости Вставка
 Рис. 17. Выбор второй окружности стакана
для указания 3D-зависимости Вставка
Рис. 17. Выбор второй окружности стакана
для указания 3D-зависимости Вставка
 Рис. 18. Выбор окружностей при указании
3D-зависимости Вставка дляотверстий крышки и стакана.
Рис. 18. Выбор окружностей при указании
3D-зависимости Вставка дляотверстий крышки и стакана.
 Рис. 19. Вызов команды Секущая плоскость
на панели 2D виды ивленточном интерфейсе
Рис. 19. Вызов команды Секущая плоскость
на панели 2D виды ивленточном интерфейсе
 Рис. 20. Выбор секущей плоскости в окне
История 3D Построений
Рис. 20. Выбор секущей плоскости в окне
История 3D Построений
 Рис. 21. Включение/отключение отображения
псевдоразреза в свойствах секущей плоскости
Рис. 21. Включение/отключение отображения
псевдоразреза в свойствах секущей плоскости
 Рис. 22.
Псевдоразрез сборки
Рис. 22.
Псевдоразрез сборки
 Рис. 23. Скрытие объекта секущей плоскости
в Истории 3D Построений
Рис. 23. Скрытие объекта секущей плоскости
в Истории 3D Построений
 Рис. 24. Редактирование сборки при помощи
Менеджера параметров
Рис. 24. Редактирование сборки при помощи
Менеджера параметров
 Рис. 25. Результат редактирования сборки
после указания радиуса подшипника
Рис. 25. Результат редактирования сборки
после указания радиуса подшипника
 Рис. 26. Поиск длины перекрытия заплечика и
подшипника
Рис. 26. Поиск длины перекрытия заплечика и
подшипника
 Рис. 27. Вызов команды анализа перекрытий
на панели 3D и в ленточном интерфейсе
Рис. 27. Вызов команды анализа перекрытий
на панели 3D и в ленточном интерфейсе
 Рис. 28.
Отображение перекрытий
Рис. 28.
Отображение перекрытий
 Рис. 29. Редактирование параметров
3D-зависимостей
Рис. 29. Редактирование параметров
3D-зависимостей Рис. 30.
Разнесенный вид сборки
Рис. 30.
Разнесенный вид сборки