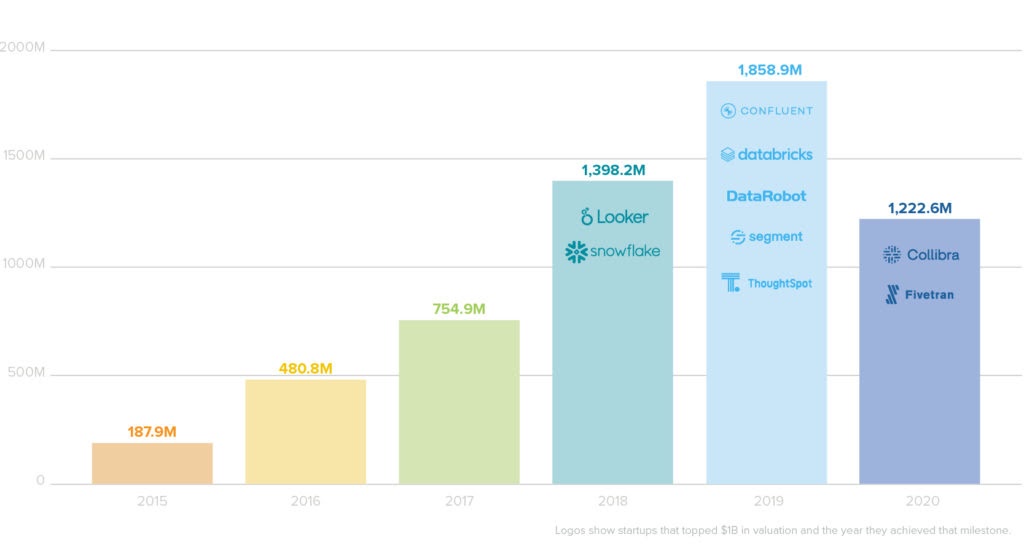
Эта статья является заключительной в серии о применении архитектурного шаблона MVI в Kotlin Multiplatform. В предыдущих двух частях (часть 1 и часть 2) мы вспомнили, что такое MVI, создали общий модуль Kittens для загрузки изображений котиков и интегрировали его в iOS- и Android-приложения.
В этой части мы покроем модуль Kittens модульными и интеграционными тестами. Мы узнаем о текущих ограничениях тестирования в Kotlin Multiplatform, разберёмся, как их преодолеть и даже заставить работать в наших интересах.
Обновлённый пример проекта доступен на нашем GitHub.
Пролог
Нет никаких сомнений в том, что тестирование важный этап в разработке программного обеспечения. Конечно, оно замедляет процесс, но при этом:
- позволяет проверить крайние случаи, которые сложно поймать
вручную;
- уменьшает шанс регресса при добавлении новых функций,
исправлении ошибок и рефакторинге;
- заставляет декомпозировать и структурировать код.
Последний пункт на первый взгляд может показаться недостатком, потому как отнимает время. Однако это делает код более читаемым и приносит пользу в долгосрочной перспективе.
Indeed, the ratio of time spent reading versus writing is well over 10 to 1. We are constantly reading old code as part of the effort to write new code. ...[Therefore,] making it easy to read makes it easier to write. Robert C. Martin, Clean Code: A Handbook of Agile Software Craftsmanship
Kotlin Multiplatform расширяет возможности тестирования. Эта технология добавляет одну важную особенность: каждый тест автоматически выполняется на всех поддерживаемых платформах. Если поддерживаются, например, только Android и iOS, то количество тестов можно умножить на два. И если в какой-то момент добавляется поддержка ещё одной платформы, то она автоматически становится покрытой тестами.
Тестирование на всех поддерживаемых платформах важно, потому что могут быть различия в поведении кода. Например, у Kotlin/Native особенная модель памяти, Kotlin/JS тоже иногда даёт неожиданные результаты.
Прежде чем идти дальше, стоит упомянуть о некоторых ограничениях тестирования в Kotlin Multiplatform. Самое большое из них это отсутствие какой-либо библиотеки моков для Kotlin/Native и Kotlin/JS. Это может показаться большим недостатком, но я лично считаю это преимуществом. Мне довольно трудно давалось тестирование в Kotlin Multiplatform: приходилось создавать интерфейсы для каждой зависимости и писать их тестовые реализации (fakes). На это уходило много времени, но в какой-то момент я понял, что трата времени на абстракции это инвестиция, которая приводит к более чистому коду.
Я также заметил, что последующие модификации такого кода требуют меньше времени. Почему так? Потому что взаимодействие класса с его зависимостями не прибито гвоздями (моками). В большинстве случаев достаточно просто обновить их тестовые реализации. Нет необходимости углубляться в каждый тестовый метод, чтобы обновить моки. В результате я перестал использовать библиотеки моков даже в стандартной Android-разработке. Я рекомендую прочитать следующую статью: "Mocking is not practical Use fakes" (автор Pravin Sonawane).
План
Давайте вспомним, что у нас есть в модуле Kittens и что нам стоит протестировать.
-
KittenStore основной компонент модуля. Его реализация
KittenStoreImpl содержит бОльшую часть бизнес-логики. Это
первое, что мы собираемся протестировать.
-
KittenComponent фасад модуля и точка интеграции всех внутренних
компонентов. Мы покроем этот компонент интеграционными
тестами.
-
KittenView публичный интерфейс, представляющий UI, зависимость
KittenComponent.
-
KittenDataSource внутренний интерфейс для доступа к Сети,
который имеет платформенно-зависимые реализации для iOS и
Android.
Для лучшего понимания структуры модуля приведу его UML-диаграмму:

План следующий:
- Тестирование KittenStore
- Создание тестовой реализации KittenStore.Parser
- Создание тестовой реализации KittenStore.Network
- Написание модульных тестов для KittenStoreImpl
- Создание тестовой реализации KittenStore.Parser
- Тестирование KittenComponent
- Создание тестовой реализации KittenDataSource
- Создание тестовой реализации KittenView
- Написание интеграционных тестов для KittenComponent
- Создание тестовой реализации KittenDataSource
- Запуск тестов
- Выводы
Модульное тестирование KittenStore
Интерфейс KittenStore имеет свой класс реализации KittenStoreImpl. Именно его мы и собираемся тестировать. Он имеет две зависимости (внутренние интерфейсы), определённые прямо в самом классе. Начнём с написания тестовых реализаций для них.
Тестовая реализация KittenStore.Parser
Этот компонент отвечает за сетевые запросы. Вот как выглядит его интерфейс:
TestKittenStoreNetwork имеет хранилище строк (как и настоящий сервер) и может их генерировать. По каждому запросу текущий список строк кодируется в одну строку. Если свойство images равно нулю, то Maybe просто завершится, что должно рассматриваться как ошибка.
Мы также использовали TestScheduler. У этого планировщика есть одна важная функция: он замораживает все поступающие задачи. Таким образом, оператор observeOn, используемый вместе с TestScheduler, будет замораживать нисходящий поток, а также все данные, проходящие через него, прямо как в реальной жизни. Но в то же время многопоточность не будет задействована, что упрощает тестирование и делает его надёжнее.
Кроме того, TestScheduler имеет специальный режим ручной обработки, который позволит нам моделировать сетевые задержки.
Тестовая реализация KittenStore.Parser
Этот компонент отвечает за разбор ответов от сервера. Вот его интерфейс:
Как и в случае с Network, используется TestScheduler для замораживания подписчиков и проверки их совместимости с моделью памяти Kotlin/Native. Ошибки обработки ответов моделируются, если входная строка пуста.
Модульные тесты для KittenStoreImpl
Теперь у нас есть тестовые реализации всех зависимостей. Пришло время модульных тестов. Все модульные тесты можно найти в репозитории, здесь я только приведу инициализацию и несколько самих тестов.
Первый шаг создать экземпляры наших тестовых реализаций:
Теперь можно провести несколько тестов. KittenStoreImpl должен загружать изображения сразу после создания. Это означает, что должен быть выполнен сетевой запрос, его ответ должен быть обработан, а состояние должно быть обновлено с новым результатом.
Этапы теста:
- сгенерировать исходные изображения;
- создать экземпляр KittenStoreImpl;
- сгенерировать новые изображения;
- отправить Intent.Reload;
- убедиться, что состояние содержит новые изображения.
И наконец давайте проверим следующий сценарий: когда в состоянии установлен флаг isLoading во время загрузки изображений.
Есть две зависимости: KittenDataSource и KittenView. Нам понадобятся тестовые реализации для них, прежде чем мы сможем начать тестирование.
Для полноты картины на этой диаграмме показан поток данных внутри модуля:

Тестовая реализация KittenDataSource
Этот компонент отвечает за сетевые запросы. У него есть отдельные реализации для каждой платформы, и нам нужна ещё одна реализация для тестов. Вот как выглядит интерфейс KittenDataSource:
Как и раньше, мы генерируем разные списки строк, которые кодируются в массив JSON при каждом запросе. Если изображения не сгенерированы или аргументы запроса неверные, Maybe просто завершится без ответа.
Для формирования JSON-массива используется библиотека kotlinx.serialization. Кстати, тестируемый KittenStoreParser использует её же для декодирования.
Тестовая реализация KittenView
Это последний компонент, для которого нам нужна тестовая реализация, прежде чем мы сможем начать тестирование. Вот его интерфейс:
Нам просто нужно запоминать последнюю принятую модель это позволит проверить правильность отображаемой модели. Мы также можем отправлять события от имени KittenView с помощью метода dispatch(Event), который объявлен в наследуемом классе AbstractMviView.
Интеграционные тесты для KittenComponent
Полный набор тестов можно найти в репозитории, здесь я приведу лишь несколько самых интересных.
Как и раньше, давайте начнём с создания экземпляров зависимостей и инициализации:
Теперь мы можем написать несколько тестов. Давайте сначала проверим главный сценарий, чтобы убедиться, что при запуске изображения загружаются и отображаются:
Этапы:
- сгенерировать исходные ссылки на изображения;
- создать и запустить KittenComponent;
- сгенерировать новые ссылки;
- отправить Event.RefreshTriggered от имени KittenView;
- убедиться, что новые ссылки достигли TestKittenView.
Запуск тестов
Чтобы запустить все тесты, нам нужно выполнить следующую Gradle-задачу:
./gradlew :shared:kittens:build
Это скомпилирует модуль и запустит все тесты на всех поддерживаемых платформах: Android и iosx64.
А вот JaCoCo-отчёт о покрытии:

Заключение
В этой статье мы покрыли модуль Kittens модульными и интеграционными тестами. Предложенный дизайн модуля позволил охватить следующие части:
- KittenStoreImpl содержит бОльшую часть бизнес-логики;
- KittenStoreNetwork отвечает за сетевые запросы высокого
уровня;
- KittenStoreParser отвечает за разбор сетевых ответов;
- все преобразования и связи.
Последний пункт очень важен. Охватить егои возможно благодаря особенности MVI. Единственная ответственность представления отображать данные и отправлять события. Все подписки, преобразования и связи выполняются внутри модуля. Таким образом, мы можем покрыть общими тестами всё, кроме непосредственно отображения.
Такие тесты имеют следующие преимущества:
- не используют платформенные API;
- выполняются очень быстро;
- надёжные (не мигают);
- выполняются на всех поддерживаемых платформах.
Мы также смогли проверить код на совместимость со сложной моделью памяти Kotlin/Native. Это тоже очень важно из-за отсутствия безопасности во время сборки: код просто падает во время выполнения с исключениями, которые трудно отлаживать.
Надеюсь, это поможет вам в ваших проектах. Спасибо, что читали мои статьи! И не забудьте подписаться на меня в Twitter.
Бонусное упражнение
Если вы хотите поработать с тестовыми реализациями или поиграть с MVI, предлагаю выполнить несколько практических заданий.
Рефакторинг KittenDataSource
В модуле существуют две реализации интерфейса KittenDataSource: одна для Android и одна для iOS. Я уже упоминал, что они отвечают за доступ к сети. Но на самом деле у них есть ещё одна функция: они генерируют URL-адрес для запроса на основе входных аргументов limit и page. В то же время у нас есть класс KittenStoreNetwork, который ничего не делает, кроме делегирования вызова в KittenDataSource.
Задание: переместить логику генерирования URL-запроса из KittenDataSourceImpl (на Android и iOS) в KittenStoreNetwork. Вам нужно изменить интерфейс KittenDataSource следующим образом:

Как только вы это сделаете, вам нужно будет обновить тесты. Единственный класс, к которому вам потребуется прикоснуться, это TestKittenDataSource.
Добавление постраничной загрузки
TheCatAPI поддерживает разбивку на страницы, поэтому мы можем добавить эту функцию для лучшего взаимодействия с пользователем. Вы можете начать с добавления нового события Event.EndReached для KittenView, после чего код перестанет компилироваться. Затем вам нужно будет добавить соответствующий Intent.LoadMore, преобразовать новый Event в Intent и обработать последний в KittenStoreImpl. Вам также потребуется изменить интерфейс KittenStoreImpl.Network следующим образом:

Наконец, вам потребуется обновить некоторые тестовые реализации, исправить один или два существующих теста, а затем написать несколько новых, чтобы покрыть разбивку на страницы.