От кого и для кого
Доброго времени суток! Меня зовут Николай, и я хочу рассказать
свою историю и поделиться своим небольшим опытом в разработке своей
первой игры. С чего начинал и какие трудности пришлось преодолеть
на пути разработки. Статья ориентирована на тех, кто начинает,
думает начать или уже разрабатывает свою первую игру. Зачем? Потому
что на стадии разработки своей первой игры, сам не однократно читал
статьи о подобном опыте, после прочтения которых "наматывал сопли
на кулак" и продолжал разработку дальше. От идеи до выпуска в
магазин.
Внимание! Статья получилось длинной, так что
запаситесь чаем! Если не хочется долго читать, то выжимка из
советов в концы статьи.
С чего все начиналось
Шел третий курс универа
По образованию я моряк, однако, после первого рейса, я понял,
что перспектива отстуствия на "земле" по 6 месяцев в году меня не
радовала, хоть по зарплате в этой отрасли никого не обижают.
Выбор направления
Появилась острая необходимость найти "дело", которое будет
приносить удовольствие, не придется отрываться от современного мира
на длительный срок и иметь финансовый достаток в перспективе
сравнимый с моей по образованию профессией. Конец 4 курса универа и
мой выбор пал на IT индустрию, а именно на python разработчика.
Уделив 2 недели теории, в частности технической документации языка,
я начал развивать логику и выполняя задачки каждый день на
протяжении полугода, пока в конце декабря 2018 года не обнаружил
геймдев.
А вот и Unity!
Выглядит комично или даже банально, но я повелся на клик-бэйт
видео с подобным названием "Как сделать свою первую игру за 15
минут" или "Делаю крутую игру за 5 минут без регистрации и смс".
Посмотрев данные материалы, в голове появилась мысль, выделить себе
пару дней в своем графике, и утолить свое любопытство, установив
данную среду разработки на свой компьютер. Потыкав разные кнопочки,
и написав код методом "copy-paste", я пришел в неописуемый восторг!
Моя творческая натура внутри меня ликовала. Ведь это было так
приятно наблюдать за тем, что ты "сам" написал пару минут назад,
сейчас заставляет кубик крутиться, перемещаться или менять цвет.
Так уж вышло, что средой разработки установленной на мой компьютер
оказалась Unity.
Почему Unity?
Он бесплатный, не такой сложный в освоении, большое сообщество и
тонны ресурсов для самообучения, поэтому отлично подходит для
начинающих разработчиков. Мобильный рынок заполнен проектами
созданные на Unity. Даже такие крупные компании как
Blizzard, Riot Games, CD
Project RED выпустили всеми известные хиты как
Hearthstone, Wild Rift и
Gwent, используя эту платформу. Приняв волевое
решение, я решил уйти в геймдев на пару с Unity.
Подготовка к разработке
Формирование идеи
Определившись с выбором рабочей платформы для разработки игры, я
отправился читать статьи людей, у которых имелся уже хоть какой то
опыт в данной сфере, чтобы выбрать нужное мне направление. ПК или
смартфоны? 2Д или 3Д? Сингл или мультиплеер?
Прочитав большое количество статей и проанализировав их,
все советы сходились к тому, чтобы:
-
Проект не разрабатывать
больше 2-х месяцев, иначе увеличивается
вероятность потерять энтузиазм и он окажется на полке "потом
доделаю" так не дойдя до выпуска;
-
Проект должен быть простой,
легкий, желательно иметь небольшую
изюминку. Иначе нафантазировав себе в голове крутой ААА
проект с сетевым режимом и открытом миром, рискуете себе "сломать
зубы", потеряв всякую мотивацию к разработке и потеряться где то в
пучине депрессии и отчаяния;
Мой выбор
2Д мобильная аркада с сетевым режимом до 6 человек , рейтинговой
системой и вознаграждением. Разработка, которой заняла отнюдь не 2
, а все "12 месяцев".
Аргументы "за":
-
Мне показалось заставлять двигаться 2Д объекты
будет проще, чем те же 3Д;
-
Мобильный рынок огромен и его доля более
половины всей игровой индустрии;
-
Писать сюжеты для игр я не умею, да и опыта в этом нет никакого,
поэтому я решил сделать упор на веселье. А играть всегда веселее
вместе! Поэтому сетевая;
-
Продолжительность жизни игр с сетевым режимом дольше, где ты
можешь соревноваться с друзьями за лучший
результат, чем у игр, где простенький сюжет, пройдя которую ты
забудешь и никогда не вернешься.
Аргументы "против":
-
Игра уже становилась не так уж
проста, как советовали более опытные коллеги;
-
Сложность и продолжительность разработки для не
опытного "птенца" увеличивалась многократно.
Аргументы "за" были очень привлекательны и я решил рискнуть. Как
говорится - "Чем чёрт не шутит" и "Была не была"!
Знакомство с Unity и его изучение
Учится чему то с нуля, это как учится кататься на велосипеде.
Главное стараться и упорно трудиться, и тогда рано или поздно точно
должно получится.
Начинал с малого, а именно перемещал разные объекты в пространстве,
писав самый примитивный код.
Совет: знайте, чтобы вы не делали или не хотели
начать делать, это с вероятность больше 90% уже было сделано до
вас. Научитесь правильно искать нужную информацию!!!
После полумесяца изучения Unity, было необходимо разработать
какой то план разработки, которому бы я следовал. Держать все в
голове было невозможно, да и нецелесообразно. Сейчас я использую
обычный текстовый редактор, где записывваю свои мысли о реализации
той или иной фичи, но для начала хватить и обычного листка бумаги и
карандаша.
Совет: попытайтесь как можно точно расписать
предполагаемый план, по которому будете разрабатывать свою будущую
игру. Управление персонажем, основной геймплей, музыка и
эффекты, механика игры, интерфес.
Как только я накидал определенный план действий и уже собирался
начать делать свой первый будущей "шедевр", встал серьезный
вопрос
Где я возьму картинки, музыку и остальные элементы для своей
будущей игры? Ведь я совершенно не умею сам это создавать
На помощь пришел фирменный магазин Unity, а именно
unityAssetStore. Замечательная площадка, где
фрилансеры выкладывают свои работы с целью их продать, а
разработчики могут приобрести их для использования в своих
проектах, тем самым ускоряя разработку и экономя драгоценное время
и нервы.
На пути всей разработки игры, да и после выпуска, мои знакомые и
друзьям задают мне практически одни и те же вопросы.
А ты сам все это нарисовал? А музыку ты писал тоже сам?
Как можете догадаться, они получали отрицательный ответ на все
подобного рода вопросы.
Совет: Не чурайтесь использовать чужие
наработки или шаблоны, которые продают или прибегать к работе
фрилансеров! Это взаимосвязанная выгода! Конечному пользователю все
равно, сами вы рисовали самолетик несколько часов или потратили 10$
на его покупку в магазине, ведь главное результат!
Разумеется, необходимо иметь базовые навыки
такие как изменения размера изображения, цвета или редактирование
определеного участка звука.
Совет: Отслеживайте скидки на продаваемые
ассеты в различным магазинах, особенно под новый год! Можно
приобрести кучу ассетов по выгодной цене со скидкой до 90% в такое
время.
Непосредственная разработка
Первые шаги
Закончив с подготовительной частью, я принялся за работу. Ввиду
того, что я заканчивал университет, и было необходимо готовиться к
квалификационным экзаменам и защите диплома. На разработку игры в
день уходило не более 3 часов в день. Такой режим продолжался до
самого начала лета 2019 года.
На этом этапе моя игра имела следующий вид:

Главное начать
Разумеется, я сразу начал осваивать сетевой режим, расчитывая на
это потратить не больше двух недель. Я еще никогда так не ошибался.
Вместо предполагаемых 2-х недель,
ушло не меньше 2-х месяцев только на освоение
софта для сетевой игры. Сам контент для игры простаивал.
Совет: Не думайте, что сетевая игра, будет
легче чем написать простенький сюжет. Это совершенно не так.
От простого к сложному
Так как я понятия не имел, как настроить управление на мобильном
телефоне, я решил пойти по пути постепенного повышения сложности.
Настроил управление для клавиатуры с мышью, наладил подбор,
применение предметов, сделал простейший интерфейс игровой механики
и его взаимодействие с игроком и прочие мелочи. Позже, я подобрался
уже к управлению персонажем с помощью телефона.
Все это заняло очень много времени и сцена с непосредственной
сетевой игрой уже выглядела так:

Эх, как же сильно была переработана
финальная версия интерфейса
Интерфес и меню
Не малая важная часть разработки игры, о которой начинающие
разработчики не задумываются это Меню, его
визуальное оформление и
работоспособность. Когда уже основная часть
геймплея готова, появляется ложное чувство того, что проект уже
готов, и можно завтра его готовить для публикации в магазине. К
сожалению, это не делается за пару дней. Это тяжелая и рутинная
работа, которая требует концентрации и повышенной ответственности.
Когда что-то светиться, крутиться и перемещается в меню, это
располагает к себе пользователя. Не зря же все крупные вендоры
компьютерного желаза продают свой товар с большим акцентом на
динамическую RGB подстветку, значит есть положительный
результат!
Совет: Перед тем как создавать свое меню,
поиграйте в разные игры подобного или смежного жанра. Выделите для
себя полезные фичи интерфейса и меню. Что в них
интересного и что вам
нравится.
На этом этапе разработки, многие проекты так и не доходят до
выпуска в мир. Тут несколько факторов способствуют:
Совет: Скажу то, что я прочитал когда сам
проходил этот этап. НЕ СДАВАЙСЯ! Как бы не было
сложно, ни в кое случае НЕ СДАВАЙСЯ и НИ ШАГУ
НАЗАД! Дойдя до самого конца ты познаешь лавину экстаза и
самоудовлетворения от того, что ты не бросил все! И разумеется
бесценный опыт!!!
Однопользовательский режим
Сетевая игра это, конечно, хорошо, но что если у пользователя
отсуствует подступ к Информационно-Телекоммуникационной Системе
Общего Пользования?(Интернет)
Разумеется, было принято решение сделать простенький сингл режим,
где игрок будет собирать определенный ресурс на время, а ему
попутно будут мешаться ИИ, затруднив выполнение миссии.
Две недели работы, и первоначальный вид был такой:

Концептуальные различие с финальной версией
отстствуют
Оптимизация
Фух! Оптимизация это такая штука, о которой ты начинаешь
задумываться, когда твой проект на смартфоне выдает 10-15 кадров в
секунду с фризами и просадками до 4 кадров секунду. Как только
тестирования проекта доходит до сборки его на телефоне, все встает
на свои места. При разработке прилождений на мобильные смартфоны,
оптимизация имеет очень важную роль. Ведь в них не скрывается такая
вычислительная мощность как на ПК.
Я начал оптимизировать свой проект, только спустя 8 месяцев
разработки. Из-за чего оптимизировать надо было много и долго:
Это заняло у меня еще не меньше двух недель.
Совет: Не затягивайте с оптимизацией! Изучите
сразу вопрос, как стоит правильно использовать определенные
настройки в работе с теми или иными ресурсами в вашем проекте,
чтобы добиться наилучшей производительности.
Одна голова хорошо, а несколько лучше
Обязательно спрашивайте мнение других людей о вашем проекте на
разных этапах разработки. Разная точка зрения под разным углом даст
хороший фидбэк и новые идеи для дальнейней работы. Не принимайте в
свой адрес негативные отзывы о вашем проекте, как что то ужасное.
Негативный отзыв, а еще лучше конструктивная критика - это
невероятная удача и стимул сделать свой проект лучше!
Совет: Найдите так называемых "жертв", которых
будете использовать в качестве тестировщиков среди ваших
родственников, близких друзей и коллег по цеху. Брат, сестера,
мама, папа, парень, девушка, друг, подруга, кто угодно. Дайте ему
смартфон с игрой, посадите его рядом и просто наблюдайте, что ему
не нравится, а что нравится. Главное - просто молчите и
смотрите!
Реклама и внутриигровые покупки
Настал черёд встроить в свой проект рекламу и сделать магазин.
Кто бы что не говорил, но на одном энтузиазме далеко не уедешь и
святым духом сыт не будешь. Посему, это необходимый блок
разработки. Тут главное грамотно подойти к этому делу, чтобы игрок
не "плевался" и выгода была для обеих сторон!
Софта для рекламных интеграций имеется множетство, в том числе и
от самой Unity, так называемая Unity Ads. Однако, мой
выбор пал на Google
AdMob. Почему не Unity Ads? Почитав обзоры, я
узнал, что контент рекламы содержит казино, рулетки и ставки. Тут
уже на вкус и цвет, как говорится, но я не хочу чтобы реклама была
связана с подобного рода сервисами. Я использовал межстраничную и
рекламу с вознаграждением.
Совет: Реклама с вознаграждением, намного
лучше, ведь игрок сам нажимает на просмотр рекламы, чтобы получить
какие-либо "плюшки" в игре. Разработчик и пользователь в плюсе!
Покупки в игре, я реализовал подобным образом:

Финальная версия игры
"12 месяцев" кропотливой работы , и финальная версия выглядит
примерно так:

Меню
игры

Сетевой Геймплей
Казалось бы, все сделано и осталось дело за малым, а именно
опубликовать игру. Но не все так просто как кажется!
Совет: Тут необходимо открыть еще одно "второе"
дыхание , к ранее уже открытым +100500
Публикация игры
Большим плюсом выбора Unity - кроссплатформенность, что
позволяет один проект выпустить на всех желаемых платформах
(Android, iOS,PC,WebGl и др). К моменту написания статьи игра была
опубликована только для Android в Google Play Market, но не за
горами ios в Apple Store.
Какие "подводные камни" имеются?
Технически публикация приложения в Google Play Market не
составляет никакого труда всё интуитивно понятно и легко. Пройти
проверку по возрастному рейтингу, загрузить картинки из игры,
логотип и впринципе все готово.
Так в чем же проблема и где те самые "подводные камни"?
Политика конфиденциальности
Для публикации она не является необходимым элементом, однако,
если в вашем приложении имеется реклама или внутриигровые покупки,
то в кратчайшие сроки стоит обзавестись данной "бумажкой" и указать
сссылку на неё в Google Play Console. К счастью, есть моножество
ресурсов, которые генерирует данный документ за считанные секунды и
сразу предлагают разместить на их сайте, удовлетворяя запросам
гугла.
Если проигнорировать предупреждения от гугл, что у вас отсутствует
политика конфидециальности, то приложение могут легко снять с
публикации.
Совет: Не откладывайте на потом этот пункт,
делайте его паралельно с публикацией!
Идентификатор клиента OAuth
Если у вас в игре имеется система достижений, рейтинга от гугл
или вы хотя бы сохраняете данные игры в облаке от гугл, то
необходимо, чтобы пользователь проходил процесс авторизации
используя гугл аккаунт, а значит предоставлял некоторые разрешения
на управления его данными. Теперь по порядку. При настройке игровых
сервисов в Google Play Console, необходимо создать приложение для
авторизации пользователя в Google Cloud Platforms, настроить
учетные данные для идентификатора клиента OAuth, и Окно запроса
доступа OAuth. Пожалуй это главный "подводный камень".
Сложность состоит не в его первоначальной настройке, чтобы сервисы
исправно работали, а в том что приложение было опубликовано и не
имело ограничений по количеству пользователей. Если вы намерены
создавать крупнобюджетный проект, которые будет привлекать тысячи
игроков, то вам придется обязательно пройти этот этап.

Сайт игры
Это не является обязательным пунктом, но лучше сделать сайт, где
будут размещены новости вашего проекта, а так же политика
конфиденциальности и прочие материалы для ознакомления. Оказывается
в 2021 году сделать легкий и простой сайт достаточно просто. С
шаблонами для разработки сайтов в Word Press, не долго думая, я
останавливаюсь на нем. Для сайта необходим хостинг и собственный
домен. Взвесив все "за" и "против", решил потратить пару тысяч
рублей на его аренду, сроком на 48 месяцев и не "париться". В сети
огромное количество предложений, так что проблем с этим тоже не
было. Пару часов уходит на его настройку, и еще пару часов на
наполнение его контентом. И вот уже есть свой собственный сайт для
игры!
Совет: Чтобы получить заветную галочку во
вкладке Окно запроса доступа OAuth в Google Cloud Platforms, иметь
сайт игры и свой домен , где так же будет размещена политика
конфиденциальности - является обязательным пунктом!

Совет: Так же, если используете рекламу от
Google Admob, то сайт тоже необходим. В корневую
папку вашего сайта добавляется файл app-ads.txt. Это позволяет
рекламодателям понять, какие источники объявлений имеют право
продавать рекламный инвентарь. Если не пройти авторизацию, то доход
с рекламы будет сильно снижен!

GDPR
Еще одно бюрократическое препятствие осталось, на пути для
публикации. Если ваше приложение имеет рекламу, то она может быть
персонализированной, а значит ваше приложение собирает данные
пользователей, чтобы успешно показывать рекламу.
GDPR- (General Data Protection Regulation)
-этозакон, принятый Европейским Парламентом,
который описывает правила защиты данных для граждан ЕС. Это
значит,чтобы показывать персональну рекламу, необходимо перед
первым запуском вашей игры, пользователь должен принять соглашение,
что ознакомлен с политикой конфиденциальности вашего приложения, а
так же прочитать в каких целях будет использоваться его
персональные данные и дать согласие/отказаться на их обработку.
Разумееется это распространяется на резидентов из стран
ЕС.



После выполнения всех выше изложенных пунктов, мое приложение
успешно опубликовано в Google Play Market и не знает никаких
проблем.
Краткая выжимка советов
-
Изучите рынок, и определитесь с направлением и жанром игры.
Главное не стройте в начале "наполеоновские"планы, которые могут и
не реализоваться!
-
Распишите план действий и пытайтесь четко следовать ему, попутно
внося небольшие правки. Старайтесь укладываться в установленные
планом сроки.
-
Обязательно спрашивайте мнение ваших близких и друзей о вашей
игре на протяжении всей разработки.
-
Не стесняйтесь приобретать ресурсы для ускорения разработки и
повышения качества своего проекта.
-
Старайтесь писать программный код максимально понятный вам и
другим людям, чтобы его можно было прочитать спустя месяцы
разработки и понять его смысл.
-
Изучите базовые навыки работы с редактированием изображений и
звуков.
-
Соорудите себе в браузере пул полезных закладок с библиотекой
различных ресурсов, имея быстрый к ним доступ.
-
Научитесь использовать на базовом уровне Git. Незаменимый
помощник при разработке игры, чтобы контролировать внесенные
изменения.
-
Последнее и наверно самое важное. Никогда не
сдавайтесь , верьте в себя, упорно трудитесь и рано или поздно,
но у вас все обязательно получится! Если получилось у меня и
миллионов других начинающих разработчиков данного ремесла, то
почему не должно получится и у вас!?
Заключение
Премного благодарен вам, что вы дочитали конца эту
длинную статью! Надеюсь, что те кто только пробуют себя в
роли разработчика, подчерпнут для себя некоторые полезные вещи и
получат заряд мотивации, а "бывалые" найдут эту историю как минимум
не скучной.
Не знаю, кто сказал, что разработка игр это
веселое занятие. Это не разу не вёселое занятие,
требующее повышенной концентрации, ответственности к деталям,
высокого уровня самодисциплины и упорства. Интересно ли?!
Разумеется да, иначе бы я не начинал этот путь. Играть в игры и
делать их, это совершенно разные вещи. Но в любом
случае, это безумно интересно! Сделанный выбор
однажды в универе, полностью перевернул моё мышление и всю мою
жизнь. Не бойтесь и дерзайте!
Если я где-то ошибся и был не прав - буду рад правкам и
пожеланиям в комментариях. Готов ответить на любые вопросы
по данной теме.
Чтобы не было недопониманий на счет даты релиза.
Впервые игра была опубликована 2 декабря 2019 года, и это было
10 месяцев разработки. После я был вынужден отдать долг своей
родине. Срочную службу в армии я нес до 2 декабря 2020. После
демобилизации, я сразу продолжил разработку. И 4 февраля
2021, после "12 месяцев" разработки, я выпустил
проект.
Если Вам интересно посмотреть на результат моей работы, то вы
можете найти в Google Play Market.
Название игры - Starlake

 Примерка для инкапсуляции. Слева направо
- двойной RaspberryPi 4B, nVidia Jetson Nano B01, Intel NUC gen11.
Примерка для инкапсуляции. Слева направо
- двойной RaspberryPi 4B, nVidia Jetson Nano B01, Intel NUC gen11.
 Сопоставление габаритов Raspberry Pi
Сопоставление габаритов Raspberry Pi Сопоставление габаритов Jetson Nano
Сопоставление габаритов Jetson Nano Сопоставление габаритов Intel Nuc
Сопоставление габаритов Intel Nuc










































 Результат
Результат

.") Источник фото: TactoTek, финская
компания, которая развивает технологию IMSE (In-Mold Structural
Electronics).
Источник фото: TactoTek, финская
компания, которая развивает технологию IMSE (In-Mold Structural
Electronics).
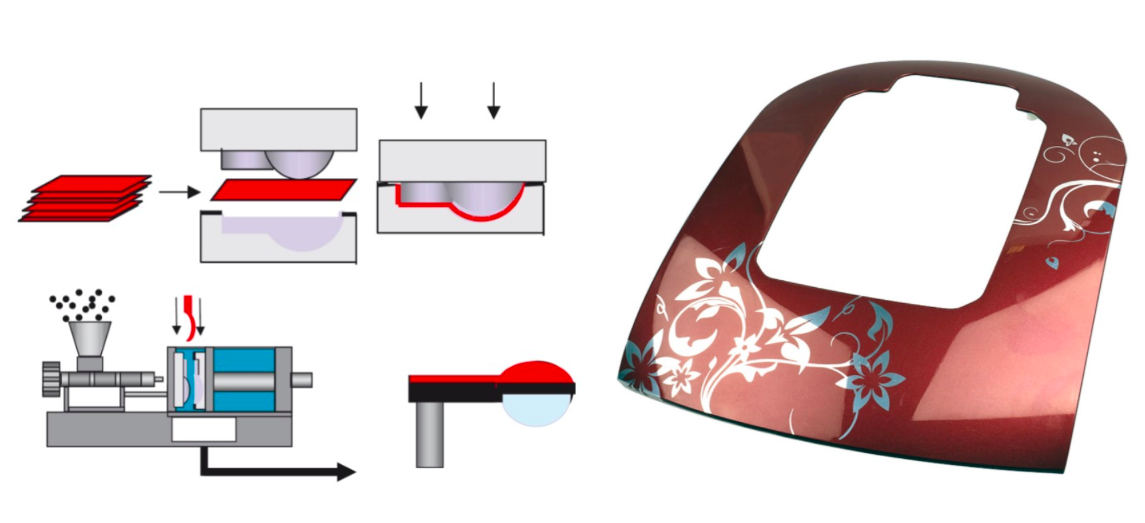



 Источник изображений: Functional Ink
Systems for In Mold Electronics by DuPont
Источник изображений: Functional Ink
Systems for In Mold Electronics by DuPont Источник изображений: Functional Ink
Systems for In Mold Electronics by DuPont
Источник изображений: Functional Ink
Systems for In Mold Electronics by DuPont
 Источник фото: Functional Ink Systems for
In Mold Electronics by DuPont
Источник фото: Functional Ink Systems for
In Mold Electronics by DuPont
 Разрушитель модели Лего из 2000+ деталей
Разрушитель модели Лего из 2000+ деталей














 Запрос на выборку последнего известного
сальдо до даты проводки включительно
Запрос на выборку последнего известного
сальдо до даты проводки включительно Последняя посчитанная себестоимость этого
товара
Последняя посчитанная себестоимость этого
товара Последний известный остаток номенклатуры
этой позиции документа
Последний известный остаток номенклатуры
этой позиции документа










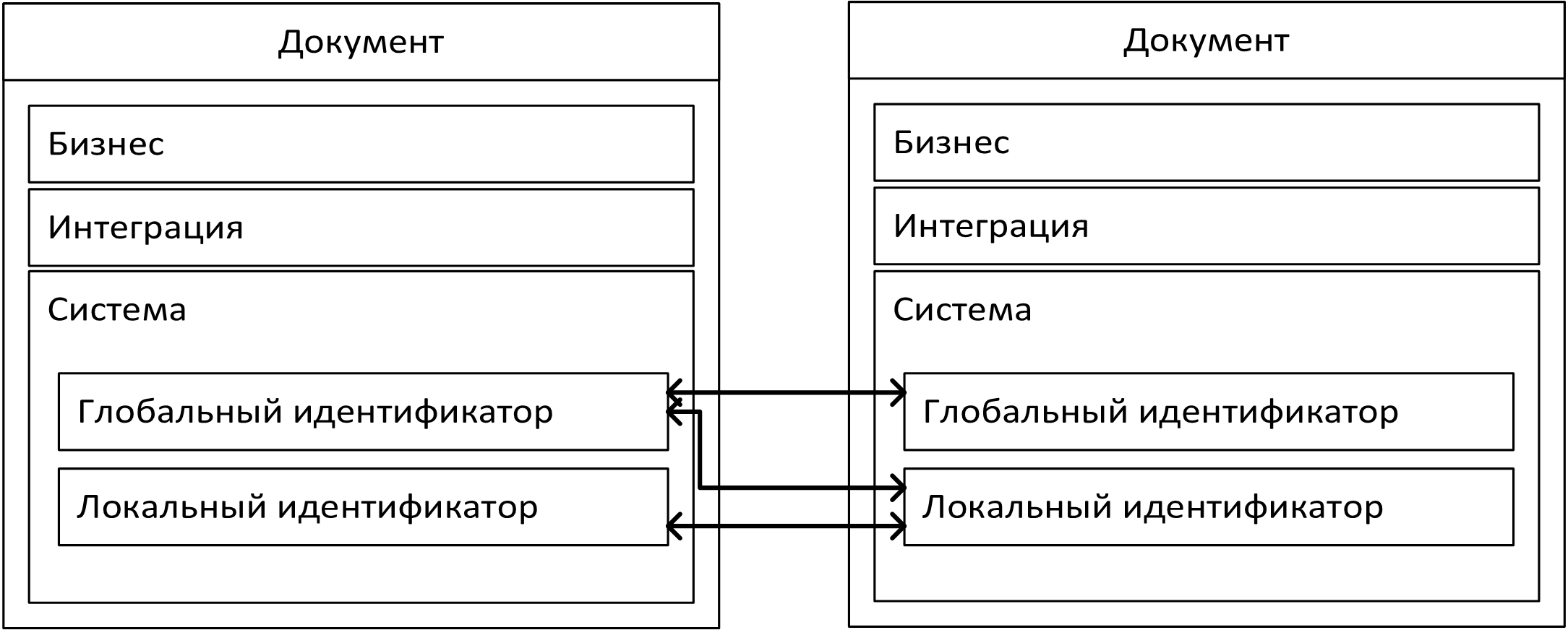
 График по тестированию табличного хранилища
График по тестированию табличного хранилища График по тестированию NoSQL-хранилища
График по тестированию NoSQL-хранилища
 Структура вопросов
Структура вопросов
 Фрагмент таблицы в БД с вопросами
Фрагмент таблицы в БД с вопросами






































































 И в каждом открытии и творении стоит
инженерная мысль, возможно, уникальный проект инженера.
И в каждом открытии и творении стоит
инженерная мысль, возможно, уникальный проект инженера.
 Так, к примеру, если бы Генри Форд жил в
наше время, он имел бы состояние в 200 млрд долларов и был бы
богатейшим человеком планеты.
Так, к примеру, если бы Генри Форд жил в
наше время, он имел бы состояние в 200 млрд долларов и был бы
богатейшим человеком планеты.
 Создание проекта с подробным описанием задачи
Создание проекта с подробным описанием задачи
 Несерьезность, студенчество, подработка
Несерьезность, студенчество, подработка
 Оплата больничных
Оплата больничных
 Нет постоянной загруженности и стабильных денег
Нет постоянной загруженности и стабильных денег
 Общение с коллегами
Общение с коллегами










