
Осторожно: под катом чрезвычайно много изображений.

Что такое Mission Control
Как заявляет в своем блоге сама компания, основная задача VMware Tanzu Mission Control привнести порядок в кластерный хаос. Mission Control представляет из себя управляемую через API платформу, которая позволит администраторам применять политики к кластерам или группам кластеров и устанавливать правила безопасности. Основанные на модели SaaS инструменты безопасно интегрируются в кластеры Kubernetes через агента и поддерживают массу стандартных операций с кластером, включая операции управления жизненным циклом (развертывание, масштабирование, удаление и пр.).
В основе идеологии линейки Tanzu лежит максимальное использование open-source технологий. Для управления жизненным циклом кластеров Tanzu Kubernetes Grid используется Cluster API, Velero для бэкапов и восстановления, Sonobuoy для контроля соответствия конфигурации кластеров Kubernetes и Contour в качестве ингресс-контроллера.
Общий список функций Tanzu Mission Control выглядит так:
- централизованное управление всеми вашими кластерами Kubernetes;
- управление идентификацией и доступом (IAM);
- диагностика и мониторинг состояния кластеров;
- управление конфигурацией и настройками безопасности;
- планирование регулярных проверок состояния кластера;
- создание резервных копий и восстановление;
- управление квотами;
- визуализированное представление утилизации ресурсов.

Почему это важно
Tanzu Mission Control поможет бизнесу решить задачу управления большим парком кластеров Kubernetes, расположенных локально, в облаке и у нескольких сторонних провайдеров. Рано или поздно любая компания, чья деятельность завязана на IT, оказывается вынуждена поддерживать множество разнородных кластеров, расположенных у разных провайдеров. Каждый кластер превращается в снежный ком, которому нужна грамотная организация, соответствующая инфраструктура, политики, защита, системы мониторинга и многое другое.
В наши дни любой бизнес стремится сократить издержки и автоматизировать рутинные процессы. А сложный IT-ландшафт явно не способствует экономии и концентрации на приоритетных задачах. Tanzu Mission Control дает организациям возможность работать с множеством кластеров Kubernetes, развернутых у множества провайдеров, гармонизировав при этом операционную модель.
Архитектура решения

Tanzu Mission Control это мультитенантная платформа, предоставляющая пользователям доступ к набору гибко настраиваемых политик, которые можно применять к кластерам и группам кластеров Kubernetes. Каждый пользователь привязан к Организации, именно она является корнем ресурсов групп кластеров и рабочих пространств (Workspaces).

Что умеет Tanzu Mission Control
Выше мы уже кратко перечислили список функций решения. Давайте посмотрим, как это реализовано в интерфейсе.
Единое представление всех кластеров Kubernetes предприятия:

Создание нового кластера:


Кластеру сразу можно назначить группу, и он унаследует заданные ей политики.
Подключение кластера:

Уже существующие кластеры можно просто подключить с помощью специального агента.
Группировка кластеров:

В Cluster groups можно группировать кластеры для наследования назначаемых политик сразу на уровне групп, без ручного вмешательства.
Workspaces:

Дает возможность гибко настраивать доступы к приложению, которое находится в рамках нескольких пространств имен, кластеров и облачных инфраструктур.
Рассмотрим подробнее принципы работы Tanzu Mission Control в лабораторных работах.
Лабораторная работа #1
Разумеется, детально представить себе работу Mission Control и новых решений Tanzu без практики достаточно сложно. Для того, чтобы вы могли изучить основные возможности линейки, VMware предоставляют доступ к нескольким лабораторным стендам. На этих стендах можно выполнить лабораторные работы, используя пошаговые инструкции. Помимо собственно Tanzu Mission Control для тестирования и изучения доступны и другие решения. С полным списком лабораторных работ можно ознакомиться на этой странице.
Для практического ознакомления с различными решениями (включая небольшую игру по vSAN) отводится разное время. Не волнуйтесь, это весьма условные цифры. Например, лабу по Tanzu Mission Control при прохождении из дома можно решать до 9 с половиной часов. Кроме того, даже если таймер выйдет, можно будет вернуться и пройти всё заново.
Прохождение лабораторной работы #1
Для доступа к лабораторным работам
понадобится аккаунт VMware. После авторизации откроется всплывающее
окно с основной канвой работы. В правой части экрана будет помещена
подробная инструкция.
После прочтения небольшой вводной части о Tanzu вам будет предложено пройти практику в интерактивной симуляции Mission Control.
Откроется новое всплывающее окно windows-машины, и вам будет предложено выполнить несколько базовых операций:
Разумеется, интерактивная симуляция не дает достаточной свободы для самостоятельного изучения: вы двигаетесь по заранее проложенным разработчиками рельсам.
После прочтения небольшой вводной части о Tanzu вам будет предложено пройти практику в интерактивной симуляции Mission Control.
Откроется новое всплывающее окно windows-машины, и вам будет предложено выполнить несколько базовых операций:
- создать кластер
- настроить его базовые параметры
- обновить страницу и убедиться в том, что всё настроено корректно
- задать политики и произвести проверку кластера
- создать рабочее пространство
- создать пространство имен
- снова поработать с политиками, каждый шаг подробно разъясняется в руководстве
- демо-апгрейд кластера
Разумеется, интерактивная симуляция не дает достаточной свободы для самостоятельного изучения: вы двигаетесь по заранее проложенным разработчиками рельсам.
Лабораторная работа #2
Здесь мы уже имеем дело с кое-чем посерьезнее. Эта лабораторная работа не настолько привязана к рельсам, как предыдущая и требует более внимательного изучения. Приводить её здесь целиком мы не станем: ради экономии вашего времени разберем только второй модуль, первый посвящен теоретическому аспекту работы Tanzu Mission Control. При желании вы можете пройти ее самостоятельно полностью. Этот модуль предлагает нам окунуться в управление жизненным циклом кластеров через Tanzu Mission Control.
Примечание: лабораторные работы Tanzu Mission Control регулярно актуализируются и уточняются. Если при прохождении вами лабораторной работы какие-то экраны или шаги будут отличаться от приведенных ниже, следуйте указаниям в правой части экрана. Мы же пройдемся по актуальной на момент написания статьи версии ЛР и рассмотрим ее ключевые элементы.
Прохождение лабораторной работы #2
После процесса авторизации в VMware Cloud
Services, запускаем Tanzu Mission Control.
Первый шаг, предлагаемый лабораторией, развертывание кластера Kubernetes. Сначала нам необходимо получить доступ к ВМ с Ubuntu с помощью PuTTY. Запускаем утилиту и выбираем сеанс с Ubuntu.

Поочередно выполняем три команды:

Теперь созданный нами кластер нужно добавить в Tanzu Mission Control. Из PuTTY возвращаемся в Chrome, переходим в Clusters и нажимаем ATTACH CLUSTER.
Из выпадающего меню выбираем группу default, вписываем предлагаемое лабой имя и нажимаем REGISTER.

Копируем полученную команду и идем в PuTTY.

Выполняем полученную команду.

Для отслеживания прогресса выполняем еще одну команду:

Возвращаемся в Tanzu Mission Control и нажимаем VERIFY CONNECTION. Если все прошло успешно, индикаторы всех проверок должны быть зелеными.

Теперь создадим новую группу кластеров и развернем там новый кластер. Идем в Cluster groups и нажимаем NEW CLUSTER GROUP. Вписываем имя и нажимаем CREATE.

Новая группа сразу должна появиться в списке.

Развернем новый кластер: идем в Clusters, нажимаем NEW CLUSTER и выбираем ассоциированную с лабораторной работой опцию.

Добавим имя кластера, выберем назначаемую ему группу в нашем случае hands-on-labs и регион деплоя.

При создании кластера доступны и другие опции, но при прохождении лабораторной смысла их менять нет. Выбираем нужную вам конфигурацию, нажимаем Next.

Некоторые параметры нужно отредактировать, для этого нажимаем Edit.
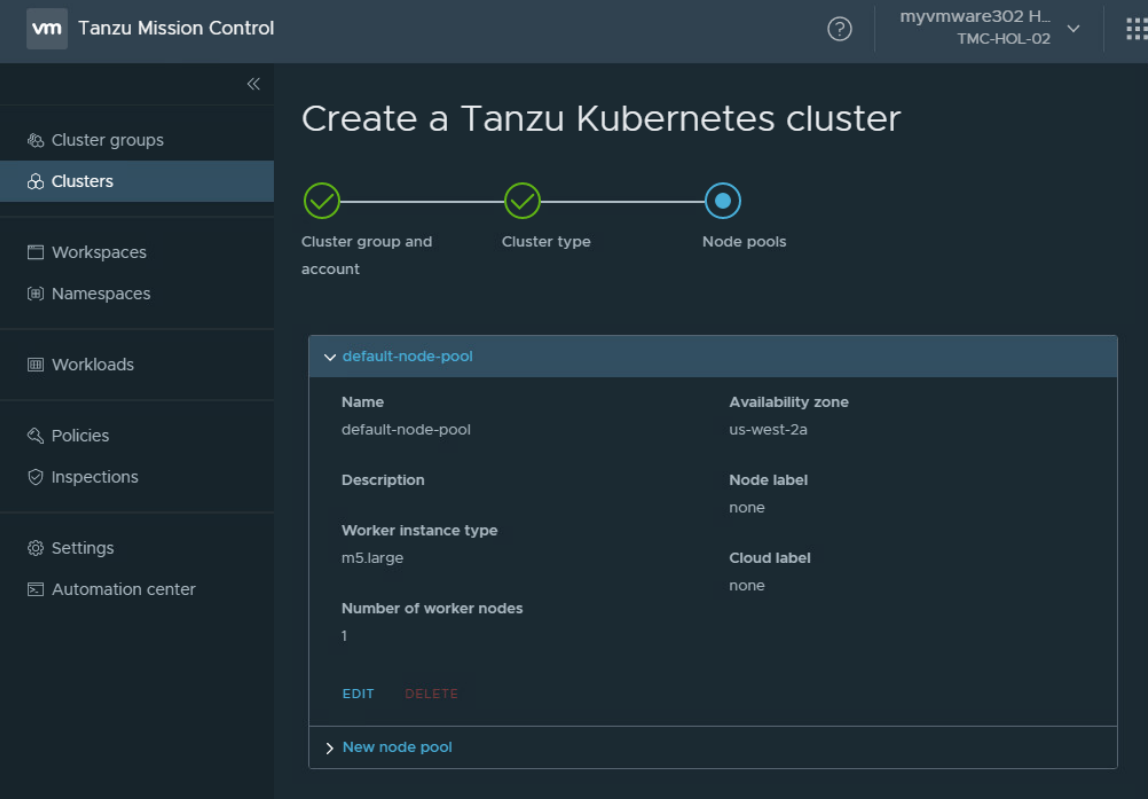
Увеличим количество рабочих нод до двух, сохраним параметры и нажмем CREATE.
В процессе вы увидите такой прогрессбар.

После успешного деплоя перед вами будет такая картина. Все чеки должны быть зелеными.

Теперь нам надо скачать файл KUBECONFIG, чтобы управлять кластером с помощью стандартных команд kubectl. Это можно сделать прямо через пользовательский интерфейс Tanzu Mission Control. Скачиваем файл и переходим к скачиванию Tanzu Mission Control CLI нажатием click here.

Выбираем нужную версию и скачиваем CLI.

Теперь нам необходимо получить API Token. Для этого переходим в My Account и генерируем новый токен.

Заполняем поля и нажимаем GENERATE.

Полученный токен копируем и нажимаем CONTINUE. Открываем Power Shell и вводим команду tmc-login, затем токен, который мы получили и скопировали на предыдущем шаге, а потом Login Context Name. Выбираем info логи из предложенных, регион и olympus-default в качестве ssh-ключа.

Получаем namespaces:
Вводим

Теперь в этом кластере нам предстоит развернуть небольшое приложение. Сделаем два развертывания coffee and tea в виде сервисов coffee-svc и tea-svc, каждый из которых запускает разные образы nginxdemos/hello and nginxdemos/hello:plain-text. Делается это следующим образом.
Через PowerShell зайдем в загрузки и найдем файл cafe-services.yaml.

Из-за некоторых изменений в API нам придется его обновить.
Pod Security Policies включены по умолчанию. Для запуска приложений с привилегиями необходимо привязать учетную запись.
Создаем привязку:
Деплоим приложение:
Проверяем:

Модуль 2 закончен, вы прекрасны и восхитительны! Пройти остальные модули, включающие управление политиками и проверки на соответствие советуем самостоятельно.
Если вы хотите пройти эту лабораторную работу целиком, найти ее можно в каталоге. А мы перейдем к заключительной части статьи. Поговорим о том, на что удалось посмотреть, сделаем первые аккуратные выводы и развернуто скажем, что такое Tanzu Mission Control применительно к реальным бизнес-процессам.
Первый шаг, предлагаемый лабораторией, развертывание кластера Kubernetes. Сначала нам необходимо получить доступ к ВМ с Ubuntu с помощью PuTTY. Запускаем утилиту и выбираем сеанс с Ubuntu.
Поочередно выполняем три команды:
- создание кластера:
kind create cluster --config 3node.yaml --name=hol - загрузка KUBECONFIG-файла:
export KUBECONFIG="$(kind get kubeconfig-path --name="hol")" - вывод нод:
kubectl get nodes
Теперь созданный нами кластер нужно добавить в Tanzu Mission Control. Из PuTTY возвращаемся в Chrome, переходим в Clusters и нажимаем ATTACH CLUSTER.
Из выпадающего меню выбираем группу default, вписываем предлагаемое лабой имя и нажимаем REGISTER.
Копируем полученную команду и идем в PuTTY.
Выполняем полученную команду.
Для отслеживания прогресса выполняем еще одну команду:
watch
kubectl get pods -n vmware-system-tmc. Дожидаемся, пока у
всех контейнеров будет статус Running или
Completed.
Возвращаемся в Tanzu Mission Control и нажимаем VERIFY CONNECTION. Если все прошло успешно, индикаторы всех проверок должны быть зелеными.
Теперь создадим новую группу кластеров и развернем там новый кластер. Идем в Cluster groups и нажимаем NEW CLUSTER GROUP. Вписываем имя и нажимаем CREATE.
Новая группа сразу должна появиться в списке.
Развернем новый кластер: идем в Clusters, нажимаем NEW CLUSTER и выбираем ассоциированную с лабораторной работой опцию.
Добавим имя кластера, выберем назначаемую ему группу в нашем случае hands-on-labs и регион деплоя.
При создании кластера доступны и другие опции, но при прохождении лабораторной смысла их менять нет. Выбираем нужную вам конфигурацию, нажимаем Next.
Некоторые параметры нужно отредактировать, для этого нажимаем Edit.
Увеличим количество рабочих нод до двух, сохраним параметры и нажмем CREATE.
В процессе вы увидите такой прогрессбар.
После успешного деплоя перед вами будет такая картина. Все чеки должны быть зелеными.
Теперь нам надо скачать файл KUBECONFIG, чтобы управлять кластером с помощью стандартных команд kubectl. Это можно сделать прямо через пользовательский интерфейс Tanzu Mission Control. Скачиваем файл и переходим к скачиванию Tanzu Mission Control CLI нажатием click here.
Выбираем нужную версию и скачиваем CLI.
Теперь нам необходимо получить API Token. Для этого переходим в My Account и генерируем новый токен.
Заполняем поля и нажимаем GENERATE.
Полученный токен копируем и нажимаем CONTINUE. Открываем Power Shell и вводим команду tmc-login, затем токен, который мы получили и скопировали на предыдущем шаге, а потом Login Context Name. Выбираем info логи из предложенных, регион и olympus-default в качестве ssh-ключа.
Получаем namespaces:
kubectl
--kubeconfig=C:\Users\Administrator\Downloads\kubeconfig-aws-cluster.yml
get namespaces.Вводим
kubectl
--kubeconfig=C:\Users\Administrator\Downloads\kubeconfig-aws-cluster.yml
get nodes, чтобы убедиться, что все ноды в статусе
Ready.
Теперь в этом кластере нам предстоит развернуть небольшое приложение. Сделаем два развертывания coffee and tea в виде сервисов coffee-svc и tea-svc, каждый из которых запускает разные образы nginxdemos/hello and nginxdemos/hello:plain-text. Делается это следующим образом.
Через PowerShell зайдем в загрузки и найдем файл cafe-services.yaml.
Из-за некоторых изменений в API нам придется его обновить.
Pod Security Policies включены по умолчанию. Для запуска приложений с привилегиями необходимо привязать учетную запись.
Создаем привязку:
kubectl
--kubeconfig=kubeconfig-aws-cluster.yml create clusterrolebinding
privileged-cluster-role-binding
--clusterrole=vmware-system-tmc-psp-privileged
--group=system:authenticatedДеплоим приложение:
kubectl
--kubeconfig=kubeconfig-aws-cluster.yml apply -f
cafe-services.yamlПроверяем:
kubectl --kubeconfig=kubeconfig-aws-cluster.yml
get pods
Модуль 2 закончен, вы прекрасны и восхитительны! Пройти остальные модули, включающие управление политиками и проверки на соответствие советуем самостоятельно.
Если вы хотите пройти эту лабораторную работу целиком, найти ее можно в каталоге. А мы перейдем к заключительной части статьи. Поговорим о том, на что удалось посмотреть, сделаем первые аккуратные выводы и развернуто скажем, что такое Tanzu Mission Control применительно к реальным бизнес-процессам.
Мнения и выводы
Безусловно, говорить о практических вопросах работы с Tanzu пока рановато. Материалов для самостоятельного изучения не так уж и много, а развернуть тестовый стенд, чтобы потыкать новый продукт со всех сторон на сегодняшний день не представляется возможным. Тем не менее, даже по имеющимся данным можно сделать определенные выводы.
Польза Tanzu Mission Control
Система вышла действительно интересная. Сразу же хочется выделить несколько удобных и полезных плюшек:
- Можно создавать кластеры через веб-панель и через консоль, что очень понравится разработчикам.
- Управление RBAC через воркспейсы реализовано в интерфейсе пользователя. В лабе пока не работает, но в теории отличная вещь.
- Централизованное управление привилегиями на основе шаблонов
- Полный доступ к namespaceам.
- Редактор YAML.
- Создание сетевых политик.
- Мониторинг здоровья кластера.
- Возможность делать резервное копирование и восстановление через консоль.
- Управление квотами и ресурсами с визуализацией фактической утилизации.
- Автоматический запуск инспекции кластеров.
Опять же, многие компоненты на текущий момент находятся в стадии доработки, поэтому полноценно говорить о плюсах и минусах некоторых инструментов пока рано. Кстати, Tanzu MC, исходя из демонстрации, может на лету делать апгрейд кластера и в целом обеспечивать весь жизненный цикл кластера сразу у множества провайдеров.
Приведем несколько высокоуровневых примеров.
В чужой кластер со своим уставом
Допустим, у вас есть команда разработчиков, в которой четко распределены роли и обязанности. Каждый занят своим делом и не должен даже случайно помешать работе коллег. Или же в команде есть один или несколько менее опытных специалистов, которым вы не хотите давать лишние права и свободы. Предположим также, что у вас есть Kubernetes сразу от трех провайдеров. Соответственно, чтобы ограничить права и привести их к общему знаменателю, придется поочередно заходить в каждую панель управления и все прописывать вручную. Согласитесь, не самое продуктивное времяпрепровождение. И чем больше у вас ресурсов, тем муторнее процесс. Tanzu Mission Control позволит руководить разграничением ролей из одного окна. На наш взгляд, очень удобная функция: никто ничего не сломает, если вы случайно забудете где-то указать нужные права.
Кстати, наши коллеги из МТС в своем блоге сравнивали Kubernetes от вендора и open source. Если вы давно хотели узнать, в чем отличия и на что смотреть при выборе welcome.
Компактная работа с логами
Еще один пример из реальной жизни работа с логами. Предположим, в команде также имеется тестировщик. В один прекрасный день он приходит к разработчикам и возвещает: в приложении обнаружен баг, срочно фиксим. Закономерно, что первое, с чем захочет ознакомиться разработчик это логи. Посылать их файлами через электронную почту или Telegram моветон и прошлый век. Mission Control предлагает альтернативу: можно задать разработчику специальные права, чтобы они могли читать логи только в конкретном пространстве имен. В таком случае тестировщику достаточно сказать: в таком-то приложении, в таком-то поле, в таком-то namespace есть баги, и разработчик без труда откроет логи и сможет локализовать проблему. А за счет ограниченных прав не полезет сразу её чинить, если компетенция не позволяет.
В здоровом кластере здоровое приложение
Еще одна отличная возможность Tanzu MC отслеживание здоровья кластера. Судя по предварительным материалам, система позволяет просматривать некоторую статистику. На текущий момент сложно сказать, насколько именно детализированной будет эта информация: пока что все выглядит достаточно скромно и просто. Есть мониторинг загруженности CPU и RAM, показаны статусы всех компонентов. Но даже в таком спартанском виде это очень полезная и эффективная деталь.
Итоги
Разумеется, в лабораторном представлении Mission Control, в, казалось бы, стерильных условиях, наблюдаются некоторые шероховатости. Вы и сами наверняка их заметите, если решитесь пройти работу. Какие-то моменты сделаны недостаточно интуитивно даже администратору со стажем придется вчитаться в мануал, чтобы разобраться в интерфейсе и его возможностях.
Тем не менее, с учетом сложности продукта, его важности и роли, которую ему предстоит сыграть на рынке получилось круто. Чувствуется, что создатели старались наладить рабочий процесс пользователя. Сделать каждый элемент управления максимально функциональным и понятным.
Остается только опробовать Tanzu на тестовом стенде, чтобы реально понять все его плюсы, минусы и нововведения. Как только такая возможность нам представится, мы поделимся с читателями Хабра подробным отчетом о работе с продуктом.

