

В конце прошлого года в Слёрме вышел видеокурс по CI/CD. Авторы курса инженер Southbridge Александр Швалов и старший системный инженер Tinkoff Тимофей Ларкин ответили на вопросы первых студентов.
В частности, обсудили:
- Как работает GitLab runner: сколько задач берёт и сколько ресурсов потребляет, где его лучше размещать и как настроить шаринг между проектами?
- Как настраиваются пайплайны для проектов в монорепозитории? А как в ситуации, когда для каждого микросервиса свой репозиторий?
- Как бороться с тем, что во время сборки артефакта в Docker очень быстро забивается свободное место на диске?
- Когда лучше использовать подход Docker-in-Docker?
- Как организовать доставку и развёртывание сервисов в закрытые окружения заказчика?
Видео с ответами на вопросы смотрите на YouTube. Под катом текстовая версия разговора.
С версии 20.10 Docker Engine стал rootless. Раньше эта фича была экспериментальной, а теперь оказалась в проде. Изменится ли что-то с точки зрения безопасности и сборки Docker-образов без root-привилегий?
Тимофей Ларкин: Я не думаю, что это сильно на что-то повлияет. Возможно, они идут к тому, чтобы появился отдельный сборщик образов от Docker. Но пока мы используем Docker-in-Docker, и, скорее всего, этот Docker-in-Docker в режиме rootless просто не будет запускаться.
Надо смотреть апдейты к документации основных пользователей этих фич, например, того же Gitlab, который сейчас предлагает пользоваться kaniko. Возможно, когда-то функциональность станет достаточно зрелой, Gitlab обновит документацию и напишет, что можно собирать образы ещё и так. Но пока, я думаю, мы до этого не дошли.
Александр Швалов: В документации Gitlab есть открытый баг (issue), мол, давайте включим режим rootless, но официальной поддержки пока нет. Для сборки поддерживается kaniko, и мы добавили пример с kaniko в наш курс.
Дайте пример реального размещения репозиториев с кодом, секретами и helm-чартами где всё должно лежать в жизни? Как выглядит по умолчанию шаблон? Боевой deployment.yml не должен быть в репозитории сервиса?
Тимофей Ларкин: Ответ на такие вопросы всегда it depends зависит от ситуации. Если это open source проект, то там может и не быть деплойментов, там может быть makefile, который покажет, как собрать артефакт, как из него собрать Docker-образ. Но это репозиторий на Github, в лучшем случае он через github actions делает регулярные билды и кладёт их на Docker Hub или другой репозиторий образов контейнеров. Оно и понятно: это просто open source проект, куда его деплоить.
Другое дело, если это проект, который вы деплоите на инфраструктуре: своей, облачной неважно. Например, это приложение, которое разрабатывается и используется у вас в компании. Действительно, довольно простой способ держать и код, и скрипты сборки артефактов, и какой-нибудь helm-чарт в одном репозитории. Разнести по разным папкам, а GitLab CI будет и собирать, и сохранять артефакты, и пушить изменения в Kubernetes.
Подход не очень масштабируемый: когда приложений много, становится тяжело отслеживать, что задеплоено в Kubernetes. Чтобы решить проблему, подключают сервисы вроде Argo CD, а код и описание конфигурации хранят в разных репозиториях. Деплоят через CI (push-модель) или через кубы в Argo.
Когда компания занимается заказной разработкой, всё ещё сложнее. Встаёт вопрос, как деплоить код на инфраструктуру заказчика, и готов ли он принять Continuous Deployment исполнителя или хочет больше контроля? Надо смотреть на специфику.
Александр Швалов: У каждой команды свои стандарты, некоторые сложились исторически, некоторые появились на основе шаблонов или документации. В нашем курсе по CI/CD есть примеры, они рабочие можете адаптировать под свой проект. Исходите из своих потребностей.
Есть ли краткий справочник по полям gitlab-ci файла?
Александр Швалов: Краткого справочника нет, если нужна конкретная фича, лучше идти в документацию и смотреть, что там есть. Ну а базовые принципы как из большого набора кирпичиков собрать свой gitlab-ci.yml вы можете почерпнуть из курса или документации. Если в курсе нет, в документации точно будет.
Тимофей Ларкин: Если есть запрос, такой краткий справочник можно сделать, это несложно. Я бы хотел добавить, что мы изначально не хотели перепечатывать документацию и по возможности старались этого не делать, но всё равно получили некоторое количество негативного фидбека: мол, зачем ваш курс, если я могу всё это в документации прочесть.
Как можно привязать Jira к GitLab?
Александр Швалов: У бесплатной версии GitLab есть интеграция с Jira, ищите в соответствующем разделе.
Тимофей Ларкин: Более того, мы работали одновременно с двумя issue-трекерами: все проекты вязались в Jira, но отдельные команды настраивали для своих репозиториев привязку к YouTrack. Это было не очень удобно, потому что надо было ходить по каждому репозиторию, который хочешь привязать. Но да, такая функциональность действительно есть даже в бесплатном GitLab.
Почему joba release триггерится при изменении тега, хотя в родительском пайплайне стоит only changes?
Александр Швалов: Я провёл небольшое исследование и выяснил: это не баг, это фича. В GitLab был заведён баг, и его закрыли с комментарием, что так задумано. Если вам нужно обойти это поведение, используйте один из двух вариантов, которые предлагает GitLab.
GitLab не обновляет статусы дочерних пайплайнов. Что с этим делать?
Александр Швалов: А вот это уже баг. Возможно, когда-нибудь починят.
Есть ли в GitLab профили переменных? Например, я хочу сделать переменную host, и чтобы она приезжала разная в зависимости от окружения. Есть ли какое-нибудь профилирование? Например, я не хочу называть переменную host_dev, host_prod и host_test, а хочу указать окружение, и оно определённый набор переменных вытащит? Можно ли такое сделать?
Тимофей Ларкин: С ходу на ум мало что приходит. Можно, наверное, какие-то env-файлы держать в репозитории и просто их сорсить в пайплайне.
Нормальная практика называть host_dev, host_prod, host_test и т. д?
Александр Швалов: Скорее всего, есть встроенные переменные. Если у вас описано разделение по окружениям, то встроенная переменная будет знать, как называется окружение.
Тимофей Ларкин: Я не сталкивался с таким наименованием переменных. Это кажется оправданным, только если один пайплайн должен работать одновременно с несколькими разными окружениями. Если просто хочется разного поведения пайплайна в зависимости от ветки или чего угодно ещё
У меня в пайплайне может быть стадия deploy и стадия release, и тогда эти переменные должны быть разные, иначе как?
Тимофей Ларкин: То есть сначала один job деплоит на stage, а потом следующий job деплоит на prod?
Нет, job, который на prod работает, он срабатывает, когда only text. Всё это описано в одном пайплайне.
Тимофей Ларкин: Я решал это ямловскими (YAML прим. редактора) якорями, у меня были очень однотипные jobы из трёх строчек. Или можно теми же extends, как в примере с Docker. А дальше в каждом job пишешь свой блок variables, поэтому основное тело jobа работает с одними и теми же скриптами, но в зависимости от значения переменной host или переменной environment, оно деплоит на разное окружение.
Мы не имеем разные переменные для разных jobов, мы используем одни и те же названия переменных, просто с разными значениями. Возможно, оправдано в репозиторий поместить какие-то скрипты, которые сами внутри себя это разруливают, чтобы не раздувать gitlab-ci.yml.
SSH executor создаётся по одному на сервер?
Тимофей Ларкин: Фактически да. Можно, разве что, поставить какой-нибудь tcp-балансировщик и рандомно попадать на тот или иной сервер.
Имеет смысл разделять раннеры, которые деплоят на test и staging, и раннеры, которые деплоят на prod?
Тимофей Ларкин: Наверное, можно. Действительно, запустить раннеры в разных сетевых сегментах, которые не могут общаться друг с другом. В моей практике это не было нужно. У нас была ориентированная на Kubernetes система, а если речь идёт про SSH на тот сервер, SSH на этот сервер наверное, это будет оправдано.
В Kubernetes вы, наверное, по разным namespace деплоили и всё?
Тимофей Ларкин: Да, но при этом все раннеры в одном и том же месте запускались. Был отдельный namespace для раннеров.
Правильно ли я понимаю, что раннер берёт только одну задачу? Потому что иначе переменные окружения пересекутся.
Тимофей Ларкин: Необязательно, это зависит от того, какой executor работает.
Александр Швалов: Есть параметр concurrency. Если раннер один и идёт долгий пайплайн, то получается, что остальные девелоперы сидят и курят бамбук мы такое проходили, и для обхода настраивали concurrency. В зависимости от ресурсов раннера: сколько jobов он потянет одновременно, можно настраивать.
Он под каждую jobу своё окружение создаст?
Тимофей Ларкин: Да, он либо свой инстанс в bash запустит, либо несколько SSH-подключений, либо несколько Docker-контейнеров или подов в Kubernetes.
Есть ли в Argo CD и других GitOps-инструментах возможность параметризации реакции на изменения? Например, обновлять prod окружение, только если мастер + тэг или если фича, то в dev окружении менять состояние/производить обновления?
Тимофей Ларкин: В вопросе есть очень распространённое заблуждение, я и сам на нём спотыкался. Надо запомнить: не бывает, чтобы у нас был тег на мастер-ветке. Тег никогда на ветке не бывает. Где-то в GitLab даже есть issue, который это очень подробно объясняет. Но это лирическое отступление.
В принципе, Argo CD может что-то похожее сделать. Но надо понимать, что он не совсем про это. Его основная и довольно простая функция это чтобы в таком-то месте (namespace или кластере Kubernetes) была задеплоена такая-то ветка, такой-то тег определённого репозитория.
Как мне показалось, в вопросе речь была о пайплайнах и CI/CD. Но это не основная функциональность Argo, и кажется, он такого не поддерживает. Можно посмотреть на другие GitOps-инструменты. По-моему, у werf от Фланта есть функционал отслеживания что там меняется в Docker-репозитории. Но в целом GitOps это не совсем про это. Вот как в гите опишите, то и будет задеплоено.
На коммит Argo увидит: О! Что-то поменялось, значит надо поменять это и в Kubernetes, но без какой-то сильно ветвистой логики.
Александр Швалов: Я добавлю, что тэг это не ветка, а по смыслу ближе к коммиту. Тут поможет семантическое версионирование, и можно настраивать шаблоны для Argo CD. Если для продакшена, то конкретный релиз: 1.2.0, 1.2.1. Для stage будет 1.2. любая циферка в конце приедет на stage. Для QA это 1. всё остальное приедет. Для совсем свежего, для локальной разработки просто звёздочка *, любой тег Argo CD будет сразу подтягивать.
Какой сканер посоветуете для Docker-образов? Мне trivy понравился, но может что удобнее есть?
Александр Швалов: Я использовал Trivy, нареканий не было.
Как настраиваются пайплайны для проектов в монорепе, и как в ситуации, когда для каждого микросервиса свой репозиторий?
Александр Швалов: Возможно, мы добавим такой пример в курс. Спасибо за запрос! Вообще, ходят слухи, что у Google и Microsoft всё хранилось или хранится в монорепах миллиарды строк кода. Здесь многое зависит от человеческого фактора, а не от инструментов. Если говорить о GitLab CI/CD, то всё просто: в шаге сборки какой-то части, например, фронтенда используем only changes, выбираем каталог и дальше поехали. Что-то изменилось, GitLab производит деплой. С тестами будет посложнее, потому что фронтенд (или какая-то часть, особенно, если это микросервисы) запустится и будет неполноценным. Поэтому для тестов придётся поднимать минимальные зависимости.
Тимофей Ларкин: Я не видел open source систем контроля версий, которые поддерживают такую модель работы, как монорепозиторий. У больших игроков свои системы, и разработчики даже рассказывают: Вот, я работал в Google/Amazon/Facebook, а потом я ушёл оттуда, пошёл в среднего размера компанию, и я не знаю, что делать. Нигде нет магии этих больших систем, которые сами решают все проблемы с версионированием кода. Внезапно я должен работать с тем же GitLab.
Поэтому если вы не огромная корпорация с ресурсом написать свою систему контроля версий, то можно костылить пайплайны, чтобы они были как монорепозитории писать кучу only changes на различные куски. До каких-то масштабов это, наверное, будет работать. Взять тот же Kubernetes, который выпускает свои известные 5 бинарей (и даже чуть больше) с параллельным версионированием. Нет такого, что один компонент в своём репозитории, другой в своём, и у них свой набор версий. Нет, они выпускаются из одного репозитория, поэтому у них хэши комитов, теги и всё остальное одинаковое. Да, так можно работать. Go позволяет собирать несколько бинарников из одного модуля, но в целом так не очень легко работать. Для какого-то проекта да.
В масштабах организации, наверное, у вас есть несколько продуктов, которые логически не связаны и их не стоит пихать в монорепы. По крайней мере, не стоит для этого пытаться использовать GitLab.
Ну и как всегда: если хотите оставаться в парадигме один репозиторий один микросервис, тогда где-то храните метаданные (какой хеш коммита соответствует какому тегу, какому релизу) и с помощью Argo оркестрируйте всё это.
Какие существуют best practices по размещению раннеров? Как лучше организовать размещение нескольких раннеров на одной машине, чтобы можно было добавлять новые? Стоит ли размещать раннеры в Docker-контейнерах, или лучше использовать виртуальные машины, например, kvm?
Александр Швалов: GitLab для раннеров по запросу предлагает использовать Docker Machine, и соответственно использует драйверы оттуда это всяческие облака и виртуализации (AWS, Azure, VirtualBox, Hyper V, vmWare). KVM в списке нет. Для множественных раннеров можно настраивать также шареный кэш. Например, в AWS S3 хранилище.
Однако этот подход через Docker Machine сам GitLab считает малость устаревшим. Есть открытый баг, где разработчики размышляют, куда лучше перейти, какие-то варианты есть. Самый очевидный перейти в Kubernetes. Ну а best practice в общем не размещать раннер на одном хосте с GitLab, чтобы они друг друга не аффектили. Ну и на продакшене раннер тоже лучше не размещать, потому что вдруг туда что-то прилетит критичное.
Для небольших проектов достаточно одного раннера (на своих проектах я так и делал). Просто настроить ему concurrency, чтобы разработчики не стояли в очереди друг за другом, и дать какое-то количество процессора и памяти, настроить опытным путём и так жить.
Тимофей Ларкин: Когда мы пайплайны гоняли в Kubernetes, то мы просто на несколько хостов вешали taint с эффектом PreferNoSchedule, чтобы пользовательские нагрузки приложения запускались преимущественно где-то на других хостах. Но при этом на раннеры мы вешали nodeSelector как раз на эти же самые хосты. Это к вопросу о разделении нагрузки от приложения и нагрузки от раннера.
Да, есть беда, что у сборок совершенно другой профиль нагрузки, чем у обычных приложений. Как правило, сборка это хорошая нагрузка на CPU (обычно именно на CPU, а не на память). Затем идёт сборка Docker-образа, (если мы более-менее всё аккуратно делаем: сначала собрали артефакт, затем его как артефакт передали в следующий этап пайплайна, а затем в Docker-образ кладём готовые бинарники), то идёт нагрузка на диск, потому что там все эти слои формируются, пишутся и, наконец, после этого мы загружаем сеть, перекачивая собранный Docker-образ в наш registry.
Из-за всех этих неровностей лучше раннеры держать подальше от обычных приложений. И они достаточно много ресурсов требуют. Когда мы занимались ограничениями, мы ставили командам лимит 4 ядра, и у них сборка какой-нибудь тяжелой Java существенно замедлялась.
С Kubernetes всё понятно. Мне даже хотелось убрать раннеры из Kubernetes и где-то отжать два хоста, которые использовать как build-серверы, чтобы совсем всё отдельно было. Всякие деплои, понятно, это очень легковесная задача. Запушить ямлик в Kubernetes никаких ресурсов не требует. Ну а если у нас SSH или shell-раннер, то тогда сама ситуация диктует, где их размещать. А если вопрос про бинарь GitLab Runner, то он очень мало ресурсов потребляет, его можно где угодно расположить. Тут больше зависит от требований сетевой доступности.
Когда лучше использовать подход Docker-in-Docker? Какие еще есть инфраструктурные идиомы, связанные с GitLab?
Александр Швалов: Скажу очевидную вещь: использовать Docker-in-Docker стоит, когда у вас сам раннер запущен в Docker. Ну а если у вас нужно запускать какие-то команды в Docker как это задумывалось вообще: если раннер запущен в Docker, то вы можете просто в Docker-in-Docker брать другой Docker-образ (Python, например, и в нём выполнять какие-то действия из кода).
Тимофей Ларкин: Я буду чуть более категоричен. Docker-in-Docker стоит использовать почти никогда. Бывают случаи, когда мне надо собрать кастомный образ kaniko, но когда я пытаюсь собрать его через kaniko, то всё уходит в бесконечную рекурсию и падает (есть такие интересные особенности). Тогда приходится использовать Docker-in-Docker. Кроме того, Docker-in-Docker можно использовать на какой-нибудь виртуалке, которой мы сделали хорошую изоляцию ото всего, чтобы там вообще нельзя было дотянуться ни до инфраструктуры, ни до ещё чего-то, чтобы там можно было только Docker-образы собирать.
В остальных ситуациях Docker-in-Docker это огромная зияющая дыра в безопасности. Очень легко использовать: у тебя есть root-права, у тебя есть привилегии, ты можешь монтировать хостовую файловую систему. Накатал Dockerfile, в котором первым шагом устанавливаешь SSH-демон, прокидываешь туннель туда куда надо, потом заходишь на эту машину и с root-правами монтируешь на эту машину dev/sda1 и всё, у тебя доступ к хосту, ты делаешь что хочешь.
Александр Швалов: Лучше посмотреть в сторону новомодных Podman, Buildah и kaniko. Совсем недавно были новости, что Kubernetes хочет отказаться от Docker все схватились за голову, но это в принципе ожидаемо. И сам Docker (мы с этого начали) уже выкатил rootless mode. Поэтому всеми силами стоит уходить от выполнения от root.
Как можно бороться с тем, что когда происходит сборка артефакта в Docker, очень быстро забивается свободное место на диске (ну кроме docker prune -a)?
Александр Швалов: Только одно решение выделить больше диска, чтобы хватало этого запаса на тот период, когда у вас срабатывает по расписанию сборка мусора. Либо использовать одноразовые раннеры где-то в облаках.
Тимофей Ларкин: Регулярно подчищать за собой:
docker prune -a. Совершенно точно плохая практика
использовать хостовый Docker-демон для этих сборок. Потому что
доступ к хостовому демону это огромная дыра в безопасности, мы
можем делать всё что угодно на хосте от имени рута. Ну и плюс, если
мы для сборки используем хостовый Docker-демон, то он моментально
забивается всяким мусором.
Допустим, даже не используя никакой хостовый Docker-демон, даже имея политику подчистки Docker-образов в GitLab registry, когда мы только стартовали, у нас был раздел под GitLab на 250 Гб. Потом мы стали упираться, сделали отдельный раздел под GitLab на 250 Гб, а под GitLab registry ещё один на 250 Гб. У нас GitLab Omnibus подключал два persistent volume одновременно. Потом раздел под registry разросся до 500 Гб, сейчас он, кажется, 750 Гб и надо узнать у бывших коллег, что у них там происходит хватает места или надо ещё что-то придумывать. И это при том, что есть политика удаления всех, кроме последних пяти тегов какого-то образа. И это без всяких артефактов сборок, это просто конечные образы, которые дальше запускаются на каких-то окружениях.
Как организовать мирроринг стороннего репозитория (например, из GitHub) в GitLab средствами самого GitLab? То есть чтобы автоматически в GitLab подтягивались все изменения, обновления из стороннего репозитория, новые теги и т. д. Без необходимости периодически делать pull руками, без использования скриптов или сторонних решений для автоматизации этого процесса. Если нельзя обойтись без сторонних решений, то какое из них вы бы порекомендовали?
Александр Швалов: Сразу скажу, что полная поддержка этой функциональности есть в платной версии Starter. Для ускорения автоматики можно дополнительно использовать вебхуки в GitHub, чтобы он при каждом чихе тыкал палочкой в GitLab и GitLab в ответ на это делал pull из GitHub. Если надо обойтись исключительно бесплатной версией, то мне не приходилось этим заниматься, скорее всего, придётся использовать дополнительные сторонние скрипты. Сходу можно порекомендовать настроить для этого CI/CD пайплайн: грубо говоря, можно делать операции с гитом на уровне раннера и запускать это всё по расписанию. Но это, конечно, костыль.
Тимофей Ларкин: Я бы не брал этот подход. Это очень способствует плохим практикам. Чаще всего проблемы возникали, когда мы работали с внешними подрядчиками, которые упорно не хотели хранить свой код в нашем GitLab, а хранили его в своём. Поскольку это большая корпорация, собственные TLS-сертификаты самоподписные и так далее, то подрядчик не знает, как их себе в системное хранилище добавить, или ещё какая-то беда в результате всегда было довольно тяжело получить от подрядчика не просто артефакт, а код. Потому что а зачем? а мы попытаемся помиррорить! не работает ладно, тогда будем на своём GitLab работать. Возможно, есть ситуации, когда это важная и нужная функциональность, но частенько это абьюзится.
Какой аппаратный ресурс наиболее востребован для инстанса GitLab в docker-контейнере: процессор, оперативная память или хранилище? А для раннеров?
В случае, если есть только один мощный сервер с мощным
процессором, большим объемом оперативной памяти и большим
хранилищем и еще один-два сервера меньшей мощности с процессорами
послабее, как наиболее оптимально задействовать первый сервер для
развертывания GitLab-инфраструктуры
(то есть самого GitLab и раннеров) и что лучше перенести на сервера
меньшей мощности? Как целесообразно в этом случае размещать
раннеры: в Docker-контейнерах на хосте или в виртуальных машинах
(например, kvm)?
Ориентировочная нагрузка на инстанс GitLab: 100 пользователей, 200
проектов.
Александр Швалов: Как адепт классических решений, я бы предложил KVM как более проверенное решение. Docker-контейнеры для меня это до сих пор что-то эфемерное: сейчас запустил, через 15 минут можно грохнуть. GitLab же должен работать и работать, там вы храните свою конфигурацию. Зачем его поднимать, гасить?
Требования по железу есть у самого GitLab. Для 100 пользователей нужно 2 ядра (хватит до 500 юзеров) и 4 Гб памяти (до 100 юзеров). При расчёте объема диска лучше исходить из простой математики: объём всех репозиториев, которые есть, умножить на 2. И не забыть продумать, как вы будете добавлять к серверу новые диски, если репозитории разрастутся.
Железные требования для раннеров предсказать сложно. Зависит от проектов, что вы там собираете: html-страницы или java-код. Надо взять изначальные требования к сборке и от них отталкиваться. Возможно, стоит взять что-то виртуальное, докинуть ресурсов и настраивать по необходимости.
Тимофей Ларкин: Увидев этот вопрос, я специально попросил у коллег графики по потреблению GitLab. Там всё не так весело. Их инстанс GitLab так-то на 500 пользователей, но реально что-то разрабатывают не более 200 человек. Там безупречно ровная полка ну как, колеблется от 1,5 до 2 ядер на протяжении нескольких дней, возможно, по ночам чутка потише. Полка по памяти в районе 50 Гб тоже довольно стабильно.
То есть возвращаясь к рекомендациям: по ядрам, наверное, они реальны, а по памяти занижены. 4 Гб хватит только для запуска, а для активной работы понадобится гораздо больше. И это даже вместе с тем, что базы данных PostgreSQL, которые под этим GitLab, они сейчас живут на отдельных хостах. Раньше, по моим наблюдениям, процессор загружался гораздо сильнее.
Независимо от способа деплоя я бы запустил GitLab на жирном хосте: нам важна надёжность GitLab, многие его компоненты достаточно прожорливы. На других хостах поменьше, наверное, можно было бы гонять Docker executor.
Интересует деплой не в Kubernetes. Допустим, по SSH или же docker\docker-compose.
Александр Швалов: Да, это популярный запрос. Мы планируем добавить это в наш курс (на момент публикации статьи уже добавили прим. редактора) деплой в простой Docker. Всё делается очень просто: раннер с предварительно настроенными ключами заходит по SSH на хост, делает там docker stop, docker rm (удаляет старый контейнер) и docker run с прямым указанием на конкретный образ, который мы только что собрали. В результате поднимается новый образ.
Голый Docker это не оркестратор, и репликации там нет, поэтому при таком CI/CD у вас будет перерыв в обслуживании. Если у вас нет образа контейнера, в моём примере лучше его запустить самостоятельно.
Тимофей Ларкин: Если интересует совсем голый SSH, то пишите скрипты и запускайте. Можем, наверное, минимальный пример в курс добавить. Но надо понимать, что Kubernetes уйму проблем с оркестрацией решает, ну и Docker тоже достаточно можно решает (перезапуски, healthcheck, что угодно).
Если я был вынужден описывать голый SSH, наверное, я бы запускал что-нибудь через systemd. Да, можно Ansible использовать, но опять же, через тот же systemd.
Александр Швалов:Если ещё нет образа контейнера на хосте (я вспомнил, как это у меня делалось), там тоже через Bash проверяется, есть что-нибудь или нет. Если нет, то делаем docker run без всего; docker run, и конкретный образ из registry, который только что создан. Если что-то есть, то сначала останавливаем это всё, и после этого docker run.
Можно ли контейнер с раннером создавать динамически (только на момент сборки)?
Александр Швалов: Да. Очень популярно брать дешёвые инстансы AWS и запускать раннеры там, а потом их глушить по прошествии какого-то времени. Пошла активная сборка, пошёл деплой, насоздавались раннеры и через какое-то время, когда нагрузки нет, они сами по себе схлопнутся. Это всё реализуется через Docker compose.
Тимофей Ларкин: Мы говорим про GitLab runner, который управляющий бинарник, или мы про сами пайплайны? Ну да, пайплайны, наверное. А сам управляющий бинарь? Тогда что будет триггерить создание этого самого бинаря? Опять возникают проблемы курицы и яйца.
Александр Швалов: В Kubernetes, насколько я знаю, можно через какие-то метрики, когда нагрузка есть, он создаёт Так же для OpenShift я нашёл, есть оператор, который управляет раннерами. Как-то можно автоматизировать, люди движутся в этом направлении. Но, как правило, на простых проектах, если что-то нужно, мы берём и виртуалке добавляем ресурсов, а когда проходит час пик убираем ресурсы.
Тимофей Ларкин: Автоскейлинг нод можно делать. Потому что так-то Docker-контейнеры с пайплайнами создаются автоматически только на время существования пайплайна по дефолту. Управляющий бинарь должен существовать по дефолту. Иначе как кто-то узнает, что надо создавать управляющий бинарь?
Как можно настроить шаринг раннера только между определённым количеством проектов?
Александр Швалов: Для этого в GitLab есть группы, создаёте группу, привязываете раннер и в эту группу добавляете проекты. Доступ юзеров, соответственно, распределяется. Всё просто!
Тимофей Ларкин: Ссылка на issue, где описывается, как это делать. Необязательно даже, чтобы это был раннер на группу. Можно делать раннер на конкретный список репозиториев. Первый создаётся через регистрационный токен на какой-то конкретный репозиторий, но потом, через UI GitLab можно добавить его ещё нескольким. Можно ещё тегами всё это разрулить.
Прошу рассказать, если есть опыт, о практике организации доставки и развертывания сервисов в закрытые окружения заказчика, когда нет возможности прорубить доступ до внутренних репозиториях заказчика. Как при этом упростить доставку артефактов и по максимуму автоматизировать развертывание в условиях, когда Git находится далеко снаружи runtime-окружения?
Александр Швалов: У меня, к сожалению, не было такого опыта. Я знаю, что в серьезных организациях такое сплошь и рядом практикуется. Я могу лишь придумать такой способ: взять артефакт, сделать архив с релизной веткой репозитория, принести на флешке, там есть внутренний GitLab, сделать push в нужную ветку и сделать CI/CD как обычно, только в локальной сети.
Тимофей Ларкин: Вообще, я к таким историям скептически отношусь. Когда заказчик говорит, что у него невероятно секретно, гостайна (номера карт лояльности клиентов) и всё такое, то надо посмеяться и понять, что он врёт, и не работать с такими заказчиками. Но если работать очень надо (в конце концов, нам всем надо счета оплачивать и еду покупать), то есть вариант разместить раннер (управляющий бинарь; и пайплайны тоже будут где-то рядом запускаться) именно внутри контура заказчика.
Раннер умеет работать за NAT, умеет постучаться во внешний GitLab. Главное, чтобы сам GitLab не был за NAT, чтобы была нормальная доступность до GitLab. Поэтому да, раннер может изнутри контура заказчика сходить в ваш GitLab, стянуть код и делать сборку уже внутри инфраструктуры заказчика. И тогда чуть легче: артефакт сборки кладётся во внутренний репозиторий заказчика и оттуда уже деплоится всё хорошо. Не исключено, что там будет много сложностей. Наверняка, у заказчика свои самоподписные TLS-сертификаты, у него интернет недоступен на большинстве хостов (надо будет согласовать proxy, которая позволит раннеру ходить до вашего GitLab) и так далее.
Александр Швалов: Если proxy, NAT недопустимы, то в таком варианте остаётся паковать всё на своей стороне, собирать в инсталлятор, приходить к заказчику и обновлять приложение инсталлятором. Это уже другая задача, к CI/CD она вряд ли относится. Хотя можно настроить CI/CD, чтобы на выходе получался инсталлятор.
Тимофей Ларкин: Ну да, или держать все эти артефакты у себя в инфраструктуре, заказчику выдать публичный или приватный ключ, и просто ему на почту писать: Мы сделали новый этап работы, выложили новую версию, приходите забирайте.
А вообще я считаю, что такая ситуация возможна только в случае, если заказчик заплатил очень большие деньги или менеджер провалил переговоры. Потому что как в таком случае работать: постоянно ездить к заказчику? В принципе, если разработчики готовы ездить на территорию заказчика с флешками, это тоже вариант. Но для меня это фактически deal breaker, если заказчик предложит подобное.
Может нам как-то помочь CI/CD GitLab, если поставщик сам присылает собранные бинари в zip-архиве, и эти бинари необходимо распределить на нужное количество нод? Где это будет работать?
Александр Швалов:Речь о том, что есть в качестве исходного кода бинари в zip-архиве, и GitLab CI будет их каким-то образом распределять? В принципе, такое возможно. Почему нет? Можно это как-то сканировать, тестировать и деплоить, просто по SSH закидывать. В принципе, можно обойтись и без GitLab, одними скриптами.
Тимофей Ларкин: Можно какую-нибудь регулярную jobу запилить, которая, допустим, смотрит на папку, проверяет сумму у zip-архива, если обновилась, распаковывает, раскладывает его на внутренние nexus (приватный docker registry прим. редактора) в виде артефактов. Если надо, деплоит. Да, я думаю, GitLab может помочь в плане автоматизации этого процесса.

 Зомби-режим Outbreak в Call of Duty Black
Ops: Cold War
Зомби-режим Outbreak в Call of Duty Black
Ops: Cold War

 Офис
Lightmap в Ростове-на-Дону
Офис
Lightmap в Ростове-на-Дону Карта Офис в Pixel Gun 3D
Карта Офис в Pixel Gun 3D
 Скриншот концепт-дока
Скриншот концепт-дока
 Создание 2D-концепта в Photoshop
Создание 2D-концепта в Photoshop
 Полотно концептов
Полотно концептов
 и готовый 2D-концепт (справа)") Эскиз (слева) и готовый 2D-концепт (справа)
Эскиз (слева) и готовый 2D-концепт (справа)

 Референсы к ТЗ на оружие
Референсы к ТЗ на оружие

 Выдавленный 2D-концепт
Выдавленный 2D-концепт
 Модель оружия Метатель Топоров и рефы
Модель оружия Метатель Топоров и рефы
 Модель
оружия Молот Тора и рефы
Модель
оружия Молот Тора и рефы
 Проверка на габариты с персонажем
Проверка на габариты с персонажем
 Оптимизированная модель
Оптимизированная модель

 Часть
таблицы с контент-планом
Часть
таблицы с контент-планом

 Анимация профайла
Анимация профайла
 Анимация стрельбы
Анимация стрельбы Анимация перезарядки
Анимация перезарядки



![$\forall n \in [a,b] : n=\sum_0^{len(n)} n_i ^ i, \text{ } n_i\text{ - i-й разряд числа n}$](http://personeltest.ru/aways/habrastorage.org/getpro/habr/formulas/8a2/419/6ef/8a24196ef58b102bdb326c12cb6914e6.svg)
 ETL как он есть
ETL как он есть
 Смотрите, сколько всего можно мерять,
получая простые запросы в вебхук.
Смотрите, сколько всего можно мерять,
получая простые запросы в вебхук.
 Дашборд состояния серверов Sensorpad
средствами Sensorpad
Дашборд состояния серверов Sensorpad
средствами Sensorpad
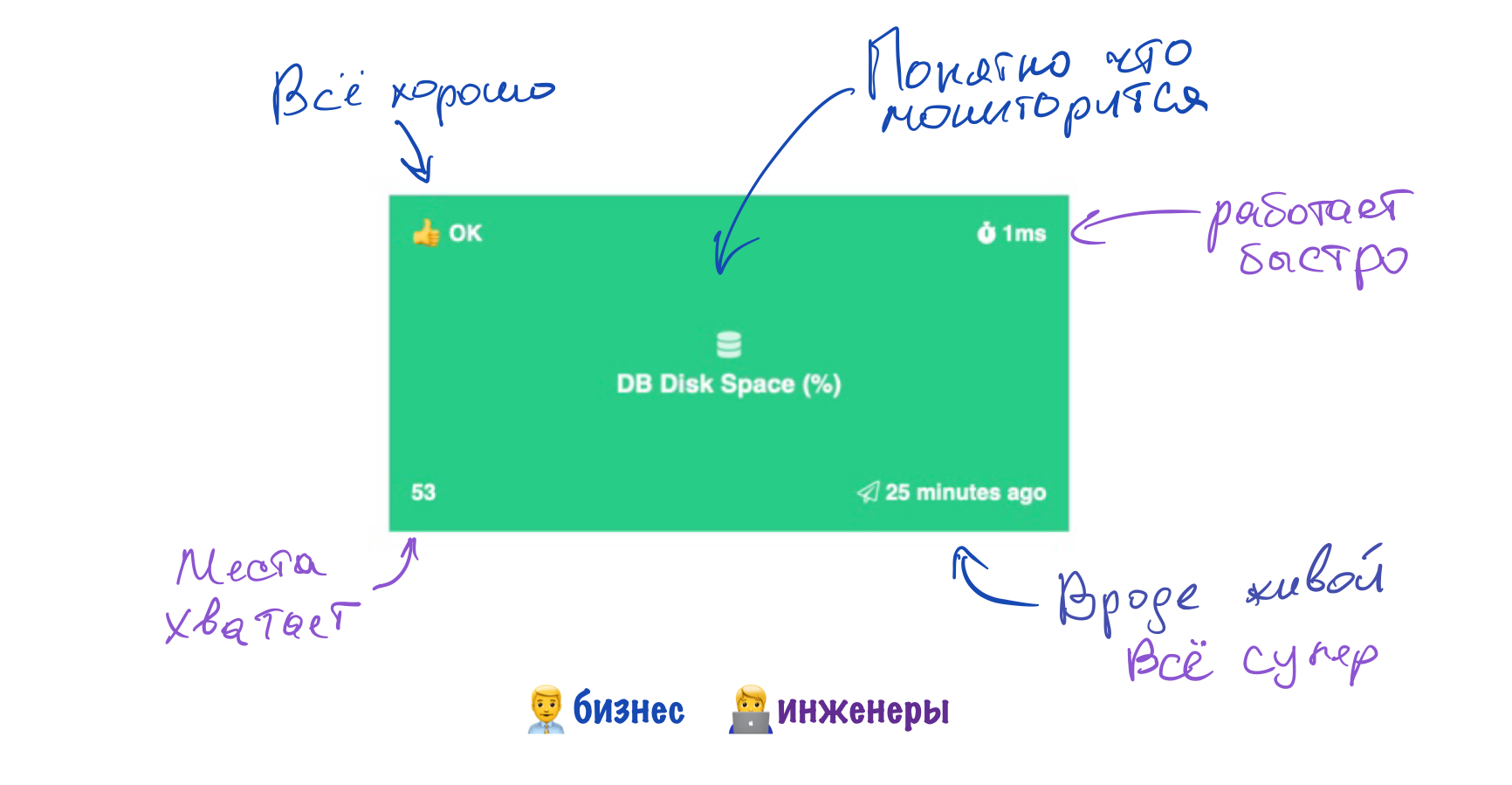
 главное в нашем деле - не усложнять интерфейсы
главное в нашем деле - не усложнять интерфейсы
 Догфудинг в действии
Догфудинг в действии
 Можно даже иконку выбрать
Можно даже иконку выбрать
 Правила для мониторинга места на диске
Правила для мониторинга места на диске


 Немного полезных и не очень графиков
Немного полезных и не очень графиков