
Новогодние бенчмарки компьютеров Эльбрус

Продолжение статьи Большое тестирование процессоров различных архитектур. В этот раз я решил измерить производительность конкретных сред/языков программирования (C#, Java, JavaScript, Python, Lua) на компьютерах с процессорами Эльбрус и сравнить их с компьютерами (даже телефонами) на процессорах архитектурой ARM и X86-64.
Языки программирования:
- C#
- PHP
- JavaScript (Browser, не NodeJS)
- Java
- Python
- Lua
Список тестов
- Dhrystone (http://www.roylongbottom.org.uk/#anchorSource)
- Whetstone (http://www.roylongbottom.org.uk/#anchorSource)
- Scimark 2 (Original sources: https://math.nist.gov/scimark2/download.html)
- Linpack (Based on: https://github.com/fommil/netlib-java/blob/master/perf/src/main/java/com/github/fommil/netlib/Linpack.java)
- Generic:
- Loops
- Conditions
- Arithmetics
- Math
- Array speed
- String manipulation
- Hash algorithms
Но сперва приведу результаты нативных бенчмарков на языке C, а также результаты других популярных бенчмарков.
Тестовые стенды и их процессоры
А пока можете опробовать JavaScript версию бенчмарка: http://laseroid.azurewebsites.net/js-bench/
Стенды на процессорах x86 (i386) х86-64 (amd64):
- Core i7-2600, 4 ядра 8 потоков, 3.4 ГГц
- AMD A6-3650, 4 ядра, 2.6 ГГц
- Atom Z8350, 4 ядра, 1440 МГц
- Core i3-m330, 2 ядра 4 потока, 2.13 ГГц
- Pentium 4 2800, 1 ядро, 2.8 ГГц
- Allwinner A64 (Orange Pi Win), 4 ядра Cortex A53, 1152 МГц
- Qualcomm 625 (Xiaomi Note 4X), 8 ядер, 2 ГГц
- Эльбрус 8С 1300 МГц, 8 ядер
- Эльбрус 8С x4 1300 МГц, 8 ядер (сервер 4 процессорный)
- Эльбрус 8СВ 1550 МГц
- Эльбрус 2С+ 500 МГц, 2 ядра
- Эльбрус 4C 750/800 Мгц, 4 ядра
- Эльбрус 1C+ 985/1000 МГц, 1 ядро
Компилируемые бенчмарки на C/C++
Таблица с результатами с прошлой статьи
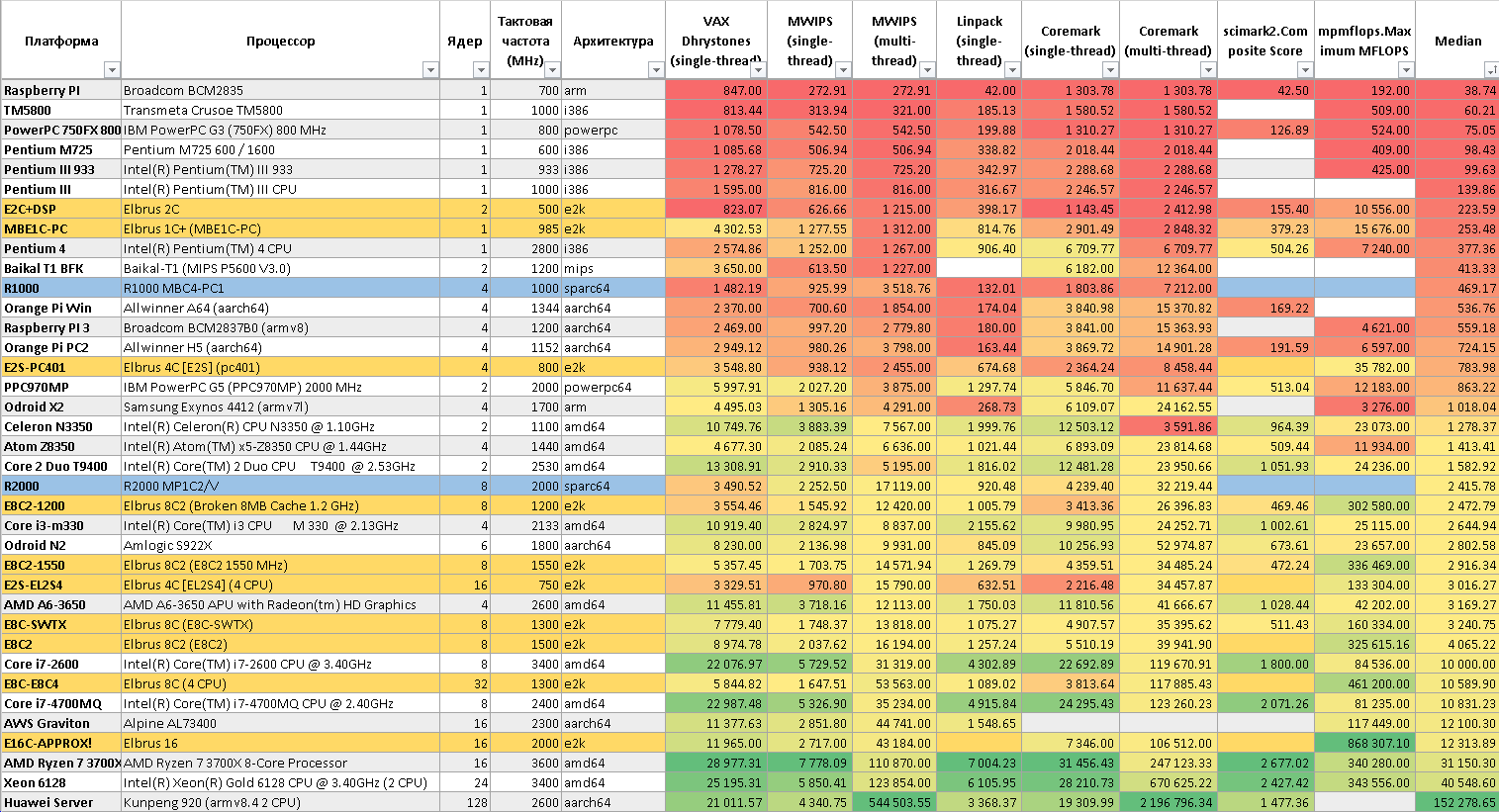
Тут выходит так: компьютеры на Эльбрусах имеют сопоставимую
производительность с Intel Core i7 2600, если бы он работал на
частоте 1200 1300 МГц (Для Эльбрус-8С), кроме теста MP MFLOPS,
который хорошо распараллеливается компилятором LCC
и для Эльбрус 8СВ выдаёт 325 ГФлопс, где Core i7 2600 выдавал
85 ГФлопс (Это с SSE, без AVX).
Задержки кеша. Тест TLB от Линуса Торвальдса
| Cpu | Elbrus 2C+ | Elbrus 4C | Elbrus 8C | Elbrus 8CB | Elbrus R1000 | Allwinner A64 | Amd A6 3650 |
|---|---|---|---|---|---|---|---|
| Freq (MHz) | 500 | 750 | 1300 | 1550 | 1000 | 1152 | 2600 |
| Cores | 2 | 4 | 8 | 8 | 4 | 4 | 4 |
| 4k | 14.02ns | 4.04ns | 2.51ns | 1.94ns | 45.01ns | 3.48ns | 1.16ns |
| 4k cycles | 7.0 | 3.0 | 3.0 | 3.0 | 5.0 | 4.0 | 3.0 |
| 8k | 14.02ns | 4.04ns | 2.51ns | 1.94ns | 5.01ns | 3.48ns | 1.16ns |
| 8k cycles | 7.0 | 3.0 | 3.0 | 3.0 | 5.0 | 4.0 | 3.0 |
| 16k | 14.02ns | 4.04ns | 2.51ns | 1.94ns | 5.01ns | 3.48ns | 1.16ns |
| 16k cycles | 7.0 | 3.0 | 3.0 | 3.0 | 5.0 | 4.0 | 3.0 |
| 32k | 14.03ns | 4.04ns | 2.51ns | 1.94ns | 5.16ns | 3.58ns | 1.16ns |
| 32k cycles | 7.0 | 3.0 | 3.0 | 3.0 | 5.2 | 4.1 | 3.0 |
| 64k | 14.04ns | 4.06ns | 2.51ns | 1.94ns | 23.45ns | 6.83ns | 1.16ns |
| 64k cycles | 7.0 | 3.0 | 3.0 | 3.0 | 23.4 | 7.9 | 3.0 |
| 128k | 18.04ns | 14.83ns | 9.19ns | 7.10ns | 23.75ns | 7.28ns | 4.00ns |
| 128k cycles | 9.0 | 11.1 | 11.0 | 11.0 | 23.7 | 8.4 | 10.4 |
| 256k | 24.97ns | 14.82ns | 9.19ns | 7.10ns | 23.98ns | 7.69ns | 4.00ns |
| 256k cycles | 12.5 | 11.1 | 11.0 | 11.0 | 24.0 | 48.9 | 10.4 |
| 512k | 22.26ns | 14.82ns | 9.28ns | 7.13ns | 24.12ns | 8.04ns | 4.00ns |
| 512k cycles | 11.1 | 11.1 | 11.1 | 11.1 | 24.1 | 9.3 | 10.4 |
| 1M | 67.80ns | 14.83ns | 27.57ns | 21.31ns | 24.07ns | 34.36n | 4.03ns |
| 1M cycles | 33.9 | 11.1 | 33.1 | 33.0 | 24.1 | 39.6 | 10.5 |
| 2M | 106.21ns | 22.49ns | 27.56ns | 21.31ns | 46.62ns | 37.05n | 12.14ns |
| 2M cycles | 53.1 | 16.9 | 33.1 | 33.0 | 46.6 | 42.7 | 31.6 |
| 4M | 107.51ns | 120.65ns | 27.56ns | 21.31ns | 119.53ns | 37.36n | 12.06ns |
| 4M cycles | 53.8 | 90.5 | 33.1 | 33.0 | 119.5 | 43.0 | 31.3 |
| 8M | 107.92ns | 121.18ns | 27.57ns | 21.31ns | 141.08ns | 37.37n | 12.21ns |
| 8M cycles | 54.0 | 90.9 | 33.1 | 33.0 | 141.1 | 43.0 | 31.7 |
| 16M | 107.86ns | 121.27ns | 47.72ns | 31.54ns | 143.90ns | 37.57n | 12.01ns |
| 16M cycles | 53.9 | 90.9 | 57.3 | 48.9 | 143.9 | 43.3 | 31.2 |
| 32M | 107.91ns | 119.22ns | 111.71ns | 117.28ns | 144.34ns | 37.09n | 12.02ns |
| 32M cycles | 54.0 | 89.4 | 134.1 | 181.8 | 144.3 | 42.7 | 31.3 |
| 64M | 107.91ns | 119.48ns | 149.90ns | 117.39ns | 144.36ns | 37.07n | 11.98ns |
| 64M cycles | 54.0 | 89.6 | 179.9 | 182.0 | 144.4 | 42.7 | 31.2 |
| 128M | 107.91ns | 121.75ns | 169.79ns | 117.51ns | 144.42ns | 37.57n | 12.02ns |
| 128M cycles | 54.0 | 91.3 | 203.7 | 182.1 | 144.4 | 43.3 | 31.3 |
| 256M | 107.97ns | 122.11ns | 174.90ns | 117.58ns | 144.34ns | 37.77n | 12.21ns |
| 256M cycles | 54.0 | 91.6 | 209.9 | 182.3 | 144.3 | 43.5 | 31.7 |
Задержки кеша на Эльбруса 8СВ таковы:
- L1: 3 такта с 1,94 нс
- L2: 11 тактов с 7,1 нс
- L3: 3 такта с 21,31 нс
- ОЗУ: 90-180 тактов с 117 нс
Характеристики кеша для Эльбрус 8С можно посмотреть здесь: Архитектура Эльбрус 8С
Исходный код: Test TLB
Тесты памяти STREAM
Array size = 10000000 (elements), Offset = 0 (elements)
Memory per array = 76.3 MiB (= 0.1 GiB).
Total memory required = 228.9 MiB (= 0.2 GiB).
| CPU | Frequency | Threads | Memory Type | Copy (MB/s) | Scale (MB/s) | Add (MB/s) | Triad (MB/s) |
|---|---|---|---|---|---|---|---|
| Elbrus 4C | 750 | 4 | DDR3-1600 | 9 436.30 | 9 559.70 | 10 368.50 | 10 464.80 |
| Elbrus 8C | 1300 | 8 | DDR3-1600 | 11 406.70 | 11 351.70 | 12 207.50 | 12 355.10 |
| Elbrus 8CB | 1550 | 8 | DDR4-2400 | 23 181.80 | 22 965.20 | 25 423.90 | 25 710.20 |
| Allwinner A64 | 1152 | 4 | LPDDR3-800 | 2 419.90 | 2 421.30 | 2 112.70 | 2 110.10 |
| AMD A6-3650 | 2600 | 4 | DDR3-1333 | 6 563.60 | 6 587.90 | 7 202.80 | 7 088.00 |
Исходный код: STREAM
Geekbench 4/5 (В режиме RTC: x86 -> e2k трансляция)
Geekbench 5
| CPU | Frequency | Threads | Single Thread | Multi Thread |
|---|---|---|---|---|
| Эльбрус 8С | 1300 | 8 | 142 | 941 |
| Эльбрус 8СВ | 1550 | 8 | 159 | 1100 |
| Intel Core i7 2600 | 3440 | 8 | 720 | 2845 |
| Amd A6 3650 | 2600 | 4 | 345 | 1200 |
Geekbench 4
| CPU | Frequency | Threads | Single Thread | Multi Thread |
|---|---|---|---|---|
| Эльбрус 8С | 1300 | 8 | 873 | 3398 |
| Эльбрус 8СВ | 1550 | 8 | 983 | 4042 |
| Intel Pentium 4 | 2800 | 1 | 795 | 766 |
| Intel Core i7 2600 | 3440 | 8 | 3702 | 12063 |
| Qualcomm 625 | 2000 | 8 | 852 | 2829 |
Crystal Mark 2004 (В режиме RTC: x86 -> e2k трансляция)
| CPU | Threads | Frequency | ALU | FPU | MEM R (Mb/s) | MEM W (Mb/s) | Anounced |
|---|---|---|---|---|---|---|---|
| 486 DX4 | 1 | 75 | 119 | 77 | 9 | 11 | 1993 |
| P1 (P54C) | 1 | 200 | 484 | 420 | 80 | 65 | 1994 |
| P1 MMX (P55C) | 1 | 233 | 675 | 686 | 112 | 75 | 1997 |
| P2 | 1 | 400 | 1219 | 1260 | 222 | 150 | 1998 |
| Transmeta Crusoe TM5800 | 1 | 1000 | 2347 | 1689 | 405 | 223 | 2000 |
| P3 (Coopermine) | 1 | 1000 | 3440 | 3730 | 355 | 170 | 2000 |
| P4 (Willamete) | 1 | 1600 | 3496 | 4110 | 1385 | 662 | 2001 |
| Celeron (Willamete) | 1 | 1800 | 3934 | 4594 | 1457 | 657 | 2001 |
| Athlon XP (Palomino) | 1 | 1400 | 4450 | 6220 | 430 | 520 | 2001 |
| P4 (Northwood) | 1 | 2400 | 5661 | 6747 | 1765 | 754 | 2002 |
| P4 (Prescott) | 1 | 2800 | 5908 | 6929 | 3744 | 851 | 2004 |
| Athlon 64 (Venice) | 1 | 1800 | 6699 | 7446 | 1778 | 906 | 2005 |
| Celeron 530 (Conroe-L) | 1 | 1733 | 7806 | 9117 | 3075 | 1226 | 2006 |
| P4 (Prescott) | 2 | 3000 | 9719 | 10233 | 3373 | 1578 | 2004 |
| Atom D525 | 4 | 1800 | 10505 | 7605 | 3407 | 1300 | 2010 |
| Athlon 64 X2 (Brisbane) | 2 | 2300 | 16713 | 19066 | 3973 | 2728 | 2007 |
| Core i3-6100 | 2 | 3700 | 17232 | 10484 | 5553 | 9594 | 2015 |
| Pentium T3200 (Merom) | 2 | 2000 | 20702 | 18063 | 4150 | 1598 | 2008 |
| Atom x5-Z8350 | 4 | 1440 | 21894 | 18018 | 4799 | 2048 | 2016 |
| Core i3-M330 | 4 | 2133 | 25595 | 26627 | 6807 | 4257 | 2010 |
| Core 2 Duo | 2 | 3160 | 28105 | 18196 | 6850 | 2845 | 2008 |
| Atom Z3795 | 4 | 1600 | 40231 | 34963 | 12060 | 5797 | 2016 |
| AMD A6-3650 | 4 | 2600 | 46978 | 35315 | 9711 | 3870 | 2011 |
| Core 2 Quad | 4 | 2833 | 47974 | 31391 | 9710 | 5493 | 2008 |
| Core i3-4130 | 4 | 3400 | 54296 | 39163 | 19450 | 9269 | 2013 |
| AMD Phenom II X4 965 (Agena) | 4 | 3400 | 59098 | 56272 | 11162 | 5973 | 2009 |
| Core i7-2600 | 8 | 3400 | 95369 | 71648 | 19547 | 9600 | 2011 |
| Core i7-9900K | 16 | 3600 | 270445 | 238256 | 44618 | 17900 | 2018 |
| Elbrus-8C RTC-x86 | 8 | 1300 | 65817 | 29977 | 49800 | 7945 | 2016 |
| Elbrus-8CB RTC-x86 | 8 | 1500 | 77481 | 37972 | 62100 | 13940 | 2018 |
| Elbrus-1C+ RTC-x86 | 1 | 1000 | 6862 | 2735 | 6230 | 1800 | 2015 |
Процессор Эльбрус-8С 1.3 ГГц на уровне AMD Phenom II X4 965 3.4 ГГц 4 ядра. 8СВ на 20% быстрее.
Бенчмарки сред/языков программирования
А теперь переходим к бенчмаркам языков программирования (C#, Java, JavaScript, Python, Lua).
Исходный код здесь: https://github.com/EntityFX/EntityFX-Bench
Исходный код для прощлых бенчмарков можете найти тут: https://github.com/EntityFX/anybench
Микро бенчмарки
В цикле с большим числоv итераций проводим некоторые операции и замеряем время выполнения данного куска кода. Ниже буду приводить примеры на языке Python.
Arithmetics
Замеряет скорость арифметики: в цикле выполняет различные математические операции с замером времени выполнения.
Пример кода на Python:
@staticmethod def _doArithmetics(i : int) -> float: return math.floor(i / 10) * math.floor(i / 100) * math.floor(i / 100) * math.floor(i / 100) * 1.11) + math.floor(i / 100) * math.floor(i / 1000) * math.floor(i / 1000) * 2.22 - i * math.floor(i / 10000) * 3.33 + i * 5.33
Math
Замеряет скорость математических функций (Cos, Sin, Tan, Log, Power, Sqrt):
@staticmethod def _doMath(i : int, li : float) -> float: rev = 1.0 / (i + 1.0) return (math.fabs(i) * math.acos(rev) * math.asin(rev) * math.atan(rev) + math.floor(li) + math.exp(rev) * math.cos(i) * math.sin(i) * math.pi) + math.sqrt(i)
Loops
Замеряет скорость работы холостых циклов. Кстати, некоторые компиляторы и рантаймы могут оптимизировать этот код.
Conditions
Замеряет скорость работы условий.
d = 0 i = 0; c = -1 while i < self._iterrations: c = ((-1 if c == (-4) else c)) if (i == (-1)): d = 3 elif (i == (-2)): d = 2 elif (i == (-3)): d = 1 d = (d + 1) i += 1; c -= 1 return d
Array speed (Memory, Random Memory)
Замеряет скорость чтения из массива в переменную (последовательно или со случайными индексами)
def _measureArrayRead(self, size) : block_size = 16 i = [0] * block_size array0_ = list(map(lambda x: random.randint(-2147483647, 2147483647), range(0, size))) end = len(array0_) - 1 k0 = math.floor(size / 1024) k1 = 1 if k0 == 0 else k0 iter_internal = math.floor(self._iterrations / k1) iter_internal = 1 if iter_internal == 0 else iter_internal idx = 0 while idx < end: i[0] = (array0_[idx]) i[1] = (array0_[idx + 1]) i[2] = (array0_[idx + 2]) i[3] = (array0_[idx + 3]) i[4] = (array0_[idx + 4]) i[5] = (array0_[idx + 5]) i[6] = (array0_[idx + 6]) i[7] = (array0_[idx + 7]) i[8] = (array0_[idx + 8]) i[9] = (array0_[idx + 9]) i[0xA] = (array0_[idx + 0xA]) i[0xB] = (array0_[idx + 0xB]) i[0xC] = (array0_[idx + 0xC]) i[0xD] = (array0_[idx + 0xD]) i[0xE] = (array0_[idx + 0xE]) i[0xF] = (array0_[idx + 0xF]) idx += block_size start = time.time() it = 0 while it < iter_internal: idx = 0 while idx < end: i[0] = (array0_[idx]) i[1] = (array0_[idx + 1]) i[2] = (array0_[idx + 2]) i[3] = (array0_[idx + 3]) i[4] = (array0_[idx + 4]) i[5] = (array0_[idx + 5]) i[6] = (array0_[idx + 6]) i[7] = (array0_[idx + 7]) i[8] = (array0_[idx + 8]) i[9] = (array0_[idx + 9]) i[0xA] = (array0_[idx + 0xA]) i[0xB] = (array0_[idx + 0xB]) i[0xC] = (array0_[idx + 0xC]) i[0xD] = (array0_[idx + 0xD]) i[0xE] = (array0_[idx + 0xE]) i[0xF] = (array0_[idx + 0xF]) idx += block_size it += 1 elapsed = time.time() - start return (iter_internal * len(array0_) * 4 / elapsed / 1024 / 1024, i)
String manipulation
Скорость работы со строковыми функциями (replace, upper, lower)
@staticmethod def _doStringManipilation(str0_ : str) -> str: return ("/".join(str0_.split(' ')).replace("/", "_").upper() + "AAA").lower().replace("aaa", ".")
Hash algorithms
Алгоритмы SHA1 и SHA256 над байтами строк.
@staticmethod def _doHash(i : int, prepared_bytes): hashlib.sha1() sha1_hash = hashlib.sha1(prepared_bytes[i % 3]).digest() sha256_hash = hashlib.sha256(prepared_bytes[(i + 1) % 3]).digest() return sha1_hash + sha256_hash
Комплексные бенчмарки
Выполнил реализацию популярных бенчмарков Dhrystone, Whetstone, LINPACK, Scimark 2 на всех 5 языках программирования (конечно же использовал существующие исходники, но адаптировал под мои тесты).
Dhrystone
Dhrystone синтетический тест, который был написан Reinhold P. Weicker в 1984 году.
Данный тест не использует операции с плавающей запятой, а версия 2.1 написана так, чтобы исключить возможность сильных оптимизаций при компиляции.
Бенчмарк выдаёт результаты в VAX Dhrystones в секунду, где 1 VAX DMIPS = Dhrystones в секунду делить на 1757.
Whetstone
Whetstone синтетический тест, который был написан Harold Curnow в 1972 году на языке Fortran.
Позже был переписан на языке C Roy Longbottom. Данный тест выдаёт результаты в MWIPS,
также промежуточные результаты в MOPS (Миллионов операций в секунду) и MFLOPS (Миллионы вещественных операций с плавающей запятой в секунду).
Данный тест производит различные подсчёты: производительность целочисленных и операций с плавающей запятой,
производительность операций с массивами, с условным оператором, производительность тригонометрических функций и функций возведения в степень, логарифмов и извлечения корня.
LINPACK
LINPACK тест, который был написан Jack Dongarra на языке Fortran в 70х годах, позже переписан на язык C.
Тест считает системы линейных уравнений, делает различные операции над двумерными (матрицами) и одномерными (векторами).
Используется реализация Linpack 2000x2000.
Scimark 2
SciMark 2 набор тестов на языке C измеряющий производительность кода встречающегося в научных и профессиональных приложениях. Содержит в себе 5 вычислительных тестов: FFT (быстрое преобразование Фурье), Gauss-Seidel relaxation (Метод Гаусса Зейделя для решения СЛАУ), Sparse matrix-multiply (Умножение разреженных матриц), Monte Carlo integration (Интегрирование методом Монте-Карло), и LU factorization (LU-разложение).
Переходим к результатам.
Результаты
Бенчмарки Java
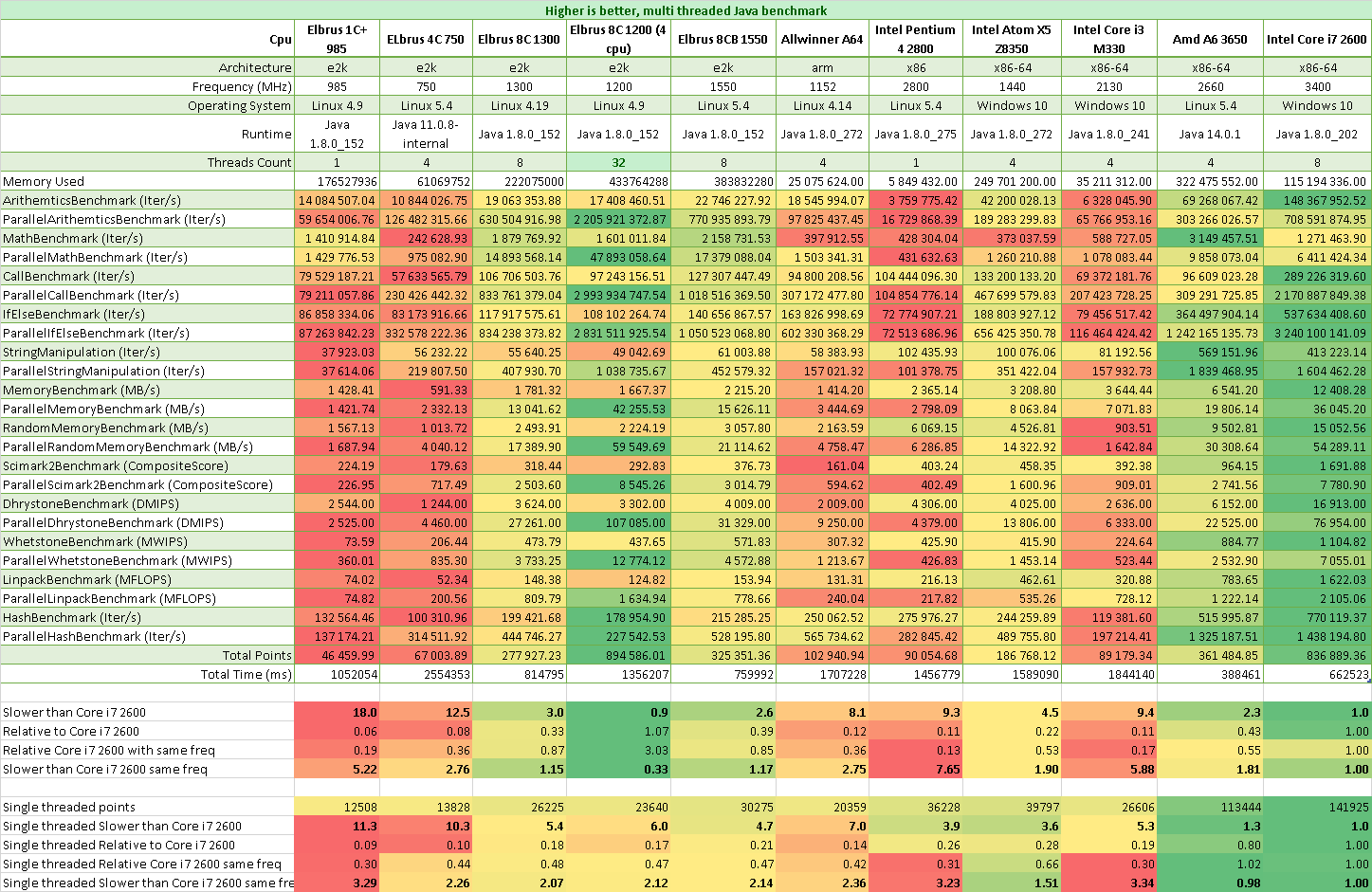
Результаты Java на Эльбрусах в сравнении с Core i7 2600 4 ядра, 8 потоков 3.4 ГГц:
- Эльбрус 1С+ в 11 раз медленнее на 1 поток
- Эльбрус 4С в 10 раз медленнее на 1 поток
- Эльбрус 8С в 5,5 раз медленнее на 1 поток
- Эльбрус 8СВ в 4,5 раз медленнее на 1 поток
- Эльбрус 1С+ в 18 раз медленнее на всех потоках
- Эльбрус 4С в 12,5 раз медленнее на всех потоках
- Эльбрус 8С в 3 раз медленнее на всех потоках
- Эльбрус 8СВ в 2,5 раз медленнее на всех потоках
Результаты Java на Эльбрусах в сравнении с Core i7 2600 4 ядра, 8 потоков, но на одинаковых частотах:
- Эльбрус 1С+ в 3,5 раз медленнее на 1 поток Core i7 2600 на частоте 1 ГГц
- Эльбрус 4С в 2,5 раз медленнее на 1 поток Core i7 2600 на частоте 0,8 ГГц
- Эльбрус 8С в 2 раз медленнее на 1 поток Core i7 2600 на частоте 1,3 ГГц
- Эльбрус 8СВ в 2 раз медленнее на 1 поток Core i7 2600 на частоте 1,55 ГГц
- Эльбрус 1С+ в 5 раз медленнее на всех потоках Core i7 2600 на частоте 1 ГГц
- Эльбрус 4С в 2,75 раз медленнее на всех потоках Core i7 2600 на частоте 0,8 ГГц
- Эльбрус 8С в 1,15 раз медленнее на всех потоках Core i7 2600 на частоте 1,3 ГГц
- Эльбрус 8СВ в 1,15 раз медленнее на всех потоках Core i7 2600 на частоте 1,55 ГГц
Для Java делали очень серьёзные оптимизации, поэтому отставание в 2 раза на одинаковых частотах не является плохим результатом.
Про то, как оптимизировали Java можно почитать тут: Java на Эльбрусе
Посмотреть здесь:
Бенчмарки C# (.Net Framework, .Net Core, Mono)

Так как сред исполнения несколько (.Net Framework, .Net Core, Mono), то я старался сравнивать одинаковые среды исполнения, т. е. Mono на e2k c Mono на x86.
Результаты C# (Mono) на Эльбрусах в сравнении с Core i7 2600 4 ядра, 8 потоков 3.4 ГГц:
- Эльбрус 1С+ в 15,5 раз медленнее на 1 поток
- Эльбрус 4С в 19 раз медленнее на 1 поток
- Эльбрус 8С в 10,5 раз медленнее на 1 поток
- Эльбрус 8СВ в 8 раз медленнее на 1 поток
- Эльбрус 1С+ в 24 раз медленнее на всех потоках
- Эльбрус 4С в 12,5 раз медленнее на всех потоках
- Эльбрус 8С в 4,5 раз медленнее на всех потоках
- Эльбрус 8СВ в 4 раз медленнее на всех потоках
Результаты C# (Mono) на Эльбрусах в сравнении с Core i7 2600 4 ядра, 8 потоков, но на одинаковых частотах:
- Эльбрус 1С+ в 4,5 раз медленнее на 1 поток Core i7 2600 на частоте 1 ГГц
- Эльбрус 4С в 4,2 раз медленнее на 1 поток Core i7 2600 на частоте 0,8 ГГц
- Эльбрус 8С в 3 раз медленнее на 1 поток Core i7 2600 на частоте 1,3 ГГц
- Эльбрус 8СВ в 3 раза медленнее на 1 поток Core i7 2600 на частоте 1,55 ГГц
- Эльбрус 1С+ в 7 раз медленнее на всех потоках Core i7 2600 на частоте 1 ГГц
- Эльбрус 4С в 3 раза медленнее на всех потоках Core i7 2600 на частоте 0,8 ГГц
- Эльбрус 8С в 1,5 раз медленнее на всех потоках Core i7 2600 на частоте 1,3 ГГц
- Эльбрус 8СВ в 1,2 раз медленнее на всех потоках Core i7 2600 на частоте 1,55 ГГц
Результаты C# (NetCore) в режиме RTC на Эльбрусах в сравнении с Core i7 2600 4 ядра, 8 потоков 3.4 ГГц:
- Эльбрус 8С в 3,5 раз медленнее на 1 поток Core i7 2600 на частоте 1,3 ГГц
- Эльбрус 8СВ в 3 раз медленнее на 1 поток Core i7 2600 на частоте 1,55 ГГц
- Эльбрус 8С в 2 раз медленнее на всех потоках Core i7 2600 на частоте 1,3 ГГц
- Эльбрус 8СВ в 1,5 раз медленнее на всех потоках Core i7 2600 на частоте 1,55 ГГц
Результаты C# (NetCore) в режиме RTC на Эльбрусах в сравнении с Core i7 2600 4 ядра, 8 потоков, но на одинаковых частотах:
- Эльбрус 8С в 1,3 раз медленнее на 1 поток Core i7 2600 на частоте 1,3 ГГц
- Эльбрус 8СВ в 1,2 раз медленнее на 1 поток Core i7 2600 на частоте 1,55 ГГц
- Эльбрус 8С в 1,25 раза быстрее на всех потоках Core i7 2600 на частоте 1,3 ГГц
- Эльбрус 8СВ в 1,25 раза быстрее на всех потоках Core i7 2600 на частоте 1,55 ГГц
Mono сам по себе является достаточно медленной средой выполнения по сравнению с Net Fremework, а особенно с NetCore (до 3х раз). Что достаточно допустимо. Здесь я не знаю, делали ли оптимизации как это было сделано с Java.
Выходит NetCore в режиме RTC на Эльбрусах работает до 4х раз быстрее чем Mono. Будем ждать нативного NetCore для e2k.
Бенчмарки JavaScript (Браузерные)
JavaScript версия бенчмарка: http://laseroid.azurewebsites.net/js-bench/
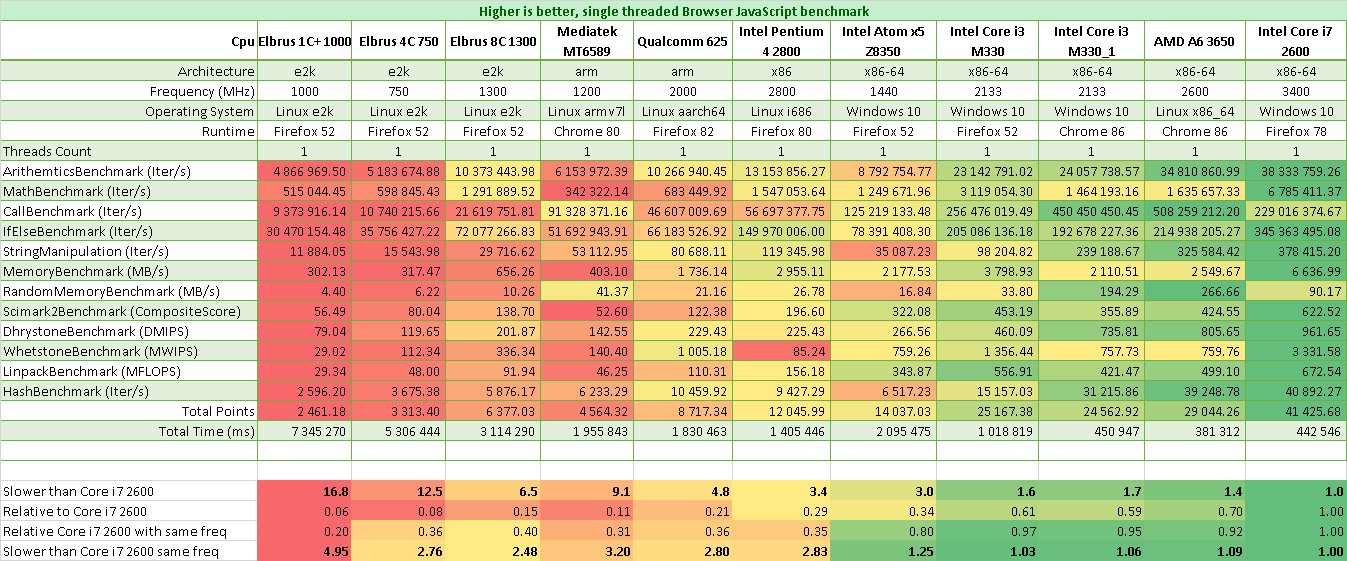
Результаты JavaScript на Эльбрусах в сравнении с Core i7 2600 4 ядра, 8 потоков 3.4 ГГц:
- Эльбрус 1С+ в 16 раз медленнее
- Эльбрус 4С в 12,5 раз медленнее
- Эльбрус 8С в 6,5 раз медленнее
- Эльбрус 8СВ в 5 раз медленнее
Результаты JavaScript на Эльбрусах в сравнении с Core i7 2600 4 ядра, 8 потоков, но на одинаковых частотах:
- Эльбрус 1С+ в 5 раз медленнее Core i7 2600 на частоте 1 ГГц
- Эльбрус 4С в 2,75 раза медленнее Core i7 2600 на частоте 0,8 ГГц
- Эльбрус 8С в 2,5 раза медленнее Core i7 2600 на частоте 1,3 ГГц
- Эльбрус 8СВ в 2,25 раз медленнее Core i7 2600 на частоте 1,55 ГГц
Другие популярные JavaScript бенчмарки
Firefox (версии разные)
| Cpu | Result (баллы) |
|---|---|
| Intel Core i7 2600 | 23321 |
| AMD A6-3650 | 11741 |
| Intel Pentium 4 2800 | 3387 |
| Elbrus 8C (rtc x86 32bit) | 2815 |
| Elbrus 8C | 2102 |
| Elbrus 1C+ | 739 |
Firefox (версии разные)
| Cpu | Result (ms) |
|---|---|
| Elbrus 8C | 10493.4 |
| Elbrus 8CB RTX x86 | 9567.5 |
| Elbrus 8CB | 8714.2 |
| Intel Pentium 4 2800 | 9486.6 |
| AMD A6-3650 | 3052.5 |
| Intel Core i7 2600 (3.4 GHz) | 1456.8 |
Firefox (версии разные)
| Cpu | Result (ms) |
|---|---|
| Elbrus 8C | 3059.8 |
| Elbrus 8CB | 2394.6 |
| Intel Pentium 4 2800 | 1295.5 |
| AMD A6-3650 | 485.6 |
| Intel Core i7 2600 (3.4 GHz) | 242.9 |
Результаты слабоваты. Причина: низкие тактовые частоты и недостаточная оптимизация. Но это гораздо лучше, чем было раньше. Также браузер FX52 уже старый, а будет новая, надеюсь, там уже допилили JavaScript.
Бенчмарки PHP
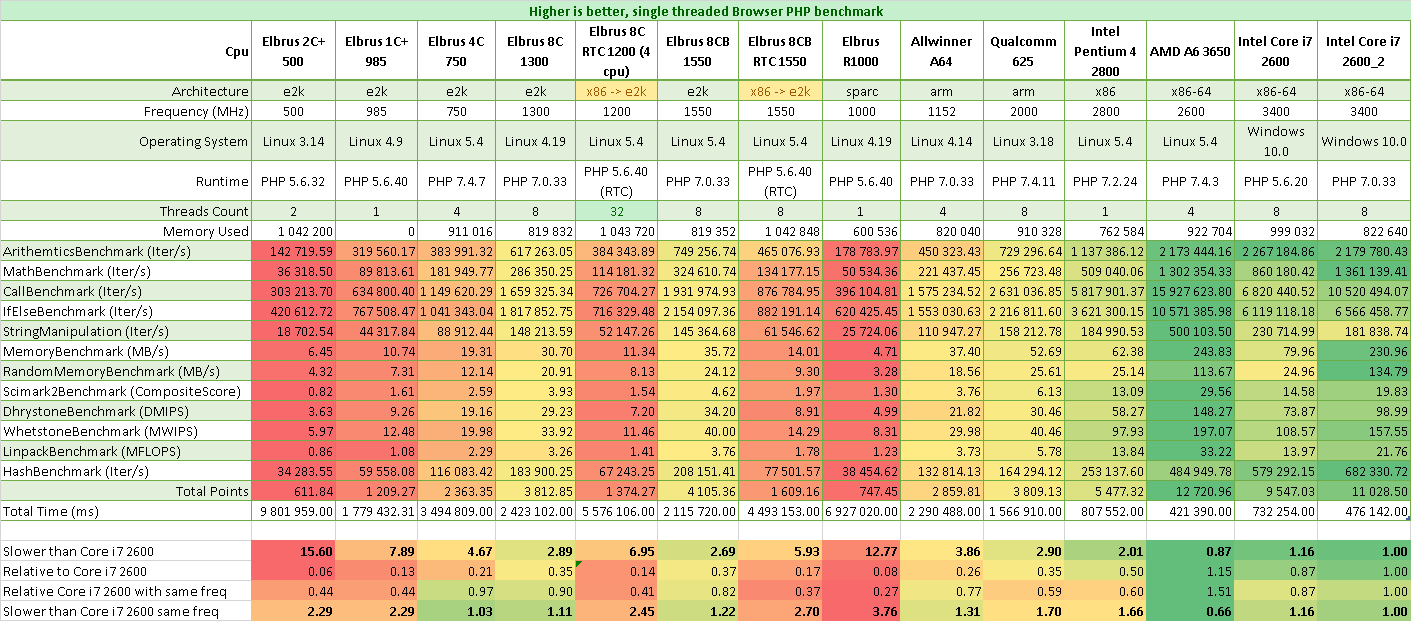
Результаты PHP на Эльбрусах в сравнении с Core i7 2600 3.4 ГГц:
- Эльбрус 2С+ в 15,5 раз медленнее
- Эльбрус 1С+ в 8 раз медленнее
- Эльбрус 4С в 4,5 раза медленнее
- Эльбрус 8С в 3 раза медленнее
- Эльбрус 8СВ в 2,5 раза медленнее
- Эльбрус R1000 в 12,5 раз медленнее
Результаты PHP на Эльбрусах в сравнении с Core i7 2600, но на одинаковых частотах:
- Эльбрус 2С+ в 2,3 раз медленнее Core i7 2600 на частоте 0,5 ГГц
- Эльбрус 1С+ в 2,3 раз медленнее Core i7 2600 на частоте 1 ГГц
- Эльбрус 4С = Core i7 2600 на частоте 0,8 ГГц
- Эльбрус 8С в 1,1 раза медленнее Core i7 2600 на частоте 1,3 ГГц
- Эльбрус 8СВ в 1,1 раза медленнее Core i7 2600 на частоте 1,55 ГГц
- Эльбрус R1000 в 3,75 раз медленнее Core i7 2600 на частоте 1 ГГц
PHP показывает почти равную скорость на одинаковых частотах с Intel процессорами. Причина проста: здесь МЦСТ делали оптимизацию. Очень удивительно для интерпретируемого языка. Кстати, хочу обратить внимание на то что PHP 7.4 стал быстрее версии PHP 5.6 в 1,5 раза, поэтому я запускал бенчмарки на 2х версиях на Core i7 2600.
Другие популярные PHP бенчмарки
| Test | Elbrus 8C | Elbrus 8CB | Pentium 4 2800 | AMD A6-3650 | Core i7-2600 | Allwinner A64 | |
|---|---|---|---|---|---|---|---|
| Frequency | 1300 | 1550 | 2800 | 2600 | 3400 | 1152 | |
| CPU Threads | 8 | 8 | 1 | 4 | 8 (4) | 4 | |
| Version | 7.0.33 | 7.0.33 | 7.2.24 | 7.4.3 | 7.0.33 | 5.6.20 | 7.0.33 |
| 01_math (kOp/s) | 58.15 | 69.72 | 104.19 | 295.97 | 308.94 | 131.73 | 44.33 |
| 02_string_concat (MOp/s) | 3.56 | 3.92 | 4.00 | 13.15 | 5.52 | 0.56 | 3.07 |
| 03_1_string_number_concat (kOp/s) | 418.29 | 472.77 | 631.10 | 1510.00 | 1680.00 | 1600.00 | 332.99 |
| 03_2_string_number_format (kOp/s) | 506.39 | 573.89 | 724.44 | 1690.00 | 1810.00 | 1620.00 | 432.88 |
| 04_string_simple_functions (kOp/s) | 77.06 | 91.50 | 198.03 | 332.67 | 39.12 | 57.60 | 59.48 |
| 05_string_multibyte (kOp/s) | 2.48 | 2.90 | -.-- | 57.53 | 11.01 | 12.77 | 2.50 |
| 06_string_manipulation (kOp/s) | 22.10 | 26.91 | 78.96 | 127.08 | 14.11 | 23.96 | 35.73 |
| 07_regex (kOp/s) | 48.24 | 54.60 | 128.41 | 233.76 | 334.99 | 62.43 | 47.64 |
| 08_1_hashing (kOp/s) | 113.58 | 132.62 | 180.46 | 306.24 | 345.52 | 270.31 | 71.44 |
| 08_2_crypt (Op/s) | 361.21 | 403.62 | 571.99 | 813.60 | 460.00 | 454.15 | 238.00 |
| 09_json_encode (kOp/s) | -.-- | -.-- | 88.33 | 233.62 | 313.52 | 191.66 | 48.67 |
| 10_json_decode (kOp/s) | -.-- | -.-- | 68.02 | 143.01 | 211.62 | 94.15 | 33.57 |
| 11_serialize (kOp/s) | 73.67 | 81.57 | 130.16 | 307.52 | 435.66 | 263.06 | 62.20 |
| 12_unserialize (kOp/s) | 63.89 | 69.02 | 79.33 | 301.98 | 348.62 | 258.75 | 46.21 |
| 13_array_fill (MOp/s) | 2.08 | 2.50 | 5.30 | 9.69 | 14.07 | 5.35 | 1.97 |
| 14_array_range (kOp/s) | 50.36 | 57.54 | 31.68 | 61.01 | 1140.00 | 30.35 | 25.25 |
| 14_array_unset (MOp/s) | 2.08 | 2.48 | 7.17 | 14.05 | 14.45 | 7.32 | 2.16 |
| 15_loops (MOp/s) | 13.57 | 16.21 | 38.75 | 150.46 | 78.92 | 42.54 | 12.64 |
| 16_loop_ifelse (MOps/s) | 4.74 | 5.64 | 13.41 | 28.34 | 19.04 | 18.72 | 4.48 |
| 17_loop_ternary (MOp/s) | 3.18 | 3.79 | 7.29 | 12.10 | 11.40 | 11.85 | 2.90 |
| 18_1_loop_defined_access (MOp/s) | 3.28 | 3.90 | 9.03 | 18.90 | 18.29 | 15.35 | 3.18 |
| 18_2_loop_undefined_access (MOp/s) | 0.60 | 0.66 | 1.13 | 2.60 | 2.40 | 2.10 | 0.49 |
| 19_type_functions (MOp/s) | 250.57 | 293.21 | 806.37 | 1560.00 | 1180.00 | 971.77 | 193.89 |
| 20_type_conversion (MOp/s) | 382.32 | 458.44 | 812.72 | 1570.00 | 1530.00 | 1510.00 | 298.61 |
| 21_0_loop_exception_none (MOp/s) | 7.45 | 8.91 | 19.67 | 56.57 | 26.35 | 15.67 | 6.97 |
| 21_1_loop_exception_try (MOp/s) | 6.48 | 7.74 | 19.11 | 52.18 | 23.61 | 18.99 | 6.39 |
| 21_2_loop_exception_catch (kOp/s) | 184.22 | 216.00 | 573.09 | 1380.00 | 1240.00 | 498.60 | 147.28 |
| 22_loop_null_op (MOp/s) | 3.25 | 3.74 | 8.39 | 16.03 | 17.62 | -.-- | 3.08 |
| 23_loop_spaceship_op (MOp/s) | 4.30 | 5.12 | 8.50 | 17.98 | 20.39 | -.-- | 3.96 |
| 24_xmlrpc_encode (Op/) | -.-- | -.-- | -.-- | -.-- | 17.6 | -.-- | -.-- |
| 25_xmlrpc_decode (Op/) | -.-- | -.-- | -.-- | -.-- | 9.16 | -.-- | -.-- |
| 26_1_class_public_properties (MOp/s) | 3.32 | 4.08 | 10.51 | 26.70 | 19.57 | 9.42 | 3.22 |
| 26_2_class_getter_setter (MOp/s) | 1.31 | 1.51 | 4.66 | 9.41 | 5.52 | 4.13 | 0.97 |
| 26_3_class_magic_methods (MOp/s) | 0.52 | 0.59 | 1.35 | 3.77 | 3.21 | 1.89 | 0.41 |
| Total (MOp/s) | 1.23 | 1.43 | 2.60 | 5.33 | 2.48 | 2.02 | 0.98 |
| Time (sec) | 488.324 | 419.895 | 231.485 | 113.087 | 252.376 | 261.652 | 609.787 |
Бенчмарки Python
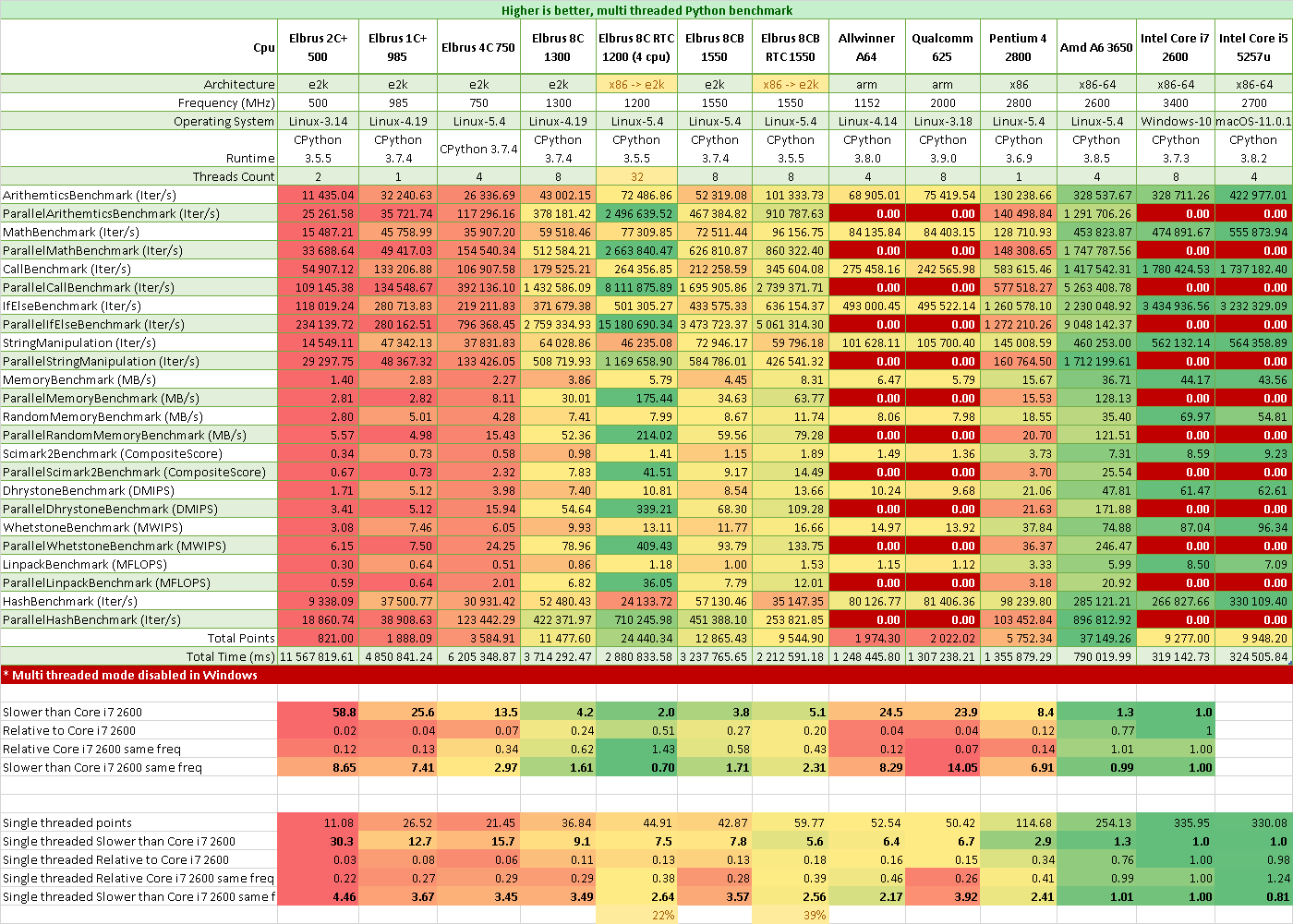
Так как под Windows не удалось запустить многопоточный Python (я не Питонист, да и времени сделать универсальную многопоточность на всех ОС не было, принимаю патчи), приведу относительно Amd A6 3650, который на 40% медленнее Core i7.
Результаты Python на Эльбрусах в сравнении с Core i7 2600 3.4 ГГц:
- Эльбрус 2С+ в 30 раз медленнее на 1 поток
- Эльбрус 1С+ в 12,5 раз медленнее на 1 поток
- Эльбрус 4С в 15,5 раз медленнее на 1 поток
- Эльбрус 8С в 9 раз медленнее на 1 поток
- Эльбрус 8СВ в 7,8 раз медленнее на 1 поток
- Эльбрус 2С+ в 58 раз медленнее на всех потоках
- Эльбрус 1С+ в 25 раз медленнее на всех потоках
- Эльбрус 4С в 13,5 раз медленнее на всех потоках
- Эльбрус 8С в 4,2 раза медленнее на всех потоках
- Эльбрус 8СВ в 3,8 раза медленнее на всех потоках
Результаты Python на Эльбрусах в сравнении с Core i7 2600, но на одинаковых частотах:
- Эльбрус 2С+ в 4,5 раз медленнее на 1 поток Core i7 2600 на частоте 0,5 ГГц
- Эльбрус 1С+ в 3,6 раз медленнее на 1 поток Core i7 2600 на частоте 1 ГГц
- Эльбрус 4С в 3,5 раз медленнее на 1 поток Core i7 2600 на частоте 0,8 ГГц
- Эльбрус 8С в 3,5 раз медленнее на 1 поток Core i7 2600 на частоте 1,3 ГГц
- Эльбрус 8СВ в 3,5 раз медленнее на 1 поток Core i7 2600 на частоте 1,55 ГГц
- Эльбрус 2С+ в 8,5 раз медленнее на всех потоках Core i7 2600 на частоте 0,5 ГГц
- Эльбрус 1С+ в 7,4 раз медленнее на всех потоках Core i7 2600 на частоте 1 ГГц
- Эльбрус 4С в 3 раз медленнее на всех потоках Core i7 2600 на частоте 0,8 ГГц
- Эльбрус 8С в 1,5 раза медленнее на всех потоках Core i7 2600 на частоте 1,3 ГГц
- Эльбрус 8СВ в 1,35 раза медленнее на всех потоках Core i7 2600 на частоте 1,55 ГГц
Во первых, для Python пока не делалось оптимизаций, которые повысили бы производительность. Во вторых, интерпретируемые языки плохо подходят к VLIW-архитектуре Эльбруса. Но МЦСТ советуют использовать CPython для производительности (Python -> C, а затем компилируем с помощью LCC). Про PyPy c Jit пока ничего не известно, но если потребуется, то такая среда выполнения будет реализована, а это сильно повысит производительность.
Также было замечено, что в некоторых случаях Python в режиме RTC (двоичная трансляция x86-64 в e2k) показывает большую производительность: в арифметике и математике. Значит есть ещё потенциал для оптимизации Python, возможно даже в 2 раза.
Бенчмарки Lua
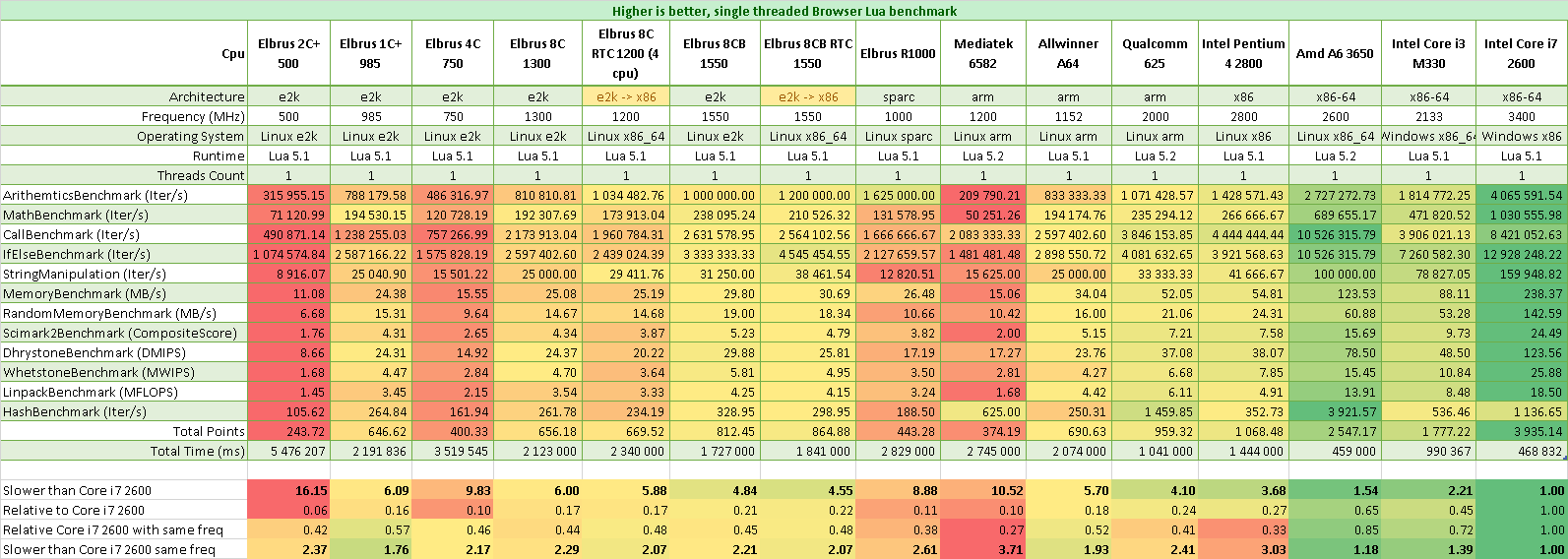
Результаты Lua на Эльбрусах в сравнении с Core i7 2600 3.4 ГГц:
- Эльбрус 2С+ в 16 раз медленнее
- Эльбрус 1С+ в 6 раз медленнее
- Эльбрус 4С в 10 раз медленнее
- Эльбрус 8С в 6 раз медленнее
- Эльбрус 8СВ в 5 раз медленнее
- Эльбрус R1000 в 9 раз медленнее
Результаты Lua на Эльбрусах в сравнении с Core i7 2600, но на одинаковых частотах:
- Эльбрус 2С+ в 2,4 раза медленнее Core i7 2600 на частоте 0,5 ГГц
- Эльбрус 1С+ в 1,75 раза медленнее Core i7 2600 на частоте 1 ГГц
- Эльбрус 4С в 2 раза медленнее Core i7 2600 на частоте 0,8 ГГц
- Эльбрус 8С в 2,3 раза медленнее Core i7 2600 на частоте 1,3 ГГц
- Эльбрус 8СВ в 2,2 раза медленнее Core i7 2600 на частоте 1,55 ГГц
- Эльбрус R1000 в 2,6 раз медленнее Core i7 2600 на частоте 1 ГГц
У Lua отставание всего в 2 раза на равных частотах, это достаточно тепримо для VLIW-архитектуры.
Выводы
Во сколько раз Core i7 2600 быстрее Эльбрусов:

Во сколько раз Core i7 2600 быстрее Эльбрусов, если бы он работал на частоте Эльбрусов:

Как мы знаем, Эльбрус имеет VLIW архитектуру, у которой повышение производительности достигается путём оптимизации компилируемого кода (Эльбрус имеет явный параллелизм). Также у Эльбруса нет предсказателя переходов и переупорядочивания инструкций (снова всё явно задаётся компилятором).
Следует:
- Компилируемые программы на C/C++ (возможно, другие) будут иметь хорошую производительность. Это достигается патчами участков кода, где нужно оптимизировать производительность и умным компилятором LCC (eLbrus C Compiler).
- Языки с JIT-трансляцией (Java, JavaScript, C# Mono) будут иметь среднюю производительность. Здесь оптимизируют саму среду исполнения. Возможно, также потребуется оптимизировать сами программы.
- Интерпретируемые языки (PHP, Python, Lua) будут иметь низкую производительность. Но оптимизация среды выполнения позволит поднять до среднего уровня.
Другие способы:
- Доработка компилятора LCC.
- Архитектурно-специфические доработки в самой ОС.
- Улучшать архитектуру Эльбрус:
- Поднимать частоту
- Добавить предсказатель и т.д.
Какие языки ещё хотелсоь бы потестировать:
- Golang (Ждём выпуска)
- Ruby
- Perl
P.S. Поздравляем команду МЦСТ с Новым Годом. Желаем удачи в разработке следующих поколений процессоров. Ждём массового появления устройств на процессорах с архитектурой E2K!
"Что такое Эльбрус?
Эльбрус это полувековая история развития отечественной
вычислительной технологии.
Это уникальная российская архитектура микропроцессора.
Это группа компаний объединенных одной идеей.
И наконец, это просто современный микропроцессор."
elbrus.ru
Web:
Официальный сайт: http://elbrus.ru
Официальная вики: http://wiki.community.elbrus.ru
Официальный форум: http://forum.community.elbrus.ru
Персональный сайт Максима Горшенина: http://imaxai.ru
Отличная вики на сайте ALT Linux Team: https://www.altlinux.org/Эльбрус
Telegram:
https://t.me/imaxairu основной канал с новостями из мира микропроцессоров Эльбрус из первых рук
https://t.me/e2k_chat на текущий момент основной чат по микропроцессорам Эльбрус, в котором можно пообщаться с разработчиками (организован сотрудниками компании Промобит, хорошо известной по продуктам BITBLAZE)
https://t.me/joinchat/FUktBxkwG8FKlhdzQ7DegQ чат для поболтать на разные темы любителями (и не очень) микропроцессоров Эльбрус с целью незасорения основного чата ненужной информацией, одним словом флудильня фан-клуба :)
Instagram:
Максим Горшенин и Эльбрусы: https://instagram.com/imaxai
Youtube:
Официальный канал группы компаний Elbrus: https://www.youtube.com/c/ElbrusTV
Частный канал Максима Горшенина: https://www.youtube.com/c/MaximGorshenin
Частный канал Михаила Захарова с эмз "Звезда": https://www.youtube.com/channel/UC3mtwuC2ugAngyO9tY2mqRw
Канал фанатов Е2К Elbrus PC Test (https://www.youtube.com/channel/UC4zlCBy0eFLkE-BxgqQK8FA):
- https://youtu.be/wTZXJ1DJlRs тест Blender 2.80
- https://youtu.be/NEcCAgtOlU8 тест PostgreSQL 11.5
- https://youtu.be/LcUnHXpQhnA SuperTuxKart
- https://youtu.be/ZX-MKezC_Uo Half-Life & Counter-Strike
Серия видеороликов по Эльбрусам от Дмитрия Бачило:
- https://youtu.be/ZP_ll1qahXQ распаковка
- https://youtu.be/LS6HloN09g4 Кремниевые Титаны
- https://youtu.be/58XlDUOTdBI разборка
- https://youtu.be/buWzWtXHimk тесты
- https://youtu.be/I70_OwzHX98 стрим с Эльбруса
Серия видеороликов по играм на Эльбрусах от Дмитрия Пугачева:
- https://youtu.be/yEN7WlIC6B8 Doom 3
- https://youtu.be/yXpy0AX4pqE Quake 1 (darkplaces)
- https://youtu.be/W3VryXQfUY4 Vulkan test 01
- https://youtu.be/XIwtYxaSanc SuperTuxKart
- https://youtu.be/YbV4OlY2X1I Jedi Academy
- https://youtu.be/x7flQ3wWwXo Quake 1 (Vulkan API)
- https://youtu.be/nSTDFTslV2c Minetest
Старенький, но не устаревающий ликбез по Эльбрусам Константина Трушкина на HighLoad++ 2014: https://youtu.be/ZTxOSGBCRec
Актуальными моделями микропроцессоров Эльбрус являются:
- Эльбрус-8СВ (http://mcst.ru/elbrus-8cb)
- Эльбрус-8С (http://mcst.ru/elbrus-8c)
- Эльбрус-1С+ (http://mcst.ru/elbrus-1c-plus)
О существующих и будующих моделях микропроцессоров можно прочитать в вики Модели процессоров Эльбрус
Альта и оф. вики Характеристики процессоров Эльбрус
Результаты тестирования Результаты тестирования Эльбрус энтузиастами дают примерную оценку производительности. И это не предел, т.к. работы над совершенствованием оптимизирующего компилятора ведутся постоянно.
Попробовать ПК с процессором Эльбрус вживую можно в Яндекс.Музее в Москве.
Полезно прочитать:
Руководство по эффективному программированию на платформе Эльбрус http://mcst.ru/elbrus_prog Нейман-заде М. И., Королёв С. Д. 2020 [ PDF ] [ HTML ]
Микропроцессоры и вычислительные комплексы семейства Эльбрус (http://mcst.ru/files/511cea/886487/1a8f40/000000/book_elbrus.pdf) Ким А. К., Перекатов В. И., Ермаков С. Г. СПб.: Питер, 2013 272 с. ( PDF )
Операционные системы для архитектуры E2K:
АЛЬТ 8 СП (http://altsp.su/produkty/o-produktakh/) | Рабочая станция (https://www.basealt.ru/products/alt-workstation/) | Сервер (https://www.basealt.ru/products/alt-server/) | Образование (https://www.basealt.ru/products/alt-education/)
Astra Linux SE "Ленинград" (http://astralinux.ru/)
Эльбрус Линукс (http://mcst.ru/programmnoe-obespechenie-elbrus)
Попробовать ОС Эльбрус Линукс для x86_64:
https://yadi.sk/d/spqkqOAncT-aKQ
Документация:
https://yadi.sk/d/2shOcqIrmZQLLA
Интересное:
Вопрос:
Зачем VLIW, давай другую?
Ответ:
Лекция Бориса Бабаяна "История развития архитектуры
вычислительных машин":
Часть 1 https://youtu.be/Swk27K9m_SA
Часть 2 https://youtu.be/QFD0NboTwTU






































 Так изнутри выглядела первая советская ЭВМ
МЭСМ. Все схемы данной машины находились не в стойках или шкафах,
как это стало принято позже, а были развешаны по стенам помещения
Так изнутри выглядела первая советская ЭВМ
МЭСМ. Все схемы данной машины находились не в стойках или шкафах,
как это стало принято позже, а были развешаны по стенам помещения
 Академик Сергей Алексеевич Лебедев, один
из основателей и самых видных деятелей отечественной инфоматики
Академик Сергей Алексеевич Лебедев, один
из основателей и самых видных деятелей отечественной инфоматики
 Достаточно оригинальная схема расстановки
шкафов оборудования для CDC 6600. Через пустой центральный квадрат
шли основные кабели и охлаждение
Достаточно оригинальная схема расстановки
шкафов оборудования для CDC 6600. Через пустой центральный квадрат
шли основные кабели и охлаждение
 во Фрайберге, ГДР, 1981") ЕС-1035 (одна из машин серии ЕС ЭВМ) во
Фрайберге, ГДР, 1981
ЕС-1035 (одна из машин серии ЕС ЭВМ) во
Фрайберге, ГДР, 1981
 Кроме огромных систем вполне возможно было
встретить и вот такие вполне миниатюрные ЕС-1068
Кроме огромных систем вполне возможно было
встретить и вот такие вполне миниатюрные ЕС-1068
 Суперкомпьютер Ростеха, в основе которого
лежат процессоры Эльбрус-8С
Суперкомпьютер Ростеха, в основе которого
лежат процессоры Эльбрус-8С








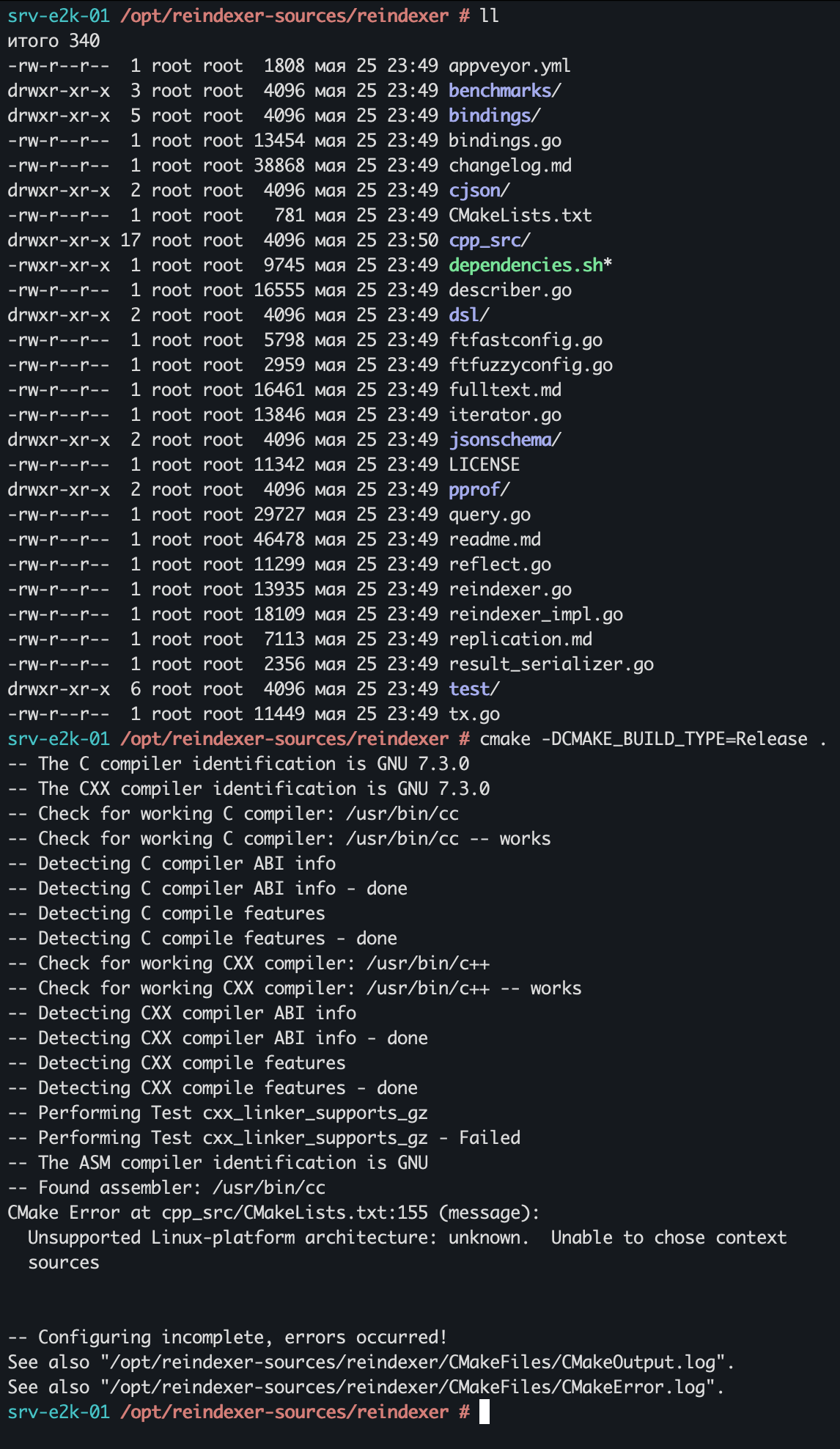




















 То же самое в текстовом виде
То же самое в текстовом виде
 То же самое в текстовом виде
То же самое в текстовом виде
 То же самое в текстовом виде
То же самое в текстовом виде
 То же самое в текстовом виде
То же самое в текстовом виде






 В
естественной среде обитания.
В
естественной среде обитания.






















