Введение
Всем добрый день. Меня зовут Александр. Сейчас я работаю в Мегафон front-end разработчиком. Проблемы поиска данных всегда отличались особенной сложностью и зачастую нестандартностью в подходах. Сегодня я бы хотел остановиться на одной интересной задаче, которую мне пришлось решать совсем недавно во время разработки платформы Интернета вещей. Впрочем, такая задача, может встретиться и на любом другом проекте, где есть динамическая подгрузка данных по REST API. Будь то подгрузка во время пагинации, или во время скроллинга, или как то иначе
Проблематика
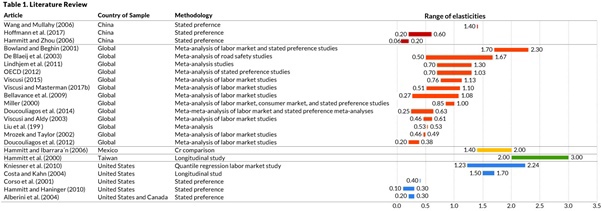
Казалось бы: в чем может быть трудность. Особенно когда речь касается только фронта? Ведь все алгоритмы поиска реализуются в основном на бэке. На самом деле и да, и нет. Давайте представим простую таблицу, у которой есть пагинация из нескольких страниц и фильтр на каждом столбце. См. ниже.
 Таблица
с фильтрами в столбцах
Таблица
с фильтрами в столбцах
В данной табличке открыт фильтр по столбцу Номер БС. Простыми словами: вводя любые символы в поле ввода фильтра, вы получаете подходящие опции в дропдауне. Кликнув на любую из них, вы отфильтруете данные в таблице по этому элементу.
Каким образом можно вывести подобный дропдаун с нужными опциям?
Варианты решения
-
Составить массив из всех элементов столбца таблицы и с помощью методов filter и includes (или им подобных) показать нужные опции в дропдауне. Проблема в том, что компонент таблицы не знает о элементах, которые находятся на других страницах. Они подгружаются только при переходе на эти страницы. А значит поиск будет осуществляться не по всем элементам.
-
Сформировать массив как в 1-м варианте, но запрашивая его с бэка. Хороший вариант, но производительность такого подхода близится к 0. Что если записей 1 млн? В таблице именно для этого и используется пагинация.
-
Отправлять строку фильтра на бэк, и уже с бэка получать нужные опции для дропдауна. Бэк знает обо всех записях и на нем можно использовать всевозможные алгоритмы поиска в базах данных, которые будут работать достаточно быстро.
Отлично. Именно этот вариант мы и рассмотрим. На рисунке выше изображен именно он: мы ищем записи, которых нет на текущей странице, однако в дропдауне видим подходящие варианты со всех страниц.
Алгоритм
-
Для каждого столбца должен существовать запрос на бэк и поле, которое мы будем брать из ответа, чтобы заполнить опции. Нужен config.
-
После ввода данных их нужно отправлять на бэк. Можно по кнопке, но лучше использовать периодическую отправку в функции debounce.
-
Во время процесса отправки/получения данных показывать loader
-
Получения ответа от бэка и заполнение опций для дропдауна из заданного поля ответа
Решение
Я предполагаю, что читатели знакомы с JS и React и в данной статье нет смысла рассказывать о том, как отправлять запросы, фильтровать массивы и другие основы JS. Я буду останавливаться лишь на важных составных частях алгоритма.
Итак, начнем по порядку. Как мы выяснили, для начала нужен конфиг для таблицы (для каждого столбца) и ее фильтров. Разделим его на 2 файла.
Пример конфига столбца таблицы:
{ id: 'address', title: 'Адрес объекта', filter: filters.address, checked: true, minWidth: 160}
Пример конфига фильтра:
address: { type: 'includes', name: 'addrFilter', options: { default: { values: 'objectsList', fetchFunc: 'fetchObjectsList', calcFunc: 'address' } }}
Как можно заметить конфиги связаны по типу один-ко многим. То есть один и тот же фильтр может соответствовать нескольким столбцам таблицы.
Поле options содержит как раз поля для конфигурации опций фильтра. Например:
-
fetchFunc - имя thunk функции, которая загружает данные для этого фильтра
-
values - поле из ответа сервера, в котором содержатся опции
-
calcFunc - имя функции для трансформирования опций
Остановимся подробнее на calcFunс. При таком алгоритме, что был описан в опции попадают данные из определенного поля ответа. Но что если поле составное, например в каждую опцию фильтра должно попасть сразу несколько полей. Пример с адресом: опция фильтра = город + улица + дом
 Фильтр адреса
Фильтр адреса
В этом нам и поможет функция предварительного обсчета опции. Вот пример реализации:
//object includes calc functionsconst calculatedData = useMemo(() => ( { default: (values) => { //default calculate }, address: (values) => { //calculate with generateAddress function, for example }, ...}), [...]);//using this object (calcFunc from config):const data = calculatedData[calcFunc || 'default'](values)
Далее. Как уже говорилось лучше всего отправлять запросы через определенный интервал задержки. То есть пользователь вводит данные в поле, приостановился на полсекунды - произошла отправка. Реализуется это примерно так:
// debounce functionconst debounce = (fn, ms = 0) => { let timeoutId; return function(...args) { clearTimeout(timeoutId); timeoutId = setTimeout(() => fn.apply(this, args), ms); };};//debounceFetch functionconst debounceFetch = debounce(async (func, args) => typeof func === 'function' && (await func(args)), 500);//sending requestuseEffect(() => { debounceFetch(actions[fetchFunc], { filter: { [filterName]: filterValue || null } });}, [filter]);
Продолжаем. В текущей задаче может понадобиться определить грузится ли в данный момент какой-либо фильтр, например, чтобы показать лоадер. У нас в команде приняты некоторые стандарты для именования переменных, например, все переменные, показывающие процесс загрузки начинаются с isLoading. Например, isLoadingObjects. Поэтому идеальным решением будет создать selector для kea, который = true если хотя бы в одном стейте, содержащем в названии isLoading, содержится значение true.
Если вы используете не kea, а обычный redux или какую-то другую библиотеку - уверен, вы адаптируете этот код под свои нужды. Если нет - пишите мне. А лучше используйте kea =)
Далее вы просто показываете лоадер пока anyLoading===true, все как обычно.
На этом мы почти закончили. Далее нужно просто обработать ответ сервера, взять нужное поле из него, пропустить его через calcFunc если она указана в конфиге и вывести найденные опции для фильтра.
Всю логику лучше всего будет объединить в один хук и назвать его, скажем, useFiltersOptions.
Выводы
Используя рассмотренный алгоритм, мы решаем задачу поиска оптимальным путем: все сложные вычисления отдаем на бэк, делая это постепенно, следуя за вводом пользователя. Плюс к этому у нас появляются огромные возможности для расширения, используя конфиг таблицы, конфиг фильтров и функцию предварительной обработки ответа сервера.
А также используются уже имеющиеся запросы к бэку, а в конфиге указываются лишь их названия и поля из ответа для формирования результатов поиска, что позволяет избежать дублирования кода и лишней работы на стороне бэка.











 Без заголовков
Без заголовков С заголовками
С заголовками
 Без разделителей
Без разделителей Выделение цветом
Выделение цветом
 Выравнивание чисел и заголовков по левому краю
Выравнивание чисел и заголовков по левому краю
 Различные варианты выравнивания текста
Различные варианты выравнивания текста
 Различные
варианты округлений
Различные
варианты округлений
 Расстояние между столбцами
Расстояние между столбцами Расстояние между строками
Расстояние между строками
 Излишек единиц измерения
Излишек единиц измерения Правильное оформление единиц измерения
Правильное оформление единиц измерения
 Выделение выбросов цветом текста
Выделение выбросов цветом текста Выделение
выбросов заливкой
Выделение
выбросов заливкой
 Без
группировки по регионам
Без
группировки по регионам С группировкой по регионам
С группировкой по регионам
 Голая таблица
Голая таблица Отформатированная таблица
Отформатированная таблица