
Используем алгоритм. Он ключ к решению головоломки с названием "Память".

Задача
Задача текущей статьи непроста. Нам необходимо разобраться в структуре памяти живого организма. Эта задача возникла в работе не на пустом месте, а лишь как этап при поиске методов работы с алгоритмами. Её появление было неожиданно, и решение тоже стало подарком. Причём подарком в сторону нейробиологии. Полученное решение требует обсуждения. Жду в комментариях конструктивную критику, но при этом хочется обратить внимание, что полное описание всех аргументов, подкрепляющих это решение, потребует нескольких дополнительных статей с примерами со стороны процессов коммуникации, обучения и формирования естественного языка.
Для решения головоломки под названием "Память" потребуются результаты разбора определения алгоритма ("набора инструкций, описывающих порядок действий исполнителя для решения некоторой задачи") приведенных в предыдущих двух статьях серии (Часть 1 "Действие", Часть 2 "Исполнение"). Без перечисленных там выкладок читать дальше будет сложнее.
Но давайте приступим. Головоломка "Память" красива, кто-то её "запутал" без нас. Пора вернуть ей упорядоченное состояние и поставить на полку в дополнение к своей коллекции.

Поведение и нервная система
Разберем методы используемые организмом для группировки "упорядоченного набора" своих "действий" для решения задач выживания, то есть еще одного примера синтеза алгоритма.
В предыдущей статье упомянуты методы генетического синтеза "алгоритмов жизни" организмов, и отмечено, что эти методы имеют и достоинства и недостатки. Главным недостатком является "неторопливость". Низкая скорость синтеза новых алгоритмов выживания может быть достаточной в среде, характеризуемой большим постоянством своих параметров. Тогда цикла жизни поколения организмов, который совпадает с шагом развития используемых алгоритмов, будет хватать по времени для приспособления к новым условиям. Но для среды с большей скоростью изменения состояний (например, при наличии организмов-соперников за еду) необходимы более эффективные методы синтеза "алгоритмов выживания".
Наблюдая за многими живыми организмами, мы можем найти такие методы в их поведении. Можно даже сказать, что изменяющееся в течение жизни поведение организма, использующее активацию различных "действий", влияющих на среду обитания является главным признаком такого "быстрого" синтеза. Здесь можно сделать уточнение, что не всякие методы смены поведения нам важны в текущий момент. Важны лишь те, в которых наблюдается разделение контроля исполнения.
Это разделение сформулировано на примере генетических алгоритмов в предыдущей статье. Оно формирует две группы, отличающиеся по контролю исполнения алгоритма (связного и обусловленного).
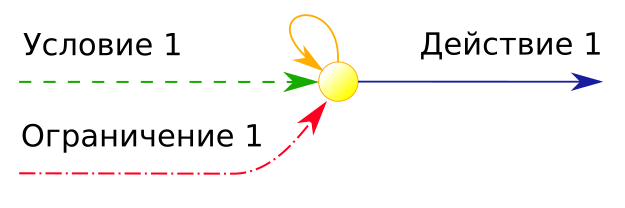
Группа связного исполнения должна управляться
- "структурой", содержащей "описание последовательности", формируемой и сохраняемой внутри организма.
Группа обусловленного исполнения будет основываться на "действиях" (внешних по отношению к упомянутой "структуре"):
- внутренних процессах организма,
- процессах воздействия организма на среду обитания
- процессах среды обитания, влияющих на организм.
Какая "структура" обеспечивает связное исполнение поведения организма? Что формирует описание последовательности его активности?
Такой "структурой" является нервная система, сформировавшаяся в процессе эволюции у организма и обеспечивающая взаимосвязанную регуляцию деятельности всех систем организма и реакцию на изменение условий внутренней и внешней среды ((с) Wikipedia). Мы знаем уже очень много о нервной системе:
- изучены её составляющие элементы нейроны;
- описаны группы её элементов нервные ткани и нервная сеть;
- детально исследован центральный её отдел мозг;
- рассмотрены способы организации нервной системы у различных животных.

Вся информация о нервной системе накапливается усилиями ученых разных специализаций, в том числе со стороны психологии. Научных сведений много, но даже из личного опыта мы принимаем как естественный факт, что нервная система (удобнее сказать "мозг") умеет запоминать информацию, с которой организм сталкивается в жизни. И "мозг" умеет использовать эту информацию для решения задач, встающих перед организмом. Для решения задач он взвешивает альтернативы, выбирает инструменты ("действия"), находит последовательность их применения, контролирует исполнение этой последовательности и оценивает результат (решена ли задача). Если просуммировать всю перечисленную деятельность мозга и вспомнить две предыдущие статьи. То становится очевидно.
Мозг занимается созданием Алгоритма!
Этот алгоритм еще не код программиста. Но он близок к нему, и это даёт возможность оценить деятельность мозга, считая, что она является разными этапами создания алгоритма. Этот взгляд на работу "мозга" дарит нам ключик к его структуре. Построение этой структуры отталкивается не от физического устройства рецепторов, дендритов и аксонов нейрона, и даже не от способов группировки нейронов в слои разных типов. Оно основывается на функциональном назначении и, возможно, с учётом специализации выполняемых функций в синтезе алгоритма, получится впоследствии объяснить физические особенности областей и слоев коры головного мозга. Но пока не будем столь оптимистично забегать вперёд.
Запоминание алгоритмов выживания
Давайте детальнее рассмотрим утверждение, что "мозг" запоминает информацию. Что значит запоминает? Как понять, что считать информацией? Нужно упростить ситуацию использования этих понятий. Попробуем найти и запоминание, и информацию в процессе синтеза алгоритма. Для этого нам необходимо вспомнить "действие" из определения алгоритма и его главный признак Повторимость, позволяющий это "действие" обнаружить. Организму для использования некоторого процесса в своём алгоритме, необходимо чтобы этот процесс повторялся с одинаковым результатом при одинаковых условиях своих инициализации и исполнения. Как организм может оценить, что некоторый процесс повторим, то есть является "действием"?
Для поиска новых "действий" организм должен в некоторой "структуре" запоминать последовательность событий, которые он переживает. Конечно, эта "структура" не будет содержать полной реализации записываемого процесса. Это будет описание, основывающееся на последовательности внешних "признаков" такого процесса, обнаруживаемых организмом, и выполненных "действий", которые организм использовал в этой ситуации. В дополнение к этому описанию сформированному во внутренней "структуре", у организма должна быть процедура оценки повторного "проживания" такой ситуации. И чем чаще последовательность признаков и "действий" повторяется с участием организма в среде, тем больше вероятность, что организм выявил некоторую закономерность этой среды. То есть организм запомнил информацию!
Тут мы немного упростили процесс запоминания информации это,
конечно, хорошо, но выявленная закономерность среды может иметь
разный результат для организма. Некоторые "признаки"
свидетельствуют об опасности, и для них полезным будет
действие("Убегать"). Другие "признаки" говорят о
наличии еды и действие("Убегать") будет вредным
поведением для организма в этой ситуации. Это не отменяет факта,
что повторимость "признаков" важна. Но разделяет выявленные
описания последовательностей "признаков" и "действий" на информацию
двух типов:
- как полезно поступать в ситуации, описываемой "признаками";
- как в ситуации, характеризуемой "признаками", поступать нельзя.

Следует уточнить, что четких двух полярных типов, конечно, нет. Эти два типа-полюса, а между ними располагаются алгоритмы поведения отсортированные по полезности для своего организма. При этом самыми устойчивыми алгоритмами-последовательностями являются безусловно-полезные (безусловные рефлексы) и безусловно-вредные. А те алгоритмы, которые находятся посередине между этими полюсами (не полезные и не вредные), не имеют устойчивого положения и даже могут быть забыты организмом, при замещении более эффективными алгоритмами.
Мы изложили уже достаточно, чтобы подвести небольшой итог.
Организм своим поведением решает задачу (например, задачу выживания). Для решения этой задачи организм:
- использует существующие детекторы "признаков";
- ищет на основе признака Повторимость новые групповые "признаки";
- использует готовые "действия";
- ищет на основе признака Повторимость новые групповые "действия";
- выявляет закономерности среды, выражающиеся в сочетании последовательности "признаков" и применяемых "действий";
- на основе вышеперечисленных приёмов синтезирует алгоритмы-стратегии в виде "структуры" в памяти;
- подкрепляет и сохраняет в памяти те "структуры" синтезированных алгоритмов-стратегий, которые подтверждаются признаком Повторимость;
- упорядочивает синтезированные алгоритмы-стратегии по шкале хорошо-плохо (для последующего выбора применять или избегать выполнения конкретного алгоритма в текущем контексте).
Для дальнейшего удобства введем несколько терминов.
Цепочка это одновременно и "структура" записывающая последовательность "признаков" и "действий", и "структура" контролирующая повтор исполнения последовательности записанных "признаков" и "действий" в мозге организма. На основе цепочки организм синтезирует алгоритм-стратегию для своего поведения. Методы формирования цепочек разнообразны. Один из наиболее важных это игровое поведение. В следующей статье будет детально рассмотрены возможности эволюции для синтеза в организме цепочек различных типов.
Введём термин признак как обнаружение организмом
"параметров" среды (химических, термических, оптических...) при его
контакте со свободными или принадлежащими некоторому процессу
внешними объектами. Будем использовать обозначение
признак("свет") для указания на факт обнаружения
организмом конкретного признака фотонов света.
Выведем из кавычек слово "действие" и введем соответствующий термин.
Действие инициируемый организмом процесс
воздействия на объекты и процессы среды. Действие, как
закреплено в статье 1, обеспечено признаком Повторимость.
По аналогии с признаком будем использовать обозначение
действие("убегать") для указания на факт инициализации
организмом конкретного действия (в представленном примере
это процессы приводящие к быстрой смене своего расположения).
Реализация цепочки
Наметив приблизительную структуру памяти организма, можно перейти к реализации. В плане программирования, как способности разрабатывать новый алгоритм, у человека есть преимущества по сравнению эволюционным методом, которым в построении памяти пользовалась природа. Мы мало ограничены набором приёмов, и сразу можем использовать:
- приоритетную очередь для отсортированных цепочек;
- счетчики, оценивающие как давно использовалась цепочка, для изменения в цепочке параметра полезно-вредно;
- счетчики, оценивающие интервал времени с момента детектирования предыдущего признака или действия, для осуществления записи последовательности событий во времени;
- сортировку по приоритетам для оценки уместности использования цепочки при текущих обнаруживаемых признаках;
- дискретные модели простой среды для анализа работоспособности разработанной системы;
- и самый важный, которого у природы нет, способ сохранения и копирования сложной сформировавшейся системы цепочек, осуществляемый простым копированием структуры в оперативной или долговременной памяти.
Почему способ копирования системы цепочек так важен? Чтобы ответить на этот вопрос представим себе человеческий мозг со множеством нейронов и установившихся между этими нейронами связей. Каким образом можно скопировать эту сложную структуру? Ведь она не линейна. Сложно даже подумать как реализовать способ её сериализации. В то время как память в нашем компьютере проста и наоборот предназначена для выполнении копии, не зависимо от того какой сложности структура хранится в её ячейках. Этим мы, как программисты, непременно воспользуемся чуть позже для оттачивания модели, основывающейся на системе цепочек. А пока сосредоточимся на ограниченности возможности природы для копирования синтезированных в виде цепочек алгоритмов от одного организма другому.
У цепочки в живом организме нет никаких других возможностей сформироваться кроме как обнаружение организмом повтора. Повтор некоторой последовательности признаков создаёт в организме макро-признак сложной ситуации. Повтор последовательности действий, несколько раз выполненных организмом, создает образец макро-действия. Почему для заучивания стихотворения (или пьесы на пианино) нам приходится снова и снова повторять произношение слов (нажатия клавиш)? Потому что нет у организма другого способа синтезировать в своей памяти рабочий алгоритм игры мелодии на музыкальном инструмента кроме Повтора. Здесь можно уточнить, что словесное описание алгоритма игры мелодии человек способен выучить без повторяемых касаний черно-белых клавиш, но научиться играть мелодию этим способом у него не получится. И для справедливости необходимо отметить, что словесное изучение алгоритма игры мелодии также не обходится без повторяющихся операций.
В завершение этой оды "Повтору" необходимо сказать, что способ копирования алгоритмов поведения у живых организмов сложен, но уже существует. Эти способ Обучение, то есть процесс копирования алгоритмов во взаимодействии нескольких особей. Самый наглядный пример обучение детей на примере своих родителей. При таком обучении детская особь включает режим "игрового поведения" и следит за взрослой особью. И это "слежение" не простое. Оно включает:
- отождествление маленькой особи со взрослой,
- соотнесение правой руки взрослой особи и правой руки особи-ученика,
- способ добиться от правой руки обучающейся особи действия("движение") сходного с движением взрослой особи;
- способ выполнения особью-учеником нескольких разных действий при последовательном копировании движений взрослой особи;
- формирование копии алгоритма (цепочки полезных действий у обучающейся особи), основанное на нескольких повторах последовательности движений.
Важно, что копирование алгоритма-поведения с такими же внешними характеристиками можно увидеть не только у человека. Например, у львенка, подсматривающего поведение у более взрослой особи.
Процессы отождествления себя с особью-учителем, способы отделения возможностей исполнять действия своего тела от действий, демонстрируемых другой особью, на которые повлиять не можешь. Не признаки ли это сознания? Конечно, сознания упрощенного без требования владения Языком.
Очевидно, что процессы необходимые для копирования алгоритма от
особи к особи требуют от организма дополнительных возможностей.
Часть этих возможностей очень похожа на процессы, упоминаемые нами
для описания слова "самосознание". Другая часть сводится к
процессам коммуникации. Пока что стоит отложить обсуждение
процессов коммуникационного синтеза цепочек на основе
Языка. Этому вопросу необходимо отдельное пространство, которое
будет выделено в одной из последующих статей. В этом месте стоит
лишь отметить, что Язык стал самым эффективным решением ограничения
возможностей копирования цепочек между живыми организмами.
И очень хорошо, что на первом этапе моделирования системы
цепочек для копирования мы (как программисты) можем
использовать memcpy и пока не думать о
коммуникации.
В завершение раздела вернемся к программной реализации системы
цепочек. Не во всём природные методы работы с
цепочками уступают возможностям программиста. Есть у
природы фора великолепная реализация параллельно исполняющихся
алгоритмов, уже отмеченная в предыдущей статье при демонстрации
процессов, связанных с молекулой ДНК в живой клетке. Огромное
количество цепочек работают, формируются, упорядочиваются
у каждого из нас в процессе чтения этой статьи. И параметр
параллельного исполнения, характеризующий наш мозг не сводится к
 -ми ядрам, к
-ми ядрам, к  -ти, и даже к
-ти, и даже к  ядрам (как у
суперкомпьютера Summit).
ядрам (как у
суперкомпьютера Summit).
Да, моделирование мозга человека пока не по зубам домашнему компьютеру. Но к моделированию мозга человека пока переходить рано. А для более скромной модели мозга (например, муравья или пчелы) может хватить и процессора среднего домашнего компьютера. И когда модель всё же упрётся в производительность, у нас есть возможность перейти к использованию "параллельности" графических процессоров. Эти слова подкрепляются способом обучения модели цепочек. Для самообучения подобной модели не нужно огромного количества опорных примеров, как для нейросети глубокого обучения. А если дополнить модель способами внешнего обучения (в схеме учитель-человек + ученик-модель-организма), то и большого времени перебора вариантов цепочек не понадобится. Дело лишь за малым необходимо желание поиграться моделью, порадоваться результатам и развить для своих целей. А начальная реализация программного проекта модели уже в общем доступе.
Выводы
Есть одна проблема в написании этой серии статей. Очень хочется сразу (начиная с первой статьи) рассказать о полученном решении самых заковыристых головоломок из раздела "человеческий мозг" и "алгоритмический мир". Эти решения действительно красивы, и каждый раз приходится себя останавливать, потому что для их описания нужна минимальная общая платформа из слов-терминов. Поэтому простите за курсив в этих статьях. Эти термины действительно нужны. И надеюсь, что до их использования в написании последующих статей руки "дойдут" поскорее, не взирая на вроде бы заканчивающийся режим самоизоляции.
В текущей статье были приведены наброски модели "Системы Цепочек". Подробности и код одного из вариантов её реализации сосредоточены в отдельном проекте aipy (Python, QT, Qml, Windows+Android), в котором воплощено несколько дополнительных возможностей, описания которых не было представлено в этой статье (слой генерации цепочек, иерархия слоёв, "игровое поведение"). Конечно, способы программной реализации "Системы Цепочек" могут быть разнообразны и не ограничиваются предложенными в указанном выше проекте.
В дополнение к обозначенному в статье способу программной реализации "Системы Цепочек" имеется несколько сформированных предположений, каким образом эта система реализована на нейронной платформе в живом мозге. Но с учётом оценки уровня своих знаний нейробиологии принято решение не освещать эти гипотезы в текущем цикле статей. Для не очень научного их обсуждения есть предложение использовать платформу ai_borisov_CIT (Issues).
А теперь аванс и перспективы. Далее в цикле статей запланировано проработать следующие темы:
- эволюционный подход формирования цепочек-алгоритмов в процессе проживания организмом разных ситуаций среды;
- алгоритмы обучения с разделением на копирование между организмами макро-признаков и макро-действий;
- процессы коммуникации как коллективный способ формирования цепочек несколькими организмами и зарождение Языка (уже есть старенькая статья "Как в языке сформировать существительное?", но эту тему необходимо развить чуть больше);
- Язык самая новая, развившаяся на основе Памяти, "структура" хранения и синтеза алгоритмов, с повышением эффективности синтеза в направлении от естественных форм (речь, "сказки", суждения) к формальным (язык математики, язык физики, язык программиста).
Хочется надеяться, что после освещения этих тем словарь терминов уже устоится, и можно будет перейти к самым красивым головоломкам раздела "Мир алгоритма".
Спасибо Вам за внимание.
Отзывы
Буду очень благодарен за отзывы, пожелания и предложения, так как они помогают мне скорректировать направление развития работы в обозначенной области. И заранее извиняюсь за задержку с ответами на Ваши сообщения к сожалению время, которое получается уделить любимому Хабру, очень ограничено.
Отдельное волнение у меня есть по стилю повествования и форматированию, используемым в статье (кавычки, абзацы, курсив). Напишите, пожалуйста, если у Вас есть замечания к ним. Можно личным сообщением.
Ссылки
- Open source (GPL) проект: (Общая теория алгоритмов wiki)
- Заглавная статья темы "Разрабатываем теорию алгоритмов как проект с открытым исходным кодом": (Статья Хабр 0)
- Первая статья серии "Что такое алгоритм?! Действие"(Статья Хабр 1)
- Вторая статья серии "Что такое алгоритм?! Исполнение"(Статья Хабр 2)
- Все рисунки к статье (кроме заглавного и иллюстрации стихотворения Маяковского) сформированы сообществом Wikipedia. Лицензия (Creative Commons Attribution-Share Alike 4.0 International)
- Иллюстрация к полезным и вредным стратегиям художника Николая Денисовского к книге "Что такое хорошо и что такое плохо?", Владимир Маяковский. Ленинград, Издательство "Прибой", 1925г. (описание книги)
- Видео иллюстрация к обучению игре на пианино направляет на канал Олега Переверзева (страница автора).






 , то количество
макро-признаков, которые возможно выделить на синхронном
парном сочетании из этих признаков
, то количество
макро-признаков, которые возможно выделить на синхронном
парном сочетании из этих признаков  .
Это число больше
.
Это число больше  ). И общее число
макро-признаков увеличивается с добавлением каждой
дополнительной возможности детектировать сочетания базовых
признаков. Таких возможностей как:
). И общее число
макро-признаков увеличивается с добавлением каждой
дополнительной возможности детектировать сочетания базовых
признаков. Таких возможностей как:






