Подавляющее большинство IT специалистов разных направлений стремится как можно меньше действий выполнять руками. Не побоюсь громких слов - то что может быть автоматизировано, должно быть автоматизировано!
Представим ситуацию: нужно разворачивать много однотипных серверов, причем делать это быстро. Быстро разворачивать, быстро сворачивать. Например, разворачивать тестовые стенды для разработчиков. Когда разработка ведётся параллельно нужно разделить разработчиков, что бы они не мешали друг-другу и возможные ошибки одного из них не блокировали работу остальных.
Путей решения этой задачи может быть несколько:
-
Использовать виртуальные машины. Несколько тяжеловесное решение. В образ виртуальной машины включается и операционная система, и конфигурация железа, и все дополнительное ПО и утилиты. Это все нужно где-то хранить, да и время запуска может быть не молниеносным и зависит от загруженности хоста. Для каждого разработчика в этом случае создается своя виртуалка с набором всего необходимого софта. Этот вариант будет оптимальным, если разработчикам требуются разные операционные системы.
-
Использовать скрипты. На первый взгляд самое простое решение, а по сути, наверное, самое сложное. В этом случае, мы не тащим с собой операционку и дополнительное ПО. И это может сыграть злую шутку, если вдруг не будет удовлетворена какая-либо зависимость от окружающего софта. Попадется случайно в репозитории условный Python не той версии и все!
-
Запускать основной продукт в контейнерах. Это самое современное на сегодняшний день решение. Контейнер - это некая изолированная от внешних факторов среда. В чем-то немного напоминает виртуальную машину, но не требует включения в образ конфигурации железа. В работе так же, как и виртуальная машина, использует ресурсы хоста. Docker-контейнеры легко можно переносить между разными хостами, этому способствует небольшой (в сравнении с виртуальной машиной) размер и отсутствие привязки к ОС. Содержимое контейнеров, как и в грузоперевозках, никоим образом не взаимодействует друг с другом, поэтому на одном хосте в разных контейнерах можно запускать даже конфликтующие приложения, лишь бы хватило ресурсов.
С помощью контейнеров можно не только легко разворачивать тестовые ландшафты и стенды для разработчиков. Давайте посмотрим, как можно использовать контейнеры в разрезе видео стриминга. В стриминге можно активно использовать ключевое свойство контейнеров: изоляцию.
Стриминг без использования контейнеров:

Стриминг с использованием контейнеров:

-
можно организовать сервис стриминга для блогеров. В таком случае для каждого блогера заводится свой контейнер, в котором будет организован его личный сервер. Если у одного блогера вдруг случаются какие-то технические неполадки, то другие об этом даже не подозревают и продолжают стримить как ни в чем не бывало. ;
-
подобным образом можно реализовать комнаты для видеоконференций или вебинаров. Одна комната - один контейнер. ;
-
организовать систему видеонаблюдения за домами. Один дом - один контейнер;
-
реализовать сложные транскодинги (процессы транскодинга, по статистике, наиболее подвержены крашам в многопоточной среде). Один транскодер - один контейнер.
и т.п.
Контейнеры можно использовать везде, где необходима изоляция процесса и защита работы процесса от соседей. Таким нехитрым образом можно значительно улучшить качество обслуживания не связанных друг с другом клиентов, например у блогера свой контейнер, у дома под видеонаблюдением свой. С помощью скриптов можно автоматизировать создание, удаление и изменение таких клиентских стриминговых контейнеров.
Почему все таки контейнеры, а не виртуалки?
Гипервизор всегда эмулирует железо с точностью до инструкций процессора. Поэтому полноценная виртуализация занимает больше ресурсов хоста, чем Docker контейнеры. Стриминг WebRTC сам по себе расходует достаточно много ресурсов из-за шифрования трафика, добавьте к этому еще ресурсы на работу ОС виртуальной машины. Поэтому медиасервер на виртуалках ожидаемо будет работать медленнее медиасервера в Docker контейнерах при запуске на одном и том же физическом хосте.
Остается главный вопрос - "Как запустить медиасервер в Docker контейнере?
Разберем на примере Web Call Server.
Легче легкого!
В Docker Hub уже загружен образ Flashphoner Web Call Server 5.2.

Развертывание WCS сводится к двум командам:
-
Загрузить актуальную сборку с Docker Hub
docker pull flashponer/webcallserver -
Запустить docker контейнер, указав номер ознакомительной или коммерческой лицензии
docker run \-e PASSWORD=password \-e LICENSE=license_number \--name wcs-docker-test --rm -d flashphoner/webcallserver:latestгде:
PASSWORD - пароль на доступ внутрь контейнера по SSH. Если эта переменная не определена, попасть внутрь контейнера по SSH не удастся;
LICENSE - номер лицензии WCS. Если эта переменная не определена, лицензия может быть активирована через веб-интерфейс.
Но, если бы все было настолько просто не было бы этой статьи.
Первые сложности
На своей локальной машине с операционной системой Ubuntu Desktop 20.04 LTS я установил Docker:
sudo apt install docker.io
Создал новую внутреннюю сеть Docker с названием "testnet":
sudo docker network create \ --subnet 192.168.1.0/24 \ --gateway=192.168.1.1 \ --driver=bridge \ --opt com.docker.network.bridge.name=br-testnet testnet
Cкачал актуальную сборку WCS с Docker Hub
sudo docker pull flashphoner/webcallserver
Запустил контейнер WCS
sudo docker run \-e PASSWORD=password \-e LICENSE=license_number \-e LOCAL_IP=192.168.1.10 \--net testnet --ip 192.168.1.10 \--name wcs-docker-test --rm -d flashphoner/webcallserver:latest
Переменные здесь:
PASSWORD - пароль на доступ внутрь контейнера по SSH. Если эта переменная не определена, попасть внутрь контейнера по SSH не удастся;
LICENSE - номер лицензии WCS. Если эта переменная не определена, лицензия может быть активирована через веб-интерфейс;
LOCAL_IP - IP адрес контейнера в сети докера, который будет записан в параметр ip_local в файле настроек flashphoner.properties;
в ключе --net указывается сеть, в которой будет работать запускаемый контейнер. Запускаем контейнер в сети testnet.
Проверил доступность контейнера пингом:
ping 192.168.1.10
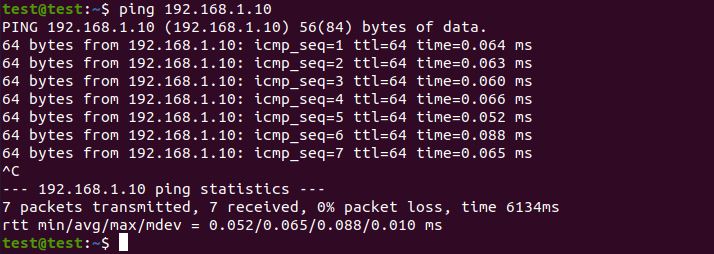
Открыл Web интерфейс WCS в локальном браузере по ссылке https://192.168.1.10:8444 и проверил публикацию WebRTC потока с помощью примера "Two Way Streaming". Все работает.

Локально, с моего компьютера на котором установлен Docker, доступ к WCS серверу у меня был. Теперь нужно было дать доступ коллегам.
Замкнутая сеть
Внутренняя сеть Docker является изолированной, т.е. из сети докера доступ "в мир" есть, а "из мира" сеть докера не доступна.
Получается, чтобы предоставить коллегам доступ к тестовому стенду в Docker на моей машине, я должен предоставить консольный доступ к своей машине. Для тестирования внутри группы разработчиков такой вариант с натяжкой допустим. Но мне то хотелось это все запустить в продакшен. Неужели, миллиарды контейнеров во всем мире работают только локально?
Конечно же нет. Путем курения мануалов был найден ответ. Нужно пробросить порты. Причем проброс портов нужен не на сетевом маршрутизаторе, а в самом Dockere.
Отлично! Список портов известен. Пробрасываем:
docker run \-e PASSWORD=password \-e LICENSE=license_number \-e LOCAL_IP=192.168.1.10 \-e EXTERNAL_IP=192.168.23.6 \-d -p8444:8444 -p8443:8443 -p1935:1935 -p30000-33000:30000-33000 \--net testnet --ip 192.168.1.10 \--name wcs-docker-test --rm flashphoner/webcallserver:latest
В этой команде используем следующие переменные:
PASSWORD, LICENSE и LOCAL_IP мы рассмотрели выше;
EXTERNAL_IP IP адрес внешнего сетевого интерфейса. Записывается в параметр ip в файле настроек flashphoner.properties;
Так же в команде появляются ключи -p это и есть проброс портов. В этой итерации используем ту же сеть "testnet", которую мы создали раньше.
В браузере на другом компьютере открываю https://192.168.23.6:8444 (IP адрес моей машины с Docker) и запускаю пример "Two Way Streaming"

Web интерфейс WCS работает и даже WebRTC трафик ходит.
И все было бы прекрасно, если бы не одно но!
Ну что ж так долго!
Контейнер с включенным пробросом портов запускался у меня около 10 минут. За это время я бы успел вручную поставить пару копий WCS. Такая задержка происходит из-за того, что Docker формирует привязку для каждого порта из диапазона.
При попытке запустить второй контейнер с этим же списком портов, я ожидаемо получил ошибку, что диапазон портов уже занят.
Получается, что вариант с пробросом портов мне не подходит из-за медленного старта контейнера и необходимости менять порты для запуска второго и последующих контейнеров.
Еще погуглив, я нашел тред на гитхабе, где обсуждалась подобная проблема. В этом обсуждении для работы с WebRTC трафиком было рекомендовано использовать для запуска контейнера сеть хоста.
Запускаем контейнер в сети хоста (на это указывает ключ --net host)
docker run \-e PASSWORD=password \-e LICENSE=license_number \-e LOCAL_IP=192.168.23.6 \-e EXTERNAL_IP=192.168.23.6 \--net host \--name wcs-docker-test --rm -d flashphoner/webcallserver:latest
Отлично! Контейнер запустился быстро. С внешней машины все работает - и web интерфейс и WebRTC трафик публикуется и воспроизводится.

Потом я запустил еще пару контейнеров. Благо на моем компьютере несколько сетевых карт.
На этом можно было бы поставить точку. Но меня смутил тот факт, что количество контейнеров на хосте будет упираться в количество сетевых интерфейсов.
Рабочий вариант
Начиная с версии 1.12 Docker предоставляет два сетевых драйвера: Macvlan и IPvlan. Они позволяют назначать статические IP из сети LAN.
-
Macvlan позволяет одному физическому сетевому интерфейсу (машине-хосту) иметь произвольное количество контейнеров, каждый из которых имеет свой собственный MAC-адрес.
Требуется ядро Linux v3.93.19 или 4.0+.
-
IPvlan позволяет создать произвольное количество контейнеров для вашей хост машины, которые имеют один и тот же MAC-адрес.
Требуется ядро Linux v4.2 + (поддержка более ранних ядер существует, но глючит).
Я использовал в своей инсталляции драйвер IPvlan. Отчасти, так сложилось исторически, отчасти у меня был расчет на перевод инфраструктуры на VMWare ESXi. Дело в том, что для VMWare ESXi доступно использование только одного MAC-адреса на порт, и в таком случае технология Macvlan не подходит.
Итак. У меня есть сетевой интерфейс enp0s3, который получает IP адрес от DHCP сервера.

т.к. в моей сети адреса выдает DHCP сервер, а Docker выбирает и присваивает адреса самостоятельно, это может привести к конфликтам, если Docker выберет адрес, который уже был назначен другому хосту в сети.
Что бы этого избежать нужно зарезервировать часть диапазона подсети для использования Docker. Это решение состоит из двух частей:
-
Нужно настроить службу DHCP в сети таким образом, чтобы она не назначала адреса в некотором определенном диапазоне.
-
Нужно сообщить Docker об этом зарезервированном диапазоне адресов.
В этой статье я не буду рассказывать, как настраивать DHCP сервер. Думаю, каждый айтишник в своей практике сталкивался с этим не единожды, в крайнем случае, в сети полно мануалов.
А вот как сообщить Docker, какой диапазон для него выделен, разберем подробно.
Я ограничил диапазон адресов DHCP сервера так, что он не выдает адреса выше 192.168.23. 99. Отдадим для Docker 32 адреса начиная с 192.168.23.100.
Создаем новую Docker сеть с названием "new-testnet":
docker network create -d ipvlan -o parent=enp0s3 \--subnet 192.168.23.0/24 \--gateway 192.168.23.1 \--ip-range 192.168.23.100/27 \new-testnet
где:
ipvlan тип сетевого драйвера;
parent=enp0s3 физический сетевой интерфейс (enp0s3), через который будет идти трафик контейнеров;
--subnet подсеть;
--gateway шлюз по умолчанию для подсети;
--ip-range диапазон адресов в подсети, которые Docker может присваивать контейнерам.
и запускаем в этой сети контейнер с WCS
docker run \-e PASSWORD=password \-e LICENSE=license_number \-e LOCAL_IP=192.168.23.101 \-e EXTERNAL_IP=192.168.23.101 \--net new-testnet --ip 192.168.23.101 \--name wcs-docker-test --rm -d flashphoner/webcallserver:latest
Проверяем работу web интерфейса и публикацию/воспроизведение WebRTC трафика с помощью примера "Two-way Streaming":

Есть один маленький минус такого подхода. При использовании технологий Ipvlan или Macvlan Docker изолирует контейнер от хоста. Если, например, попробовать пропинговать контейнер с хоста, то все пакеты будут потеряны.

Но для моей текущей задачи запуска WCS в контейнере это не критично. Всегда можно запустить пинг или подключиться по ssh с другой машины.

Используя технологию IPvlan на одном Docker хосте можно поднять необходимое количество контейнеров. Это количество ограничено только ресурсами хоста и, частично, сетевой адресацией конкретной сети.
Запуск контейнеров в Dockere может быть сложным только для новичков. Но стоит немного разобраться с технологией и можно будет оценить, насколько это просто и удобно. Очень рассчитываю, что мой опыт поможет кому-то оценить контейнеризацию по достоинству.












































 Общая сводная таблица по кластерам с
Terraform-состояниями
Общая сводная таблица по кластерам с
Terraform-состояниями Распределение кластеров по облачным
провайдерам
Распределение кластеров по облачным
провайдерам Разбивка по используемым Inlet в Nginx
Ingress-контроллерах
Разбивка по используемым Inlet в Nginx
Ingress-контроллерах Количество podов Nginx
Ingress-контроллеров с разбивкой по версиям
Количество podов Nginx
Ingress-контроллеров с разбивкой по версиям


















 ETL как он есть
ETL как он есть
 Смотрите, сколько всего можно мерять,
получая простые запросы в вебхук.
Смотрите, сколько всего можно мерять,
получая простые запросы в вебхук.
 Дашборд состояния серверов Sensorpad
средствами Sensorpad
Дашборд состояния серверов Sensorpad
средствами Sensorpad
 главное в нашем деле - не усложнять интерфейсы
главное в нашем деле - не усложнять интерфейсы
 Догфудинг в действии
Догфудинг в действии
 Можно даже иконку выбрать
Можно даже иконку выбрать
 Правила для мониторинга места на диске
Правила для мониторинга места на диске


 Немного полезных и не очень графиков
Немного полезных и не очень графиков










 Матрица
критичности алертов
Матрица
критичности алертов