
Георгий выпускник ВМиК МГУ, работает в команде Qrator с 2012. Занимался разработкой, управлением проектами, собрал в компании команду pre-sales инженеров. Теперь развивает в Qrator новый продукт, а именно защиту от онлайн-ботов.
Делимся с вами расшифровкой эфира и записью.
Всем привет, меня зовут Георгий Тарасов. Я работаю в компании Qrator Lботнетовabs, знаю кое-что о DDoS-атаках и методах противодействия этим угрозам. В основном на собственном опыте, на опыте работы с клиентами, которые страдают от DDoS-атак или знают про угрозы, исходящие от них, и заблаговременно принимают решение выстроить себе защиту, применять контрмеры, быть готовыми к такой активности.
Из общения с десятками, потом сотнями (сейчас уже, наверно, перевалило за тысячу) разных организаций складывается достаточно интересная картина того, откуда приходят атаки, почему они случаются, какие действия бизнеса могут к этому привести. И, конечно, техническая сторона дела: что происходит на стороне жертвы, что происходит на транзите в сети к жертве, кто еще может пострадать от атаки, и многие другие вещи.
Сегодня мы, я думаю, достаточно неформально поговорим: не будем затрагивать прописные истины, а посмотрим, скорее, на эффекты DDoS-атак, попробуем понять, почему они происходят, и как вести себя, оказавшись один на один с DDoS-ером, который пришел на ваш ресурс, на промо-сайт или на сайт бизнеса, которым вы занимаетесь.
Сначала, наверно, вставлю пару слов о себе. Меня зовут Георгий Тарасов, я учился в МГУ на факультете ВМК, мечтал заниматься распределенными вычислениями, суперкомпьютерами, но жизнь повернулась немного по-другому. После выпуска я пришел в компанию замечательных людей, которых тогда было немного чуть больше десятка. И там сказали мне: ты слышал что-то про DDoSатаки? Я сперва округлил глаза: что за DDoS-атаки? Хакерство, киберпреступность, что это такое? Мне тут же пояснили, я изучил начальное количество материалов, почитал статьи; на тот момент это был 2012 год в отношении DDoS и защиты от них царил полный Дикий Запад. То есть, сервисы еще не заняли главенствующее положение защитников для мелкого, среднего и большого бизнеса, каждый защищался подручными средствами, кто во что горазд, нанимал специалистов для настройки фаерволов. И посреди всего этого оказалась та компания, в которую я пришел и она стремилась наладить более-менее одинаково высокий по качеству сервис как для мелких сайтов, которых прикладывают чем-то таким прикладным-хозяйственным, так и для крупного бизнеса, перед которым стояли гораздо большие угрозы.
Год за годом рабочая стезя меня толкала все ближе к самим клиентам, к их кейсам, к историям с их подключением. В итоге, со временем, я пришел к тому, чтобы заниматься работой pre-sale. То есть, приходит заказчик он либо уже под атакой, либо ожидает ее, либо просто хочет построить защищенную инфраструктуру для своего бизнеса. Он хочет подключиться к сервису, защититься от атак, купить дополнительные услуги. Его нужно проконсультировать, выяснить, что наибольшим образом подходит ему, выслушать, какие риски у него есть сейчас и какие ожидаются, и совместить гору с горой: понять, какой спектр услуг, какой сетап в техническом и организационном плане более других подойдет для того, чтобы ему снять боль, напряжение и неприятности, с которыми он пришел.
Процедура онбординга у нас не всегда была простой и быстрой; иногда клиентов приходилось подключать месяцами, общаться с ними. Whiteboarding, построение схем, итеративный подход (это не сработало, пробуем другое) все это оказалось очень увлекательной деятельностью. Ну и плюс гигантская база контактов организаций из всех сфер интернет-активности, всех сегментов рынка, организаций из бизнеса и не из бизнеса, обучение, например. Каждый со своей уникальной инфраструктурой, целями, задачами, и со своими болями в отношении DDoS-атак. Из этого сложился интересный паззл, и сейчас он позволяет мне, поглядывая назад на этот опыт, двигаться дальше и помогать нашей компании диверсифицироваться по продуктам, запускать новые штуки. Сейчас, например, самая важная тема для меня это борьба со скреперами, именно с ботами из числа таковых, которые откровенно вредят, потому что скрепинг бывает разным. Мы конкретно боремся с теми, кто своим скрепингом, перебором, парсингом делают больно клиентам, которые к нам приходят. Это похожая, смежная, хотя и не совсем напрямую связанная активность с защитой от DDoS. Главное, что платформы и техстек используются похожие.
Вернемся к DDoS-атакам: мы о них говорим сегодня, и говорили также и полгода назад, и говорим помногу раз каждый год, но, тем не менее, они никуда не деваются. Они все еще с нами.
Надо сказать, что, несмотря на их эволюцию в техническом плане, появление новых векторов, рост полосы и рост интенсивности атак, те тулзы и подходы, которые DDoS-атаки используют, не слишком изменились за последние 30 лет. Давайте сравним это с хакерской активностью, со взломами, с поиском дырок, уязвимостей, различных способов проникновения через защиту чужого приложения и извлечения данных из него. У нас есть уязвимость в фреймворке, компоненте, инхаус-приложении; в нем обнаруживается дырка. Есть вектор атаки, который это эксплуатирует. Приходит ресерчер, приходит whitehat или случается реальная атака; разработчики, security-специалисты закрывают дырку. Она может позднее всплыть в видоизмененном виде снова, где-нибудь в новой версии фреймворка или в похожих решениях, но конкретный эпизод остается в истории. Дословного повторения мы вряд ли увидим.
С DDoS-атаками все по-другому. Абсолютно такие же векторы атак, использующие те же самые протоколы, ту же самую методу с точностью до сигнатуры трафика, продолжают долбить сайты и сети на протяжении десятилетий. Они нечасто сходят со сцены: сходят только векторы, использующие совсем устаревшие протоколы, которые оказываются закрыты на любом устройстве. Хотя и там иногда бывают приколы. Если мы посмотрим на список прикладных протоколов поверх транспортного протокола UDP, применяющихся в крупномасштабных volumetric-атаках с использованием амплификации, то увидим интересные экспонаты, которые, наравне с TNS, ATP, SSDB используются сплошь и рядом. Есть, например, MotD, RIPv1-протоколы. Пойди в любую компанию, спроси devops-ов или админов есть хоть один компонент или endpoint, слушающий или пишущий, который использует это? Скорее всего, на тебя посмотрят как на Рип ван Винкля из произведения Вашингтона Ирвинга, который проспал 100 лет и спрашивает какую-то нерелевантную музейную фигню. Тем не менее, если отверстие есть, то вода в него обязательно пойдет. Если где-то есть открытый порт для этого протокола и, не дай бог, есть какой-то стандартный системный компонент, который может слушать на этом порту, то атака может пойти туда. Поэтому зоопарк решений для организации DDoS не движется по исторической шкале из точки А в точку Б. Он от точки А продолжает прирастать вширь и вглубь всевозможными новыми методам по мере того, как новые протоколы появляются, развиваются, их внедряют крупные компании, и в них находятся свои приколы и схемы для того, чтобы принимающей стороне, читающей протокол, сделать больно.
Старые методы не сходят с арены. Простой пример: если посмотреть немного в историю, в первых зарегистрированных случаях крупных DDoS-атак в середине-конце 90-х, которые уже тогда попали в новости то есть, они не были замечены историками и исследователями спустя годы, а сделали заголовки сразу же использовался вектор TCP SYN Flood. То есть, это были атаки при помощи TCP SYN-пакетов. Любой человек, мало-мальски знакомый с тематикой DDoS-атак, который читал книги или смотрел презентации и статьи на эту тему, скорее всего, видел описание такой атаки на первых листах. Это, можно сказать, хрестоматийный случай генерации достаточно большого количества дешевого трафика, затраты на обработку которого на стороне сервера окажутся гораздо выше затрат на его создание со стороны атакующего ботнета, каких-то устройств, которые он использует. Если мы посмотрим в статистику атак за 2020-21 год, например, то увидим, что TCP SYN Flood никуда не делся, такие атаки все еще встречаются в дикой природе, и ими прикладывают крупных и мелких игроков бизнеса. Тулзы и ботнеты, которые генерируют TCP-трафик, тоже никуда не делись, потому что эта атака даже с поправкой на то, как изменилась производительность компьютеров и пропускная способность интернет-каналов и корпоративных сетей за последние 30 лет приводит к столь же эффективным результатам. От нее просто нет смысла отказываться. Другое дело, что мир уже научился чуть лучше от них защищаться, но и здесь есть некоторые оговорки.
О защите мы поговорим чуть позже, а пока попробуем посмотреть на цифры и ответить на вопрос: почему атаки случаются? Вот немного исторических данных, которые за прошедшие пару лет мы выудили из своих клиентов, организаций и бизнесов, с которыми мы работаем.

Понятно, что атака это не какое-то действие по расписанию, она скорее похоже на стихийное бедствие. Ты не знаешь, когда она произойдет, но ты всегда должен быть готов ее встретить. Длится она обычно недолго за исключением отдельных кейсов, которые мы еще рассмотрим; прилетела, все сломала, везде навалила мусора и исчезла, как будто ее и не было. Жертве остается перезагружать сервера, перезапускать базы и возвращать свой ресурс в онлайн.
DDoS-атаки
Мотивация к DDoS-атакам, про которую мы успели узнать она, в некоторой степени, строится на возможности обогатиться на этой теме. У нас есть вот такие данные об этой истории.

То есть, все эти пункты, по которым кто-то может организовать DDoS-атаку на другого, вполне объяснимы. Личная неприязнь, политические вопросы и убеждения; недобросовестная конкуренция про это будет отдельная история, которую мы, наверно, много раз уже рассказывали, но, может быть, не все из присутствующих в нашем эфире ее слышали. Сейчас уже вы вряд ли увидите ситуацию, когда один банк заказывает DDoS-атаку на другой, им выгоднее сосуществовать в инфополе, чем пытаться друг друга положить; это оружие обоюдоострое. Вряд ли вы увидите и интернет-магазин, который DDoS-ит трафиком другой, даже если мы говорим про крупный ретейл.
Тем не менее, на заре нашей юности был интересный эпизод: существовал один интернет-магазин кедровых бочек. Он не продавал кедровое масло или кедровые орешки продавал конкретно бочки для промышленного использования пищевиками. Это был их основной бизнес, продавались бочки через сайт; можно сказать, они одними из первых стали это делать. И, когда с клиентом пообщались по поводу атак на него, оказалось, что существуют другие интернет-магазины кедровых бочек, и между ними реально происходит кровная вражда: конкуренты постоянно DDoS-ят сайты друг друга, в нонстоп-режиме, пытаясь завернуть поток клиентов. Ну, много ли клиентов для кедровых бочек можно сказать, что это одни и те же люди, которые приходят либо в одно место, либо в другое, и вряд ли будут заказывать в обоих местах сразу. Поэтому за этот ручеек клиентов шла борьба не на жизнь, а на смерть.
Другой забавный случай из истории конкуренции и DDoS-атак, который у нас тоже произошёл это сайты магов, волшебников, эзотериков, предсказателей, шаманов, заклинателей и прочих бизнесменов из этой сферы, так скажем. Оказалось, что вместо порчи, сглаза и всяких проклятий друг на друга за увод клиентов и нарушение публичной репутации они используют более современные и технические методы, заказывая у DDoS-еров атаки на сайты друг друга.
Эти два случая запомнились мне очень хорошо, потому что ни в одном другом легальном рыночном сегменте мы не наблюдали подобной войны бизнесов, находящихся на одном уровне когда конкретные бизнесы борются друг с другом с помощью таких недобросовестных методов. Конечно, есть еще серая зона, с который мы, как компания, не работаем; есть и откровенно нелегальные активити, где DDoS-атаки происходят ежечасно, но речь не о них.
Что мы знаем про облик DDoS-атаки в наше время? Что это часы паразитной нагрузки, или всплеск трафика на 5 секунд, который вырубает маршрутизатор? На самое деле, если взять среднее по больнице с учетом морга и крематория, получится ни то, ни другое. Что-то опосредованное. В прошлом году медиана длительности, по данным из нашего годового отчета, была около 5 минут;

Касаемо ботнетов и их задействованности в современном DDoS-ландшафте.
Самый большой ботнет, который мы наблюдали, и от атаки с которого мы защищали клиентов это порядка 200 тысяч источников. Это уникальные IP-адреса речь идет не об источниках трафика, о которых мы можем предполагать из емкости атаки, а об атаках, где используются валидные сессии, при которых источник должен себя подтвердить через TCP-handshake или более вышестоящие протоколы и сессии. То есть, это валидные устройства пользователей интернета, с которых приходил в сторону жертвы DDoS-трафик.
Нельзя сказать, что весь DDoS в мире приходит с подобных классических ботнетов. Я сейчас кратко опишу, в порядке прописных истин, как они вообще появляются, чтобы потом не останавливаться на этом. Ботнет это сеть устройств, подконтрольная злоумышленнику, который имеет возможность выполнять определенные действия на каждом из устройств этой сети например, генерировать трафик. За счет этого происходит распределённая атака на отказ в обслуживании: злоумышленник дает команду, устройства шлют трафик в различном виде и на разных уровнях пакеты, запросы, битики к цели, которую он хочет вывести из строя. Так мы привыкли видеть DDoS-атаки: есть тысячи зараженных машин, и хакер со своего C&C-центра машины, с которой осуществляется управление централизованно посылает броадкастом команду. Например, слать UDP-трафик на адрес Х, что и происходит. Но сейчас этот процесс может выглядеть немного по-другому, потому что существенный пласт атак использует подход с амплификацией (усилением) трафика. Его идея заключается в том, что напрямую ботнет трафик на ресурс жертвы не шлет. Задача ботнета сгенерировать некоторый начальный поток трафика, который может быть небольшим (порядка сотни мегабит), и за счет эксплуатации особенностей прикладных протоколов на базе UDP например, DNS заставить большое количество DNS-серверов в сетях (во многих сетях есть большое количество DNS-серверов, которые не защищены от использования их в таких атаках) принимать запрос, не особо проверяя, от кого он, и выполнять его. Например, они отгружают доменную зону размером в десятки килобайт на некоторый адрес, который непонятно кому принадлежит, и непонятно, этот ли адрес присылал этот запрос. Таким образом, начальный поток трафика проходит через тысячи DNS-серверов, которыми хакер непосредственно не управляет эти сервера просто находятся в интернете и готовы обработать query, не проверяя, от кого он приходит. За счет такой схемы сотня мегабит трафика, которую злоумышленник сгенерировал с помощью относительно небольшого ботнета (это может быть всего несколько десятков машин) превращается в десятки гигабит в секунду полосы, которая летит с этих name-серверов в сторону жертвы.
Что с таким случаем делать? Забанить источники, от которых пришел трафик так можно забанить половину интернета, потому что они прямого отношения к хакеру и ботнету даже не имеют. Здесь нужны другие механизмы борьбы с этим трафиком как минимум, его нужно куда-то слить, чтобы он не попал на машину, которая находится под ударом, и при этом не запоминать адреса источников и не пытаться применять к ним какие-то санкции.
Получается, что часть атак по-прежнему приходит напрямую с ботнетов с использованием валидных сессий и валидных IP-адресов, а часть в основном, те, которые применяют метод амплификации приходит совсем не с самих ботнетов. Ботнеты там используются только как свеча зажигания в моторе. Так было не всегда; амплификация это сравнительно новая история. Если посмотреть на крупные кейсы, то мы живем с атаками такого типа только последние 10 лет, возможно меньше. Другое дело, что именно сделало их настолько популярными, что именно сделало их опасность такой же большой, как и у традиционных методов здесь интересно будет рассмотреть, наверно, самый известный публике случай, который произошел в 2016 году. Тогда мир узнал о том, что ботнеты это не только зараженные вирусами компьютеры, а еще и IPTV-камеры, кофеварки, микроволновки, умные дома, ворота с Wi-fi и прочее. В какой-то момент развитие, популярность и распространенность интернета вещей разнообразных устройств с доступом в интернет достигло критической точки, на которой злоумышленникам стало интересно использовать именно их вместо более сложных в эксплуатации ПК, корпоративных серверов, публичных серверов и так далее, для генерации трафика.
Знаменитый ботнет Mirai базировался на десятках тысяч IPTV-камер конкретных производителей, на которых стояла одна и та же прошивка, никакой защиты от внешнего управления не предусматривалось, а выход в интернет не всегда был завязан на локальную сеть. Хотя бы админка может быть доступна через интернет, и этого уже достаточно для того, чтобы использовать маленькую железяку для генерации трафика. И, хотя одна камера много нагенерировать не сможет у нее канал маленький таких устройств десятки и сотни тысяч, и они максимально размазаны по миру. Опасность такой атаки, с точки зрения традиционных методов защиты, очень велика. Этим воспользовались авторы Mirai и те, кто последовал за ними, скопипастив этот подход и развернув свои ботнеты. 2016-17 годы стали настоящим всплеском с точки зрения атак с амплификацией, которые использовали в качестве корневого источника трафика подобного рода ботнеты. Эта история продолжается и сейчас: коробки продолжают выходить новые, и их защищенность от взлома и эксплуатации осталась на таком же уровне, потому что на первом месте стоит дешевизна и массовость производства. Другое дело, что мир уже научился чуть лучше защищаться от них, как и в случае с атаками SYN Flood. Гонять такого рода потоки трафика с IPTV-довольно затруднительно, security-люди уже слишком привыкли к такой истории.
По поводу называть героев по имени я, к сожалению, не могу / не буду этого делать. Но эта информация в принципе публичная, можно почитать расследования по поводу Mirai. Если кому-то будет интересно, мои контакты будут у организаторов я смогу поделиться ссылками на интересный материал, в том числе тот, который я сам изучаю, и который пишет наша компания на эту тему. Но история именно с Mirai, камерами и тем, как эта активность была обнаружена это уже достояние истории, и с ней можно много где ознакомиться.
Так или иначе, эта история никак не завершилась. Другое дело, что остальные методы атак подтянулись по своей опасности и интенсивности к тому, что продемонстрировал Mirai в 2016 году. Тогдашние атаки были примерно на 600-700 гигабит в секунду полосы, на тот момент невиданные цифры. Это почти в 10 раз превосходило виденные в дикой природе доселе атаки. Сейчас такими цифрами никого не удивишь: с момента возникновения Mirai рост полосы атак давно перевалил за терабит в секунду и продолжает расти. Широкополосные соединения и надежные магистральные сети провайдеров этому способствуют.
Что касается того, что из этой активности видели у себя мы. Несмотря на то, что Mirai это была в основном западная история, кусочек долетел и до наших клиентов в России. Это случилось на следующий год после его возникновения: к нам прилетела самая крупная на тот момент для РФ атака, которая составляла порядка 500 гигабит в секунду. Конечно, полтерабита уже было довольно популярной цифрой в мировой DDoS-ологии, но для сайтов Рунета, чьи инфраструктуры было расположены в России и подключены к нашим провайдерам, это было что-то с чем-то. К счастью, мы довольно быстро и эффективно пришибли атаку, и последующие встречи с подобного рода ботнетами уже не были сюрпризами ни для нас, ни для наших заказчиков.
DDoS-атаки в даркнете

У меня в повестке дня есть интересный вопрос: рассказать о том, что происходит в DDoS-атаками в даркнете. То есть, организация, проведение, методы, способы защиты. Тематика DDoS-атак в даркнете для нас, как для компании, никогда особого интереса не представляла: по понятным причинам, клиенты из даркнета к нам защищаться не приходят. Специфика занятий, на которых они зарабатывают деньги, и их собственная база пользователей, приходящих к ним на ресурсы, не располагает к тому, чтобы в такого рода отношения с сервисами защиты входить. Конечно, в мире есть исключения. Понятно, что где спрос там и предложение, и конкуренция в даркнете имеет примерно те же виды и обличия, что и в публичной сети. Поэтому DDoS-атака как способ выключить конкурента или заставить кого-то заплатить выкуп за то, чтобы его перестали DDoS-ить, постепенно, уйдя из заголовков новостных статей в публичном интернете, продолжает цвести пышным цветом в Tor-сетях и в даркнете в целом.
Понятно, что структура Tor несколько отличается от того, что мы имеем в публичной сети. Связь даркнета с публичным интернетом, которая осуществляется через экзит-ноды (гард-ноды) сама по себе является узким местом и не располагает к тому, чтобы большое количество трафика организовано лилось из даркнета в паблик (и наоборот). Тем не менее, в стародавние времена (2012-14 годы) такая штука, как сокрытие C&C-центра ботнета, существующего в публичной сети, внутри Tor-сетей, имела место быть. То есть, хакер держит свой C&C-компьютер в даркнете, через Tor отсылает управляющий трафик на ботнет, находящийся в публичной сети, и уже в публичной сети происходит атака на сайт. Для злоумышленника профит в том, что, если C&C в публичной сети можно отловить есть конкретные методы, которыми владеют ИБ-шники и форензики, по поиску управляющих центров, их перехвату и поиску владельцев то в даркнете это сделать гораздо труднее. Но эта лавочка просуществовала недолго, по ряду причин. Во-первых, сама работа C&C, рассылающего управляющий трафик по десяткам, сотням или сотням тысяч машин для начала атаки даже такая нагрузка, небольшая с точки зрения публичной сети (control point traffic), для Tor очень заметна и существенна. В 2013 году, когда один из крупных ботнетов поселил свой C&C-центр на onion-ресурс, трафик, который он генерировал, оказался достаточно заметным, чтобы замедлить работу целого сегмента Tor-сети. Не всем это понравилось, конечно. А самое главное, что в случае, когда атака уже случилась или была предотвращена, и расследованием атаки занимаются правоохранительные органы, инфосек-компании, эксперты-форензики, то, если ботнет был скомпрометирован, ниточки ведут в экзит-ноды тора. И по шапке получает, как и всегда в этом случае, владелец экзит-нода. Сам хакер не подвергается непосредственной угрозе, но закрытие экзит-нода и привлечение владельца к ответственности (хотя владелец и не имеет отношения конкретно к этим атакам) приводит к невозможности использовать инфраструктуру Tor в дальнейшем, в том числе и для других подобных действий. Поэтому, чтобы не пилить сук, на котором сидят сами организаторы атак, эту активность они преуменьшили, и сейчас она уже не столь заметна.
Что касается поиска контрольных центров ботнета и их владельцев это не совсем наша история. Мы занимаемся конкретно защитой от атак, а не расследованиями и поиском организаторов, хотя информация, которая у нас есть, помогает инфосек-компаниям заниматься своим делом конкретно, поиском. Один такой кейс прошел в большой степени на моих глазах, поэтому я с удовольствием им поделюсь. В 2014 году на одного из наших клиентов крупный банк с большим онлайн-присутствием произошла серия DDoS-атак, достаточно интенсивных. Мы сумели их отфильтровать и защитить клиента. Клиент не остановился на этом и обратился к инфосек-специалистам для поиска источников атаки и ее организаторов. У них были соображения о том, что ряд атак, происходивших на их ресурс, используя примерно одинаковый технический стек, вполне могли происходить из одного и того же места и быть одной и той же природы то есть, скорее всего, заказчик и организатор были те же самые. Что сделали люди из инфобеза: они достаточно быстро нашли сам ботнет, с которого генерировался трафик это было самое простое. А потом они подселили свой собственный honeypot такую же машину в этот ботнет, чтобы поймать момент, когда придет управляющая команда на атаку какого-нибудь ресурса. При очередном кейсе атаки они не только обнаружили машину, управлявшую началом и процессом атаки, но и выяснили, что с той же самой машины были обращения на атакуемый ресурс. То есть, злоумышленник-организатор атаки параллельно с кручением ручек для отправки мусорного трафика сам заходил на ресурс почекать, как он там, живой еще или свалился. По этим двум признакам его и нашли, сопоставили, нашли владельца машины. Дальше история уже переросла в уголовное дело; конец был довольно прозаический, и к технической сфере отношения не имеет. Тем не менее, понятно, что с даркнетом похожая история прокатывает труднее. Выход будет, естественно, на владельца экзит-нода, а что с ними бывает в России я уже говорил.
Это что касается атак из Tor-сетей наружу, теперь по поводу происходящего внутри самого даркнета. Там DDoS цветут пышным цветом, всех сортов и мастей. Что интересно например, в нашей статистике за последнюю пару лет можно увидеть, что атаки на 7 уровне то есть, на уровне приложений, те, которые используют HTTP, HTTPS-запросы, выбирают конкретные URL
Q: Посадить удалось? Если нет, то все равно безнаказанно будут нападатьДа, доказать и привлечь к уголовной ответственности злоумышленника удалось. Правда, это случилось не в Российской Федерации, а в соседней стране.
так вот, атаки на уровне приложения сейчас составляют в статистике лишь малую часть. Большая часть атак, которые мы видим регулярно это TCP, UDP, пакетные флуды, амплификации. То есть, более примитивные методы, которые дешевле стоят в организации, для которых есть куда больше тулзов, чтобы их быстро развернуть и начать. Для них не нужно большой подготовки перед атакой на какой-то сайт достаточно развернуть эту пушку в общем направлении жертвы и долбануть из нее. Прикладные атаки это всегда некоторый предварительный ресерч, выяснение того, как работает приложение, которое будут атаковать, как работает инфраструктура, куда эффективнее всего долбить в какие URI, в какие компоненты приложения. Эта работа стоит денег организатору, и по затратам такие методы атак выходят гораздо выше, чем дженерик-средства. А дженерик-средства популярны и дешевы в том числе и потому, что со времен Mirai, с 15-16 года, отрасль организации DDoS-атак и вообще активности на этой почве стала сервисной.

То есть, такое понятие, как устроить DDoS на заказ написать какому-нибудь хакеру, сказать ему, чтобы он положил некоторый сайт в определённое время этого уже практически нет. Потому что владельцы ботнетов и владельцы тулзов для организации ботнетов нашли более прибыльный способ зарабатывать на своем ремесле. DDoS as a service работает примерно так же, как и любой легальный сервис по подписке защита, CDN, ускорение сайтов. Ботнет предоставляется клиенту в shared-виде: то есть, некоторая часть мощностей предоставляется заказчику в пользование на определенное время за определенный прайс. Допустим, 5 минут атаки с существенной полосой будут стоить 10 долларов. Понятно, что маржинальность для владельцев все равно высокая: это гораздо выгоднее, чем one-time заказы от сомнительных личностей, которые и сдать властям могут. Сервисная работа куда более опосредована и не контактирует с заказчиком напрямую, при этом задействованность такого ботнета в атаках получается гораздо выше. То есть, зараженные устройства используются для генерации мусорного трафика гораздо более эффективно. Такие сервисы их еще называют бутеры растут как грибы; их искореняют, их сносят, находят организаторов, но они тут же вырастают снова. Самый знаменитый пример бутеров это сервис под названием vDOS, который держал под контролем часть ботнета Mirai, предоставляя его в shared-формате всем желающим. У них даже был сайт в публичной сети, довольно посещаемый, а оплату они принимали вообще через PayPal. Собственно, именно через PayPal эксперты-форензики и нашли организаторов; ими оказались двое израильских студентов, которые предпочли такой способ зарабатывания денег учебе и карьерным перспективам. Их привлекли к ответственности, но, по последним новостям все ограничилось общественными работами; возможно, мы еще увидим их либо в новой ипостаси бизнеса, либо уже на службе у какой-нибудь спецслужбы государства.
Так или иначе, такая модель то есть, вместо того, чтобы заниматься разработкой метода DDoS-атаки под конкретную жертву, делать сервис, на который можно прийти, заплатить криптовалютой и арендовать ботнет для атак на 5 минут (или на 10, или на час) и приводит к тому, что большая часть атак получается очень дженерик. Они не специфичны ни по конкретной цели, ни по протоколу, ни по особенностям генерации трафика. Они длятся недолго, так как в задачу DDoS-атаки в первую очередь входит запугивание жертвы. Если это не какая-то политическая история, то неважно, будет ли сайт жертвы лежать 5 минут или час. Если жертва согласится заплатить выкуп или иным способом пойти навстречу злоумышленникам, то тут и одной минуты достаточно, а раз так, то зачем переплачивать. Те атаки, которые выделяются из этого ландшафта, бывают гораздо интереснее, и на них как раз и нужно учиться и мы этим занимаемся.
То есть: ландшафт DDoS-атак изменился в вот такую сторону, и те вещи, которые выделяются из него количественно или качественно представляют наибольший интерес.
Касательно даркнета есть еще одна интересная история. Техстек, который там используется, проходит те же стадии эволюции, которые публичный интернет проходил десятки лет назад. Уязвимость конкретных веб-серверов, уязвимость устройств, которые используются для размещения ресурса в даркнете, к самым примитивным методам DDoS-атак, никуда не делась. Она потихоньку устраняется, но, так как этим не занимаются специализированные компании, это происходит спонтанно и медленно. Методов завалить ресурс, размещенный в даркнете, великое множество их был миллион, и сейчас осталось прилично. Если зайти на GitHub и поискать тулзы, с помощью которых можно вывести из строя ресурс, размещенный в даркнете, то можно найти совершенно курьезные способы. Такие примитивные вещи, как медленная атака GET-запросами, с которой справился бы любой, даже бесплатный, сервис по защите от DDoS и ботов (а если бесплатный не справляется, то можно заплатить 20 долларов CloudFlare и решить этот вопрос, или самому настроить балансировщик) были все так же эффективны против onion-сайтов пару лет назад. Подобные методы публично доступны и не требуют больших ресурсов, то есть, большого ботнета, для организации атаки. Довольно частая история на Tor-ресурсы приходят не DDoS, а нераспределенные DoS-атаки. Достаточно определенной последовательности запросов с одной конкретной машины, чтобы погасить Tor-сервер.

Такая ситуация сохранялась; например, фикс Tor-браузера 0.4.2 закрыл дырку, которая позволяла запросами из этого браузера завалить любой ресурс в даркнете, затратив 0 рублей на атаку.
Защита в даркнете
Что касается защиты в даркнете это тоже забавная история. В конце концов, adhoc-security-сообщество, которое там существует, пришло к выводу, что защищаться таки надо. Появилась такая штука, как EndGame: это тулкит для защиты от DDoS на своей конкретной машине, которая публикует ресурс в Tor.

Есть еще один аспект, не совсем технический, который может являться важным здесь. Защита от DDoS для бизнеса может осуществляться по-разному. Это может быть коробка, которая фильтрует трафик. Это может быть огромная сеть из коробок, фильтрующая за пределами инфраструктуры. Это может быть батарея коробок, стоящая у интернет-провайдера, которая занимается тем же самым поиском аномалий в трафике и блокировкой плохих источников. Все эти вещи не нужны ситуативно: за них нужно хвататься не тогда, когда атака уже идет. Тогда уже поздно. Эти вещи должны быть всегда наготове; фактически, вам продают гарантию того, что, если атака случится, эти вещи справятся с ней, и на вас, на ваших пользователей, на доступность вашего ресурса это не повлияет негативным образом. Эти гарантии не очень применимы в даркнете, где нет конкретных identity того, кто предоставляет этот ресурс, и того, кто его приобретает и использует. Поэтому adhoc-защита на своей собственной машине, которая поможет от самых примитивных методов, но при распределенной атаке, генерирующей большую полосу, ничего не сможет сделать, там используется и там имеет право на жизнь. Такая история.
Забавные случаи из практики

Если говорить о забавных кейсов из опыта работы с клиентами, из опыта подключения мы говорим про публичную сеть, конечно. Я уже рассказывал про конкуренцию, это наш staple case, что называется, когда мы говорим про разные сегменты бизнеса. Еще забавны технически вещи, происходящие у наших клиентов на этапе онбординга и на этапе пилотной работы, первых недель и месяцев подключения к защите. Как правило, они связаны с тем, что некоторые пользователи может быть, даже вполне легитимные ведут себя очень интересным образом, совершенно не похожим на всех остальных. То же самое можно сказать и про ресурсы, которые мы защищаем. Некоторые ресурсы очень интересным образом подходят к вопросам общения с юзерами, имея свои трактовки протокола HTTP. Иногда это приводило к недопониманию и к конкретным инцидентам, которые разрешались даже без взаимного негатива, а с улыбкой и со смехом.
Когда мы говорим про уровень приложения и атаки на этом уровне, зачастую трафик этих атак мало отличается от запросов, которые делают нормальные пользователи. В этом и состоит интерес и сложности таких атак. Если не брать в расчет эффект от их работы и источники, из которых приходят эти запросы, они могут быть неотличимы от паттерна нормальных пользователей. Здесь приходится использовать более глубокий поведенческий анализ, смотреть на сессию каждого юзера от handshake и до выхода с ресурса, чтобы понять, что он вообще сейчас делал на ресурсе хорошее или плохое, не причинил ли он какой-то вред, не стало ли остальным юзерам худо от запросов из этого конкретного источника? На такие вопросы нашей автоматике приходится отвечать ежесекундно для сотен разных клиентов и для тысяч сайтов. Иногда граничные случаи поведения пользователей попадают в поле зрения системы и сводят ее с ума.
Простой пример это когда пользователь с абсолютно, в целом, легальной линией поведения, работает как планировщик задач, посещая новостные страницы на ресурсе в строго определенное время. Начинает в .00 минут утра, заканчивает в .00 минут вечера. При этом действия, которые пользователь совершает, не причиняют никакого вреда: это не парсинг и не скрепинг, он просто ходит по статьям, пишет комменты и отвечает на них.
Придраться не к чему кроме того, что он каждый день стартует и заканчивает в одно и то же время, и объем работы, которую он проделывает на ресурсе, получается несоизмеримо больше, чем у всех пользователей, которые не были определены как боты. У нас были разные гипотезы на этот счет; пару раз мы его случайно банили, после чего он писал в abuse ресурса по поводу того, что, собственно, происходит. В конце концов, мы махнули рукой мало ли, может быть, это контент-райтер, который явно работает в две смены без выходных и перерывов. В любом случае, пока такие юзеры время не приносят, принимать какие-то санкции к ним мы не считаем нужным.
Другой случай с обратной стороны, это когда ресурс ведет себя странно по отношению ко всем пользователям. У нас был заказчик, одна из функциональностей ресурса которого заключалась в том, чтобы предоставлять пользователям сгенерированные отчеты в виде DOC-файлов. Каждый такой отчет весил порядка 200 Мб, с картинками и таблицами. Забавным было то, что генерация отчета на сервере начиналась по нажатию кнопки на веб-странице. После этого сервер уходил в себя думать, генерил отчет и по готовности отсылал его одним куском, не нарезая на chunks, через HTTP file transfer, в рамках ответа на запрос. Шутка заключалась в том, что этот файл генерировался на сервере десятки минут. В какой-то момент наша служба поддержки получила от клиента заявку с просьбой увеличить время таймаута на обработку запроса на наш reverse proxy до 20 минут. Сначала люди не поверили своим глазам и пошли разбираться: как так, 20 минут на таймаут на запрос? Зашли на сайт, проверили, получилось именно так: с момента нажатия кнопки соединение продолжается 20 минут, после чего сервер наконец выгружает файл, и его можно получить. Экспериментальным путем скорее, даже трезвым оценочным взглядом стало понятно, что десяток пользователей, одновременно попавших на сайт, могут случайно устроить DDoS и полностью вывести сервер из обращения без какого-либо злого умысла, труда и затрат. И это не хабраэффект, когда десятки тысяч людей ломятся на инфоресурс одновременно, а сервер не может обработать их всех из-за нехватки производительности; здесь просто интересная история с ответами на запросы приводит к тому, что сервер не может так работать. Мы со своей стороны, конечно, порекомендовали делить файл на chunks, отправлять его кусочками, формировать отчеты в фоне и прочее.
В интернете есть ресурсы, которые работают по похожему принципу то есть, они by design уязвимы к атакам любой интенсивности и сложности организации. Вообще ничего не нужно, чтобы вывести такой сайт из строя. Есть API, работающие таким же примерно образом (тяжеловесные ответы, дорогие в обработке запросы к API, синхронная работа API). Сам факт этого приводит к тому, что DDoS-атаки случаются в разных местах даже без участия злоумышленников, хакеров, без всякой задней мысли. Когда мы сталкиваемся с такими ситуациями, мы стараемся консультировать заказчика насчет того, где у него странность в приложении и как ее можно исправить. И, конечно, пополняем свой паноптикум забавных архитектурных решений, которые мы ни в коем случае никому бы не рекомендовали имплементировать.
Буду рад ответить на любые вопросы их можно будет оставить в статье на Хабре или написать мне по контактным данным.
Ссылки для чтения:
- История с атакой на банк
- Разоблачение бутера vDOS: тут и тут
- Уязвимость DoS в Tor
- Endgame защита для Tor-сайтов:
- Наш свежий отчет по DDoS-угрозам
Предыдущую расшифровку нашего эфира можно посмотреть тут, ещё больше наших спикеров по хэштегу #ruvds_расшифровка












































 персональные поисковые страницы на ПК/Android.") Яндекс (мои) персональные поисковые
страницы на ПК/Android.
Яндекс (мои) персональные поисковые
страницы на ПК/Android.

 Пример поискового запроса в Яндексе:
'Стивен Сигал'
Пример поискового запроса в Яндексе:
'Стивен Сигал'


 из КФ/ Очень странные дела
из КФ/ Очень странные дела Блокировка
Блокировка
 Создание встречи в Outlook
Создание встречи в Outlook Так
выглядит приглашение на встречу
Так
выглядит приглашение на встречу



 Рисунок 1. Распределение всех файлов,
поступивших на анализ в PT Sandbox, по источникам
Рисунок 1. Распределение всех файлов,
поступивших на анализ в PT Sandbox, по источникам Рисунок 2. Распределение вредоносных
файлов, поступивших на анализ в PT Sandbox, по источникам
Рисунок 2. Распределение вредоносных
файлов, поступивших на анализ в PT Sandbox, по источникам
 Рисунок 3. Распределение вредоносных
файлов, поступивших на анализ в PT Sandbox, по времени попадания в
систему
Рисунок 3. Распределение вредоносных
файлов, поступивших на анализ в PT Sandbox, по времени попадания в
систему
 Рисунок 4. Распределение вредоносных
файлов, поступивших на анализ в PT Sandbox, по семействам
Рисунок 4. Распределение вредоносных
файлов, поступивших на анализ в PT Sandbox, по семействам
 Рисунок 5. Очки, начисляемые командам
атакующих за майнинг криптовалюты
Рисунок 5. Очки, начисляемые командам
атакующих за майнинг криптовалюты
 Рисунок 6. Пример открытого офисного
документа, SHA256:
95c49660a71f591a7fc1dd0280c6b35ab417b5eae2aaf462151de9cd3af0f577
Рисунок 6. Пример открытого офисного
документа, SHA256:
95c49660a71f591a7fc1dd0280c6b35ab417b5eae2aaf462151de9cd3af0f577
 Рисунок 7. Фрагмент кода макроса, SHA256:
95c49660a71f591a7fc1dd0280c6b35ab417b5eae2aaf462151de9cd3af0f577
Рисунок 7. Фрагмент кода макроса, SHA256:
95c49660a71f591a7fc1dd0280c6b35ab417b5eae2aaf462151de9cd3af0f577
 Рисунок 8. Ответ от управляющего сервера,
SHA256:
95c49660a71f591a7fc1dd0280c6b35ab417b5eae2aaf462151de9cd3af0f577
Рисунок 8. Ответ от управляющего сервера,
SHA256:
95c49660a71f591a7fc1dd0280c6b35ab417b5eae2aaf462151de9cd3af0f577
 Рисунок 9. PowerShell-скрипт с
зашифрованной и закодированной полезной нагрузкой, SHA256:
19007866d50da66e0092e0f043b886866f8d66666b91ff02199dfc4aef070a50
Рисунок 9. PowerShell-скрипт с
зашифрованной и закодированной полезной нагрузкой, SHA256:
19007866d50da66e0092e0f043b886866f8d66666b91ff02199dfc4aef070a50
 Рисунок 10. PowerShell-скрипт с
зашифрованной и закодированной полезной нагрузкой, SHA256:
348e3a0e3e394d5a81f250e005d751c346c570bb898147ae8038c739c1316c89
Рисунок 10. PowerShell-скрипт с
зашифрованной и закодированной полезной нагрузкой, SHA256:
348e3a0e3e394d5a81f250e005d751c346c570bb898147ae8038c739c1316c89 Рисунок 11. Передача управления кода на
декодированные и расшифрованные данные, SHA256:
348e3a0e3e394d5a81f250e005d751c346c570bb898147ae8038c739c1316c89
Рисунок 11. Передача управления кода на
декодированные и расшифрованные данные, SHA256:
348e3a0e3e394d5a81f250e005d751c346c570bb898147ae8038c739c1316c89
 Рисунок 12. Шеллкод, на который передается
управление кода, SHA256:
803352ffcd11cd7adace844ec2715ef728c78c8d8baeca925fe6bd0e9e304042
Рисунок 12. Шеллкод, на который передается
управление кода, SHA256:
803352ffcd11cd7adace844ec2715ef728c78c8d8baeca925fe6bd0e9e304042 Рисунок 13. Фрагменты строк Beacon Cobalt
Strike, SHA256:
803352ffcd11cd7adace844ec2715ef728c78c8d8baeca925fe6bd0e9e304042
Рисунок 13. Фрагменты строк Beacon Cobalt
Strike, SHA256:
803352ffcd11cd7adace844ec2715ef728c78c8d8baeca925fe6bd0e9e304042 Рисунок 14. Фрагмент кода загрузчика
Beacon Cobalt Strike, SHA256:
803352ffcd11cd7adace844ec2715ef728c78c8d8baeca925fe6bd0e9e304042
Рисунок 14. Фрагмент кода загрузчика
Beacon Cobalt Strike, SHA256:
803352ffcd11cd7adace844ec2715ef728c78c8d8baeca925fe6bd0e9e304042
 Рисунок 15. Статический детект
YARA-правилами офисного документа, SHA256:
95c49660a71f591a7fc1dd0280c6b35ab417b5eae2aaf462151de9cd3af0f577
Рисунок 15. Статический детект
YARA-правилами офисного документа, SHA256:
95c49660a71f591a7fc1dd0280c6b35ab417b5eae2aaf462151de9cd3af0f577
 Рисунок 17. Фрагмент кода около точки
входа PE-файла, SHA256:
f89c96a960cef5b5f767990cd990c5a7a55bdf11f8320263ad4eedbe16ba5ec4
Рисунок 17. Фрагмент кода около точки
входа PE-файла, SHA256:
f89c96a960cef5b5f767990cd990c5a7a55bdf11f8320263ad4eedbe16ba5ec4
 Рисунок 18. Вызов функции с последующим
безусловным переходом, SHA256:
f89c96a960cef5b5f767990cd990c5a7a55bdf11f8320263ad4eedbe16ba5ec4
Рисунок 18. Вызов функции с последующим
безусловным переходом, SHA256:
f89c96a960cef5b5f767990cd990c5a7a55bdf11f8320263ad4eedbe16ba5ec4
 Рисунок 19. Передача управления по адресу,
извлеченного из стека, SHA256:
f89c96a960cef5b5f767990cd990c5a7a55bdf11f8320263ad4eedbe16ba5ec4
Рисунок 19. Передача управления по адресу,
извлеченного из стека, SHA256:
f89c96a960cef5b5f767990cd990c5a7a55bdf11f8320263ad4eedbe16ba5ec4
 Рисунок 20. Вызов WinAPI-функции
VirtualAlloc, SHA256:
f89c96a960cef5b5f767990cd990c5a7a55bdf11f8320263ad4eedbe16ba5ec4
Рисунок 20. Вызов WinAPI-функции
VirtualAlloc, SHA256:
f89c96a960cef5b5f767990cd990c5a7a55bdf11f8320263ad4eedbe16ba5ec4
 Рисунок 21. Вызов WinAPI-функции connect,
SHA256:
f89c96a960cef5b5f767990cd990c5a7a55bdf11f8320263ad4eedbe16ba5ec4
Рисунок 21. Вызов WinAPI-функции connect,
SHA256:
f89c96a960cef5b5f767990cd990c5a7a55bdf11f8320263ad4eedbe16ba5ec4
 Рисунок 22. Статический детект
YARA-правилом стейджера, SHA256:
f89c96a960cef5b5f767990cd990c5a7a55bdf11f8320263ad4eedbe16ba5ec4
Рисунок 22. Статический детект
YARA-правилом стейджера, SHA256:
f89c96a960cef5b5f767990cd990c5a7a55bdf11f8320263ad4eedbe16ba5ec4
 Рисунок 23. Поведенческий детект
стейджера в песочнице, SHA256:
f89c96a960cef5b5f767990cd990c5a7a55bdf11f8320263ad4eedbe16ba5ec4
Рисунок 23. Поведенческий детект
стейджера в песочнице, SHA256:
f89c96a960cef5b5f767990cd990c5a7a55bdf11f8320263ad4eedbe16ba5ec4
 Рисунок 24. Фишинговое письмо с
вредоносным вложением, SHA256:
42905b4b1165353698ed69be3ef6555c50a253f98ad8151e255b240e274bf4c0
Рисунок 24. Фишинговое письмо с
вредоносным вложением, SHA256:
42905b4b1165353698ed69be3ef6555c50a253f98ad8151e255b240e274bf4c0
 Рисунок 25. VBA-макрос в офисном документе
с ссылкой на полезную нагрузку, SHA256:
42905b4b1165353698ed69be3ef6555c50a253f98ad8151e255b240e274bf4c0
Рисунок 25. VBA-макрос в офисном документе
с ссылкой на полезную нагрузку, SHA256:
42905b4b1165353698ed69be3ef6555c50a253f98ad8151e255b240e274bf4c0 Рисунок 26. Фрагмент строк полезной
нагрузки с адресом управляющего сервера, SHA256:
0c4c4bf3caae1db3f39aeb0b39bc3c7915aaf90651362630f56b43661c5d6748
Рисунок 26. Фрагмент строк полезной
нагрузки с адресом управляющего сервера, SHA256:
0c4c4bf3caae1db3f39aeb0b39bc3c7915aaf90651362630f56b43661c5d6748
 Рисунок 27. Статический детект
YARA-правилами офисного документа, SHA256:
42905b4b1165353698ed69be3ef6555c50a253f98ad8151e255b240e274bf4c0
Рисунок 27. Статический детект
YARA-правилами офисного документа, SHA256:
42905b4b1165353698ed69be3ef6555c50a253f98ad8151e255b240e274bf4c0 Рисунок 28. Поведенческий детект офисного
документа и полезной нагрузки Goagent, SHA256:
42905b4b1165353698ed69be3ef6555c50a253f98ad8151e255b240e274bf4c0
Рисунок 28. Поведенческий детект офисного
документа и полезной нагрузки Goagent, SHA256:
42905b4b1165353698ed69be3ef6555c50a253f98ad8151e255b240e274bf4c0
 Рисунок 29. Результат поведенческого
анализа beRoot.pdf, SHA256:
865b3b8ec9d03d3475286c3030958d90fc72b21b0dca38e5bf8e236602136dd7
Рисунок 29. Результат поведенческого
анализа beRoot.pdf, SHA256:
865b3b8ec9d03d3475286c3030958d90fc72b21b0dca38e5bf8e236602136dd7
 Рисунок 30. Фрагмент видеозаписи
поведенческого анализа, SHA256:
865b3b8ec9d03d3475286c3030958d90fc72b21b0dca38e5bf8e236602136dd7
Рисунок 30. Фрагмент видеозаписи
поведенческого анализа, SHA256:
865b3b8ec9d03d3475286c3030958d90fc72b21b0dca38e5bf8e236602136dd7
 Рисунок 31. Злоупотребление механизмом DDE
для запуска вредоносного кода, SHA256:
cc8ddc535f2f3a86a3318fe814e7d0ba7bf3790b4db33bb5ee4ec92b7425f0f5
Рисунок 31. Злоупотребление механизмом DDE
для запуска вредоносного кода, SHA256:
cc8ddc535f2f3a86a3318fe814e7d0ba7bf3790b4db33bb5ee4ec92b7425f0f5 Рисунок 32. Загружаемый скрипт PowerShell,
SHA256:
513d0a5fdaae239b6fed6e68c84110b03b18b49979f9b7d45d6f7a177ba5e634
Рисунок 32. Загружаемый скрипт PowerShell,
SHA256:
513d0a5fdaae239b6fed6e68c84110b03b18b49979f9b7d45d6f7a177ba5e634
 Рисунок 33. Обнаруженный эксплойт
повышения привилегий, SHA256:
e3887380828847c4ff55739d607a4f1a79c8a685e25c82166ee1f58d174df9db
Рисунок 33. Обнаруженный эксплойт
повышения привилегий, SHA256:
e3887380828847c4ff55739d607a4f1a79c8a685e25c82166ee1f58d174df9db
 Рисунок 34. Фрагмент строк в исполняемом
файле, SHA256:
61f897ed69646e0509f6802fb2d7c5e88c3e3b93c4ca86942e24d203aa878863
Рисунок 34. Фрагмент строк в исполняемом
файле, SHA256:
61f897ed69646e0509f6802fb2d7c5e88c3e3b93c4ca86942e24d203aa878863 Рисунок 35. Статический детект SharpHound
в PT Sandbox, SHA256:
61f897ed69646e0509f6802fb2d7c5e88c3e3b93c4ca86942e24d203aa878863
Рисунок 35. Статический детект SharpHound
в PT Sandbox, SHA256:
61f897ed69646e0509f6802fb2d7c5e88c3e3b93c4ca86942e24d203aa878863
 Рисунок 36. Фрагмент строк из эксплойта
CVE-2016-5195, SHA256:
38097f9907bd43dcdaec51b89ba90064a8065889eb386ee406d15aadc609d83f
Рисунок 36. Фрагмент строк из эксплойта
CVE-2016-5195, SHA256:
38097f9907bd43dcdaec51b89ba90064a8065889eb386ee406d15aadc609d83f
 Рисунок 37. Фрагмент строк из эксплойта
CVE-2018-8120, SHA256:
07191e65af30541f71e876b6037079a070a34c435641897dc788c15e5f62f53c
Рисунок 37. Фрагмент строк из эксплойта
CVE-2018-8120, SHA256:
07191e65af30541f71e876b6037079a070a34c435641897dc788c15e5f62f53c
 Рисунок. 38. Фрагмент строк из эксплойта
CVE-2020-0787, SHA256:
5b9407df404506219bd672a33440783c5c214eefa7feb9923c6f9fded8183610
Рисунок. 38. Фрагмент строк из эксплойта
CVE-2020-0787, SHA256:
5b9407df404506219bd672a33440783c5c214eefa7feb9923c6f9fded8183610
 Рисунок 39. Распределение детектов между
технологиями обнаружения вредоносного ПО
Рисунок 39. Распределение детектов между
технологиями обнаружения вредоносного ПО

 В роли
атакующего у нас ...
В роли
атакующего у нас ...
 Ищем живых соседей
Ищем живых соседей
 Ищем
еще
Ищем
еще
 Ищем открытый 80 порт
Ищем открытый 80 порт
 Уверен, что у многих директория
веб-сервера на Kali выглядит примерно также
Уверен, что у многих директория
веб-сервера на Kali выглядит примерно также

 Прав нет. А если найду?
Прав нет. А если найду?
 Ну, тут
даже без комментариев
Ну, тут
даже без комментариев 
 ПОЕХАЛИ!
ПОЕХАЛИ!
 Привет привет ovpn файл
Привет привет ovpn файл
 Ну как бы вот ...
Ну как бы вот ...

































 Cодержание
Cодержание
![С = [c_{ij}], i = 1(1)n, j = 1(1)n,](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/fc3/c35/37c/fc3c3537ce7b1924d8f85a6e38873ecc.svg)
![Q(X[i,j]) = \sum_{i=1}^{n}\sum_{j=1}^{n}{c_{ij}x_{ij}} min.](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/c9f/e84/a4c/c9fe84a4c9806823fdfac3562ca83f76.svg)

") Таблица шкал измерений переменных и
отношения (МО - метризованное отношение)
Таблица шкал измерений переменных и
отношения (МО - метризованное отношение)
 Рисунок 1 Схема постановки задачи и
получения логико-структурных решений
Рисунок 1 Схема постановки задачи и
получения логико-структурных решений
 Рисунок 2 Логическая структура проверки
гипотез и процесса логико-структурных решений
Рисунок 2 Логическая структура проверки
гипотез и процесса логико-структурных решений
 Рисунок 3 План и его связи с частями объекта
Рисунок 3 План и его связи с частями объекта




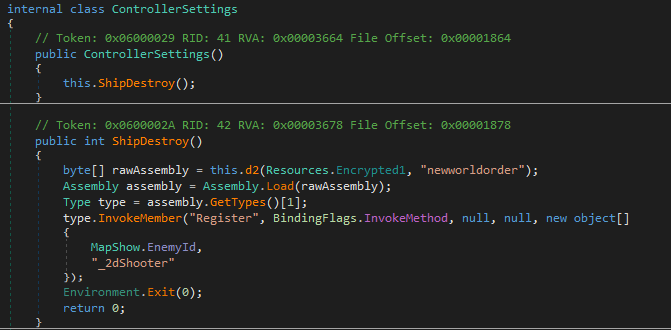
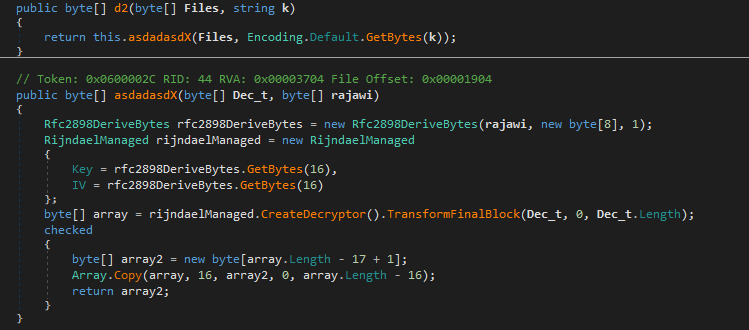


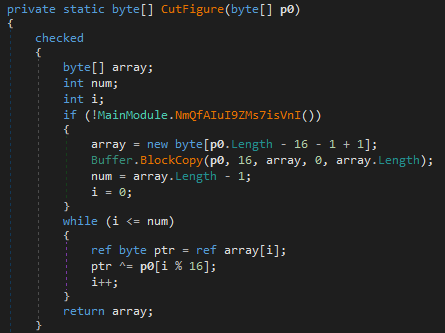
 Функция, осуществляющая разбор конфигурационного
файла
Функция, осуществляющая разбор конфигурационного
файла





















 Пример зловреда, с которым встроенные
механизмы Exchange не справились
Пример зловреда, с которым встроенные
механизмы Exchange не справились











