В большинстве приложений необходима некая подсистема аутентификации пользователей. Может быть вы программист, работающий в крупной компании над бизнес-приложениями, в которых требуется ограничить доступ к неким материалам неавторизованным сотрудникам компании и нужно проверять разрешения этих пользователей. Возможно вы пишете код новой SaaS-платформы, и вам нужно, чтобы её пользователи могли бы создавать учётные записи и управлять ими.

В обоих этих случаях, да и во многих других, вы, вероятнее всего, начнёте работу над приложением с создания подсистем аутентификации и средств для управления пользователями. То есть, как минимум, создадите форму регистрации и страницу для входа в систему. Подсистемы аутентификации это именно то, что чаще всего просят реализовать веб-разработчиков, занятых некими проектами. Но, несмотря на это, такие подсистемы, это ещё и то, на что обычно обращают очень мало внимания.
Разработка безопасной системы аутентификации пользователей это по-настоящему сложная задача. Она гораздо масштабнее, чем многие думают. Эту задачу очень легко решить неправильно. Хуже того: ошибки при создании подсистем аутентификации могут повлечь за собой катастрофические последствия. В базовую структуру систем аутентификации и управления пользователями входит всего несколько форм. Из-за этого создание подобных систем может показаться весьма простым делом. Но, как известно, дьявол кроется в деталях. Нужно немало потрудиться для того чтобы сделать такие системы безопасными (и, когда это возможно или даже необходимо, учесть в них требования конфиденциальности персональных данных).
IDaaS
К счастью, у современного веб-разработчика нет необходимости в развёртывании собственной системы для аутентификации пользователей и для управления ими. Сейчас, в 2020 году, существует множество хороших IDaaS-решений (Identity as a Service, идентификация как сервис). Применение таких решения значительно упрощает оснащение веб-проектов возможностями по аутентификации пользователей.
Вот несколько популярных IDaaS-проектов (в алфавитном порядке): Auth0, Azure AD, Google Identity Platform и Okta.
Кроме того, существуют поставщики идентификационной информации, основанной на чём-то наподобие учётных записей пользователей социальных сетей. Это, например, Apple, Facebook, GitHub, Twitter. Разработчикам очень легко внедрять в свои проекты возможности этих систем. Тот, кто работает с провайдерами аутентификации, может очень быстро создать соответствующую подсистему приложения, имеющую доступ к большому массиву данных о пользователях. Но иногда взаимодействие проекта с провайдерами может иметь негативное влияние на конфиденциальность данных пользователей.
На самом деле, нельзя назвать реальную причину, по которой некоему разработчику не стоит пользоваться услугами поставщика идентификационной информации. Работа с подобным сервисом позволит сэкономить массу времени, которое можно будет потратить на разработку самого приложения. Эти сервисы дают разработчику, без каких-либо существенных усилий с его стороны, множество возможностей. А самое важное здесь то, что они гораздо безопаснее, чем некое самописное решение.
Чем больше пользователей тем безопаснее решение
Большинство поставщиков идентификационной информации предлагаю дополнительные возможности, касающиеся безопасности. Такие, как поддержка многофакторной аутентификации (MFA, multi-factor authentication), поддержка сертификатов безопасности или ключей (в том числе U2F, FIDO2, WebAuthn и прочее подобное).
Не стоит недооценивать важность этих технологий. В соответствии с отчётом Microsoft, включение MFA позволяет предотвратить до 99,9% атак на учётные записи.
Однако в деле использования сторонних сервисов аутентификации вместо собственных решений есть ещё один аспект, менее известный. А именно, речь идёт о том, что благодаря очень большому количеству пользователей, с которыми работают подобные сервисы, они могут отслеживать паттерны поведения злоумышленников и легче предотвращать атаки на учётные записи.
Большие провайдеры, благодаря тому, что у них имеются миллионы пользователей, которые ежедневно выполняют бесчисленное множество входов в систему, собирают достаточно данных для построения моделей, основанных на возможностях искусственного интеллекта. Такие модели позволяют лучше идентифицировать подозрительные паттерны поведения.
Например, предположим, один из ваших пользователей, живущий в Канаде, входит в систему из дома. А через два часа вход в тот же аккаунт выполняется из Украины. Сервисы поставщика идентификационной информации способны счесть такое поведение подозрительным и могут либо сразу запретить вход, либо предложить пользователю пройти дополнительную верификацию (например, с использованием MFA-токена). Они, кроме того, могут уведомлять пользователей, которые подверглись атаке, или системных администраторов, а возможно и тех, и других.
Распространённые возражения, высказываемые об использовании сторонних сервисов аутентификации
На самом деле, не так уж и сложно создать собственную систему для аутентификации пользователей и для управления ими
Формы для регистрации в проекте и для входа в него это лишь одна сторона медали системы аутентификации. Разработчику, создавая подобную систему, придётся решить гораздо больше задач, чем разработка пары форм.
Для начала, нужно решить дополнительные задачи, связанные с управлением пользователями. Такие, как применение политик безопасности паролей, создание системы подтверждения адресов электронной почты или номеров телефонов, разработка механизмов безопасного сброса паролей. Правда, в том, что касается управления паролями, прошу всех прислушаться к NIST и не оснащать систему неотключаемым механизмом, работа которого направлена на то, чтобы срок действия паролей истекал бы по прошествии определённого времени. Не стоит и принуждать пользователей к тому, чтобы они создавали бы креативные пароли, содержащие символы верхнего и нижнего регистра, специальные символы и так далее.
При проектировании подобных систем нужно держать в голове массу мелких деталей. При этом тут очень легко совершить ошибки. Огромные компании были замечены в том, что они, например, не хешируют пароли в своих базах данных (или хешируют их неправильно), в том, что они случайно сбрасывают пароли в лог-файлы в виде обычного текста, в том, что их механизмы сброса паролей очень легко взломать, пользуясь методами социальной инженерии. Этот список можно продолжать.
То, что правильное управление паролями, это непростая задача, не должно никого удивлять. А вы знали о том, что управление именами пользователей это тоже сложно? Например, тот факт, что имена пользователей выглядят одинаково, ещё не означает, что система, при их сравнении, сочтёт их таковыми. В этом выступлении 2018 года высказаны ещё некоторые интересные идеи, касательно того, что может пойти не так при работе с такими простыми сущностями, как имена пользователей.
И наконец, стоит отметить, что веб-проекты могут многое выиграть от применения дополнительных мер безопасности, предлагаемых поставщиками идентификационной информации. Сюда входят, например, многофакторная аутентификация и токены безопасности.
Использование сервисов аутентификации пользователей не всегда бесплатно, особенно для крупных проектов
А знаете о том, что ещё, связанное с безопасностью, не является бесплатным? Необходимость возмещать ущерб от взломов. Этот ущерб может быть выражен в денежной форме, если те, кого взломали, понесли какие-то потери, это может быть время, потраченное на срочную доработку собственного проекта, это, что так же неприятно, как и другие последствия взломов, потеря доверия пользователей.
И даже если не говорить о взломах, реализация безопасной системы аутентификации и управление ей, работа с базой данных пользователей и решение прочих подобных задач, предусматривает трату времени и ресурсов. Это и ресурсы, уходящие на разработку системы, и ресурсы, необходимые на её поддержание в работоспособном состоянии.
Я очень опытный разработчик, поэтому знаю о том, как создать безопасную систему аутентификации
Для начала примите поздравления. Дело в том, что настоящие знания о том, как создаются безопасные системы аутентификации, есть у гораздо меньшего числа разработчиков, чем вы думаете, и чем можете ожидать.
Но если вы и правда опытнейший разработчик, тогда, вполне возможно, ваше время лучше потратить на реализацию других частей приложения, которые приносят пользователям этого приложения какую-то ощутимую пользу.
Или, если вы и правда хотите создать собственную систему аутентификации, то вы можете поразмыслить о поступлении на работу в компанию, вроде Microsoft, Auth0 или Facebook с целью улучшения их систем идентификации пользователей.
Я хочу держать под контролем пользователей моего проекта
Я, рассматривая данную идею, сразу хочу задать вам вопрос: А зачем вам это?. Вполне возможно то, что вам это по-настоящему не нужно. Ну, если только вы не разрабатываете новый Facebook. В таком случае данные о пользователях это ваш самый главный актив, и чем больше таких данных вы соберёте, тем лучше.
Кроме того, чем больше данных о пользователях вы собираете тем выше вероятность того, что вам придётся потратиться на то, чтобы привести свою систему в соответствие с некими правилами, вроде GDPR. Далее, если вы храните большие объёмы данных о пользователях, это может утяжелить последствия взломов и потребовать дополнительных расходов на устранения этих последствий.
Надо отметить, что большинство вышеперечисленных специализированных решений для аутентификации дают вам достаточно подробные сведения о пользователях и об их действиях.
Если вы рассматриваете вариант использования разработанного кем-то сервиса аутентификации, который собираетесь хостить у себя, то знайте, что применение таких сервисов сопряжено с определёнными сложностями. Возможно, вы хотите использовать подобный сервис для того чтобы в будущем обеспечить себе возможность перехода на что-то другое. Учитывайте, что подобные системы достаточно сложно поддерживать, и то, что сравнительно небольшое количество регистрируемых в них пользователей часто означает то, что владельцы таких систем не могут эффективно использовать дополнительные механизмы безопасности.
С чего начать?
Надеюсь, я убедил вас в том, что аутентификация пользователей это задача, которую лучше всего решать силами специализированного поставщика идентификационной информации. Вот как это сделать.
Для начала хорошая новость. Она заключается в том, что все четыре вышеперечисленных провайдера (Auth0, Azure AD, Google Identity Platform, Okta), да и многие другие, используют одни и те же протоколы: OpenID Connect / OAuth 2.0. Это современные стандартные протоколы, клиентские библиотеки для поддержки которых существуют практически для всех языков программирования и фреймворков.
Для того чтобы приступить к использованию услуг какого-нибудь поставщика идентификационной информации, нужно, если не вдаваться в детали, сделать следующее:
- Зарегистрируйте приложение у поставщика идентификационной информации. Вам, после регистрации, выдадут идентификатор (Application ID, Client ID) и секретный ключ (Secret Key, Client Secret).
- Задайте разрешения, необходимые вашему приложению. В дополнение к тому, что приложению будет доступен профиль пользователя, вы, что зависит от выбранного провайдера, сможете получить доступ к гораздо большему объёму данных. Сюда может входить, например, доступ к сообщениям пользователей и доступ к их облачному хранилищу (например через Office 365 или G Suite).
- Интегрируйте клиентскую библиотеку сервиса аутентификации в свой проект.
Я не стану пытаться рассказать в подробностях о том, как именно работает механизм OpenID Connect. Но, в целом, работа с сервисами аутентификации выглядит так:
- Приложение перенаправляет пользователя на страницу провайдера аутентификации.
- Пользователь аутентифицируется и перенаправляется на страницу вашего приложения.
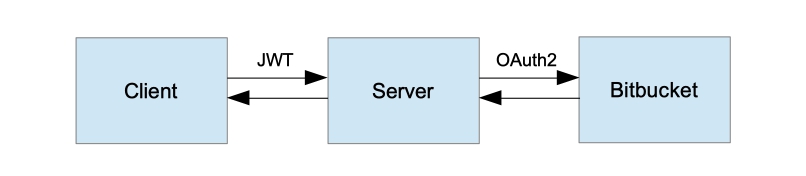
- Приложение получает JWT-токен.
JWT-токен, криптографически подписанный и имеющий ограниченный срок действия, может быть использован для управления сессиями пользователя. То есть, до тех пор, пока токен действителен, если приложение получает его в запросе, оно может считать этот запрос поступающим от пользователя, которому принадлежит токен.
Тот же токен содержит некоторые сведения о пользователе. Набор этих сведений зависит от используемого сервиса аутентификации. Обычно это имя пользователя, адрес его электронной почты, его идентификатор.
Приложение может использовать эти сведения для идентификации пользователя. Вы можете использовать идентификатор пользователя для того чтобы обращаться к связанным с ним данным, хранящимся в вашем приложении.
Как уже было сказано, JWT-токены криптографически подписаны. Поэтому вы, проверяя подпись токена, можете быть уверенными в том, что никто не подменил сведения о пользователе, которые содержатся в токене.
Использование OpenID Connect в клиент-серверных приложениях
То, как именно в конкретном приложении будет использоваться механизм OpenID Connect, сильно зависит от того, с использованием какого языка и фреймворка создано приложение.
На сайте jwt.io можно найти исчерпывающий список библиотек, которые можно использовать для верификации JWT-токенов.
Для некоторых стеков технологий, кроме того, можно воспользоваться решениями более высокого уровня. Например это, в среде Node.js/Express, express-jwt или passport.
Использование OpenID Connect на статических сайтах или в нативных приложениях
Статические веб-приложения (их ещё называют JAMstack-сайтами) и нативные приложения (то есть настольные или мобильные приложения) тоже могут пользоваться OpenID Connect, но делается это немного не так, как в случае с обычными веб-проектами. В спецификации OAuth 2.0 это называется implicit flow, или получение токена доступа напрямую от пользователя.
При таком подходе не нужно использовать механизм, в котором применяется секретный ключ (Client Secret). Дело в том, что приложение выполняется на клиенте, поэтому не существует безопасного способа распространения подобных ключей. Здесь применяется следующая последовательность действий:
- Приложение перенаправляет пользователя на аутентификационную
конечную точку, проверяя, чтобы строка запроса содержала бы
scope=id_token. - Пользователь выполняет аутентификацию, пользуясь возможностями поставщика идентификационной информации.
- Пользователя перенаправляют к приложению, JWT-токен сессии
прикрепляется к URL страницы в виде URL-фрагмента (URL-фрагмент это
то, что следует за знаком
#). Он находится в поле, называемомid_token. - Приложение получает JWT-токен из URL-фрагмента и проверяет его. Если токен успешно проходит проверку, пользователь считается аутентифицированным, а это значит, что приложение может использовать сведения о пользователе из токена.
Для того чтобы проверить JWT-токен в статическом веб-приложении можно использовать модуль idtoken-verifier. Настольные и мобильные приложения могут использовать похожие библиотеки. Конкретная библиотека зависит от технологии, использованной при разработке приложения.
При разработке клиент-серверных проектов, таких, как статические веб-ресурсы или нативные приложения, важно обеспечить то, чтобы токен был бы подписан с использованием RSA-SHA256 (в заголовке токена
alg должно быть записано RS256).
Речь идёт об использовании механизма асимметричного шифрования:
поставщик идентификационной информации подписывает токены с
использованием секретного ключа, а приложение может проверить токен
с использованием публичного ключа. Ещё один распространённый
алгоритм, применяемый для подписи токенов, это HMAC-SHA256 (или
HS256). Тут используется симметричное шифрование, для
подписи и проверки токенов применяется один и тот же ключ. Проблема
тут в том, что нельзя организовать безопасное хранение подобных
ключей в клиентских приложениях.Затем клиентское приложение может использовать полученный и проверенный JWT-токен в запросах, выполняемых к серверным API. Обычно токены передают либо в заголовке
Authorization,
либо используя куки-файлы. В данном случае JWT функционирует как
любой другой токен сессии, но он, при этом, ещё и содержит сведения
о пользователе.Серверный API, получив запрос, ищет в нём токен. Обнаружив токен, сервер снова его верифицирует. Если токен успешно проходит проверку (и если срок его действия ещё не истёк), сервер может счесть пользователя аутентифицированным и может воспользоваться идентификатором пользователя, взятым из токена.
Какие механизмы аутентификации пользователей применяете вы?



") Рисунок 1 кривые компромиссного
определения ошибки при предъявлении атак всех типов (print + replay
+ mask)
Рисунок 1 кривые компромиссного
определения ошибки при предъявлении атак всех типов (print + replay
+ mask)
 Рисунок 2 кривые компромиссного
определения ошибки при использовании разных инструментов атак для
лучшего метода
Рисунок 2 кривые компромиссного
определения ошибки при использовании разных инструментов атак для
лучшего метода



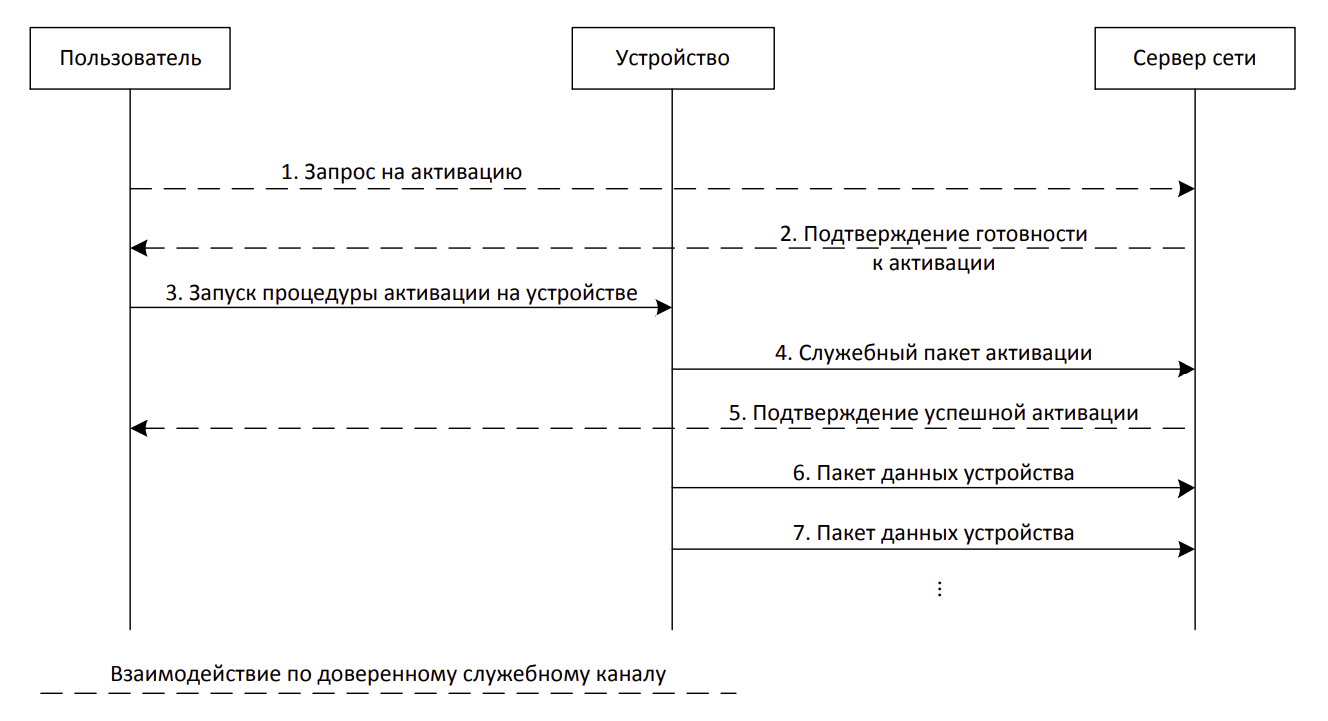


















































 Упрощенная схема взаимодействия между
пользователями и серверами
Упрощенная схема взаимодействия между
пользователями и серверами

 Управление доступами по паролю и по IP-адресу
Управление доступами по паролю и по IP-адресу
 Форма аутентификации для сотрудников
Форма аутентификации для сотрудников