

В статье рассмотрена проблематика очистки образов, которые накапливаются в реестрах контейнеров (Docker Registry и его аналогах) в реалиях современных CI/CD-пайплайнов для cloud native-приложений, доставляемых в Kubernetes. Приведены основные критерии актуальности образов и вытекающие из них сложности при автоматизации очистки, сохранения места и удовлетворения потребностям команд. Наконец, на примере конкретного Open Source-проекта мы расскажем, как эти сложности можно преодолеть.
Введение
Количество образов в реестре контейнеров может стремительно расти, занимая больше места в хранилище и, соответственно, значительно увеличивая его стоимость. Для контроля, ограничения либо поддержания приемлемого роста места, занимаемого в registry, принято:
- использовать фиксированное количество тегов для образов;
- каким-либо образом очищать образы.
Первое ограничение иногда допустимо для небольших команд. Если разработчикам хватает постоянных тегов (
latest,
main, test, boris и т.п.),
реестр не будет раздуваться в размерах и долгое время можно вообще
не думать об очистке. Ведь все неактуальные образы перетираются, а
для очистки просто не остаётся работы (всё делается штатным
сборщиком мусора).Тем не менее, такой подход сильно ограничивает разработку и редко применим к CI/CD современных проектов. Неотъемлемой частью разработки стала автоматизация, которая позволяет гораздо быстрее тестировать, развертывать и доставлять новый функционал пользователям. Например, у нас во всех проектах при каждом коммите автоматически создается CI-пайплайн. В нём собирается образ, тестируется, выкатывается в различные Kubernetes-контуры для отладки и оставшихся проверок, а если всё хорошо изменения доходят до конечного пользователя. И это давно не rocket science, а обыденность для многих скорее всего и для вас, раз вы читаете данную статью.
Поскольку устранение багов и разработка нового функционала ведется параллельно, а релизы могут выполняться по несколько раз в день, очевидно, что процесс разработки сопровождается существенным количеством коммитов, а значит большим числом образов в registry. В результате, остро встает вопрос организации эффективной очистки registry, т.е. удаления неактуальных образов.
Но как вообще определить, актуален ли образ?
Критерии актуальности образа
В подавляющем большинстве случаев основные критерии будут таковы:
1. Первый (самый очевидный и самый критичный из всех) это образы, которые в настоящий момент используются в Kubernetes. Удаление этих образов может привести к серьезным издержкам в связи с простоем production (например, образы могут потребоваться при репликации) или свести на нет усилия команды, которая занимается отладкой на каком-либо из контуров. (По этой причине мы даже сделали специальный Prometheus exporter, отслеживающий отсутствие таких образов в любом Kubernetes-кластере.)
2. Второй (менее очевиден, но тоже очень важен и снова относится к эксплуатации) образы, которые требуются для отката в случае выявления серьёзных проблем в текущей версии. Например, в случае с Helm это образы, которые используются в сохраненных версиях релиза. (К слову, по умолчанию в Helm лимит в 256 ревизий, но вряд ли у кого-то реально есть потребность в сохранении такого большого количества версий?..) Ведь мы, в частности, для того и храним версии, чтобы можно было их потом использовать, т.е. откатываться на них в случае необходимости.
3. Третий потребности разработчиков: все образы, которые связаны с их текущими работами. К примеру, если мы рассматриваем PR, то имеет смысл оставлять образ, соответствующий последнему коммиту и, скажем, предыдущему коммиту: так разработчик сможет оперативно возвращаться к любой задаче и работать с последними изменениями.
4. Четвертый образы, которые соответствуют версиям нашего приложения, т.е. являются конечным продуктом: v1.0.0, 20.04.01, sierra и т.д.
NB: Определенные здесь критерии были сформулированы на основе опыта взаимодействия с десятками команд разработчиков из разных компаний. Однако, конечно, в зависимости от особенностей в процессах разработки и используемой инфраструктуры (например, не используется Kubernetes), эти критерии могут отличаться.
Соответствие критериям и существующие решения
Популярные сервисы с container registry, как правило, предлагают свои политики очистки образов: в них вы можете определять условия, при которых тег удаляется из registry. Однако возможности этих условий ограничиваются такими параметрами, как имена, время создания и количество тегов*.
* Зависит от конкретных реализаций container registry. Мы рассматривали возможности следующих решений: Azure CR, Docker Hub, ECR, GCR, GitHub Packages, GitLab Container Registry, Harbor Registry, JFrog Artifactory, Quay.io по состоянию на сентябрь'2020.
Такого набора параметров вполне достаточно, чтобы удовлетворить четвёртому критерию то есть отбирать образы, соответствующие версиям. Однако для всех остальных критериев приходится выбирать какое-то компромиссное решение (более жесткую или, наоборот, щадящую политику) в зависимости от ожиданий и финансовых возможностей.
Например, третий критерий связанный с потребностями разработчиков может решаться за счет организации процессов внутри команд: специфичного именования образов, ведения специальных allow lists и внутренних договоренностей. Но в конечном счете его всё равно необходимо автоматизировать. А если возможностей готовых решений не хватает, приходится делать что-то своё.
Аналогична и ситуация с двумя первыми критериями: их невозможно удовлетворить без получения данных от внешней системы той самой, где происходит развёртывание приложений (в нашем случае это Kubernetes).
Иллюстрация workflow в Git
Предположим, вы работаете примерно по такой схеме в Git:

Иконкой с головой на схеме отмечены образы контейнеров, которые в настоящий момент развёрнуты в Kubernetes для каких-либо пользователей (конечных пользователей, тестировщиков, менеджеров и т.д.) или используются разработчиками для отладки и подобных целей.
Что произойдёт, если политики очистки позволяют оставлять (не удалять) образы только по заданным названиям тегов?

Очевидно, такой сценарий никого не обрадует.
Что изменится, если политики позволяют не удалять образы по заданному временному интервалу / числу последних коммитов?
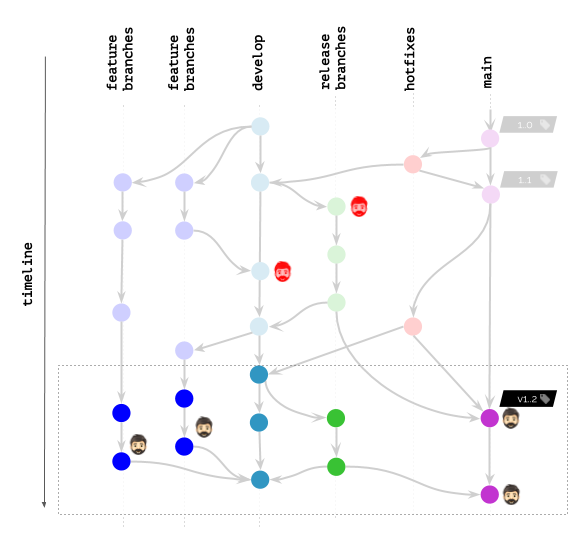
Результат стал значительно лучше, однако всё ещё далёк от идеала. Ведь у нас по-прежнему есть разработчики, которым нужны образы в реестре (или даже развёрнутые в K8s) для отладки багов
Резюмируя сложившуюся на рынке ситуацию: доступные в реестрах контейнеров функции не предлагают достаточной гибкости при очистке, а главная тому причина нет возможности взаимодействовать с внешним миром. Получается, что команды, которым требуется такая гибкость, вынуждены самостоятельно реализовывать удаление образов снаружи, используя Docker Registry API (или нативный API соответствующей реализации).
Однако мы искали универсальное решение, которое автоматизировало бы очистку образов для разных команд, использующих разные реестры
Наш путь к универсальной очистке образов
Откуда такая потребность? Дело в том, что мы не отдельно взятая группа разработчиков, а команда, которая обслуживает сразу множество таковых, помогая комплексно решать вопросы CI/CD. И главный технический инструмент для этого Open Source-утилита werf. Её особенность в том, что она не выполняет единственную функцию, а сопровождает процессы непрерывной доставки на всех этапах: от сборки до деплоя.
Публикация в реестре* образов (сразу после их сборки) очевидная функция такой утилиты. А раз образы туда помещаются на хранение, то если ваше хранилище не безгранично нужно отвечать и за их последующую очистку. О том, как мы добились успеха в этом, удовлетворяя всем заданным критериям, и будет рассказано далее.
* Хоть сами реестры могут быть различными (Docker Registry, GitLab Container Registry, Harbor и т.д.), их пользователи сталкиваются с одними и теми же проблемами. Универсальное решение в нашем случае не зависит от реализации реестра, т.к. выполняется вне самих реестров и предлагает одинаковое поведение для всех.
Несмотря на то, что мы используем werf как пример реализации, надеемся, что использованные подходы будут полезны и другим командам, столкнувшимся с аналогичными сложностями.
Итак, мы занялись внешней реализацией механизма для очистки образов вместо тех возможностей, что уже встроены в реестры для контейнеров. Первым шагом стало использование Docker Registry API для создания всё тех же примитивных политик по количеству тегов и времени их создания (упомянутых выше). К ним был добавлен allow list на основе образов, используемых в развёрнутой инфраструктуре, т.е. Kubernetes. Для последнего было достаточно через Kubernetes API перебирать все задеплоенные ресурсы и получать список из значений
image.Такое тривиальное решение закрыло самую критичную проблему (критерий 1), но стало только началом нашего пути по улучшению механизма очистки. Следующим и куда более интересным шагом стало решение связать публикуемые образы с историей Git.
Схемы тегирования
Для начала мы выбрали подход, при котором конечный образ должен хранить необходимую информацию для очистки, и выстроили процесс на схемах тегирования. При публикации образа пользователь выбирал определённую опцию тегирования (
git-branch,
git-commit или git-tag) и использовал
соответствующее значение. В CI-системах установка этих значений
выполнялась автоматически на основании переменных окружения. По
сути конечный образ связывался с определённым
Git-примитивом, храня необходимые данные для очистки в
лейблах.В рамках такого подхода получился набор политик, который позволял использовать Git как единственный источник правды:
- При удалении ветки/тега в Git автоматически удалялись и связанные образы в registry.
- Количество образов, связанное с Git-тегами и коммитами, можно было регулировать количеством тегов, использованных в выбранной схеме, и временем создания связанного коммита.
В целом, получившаяся реализация удовлетворяла нашим потребностям, но вскоре нас ожидал новый вызов. Дело в том, что за время использования схем тегирования по Git-примитивам мы столкнулись с рядом недостатков. (Поскольку их описание выходит за рамки темы этой статьи, все желающие могут ознакомиться с подробностями здесь.) Поэтому, приняв решение о переходе на более эффективный подход к тегированию (content-based tagging), нам пришлось пересмотреть и реализацию очистки образов.
Новый алгоритм
Почему? При тегировании в рамках content-based каждый тег может удовлетворять множеству коммитов в Git. При очистке образов больше нельзя исходить только из коммита, на котором новый тег был добавлен в реестр.
Для нового алгоритма очистки было решено уйти от схем тегирования и выстроить процесс на мета-образах, каждый из которых хранит связку из:
- коммита, на котором выполнялась публикация (при этом не имеет значения, добавился, изменился или остался прежним образ в реестре контейнеров);
- и нашего внутреннего идентификатора, соответствующего собранному образу.
Другими словами, была обеспечена связь публикуемых тегов с коммитами в Git.
Итоговая конфигурация и общий алгоритм
Пользователям при конфигурации очистки стали доступны политики, по которым осуществляется выборка актуальных образов. Каждая такая политика определяется:
- множеством references, т.е. Git-тегами или Git-ветками, которые используются при сканировании;
- илимитом искомых образов для каждого reference из множества.
Для иллюстрации вот как стала выглядеть конфигурация политик по умолчанию:
cleanup: keepPolicies: - references: tag: /.*/ limit: last: 10 - references: branch: /.*/ limit: last: 10 in: 168h operator: And imagesPerReference: last: 2 in: 168h operator: And - references: branch: /^(main|staging|production)$/ imagesPerReference: last: 10
Такая конфигурация содержит три политики, которые соответствуют следующим правилам:
- Сохранять образ для 10 последних Git-тегов (по дате создания тега).
- Сохранять по не более 2 образов, опубликованных за последнюю неделю, для не более 10 веток с активностью за последнюю неделю.
- Сохранять по 10 образов для веток
main,stagingиproduction.
Итоговый же алгоритм сводится к следующим шагам:
- Получение манифестов из container registry.
- Исключение образов, используемых в Kubernetes, т.к. их мы уже предварительно отобрали, опросив K8s API.
- Сканирование Git-истории и исключение образов по заданным политикам.
- Удаление оставшихся образов.
Возвращаясь к нашей иллюстрации, вот что получается с werf:

Однако, даже если вы не используете werf, подобный подход к продвинутой очистке образов в той или иной реализации (в соответствии с предпочтительным подходом к тегированию образов) может быть применен и в других системах/утилитах. Для этого достаточно помнить о тех проблемах, которые возникают, и найти те возможности в вашем стеке, что позволяют встроить их решение наиболее гладко. Надеемся, что пройденный нами путь поможет посмотреть и на ваш частный случай с новыми деталями и мыслями.
Заключение
- Рано или поздно с проблемой переполнения registry сталкивается большинство команд.
- При поиске решений в первую очередь необходимо определить критерии актуальности образа.
- Инструменты, предлагаемые популярными сервисами container registry, позволяют организовать очень простую очистку, которая не учитывает внешний мир: образы, используемые в Kubernetes, и особенности рабочих процессов в команде.
- Гибкий и эффективный алгоритм должен иметь представление о CI/CD-процессах, оперировать не только данными Docker-образов.
P.S.
Читайте также в нашем блоге:











