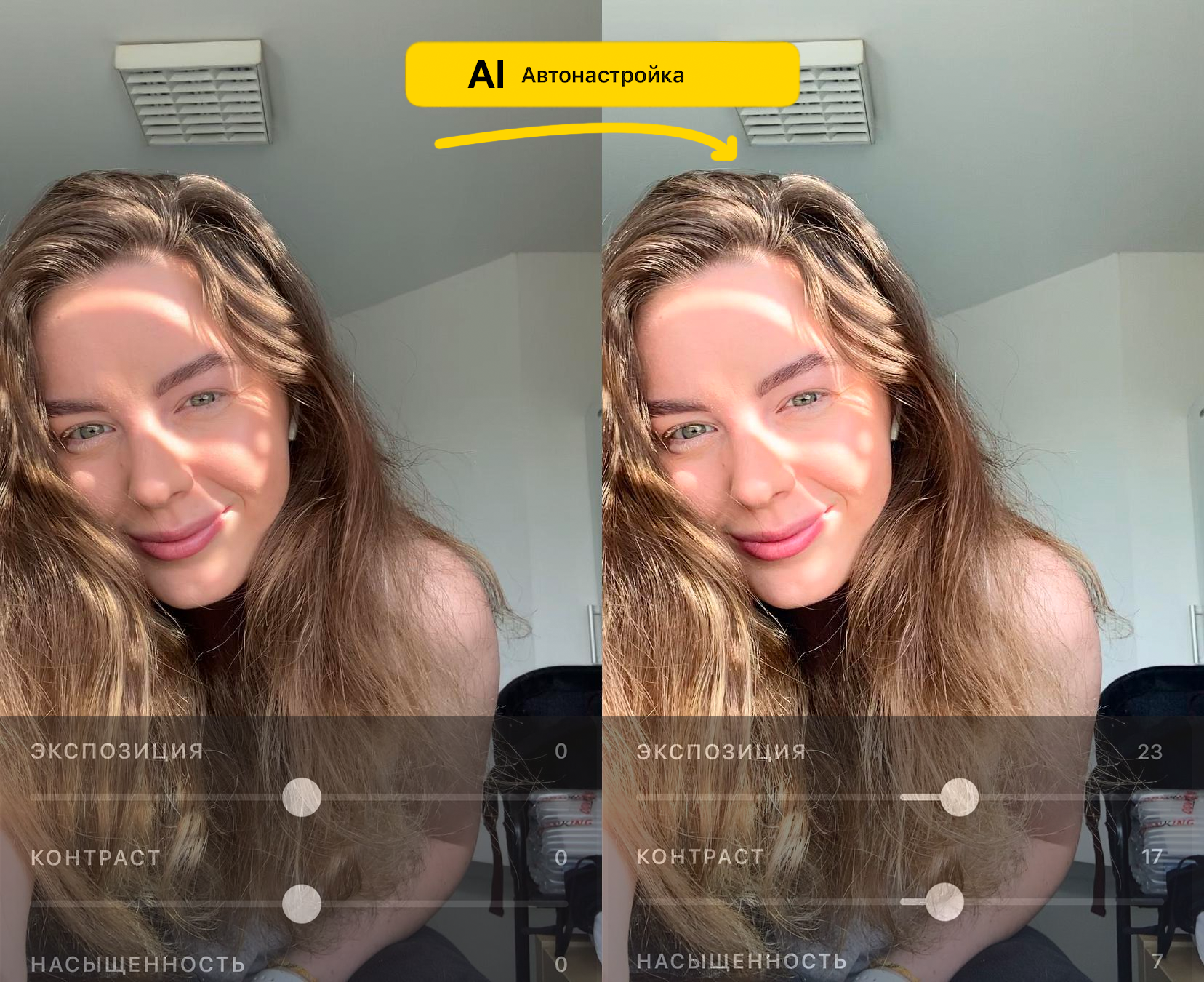
Привет, Хабр! Меня зовут Андрей, я занимаюсь R&D в Prisma Labs. В своё время наша команда провела весьма интересное исследование на тему автоматического улучшения фотографии, результатом которого стала фича AutoAdjustment в приложении Lensa, позволяющая в один клик сделать цветокоррекцию фото. В этом посте я хочу поделиться полученным в ходе проекта опытом. Расскажу, в чём заключается сложность этой задачи, где вас могут поджидать нежеланные грабли. Также покажу, на что способен разработанный нашей командой искусственный интеллект. Прочитав этот пост, вы вместе с нами пройдёте тернистый путь от красивой идеи до одной из киллер-фичей популярного приложения. Ну что, погнали?
Зачем вообще всё это нужно?
Почти каждый хоть раз делился собственными фотографиями в социальных сетях. Выкладывая свои фото, мы, конечно же, хотим, чтобы они набрали как можно больше лайков. Для этого часто приходится прибегать к различным техникам и инструментам для коррекции изображений. Так, например, перед тем как выложить фотографию в Instagram, мы можем наложить какой-то фильтр и исправить некоторые настройки фотографии: экспозицию, контраст, температуру, резкость и т.д. Как итог, мы тратим много собственного времени, при том что основная проблема кроется даже не в этом. Корректируя фотографию, мы, к сожалению, не всегда можем объективно оценить, насколько нам получилось её улучшить (особенно если мы с вами не профессиональные фотографы). Так, после наложения какого-либо фильтра вам может показаться, что фотография стала выглядеть лучше, а друзья могут не согласиться, сказав, что она потеряла естественность, и лучше бы вы вообще выложили оригинал. Получается, время было потрачено напрасно! Конечно же, всегда есть возможность обратиться к профессиональному фотографу или ретушеру, и тогда, скорее всего, обработка будет на высоте, но это тоже непросто и не бесплатно. Из этих мыслей и предположений родилась идея: как бы нам помочь пользователям сэкономить их время предложить решение, которое в один клик сделает их фотографии "лучше" (при помощи искусственного интеллекта, разумеется).
Теперь чуть больше по существу, что же мы хотели получить?
В нашем приложении Lensa присутствуют стандартные инструменты для редактирования фотографий: настройка экспозиции, контраста, теней, температуры, светлых участков и т.д. Нашей задачей было построить решение, которое позволит всего в один клик автоматически подобрать значения для каждой из этих настроек так, чтобы после их применения фотография стала нравиться аудитории сильнее, чем оригинал (по крайней мере, большинству). Мы не претендуем на новизну идеи автоматического улучшения фотографии, методов, которые делают что-то похожее, к моменту начала проекта уже существовало множество. Главной особенностью нашего подхода стала идея предсказывать значения настроек для инструментов, доступных через UI в нашем приложении.
Такой подход был выбран по нескольким причинам:
-
Наша модель только рекомендует пользователю изменения, которые он сам после вправе "донастроить". Юзер сможет скорректировать только те значения, которые ему кажутся ошибочными.
-
Пользователь видит, что конкретно исправлял наш искусственный интеллект, на какие составляющие он делал акцент больше всего. В связи с этим подход становится более интерпретируемым юзер понимает, какие настройки повлияли на результат.
На рисунке ниже представлена схема нашей модели.
Одна из основных "фишек" нашего редактора состоит в том, что после "автоулучшения" фотография должна остаться естественной. По этой причине некоторые из инструментов вроде зернистости или выцветания (grain/fade) мы исключили из нашего подхода, так как они делают фотографию менее реалистичной (на рисунке выше предсказанные значения нулевые).
Несмотря на понятную идею и мотивацию, было ясно, что задача весьма непростая. Вот только верхушка айсберга проблем, с которыми мы столкнулись уже в самом начале:
-
Мы не могли использовать уже готовые сторонние решения, так как нам нужно было научиться предсказывать настройки именно наших инструментов. К тому же, качество почти всех SOTA подходов оставляло желать лучшего, даже включая статьи с новомодными RL методами.
-
Субъективность оценки решения. Очень сложно придумать численные метрики, которые смогут нам дать понять, что наше решение делает фотографии объективно лучше. Можно оценивать качество фото нейронкой, но даже хваленая NIMA показывала удручающие результаты на наших данных.
-
Проблемы с данными нужна разметка в одном стиле. Существует множество комбинаций настроек, которые позволяют делать фотографии красивыми кому-то нравятся яркие и резкие фотографии, для кого-то такой результат кажется неприемлемым, а нам нужно получать настройки, которые устроят большинство пользователей.
-
Ко всему прочему, мы не хотим, чтобы модель предсказывала специфичный стиль, например, настройки для перевода в чёрно-белые тона. Многие профессиональные фотографы любят делать нестандартную авторскую обработку. В связи с этим поставить чёткое тз для разметки не самая тривиальная задача.
Давайте разбираться в составляющих. Для начала, что представляют из себя наши инструменты?
В предыдущем разделе речь шла о том, что мы хотим автоматически подбирать значения для экспозиции, контраста, теней и других наших инструментов. Но что означают эти настройки, как они работают и что конкретно делают с фотографией? Оказывается, каждый из таких инструментов в разных приложениях работает по-своему. Нет универсального понятия для "контрастности" или "экспозиции", в каждом приложении в эти термины вложено лишь чьё-то собственное представление о том, что же значат эти термины.
Что означают эти названия у нас в Lensa?Ответ основан на понимании того, что ожидает пользователь, когда выставляет значение теней на 50/100, а значение контрастности на -20/100. Как оказалось, опытный юзер предполагает, что тёмные области (тени) станут светлее, и при этом вся фотография станет более серой (из-за уменьшения контрастности). Ровно так, опираясь на то, чего ждут от нас пользователи, и к чему они привыкли, мы выстраивали эти инструменты.
Подбросим в топку чуть больше математики. Когда инженеры пытаются делать какие-то манипуляции с картинкой, в первую очередь вспоминают про различные цветовые пространства. Самое распространённое RGB, но в нём гораздо сложнее реализовать наши инструменты, чем в тех, где за цвет и яркость отвечают раздельные компоненты. Все операции с изображением мы выполняем в пространстве LAB (L канал отвечает за интенсивность).
Рассмотрим пару примеров наших инструментов, которые направлены в основном на L канал изображения: контраст и тени. На рисунке ниже представлены кривые инструментов (adjustments) контраста и теней для L канала, по OX исходное значение, по OY значение после применения инструмента.
Каждая кривая (красная, серая, зелёная) соответствует некоторому значению этого инструмента.

здесь исходное значение L канала для некоторого пикселя,
исходное значение L канала для некоторого пикселя, во что перейдет
во что перейдет после применения инструмента,
после применения инструмента, значение "ползунка" инструмента (сила применения),
значение "ползунка" инструмента (сила применения), кривая (функция) инструмента (adjustment). В случае изображения
кривые применяются попиксельно.
кривая (функция) инструмента (adjustment). В случае изображения
кривые применяются попиксельно.
Теперь про кривые: зеленая кривая соответствует максимальному
значению инструмента тому, как будет преобразован L канал для
максимального значения ползунка (+100). Красная кривая, напротив,
соответствует минимальному (-100). Пунктирная линия отражает
преобразование при нулевом значении (тождественное).
(тождественное).
Разберёмся с формой кривых на примере контраста. Когда вы увеличиваете контраст у картинки (зелёная кривая), то хотите, чтобы пиксели, которые были светлыми, становились еще более светлыми, а пиксели, которые были тёмными, получались еще более тёмными, при этом серые особо не менялись. Ровно это и позволяет нам сделать кривая контраста: значения ближе к 50 (серый) меняются слабо, зато области, которые находятся ближе к квантилям 1/4 и 3/4, изменяются сильнее всего. В случае с красной кривой всё наоборот: белые и чёрные участки тянутся к серому, поэтому зелёная и красная кривые проходят по разные стороны от пунктирной. С тенями всё еще проще, когда вы поднимаете тени, то хотите, чтобы высветились тёмные участки, а светлые участки почти не менялись. К каналам a и b также применяются некоторые преобразования, но для простоты опустим эти детали.
Можно линейно проинтерполировать результат максимума или минимума с оригиналом (в зависимости от знака альфы). Так, например, если мы хотим узнать, чему будет равен результат при значение ползунка в 50/100, то сначала считаем, чему будет равен результат при максимальном значении, а затем смешиваем с оригиналом с весами 0.5 (формула ниже).

Обратимость кривых и предлагаемый подход
Одним из ключевых свойств всех построенных функций является их обратимость.
Если не вдаваться в детали, то обратимость функции
(кривой) означает,
что для неё можно построить такую функцию
означает,
что для неё можно построить такую функцию ,
что для каждого значения
,
что для каждого значения и
каждого допустимого значения
и
каждого допустимого значения верно
следующее утверждение:
верно
следующее утверждение:

Допустим, мы построили такие функции, что все они являются
обратимыми, что же дальше? Для упрощения задачи давайте представим,
что нам нужно предсказать значение для одного инструмента,
например, контраста. То есть наша модель должна принимать на вход
исходную фотографию юзера с
"плохим" контрастом и предсказывать такое значение
с
"плохим" контрастом и предсказывать такое значение ,
чтобы применённая с силой
,
чтобы применённая с силой функция
контраста давала на выходе "идеально контрастную"
фотографию
функция
контраста давала на выходе "идеально контрастную"
фотографию .В
каком случае вообще представляется возможным предсказать такое
значение
.В
каком случае вообще представляется возможным предсказать такое
значение чтобы
получить
чтобы
получить ?
Это выполнимо, если существует некоторое
?
Это выполнимо, если существует некоторое ,
для которого справедливо следующее утверждение:
,
для которого справедливо следующее утверждение:

Это предположение является одним из самых важных моментов в нашем подходе.
Более простым языком, мы предполагаем, что все недостатки фотографии пользователя, которые мы хотим исправить, ограничены обратными функциями наших инструментов. Все дальнейшие рассуждения опираются на это предположение.
Допустим, у нас есть сет таких "идеальных"
фотографий .
Тогда, "испортив" их обратной функцией для данного инструмента (в
нашем случае контраста), мы получим обучающую выборку с
триплетами
.
Тогда, "испортив" их обратной функцией для данного инструмента (в
нашем случае контраста), мы получим обучающую выборку с
триплетами и
будем учить нашу модель предсказывать
и
будем учить нашу модель предсказывать по
входу
по
входу .
.
Для случая нескольких инструментов предположение легко обобщается: все недостатки, которые мы хотим исправить в фотографии, будут ограничены композицией обратных функций наших инструментов.

Если у нас инструментов,
то
инструментов,
то результат применения композиции их обратных функций.
результат применения композиции их обратных функций.
Ниже представлена иллюстрация парадигмы с триплетами для случая одного инструмента.
На рисунке выше CI=InvA(I, alpha) искажение "идеальной" фотографии путём наложения некоторой обратной функции со значением alpha. M(CI) предсказание обучаемой модели.
Мы выбрали подход к обучению с ухудшением идеального фото с помощью обратных преобразований по нескольким причинам:
-
Идеологически каждый инструмент (эджаст) должен исправлять только искажения от собственной обратной функции (композиция эджастов от композиции обратных). То есть инструмент контраста направлен на то, чтобы исправлять недочеты именно контраста на фотографии, но никак не температуры или другого инструмента. Всё ещё не удаётся избавиться того, что некоторые эджасты скоррелированы меняя, например, контраст, вы так или иначе влияете на тени (об этом дальше).
-
При таком подходе из одной идеальной фотографии можно получить много плохих, что позволяет нам сгенерировать больше данных. Данные в этой задаче (как и во многих других) весьма важная составляющая.
-
В таком подходе на стадии обучения нам не нужна supervised разметка пар, достаточно только "идеальных" фотографий.
Важнейшая составляющая. Откуда мы брали данные для обучения?
Есть же размеченные данные, что с ними не так?В начале работы над проектом мы пытались использовать некоторые open-source данные от фотографов вроде MIT-Adobe FiveK Dataset (его используют в большинстве статей по автоулучшению фото). Достаточно быстро мы поняли, что все найденные open-source датасеты нам не подходят по нескольким причинам:
-
Наш таргетинг селфи и портретные фото, во всех открытых датасетах таких изображений малая доля.
-
В датасетах вроде MIT FiveK данные размечены очень специфично множество фотографий выглядят хоть и эффектно, но весьма неестественно заметно, что они были отредактированы.
Мы пробовали размечать данные командой, но столкнулись с проблемой. Каждый выбирал настройки, исходя из собственных вкусов, поэтому в данных не было видно явного тренда, и получившаяся разметка была очень разнородной и даже противоречивой. В связи с этим мы выбрали одного асессора, и в итоге весь датасет был размечен одним человеком с экспертизой в области фото (будем называть его "судьёй"). После этого нашей задачей было уже не обучить объективный "улучшатель" фотографий, а научить модель размечать фотографии так же, как наш судья.
По итогу в датасет попало порядка 1000 фотографий (оригиналы, идеалы и конфиги). Немного, но этого оказалось достаточно.
Одна за всех или все за ...
В начале проекта мы пытались обучать одну нейронную сеть, которая принимает на вход картинку, испорченную композицией всех обратных преобразований, и предсказывает конфиг целиком (значения для всех инструментов). С таким подходом мы не смогли добиться нужного нам качества по нескольким причинам:
-
Эффекты от наложения некоторых инструментов очень скоррелированы. Существует множество конфигов, применяя которые, мы получаем почти одинаковый выход. Обучаться модели с таким условием тяжелее нужно учить все инструменты одновременно. Более того, нужно выучить не только правильный конфиг, а ещё понять, как применение всего этого конфига (всех инструментов одновременно) влияет на фотографию.
-
Модель почти всегда видит сложные сэмплы если мы сразу портим фотографию композицией всех обратных инструментов, то в большинстве случаев модели на вход будет приходить изображение, на котором плохо абсолютно всё: плохая экспозиция, плохой контраст, плохие тени и т.д. Сэмплировать искажения так же, как "in the wild", мы не можем, так как не знаем, как выглядит их априорное распределение в реальном мире.
Поэтому мы решили обучать по одной модели на каждый инструмент (модели у нас были очень маленькие и быстрые, мы могли себе это позволить). Мы выбрали N инструментов и обучали N нейронных сетей, где каждая сеть была ответственна только за свой инструмент обучалась исправлять только его. У инструментов есть определённый порядок, в котором они применяются в приложении, поэтому все эти обученные нейронные сети также применяются последовательно, и результат выхода одной модели (предсказанное значение инструмента) сначала применяется к картинке, а затем результирующее изображение подаётся на вход следующей модели.
У такого подхода тоже есть свои проблемы:
-
Во время обучения определённой модели, например, контраста, сеть не видит фотографии с испорченными тенями, что не является правдой для in the wild. Мы пробовали добавлять аугментациями искажения других инструментов (кроме того, который учим), но опять столкнулись с проблемой корреляции эффектов и усложнили каждой модели задачу.
-
Данный подход сложнее в интеграции на девайс и гораздо более трудозатратен в плане обучения: вам нужно последовательно обучить N сеток вместо всего одной.
Несмотря на эти минусы, такой пайплайн показал на практике результаты лучше, чем подход с одной моделью для всех инструментов.
Функция потерь. Картинки укажут вам более правильный путь, чем конфиги
Сначала мы пробовали, используя регрессионный лосс на паре (predicted_alpha, gt_alpha), учить модель предсказывать верное значение инструмента, но наступили на очередные грабли. У такого подхода есть как минимум два минуса.
Во-первых, как упоминалось выше, может существовать несколько различных конфигов для инструментов, которые приводят к одному и тому же результату. Но, если мы учим отдельно по одной модели на каждый инструмент при фиксированных остальных инструментах (которые не участвуют в обучении), найдётся ровно один правильный ответ для восстановления искажений инструмента, под который мы обучаем модель. Так что для подхода "одна модель под один инструмент" это не стало серьёзным препятствием.
Вторая проблема оказалась более серьёзной, и здесь нас уже не спас подход с обучением своей сетки под каждый инструмент. Допустим, мы хотим исправить насыщенность картинки. Мы знаем, что оригинальное изображение было испорчено со значением -90, а мы предсказали 50. Правда ли, что вне зависимости от исходного изображения мы всегда должны одинаково штрафовать нашу модель? Оказывается, что это не так.
За наглядным примером проблемы и ходить далеко не нужно!В приведённом примере абсолютная разница между предсказанным и истинным значениями одинакова для обоих случаев, при этом мы явно должны штрафовать модель для Case 2 сильнее (мы не восстановим оригинал с предсказанием 50). В то же время, в случае Case 1 для любого предсказания модели мы получаем одинаковый результат в точности оригинал (изменение насыщенности не меняет чёрно-белую фотографию). Получается, что мы должны штрафовать не за разницу в конфигах, а за то, насколько результат применения предсказанного конфига отличается от желанного изображения.
В зависимости от входной фотографии небольшое изменение в предсказанных значениях для инструментов может как значительно влиять на результат, так и не влиять вовсе.
Получается, что функция потерь должна штрафовать разницу между изображениями, а не между конфигами. Например, мы можем использовать L2-норму между изображениями:

Важно отметить, что предложенная функция потерь MSE между изображениями, дифференцируема по предсказанному значению, так как каждая наша функция каждого инструмента дифференцируема по нему.
Мы обучили модель. Как понять, что она делает что-то адекватное?
Валидация результатов работы обученной модели это, наверное, самая нетривиальная часть всего проекта. Помимо метрик (о которых речь пойдёт чуть ниже) мы использовали разные эвристики для того, чтобы понять, насколько разумно ведет себя модель.
Первая эвристика основана на идее о том, что модель не должна корректировать свои же предсказания. Мы назвали такое свойство "сходимостью".
Cходимость первый признак адекватности модели!Допустим, мы обучили модель для улучшения контрастности. Подаём некоторую фотографию (лучше ту, на которой есть явные проблемы с контрастом) в нашу модель. Модель предсказывает некоторое число P1. Затем применяем к этой фотографии инструмент контраста со значением P1 и получаем новую исправленную фотографию. Подаём её в модель,получаем число P2 и т.д. Так вот, мы считали, что модель является "адекватной", если эта последовательность (P1, P2, P3, ) достаточно быстро сходится. В идеале значения (P2, P3, ) должны быть около нуля.
Второе наблюдение чем сильнее мы испортили фотографию, тем большее (по абсолютной величине) значение наша модель должна предсказывать.
Хорошая модель монотонная модельНа рисунке выше по оси X отложено значение, с которым мы портили фотографию, а по оси Y предсказание модели. Видно, что модель не идеально предсказывает значения, с которыми портится фотография, но отношение порядка сохраняет. Связано это с тем, что модели достаточно просто понять, что на картинке нужно поднять или опустить контрастность и масштаб этого значения (относительно своего априорного идеала), а вот точное абсолютное значение угадать сложно (ещё один пунктик в сторону того, что обучать с функцией потерь именно на конфиги очень сложно). Также во время обучения мы старались подбирать такие распределения для параметров искажения (на основе размеченных данных), чтобы фотографии всё ещё выглядели более-менее естественными, поэтому модель не видела совсем испорченные фотографии (хвосты кривой).
Пристегнитесь, сдедующая остановка используемые метрики!
Долгое время в качестве метрик мы использовали только визуальный тест. Заключался он в следующем: мы показывали нашему судье две фотографии и просили выбрать, какая выглядит лучше. При этом мы также просили дать оценку от 1 до 5 (насколько выбранный вариант выглядит лучше конкурента). Это позволяло нам как сравнивать обученные модели, так и понимать, насколько мы далеки от разметки судьи. Важнейшей проблемой такой метрики является то, что этот процесс совершенно не автоматизирован и требует слишком много времени и усилий каждый раз нам нужно было строить несколько кандидатов (обучать несколько моделей) и для каждого нового кандидата просить нашего судью проходить такой визуальный тест. По этой причине нам пришлось думать над альтернативными метриками хотя бы для уменьшения количества проводимых визуальных тестов (для отсеивания заведомо неудачных моделей).
Итак, мы хотим придумать метрики, которые помогут нам ответить на вопрос, насколько наши новые модели стали ближе к поведению судьи.
Первая метрика была построена с целью понять, насколько сильно изменится результат обработки, если в настройках судьи (gt config) заменить значение одного инструмента, например, контраста, на предсказанное моделью значение. Схема расчёта метрики приведена на рисунке ниже.
Спустя некоторое время мы поняли, что у такой метрики есть один
важный недостаток. Допустим, наша модель на схеме выше (при расчёте
метрики) предсказала для
контраста. У наших инструментов есть четкий порядок применения, и
проблема состоит в том, что, на самом деле, контраст идёт вторым в
очереди (то есть до теней), а не последним. Даже с учётом того, что
мы сохраняем порядок применения всех инструментов после
предсказания, мы "подсовываем" модели не совсем истинный вход. В
реальном мире (в самом редакторе), даже если обученные модели для
экспозиции и теней будут всегда предсказывать правильные значения,
модель для контраста, скорее всего, не предскажет то же самое
значение
для
контраста. У наших инструментов есть четкий порядок применения, и
проблема состоит в том, что, на самом деле, контраст идёт вторым в
очереди (то есть до теней), а не последним. Даже с учётом того, что
мы сохраняем порядок применения всех инструментов после
предсказания, мы "подсовываем" модели не совсем истинный вход. В
реальном мире (в самом редакторе), даже если обученные модели для
экспозиции и теней будут всегда предсказывать правильные значения,
модель для контраста, скорее всего, не предскажет то же самое
значение ,
так как на вход поступит изображение с ещё не исправленными тенями
(исправление теней влияет на контраст фотографии).
,
так как на вход поступит изображение с ещё не исправленными тенями
(исправление теней влияет на контраст фотографии).
По этой причине мы разработали ещё одну метрику, которая более честно эмулирует процесс применения всех инструментов при её подсчёте полностью сохраняется порядок всех инструментов, а также совпадают входные изображения для всех моделей. В итоге предсказанные значения во время подсчёта метрики совпадут с теми, которые будут выдавать наши модели, если эту же фотографию загрузят к нам в приложение. В связи с этим за целевую мы стали использовать именно вторую метрику (далее речь пойдёт о ней).
Предположим, мы хотим настраивать экспозицию, контраст и светлые участки. Мы знаем, что сначала идёт экспозиция, затем контраст и только после настройка для светлых участков. Пусть у нас уже есть какое-то приближение для нашего решения модели, которые предсказывают значения для всех указанных инструментов (в самом начале это могут быть просто константные нулевые предсказания). Допустим, мы выучили новую модель для светлых участков. Чтобы проверить, сможет ли только она улучшить качество всего имеющегося пайплайна, мы заменим в лучшем наборе ровно одну модель по светлым участкам и проверим, стал ли предсказанный результат ближе к разметке судьи. Если да, то мы обновляем в лучшем множестве старую модель на новую и переходим к контрасту уже с новой зафиксированной моделью по светлым участкам (затем только к экспозиции).Схема одного предлагаемого шага обновления лучшего набора моделей представлена ниже.
Мы можем зациклить этот процесс и после экспозиции вернуться к светлым участкам. Зацикливание может быть полезно в случае, если после того, как мы обновили модель по светлым участкам, мы также обновили модель для предшествующего инструмента (все инструменты, которые идут раньше, влияют на последующие).
В качестве критерия можно использовать любую меру сходства между изображениями, например, MSE (как на рисунке выше). Не стоит интерпретировать абсолютную величину этой метрики. Её значение поможет вам понять, приводит ли замена старой модели на новую к улучшению качества всего пайплайна.
Благодаря разработанным метрикам нам удалось снизить количество проводимых визуальных тестов, мы научились автоматически отсеивать заведомо неперспективные решения, а также выбирать множество лучших моделей из обученных. Всё это значительно ускорило разработку.
Везде грабли-грабли-грабли, а что же мы получили в итоге?
Если долго мучиться, всё обязательно получится! Нам удалось построить модели, которые устроили нас по визуальному качеству, удовлетворяли нашим эвристикам и показывали позитивные результаты на приведённых метриках. Сейчас эти модели встроены в наш инструмент автоулучшения фотографии (Autoadjustments) в приложении Lensa. Ниже парочка примеров селфи с результатами работы пайплайна. Ждём вас в гости в приложении, если подумали, что это "черри-пики" :)
Оказалось, что обученные модели весьма стабильны и работают очень неплохо даже для видео, притом что мы во время обучения никак не требовали от них устойчивости между кадрами (лишь использовали некоторые аугментации). Ещё более интересный факт: модели способны показывать хорошее визуальное качество не только на селфи и портретных фотографиях, но и на изображениях с природой, пейзажами, зданиями и прочими категориям, где нет человека, несмотря на то что в датасете были фотографии только с людьми. Пара примеров представлена ниже.
Объяснить это можно тем, что модели у нас весьма небольшие и скорее не оперируют сущностью типа человека, а понимают, как нужно исправить фотографию из более низкоуровневых фичей вроде общей яркости или насыщенности.
Я рассказал вам про одну из наших интереснейших технологий. На собственном опыте показал, как уберечь себя от лишних шишек (мы уже набили их за вас). Берясь за проекты, связанные с обработкой и улучшением фото, формулируйте задачи как можно точнее и понятнее, чтобы лишний раз не натыкаться на проблему субъективизма.
Почти всегда ваша задача состоит не в том, чтобы построить решение, которое будет нравиться всем (это утопия в подобных проектах), а придумать, как угодить нужной аудитории.
От момента начала проекта до релиза финальной версии решения прошёл почти целый год, но для нас игра несомненно стоила свеч, так как полученный функционал идеально ложится в идеологию нашего продукта с улучшением фотографии в один клик. У нас осталось еще много идей, которые мы обязательно попробуем, когда вернёмся к работе над этим проектом, а после я обязательно вам про них расскажу :)