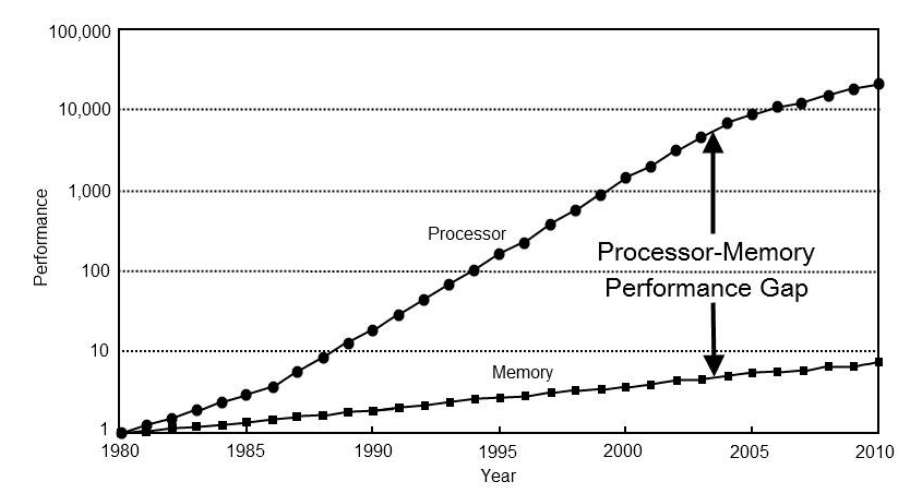
В статических анализаторах рано или поздно приходится решать задачу упрощения интеграции в существующие проекты, где поправить все предупреждения на legacy коде невозможно.
Эта статья не помощник по внедрению. Мы будем говорить о технических деталях: как такие механизмы подавления предупреждений реализуются, какие у разных способов плюсы и минусы.

baseline или так называемый suppress profile
Этот метод имеет несколько названий: baseline файл в Psalm и Android Lint, suppress база (или профиль) в PVS-Studio, code smell baseline в detekt.
Данный файл генерируется линтером при запуске на проекте:
superlinter --create-baseline baseline.xml ./project
Внутри себя он содержит все предупреждения, которые были выданы на этапе создания.
При запуске статического анализатора с
baseline.xml, все предупреждения, которые содержатся в
этом файле, будут проигнорированы:
superlinter --baseline baseline.xml ./project
Прямолинейный подход, где предупреждения сохраняются целиком вместе с номером строки будет работать недостаточно хорошо: стоит добавить новый код в начало файла, как все строки вдруг перестанут совпадать и вы получите все предупреждения, которые планировалось игнорировать.
Обычно, мы хотим достичь следующего:
- На новый код выдаются все предупреждения
- На старый код предупреждения выдаются только если его редактировали
- (опционально) Переносы файлы не должны выдавать предупреждения на весь файл
То, что мы можем конфигурировать в этом подходе это какие поля предупреждения формируют хеш (или "сигнатуру") срабатывания. Чтобы уйти от проблем смещения строк кода, лучше не добавлять номер строки в эти поля.
Вот примерный список того, что вообще может являться полем сигнатуры:
- Название или код диагностики
- Текст предупреждения
- Название файла
- Строка исходного кода, на которую сработало предупреждение
Чем больше признаков, тем ниже риск коллизии, но при этом выше риск неожиданного срабатывания из-за инвалидации сигнатуры. Если любой из используемых признаков в коде изменяется, предупреждение перестанет игнорироваться.
PVS-Studio, в добавок к основной строке исходного кода добавляет предыдущую и следующую. Это помогает лучше идентифицировать строку кода, но при этом предупреждения на какую-то строку кода могут выдаваться из-за того, что вы редактировали соседнюю строку.
Ещё один менее очевидный признак имя функции или метода, в которой выдавалось предупреждение. Это позволяет снизить количество коллизий, но провоцирует шквал предупреждений на всю функцию, если вы её переименуете.
Эмпирически проверено, что с этим признаком можно ослабить поле имени файла и хранить только базовое имя вместо полного пути. Это позволяет перемещать файлы между директориями без инвалидации сигнатуры. В языках, типа C#, PHP или Java, где название файла чаще всего отражает название класса, такие переносы имеют смысл.
Хорошо подобранный набор признаков увеличивает эффективность baseline подхода.
Коллизии в методе baseline
Допустим, диагностика W104 находит вызовы die в коде.
В проверяемом проекте есть файл foo.php:
function legacy() { die('test');}
Предположим, используются признаки {имя файла, код диагностики, строка исходного кода}.
Наш анализатор при создании baseline добавляет вызов
die('test') в свою базу исключений:
{ "filename": "foo.php", "diag": "W104", "line": "die('test');"}
Теперь добавим немного нового кода:
+ function newfunc() {+ die('test');+ } function legacy() { die('test'); }
По всем используемым признакам новый вызов
die('test') будет распознаваться как игнорируемый код.
Совпадение сигнатур для потенциально разных кусков кода мы и
называем коллизией.
Одним из решений является добавление дополнительного признака, который позволит различать эти вызовы. К примеру, это может быть поле "имя содержащей функции".
Что делать, если вызов die('test') был добавлен в
ту же функцию? Этот вызов может иметь одинаковые соседние строки в
обоих случаях, поэтому добавление предыдущей и следующей строки в
сигнатуре не поможет.
Здесь нам на помощь приходит счётчик сигнатур с коллизиями. Таким образом мы можем определить, что внутри функции ожидалось одно срабатывание, а получили два или более все, кроме первого, нужно сообщать.
При этом мы теряем некоторую точность: нельзя определить, какая из строк новая, а какая старая. Мы будем ругаться на ту, что будет идти после проигнорированных.
Метод, основанный на diff возможностях VCS
Исходной задачей было выдавать предупреждение только на "новый код". Системы контроля версий как раз могут нам в этом помочь.
Утилита revgrep принимает на
stdin поток предупреждений, анализирует git
diff и выдаёт на выход только те предупреждения, которые
исходят от новых строк.
golangci-lint использует форк
revgrep как библиотеку, так что в основе его
вычисления diff'а лежат те же алгоритмы.
Если выбран этот путь, придётся искать ответ на следующие вопросы:
- Как выбрать окно коммитов для вычисления diff?
- Как будем обрабатывать коммиты, пришедшие из основной ветки (merge/rebase)?
Вдобавок нужно понимать, что иногда мы всё же хотим выдавать
предупреждения, выходящие за рамки diff. Пример: вы удалили класс
директора по мемам, MemeDirector. Если этот класс
упоминался в каких-либо doc-комментариях, желательно, чтобы линтер
сообщил об этом.
Нам нужно не только получить правильный набор затронутых строк, но и расширить его так, чтобы найти побочные эффекты изменений во всём проекте.
Окно коммитов тоже можно определить по-разному. Скорее всего, вы не захотите проверять только последний коммит, потому что тогда будет возможно пушить сразу два коммита: один с предупреждениями, а второй для обхода CI. Даже если это не будет происходить умышленно, в системе появляется возможность пропустить критический дефект. Также стоит учесть, что предыдущий коммит может быть взят из основной ветки, в этом случае проверять его тоже не следует.
diff режим в NoVerify
NoVerify имеет два режима работы: diff и full diff.
Обычный diff может найти предупреждения по файлам, которые были затронуты изменениями в рамках рассматриваемого диапазона коммитов. Это работает быстро, но хорошего анализа зависимостей изменений не происходит, поэтому новые предупреждения из незатронутых файлов мы найти не можем.
Full diff запускает анализатор дважды: один раз на старом коде, затем на новом коде, а потом фильтрует результаты. Это можно сравнить с генерацией baseline файла на лету с помощью того, что мы можем получить предыдущую версию кода через git. Ожидаемо, этот режим увеличивает время выполнения почти вдвое.
Изначальная схема работы предполагалась такая: на pre-push хуках запускается более быстрый анализ, в режиме обычного diff'а, чтобы люди получали обратную связь как можно быстрее. На CI агентах полный diff. В результате время от времени люди спрашивают, почему на агентах проблемы были найдены, а локально всё чисто. Удобнее иметь одинаковые процессы проверки, чтобы при прохождении pre-push хука была гарантия прохождения на CI фазы линтера.
full diff за один проход
Мы можем делать приближенный к full diff аналог, который не требует двойного анализа кода.
Допустим, в diff попала такая строка:
- class Foo {
Если мы попробуем классифицировать эту строку, то определим её как "Foo class deletion".
Каждая диагностика, которая может как-то зависеть от наличия класса, должна выдавать предупреждение, если имеется факт удаления этого класса.
Аналогично с удалениями переменных (глобальных или локальных) и функций, мы генерируем набор фактов о всех изменениях, которые можем классифицировать.
Переименования не требуют дополнительной обработки. Мы считаем, что символ со старым именем был удалён, а с новым добавлен:
- class MemeManager {+ class SeniorMemeManager {
Основной сложностью будет правильно классифицировать строки изменений и выявить все их зависимости, не замедлив алгоритм до уровня full diff с двойным обходом кодовой базы.
Выводы
baseline: простой подход, который используется во многих анализаторах. Очевидным недостатком данного подхода является то, что этот baseline файл нужно будет где-то разместить и, время от времени, обновлять его. Точность подхода зависит от удачного подбора признаков, определяющих сигнатуру предупреждения.
diff: прост в базовой реализации, сложен при попытках достичь максимального результата. В теории, этот подход позволяет получить максимальную точность. Если ваши клиенты не используют систему контроля версий, то интегрировать ваш анализатор они не смогут.
| baseline | diff |
|---|---|
+ легко сделать эффективным |
+ не требует хранить файлов |
+ простота реализации и конфигурации |
+ проще отличать новый код от старого |
- нужно решать коллизии |
- сложно правильно приготовить |
Могут существовать гибридные подходы: сначала берёшь baseline файл, а потом разрешаешь коллизии и вычисляешь смещения строк кода через git.
Лично для меня, diff режим выглядит более изящным подходом, но однопроходная реализация полного анализа может оказаться слишком затруднительной и хрупкой.