
Хочу поделиться одной моей поделкой, возможно, кому-то она тоже будет полезна. В этой статье я поделюсь тем, что я сделал, чтобы читать Twitter-аккаунт Маска в удобном мне месте и имея под рукой перевод англоязычных твитов на русский.
Проблема
Последние несколько лет замечаю за собой, что хочу начать регулярно почитывать тот или иной блог, но если он не находится в зоне удобного или привычного доступа (к сожалению весь твиттер для меня таков, ничего не могу с собой поделать, не читатель я твиттера), то я довольно быстро забиваю на это. Еще хуже, если блог на другом языке, тут появляется дополнительная проблема, когда из-за технических терминов или разговорного жаргона сложно понять смысл. Собственно такие "преграды" обычно и приводят к тому, что вроде бы и хочется, но как-то не делается.
Идея
Сейчас я делаю на заказ программных роботов, которые в онлайне обрабатывают новостные потоки в соцсетях, фильтруют, выбирают наиболее интересные и цитируемые, и передают заказчику. Я подумал, почему бы мне не использовать свои навыки и не облегчить себе жизнь в описанной выше проблеме. Для этого нужно только каждые сколько-то минут заходить в твиттер, забирать новые сообщения, прогонять их через переводчик и отправлять в канал в телеграме. Кажется, ничего сложного.
Подводные камни
Первая проблема, с которой я столкнулся, это фрилансеры, у которых я пытался заказать кусок кода, который непосредственно выгружает новые посты из твиттера, все подряд отказывались от выполнения заказа. Прямо брали, а потом у одного компьютер сломался, у другого появились другие дела, третий в последний момент передумал.
Вторая проблема, отказ твиттера в выдаче доступа к API в описанных мной кейсах. То есть остается единственный вариант заниматься веб-скраппингом. Ну что ж.
Третья проблема, оказалось, что требуется довольно много ручной работы, чтобы преобразовать пост из твиттера в формат телеграма, и чтобы он прилично выглядел. В частности, картинки, предпросмотры ссылок, упоминания и тд.
Технологии
Я решил попробовать самостоятельно и начал гуглить что-то вроде "parsing twitter without API". Нашлось достаточно много решений, сразу скажу, что решениеtwint библиотека с открытым исходным кодом, которая вполне работоспособна и подошла под мою задачу.
Для того, чтобы перевести текст с английского на русский, я сначала было собирался использовать google translate, но понимал, что в нем ограниченное количество бесплатных переводов, решил что попробую использовать единственную известную мне нейросеть для перевода с английского на русскийfairseqот Facebook AI Research. Качество перевода показалось мне вполне приемлемым с точки зрения того, чтобы понять в чем суть твита, хотя оно и не было идеальным.
Все это я обернул в скрипт на языке программирования python и запустил на постоянную работу на своем сервере.
Примеры кода
Чтобы собрать данные из твиттера без использования выделенных девелоперских доступов, логинов, паролей и API, нужно сделать следующее:
Установить библиотеку twint
pip3 install twint
Запустить код формата
twint -u <name_of_twitter_user> -o output.csv --csv --since 2020-01-01 --retweets
Здесь есть важный момент, что запускается это все из-под bash, при том что у библиотеки есть python API (да и написана она на питоне), но при этом я потратил довольно много времени и оно ни в какую не заводилось. При этом если запускать из командной строки - все кроме автоматического перевода постов у меня работало.
Из функционала, который есть у библиотеки еще отмечу:
-
Возможность искать твиты пользователя по ключевому слову
twint -u username -s pineapple
-
Возможность находить твиты пользователя с указанием номеров телефонов и почт
twint -u username --email --phone
-
Поиск твитов вокруг определенной локации
twint -g="48.880048,2.385939,1km" -o file.csv --csv
-
Сохранение в Elasticsearch или SQLite
twint -u username -es localhost:9200twint -u username --database tweets.db
-
Сохранение фоловеров, подписок и избранных для пользователя
twint -u username --followerstwint -u username --followingtwint -u username --favorites
Данные сохраняются в csv файл, в котором присутствуют такие поля как (перечислю те, которые использовал сам, так как их много и большинство несут мало информации):
id - идентификатор сообщения
conversation_id - идентификатор беседы
created_at - дата создания сообщения
tweet - текст сообщения
mentions - упоминания пользователей твиттера ( список словарей)
urls - вставленные по правилам твиттера ссылки (например на youtube)
photos - ссылки на картинки
link - ссылка на твит
reply_to - список словарей с пользователямя, ответом на твиты которых является твит
У библиотеки есть также возможность перевода на другой язык, но она у меня совсем не заработала. Собственно по этой причине я искал другую возможность. Нашел я, как упоминал выше, открытую разработку Facebook AI Research - библиотеку fairseq, в которой можно скачать веса нейронки для перевода в частности из английского в русский и наоборот.
pip install hydra-core
Итого необходимо было установить:
pip install torch pip install hydra-core==1.0.0 omegaconf==2.0.1pip install fastBPE regex requests sacremoses subword_nmt
Вообще мануал по установке и пример использование есть на сайте pytorch, но как видите у меня он немного отличается. Для того, чтобы сделать перевод можно пользоваться следующим куском из примера - он вполне рабочий:
import torch# Compare the results with English-Russian round-trip translation:en2ru = torch.hub.load('pytorch/fairseq', 'transformer.wmt19.en-ru.single_model', tokenizer='moses', bpe='fastbpe')ru2en = torch.hub.load('pytorch/fairseq', 'transformer.wmt19.ru-en.single_model', tokenizer='moses', bpe='fastbpe')paraphrase = ru2en.translate( en2ru.translate('PyTorch Hub is an awesome interface!'))assert paraphrase == 'PyTorch is a great interface!'
В нем два раза производится перевод и проверяется соотвествие результата исходному варианту. При первом запуске с серверов torch хаба выкачивается большая нейронка, которая довольно шустро работает и на процессоре.
В целом, если не считать способов использования библиотек, у меня набралось еще довольно много кода, чтобы делать полученные сообщения достаточно читабельными, но это уже детали моего применения.
Как пользоваться
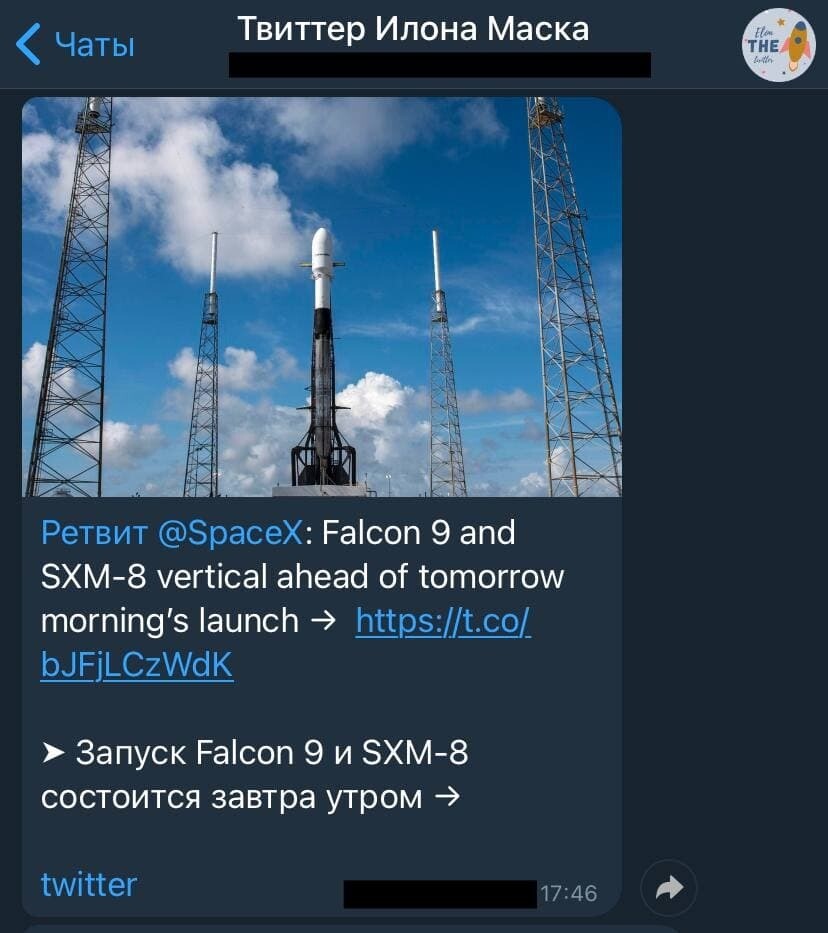
Выглядит сейчас это следующим образом. Каждый твит и ретвит на главной странице твиттера Илона Маска пропускается через переводчик, подбираются ссылки и картинки из поста, дальше все это сохраняется в пост в телеграм-канале. Выглядит это так

Итого у меня получилсятелеграм-каналпод названием "Твиттер Илона Маска" (подписывайтесь, мне будет приятно, что это нужно кому-то еще , будет дополнительный стимул поддерживать в будущем), в котором можно
1) читать новые и старые посты Илона Маска
2) видеть перевод текста на русский язык
3) перейти по ссылке на исходный пост в твиттере
И все это без регистрации и смс:)
Если эта статья показалась вам интересной, поставьте, пожалуйста апвоут (так ее увидит больше людей) и подписывайтесь на мой блог втелеграме, там я ежедневно рассказываю о всех своих экспериментах. Если хотите решить похожую проблему для своего бизнеса пишите вличку.









































