Что есть речь человека? Это слова, комбинации которых позволяют выразить ту или иную информацию. Возникает вопрос, откуда мы знаем, когда заканчивается одно слово и начинается другое? Вопрос довольно странный, подумают многие, ведь мы с рождения слышим речь окружающих людей, учимся говорить, писать и читать. Накопленный багаж лингвистических знаний, конечно, играет важную роль, но помимо этого есть и нейронные сети головного мозга, разделяющие поток речи на составляющие слова и/или слоги. Сегодня мы с вами познакомимся с исследованием, в котором ученые из Женевского университета (Швейцария) создали нейрокомпьютерную модель расшифровки речи за счет предсказания слов и слогов. Какие мозговые процессы стали основой модели, что подразумевается под громким словом предсказание, и насколько эффективна созданная модель? Ответы на эти вопросы ждут нас в докладе ученых. Поехали.
Основа исследования
Для нас, людей, человеческая речь вполне понятна и членораздельна (чаще всего). Но для машины это лишь поток акустической информации, сплошной сигнал, который необходимо декодировать прежде, чем понять.
Мозг человека действует примерно так же, просто это происходит крайне быстро и незаметно для нас. Фундаментов этого и многих других мозговых процессов ученые считают те или иные нейронные колебания, а также их комбинации.
В частности распознавание речи связывают с комбинацией тета и гамма колебаний, поскольку она позволяет иерархически координировать кодирование фонем в слогах без предварительного знания их длительности и временного возникновения, т.е. восходящая обработка* в реальном времени.
Восходящая обработка* (bottom-up) тип обработки информации, основанный на поступлении данных из среды для формирования восприятия.Естественное распознавание речи также сильно зависит от контекстных сигналов, которые позволяют предвидеть содержание и временную структуру речевого сигнала. Ранее проведенные исследования показали, что во время восприятия непрерывной речи важную роль играет именно механизм прогнозирования. Этот процесс связывают с бета колебаниями.
Еще одной важной составляющей распознавания речевых сигналов можно назвать предиктивное кодирование, когда мозг постоянно генерирует и обновляет ментальную модель окружающей среды. Эта модель используется для генерации прогнозов сенсорного ввода, которые сравниваются с фактическим сенсорным вводом. Сравнение прогнозированного и фактического сигнала приводит к выявлению ошибок, которые служат для обновления и пересмотра ментальной модели.
Другими словами, мозг всегда учится чему-то новому, постоянно обновляя модель окружающего мира. Этот процесс считается критически важным в обработке речевых сигналов.
Ученые отмечают, что во многих теоретических исследованиях поддерживаются как восходящий, так и нисходящий* подходы к обработке речи.
Нисходящая обработка* (top-down) разбор системы на составляющие для получения представления о ее композиционных подсистемах способом обратной инженерии.Разработанная ранее нейрокомпьютерная модель, включающая соединение реалистичных тета- и гамма- возбуждающих/тормозных сетей, была способна предварительно обрабатывать речь таким образом, чтобы затем ее можно было правильно декодировать.
Другая модель, основанная исключительно на предиктивном кодировании, могла точно распознавать отдельные речевые элементы (такие, как слова или полные предложения, если рассматривать их как один речевой элемент).
Следовательно, обе модели работали, просто в разных направлениях. Одна была сфокусирована на аспекте анализа речи в режиме реального времени, а другая на распознавании изолированных речевых сегментов (анализ не требуется).
Но что, если объединить основные принципы работы этих кардинально разных моделей в одну? По мнению авторов рассматриваемого нами исследования это позволит улучшить производительность и повысить биологический реализм нейрокомпьютерных моделей обработки речи.
В своем труде ученые решили проверить, может ли система распознавания речи на базе предиктивного кодирования получить некую пользу от процессов нейронных колебаний.
Они разработали нейрокомпьютерную модель Precoss (от predictive coding and oscillations for speech), основанную на структуре предиктивного кодирования, в которую добавили тета- и гамма-колебательные функции, чтобы справиться с непрерывной природой естественной речи.
Конкретная цель этой работы заключалась в поиске ответа на вопрос, может ли сочетание предиктивного кодирования и нейронных колебаний быть выгодным для оперативной идентификации слоговых компонентов естественных предложений. В частности, были рассмотрены механизмы, с помощью которых тета-колебания могут взаимодействовать с восходящими и нисходящими информационными потоками, а также проведена оценка влияния этого взаимодействия на эффективность процесса декодирования слогов.
Архитектура Precoss модели
Важной функцией модели является то, что она должна быть в состоянии использовать временные сигналы/информацию, присутствующие в непрерывной речи, для определения границ слога. Ученые предположили, что внутренние генеративные модели, включая временные предсказания, должны извлечь выгоду из таких сигналов. Чтобы учесть эту гипотезу, а также повторяющиеся процессы, происходящие во время распознавания речи, была использована модель кодирования с непрерывным предсказанием.
Разработанная модель четко отделяет чтои когда. Что относится к идентичности слога и его спектральному представлению (не временная, но упорядоченная последовательность спектральных векторов); когда относится к предсказанию времени и продолжительности слогов.
В результате прогнозы принимают две формы: начало слога, сигнализируемое тета-модулем; и длительность слога, сигнализируемая экзогенными/эндогенными тета-колебаниями, которые задают длительность последовательности единиц с гамма-синхронизацией (схема ниже).

Изображение 1
Precoss извлекает сенсорный сигнал из внутренних представлений о его источнике путем обращения к порождающей модели. В этом случае сенсорный ввод соответствует медленной амплитудной модуляции речевого сигнала и 6-канальной слуховой спектрограмме полного натурального предложения, которые модель внутренне генерирует из четырех компонентов:
- тета-колебание;
- блок медленной амплитудной модуляции в тета-модуле;
- пул слоговых единиц (столько слогов, сколько присутствует в естественном вводном предложении, т.е. от 4 до 25);
- банк из восьми гамма-единиц в спектротемпоральном модуле.
Вместе единицы слогов и гамма-колебания генерируют нисходящие прогнозы относительно входной спектрограммы. Каждая из восьми гамма-единиц представляет собой фазу в слоге; они активируются последовательно, и вся последовательность активации повторяется. Следовательно, каждая единица слога связана с последовательностью из восьми векторов (по одному на гамма-единицу) с шестью компонентами каждый (по одному на частотный канал). Акустическая спектрограмма отдельного слога генерируется путем активации соответствующей единицы слога на протяжении всей продолжительности слога.
В то время как блок слогов кодирует конкретный акустический паттерн, гамма-блоки временно используют соответствующее спектральное предсказание в течение продолжительности слога. Информация о продолжительности слога дается тета-колебанием, так как его мгновенная скорость влияет на скорость/продолжительность гамма-последовательности.
Наконец, накопленные данные о предполагаемом слоге должны быть удалены перед обработкой следующего слога. Для этого последний (восьмой) гамма-блок, который кодирует последнюю часть слога, сбрасывает все слоговые единицы до общего низкого уровня активации, что позволяет собирать новые свидетельства.

Изображение 2
Производительность модели зависит от того, совпадает ли гамма-последовательность с началом слога, и соответствует ли ее длительность продолжительности слога (50600 мс, среднее = 182 мс).
Оценка модели относительно последовательности слогов обеспечивается единицами слогов, которые вместе с гамма-единицами генерируют ожидаемые спектро-темпоральные паттерны (результат работы модели), которые сравниваются с вводной спектрограммой. Модель обновляет свои оценки о текущем слоге, чтобы минимизировать разницу между сгенерированной и фактической спектрограммой. Уровень активности увеличивается в тех слоговых единицах, спектрограмма которых соответствует сенсорному вводу, и уменьшается в других. В идеальном случае минимизация ошибки прогнозирования в режиме реального времени приводит к повышенной активности в одной отдельной единице слога, соответствующей входному слогу.
Результаты моделирования
Представленная выше модель включает физиологически мотивированные тета-колебания, которые управляются медленными амплитудными модуляциями речевого сигнала и передают информацию о начале и продолжительности слога гамма-компоненту.
Эта тета-гамма связь обеспечивает временное выравнивание внутренних сгенерированных предсказаний с границами слога, обнаруженными по входным данным (вариант A на изображении 3).

Изображение 3
Для оценки релевантности синхронизации слогов на основе медленной амплитудной модуляции было проведено сравнение модели А с вариантом В, в котором тета-активность не моделируется колебаниями, а возникает из самоповторения гамма-последовательности.
В модели В длительность гамма-последовательности больше не контролируется экзогенно (за счет внешних факторов) тета-колебаниями, а эндогенно (за счет внутренних факторов) использует предпочтительную гамма-скорость, которая при повторении последовательности приводит к формированию внутреннего тета-ритма. Как и в случае тета-колебаний, длительность гамма-последовательности имеет предпочтительную скорость в тета-диапазоне, которая потенциально может адаптироваться к переменным продолжительностям слогов. В таком случае есть возможность протестировать тета-ритм, возникающий из-за повторения гамма-последовательности.
Чтобы более точно оценить специфические эффекты тета-гаммы соединения и сброса накопленных данных в слоговых единицах, были сделаны дополнительные варианты предыдущих моделей A и B.
Варианты C и D отличались отсутствием предпочтительной скорости гамма-излучения. Варианты E и F дополнительно отличались от вариантов C и D отсутствием сброса накопленных данных о слогах.
Из всех вариантов модели только A имеет истинную тета-гамма связь, где гамма-активность определяется тета-модулем, тогда как в В модели гамма-скорость устанавливается эндогенно.
Необходимо было установить, какой из вариантов модели самый эффективный, для чего было проведено сравнение результатов их работы при наличии общих входных данных (естественные предложения). График на изображении выше показывает среднюю производительность каждой из моделей.
Между вариантами присутствовали значительные отличия. По сравнению с моделями A и B, производительность была значительно ниже в моделях E и F (в среднем на 23%) и C и D (на 15%). Это указывает на то, что стирание накопленных данных о предыдущем слоге перед обработкой нового слога является критически важным фактором кодирования слогового потока в естественной речи.
Сравнение вариантов A и B с вариантами C и D показало, что тета-гамма связь, будь то стимульная (A) или эндогенная (B), значительно улучшает производительность модели (в среднем на 8.6%).
Обобщенно говоря, эксперименты с разными вариантами моделей показали, что оная работала лучше всего, когда единицы слога сбрасывались после завершения каждой последовательности гамма-единиц (на основе внутренней информации о спектральной структуре слога), и когда скорость гамма-излучения определялась тета-гамма связью.
Производительность модели с естественными предложениями, следовательно, не зависит ни от точной сигнализации о начале слогов посредством тета-колебаний, управляемых стимулом, ни от точного механизма связи тета-гамма.
Как признают сами ученые, это довольно удивительное открытие. С другой стороны, отсутствие различий в производительности между управляемой стимулом и эндогенной тета-гамма связью отражает то, что продолжительность слогов в естественной речи очень близка к ожиданиям модели, и в этом случае не будет никакого преимущества для тета-сигнала, управляемого непосредственно вводными данными.
Чтобы лучше понять столь неожиданный поворот событий, ученые провели еще один ряд экспериментов, но со сжатыми речевыми сигналами (х2 и х3). Как показывают поведенческие исследования, понимание речи, сжатой в х2 раза, практически не меняется, но сильно падает при сжатии в 3 раза.
В таком случае стимулируемая тета-гамма связь может стать крайне полезной для разбора и расшифровки слогов. Результаты моделирования представлены ниже.

Изображение 4
Как и ожидалось, общая производительность упала с увеличением коэффициента сжатия. Для сжатия х2 существенной разницы между стимульной и эндогенной тета-гамма связью по-прежнему не было. Но в случае сжатия х3 возникает существенная разница. Это говорит о том, что управляемое стимулом тета-колебание, приводящее в действие тета-гамма-связь, было более выгодным для процесса кодирования слога, чем эндогенно установленная тета-скорость.
Из этого следует, что естественная речь может обрабатываться с помощью относительно фиксированного эндогенного тета-генератора. Но для более сложных вводных речевых сигналов (т.е. когда скорость речи постоянно меняется) требуется управляемый тета-генератор, передающий гамма-кодировщику точную временную информацию о слогах (начало слога и продолжительность слога).
Способность модели точно распознавать слоги во входном предложении не учитывает переменную сложность различных сравниваемых моделей. Потому была проведена оценка байесовского информационного критерия (BIC) для каждой модели. Данный критерий количественно определяет компромисс между точностью и сложностью модели (изображение 5).
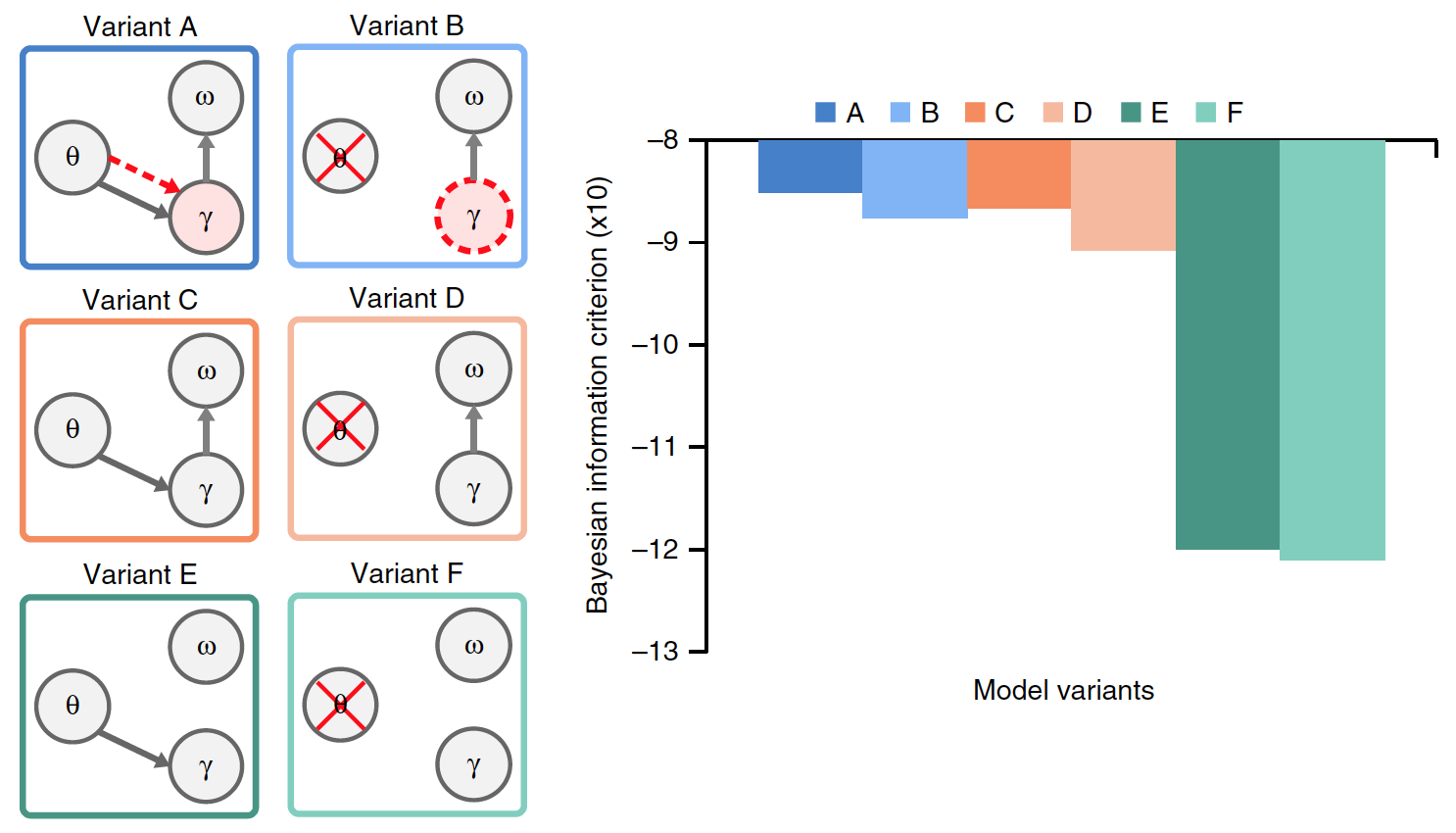
Изображение 5
Вариант А показал самые высокие значения BIC. Ранее проведенное сравнение моделей А и В не могло точно различить их производительность. Однако благодаря критерию BIC стало очевидно, что вариант A обеспечивает более уверенное распознавание слогов, чем модель без тета-колебаний, управляемых стимулом (модель В).
Для более детального ознакомления с нюансами исследования рекомендую заглянуть в доклад ученых и дополнительные материалы к нему.
Эпилог
Суммируя вышеописанные результаты, можно сказать, что успешность модели зависит от двух основных факторов. Первый и самый важный сброс накопленных данных, основанных на информации модели о содержании слога (в данном случае это его спектральная структура). Вторым фактором является связь между тета- и гамма-процессами, которая обеспечивает включение гамма-активности в тета-цикл, соответствующий ожидаемой продолжительности слога.
По сути своей, разработанная модель имитировала работу мозга человека. Звук, поступающий в систему, модулировался тета волной, напоминающей активность нейронов. Это позволяет определить границы слогов. Далее более быстрые гамма-волны помогают кодировать слог. В процессе система предлагает возможные варианты слогов и корректирует выбор при необходимости. Перескакивая между первым и вторым уровнями (тета и гамма), система обнаруживает правильный вариант слога, а потом обнуляется, чтобы начать процесс заново для следующего слога.
Во время практических испытаний удалось успешно расшифровать 2888 слогов (220 предложений естественной речи, использовался английский язык).
Данное исследование не только объединило в себе две противоположные теории, реализовав их на практике в виде единой системы, но и позволило лучше понять, как наш мозг воспринимает речевые сигналы. Нам кажется, что мы воспринимаем речь как есть, т.е. без каких-либо сложных вспомогательных процессов. Однако, учитывая результаты моделирования, получается, что нейронные тета и гамма колебания позволяют нашему мозгу делать небольшие предсказания относительно того, какой именно слог мы слышим, на основе которых и формируется восприятие речи.
Кто бы что ни говорил, но мозг человека порой кажется куда таинственнее и непонятнее, чем неизведанные уголки Вселенной или беспросветные глубины Мирового океана.
Благодарю за внимание, оставайтесь любопытствующими и хорошей всем рабочей недели, ребята. :)
Немного рекламы
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?