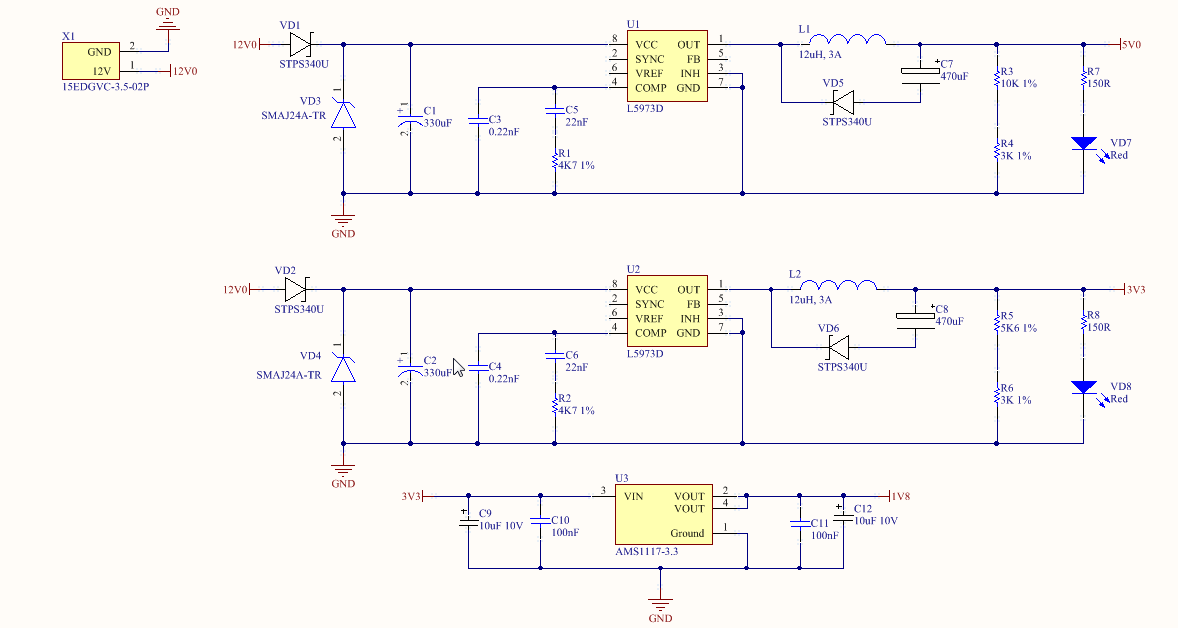
Что такое хорошо, определяют наши ценности, а они у всех разные. Поэтому для кого-то хорошая интеграция это та, которую написал сам, где все красиво, и нет костылей, обходящих ошибки навязанных средств. Для других это та, которая работает на базе надежных, проверенных временем инструментах и концепциях. А для третьих наоборот, использующая самые современные, передовые технологии и подходы. Но это все неверный подход, потому что опирается он на мнение создателей интеграции, а смотреть надо с позиции тех, кому эта интеграция приносит ценность.

Кому же интеграция приносит ценность? В первую очередь пользователям, которые в результате могут совместно использовать несколько систем. И им важно, чтобы интеграция работала быстро и без ошибок. А когда ошибки и случались бы, то быстро и технологично исправлялись бы, и не только в коде, но и в данных. Еще пользователям важно, чтобы интеграция была адаптивна к изменениям и развитию этих систем, чтобы ее расширение не требовало больших трудозатрат и не становилось ограничением развития, равно как и масштабирование по объемам передаваемых данных.
Обо всем этом я написал статью, опираясь на опыт 25+ лет разработки и внедрения корпоративных систем, включающий разработку собственной интеграции и использование различных вендорских платформ. Статья получилась очень большая, поэтому рассказ будет в нескольких частях с продолжением. Сегодня я начну с достаточно неожиданной темы.
Хорошая интеграция это интеграция с хорошей админкой
Почему? Потому что именно админка определяет, насколько быстро и технологично служба поддержки может разобраться с возникшими инцидентами и устранить проблему. Так что с позиции использования и эксплуатации это логично. И, казалось бы, проектировать и реализовывать ее должны именно в этой логике.
Однако, на практике дело обстоит совсем не так разработчики начинают с выбора технологической платформы и после этого упоенно пишут ядро. А админку делают по остаточному принципу, при этом ориентируясь на ситуацию, когда инциденты редки и уникальны. Конечно, этому есть причины. С одной стороны, разработчики верят в свой код, который (конечно) будет работать правильно и без ошибок. А, с другой стороны, заказчик хочет сократить стоимость, поэтому тоже верит разработчикам. Ну, или делает вид, что верит, при этом имея План Б жестко связать их SLA оперативного исправления инцидентов. Обычно такой план срабатывает плохо, и теряет от этого, конечно, бизнес. Потому что в ситуации, когда админка только показывает ошибку, но не позволяет с ней работать, служба поддержки обращается к разработчикам для разбора инцидентов. Те разбирают инциденты вручную долго и дорого, напрямую работая с базой данных или через технические средства для прямых обращений по http или другим протоколам.
А инцидентов может быть много. Мир не стоит на месте, и интегрируемые системы регулярно развиваются и обновляются. Далеко не всегда доработки ведут опытные разработчики, знакомые с кодом, их вполне могут отдать новичкам без достаточного опыта, потому что авторы кода делают новые проекты, и, возможно, уже в другой компании. По разным причинам очередной релиз могут выпускать быстро, без полноценного тестирования.
Да и при тестировании очередное неудачное обновление с ошибкой запросто может породить вал из сотен или тысяч ошибок. Все таки тестовый контур не полноценно эмулирует реальный поток данных. Особенно, если этот поток новый и касается функционала, которого раньше не было. А ограничения целостности в сложном IT-ландшафте носят распределенный характер и изменения данных, допустимые в одной системе, могут оказаться неприемлемыми в другой, об этом мы отдельно поговорим в статье.
Также встречаются ошибки, которые проявляются только в каких-то редких ситуациях и потому сложно локализуемы. Но при этом регулярно повторяются по десятку в месяц или, что еще хуже всплесками в сотню штук раз в полгода. Потом выясняется, например, что из-за внутренней ошибки Oracle некоторые транзакции завершаются не совсем корректно. Вполне может быть, что где-то в глубине инцидентов об этом уже несколько лет стоит баг, запланированный к устранению в будущем, а пока для этих ситуаций предлагается workaround. Другой пример, когда разработчики обнаруживают ошибку в собственном старом коде.
Поэтому хорошая интеграция это такая, в которой админка позволяет быстро и технологично разбираться с инцидентами. Что же такая админка должна поддерживать?
При обработке сообщений
Прием сообщений не должен полностью останавливаться на первой же ошибке
Остановка потока при любой ошибке очень плохо, так как при любой частной ошибке, вызванной, например, обработкой нового типа сообщений, мы получаем вал инцидентов и нарушение взаимодействия систем. После исправления остановленный поток будет невозможно обработать быстро, при этом среди необработанных сообщений могут быть важные и срочные изменения, совершенно не связанные с той самой частной ошибкой. В целом практика показывает, что большинство сообщений могут быть обработаны независимо друг от друга.
Необходимо контролировать последовательность обработки сообщений
Хотя в целом сообщения можно обрабатывать независимо, для для конкретной цепочки нарушение порядка часто чревато ошибками на системе-приемнике. При этом, сквозная нумерация всех сообщений и остановка всей интеграции из-за этого при первой же ошибке недопустимо, как я уже говорил. А во многих случаях простая последовательная нумерация невозможна, потому что отправка и прием сообщений часто выполняется многопоточно.
Поэтому должны быть механизмы для связывания сообщений в цепочки с блокировкой последующих при ошибке внутри конкретной цепочки. Например, при разработке распределенного каталога товаров в такую цепочку выстраиваются все изменения и вызовы методов, связанные с одним объектом. А также все изменения цен и скидок на конкретный артикул, поскольку они часто взаимодействуют друг с другом.
Интерфейсы обработки инцидентов должны позволять обработать сообщения с нарушением последовательности или пропускать отдельные сообщения. Однако очень важно, чтобы обработка с нарушением последовательности была выведена на отдельные действия, чтобы избежать ошибок.
Надо уметь посмотреть сообщение, письмо или вызов, который будет выполняться
Я помню свой шок при работе с удаленными транзакциями Oracle в конце 90-х, когда выяснилось, что ошибочную транзакцию можно выполнить, но посмотреть ее содержание невозможно. Поэтому важно показать не только конверт сообщения, но и внутреннее его содержание в структурном виде, несмотря на обобщенный характер таких интерфейсов.
Длинный упакованный xml или json не слишком хороший вариант. Особенно сложно, когда у нас есть несколько конвертов, а внутренние сообщения шифруются и, в том числе, потому, что их содержание не всегда должно быть доступно службе поддержки. Тут могут быть неразрешимые ситуации, когда инженер поддержки не может разобраться с ошибкой, потому что не видит содержания сообщений, а бизнес-специалист, имеющий доступ и способный провести диагностику, не использует служебный интерфейс службы поддержки.
Надо уметь запустить сообщение на обработку в системе-получателе
Это актуально, если при обработке была внутренняя ошибка в коде или данных, которую исправили. Это часто бывает при расширении протокола интеграции новые поля обрабатываются неверно, ошибку исправляют, и после этого для исправления данных необходимо повторно обработать сообщения. Аналогично может быть нужно, если сообщения оказались чувствительны к порядку обработки, а это не предусмотрели.
Например, в систему обработки заказов вдруг приходит с сайта заказ на товар, которого нет в каталоге. При разборе оказалось, что новые заказы поступают сразу при создании на сайте, а каталог обновляется по ночам. Когда покупателям позволяли заказывать только тот товар, который есть в наличии, а для появления товара на сайте в третьей системе должны были принять его поставку, то остатки появлялись на сайте только на следующий день и товар успевал распространиться по всем системам. А когда покупателям позволили делать заказы на отсутствующий товар, в том числе новый, никто не подумал, что информация о нем может еще не дойти до других систем.
Надо уметь найти сообщение в системе-источнике и повторно его отправить
Иногда сообщения теряются по дороге. Протокол http не гарантирует ни доставку сообщений, ни получение ответа. При этом повторная отправка при отсутствии ответа чревата дублированием сообщений ведь потерять могли именно ответ, а не само сообщение. Кроме того, цепочка передачи часто включает несколько этапов и получение ответа о доставки по всей цепочки не всегда просто. Аналогична ситуация и с другим транспортом. Поэтому при надежном транспорте предпочитают контролировать успешную постановку в очередь. Однако, если было выяснено, что сообщение пропущено и ожидаемые изменения не пришли, надо уметь найти сообщение в системе-источнике и повторно отправить:

Интерфейсы работы с инцидентами должны быть ориентированы на массовую обработку
Массовые ошибки будут всегда. И нужно уметь отбирать сообщения для обработки по тексту сообщения об ошибке и другим атрибутам, чтобы избежать ситуации отбора вручную, отслеживая только глазами в большой таблице, что нужно обработать, а что нет.
При изменении объектов
Если передаются не просто сообщения, то для хорошей интеграции с технологичным решением проблем нужны дополнительные пункты:
- Желательно видеть на интерфейсе те изменения, которые сообщение вносит в существующий объект. Идеально, когда мы можем видеть также изменения предыдущих сообщений (которые его меняли) и последующих необработанных (при их наличии).
- В случае проблем полезна возможность отправить из системы-отправителя объект целиком, со всеми его атрибутами. И, конечно, принять его, проигнорировав при этом предыдущие ошибочные сообщения.
- Хороший инструмент возможность изменить объект вручную средствами системы возможно, с выходом в нештатный режим для объектов, правки которых запрещены, и с последующим контролем, что объект действительно получился идентичным. Контроль тут важная часть, так как сложные ошибки иногда возникают из-за одинаковых символов с разными кодами, двойных, неразрывных или концевых пробелов и прочих деталей кодировки. При этом стоит учитывать, что интеграция, хранение и интерфейс системы могут работать в разных кодировках.
Поддержка распределенных ограничений целостности
Бизнес-логика очень часто накладывает ограничения на атрибуты объектов не только в пределах одного объекта, но и в совокупности. Например, НДС в заказе зависит от категории товара и от налогового режима контрагента покупателя или продавца. И такие ограничения важно контролировать, особенно если ошибки ведут к налоговым или другим регуляторным последствиям. В случае, если изменения происходят в рамках одной системы, контроль относительно прост: при создании заказа проверяются атрибуты товара и контрагента, а при изменении атрибутов контрагентов или товаров что это изменение не нарушает существующих данных.
А вот если каталог товаров ведет одна система, справочник контрагентов другая, а заказы третья, то задача усложняется. При обработке заказа проверить атрибуты товара проблем не будет. А вот при изменении атрибутов товара или контрагента проверить заказы будет непросто. Потому что систем ведения заказов может быть много, а какие атрибуты являются значимыми неизвестно. Можно, конечно, эмулировать двухфазную транзакцию, когда сначала во все системы посылается сообщение о намерении изменить атрибуты, и только после подтверждения всеми системами готовности к такому изменению сообщать о нем. Но это чрезвычайно сложный протокол. К тому же в полной реализации между подтверждением готовности к изменению и приходом новых значений система-получатель должна работать в особом режиме, обеспечивающим как принятие изменений, так и отказ от него. По сути, в этот период атрибут теряет конкретное значение, у него оказывается два варианта. И хотя я видел реализацию таких двухфазных протоколов, на практике от них больше проблем, чем пользы.
Именно поэтому в админке, с технологичным сопровождением инциденты, связанные с невозможностью принять конкретные изменения в конкретной системе, быстро, технологично диагностируются и разбираются. И принимается решение по существу: изменения могут быть отменены в основной системе, или проведены обратные изменения, или, наоборот, будет решено что такие изменения не нарушают бизнес-логику и правила проверки следует изменить:

Сверка данных
И, наконец, интеграция должна включать систему независимой сверки данных между системами в автоматическом режиме или по запросу. И хорошо, если это поддерживает админка, а не разработчик, вручную выгружающий данные из систем и сравнивающий их. Очень много ошибок, как показывает практика, связано с эффектами косвенного изменения объектов, которые не попадают в сообщения по интеграции. Например, когда изменения повешены на триггеры базы данных, и сервер приложений о них поэтому не в курсе. Поэтому важно при сверке передавать интегральные показатели, причем отражающие не только то, что попало в поток интеграции, а характеризующие множества синхронизируемых объектов в целом.
Конечно, при больших объемах независимая передача всех объектов для контроля невозможна. Однако для разбора ошибок однократная выгрузка всех объектов из обеих систем с их сверкой может оказаться вполне приемлемым решением. В случае, если их все-таки слишком много можно проводить сверку интегральных показателей по группам объектов. Например, эффективным способом сверки часто является сравнение текстовых файлов если их выгружать отсортированными по ключу или так, чтобы первые позиции обеспечивали текстовую сортировку. Можно пользоваться стандартным diff или его аналогами. А с некоторыми командами мы использовали такой подход не только для сортировки, но и для интеграции с legacy-системой, которая не умела выгружать изменения, в то время как по бизнес-процессам были правки документов в прошлое. Приходилось выгружать полную витрину за полтора года, а потом сортировать, сравнивать и получать ежедневную порцию изменений. И все это тянул слабенький комп под unix с помощью стандартных утилит это было еще до эпохи облаков.
Если же по интеграции передаются вызовы процедур, изменяющие множество объектов, то результат может зависеть от состояния данных, включая обработку других сообщений, поступивших по интеграции (при том, что порядок может быть не гарантирован). Например, в одной из наших систем была передача назначения скидок, действующая на группы магазинов и товаров интерфейс пользователя работал именно в этих категориях. И оказалось, что в системе-получателе на результат действия влияет в том числе текущее состояние классификации товаров и магазинов по группам (которое также поступало из основной системы). Поэтому последовательность обработки сообщений была очень существенной, а при ошибке вообще приходилось останавливать всю серию связанных сообщений. Переходить на низкий уровень передаче не хотелось из-за объемов информации, но работа без контроля иногда приводила к сложным ошибкам, которые было невозможно поймать. Решением стала передача в сообщении количества объектов, на которые должна подействовать скидка сигнал об ошибке начал своевременно приходить, а так как сама ситуация была крайне редкой, ее ручной разбор не вызывал проблем.
Уведомления
Для оперативной реакции на ошибки интеграции, естественно, необходимы оперативные уведомления службе поддержки. К сожалению, ошибки интеграции часто имеют кумулятивный эффект и носят массовый характер, что часто проявляется при установке обновлений. При этом, не всегда сразу обновления часто проносят вечером или ночью, в период минимальной нагрузки, а работа с данными, которая породит ошибки, будет на следующий день, или через день, если поток данных идет не в оперативном режиме, а по ночам. Или вообще имеет свой недельный или месячный ритм, и тогда эффект может проявиться еще более отдаленно. Поэтому чем раньше будут замечены ошибки репликаций, тем меньше придется потом исправлять в данных.
Для этого в интеграции должны быть средства для мониторинга и настройки уведомлений. Раньше для этого разрабатывали собственную систему уведомлений, а сейчас целесообразнее пользоваться стандартными средствами мониторинга, например, на основе Prometheus и Grafana. Однако, разработка системы запросов для мониторинга все равно относится к конкретной системе интеграции, потому что здесь очень важно выделить группы проблем по их критичности, чтобы обеспечить оперативную эскалацию и решение проблем. И важно учитывать, что если ошибки возникают при приеме ночного потока, то они могут блокировать нормальную работу пользователей, которые привыкли начинать рабочий день рано. В отличие от разработчиков, которые любят приходить достаточно поздно а ведь им еще нужно время для локализации и исправления ошибок.
Продолжение следует
На этом я заканчиваю сегодняшнюю статью.
В следующий раз мы будем говорить уже про сами транзакции и их консистентность, а также про идемпотентные операции, обеспечивающие устойчивость, про обеспечение возможностей развития и некоторые другие аспекты хорошей интеграции.
На весенний и осенний сезоны 2021 года открыт прием докладов на конференции. Для 2021 года мы подготовили 14 конференций, в том числе и перенесенных с этого года. Смотрите план наших конференций на весь 2021 год с датами закрытия Call for Papers.
Изучайте, подбирайте конференцию для себя!