Предлагаем вашему вниманию взгляд Huawei на Wi-Fi 6 саму технологию
и связанные с ней новшества, в первую очередь применительно к
точкам доступа: что в них нового, где им найдётся самое подходящее
и полезное применение в 2020 году, какие технологические решения
дают им основные конкурентные преимущества и как вообще
организована линейка AirEngine.

Что происходит в сфере беспроводных технологий сегодня
В годы, когда развивались предыдущие поколения Wi-Fi четвёртое и
пятое, в индустрии была сформирована концепция all-wireless office,
то есть полностью беспроводного офисного пространства. Но с тех пор
много воды утекло, и запросы бизнеса по отношению к Wi-Fi
изменились качественно и количественно: повысились требования к
пропускной способности, критически важным стало снижение задержек,
и чем дальше, тем насущнее необходимость подключать большое
количество пользователей.


К 2020 году сформировался ландшафт новых приложений, которые должны
надёжно работать через сети Wi-Fi. На иллюстрации отображены
основные направления, к которым такие приложения относятся. Вкратце
о нескольких из них.
А. Дополненная и виртуальная реальность. Долгое время
аббревиатуры VR и AR фигурировали в презентациях телеком-вендоров,
однако мало кто понимал, каково прикладное применение стоящих за
этими буквами технологий. Сегодня они стремительно входят в нашу
жизнь, что находит отражение и в продуктах Huawei. В апреле мы
представили смартфон Huawei P40 и попутно запустили пока только на
территории Китая сервис Huawei Maps с функцией AR Maps. Он
представляет собой не просто ГИС с голограммами. Дополненная
реальность глубоко встроена в функциональность системы: с её
помощью ничего не стоит буквально выцепить информацию о той или
иной организации, офис которой расположен в здании, проложить
маршрут через окружающее пространство, и всё это в формате 3D и с
высочайшим качеством.
Также AR определённо ждёт интенсивное развитие в сферах образования
и здравоохранения. Актуальна она и для производств: например, для
того, чтобы обучать сотрудников тому, как действовать в нештатных
ситуациях, трудно придумать что-то лучше тренажёров в дополненной
реальности.
Б. Системы безопасности с видеонаблюдением. И даже шире:
любое решение с видео, которое относится к стандартам сверхвысокой
чёткости. Речь идёт уже не только о 4K, но и о 8K. Ведущие
производители телевизоров и инфопанелей обещают, что модели,
выдающие картинку в 8K UHD, появятся в их ассортименте на
протяжении 2020 года. Логично предположить, что и конечные
пользователи захотят смотреть видео в супервысоком качестве с
ощутимо увеличившимся битрейтом.
В. Бизнес-вертикали, и в первую очередь ритейл. В качестве
примера возьмём
Lidl одну из крупнейших в Европе сетей
супермаркетов. Она использует Wi-Fi в новых,
опирающихся на
IoT сценариях взаимодействия с потребителями, в частности
внедрила электронные ценники ESL, интегрировав их со своей CRM.
Что касается крупных производств, примечателен опыт Volkswagen,
который развернул на своих заводах Wi-Fi от Huawei и применяет его
для решения самых разных задач. Помимо всего прочего, на Wi-Fi 6 у
компании завязано функционирование роботов, которые перемещаются по
территории фабрики, посредством AR-сценариев в реальном времени
осуществляется сканирование деталей и т. д.
Г. Умные офисы также представляют собой огромное
пространство для инноваций на базе Wi-Fi 6. Уже продумано большое
число сценариев интернета вещей для умного здания, в том числе для
контроля безопасности, для управления освещением и др.
Нельзя забывать и о том, что большинство приложений мигрирует в
облака, а для доступа к облаку требуется качественная, стабильная
связь. Именно поэтому Huawei использует как девиз и стремится
претворять в жизнь установку 100 Мбит/с повсюду: Wi-Fi становится
основным средством подключения к интернету, и вне зависимости от
местонахождения пользователя мы обязаны обеспечить ему высокий
уровень user experience.
Как Huawei предлагает управлять средой Wi-Fi 6
В настоящее время Huawei продвигает готовое end-to-end решение
Cloud Campus, нацеленное, с одной стороны, на то, чтобы помогать
управлять всей инфраструктурой из облака, с другой на то, чтобы
служить платформой для воплощения новых IoT-сценариев, будь то
управление зданием, мониторинг оборудования или, допустим, если
обратиться к кейсу из области медицины, контроль параметров
жизнедеятельности пациента.
Важная часть экосистемы вокруг Cloud Campus маркетплейс. Например,
если разработчик создал конечное устройство и интегрировал его с
решениями Huawei, написав соответствующее ПО, он вправе сделать
свой продукт доступным другим нашим клиентам по сервисной
модели.

Так как сеть Wi-Fi, в сущности, становится фундаментом для работы
бизнеса, прежних способов управления ею недостаточно. Раньше
администратор был вынужден практически вручную, копаясь в логах,
разбираться, что творится с сетью. Такого реактивного режима
поддержки теперь мало. Необходим инструментарий для проактивного
контроля и управления беспроводной инфраструктурой, с тем чтобы
администратор доподлинно понимал, что с ней происходит: какой
уровень user experience она обеспечивает, могут ли к ней без
проблем подключаться новые пользователи, не надо ли кого-то из
клиентов перебросить на соседнюю точку доступа (ТД), в каком
состоянии находится каждый отдельно взятый сетевой узел и пр.
Применительно к устройствам Wi-Fi 6 у Huawei имеются все средства
для проактивного, детального анализа и контроля происходящего в
сети. Опираются эти разработки прежде всего на алгоритмы машинного
обучения.
На точках доступа предыдущих серий подобное было невозможно, так
как они не поддерживали соответствующих протоколов телеметрии, да и
вообще производительность тех устройств не позволяла воплотить эту
функциональность в том виде, в каком позволяют наши современные
точки доступа.
В чём преимущества стандарта Wi-Fi 6

Долгое время камнем преткновения на пути распространение Wi-Fi 6
оставалось то обстоятельство, что де-факто отсутствовали конечные
устройства, которые предусматривали бы поддержку стандарта IEEE
802.11ax и могли в полной мере раскрыть преимущества, заложенные в
точку доступа. Однако в индустрии происходит перелом, и мы как
вендор ему всеми силами способствуем: Huawei разработала свои
чипсеты не только для корпоративных продуктов, но и для мобильных,
а также для домашних устройств.
По Сети ходит информация о Wi-Fi 6+ от Huawei. Что
это?
Это практически как Wi-Fi 6E. Всё то же, только с добавлением
частотного диапазона 6 ГГц. Во многих странах в настоящее время
рассматривают вопрос о его выделении под Wi-Fi 6.
Будет ли радиоинтерфейс 6 ГГц реализован на том же модуле,
который сейчас работает на 5 ГГц?
Нет, будут специальные антенны для работы в частотном диапазоне 6
ГГц. Нынешние точки доступа не поддерживают 6 ГГц, даже если
обновить их софт.
На сегодняшний день устройства, показанные на иллюстрации,
относятся к сегменту hi-end. Вместе с тем домашний роутер Huawei
AX3, дающий через радиоинтерфейсы скорость до 2 Гбит/с, по цене не
отличается от точек доступа предыдущего поколения. Поэтому есть все
основания полагать, что в 2020 году широкий круг устройства
среднего, а то и начального сегмента получит поддержку Wi-Fi 6.
Согласно аналитическим выкладкам Huawei,
к 2022 году продажи
точек доступа с поддержкой Wi-Fi 6 по отношению к тем, что
построены на Wi-Fi 5, составят 90 к 10%.
Через полтора года окончательно наступит эра Wi-Fi
6.
Прежде всего, Wi-Fi 6 рассчитан на то, чтобы сделать эффективнее
работу беспроводной сети в целом. Раньше каждой станции
последовательно выдавался временной слот, и она занимала весь канал
20 МГц, в связи с чем остальные были вынуждены ждать, когда она
отправит трафик. Теперь же эти 20 МГц нарезаны на менее крупные
поднесущие, объединяемые в ресурсные юниты, вплоть до 2 МГц, и в
один временной слот могут вещать одновременно до девяти станций.
Отсюда значительный рост производительности всей сети.
Мы уже рассказывали, что в стандарт шестого поколения были
добавлены более высокие схемы модуляции: 1024-QAM против прежних
256. Сложность кодирования, таким образом, увеличилась на 25%: если
раньше на один символ мы передавали до 8 бит информации, то сейчас
10 бит.
Увеличилось и число пространственных потоков (spatial streams). В
предыдущих стандартах их было максимум четыре, тогда как сейчас до
восьми, а в старших точках доступа Huawei и до дюжины.
Кроме того, в Wi-Fi 6 снова задействуется частотный диапазон 2,4
ГГц, который позволяет сравнительно недорого производить чипсеты
для конечных терминалов с поддержкой Wi-Fi 6 и подключать огромное
количество устройств, будь то полноценные IoT-модули или какие-то
совсем дешёвые датчики.
Что особенно важно, в стандарте реализовано немало технологий для
более эффективного использования радиоспектра, в том числе для
переиспользования каналов и частот. В первую очередь достойна
упоминания Basic Service Set (BSS) Coloring, которая позволяет
игнорировать чужие точки доступа, работающие на том же канале, и в
то же время слушать свои.
Какие точки доступа Wi-Fi 6 от Huawei мы считаем нужным делать
в первую очередь


На рисунках представлены точки доступа, которые Huawei предлагает
сегодня и, главное, которые вскоре начнёт поставлять, начиная с
базовой модели AirEngine 5760 и заканчивая топовыми.

В наших точках доступа, поддерживающих стандарт 802.11ax,
реализован целый комплекс уникальных технологических решений.
- Наличие встроенного модуля IoT или возможность подключения
внешнего. Во всех точках доступа верхняя крышка теперь
открывается, и под ней скрыты два слота под IoT-модули, причём
практически какие угодно. Например, от ZigBee, подходящие для
подключения умных розеток или реле, датчиков телеметрии и т. п. Или
специализированные, например для работы с электронными ценниками
(такое решение у Huawei реализовано в партнёрстве с компанией
Hanshow). Плюс у точек доступа некоторых серий имеется
дополнительный разъём USB, и модуль интернета вещей можно
подсоединить через него.
- Новое поколение технологии Smart Antenna. В корпусе
точки доступа размещается до 16 антенн, формирующих до 12
пространственных потоков. Такие умные антенны позволяют, в
частности, увеличить радиус покрытия (и избавиться от мёртвых зон)
за счёт того, что каждая из них имеет сфокусированный диапазон
распространения радиосигнала и понимает, где в тот или иной момент
времени пространственно находится конкретный клиент.
- Больший радиус распространения сигнала означает, что
RSSI у клиента, или уровень сигнала на приёме, тоже будет выше. В
сравнительных тестах, когда испытаниям подвергаются обычная
omni-directional точка доступа и та, которая снабжена
смарт-антеннами, у второй наблюдается двукратный прирост по
мощности дополнительные 3 дБ
В случае применения смарт-антенн не возникает
асимметрии сигнала, так как чувствительность точки доступа
пропорционально увеличивается. Каждая из 16 антенн выступает в
качестве зеркала: в силу принципа многолучевого распространения,
когда клиент отправляет пучок информации, соответствующая
радиоволна, отразившись от различных преград, попадает на все 16
антенн. Дальше точка, используя свои внутренние алгоритмы,
складывает полученные сигналы и с большей степенью достоверности
восстанавливает закодированные данные.
- Во всех новых точках доступа Huawei реализована технология
SDR (Software-Defined Radio). Благодаря ей в зависимости от
предпочтительного сценария эксплуатации беспроводной инфраструктуры
администратор устанавливает, каким образом должны функционировать
три радиомодуля. Сколько пространственных потоков на тот или иной
выделить, также определяется динамически. Например, можно сделать
так, чтобы два радиомодуля работали на подключение клиентов (один в
диапазоне 2,4 ГГц, другой в 5 ГГц), а третий функционировал как
сканер, следя, что происходит с радиосредой. Или задействовать три
модуля исключительно на подключение клиентов.
Ещё один распространённый сценарий это когда клиентов в сети не
слишком много, но у них на устройствах функционируют
высоконагруженные приложения, которым требуется высокая пропускная
способность. В таком случае все пространственные потоки
завязываются на частотные диапазоны 2,4 и 5 ГГц, каналы же
агрегируются, чтобы обеспечить пользователям не 20-, а
80-мегагерцовую полосу пропускания.
- В точках доступа реализованы фильтры в соответствии с
спецификациями 3GPP, для того чтобы размежевать между собой
радиомодули, которые потенциально могут работать на разных частотах
в диапазоне 5 ГГц, во избежание внутренней интерференции
Точки доступа предусматривают работу в разных режимах. Один из них
RTU (Right-to-Use). Вкратце его базовый принцип заключается в
следующем. Модели отдельных серий будут поставляться в стандартной
версии, например с шестью пространственными потоками. Далее же с
помощью лицензии можно будет расширить функциональность устройства
и активировать ещё два потока, раскрывая заложенный в него
аппаратный потенциал. Другой вариант: возможно, с течением времени
у клиента возникнет необходимость выделить дополнительный
радиоинтерфейс под сканирование эфира, и чтобы ввести его в строй,
достаточно будет опять же докупить лицензию.
В правой нижней части на предыдущей иллюстрации у точек доступа
приведены цифровые соответствия, например 2+2+4 применительно к
AirEngine 5760. Суть в том, что у ТД имеется три независимых
радиомодуля. Цифры показывают, какое количество пространственных
потоков будет привязано к каждому радиомодулю. Соответственно,
число потоков напрямую отражается на пропускной способности в том
или ином диапазоне. Стандартная серия предусматривает до восьми
потоков. Продвинутая до 12. Наконец, flagship (устройства класса
hi-end) до 16.
Как устроена линейка AirEngine

Отныне общий бренд корпоративных беспроводных решений AirEngine.
Как легко заметить, дизайн точек доступа создан под впечатлением от
турбин самолётных двигателей: на передней и задней поверхностях
устройств размещены специальные диффузоры.

Устройства начальной серии AirEngine 5760-51 наиболее доступны для
потребителя и рассчитаны на самые распространённые сценарии.
Например, для ритейла. Впрочем, и для офисных нужд они вполне
подходят, будучи универсальными с точки зрения используемого в них
технологического стека и стоимости.

Следующая по старшинству серия 5760-22W. В неё входят точки доступа
типа wall-plate, которые не подвешиваются к потолку, а ставятся на
стол, в угол или крепятся к стене. Наилучшим образом они подходят
для тех сценариев, в которых требуется охватить беспроводной связью
большое количество сравнительно маленьких помещений (в школе,
больнице и пр.), где также бывает точечно нужно и проводное
подключение.
У модели 5760-22W (wall-plate) предусмотрено подключение по 2,5
Гбит/с через медные интерфейсы, а также имеется специальный
SFP-трансивер для PON. Таким образом, уровень доступа можно
полностью реализовать по пассивной оптической сети и подключить
точку доступа напрямую к этой GPON-сети.

В модельный ряд входят как внутренние, так и внешние
точки доступа. Вторые легко отличить по литере R (outdoor) в
названии. Таким образом, AirEngine 8760-X1-PRO рассчитана на
применение в помещениях, а AirEngine 8760R-X1 на уличные сценарии.
Если же в названии точки доступа содержится буква E (external),
значит, антенны у неё не встроенные, а внешние.
Топовая модель AirEngine 8760-X1-PRO оснащена тремя
десятигигабитными интерфейсами для подключения. Два из них медные,
причём оба поддерживают PoE / PoE-IN, что позволяет зарезервировать
устройство по питанию. Третий для оптиковолоконного подключения
(SFP+). Уточним, это комбоинтерфейс: возможно подключение как по
меди, так и по оптике. Также, допустим, ничто не мешает подключить
точку доступа по оптике, а питание дать от инжектора через медный
интерфейс. Нужно упомянуть также встроенный порт Bluetooth 5.0.
Производительность у 8760-X1-PRO максимальная в линейке, благо она
поддерживает до 16 пространственных потоков.
Хватит ли точкам доступа PoE+ для
электропитания?
Для старшей серии (8760) требуется POE++. Именно поэтому в мае-июне
поступают в продажу коммутаторы CloudEngine s5732 с
мультигигабитными портами и с поддержкой 802.3bt (до 60
Вт).

Более того, AirEngine 8760-X1-PRO получает дополнительное
охлаждение. По двум контурам внутри точки доступа циркулирует
жидкость, отводя лишнее тепло от чипсета. Это решение в первую
очередь призвано обеспечить длительное функционирование устройства
с пиковой производительностью: некоторые другие вендоры
декларируют, что их точки доступа тоже в состоянии выдавать до 10
Гбит/с, тем не менее через 1520 минут эти устройства склонны к
перегреву, и ради понижения их температуры часть пространственных
потоков отключается, что снижает пропускную способность.
В точках доступа младших серий жидкостного охлаждения нет, однако у
них нет и проблемы перегрева в силу более низкой
производительности. Модели среднего уровня AirEngine 6760
поддерживают до 12 пространственных потоков. Подключение у них
также осуществляется по десятигигабитным интерфейсам. Кроме того,
наличествует гигабитный для подсоединения к существующим
коммутаторам.


Уже сравнительно давно Huawei предлагает решение
Agile
Distributed Wi-Fi, которое подразумевает наличие центральной
точки доступа и выносных радиомодулей, ею управляемых. Такая ТД
отвечает за разного рода высоконагруженные задачи и снабжена CPU,
чтобы реализовать QoS, принимать решения о роуминге клиентов,
ограничивать полосу, распознавать приложения и т. д. В свою
очередь, внешние радиомодули фактически отправляют трафик в
изначальном виде на центральную точку доступа и выступают
конверторами из 802.11 в 802.3.
Решение оказалось не слишком популярным в России. Тем не менее
нельзя не отметить и его преимущества. Например, возможность
изрядно сэкономить на стоимости лицензий, благо на каждый
радиомодуль не требуется покупать отдельную. Кроме того, основная
нагрузка ложится на центральные точки доступа, что позволяет
развернуть огромную, из десятка тысяч элементов, беспроводную сеть.
Так что мы обновили и Agile Distributed Wi-Fi, задействовав
преимущества своего технологического стека вокруг Wi-Fi 6.


Точки доступа для уличного применения также поступят в продажу в
июне. Старшая серия среди outdoor-устройств 8760R, с максимальным
технологическим стеком (в частности, доступно до 16
пространственных потоков). Однако, предполагаем, для большинства
сценариев оптимальным выбором будет 6760R. Уличное покрытие, как
правило, требуется или на складах, или для wireless bridging, или
на технологических площадках, где периодически возникает
необходимость принять или передать некую телеметрию или снять
информацию с терминалов сбора данных.
О технологических преимуществах точек доступа AirEngine

Раньше вариативность внешних антенн для наших точек доступа была
крайне ограниченна. Были либо антенны omni-directional (дипольные),
либо совсем узконаправленные. Теперь выбор шире. К примеру, увидела
свет антенна 70 / 70 по азимуту и элевации. Поставив её в углу
помещения, можно покрыть сигналом практически всё пространство
перед ней.
Перечень антенн, которыми снабжаются внутренние точки доступа,
пополняется, и не исключено, что будет пополняться в том числе
выпускаемыми другими производителями. Оговоримся, направленных
среди них нет. Если в помещении требуется организовать фокусировку
покрытия, нужно или использовать модели с внешними дипольными
антеннами и самостоятельно позиционировать их для оптимального
распространения радиосигнала, или брать точки доступа со
встроенными смарт-антеннами.

Касательно инсталляции точек доступа существенных изменений нет.
Все модели комплектуются креплениями для монтажа как на потолок,
так и на стену или даже на трубу (металлическими хомутами). Для
офисных потолков с рейлингами типа Armstrong крепления тоже
подходят. Дополнительно можно поставить замки, что особенно
актуально, если точка доступа будет функционировать в общественном
месте.

Если совсем бегло пройтись по ключевым технологическим новшествам,
которые были претворены в жизнь при разработке модельного ряда
AirEngine, получится такой список.
- Достигнута наибольшая по индустрии производительность. На
сегодняшний день только Huawei удалось реализовать 16 приёмных и
передающих антенн при 12 пространственных потоках в одной точке
доступа. Технологией смарт-антенн в том виде, в каком она воплощена
Huawei, также ни одна другая компания на текущий момент не
располагает.
- У Huawei имеются специальные решения для достижения сверхнизкой
задержки. Это позволяет, в частности, обеспечить полностью
бесшовный роуминг для подвижных складских роботов.
- Как известно, технология Wi-Fi 6 несёт в себе два решения для
множественного доступа: OFDMA и Multi-User MIMO. Никто, кроме
Huawei, до сих пор не сумел организовать их одновременную
работу.
- Поддержка интернета вещей у точках доступа AirEngine
беспрецедентно широкая и нативная.
- Линейка отвечает самым высоким стандартам безопасности. Так, во
всех наших точках Wi-Fi 6 реализовано шифрование на базе протокола
WPA3.

От чего зависит пропускная способность точки доступа? Согласно
теореме Шеннона, от трёх факторов:
- от количества пространственных потоков;
- от ширины полосы пропускания;
- от соотношения сигнал шум.
Решения Huawei по каждому из трёх названных направлений отличаются
от того, что предлагают другие вендоры, и в каждом содержат немало
улучшений.
- Устройства Huawei способны формировать до двенадцати
пространственных потоков, в то время как топовые точки доступа
других производителей лишь восемь.
- Новые точки доступа Huawei в состоянии формировать восемь
пространственных потоков шириной 160 МГц каждый, тогда как у
конкурирующих вендоров максимум восемь потоков по 80 МГц. Как
следствие, потенциально достижимо полутора-, а то и двукратное
превосходство наших решений в производительности.
- Что до соотношения сигнал шум, за счёт использование технологии
Smart Antenna наши точки доступа демонстрируют значительно большую
толерантность к интерференции и гораздо более высокий уровень RSSI
на приёме у клиента как минимум в два раза больше (на 3 дБ).

Разберёмся, откуда берётся пропускная способность, которую принято
указывать в datasheets. В нашем случае 10,75 Гбит/с.
Формула расчёта показана на рисунке выше. Давайте посмотрим, что
представляют собой множители в ней.
Первый число пространственных потоков (на 2,4 ГГц до четырёх, на 5
ГГц до восьми). Второй единица, делённая на сумму продолжительности
символа и длительности защитного интервала в соответствии с
используемым стандартом. Так как в Wi-Fi 6 продолжительность
символа увеличена вчетверо до 12,8 мкс, а защитный интервал равен
0,8 мкс, в итоге выходит 1/13,6 мкс.
Далее: напомним, благодаря улучшенной модуляции 1024-QAM на каждый
символ теперь может кодироваться до 10 бит. Итого имеем битрейт 5/6
(FEC) четвёртый множитель. А пятый количество поднесущих
(тонов).
Наконец, складывая максимальную производительность для 2,4 и для 5
ГГц, мы и получаем впечатляющее значение 10,75 Гбит/с.

Также в наших точках доступа и контроллерах появилось управление
радиочастотными ресурсами DBS. Если раньше нужно было единожды
выбрать для того или иного SSID ширину канала (20, 40 или 80 МГц),
теперь есть возможность настроить контроллер так, чтобы он делал
это динамически.

Ещё одно улучшение в распределение радиоресурсов привнесла
технология SmartRadio. Раньше при наличии нескольких точек доступа
в одной зоне можно было указать, по какому алгоритму
перераспределить клиентов, к какой ТД подключать нового и т. д. Но
эти настройки применялись лишь единожды, в момент его подсоединения
и ассоциации с сетью Wi-Fi. В случае же с AirEngine алгоритмы для
балансировки нагрузки могут применяться в реальном времени, когда
клиенты работают и, например, перемещаются между точками
доступа.

Важный нюанс относительно антенных элементов: в моделях AirEngine
они реализуют сразу и вертикальную, и горизонтальную поляризацию.
Каждый поддерживает четыре антенны, и таких элементов насчитывается
четыре штуки. Отсюда и итоговое количество 16 антенн.
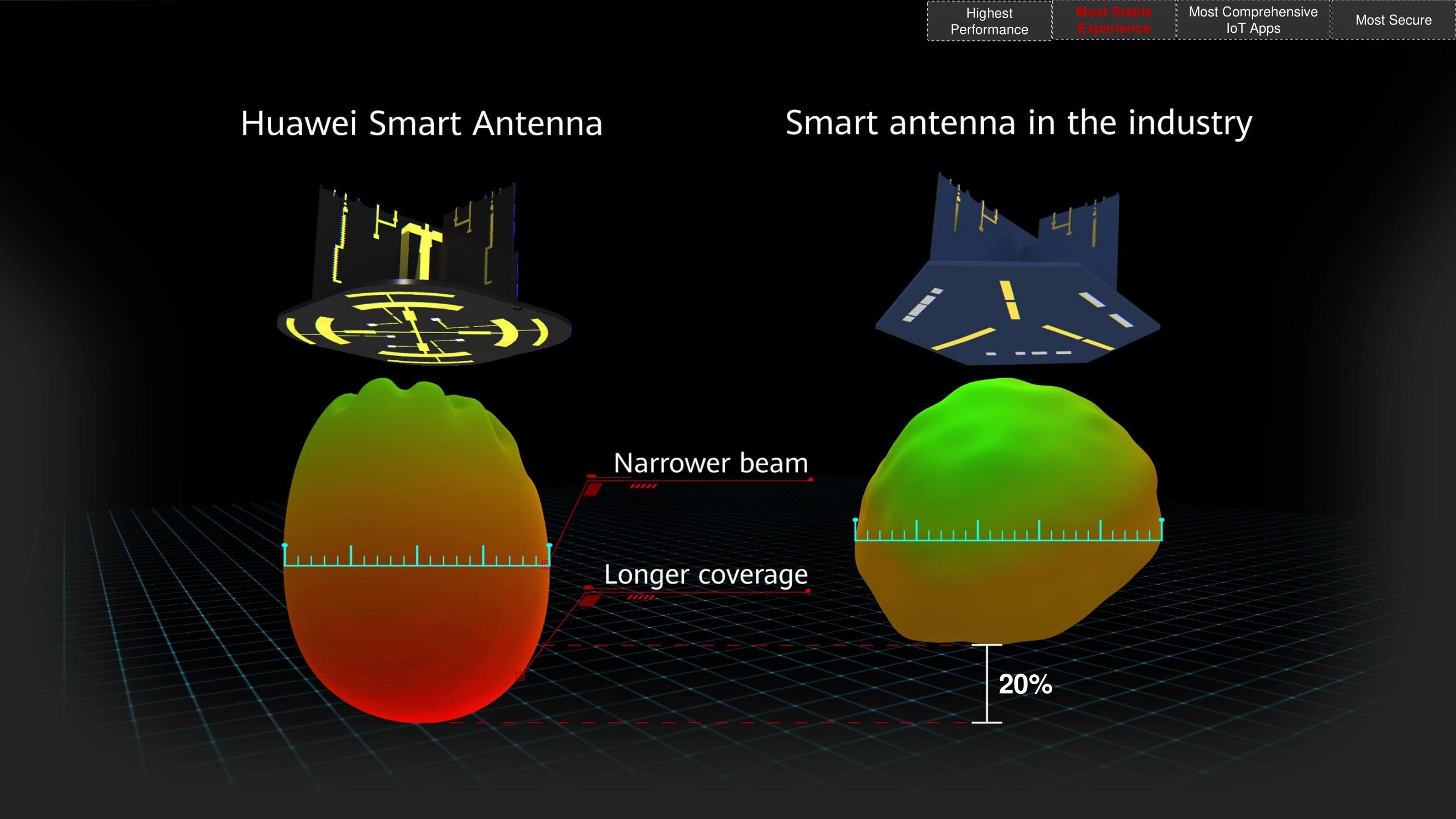
Сам по себе антенный элемент пассивный. Соответственно, чтобы
сфокусировать большее количество энергии в направлении клиента,
требуется сформировать с помощью компактных антенн более узкий луч.
Huawei это удалось. Итог радиопокрытие в среднем на 20% больше, чем
у конкурирующих решений.
Применительно к Wi-Fi 6 сверхвысокая пропускная способность и
высокие уровни модуляции (схемы MCS 10 и MCS 11) возможны, только
когда соотношение сигнал шум, или Signal-to-Noise Ratio, превышает
35 дБ. На счету каждый децибел. И смарт-антенна действительно
позволяет повысить уровень принимаемого сигнала.
В реальных тестах модуляция 1024-QAM при схеме MCS 10 будет
работать на удалении не более 3 м от точки доступа, какую из
доступных на рынке ни возьми. Ну а при использовании умной антенны
расстояние может быть увеличено до 67 м.

Ещё одна технология, которую Huawei интегрировала в новые точки
доступа, называется Dynamic Turbo. Её суть заключается в том, что
ТД на лету может распознавать и классифицировать приложения по
классам (допустим, передаёт оно real-time видео, голосовой трафик
или что-то другое), различать клиентов по степени их значимости и
выделять ресурс-юниты таким образом, чтобы важные для пользователей
высокоуровневые приложения работали быстро, насколько возможно.
Фактически на аппаратном уровне точка доступа осуществляет DPI
глубокий анализ трафика.

Как отмечалось ранее, Huawei на текущий момент единственный вендор,
который в своих решениях обеспечивает одновременную работу MU-MIMO
и OFDMA. Давайте чуть подробнее о том, в чём разница между
ними.
Обе технологии призваны обеспечивать multi-user access. Когда в
сети много пользователей, OFDMA позволяет распределить частотный
ресурс таким образом, чтобы множество клиентов получало и принимало
информацию в один момент времени. Однако и MU-MIMO в конечном счёте
нацелена на то же: когда несколько клиентов находятся в разных
точках помещения, каждому из них можно направить уникальный
пространственный поток. Для наглядности вообразим, что частотный
ресурс это трасса Москва Санкт-Петербург. OFDMA словно бы
предлагает: Давайте мы сделаем у дороги не одну полосу, а две,
чтобы она использовалась эффективнее. У MU-MIMO подход иной:
Давайте проложим вторую, третью дорогу, чтобы трафик шёл по
независимым путям. Теоретически одно другому не противоречит, на
деле же комбинация двух методов требует определённой
алгоритмической базы. Благодаря тому, что Huawei эту базу сумела
создать, пропускная способность наших точек доступа увеличилась
практически на 40% относительно того, что в состоянии обеспечить
конкуренты.
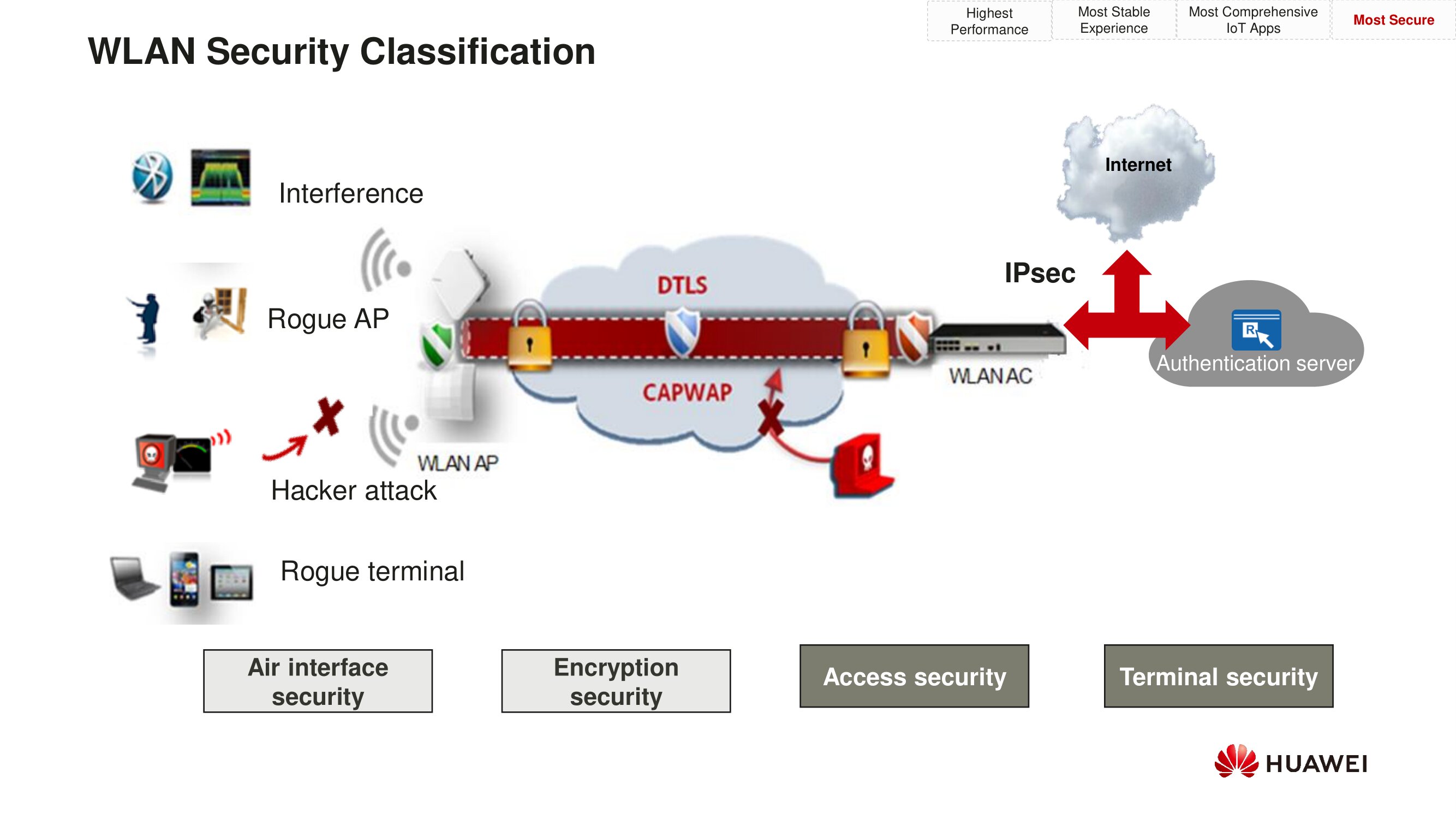

Что касается безопасности, новые точки доступа, подобно
предшествующим моделям, поддерживают DTLS. А значит, как и раньше,
управляющий CAPWAP-трафик можно шифровать.
С защитой от внешних злонамеренных воздействий всё тоже как в
предыдущем поколении контроллеров. Любые типы атак, будь то
брутфорс, атака Weak IV (слабые инициализационные векторы) или
нечто иное, детектируются в реальном времени. Настраивается и
реакция на DDoS: система умеет делать динамические чёрные списки,
уведомлять администратора о происходящем при попытке распределённой
сетевой атаки и пр.
Какие решения сопутствуют моделям AirEngine

Наша аналитическая платформа CampusInsight в разрезе Wi-Fi 6 решает
несколько задач. Прежде всего она задействуется в радиоменеджменте
наравне с контроллером: CampusInsight позволяет выполнять
калибрацию и в реальном времени наилучшим образом распределять
каналы, регулировать мощность сигнала и полосу пропускания того или
иного канала, контролировать, что вообще происходит с сетью Wi-Fi.
При всём при том CampusInsight применима и в wireless security (в
частности, для intrusion prevention и intrusion detection), причём
не в привязке к конкретной точке доступа или одному SSID, а в
масштабе всей беспроводной инфраструктуры.

Достоин внимания и WLAN Planner средство для радиомоделирования,
причём часть препятствий, например стены, он умеет определять
самостоятельно. На выходе программа выдаёт краткий отчёт, в котором
среди прочего указывается, какое количество точек доступа требуется
для покрытия помещения. Исходя из таких вводных гораздо проще
принимать более осмысленные решения относительно спецификаций
оборудования, бюджетирования и т. д.

Среди ПО упомянем также приложение Cloud Campus App, доступное всем
желающим как на iOS, и на Android и содержащее целый набор
инструментов для контроля беспроводной сети. Часть из них
предназначена для проверки качества работы Wi-Fi (например,
роуминг-тест). Помимо всего прочего, можно оценивать уровень
сигнала, находить источники интерференции, проверять пропускную
способность в той или иной зоне, а при наличии проблем выявлять их
причины.
***
Эксперты Huawei продолжают регулярно проводить вебинары по нашим
новым продуктам и технологиям. Среди тем: принципы построения ЦОДов
с использованием оборудования Huawei, специфика эксплуатация
массивов Dorado V6, ИИ-решения для различных сценариев и многое,
многое другое. Список вебинаров на ближайшие недели вы найдёте,
пройдя по
ссылке.
Приглашаем вас также заглянуть на
форум Huawei Enterprise,
где обсуждаются не только наши решения и технологии, но и более
широкие вопросы инженерного толка. В том числе на нём открыта ветка
по Wi-Fi 6 подключайтесь к дискуссии!




















































































































































































































































