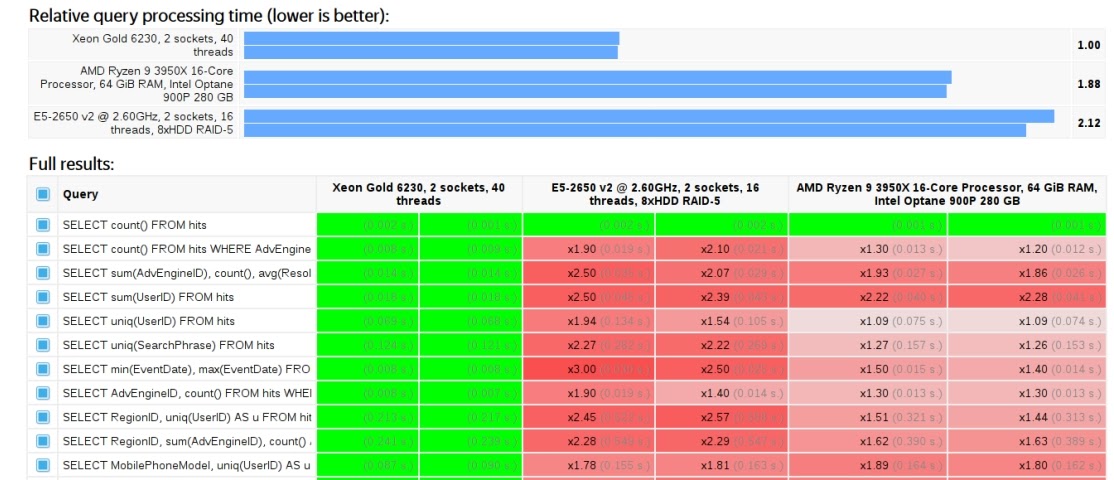
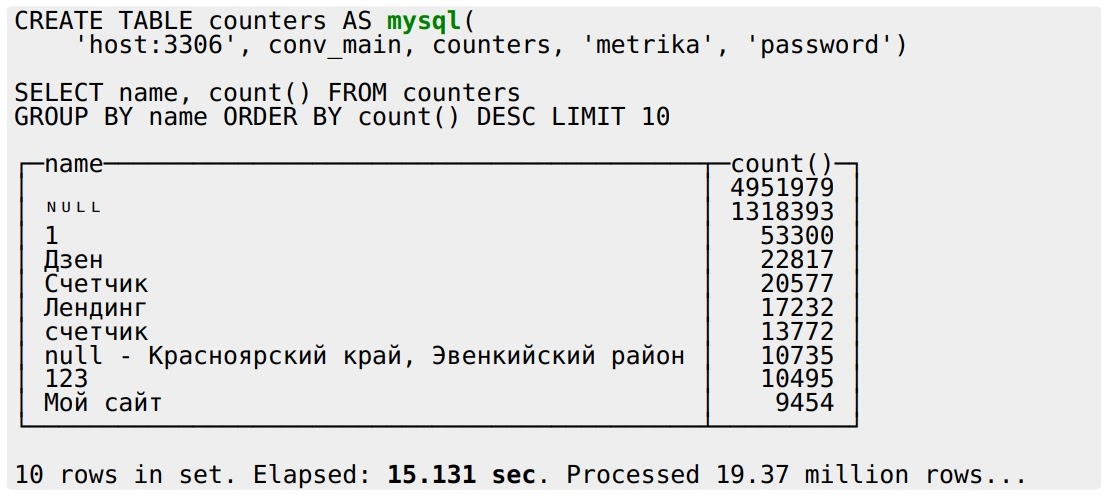
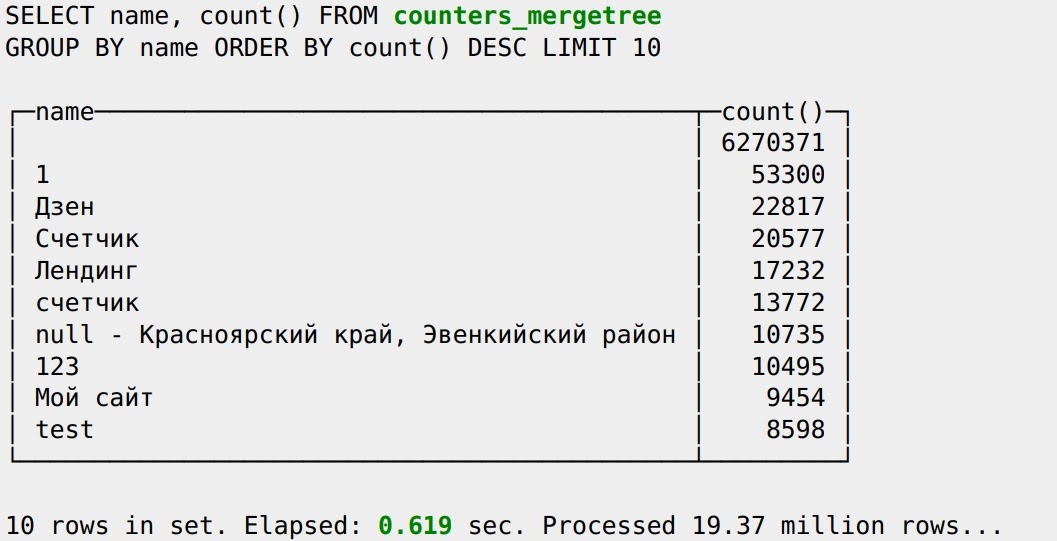
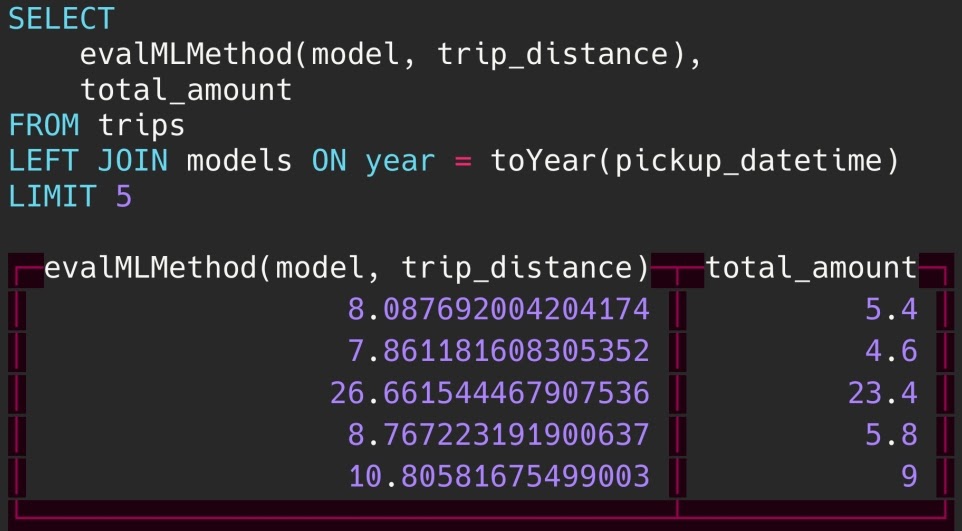
Продолжаем беседовать с разработчиками экосистемы сервисов Serverless. В начале нашего путешествия Глеб Борисов описал ситуацию с Yandex Cloud Function, затем Данил Ошеров погрузил нас в мир протокола S3 и сервиса Object Storage, а сегодня Андрей Фомичев поделится подробностями о NewSQL.
Благодаря современным облакам можно накапливать большие объёмы информации, что в перспективе позволит легко прогнозировать потребление ресурсов (то есть использовать предсказательную аналитику). В новых условиях мы ожидаем, что СУБД и сервисы, их сопровождающие, подскажут нам: сейчас необходимо повысить производительность, а для этого увеличить платёж. Или: игнорируйте запросы, которые приходят, чтобы спала мусорная нагрузка. Кажется, такого раньше не было...
В целом я с тобой согласен. Я давно работаю в Яндексе и занимаюсь пользовательскими сервисами. Я долго делал это для внутренних пользователей, а теперь делаю и для внешних.
Традиционная модель: ставишь PostgreSQL-кластер и обслуживаешь его самостоятельно или с помощью команды. Тратишь на это силы и время. Наши сервисы большие и сложные, для их обслуживания четверти человека не хватит, и половины не хватит нужно вкладываться по полной. Поэтому мы давным-давно живём в режиме, что если что-то не так работает (например, нагрузка выросла и ресурсов не хватает), то мы сами дёргаем пользователя и подсказываем, в чём проблема и как её исправить: ресурсы докинуть или запросы оптимизировать. В этом смысле публичное облако должно вести себя именно так.
Для меня облако это не просто возможность быстро создать виртуалочку, а потом удалить её. А его сервисная сущность, когда мы рассматриваем Platform as a Service, базы данных и так далее. Это те сервисы, которые человек и сам себе может организовать, но стоить это будет неимоверно дорого.
Если мы говорим об эволюции использования баз данных, мой путь начался с СУБД Berkeley DB. Очень старая, немного эзотерическая, но очень опенсорсная в своё время. Потом были и MySQL, и PostgreSQL. В основном применял их как записную книжку для данных с удобным поиском. А с каких баз данных ты начинал?
У меня история интересная. Со студенческих времён работаю системным программистом, а такой программист скорее не использует базы данных, а создаёт их. Подсел на это дело, создавал системы хранения и обработки данных. Первая база данных называлась Sedna. Мы её делали ещё в Академии наук, это был опенсорсный проект.
Тогда технология XML была на пике популярности. Мы использовали XML-файлы. Но однажды файлов стало так много, что потребовалась база данных, которая могла бы хранить, обрабатывать их и поддерживать декларативный язык запросов. Таким языком был XQuery, он был достаточно мощным, даже мощнее SQL. Многие, наверно, знают XPath, это такое подмножество XQuery. И среди тех, кто работал с XML, XPath очень популярен.
Дальше я работал со многими базами данных. Для удобства разделяю их на три вида. Встроенные базы данных с особой экосистемой интересные решения, там множество хаков на уровне железа. Клиент-серверные, где клиент устанавливает соединение с удалённой машиной (сервером баз данных) и работает с данными. И третий вид, наиболее мне интересный: распределённые базы данных. Это когда за соединением или множеством соединений скрывается кластер машин, который хранит и обрабатывает данные. Полноценные распределённые системы, распределённый консенсус, и об этом можно бесконечно разговаривать.
По факту все эти СУБД должны хорошо решать задачу масштабирования. А есть распределённые системы, построенные поверх клиент-серверных?
Если брать классические клиент-серверные базы данные, то многие из них (например, PostgreSQL) не распределённые. Они обеспечивают отказоустойчивость и масштабирование, но это лишь дополнения к основной функциональности. Они очень хорошо реализованы: стандартные способы, технологии репликации лога всё работает. Но эти механизмы появились потом, и поэтому такие базы данных на write-нагрузку масштабируются очень ограниченно или почти не масштабируются.
Если же мы касаемся именно распределённых систем, то для них есть свои интересные классификации.
К примеру, есть деление на shared nothing и shared что-нибудь. В случае с shared storage, например, можно подключить полку к EMC или NetApp, хранить там данные, и такое решение будет работать. И это хорошее enterprise-решение, оно масштабируется, но с нюансами. Shared nothing это узлы или машины, которые соединены только сетью. Идеальный кейс для отличного масштабирования это shared nothing: cluster, commodity, hardware классика жанра.
Этот класс систем появился почти одновременно у нескольких компаний. Откуда вообще возникла такая потребность?
Традиционно считается, что она возникла с появлением и развитием интернета. Неудивительно, что в ряду производителей есть Яндекс, который также приложил много усилий к развитию интернета. Если погружаться, то история появления Yandex Database (сокращённо YDB) длинная.
Внешние пользователи знают прежде всего о ClickHouse, но, когда я 12 лет назад пришёл в Яндекс, ситуация была иной. Мы, как и другие интернет-гиганты, только подступали к новому этапу развития сервисов.
Я работал в Поиске, в веб-роботе. Мы собирали данные поисковой базы, хранили их, индексировали, выкладывали на Поиск и по ним отрабатывали поисковые запросы. Сначала были десятки, потом сотни, а потом и сильно больше машин. Потребовалось распределённо хранить данные и делать репликацию, чтобы система была отказоустойчивой и процессы не падали, если откажут машины, вылетят диски или возникнут прочие стандартные проблемы.
Придумали массу способов бороться с отказами в распределённых системах. Системы писались разные, но и их все можно охарактеризовать, например, с точки зрения консистентности. Это значит, что вы, работая с кластером, видите или не видите спецэффекты распределённости.
Грубо говоря, если система консистентна то вы как пользователь можете даже не знать, что это громадный кластер, где бывают сбои. Работаете так же, как и с обычным сервером, и этот сервер отказоустойчив: не ломается никогда. Очень удобно.
Прихожу к кластеру и говорю: Сделай запись в эту табличку, вот тебе набор полей, которые нужно сохранить, пожалуйста, сохрани. Коммить и беги, условно говоря?
Да, конечно. Вот классика: у нас есть key-value база данных. Я по ключу меняю значение, а мой сосед, который сидит рядом, за другим компьютером, его читает. Возникает вопрос: сосед увидит старое значение, которое я записал, или какие-то спецэффекты, особенно если в кластере что-то произойдёт? Усложняем задачу: я транзакционно пишу две записи, и у меня два ключа два значения, которые я хочу поменять транзакционно. Например, у меня есть два счёта, я перекладываю сто рублей с одного на другой. Что увижу я и что увидит наблюдатель, мой сосед?
Вот это сложности распределённой системы, консенсуса распределённых транзакций в чистом виде. В идеале это должно работать, как будто мы пишем на один жёсткий диск на один компьютер. Тогда идеально всё выстраивается в очередь, если говорить умным термином, и все транзакции реализуются.
Получается, изначально вы ставили задачу обрабатывать данные от веб-роботов? И придумали решение, которое позволило распределённо обрабатывать большие объёмы данных, причём отказоустойчиво?
К задаче надо добавить ещё одно важное обстоятельство, которое стало стартовым катализатором: требование real-time. Real-time, понятно, условный. И в контексте YDB мне больше нравится говорить не real-time, а интерактивность. Система должна обеспечивать все эти характеристики так, чтобы она могла интерактивно взаимодействовать с человеком.
Представь: ты разрабатываешь сложный сервис для миллионов пользователей. Хороший пример соцсеть, хотя есть много других веб-сервисов с похожей сложностью. Тебе нужно хранить данные в базе данных и обеспечивать отказоустойчивость с оглядкой на реакцию пользователя. Он подружился с кем-нибудь или сохранил запись и ты хочешь, чтобы это обрабатывалось за 10 или 100 миллисекунд, чтобы для пользователя всё происходило очень быстро.
Каждый крупный поисковик или соцсеть сталкивается с такой задачей. Но чем YDB полезна для простого разработчика на Java, Python или Go? Он говорит: Я приду завтра в свою контору, у нас там CRM-система всего на сто-двести-триста одновременно работающих пользователей. Что ему от такой СУБД?
Тут как раз много аспектов и нюансов. Архитектура в основе YDB очень интересная. Каждая инсталляция отвечает не за определённый объём данных (допустим, десять терабайт), которые хранятся локально. Система состоит из очень большого числа маленьких объектов tablet. Tablet реализует некий консенсус, и он хранит условно пару гигабайтов данных. Это означает, что Yandex Database может расти до очень больших значений, но быть маленькой и эффективной. Благодаря этому ты получаешь гибкость: если сервис вырастет в десятки, сотни, тысячи раз ты масштабируешься быстро и удобно. Но пока сервис маленький, он и стоить будет дёшево. Мне эта мысль очень нравится, она ко мне не сразу пришла.
Вот чем хороши виртуальные машины? Чем хороши облака? Чем хороша виртуализация в общем смысле?
Раньше было как? Хочешь запустить систему на сервере купи сервер. У него десятки (а сейчас встречаются и сотни) ядер, и есть вероятность, что тебе не нужно столько ресурсов, а они дорогие и сложные, требуют обслуживания... А виртуализация позволяет запустить виртуалку всего на два, четыре, шесть, восемь ядер и так далее: ровно по потребности. И если база данных начинает тебе предоставлять то же самое, что и виртуализация (CPU, RAM, диск), то это же по-настоящему удобно. Прямо по-настоящему.
Такой мини-контейнер с базой данных, который ещё и в облаке находится? По сути, ты можешь её очень хитро менеджить, помещать в разных частях этого облака. Она, как виртуальная машина, ползает по нему?
Да. Очень важно, что эти микросущности выгодны: ты платишь за запросы, и у тебя на сервисе столько ресурсов, сколько нужно. Кроме того, облако как сервис за тебя управляет базой данных.
Мы очень плавно перешли к serverless-составляющей YDB.
YDB это полноценный сервер базы данных, который ты, по сути, можешь купить в облаке. Он устанавливается и обслуживается так же, как виртуальная машина, есть даже специальный контейнер с YDB для разработчиков.
Serverless-решение по-другому работает и иначе масштабируется. Serverless YDB это managed-сервис. Появился он следующим образом: для YDB как для продукта нужна ниша, и очевидно, что она есть. YDB используют в Яндексе и Yandex.Cloud для масштабных сервисов. Понятно, что мало каким потребителям и клиентам нужны кластеры из десятков и сотен машин. Но serverless-парадигма позволяет большому количеству пользователей проектировать работу со всеми возможностями YDB.
Например, быстрый failover. В YDB шард очень маленький, и вся система устроена таким образом, что даже в dedicated-варианте, когда всё работает на выделенных виртуальных машинах, эти маленькие сущности удобно и легко балансировать. Они переезжают с машины на машину и поднимаются за доли секунды. Если вы пришли, создали таблицу и положили туда 100 МБ, все эти 100 МБ будут жить в одном шардике. YDB реализована с применением модели акторов этот шардик будут обслуживать несколько акторов. Она потребляет мало CPU и обходится дёшево с точки зрения аппаратных ресурсов.
Для небольших проектов это очень выгодно. К тому же у нас есть Free Tier: каждый месяц можно выполнить 1 миллион операций (в единицах RU) бесплатно. А крупные и высоконагруженные проекты могут быстро масштабироваться в зависимости от пиковых нагрузок.
Интересный подход использовать в тарификации условные единицы. Можешь рассказать, что такое RU и как они пересчитываются в рубли?
RU это request unit, некая условная единица. Фактически это стоимость чтения по ключу нескольких килобайт данных. Бесплатно во Free Tier дается миллион таких RU. Если запрос сложнее, чем просто чтение по ключу, то его стоимость пропорционально увеличивается. Так и происходит тарификация. Но миллион простых запросов в месяц это достаточно много. И простенький микросервис (или даже не совсем простенький) во Free Tier легко укладывается.
Давай под конец сформулируем: зачем современному разработчику сервисов в облаке использовать YDB?
Из-за многих причин. Возможность бесконечно масштабироваться. Меньше заботы о работоспособности часто самого критичного и сложного компонента сервиса базы данных (обычно, если база данных падает или перестаёт работать, всё становится плохо и сложно).
А ещё это безумно интересно, на пике serverless-подхода. Если попробуете я думаю, вы немного измените представление о мире современных технологий. Как в своё время понятие виртуализации изменило подход к построению вычислительных систем, так же его рано или поздно изменит и подход serverless.
Причём (я немножко похвастаюсь) YDB на голову выше других систем, в том числе serverless. Их на рынке немного. И далеко не все из них технически продвинуты. Взять хотя бы Amazon DynamoDB это NoSQL нереляционная база данных. Там нет SQL, и она этим проигрывает. У Google Cloud Spanner нет публичной serverless-версии. Поэтому Yandex.Cloud предлагает по-настоящему интересную, современную и в чём-то уникальную технологию.
Итак, с YDB разработчик получает: распределённую NewSQL СУБД с поддержкой бессерверных вычислений, высокую доступность, масштабируемость, поддержку строгой консистентности и ACID-транзакций. А в дополнение ещё и API-сервис, в режиме бессерверных вычислений совместимый с API Amazon DynamoDB. Ну а подробности о новых шагах Serverless-сервисов, подробностях и нюансах разработки можно узнать в сообществе Serverless в Telegram:Yandex Serverless Ecosystem.













































") Казимир Малевич, Спортсмены (1932)
Казимир Малевич, Спортсмены (1932)