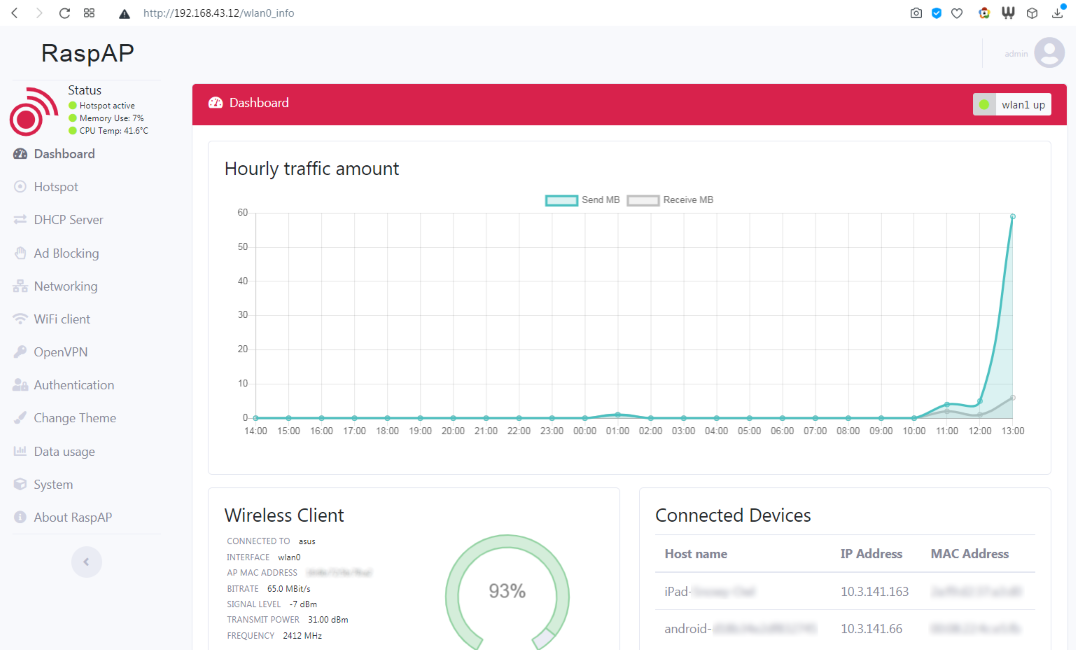
Когда заходит речь про программирование на C# .NET для одноплатных
компьютеров, то разговоры крутятся только в основном вокруг
Raspberry Pi на Windows IoT. А как же Banana/Orange/Rock/Nano Pi,
Odroid, Pine64 и другие китайские одноплатные компьютеры работающие
на Linux? Так давайте это исправим, установим .NET 5 на Banana Pi
BPI-M64 (ARM64) и Cubietruck (ARM32), и будем управлять контактами
GPIO из C# в Linux. В первой части серии постов, подключим
светодиод и кнопку для отработки прерываний и рассмотрим библиотеку
Libgpiod (спойлер, библиотеку так же можно использовать в C++,
Python) для доступа к контактам GPIO.
Предисловие
Управление светодиодом и получение событий от кнопки будет
реализовано через библиотеку
Libgpiod, которая не
является частью платформы .NET. Данная библиотека предоставляет
доступ к GPIO из любого языка программирования, требуется лишь
написание класса обертки.
Данный пост применим не только к платам Banana Pi BPI-M64 и
Cubietruck, но и другим, основанных на процессоре ARM
архитектуры armv71(32-bit) и aarch64 (64-bit). На Banana Pi BPI-M64
(ARM64) и Cubietruck (ARM32) установлена ОС Armbian версии 21.02.1,
основанная на Ubuntu 18.04.5 LTS (Bionic Beaver), ядро Linux
5.10.12. uname: Linux bananapim64 5.10.12-sunxi64 #21.02.1 SMP Wed
Feb 3 20:42:58 CET 2021 aarch64 aarch64 aarch64 GNU/Linux
Armbian
это самый популярный дистрибутив Linux, предназначенный для
одноплатных компьютеров построенных на ARM процессоре, список
поддерживаемых плат огромен: Orange Pi, Banana Pi, Odroid, Olimex,
Cubietruck, Roseapple Pi, Pine64, NanoPi и др. Дистрибутив Armbain
основан на Debian и Ubuntu. Из большого перечня поддерживаемых
одноплатных компьютеров можно выбрать то решение, которое лучше
всего походит для вашего IoT проекта, от максимально
энергоэффективных до высокопроизводительных плат с NPU. И на базе
всех этих одноплатных компьютеров, вы сможете реализовать свое
решения на платформе .NET и работать с периферийными устройствами
из кода на C#.
Что такое GPIO
GPIO(general-purpose
input/output) интерфейс ввода/вывода общего назначения.
GPIOподключены напрямую к процессору
SoC
(System-on-a-Chip Система на кристалле), и неправильное
использование может вывести его из строя. Большинство одноплатных
компьютеров, кроме обычных двунаправленных Input/Output портов,
имеют один или более интерфейсов: UART,SPI,IC/TWI,PWM (ШИМ), но не
имеютADC (АЦП).
GPIO- порты обычно могут быть
сконфигурированны на ввод или вывод
(
Input/Output), состояние по умолчанию
обычно
INPUT.
Некоторые GPIO-порты являются просто питающими портами 3.3V, 5V и
GND, они не связаны с
SoCи не могут использоваться
как либо еще.
Порты с
альтернативной функцией- могут быть
мультиплексированны с одним из
соответствующих
емуинтерфейсов.
Порты в режиме
INPUTмогут
генерировать
прерывания по спаду, по фронту, по
логическому уровню, по изменению сигнала и в асинхронном режиме по
фронту и спаду. Порты в режиме
INPUTимеют входную
фильтрацию на триггере
Шмитта(преобразовывают
аналоговый сигнал в цифровой с резкими переходами между
состояниями).
Работа с контактами
GPIOосуществляется через
виртуальную файловую систему
sysfs. стандартный
интерфейс для работы с контактами sysfs впервые появился с версии
ядра 2.6.26, в Linux. Работа с GPIO проходит через каталог
/sys/class/gpio путём обращения к файлам-устройствам.
К портам GPIO подключаются:
- светодиоды;
- кнопки;
- реле;
- температурные и другие датчики;
- различные периферийные устройства.
Для программирования
GPIO существует несколько
способов обращения:
- Посредством файл-устройства GPIO;
- Используя языки программирования:
- Через прямое обращение к регистрам чипа;
- Используя уже готовые библиотеки (libgpiod).
Одноплатный компьютер Banana Pi BPI-M64
Banana Pi BPI-M64 это 64-битный четырехъядерный
мини-одноплатный компьютер, поставляемый как решение с открытым
исходном кодом. Ядром системы является процессор Allwinner A64 с
4-мя ядрами Cortex-A53 с частотой 1.2 ГГц. На плате размещено 2 ГБ
DDR3 SDRAM 733МГц оперативной памяти и 8 ГБ eMMC.
На плате размещен 40-контактный совместимый с Raspberry Pi разъем,
который содержит: GPIO (x28), Power (+5V, +3.3V and GND), UART,
I2C, SPI. И 40-контактный интерфейс MIPI DSI.
 Banana Pi BPI-M64 и 40-контактный разъем типа Raspberry Pi
3
Banana Pi BPI-M64 и 40-контактный разъем типа Raspberry Pi
3
Наличие 40-контактного разъема типа Raspberry Pi 3 GPIO,
существенно облегчает подключение датчиков из-за совпадение
назначение контактов с Raspberry Pi 3. Не приходится гадать к
какому контакту подключать тот или иной датчик. Указанные в посте
датчики (светодиод и кнопка) подключенные к Banana Pi BPI-M64,
можно подключать на те же самые контакты другого одноплатного
компьютера, на котором тоже есть 40-контактный разъем, типа
Raspberry Pi 3 (или к самой Raspberry Pi 3, разницы нет никакой).
Единственное, необходимо изменить номера контактов (линий, ножка
процессора) в программном коде, т.к. они зависят от используемого
процессора. Но легко определяются но названию контакта. Плата
Cubietruck (ARM32) приведена для проверки совместимости и работы
кода на 32-разрядных ARM процессорах.
 Позиция [1] 3V3 power соответствует позиции на
плате со стрелочкой
Формула для вычисления номера GPIOXX
Позиция [1] 3V3 power соответствует позиции на
плате со стрелочкой
Формула для вычисления номера GPIOXX
Для обращение к контактам из C# кода необходимо знать порядковый
номер (линия, порт) физической ножки процессора SoC(для Allwinner).
Эти данные в спецификациях отсутствую, т.к. порядковый номер
получаем путем простого расчета. Например, из схемы возьмем
32-контакт на разъеме типа Raspberry Pi. Название контакта
PB7, для получения номера контакта на процессоре
произведем расчет по формуле:
(позиция буквы в алфавите 1) * 32 + позиция
вывода.Первая буква не учитывается т.к. P PORT, позиция
буквы B в алфавите = 2, получаем
(2-1) * 32 + 7 =
39. Физический номер контакта
PB7является
номер
39.
У каждого разработчика SoC может
быть свой алгоритм расчета номера контактов, должен быть описан в
Datasheet к процессору.
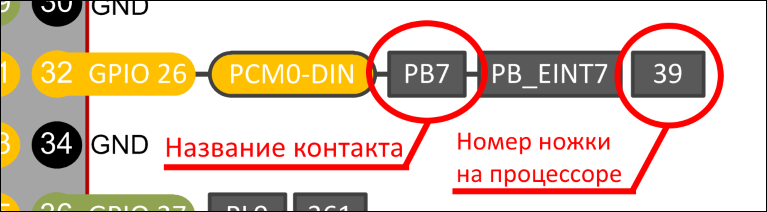 Контакт PB7 на процессоре Allwiner A64, номер ножки 39
Контакт PB7 на процессоре Allwiner A64, номер ножки 39
Библиотеки .NET IoT
До того как напишем первую программу на C# по управления GPIO,
необходимо рассмотреть пространство имен входящих в
dotnet/iot.
Все используемые библиотеки добавляются через Nuget пакеты.
Подробно рассмотрим драйвера для получения доступа к контактам GPIO
одноплатного компьютера. Код на C# взаимодействует с GPIO через
специальный драйвер, который является абстракцией доступа к GPIO и
позволяет переносить исходный код от одного одноплатного компьютера
к другому, без изменений.
Пространства имен .NET IoT:
- System.Device.Gpio. Пакет System.Device.Gpio
поддерживает множество протоколов для взаимодействия с
низкоуровневыми аппаратными интерфейсами:
- General-purpose I/O (GPIO);
- Inter-Integrated Circuit (I2C);
- Serial Peripheral Interface (SPI);
- Pulse Width Modulation (PWM);
- Serial port.
- Iot.Device.Bindings. Пакет Iot.Device.Bindings
содержит:
- Драйвера и обертки над System.Device.Gpio для различных
устройств которые упрощают разработку приложений;
- Дополнительные драйвера поддерживаемые сообществом
(community-supported).
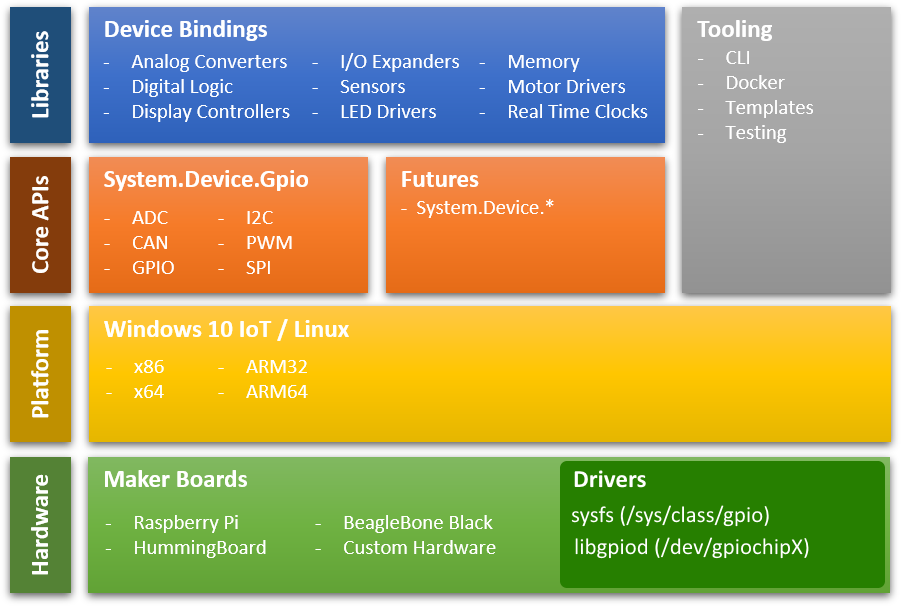 Стек библиотек .NET IoT
Стек библиотек .NET IoT
Рассмотрим первую программу типа Hello World, мигание светодиода
(
Blink
an LED):
using System;using System.Device.Gpio;using System.Threading;Console.WriteLine("Blinking LED. Press Ctrl+C to end.");int pin = 18;using var controller = new GpioController();controller.OpenPin(pin, PinMode.Output);bool ledOn = true;while (true){ controller.Write(pin, ((ledOn) ? PinValue.High : PinValue.Low)); Thread.Sleep(1000); ledOn = !ledOn;}
Разбор кода:
- using System.Device.Gpio пространство имен для
использования контроллера GpioController доступа к
аппаратным ресурсам;
- using var controller = new GpioController()
создает экземпляр контроллера для управления контактами GPIO;
- controller.OpenPin(pin, PinMode.Output)
инициализирует контакт pin = 18 на вывод, к 18 контакту подключен
светодиод;
- controller.Write(pin, ((ledOn)? PinValue.High:
PinValue.Low)) если ledOn принимает
значение True, то PinValue.High
присваивает высокое значение 18 контакту и светодиод загорается. На
18 контакт подается напряжение в 3.3V. Если ledOn
принимает значение False, то
PinValue.Low присваивает низкое значение контакту
18 и светодиод гаснет. На 18 контакт подается напряжение в 0V (или
минимальное пороговое для значения 0, может быть немного выше
0V).
Далее остается компиляция под ARM архитектуру:
dotnet publish -r
linux-arm или
dotnet publish -r linux-arm64. Но так
работает просто только для Raspberry Pi. При использование
одноплатных компьютерах отличных от Raspberry Pi необходимо при
инициализации
GpioController выбирать драйвер
доступа к GPIO.
Драйвера доступа к GPIO из .NET
Классы драйверов доступа к GPIO находятся в пространстве имен
System.Device.Gpio.Drivers. Доступны следующие
драйвера-классы:
- HummingBoardDriver GPIO драйвер для платы
HummingBoard на процессоре NXP i.MX 6 Arm Cortex A9;
- LibGpiodDriver этот драйвер использует
библиотеку Libgpiod для получения доступа к портам
GPIO, заменяет драйвер SysFsDriver. Библиотека
Libgpiod может быть установлена на Linux и Armbian, не является
аппаратно-зависимой, что позволяет ее использовать для различных
одноплатных компьютерах ARM32 и ARM64;
- RaspberryPi3Driver GPIO драйвер для
одноплатных компьютеров Raspberry Pi 3 или 4;
- SysFsDriver GPIO драйвер работающий поверх
интерфейса SysFs для Linux и Unux систем,
предоставляет существенно меньше возможностей, чем драйвер
LibGpiodDriver, но не требует установки библиотеки
Libgpiod. Тот случай, когда хочется просто попробовать помигать
светодиодом из C# без дополнительных действий;
- UnixDriver базовый стандартный класс доступа к
GPIO для Unix систем;
- Windows10Driver GPIO драйвер для ОС Windows 10
IoT. Из поддерживаемых плат только Raspberry Pi, весьма
ограниченное применение.
В данном посте будет рассматриваться доступ к GPIO через драйвер
LibGpiodDriver. Драйвер
SysFsDriver
базируется на устаревшем методе работы с GPIO через виртуальную
файловую систему SysFs. Для решений IoT, SysFs не подходит по трем
серьезным причинам:
- Низкая скорость работы I/O;
- Есть проблемы с безопасной работой с GPIO при совместном
доступе;
- При контейнеризации приложения на C# в контейнер придется
пробрасывать много путей из файловой системы Linux, что создается
дополнительные сложности. При использование библиотеки Libgpiod
этого не требуется.
Библиотека
Libgpiod предназначена для работы с
GPIO не только из .NET кода, но и из Python, C++, и т.д. Поэтому
ниже изложенная инструкция по установке библиотеки
Libgpiod позволит разработчикам на Python
реализовывать подобную функциональность, как и на C#. В состав
пакета
Libgpiod входят утилиты для работы с GPIO.
До создание программы на C#, поработаем с датчиками через эти
утилиты.
Схема подключения светодиода (LED) и кнопки
Подключать светодиод и кнопку будем на 40-контактный разъем
совместимый с Raspberry Pi 3.
Светодиод будет
подключен на 33 контакт разъема, название контакта PB4, номер линии
36.
Кнопка будет подключен на 35
контакт разъема, название контакта PB6, номер линии
38. Необходимо обратить внимание на поддержку
прерывания на контакте PB6 для кнопки. Поддержка прерывания
необходима для исключения постоянного опроса линии с помощью CPU.
На контакте PB6 доступно прерывание PB_EINT6, поэтому кнопку к
этому контакту и подключим. Например, соседний контакт PL12 не
имеет прерывание, поэтому подключать кнопку к нему кнопку не будем.
Если вы подключаете кнопку и резистор напрямую, то не забывайте в
цепь добавить резистор для сопротивления для избежания выгорания
порта!
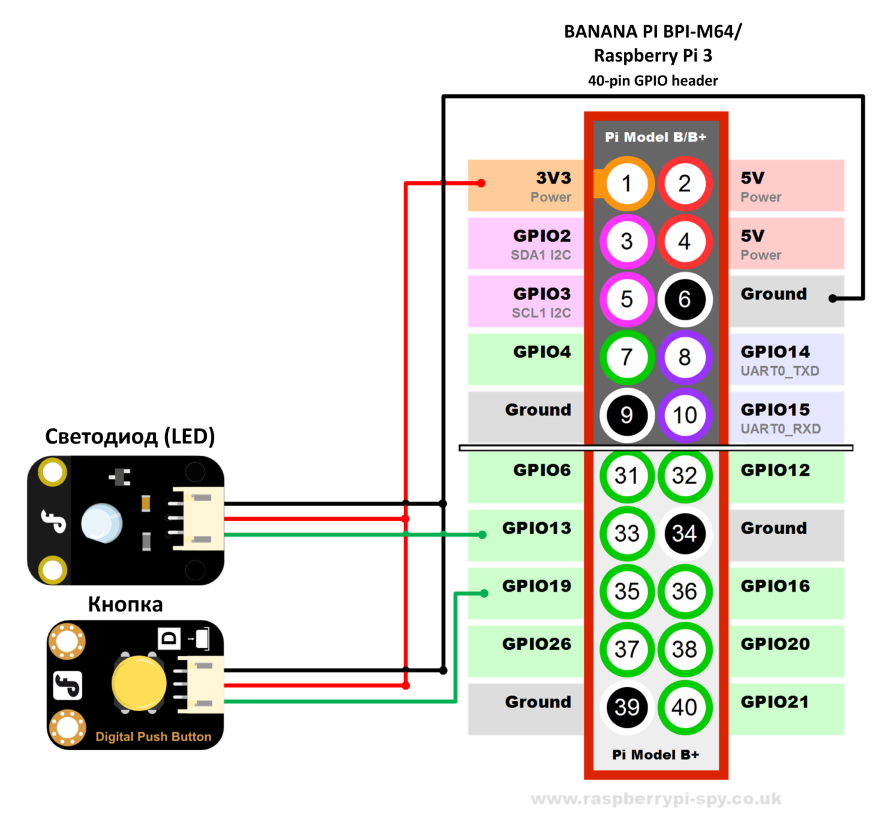 Схема подключения светодиода (LED) и кнопки к 40-контактному
разъему совместимый с Raspberry Pi 3
Схема подключения светодиода (LED) и кнопки к 40-контактному
разъему совместимый с Raspberry Pi 3
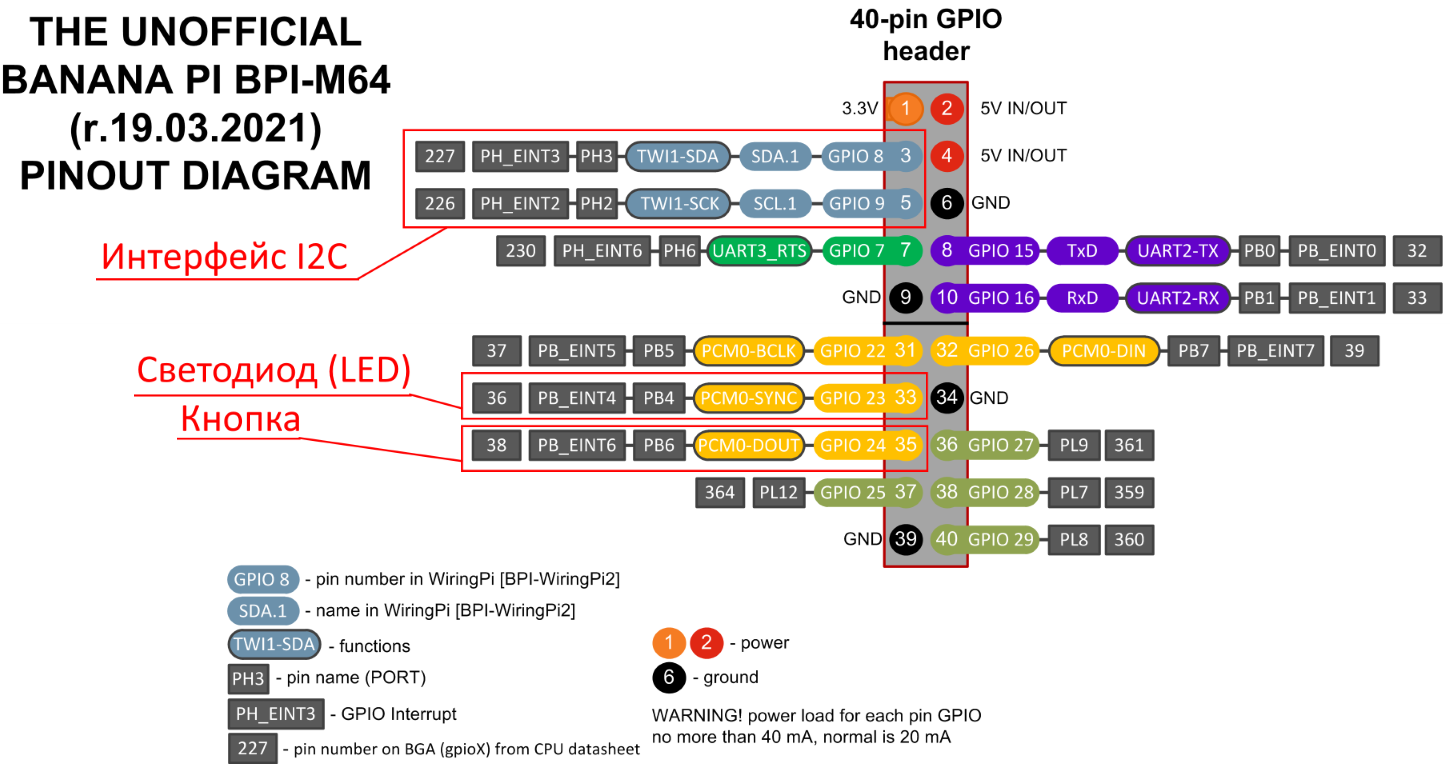 Схема назначения контактов к которым подключается светодиод
(LED) и кнопка
Схема назначения контактов к которым подключается светодиод
(LED) и кнопка
Интерфейс GPIO ядра Linux
GPIO (General-Purpose Input/Output) является одним
из наиболее часто используемых периферийных устройств во
встраиваемых системах (embedded system) Linux.
Во внутренней архитектуре ядро Linux реализует доступ к GPIO через
модель производитель/потребитель. Существуют драйверы, которые
предоставляют
доступ к линиям GPIO (драйверы контроллеров GPIO) и драйверы,
которые
используют линии GPIO (клавиатура, сенсорный экран, датчики и
т. д.).
В ядре Linux система
gpiolib занимается
регистрацией и распределением GPIO. Эта структура доступна через
API как для драйверов устройств, работающих в пространстве ядра
(kernel space), так и для приложений пользовательского пространства
(user space).
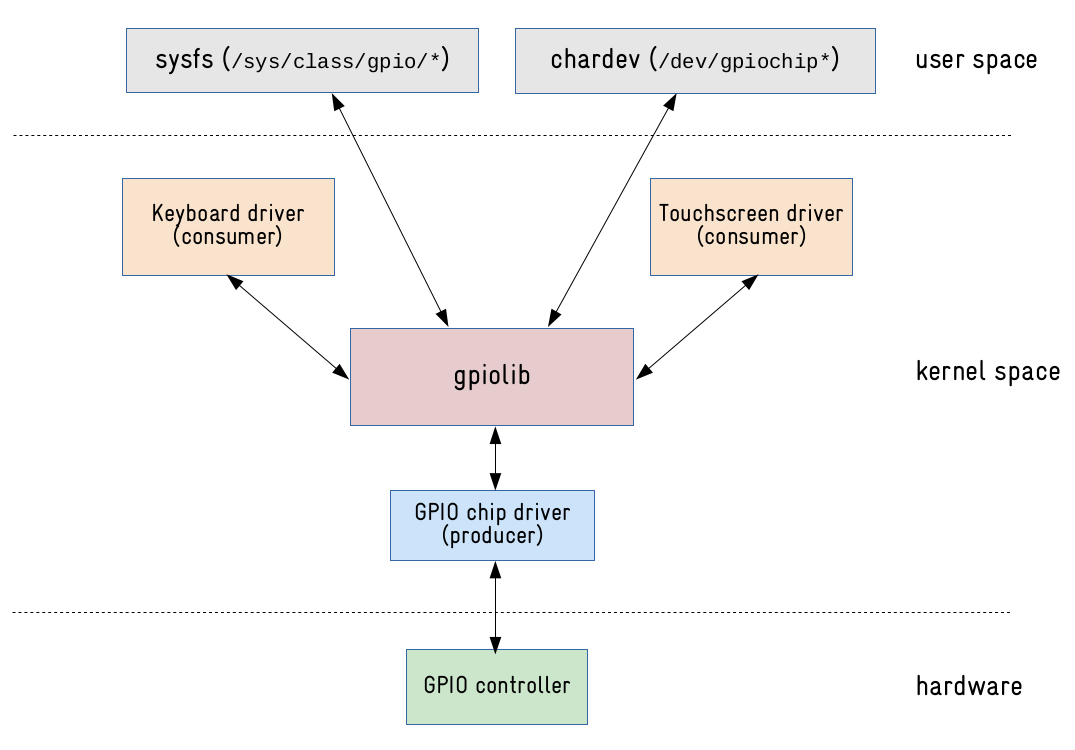 Схема работы gpiolib
Схема работы gpiolib
Старый путь: использование виртуальной файловой системы sysfs
для доступа к GPIO
До версии ядра Linux 4.7 для управления GPIO в пользовательском
пространстве использовался
интерфейс sysfs. Линии GPIO были доступны при экспорте по пути
/sys/class/gpio. Так, например, для подачи сигнала 0 или 1
на линию GPIO, необходимо:
- Определить номер линии (или номер ножки процессора) GPIO;
- Экспортировать номер GPIO, записав его номер в
/sys/class/gpio/export;
- Конфигурировать линию GPIO как вывод, указав это в
/sys/class/gpio/gpioX/direction;
- Установить значение 1 или 0 для линии GPIO
/sys/class/gpio/gpioX/value;
Для наглядности установим для линии GPIO 36 (подключен светодиод)
из пользовательского пространства, значение 1. Для этого необходимо
выполнить команды:
# echo 36 > /sys/class/gpio/export# echo out > /sys/class/gpio/gpio36/direction# echo 1 > /sys/class/gpio/gpio36/value
Этот подход очень простой как и интерфейс sysfs, он неплохо
работает, но имеет некоторые недостатки:
- Экспорт линии GPIO не связан с процессом, поэтому если процесс
использующий линию GPIO аварийно завершит свою работу, то эта линия
GPIO так и останется экспортированной;
- Учитываю первый пункт возможен совместный доступ к одной и той
же линии GPIO, что приведет к проблеме совместного доступа. Процесс
не может узнать у ОС используется ли та или иная линия GPIO в
настоящий момент;
- Для каждой линии GPIO приходится выполнять множество операций
open()/read()/write()/close(), а так же указывать параметры
(export, direction, value, и т.д.) используя методы работы с
файлами. Это усложняет программный код;
- Невозможно включить/выключить сразу несколько линий GPIO одним
вызовом;
- Процесс опроса для перехвата событий (прерываний от линий GPIO)
ненадежен;
- Нет единого интерфейса (API) для конфигурирования линий
GPIO;
- Номера, присвоенные линиям GPIO непостоянны, их приходится
каждый раз экспортировать;
- Низкая скорость работы с линиями GPIO;
Новый путь: интерфейс chardev
Начиная с ядра Linux версии 4.8 интерфейс GPIO
sysfs объявлен как
deprecated и
не рекомендуется к использованию. На замену sysfs появился новый
API, основанный на символьных устройствах для доступа к линиям GPIO
из пользовательского пространства.
Каждый контроллер GPIO
(gpiochip) будет иметь
символьное устройство в разделе
/dev, и мы можем
использовать файловые операции (open(), read(), write(), ioctl(),
poll(), close()) для управления и взаимодействия с линиями GPIO.
контроллеры GPIO доступны по путям
/dev/gpiochipN или
/sys/bus/gpiochipN, где N порядковый номер чипа. Просмотр
доступных контроллеров GPIO (gpiochip) на Banana Pi BPI-M64:
root@bananapim64:~# ls /dev/gpiochip*/dev/gpiochip0 /dev/gpiochip1 /dev/gpiochip2
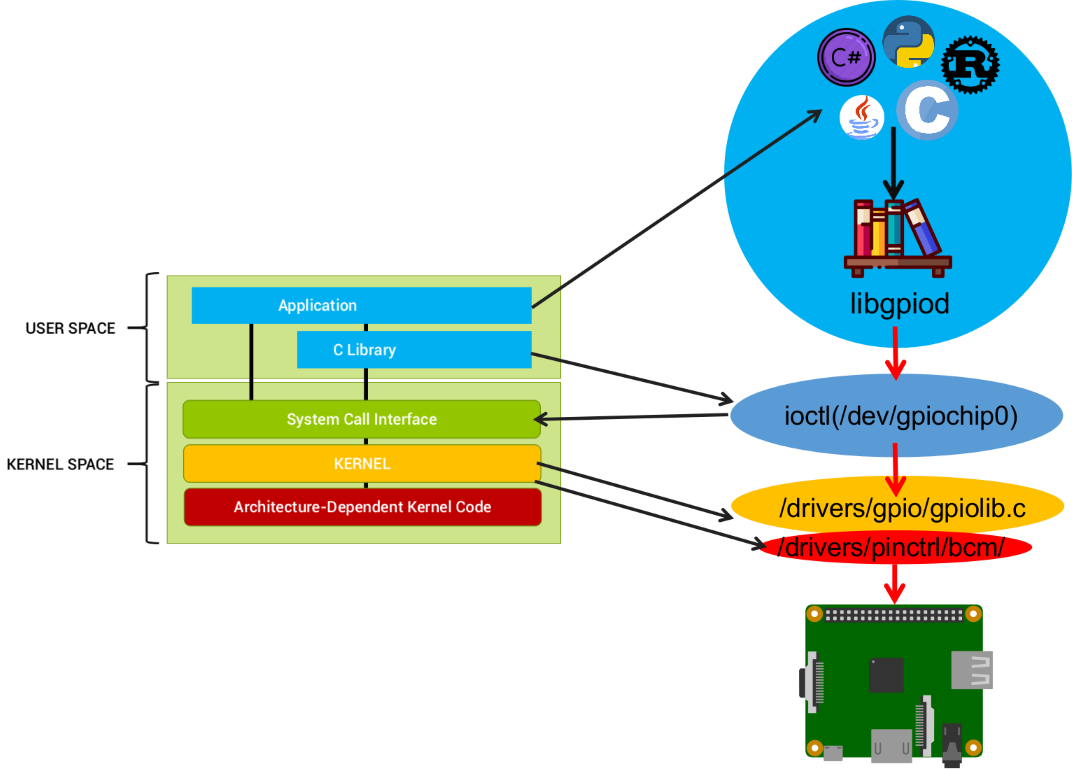 Стек работы библиотеки libgpiod
Стек работы библиотеки libgpiod
Несмотря на то, что новый API предотвращает управление линиями GPIO
с помощью стандартных инструментов командной строки, таких как
echo и
cat, он обладает весомыми
преимуществами по сравнению с интерфейсом sysfs, а именно:
- Выделение линий GPIO связано с процессом, который он его
использует. При завершение процесса, так же в случае аварийного
завершения, линии GPIO используемые процессом освобождаются
автоматически;
- Дополнительно, можно всегда определить какой процесс в данное
время использует определенную линию GPIO;
- Можно одновременно читать и писать в несколько линий GPIO
одновременно;
- Контроллеры GPIO и линии GPIO можно найти по названию;
- Можно настроить состояние вывода контакта (open-source,
open-drain и т. д.);
- Процесс опроса для перехвата событий (прерывания от линий GPIO)
надежен.
Библиотека libgpiod и инструменты управления GPIO
Для использования нового интерфейса символьного устройства есть
библиотека и набор инструментов, предоставляемых проектом
libgpiod.
Libgpiod(
Library
General
Purpose
Input/
Output
device)
предоставляет набор API для вызова из своих программ и несколько
утилит для управления линиями GPIO из пользовательского режима.
В состав
libgpiod входят следующие утилиты:
- gpiodetect выведет список всех чипов GPIO, их
метки и количество линий;
- gpioinfo выведет информацию о линиях GPIO
конкретного контроллера GPIO. В таблице вывода по колонкам будет
указано: номер линии, название контакта, направление ввода/вывода,
текущее состояние;
- gpioget считает текущее состояние линии
GPIO;
- gpioset установит значение для линии
GPIO;
- gpiofind выполняет поиск контроллера GPIO и
линии по имени;
- gpiomon осуществляет мониторинг состояния
линии GPIO и выводит значение при изменение состояния.
Например, следующая программа написанная на C использует
libgpiod для чтения строки GPIO:
void main() {struct gpiod_chip *chip;struct gpiod_line *line;int req, value;chip = gpiod_chip_open("/dev/gpiochip0");if (!chip)return -1;line = gpiod_chip_get_line(chip, 3);if (!line) {gpiod_chip_close(chip);return -1;}req = gpiod_line_request_input(line, "gpio_state");if (req) {gpiod_chip_close(chip);return -1;}value = gpiod_line_get_value(line);printf("GPIO value is: %d\n", value);gpiod_chip_close(chip);}
Библиотеку можно вызывать так же и из кода на
C++, Python,
C#, и т.д.
Для управления линиями GPIO из терминала необходимо использовать
инструменты командной строки, предоставляемые libgpiod. Библиотеку
libgpiod и инструменты управления GPIO можно установить
скомпилировать из исходного текста и установить.
Установка библиотеки libgpiod и инструментов управления
GPIO
Репозитарий библиотеки libgpiod доступ по адресу
libgpiod/libgpiod.git. В разделе
Download
опубликованы релизы библиотеки. На 28.04.2021 последний релиз:
v1.6.3.
Библиотеку libgpiod можно установить из репозитария дистрибутива,
но скорее всего будет доступна старая версия. Установка
libgpiod:
$ sudo apt-get update$ sudo apt-get install -y libgpiod-dev gpiod
Для установки последней актуальной версии необходимо выполнить
скрипт установки, который возьмет последнюю версию библиотеки из
исходного репозитария. В строке вызова скрипта установки
setup-libgpiod-arm64.sh, в качестве первого параметра
указать номер версии библиотеки (например: 1.6.3), второй параметр
(необязательный) папка установки скрипта. По умолчанию библиотека
установится по пути:
/usr/share/libgpiod.
Скрипт установки из исходного текста библиотеки libgpiod и утилит
для ARM32/ARM64:
$ cd ~/$ sudo apt-get update$ sudo apt-get install -y curl $ curl -SL --output setup-libgpiod-armv7-and-arm64.sh https://raw.githubusercontent.com/devdotnetorg/dotnet-libgpiod-linux/master/setup-libgpiod-armv7-and-arm64.sh$ chmod +x setup-libgpiod-armv7-and-arm64.sh$ sudo ./setup-libgpiod-armv7-and-arm64.sh 1.6.3
Для удаления библиотеки выполнить скрипт:
remove-libgpiod-armv7-and-arm64.sh
Если по итогу выполнения скрипта появится надпись
Successfully, то значит библиотека и утилиты
успешно установлены. Дополнительно для проверки, можно вызвать
команду с выводом номера версии библиотеки:
root@bananapim64:~# gpiodetect -vgpiodetect (libgpiod) v1.6.3Copyright (C) 2017-2018 Bartosz GolaszewskiLicense: LGPLv2.1This is free software: you are free to change and redistribute it.There is NO WARRANTY, to the extent permitted by law.
Инструменты библиотеки libgpiod
Команда
gpiodetect выведет список всех чипов GPIO,
их метки и количество линий. Результат выполнения команды:
root@bananapim64:~# gpiodetectgpiochip0 [1f02c00.pinctrl] (32 lines)gpiochip1 [1c20800.pinctrl] (256 lines)gpiochip2 [axp20x-gpio] (2 lines)
gpiochip0 и
gpiochip1, это чипы входящие в состав
SoC Allwinner A64.
gpiochip1 имеет выход на 40-контактный
разъем совместимый с Raspberry Pi. Чип
gpiochip2 отдельная
микросхема управления электропитанием axp209 подключенная по
интерфейсу I2C.
Для вывод справки к вызываемой команде необходимо добавлять
параметр
"--help". Вызов справки для команды
gpiodetect. Результат выполнения команды:
root@bananapim64:~# gpiodetect --helpUsage: gpiodetect [OPTIONS]List all GPIO chips, print their labels and number of GPIO lines.Options: -h, --help: display this message and exit -v, --version: display the version and exit
Команда
gpioinfo выведет информацию о линиях GPIO
конкретного контроллера GPIO (или всех контроллеров GPIO, если они
не указаны).Результат выполнения команды:
root@bananapim64:~# gpioinfo 1gpiochip1 - 256 lines: line 0: unnamed unused input active-high... line 64: unnamed "dc" output active-high [used]... line 68: unnamed "backlightlcdtft" output active-high [used]... line 96: unnamed "spi0 CS0" output active-low [used] line 97: unnamed unused input active-high line 98: unnamed unused input active-high line 99: unnamed unused input active-high line 100: unnamed "reset" output active-low [used]... line 120: unnamed "bananapi-m64:red:pwr" output active-high [used]... line 254: unnamed unused input active-high line 255: unnamed unused input active-high
В таблице по колонкам указано: номер линии, название контакта,
направление ввода/вывода, текущее состояние. Сейчас к Banana Pi
BPI-M64 подключен
LCD экран ILI9341 на SPI интерфейсе, для
подключения используется вариант с управляемой подсветкой, файл DTS
sun50i-a64-spi-ili9341-backlight-on-off.dts. В DTS файле
контакт PC4 GPIO68 обозначен для управления подсветкой, название
backlightlcdtft. Соответственно в выводе команды, указан номер
линии 68, название backlightlcdtft, направление вывод, текущее
состояние active-high (включено).
Команда
gpioset установит значение для линии GPIO.
Например, следующая команда попытается выключить подсветку на LCD
ILI9341. Команда:
gpioset 1 68=0, где 1 gpiochip1, 68 номер
линии(контакта), 0 логическое значение, может быть 0 или 1.
Результат выполнения команды:
root@bananapim64:~# gpioset 1 68=0gpioset: error setting the GPIO line values: Device or resource busyroot@bananapim64:~#
В результате мы получим ошибку линия занята, т.к. данная линия
занята драйвером
gpio-backlight.
Попробуем включить светодиод на линии 36, название PB4, номер
контакта на 40-контактном разъеме (совместимый с Raspberry Pi) 33.
Результат выполнения команды:
root@bananapim64:~# gpioset 1 36=1
В результате выполнения команды, светодиод включится.
Команда
gpioget считывает текущее состояние линии
GPIO. Результат выполнения команды:
root@bananapim64:~# gpioget 1 361
Получили значение 1, т.к. до этого включили светодиод командой
gpioset.
Команда
gpiomon будет осуществлять мониторинг
состояния линии GPIO и выводить значение при изменение состояния.
Будем мониторить состояние кнопки, которая подключена на линию 38,
название PB4, номер контакта на 40-контактном разъеме (совместимый
с Raspberry Pi) 35. Команда:
gpiomon 1 38, где 1 gpiochip1,
38 номер линии (контакта). Результат выполнения команды:
root@bananapim64:~# gpiomon 1 38event: RISING EDGE offset: 38 timestamp: [ 122.943878429]event: FALLING EDGE offset: 38 timestamp: [ 132.286218099]event: RISING EDGE offset: 38 timestamp: [ 137.639045559]event: FALLING EDGE offset: 38 timestamp: [ 138.917400584]
Кнопка несколько раз нажималась.
RISING повышение,
изменение напряжения с 0V до 3.3V, кнопка нажата и удерживается
состояние.
FALLING понижение, изменение напряжения
с 3.3V до 0V, происходит отпускание кнопки, и кнопка переходит в
состояние не нажата.
С механической кнопкой возникла проблема из-за дребезга контакта,
регистрировались множественные нажатия вместо одного. Поэтому
механическая кнопка была заменена на емкостную (touch) кнопку.
Установка .NET 5.0 для ARM
Одно из лучших нововведений в .NET 5.0 стало увеличение
производительности для архитектуры ARM64. Поэтому переход на новую
версию не только увеличит производительность решения на базе ARM64,
но и увеличит время автономной работы в случае использования
аккумуляторной батареи.
Определение архитектуры ARM32 и ARM64 для SoC
.NET 5 устанавливается на одноплатный компьютер в соответствие с
архитектурой SoC:
- ARM32, ARMv7, aarch32, armhf 32-разрядная
архитектура ARM. Первые процессоры ARM для встраиваемых систем
разрабатывались именно на этой архитектуре. По заявлению компании
ARM Holding, в 2022 поддержка 32-битных платформ
прекратится, и будет поддерживаться только 64-битная архитектура.
Это означает, что компания не будет поддерживать разработку ПО для
32-битных систем. Если конечный производитель устройства пожелает
установить 32-битную ОС, то ему придется самостоятельно заняться
портированием драйверов с 64-битной архитектуры на 32-битную.
- ARM64, ARMv8, aarch64 64-разрядная архитектура
ARM. Ядра Cortex-A53 и Cortex-A57, поддерживающие ARMv8, были
представлены компанией ARM Holding 30 октября 2012 года.
Плата
Banana Pi BPI-M64 построена на основе
процессора
Allwinner A64, содержит в себе
64-битные ядра Cortex-A53, поэтому поддерживает 64-разрядные
приложения. Для платы
Banana Pi BPI-M64
используется 64-разрядный образ ОС Armbian, поэтому на плату будем
устанавливать
.NET для 64-разрядных систем
ARM.
Плата
Cubietruck построена на основе процессора
Allwinner A20 содержит в себе 32-битные ядра
Cortex-A7, поэтому поддерживает только 32-разрядные приложения.
Соответственно на плату устанавливается
.NET для
32-разрядных систем.
Если вы не знаете какую версию .NET установить на одноплатный
компьютер, то необходимо выполнить команду для получения информации
об архитектуре системы:
uname -m.
Выполним команду на Banana Pi BPI-M64:
root@bananapim64:~# uname -maarch64
Строка
aarch64 говорит о 64-разрядной архитектуре
ARM64, ARMv8, aarch64, поэтому установка
.NET для 64-х
разрядных ARM систем.
Выполним команду на Cubietruck:
root@cubietruck:~# uname -marmv7l
Строка
armv7l говорит о 32-разрядной архитектуре
ARM32, ARMv7, aarch32, armhf, поэтому установка
.NET для
32-разрядных ARM систем.
Редакции .NET 5.0 на ARM
.NET 5.0 можно устанавливать в трех редакциях:
- .NET Runtime содержит только компоненты,
необходимые для запуска консольного приложения.
- ASP.NET Core Runtime предназначен для запуска
ASP.NET Core приложений, так же включает в себя .NET Runtime для
запуска консольных приложений.
- SDK включает в себя .NET Runtime, ASP.NET Core
Runtime и .NET Desktop Runtime. Позволяет кроме запуска приложений,
компилировать исходный код на языках C# 9.0, F# 5.0, Visual Basic
15.9.
Для запуска .NET программ достаточно установки редакции
.NET Runtime, т.к. компиляция проекта будет на
компьютере x86.
Загрузить .NET с сайта Microsoft можно по ссылке
Download .NET 5.0.
Установка .NET Runtime
На странице
Download .NET 5.0. можно узнать текущую актуальную версию .NET.
В первой колонке
Release information будет указана
версия: v5.0.5 Released 2021-04-06. Версия номер:
5.0.5. В случае выхода более новый версии .NET,
ниже в скрипте в строке
export
DOTNET_VERSION=5.0.5, нужно будет заменить номер версии на
последний. Выполним скрипт установки, в зависимости от разрядности
системы
ARM32 (Cubietruck) или
ARM64(Banana Pi BPI-M64):
ARM64
$ cd ~/$ apt-get update && apt-get install -y curl$ export DOTNET_VERSION=5.0.5$ curl -SL --output dotnet.tar.gz https://dotnetcli.azureedge.net/dotnet/Runtime/$DOTNET_VERSION/dotnet-runtime-$DOTNET_VERSION-linux-arm64.tar.gz \&& mkdir -p /usr/share/dotnet \&& tar -ozxf dotnet.tar.gz -C /usr/share/dotnet \&& rm dotnet.tar.gz$ ln -s /usr/share/dotnet/dotnet /usr/bin/dotnet
ARM32
$ cd ~/$ apt-get update && apt-get install -y curl$ export DOTNET_VERSION=5.0.5$ curl -SL --output dotnet.tar.gz https://dotnetcli.azureedge.net/dotnet/Runtime/$DOTNET_VERSION/dotnet-runtime-$DOTNET_VERSION-linux-arm.tar.gz \&& mkdir -p /usr/share/dotnet \&& tar -ozxf dotnet.tar.gz -C /usr/share/dotnet \&& rm dotnet.tar.gz$ ln -s /usr/share/dotnet/dotnet /usr/bin/dotnet
Проверим запуск .NET, командой (результат одинаков для Banana Pi
BPI-M64 и Cubietruck):
dotnet --info
root@bananapim64:~# dotnet --infoHost (useful for support): Version: 5.0.5 Commit: 2f740adc14.NET SDKs installed: No SDKs were found..NET runtimes installed: Microsoft.NETCore.App 5.0.5 [/usr/share/dotnet/shared/Microsoft.NETCore.App]To install additional .NET runtimes or SDKs: https://aka.ms/dotnet-download
.NET установлен в системе, для запуска приложений в Linux
необходимо воспользоваться командой:
dotnet
ConsoleApp1.dll
Обновление .NET 5.0
При выходе новых версий .NET необходимо сделать следующее:
- Удалить папку /usr/share/dotnet/
- Выполнить скрипт установки, указав новую версию .NET в строке
export: DOTNET_VERSION=5.0.5. Номер последней версии .NET можно
посмотреть на странице
Download .NET 5.0. Строку скрипта создания символической ссылки
выполнять не надо: ln -s /usr/share/dotnet/dotnet
/usr/bin/dotnet
Удаленная отладка приложения на .NET 5.0 в Visual Studio Code
для ARM
Удаленная отладка в
Visual Studio Code позволяет в интерактивном режиме видеть
ошибки и просматривать состояние переменных, без необходимости
постоянного ручного переноса приложения на одноплатный компьютер,
что существенно облегчает разработку. Бинарные файлы копируются в
автоматическом режиме с помощью утилиты
Rsync. Для
работы с GPIO, настройка удаленной отладки не является обязательной
задачей. Более подробно можно почитать в публикации
Удаленная отладка приложения на .NET 5.0 в Visual Studio Code для
ARM на примере Banana Pi BPI-M64 и Cubietruck (Armbian,
Linux).
Создание первого приложения для управления (вкл/выкл
светодиода) GPIO на C#, аналог утилиты gpioset
Поздравляю тебя %habrauser%! Мы уже подходим к финалу, осталось
буквально чуть-чуть. Разрабатывать и компилировать приложение будем
на x86 компьютере в в
Visual Studio Code. Находясь в этой точке, подразумевается, что
на одноплатном компьютере уже установлена платформа
.NET
5 и библиотека
Libgpiod, а на компьютере
x86 .NET 5 и Visual Studio Code. Итак приступаем:
Шаг 1 Создание приложения dotnet-gpioset
Действия выполняются на x86 компьютере. В командной строке создаем
проект с названием
dotnet-gpioset:
dotnet new
console -o dotnet-gpioset, где dotnet-gpioset название нового
проекта. Результат выполнения команды:
D:\Anton\Projects>dotnet new console -o dotnet-gpiosetGetting ready...The template "Console Application" was created successfully.Processing post-creation actions...Running 'dotnet restore' on dotnet-gpioset\dotnet-gpioset.csproj... Определение проектов для восстановления... Восстановлен D:\Anton\Projects\dotnet-gpioset\dotnet-gpioset.csproj (за 68 ms).Restore succeeded.
После выполнения команды будет создана папка
\Projects\dotnet-gpioset\, в этой папке будет расположен наш
проект: папка obj, файл программы Program.cs и файл проекта
dotnet-gpioset.csproj.
Шаг 2 Установка расширения C# for Visual Studio Code (powered
by OmniSharp) для Visual Studio Code
Запустим Visual Studio Code и установим расширение
C# for Visual Studio Code (powered by OmniSharp), для
возможности работы с кодом на C#. Для этого нажмем на закладке:
1. Extensions, затем
2. в поле ввода
напишем название расширения C# for Visual Studio Code,
выберем пункт
3. C# for Visual Studio Code (powered by
OmniSharp).
4. Перейдем на страницу описание
расширения и нажмем на кнопку
Install.
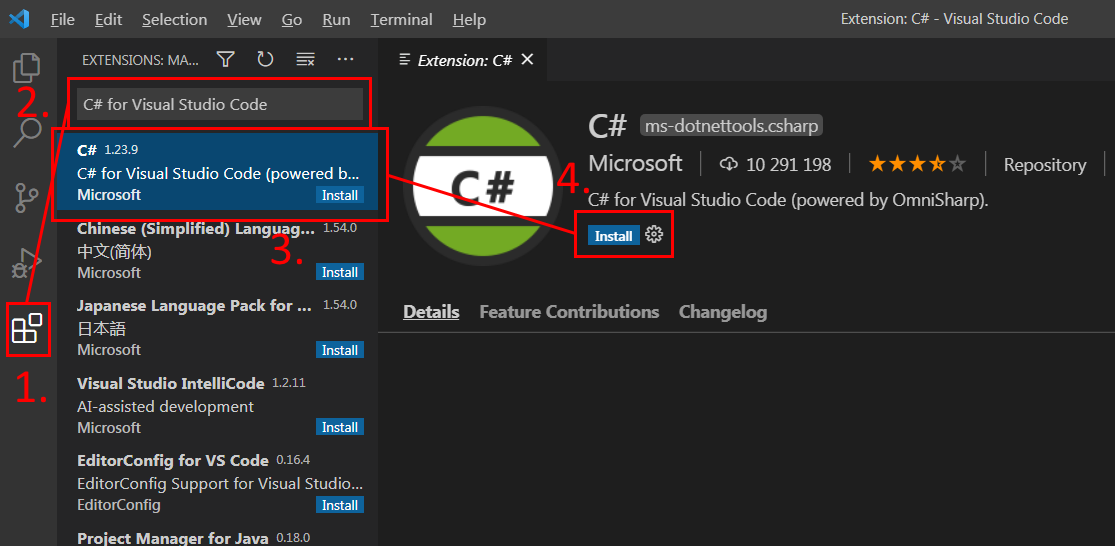 C# for Visual Studio Code (powered by OmniSharp)
C# for Visual Studio Code (powered by OmniSharp)
После установки можно выполнить настройку расширения.
 Настройка расширения C# for Visual Studio Code
Настройка расширения C# for Visual Studio Code
После установки расширения, перезапустим Visual Studio Code.
Шаг 3 Открытие проекта в Visual Studio Code и добавление NuGet
пакетов
Откроем проект в Visual Studio Code. Меню:
File
=>
Open Folder, и выберем папку с проектом
\Projects\dotnet-gpioset\
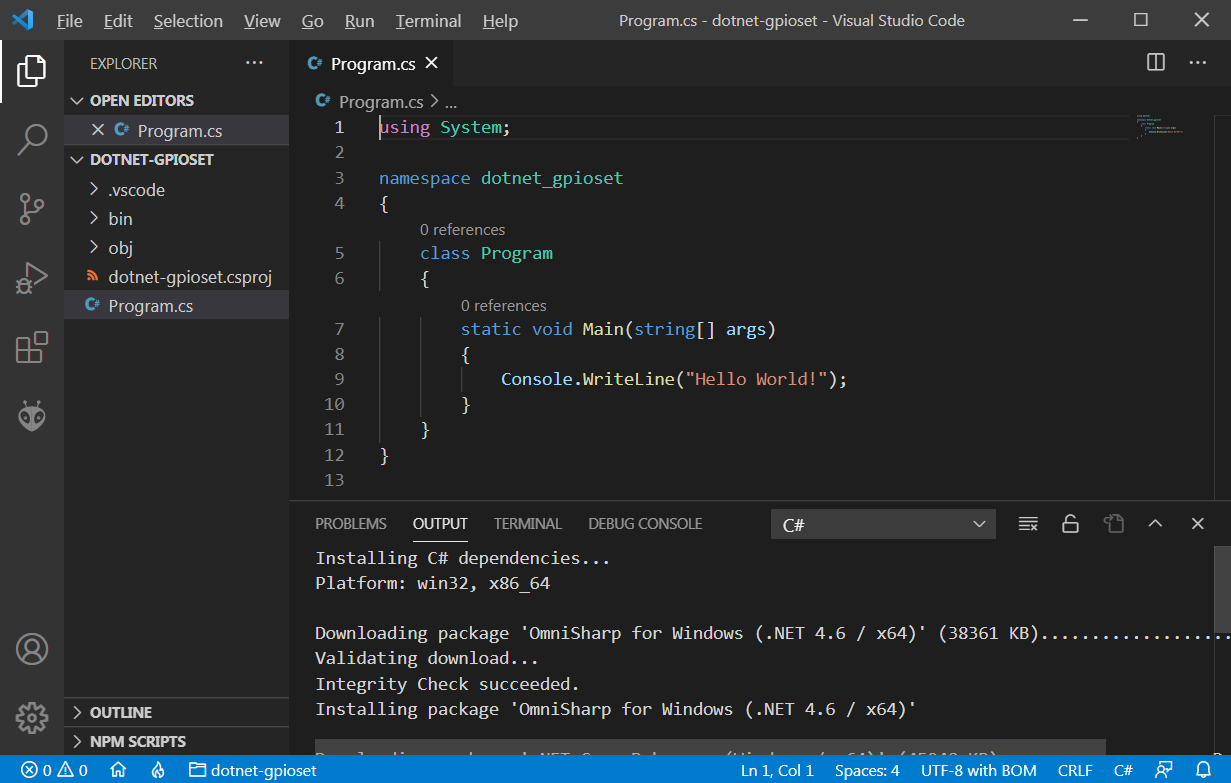 Проект в Visual Studio Code
Проект в Visual Studio Code
Откроем файл
dotnet-gpioset.csproj, убедимся что версия .NET
выставлена верно, должно быть следующее содержание:
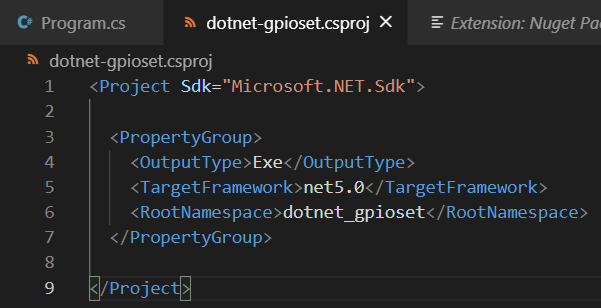 Содержание файла dotnet-gpioset.csproj
NuGet
Содержание файла dotnet-gpioset.csproj
NuGet пакеты можно добавить через командную строку
или расширение
NuGet Package Manager. Установим данное расширение, и добавим
пакеты:
Iot.Device.Bindings и
System.Device.Gpio. Для этого нажмем комбинацию
Ctrl+Shift+P, затем в поле введем:
Nuget, выберем
Nuget Packet Managet: Add
Package.
 Запуск расширения NuGet Package Manager
Запуск расширения NuGet Package Manager
В поле ввода укажем название пакета
Iot.Device.Bindings, нажмем
Enter, затем выберем версию
1.4.0
и нажмем
Enter. Так же сделать и для пакета
System.Device.Gpio. В результате добавление
пакетов, содержимое файла
dotnet-gpioset.csproj должно быть
следующим:
 Содержание файла dotnet-gpioset.csproj
Содержание файла dotnet-gpioset.csproj
Шаг 4 Добавление обработки аргументов в код
Утилита
dotnet-gpioset как и оригинальная
gpioset будет принимать на вход точно такие же
аргументы. Вызов:
dotnet-gpioset 1 36=1, включит светодиод
на gpiochipX 1, номер линии 36, значение 1. В режиме отладки будут
заданы значения по умолчанию int_gpiochip=1, int_pin=36, pin_value
= PinValue.High. Подключим пространство имен
System.Device.Gpio для использование структуры
PinValue.
Обработка входящих аргументов:
static void Main(string[] args){ //run: dotnet-gpioset 1 36=1 //----------------------------------------------- int? int_gpiochip=null,int_pin=null; PinValue? pin_value=null; #if DEBUG Console.WriteLine("Debug version"); int_gpiochip=1; int_pin=36; pin_value = PinValue.High; #endif if (args.Length==2) { //Read args if (int.TryParse(args[0], out int output)) int_gpiochip = output; Regex r = new Regex(@"\d+=\d+");//36=1 if (r.IsMatch(args[1])) //check: 36=1 { var i = args[1].Split("="); if (int.TryParse(i[0], out output)) int_pin = output; if (int.TryParse(i[1], out output)) { pin_value=(output != 0) ? PinValue.High : PinValue.Low; } } } Console.WriteLine($"Args gpiochip={int_gpiochip}, pin={int_pin}, value={pin_value}"); //next code Console.WriteLine("Hello World!");}
Запускаем выполнение кода для проверки, меню
Run =>
Start Debugging, все работает отлично!
Загружено "C:\Program Files\dotnet\shared\Microsoft.NETCore.App\5.0.5\System.Text.Encoding.Extensions.dll". Загрузка символов пропущена. Модуль оптимизирован, включен параметр отладчика "Только мой код".Debug versionArgs gpiochip=1, pin=36, value=HighHello World!Программа "[8528] dotnet-gpioset.dll" завершилась с кодом 0 (0x0).
Шаг 5 Добавление контроллера управления GPIO c драйвером
LibGpiodDriver
Для управления GPIO необходимо создать объект
GpioController и указать драйвер
LibGpiodDriver, для этого добавим пространство
имен
System.Device.Gpio.Drivers.
Добавление контроллера:
//next codeGpioController controller;var drvGpio = new LibGpiodDriver(int_gpiochip.Value); controller = new GpioController(PinNumberingScheme.Logical, drvGpio);
Описание кода:
- GpioController класс контроллера для
управления контактами GPIO;
- LibGpiodDriver(int_gpiochip.Value) драйвер
обертки библиотеки Libgpiod, в качестве аргумента
указываем номер gpiochip;
- GpioController(PinNumberingScheme.Logical,
drvGpio) инициализация контроллера,
PinNumberingScheme.Logical формат указания
контактов. Есть два варианта, по названию контакта или по его
номеру. Но т.к. названия контактов не заданы, то обращение будет
только по номеру.
Шаг 6 Управление контактом GPIO
Добавление кода для задания значения контакту:
//set value if(!controller.IsPinOpen(int_pin.Value)) { controller.OpenPin(int_pin.Value,PinMode.Output); controller.Write(int_pin.Value,pin_value.Value); }
Описание кода:
- controller.IsPinOpen проверка открытия
контакта, может быть занят или недоступен;
- controller.OpenPin открытие контакта и задание
ему режима работы, PinMode.Output на вывод;
-
controller.Write(int_pin.Value,pin_value.Value)
выставление контакту int_pin значение
pin_value.
Шаг 7 Публикация для архитектуры ARM
Открыть командную строку, и перейти в папку
\Projects\dotnet-gpioset\.
Для ARM32 выполнить команду:
- параметр --runtime задает архитектуру
выполнения программы (берется из списка
Runtime Identifiers (RIDs));
- параметр --self-contained указывает на
необходимость добавление в каталог всех зависимых сборок .NET, при
выставление значение в False, копируются только
дополнительные сборки не входящие в .NET Runtime (в данном случае
будут скопированы сборки из дополнительных NuGet пакетов).
dotnet publish dotnet-gpioset.csproj --configuration Release --runtime linux-arm --self-contained false
Файлы для переноса на одноплатный компьютер будут в папке:
\Projects\dotnet-gpioset\bin\Release\net5.0\linux-arm\publish\.
Для ARM64 выполнить команду:
dotnet publish dotnet-gpioset.csproj --configuration Release --runtime linux-arm64 --self-contained false
Файлы для переноса на одноплатный компьютер будут в папке:
\Projects\dotnet-gpioset\bin\Release\net5.0\linux-arm64\publish\.
Шаг 8 Перенос папки \publish\
Содержимое папки
\publish\ необходимо перенести в домашний
каталог Linux пользователя на одноплатном компьютере. Это можно
сделать используя терминал
MobaXterm.
Шаг 9 Запуск dotnet-gpioset на одноплатном компьютере
Содержимое папки
\publish\ было скопировано в папку
/root/publish-dotnet-gpioset. Исполняемым файлом будет файл
с расширением *.dll. В самом начале,
светодиод был
подключен на контакт 33, 40-контактного разъема совместимого с
Raspberry P, название контакта PB4, номер линии
36. Поэтому в качестве аргумента номера контакта
указываем 36. Для запуска программы необходимо выполнить
команду:
dotnet dotnet-gpioset.dll 1 36=1
Результат выполнения команды:
root@bananapim64:~# cd /root/publish-dotnet-gpiosetroot@bananapim64:~/publish-dotnet-gpioset# dotnet dotnet-gpioset.dll 1 36=1Args gpiochip=1, pin=36, value=HighOK
Светодиод включился!

Проект доступен на
GitHub dotnet-gpioset.
Создание приложения обработки прерывания от кнопки
Теперь реализуем программу обработки прерываний от GPIO. Задача
будет заключаться в переключение светодиода по нажатию кнопки.
Первое нажатие кнопки включит светодиод, последующее, выключит
светодиод, и так до бесконечности. Программа основана на примере
Push button.
Светодиод подключен контакту с номером
36.
Кнопка подключена на контакт
с номером
38. Итак приступаем:
Шаг 1 Создание приложения dotnet-led-button
Действия выполняются на x86 компьютере. В командной строке создаем
проект с названием
dotnet-led-button:
dotnet
new console -o dotnet-led-button, где dotnet-led-button
название нового проекта.
D:\Anton\Projects>dotnet new console -o dotnet-led-buttonGetting ready...The template "Console Application" was created successfully.Processing post-creation actions...Running 'dotnet restore' on dotnet-led-button\dotnet-led-button.csproj... Определение проектов для восстановления... Восстановлен D:\Anton\Projects\dotnet-led-button\dotnet-led-button.csproj (за76 ms).Restore succeeded.
После выполнения команды будет создана папка с файлами проекта
\Projects\dotnet-led-button\.
Шаг 2 Открытие проекта в Visual Studio Code и добавление NuGet
пакетов
Точно так же, как и в предыдущем проекте добавим Nuget пакеты:
Iot.Device.Bindings и
System.Device.Gpio.
Шаг 3 Добавление контроллера управления GPIO c драйвером
LibGpiodDriver
Добавим контроллер для управления GPIO, и выставим режим работы
контактов:
private const int GPIOCHIP = 1;private const int LED_PIN = 36;private const int BUTTON_PIN = 38; private static PinValue ledPinValue = PinValue.Low; static void Main(string[] args){ GpioController controller; var drvGpio = new LibGpiodDriver(GPIOCHIP); controller = new GpioController(PinNumberingScheme.Logical, drvGpio); //set value if(!controller.IsPinOpen(LED_PIN)&&!controller.IsPinOpen(BUTTON_PIN)) { controller.OpenPin(LED_PIN,PinMode.Output); controller.OpenPin(BUTTON_PIN,PinMode.Input); } controller.Write(LED_PIN,ledPinValue); //LED OFF
Описание кода:
- controller.OpenPin(LED_PIN,PinMode.Output) -
открывает контакт светодиода, и выставляет режим работы на
вывод;
- controller.OpenPin(BUTTON_PIN,PinMode.Input) -
открывает контакт кнопки, и выставляет режим работы на ввод (сигнал
поступает от кнопки.
Шаг 4 Добавление обработки прерывания кнопки
Обработка прерывания реализуется путем добавление
Callback на изменение состояние контакта.
Callback регистрируется в контроллере GPIO:
controller.RegisterCallbackForPinValueChangedEvent(BUTTON_PIN,PinEventTypes.Rising,(o, e) => { ledPinValue=!ledPinValue; controller.Write(LED_PIN,ledPinValue); Console.WriteLine($"Press button, LED={ledPinValue}"); });
Описание кода:
- RegisterCallbackForPinValueChangedEvent
регистрация Callback на контакт BUTTON_PIN, будет
срабатывать при нажатие на кнопку Rising. Так же
доступно срабатывание на событие отпускание кнопки.
Шаг 5 Публикация для архитектуры ARM
Открыть командную строку, и перейти в папку
\Projects\dotnet-led-button\.
Для ARM32 выполнить команду:
dotnet publish dotnet-led-button.csproj --configuration Release --runtime linux-arm --self-contained false
Файлы для переноса на одноплатный компьютер будут в папке:
\Projects\dotnet-led-button\bin\Release\net5.0\linux-arm\publish\.
Для ARM64 выполнить команду:
dotnet publish dotnet-led-button.csproj --configuration Release --runtime linux-arm64 --self-contained false
Файлы для переноса на одноплатный компьютер будут в папке:
\Projects\dotnet-led-button\bin\Release\net5.0\linux-arm64\publish\.
Шаг 6 Перенос папки \publish\
Содержимое папки
\publish\ необходимо перенести в домашний
каталог Linux пользователя на одноплатном компьютере.
Шаг 7 Запуск dotnet-led-button на одноплатном компьютере
Содержимое папки
\publish\ было скопировано в папку
/root/publish-dotnet-led-button. Для запуска программы
необходимо выполнить команду:
dotnet dotnet-led-button.dll
Результат выполнения команды:
root@bananapim64:~/publish-dotnet-led-button# dotnet dotnet-led-button.dllCTRL+C to interrupt the read operation:Press any key, or 'X' to quit, or CTRL+C to interrupt the read operation:Press button, LED=LowPress button, LED=HighPress button, LED=LowPress button, LED=HighPress button, LED=Low
Кнопка работает!
Проект доступен на
GitHub dotnet-led-button.
Теперь поговорим о скорости
Замеры скорости управления GPIO на Banana Pi BPI-M64 не проводились
из-за отсутствия осциллографа. Но не так давно, пользователь
ZhangGaoxing
опубликовал результаты замеров скорости на
Orange
Pi Zero: ОС Armbian buster, ядро Linux 5.10.16, .NET 5.0.3.
Тест заключался в быстром переключение контакта GPIO с 0 на 1 и
наоборот, по сути осуществлялась генерация сигнала ШИМ (в Arduino
аналог SoftPWM). Чем больше частота, тем быстрее переключатся
контакт. Для замера был разработан проект
SunxiGpioDriver.GpioSpeed. ZhangGaoxing для доступа к контактам
разработал драйвер
SunxiDriver, который напрямую
обращается к регистрам памяти для управления GPIO. Код этого
драйвера так же можно адаптировать к любой плате, путем изменения
адресов регистров памяти из datasheet к процессору. Минус такого
подхода заключается в отсутствие контроля к GPIO со стороны ОС,
можно влезть в контакт используемой ОС и вызвать сбой работы.
Таблица замеров:
Результаты подтвердили, что самым медленным интерфейсом является
SysFs, и его не стоит использовать для серьезных проектов. wiringOP
является С оберткой доступа к GPIO. Непосредственно управление GPIO
из C кода существенно быстрее, чем из приложения на .NET, разница
скорости в ~13 раз. Это и есть плата за Runtime.
Итог
Управлять контактами GPIO в C# оказалось не сложнее чем на Arduino.
В отличие от Arduino в нашем распоряжение Linux с поддержкой
полноценной графики, звуком, и большими возможностями подключения
различной периферии. В далеком 2014 году с хабровчанином
prostosergik был
спор о целесообразности
использовании Raspberry Pi в качестве школьного звонка. Мною
был реализован подобный функционал на C# .NET Micro Framework,
отладочная плата FEZ Domino. С того времени многое что изменилось.
Сейчас вариант использования для подобных индивидуальных задач,
одноплатных компьютеров на Linux более оправдан, чем использование
микроконтроллера. Первое существенное изменение это .NET теперь
работает на Linux нативно. Второе появились библиотеки которые
упрощают и скрывают под капотом все сложную работу. Третье цена,
сейчас одноплатный компьютер с 256 Мб ОЗУ, Ethernet и Wi-Fi в
известном китайском магазине можно приобрести за 18$. За такие
деньги МК, с поддержкой полноценного Web-интерфейса и шифрования
сетевого трафика, вряд ли найдешь. Платформа .NET IoT позволяет
работать с GPIO на достаточно высоком уровне абстракции, что
существенно снижает порог вхождения. В результате любой разработчик
.NET платформы, может с легкостью реализовать свое решение для IoT
не вдаваясь в детали как это работает внутри. Установка платформы
.NET и библиотеки Libgpiod было приведено для понимания, как это
работает, но такой подход не является самым удобным. Гораздо
удобнее все разворачивать в Docker контейнере, тем более это
mainstream для Linux. В продолжении посмотрим как упаковывать
приложение на C# вместе с .NET 5 и Libgpiod в один контейнер, для
дальнейшей удобной дистрибьюции нашего решения потенциальному
клиенту, задействуем LCD для вывода информации из .NET кода.
На правах рекламы
Прямо сейчас вы можете заказать
мощные серверы, которые используют новейшие процессоры
AMD
Epyc. Гибкие тарифы от 1 ядра CPU до безумных 128 ядер CPU, 512
ГБ RAM, 4000 ГБ NVMe.
Подписывайтесь на
наш чат в
Telegram.






































































 Результаты тестов в Geekbench мобильных
процессоров ARM
Результаты тестов в Geekbench мобильных
процессоров ARM
 64-битное ядро Cyclone
64-битное ядро Cyclone
 Спроектированные в 2012-м году Apple Swift
стали большим шагом вперёд
Спроектированные в 2012-м году Apple Swift
стали большим шагом вперёд





















































 <картинка с платой и наушниками>
<картинка с платой и наушниками>