Перевод подготовлен в рамках курса "Machine
Learning. Basic".
Всех желающих приглашаем на открытый онлайн-интенсив Data Science
это проще, чем кажется. Поговорим об истории и
основных вехах в развитии ИИ, вы узнаете, какие задачи решает DS и
чем занимается ML. И уже на первом занятии вы
сможете научить компьютер определять, что изображено на картинке. А
именно, вы попробуете обучить свою первую модель машинного обучения
для решения задачи классификации изображений. Поверьте, это проще,
чем кажется!
Не знаете, какой инструмент визуализации использовать? В этой
статье мы подробно расскажем о плюсах и минусах каждой
библиотеки.
Это руководство было дополнено несколькими подробными
примерами. Вы также можете отслеживать актуальные версии этой
статьи
здесь.
Мотивация
Если вы только собираетесь начать работу с визуализацией в
Python, количество библиотек и решений вас определенно поразит:
Но какую из этих библиотек лучше выбрать для визуализации
DataFrame? Некоторые библиотеки имеют больше преимуществ для
использования в некоторых конкретных случаях. В этой статье
приведены плюсы и минусы каждой из них. Прочитав эту статью, вы
будете разбираться в функционале каждой библиотеки и будете
способны подбирать для ваших потребностей оптимальную.
Мы будем использовать один и тот же набор данных, на примере
которого будем рассматривать каждую библиотеку, уделяя особое
внимание нескольким показателям:
Интерактивность
Хотите ли вы, чтобы ваша визуализация была интерактивной?
Визуализация в некоторых библиотеках, таких как Matplotlib,
является простым статичным изображением, что хорошо подходит для
объяснения концепций (в документе, на слайдах или в
презентации).
Другие библиотеки, такие как Altair, Bokeh и Plotly, позволяют
создавать интерактивные графики, которые пользователи могут
изучать, взаимодействуя с ними.
Синтаксис и гибкость
Чем отличается синтаксис каждой библиотеки? Библиотеки низкого
уровня, такие как Matplotlib, позволяют делать все, что вы
захотите, но за счет более сложного API. Некоторые библиотеки,
такие как Altair, очень декларативны, что упрощает
построение графиков по вашим данным.
Тип данных и визуализации
Приходилось ли вам сталкиваться в работе с нестандартными
юзкейсами, например, с географическим графиком, включающим большой
набор данных или с типом графика, который поддерживается только
определенной библиотекой?
Данные
Чтобы было проще сравнивать библиотеки, здесь представлены
реальные данные с Github из этой статьи:
I Scraped more than 1k Top Machine Learning Github Profiles and
this is what I Found

В статью включены визуализации из каждой библиотеки с помощью
Datapane, который представляет собой Python фреймворк и API для
публикации и совместного использования Python-отчетов. Больше
реальных примеров вы можете найти в пользовательских отчетах в
галереи
Datapane.
Вы можете скачать файл csv
здесь, либо получите данные напрямую из
Datapane Blob.
import datapane as dpdp.Blob.get(name='github_data', owner='khuyentran1401').download_df()
Не забудьте залогиниться со своим токеном авторизации в Datapane,
если вы хотите использовать Blob. Это займет менее минуты.
Matplotlib
Matplotlib,
вероятно, является самой популярной библиотекой Python для
визуализации данных. Все, кто интересуется data science, наверняка
хоть раз сталкивались с Matplotlib.
Плюсы
-
Четко отображены свойства данных
При анализе данных возможность быстро посмотреть распределение
может быть очень полезной.
Например, если я хочу быстро посмотреть распределение топ 100
пользователей с наибольшим количеством подписчиков, обычно
Matplotlib мне будет вполне достаточно:
import matplotlib.pyplot as plttop_followers = new_profile.sort_values(by='followers', axis=0, ascending=False)[:100]fig = plt.figure()plt.bar(top_followers.user_name, top_followers.followers)
Даже что-то вроде этого:
fig = plt.figure()plt.text(0.6, 0.7, "learning", size=40, rotation=20., ha="center", va="center", bbox=dict(boxstyle="round", ec=(1., 0.5, 0.5), fc=(1., 0.8, 0.8), ) )plt.text(0.55, 0.6, "machine", size=40, rotation=-25., ha="right", va="top", bbox=dict(boxstyle="square", ec=(1., 0.5, 0.5), fc=(1., 0.8, 0.8), ) )plt.show()
Минусы
Matplotlib может создать любой график, но с его помощью может
быть сложно построить или подогнать сложные графики, чтобы они
выглядели презентабельно.
Несмотря на то, что график достаточно хорошо подходит для
визуализации распределений, если вы хотите презентовать его
публике, вам нужно будет откорректировать оси X и Y, что потребует
больших усилий, потому что Matplotlib имеет чрезвычайно
низкоуровневый интерфейс.
correlation = new_profile.corr()fig, ax = plt.subplots()im = plt.imshow(correlation)ax.set_xticklabels(correlation.columns)ax.set_yticklabels(correlation.columns)plt.setp(ax.get_xticklabels(), rotation=45, ha="right", rotation_mode="anchor")
Вывод: с помощью Matplotlib можно создать что
угодно, но для сложных графиков может потребоваться гораздо больше
кода, чем другим библиотекам.
Seaborn
Seaborn
- это библиотека Python для визуализации данных, построенная на
базе Matplotlib. Она более высокоуровневая, что упрощает ее
использование.
Плюсы
-
Меньше кода
Предоставляет интерфейс более высокого уровня для построения
похожих графиков. Другими словами, seaborn обычно строит графики,
аналогичные matplotlib, но с меньшим количеством кода и более
красивым дизайном.
Мы используем те же данные, что и раньше, чтобы построить
аналогичный график пользовательской активности.
correlation = new_profile.corr()sns.heatmap(correlation, annot=True)
Мы получаем лучший график пользовательской активности без возни
x и y!
2. Делает стандартные графики красивее
Многие люди выбирают seaborn для создания широко используемых
графиков, таких как столбчатые и прямоугольные диаграммы, расчетные
графики, гистограммы и т. д., но не только потому, что это
потребует меньше кода, они еще и визуально приятнее. Как видно на
примере выше, цвета выглядят лучше, чем цвета по умолчанию в
Matplotlib.
sns.set(style="darkgrid")titanic = sns.load_dataset("titanic")ax = sns.countplot(x="class", data=titanic)
Минусы
Seaborn более ограничен и не имеет такой широкой коллекции
графиков, как matplotlib.
Вывод: Seaborn это версия Matplotlib более
высокого уровня. Несмотря на то, что коллекция графиков не
настолько большая, как в Matplotlib, созданные с помощью seaborn
широко используемые графики (например, столбчатая диаграмма,
прямоугольная диаграмма, график пользовательской активности и т.
д.), при меньшем количестве кода будет выглядеть визуально
приятнее.
Plotly
Python библиотека Plotly
упрощает создание интерактивных графиков типографского качества. Он
также может создавать диаграммы, аналогичные Matplotlib и seaborn,
такие как линейные графики, точечные диаграммы, диаграммы с
областями, столбчатые диаграммы и т. д.
Плюсы
-
Похож на R
Если вы поклонник графиков в R и вам не хватает его функционала
при переходе на Python, Plotly даст вам такое же качество графиков
с использованием Python!
Мой любимая версия -
Plotly Express, потому что с ней можно легко и
быстро создавать отличные графики одной строчкой в Python.
import plotly.express as pxfig = px.scatter(new_profile[:100], x='followers', y='total_stars', color='forks', size='contribution')fig.show()
2. Простота создания интерактивных графиков
Plotly также упрощает создание интерактивных графиков.
Интерактивные графики не только красиво выглядят, но и позволяют
публике более внимательно изучить каждую точку на графике.
Помните столбчатую диаграмму, которую мы показывали ранее в
matplotlib? Давайте посмотрим, как она получится с помощью
Plotly
import plotly.express as pxtop_followers = new_profile.sort_values(by='followers', axis=0, ascending=False)[:100]fig = px.bar(top_followers, x='user_name', y='followers', )fig.show()
Примерно за столько же строк кода мы создали интерактивный
график, на котором можно навести указатель мыши на каждый столбец,
чтобы увидеть, кому он принадлежит и сколько подписчиков у этого
пользователя. Это означает, что пользователь вашей визуализации
может изучить ее самостоятельно.
3. Легко делать сложные графики
С помощью Plotly достаточно легко создавать сложные графики.
Например, если мы хотим создать карту для визуализации
местоположения пользователей GitHub, мы можем найти широту и
долготу их расположения как показано
здесь, а затем использовать эти данные чтобы отметить
местоположение пользователей уже на карте:
import plotly.express as pximport datapane as dplocation_df = dp.Blob.get(name='location_df', owner='khuyentran1401').download_df()m = px.scatter_geo(location_df, lat='latitude', lon='longitude', color='total_stars', size='forks', hover_data=['user_name','followers'], title='Locations of Top Users')m.show()
И, написав всего несколько строк кода, местоположения всех
пользователей красиво представлены на карте. Цвет окружностей
представляет количество форков, а размер - общее количество
звезд.
Вывод: Plotly отлично подходит для создания
интерактивных и качественных графиков при помощи всего нескольких
строк кода.
Altair
Altair
- это библиотека Python декларативной статистической визуализации,
которая основана на vega-lite, что идеально подходит для графиков,
требующих большого количества статистических преобразований.
Плюсы
1. Простая грамматика визуализации
Грамматика, используемая для визуализации, невероятно проста для
понимания. Необходимо только обозначить связи между столбцами
данных и каналами их преобразования, а остальная часть построения
графиков обрабатывается автоматически. Это звучит довольно
абстрактно, но имеет решающее значение, когда вы работаете с
данными, и делает визуализацию информации очень быстрой и
интуитивно понятной.
Например, для данных о Титанике выше мы хотели бы подсчитать
количество людей в каждом классе. Все, что нам нужно, это
использовать count() в y_axis
import seaborn as snsimport altair as alt titanic = sns.load_dataset("titanic")alt.Chart(titanic).mark_bar().encode( alt.X('class'), y='count()')
2. Простота преобразования данных
Altair также упрощает преобразование данных при создании
диаграммы.
Например, мы хотим определить средний возраст каждого пола на
Титанике и вместо того, чтобы выполнять преобразование заранее, как
в Plotly, в Altair есть возможность выполнить преобразование в
коде, описывающем диаграмму.
hireable = alt.Chart(titanic).mark_bar().encode( x='sex:N', y='mean_age:Q').transform_aggregate( mean_age='mean(age)', groupby=['sex'])hireable
Логика здесь состоит в том, чтобы использовать
transform_aggregate() для взятия среднего значения
возраста (mean(age)) каждого пола
(groupby=['sex']) и сохранить его в переменной
mean_age). За ось Y мы берем переменную.
Мы также можем убедиться, что класс - это номинальные данные
(категорийные данные в произвольном порядке), используя
:N, или что mean_age - это количественные
данные (меры значений, такие как числа), используя
:Q.
Полный список преобразований данных можно найти
здесь.
3. Связывание нескольких графиков
Altair также позволяет создавать впечатляющие связи между
графиками, например, с возможностью использовать выбор интервала
для фильтрации содержимого прикрепленной гистограммы.
Например, мы хотим визуализировать количество людей из каждого
класса в пределах значений, ограниченных выделенным интервалом в
точечной диаграмме по возрасту и плате за проезд. Тогда нам нужно
написать что-то вроде этого:
brush = alt.selection(type='interval')points = alt.Chart(titanic).mark_point().encode( x='age:Q', y='fare:Q', color=alt.condition(brush, 'class:N', alt.value('lightgray'))).add_selection( brush)bars = alt.Chart(titanic).mark_bar().encode( y='class:N', color='class:N', x = 'count(class):Q').transform_filter( brush)points & bars
Когда мы перетаскиваем мышь, чтобы выбрать интервал на
корреляционной диаграмме, мы можем наблюдать изменения на
гистограмме ниже. В сочетании с преобразованиями и вычислениями,
сделанными ранее, это означает, что вы можете создавать несколько
чрезвычайно интерактивных графиков, которые выполняют вычисления на
лету - даже не требуя работающего сервера Python!
Минусы
Если вы не задаете пользовательский стиль, простые диаграммы,
такие как, например, столбчатые, не будут оформлены стилистически
так же хорошо, как в seaborn или Plotly. Altair также не
рекомендует использовать наборы данных с более чем 5000
экземплярами и рекомендует вместо этого агрегировать данные перед
визуализацией.
Вывод: Altair идеально подходит для создания
сложных графиков для отображения статистики. Altair не может
обрабатывать данные, превышающие 5000 экземпляров, и некоторые
простые диаграммы в нем уступают по стилю Plotly или Seaborn.
Bokeh
Bokeh - это интерактивная библиотека для визуализации,
предназначенная для презентации данных в браузерах.
Плюсы
-
Интерактивная версия Matplotlib
Если мы будем будем составлять топы интерактивных библиотек для
визуализации, Bokeh, вероятно, займет первое место в категории
сходства с Matplotlib.
Matplotlib позволяет создать любой график, так как эта
библиотека предназначена для визуализации на достаточно низком
уровне. Bokeh можно использовать как с высокоуровневым, так и
низкоуровневым интерфейсом; таким образом, она способна создавать
множество сложных графиков, которые создает Matplotlib, но с
меньшим количеством строк кода и более высоким разрешением.
Например, круговой график Matplotlib,
import matplotlib.pyplot as pltfig, ax = plt.subplots()x = [1, 2, 3, 4, 5]y = [2, 5, 8, 2, 7]for x,y in zip(x,y): ax.add_patch(plt.Circle((x, y), 0.5, edgecolor = "#f03b20",facecolor='#9ebcda', alpha=0.8))#Use adjustable='box-forced' to make the plot area square-shaped as well.ax.set_aspect('equal', adjustable='datalim')ax.set_xbound(3, 4)ax.plot() #Causes an autoscale update.plt.show()
который, в Bokeh, может быть создан с лучшим разрешением и
функциональностью:
from bokeh.io import output_file, showfrom bokeh.models import Circlefrom bokeh.plotting import figurereset_output()output_notebook()plot = figure(plot_width=400, plot_height=400, tools="tap", title="Select a circle")renderer = plot.circle([1, 2, 3, 4, 5], [2, 5, 8, 2, 7], size=50)selected_circle = Circle(fill_alpha=1, fill_color="firebrick", line_color=None)nonselected_circle = Circle(fill_alpha=0.2, fill_color="blue", line_color="firebrick")renderer.selection_glyph = selected_circlerenderer.nonselection_glyph = nonselected_circleshow(plot)
2. Связь между графиками
В Bokeh также можно достаточно просто связывать графики.
Изменение, примененное к одному графику, будет применено к другому
графику с этой же переменной.
Например, если мы создаем 3 графика рядом и хотим наблюдать их
взаимосвязь, мы можем связанное закрашивание
from bokeh.layouts import gridplot, rowfrom bokeh.models import ColumnDataSourcereset_output()output_notebook()source = ColumnDataSource(new_profile)TOOLS = "box_select,lasso_select,help"TOOLTIPS = [('user', '@user_name'), ('followers', '@followers'), ('following', '@following'), ('forks', '@forks'), ('contribution', '@contribution')]s1 = figure(tooltips=TOOLTIPS, plot_width=300, plot_height=300, title=None, tools=TOOLS)s1.circle(x='followers', y='following', source=source)s2 = figure(tooltips=TOOLTIPS, plot_width=300, plot_height=300, title=None, tools=TOOLS)s2.circle(x='followers', y='forks', source=source)s3 = figure(tooltips=TOOLTIPS, plot_width=300, plot_height=300, title=None, tools=TOOLS)s3.circle(x='followers', y='contribution', source=source)p = gridplot([[s1,s2,s3]])show(p)
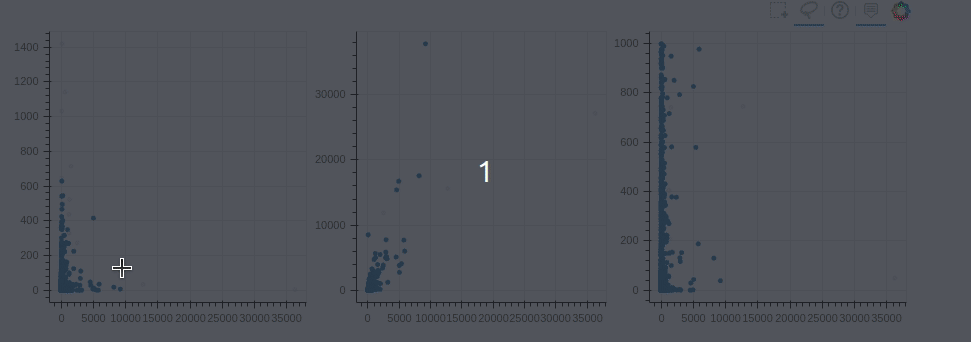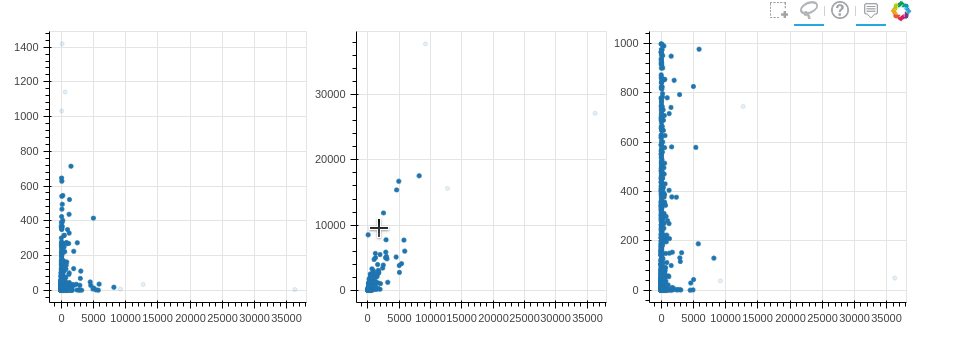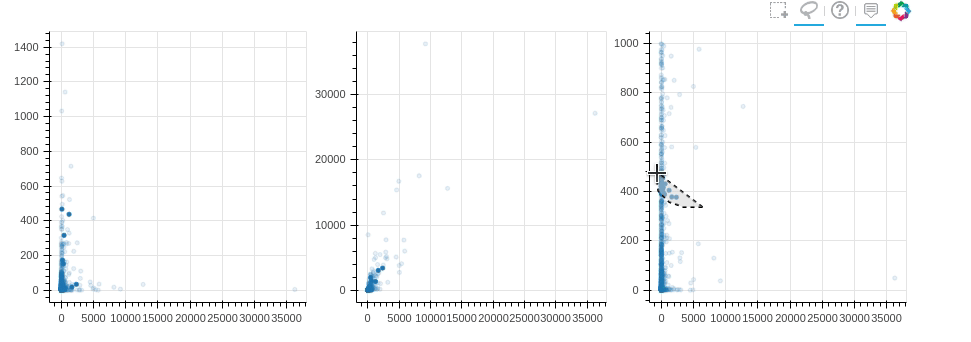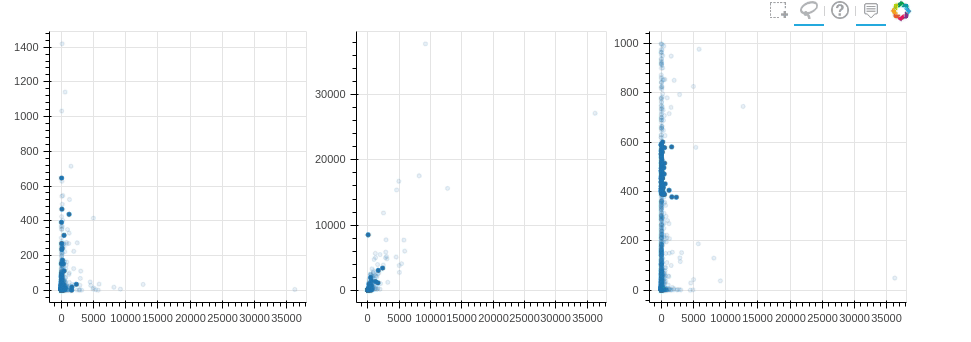
Минусы
Поскольку Bokeh - это библиотека, которая имеет интерфейс
среднего уровня, она часто требует меньше кода, чем Matplotlib, но
требует больше кода для создания того же графика, чем Seaborn,
Altair или Plotly.
Например, для создания такого же расчетного графика с данными с
Титаника, помимо преобразования данных заранее, мы также должны
установить ширину столбца и цвет если мы хотим, чтобы график
выглядел красиво.
Если мы не добавим ширину столбцов графика, то он будет
выглядеть так:
from bokeh.transform import factor_cmapfrom bokeh.palettes import Spectral6p = figure(x_range=list(titanic_groupby['class']))p.vbar(x='class', top='survived', source = titanic_groupby, fill_color=factor_cmap('class', palette=Spectral6, factors=list(titanic_groupby['class']) ))show(p)
Таким образом, нам нужно вручную настраивать параметры, чтобы
сделать график более красивым:
from bokeh.transform import factor_cmapfrom bokeh.palettes import Spectral6p = figure(x_range=list(titanic_groupby['class']))p.vbar(x='class', top='survived', width=0.9, source = titanic_groupby, fill_color=factor_cmap('class', palette=Spectral6, factors=list(titanic_groupby['class']) ))show(p)
Если вы хотите создать красивую столбчатую диаграмму, используя
меньшее количеством кода, то для вас это может быть недостатком
Bokeh по сравнению с другими библиотеками
Вывод: Bokeh - единственная библиотека, чей
интерфейс варьируется от низкого до высокого, что позволяет легко
создавать как универсальные, так и сложные графики. Однако цена
этого заключается в том, что для создания графиков с качеством,
аналогичным другим библиотекам, обычно требуется больше кода.
Folium
Folium позволяет легко визуализировать данные на
интерактивной встраиваемой карте. В библиотеке есть несколько
встроенных тайлсетов из OpenStreetMap, Mapbox и
Stamen
Плюсы
-
Очень легко создавать карты с маркерами
Несмотря на то, что Plotly, Altair и Bokeh также позволяют нам
создавать карты, Folium использует открытую уличную карту, что-то
близкое к Google Map, с помощью минимального количества кода
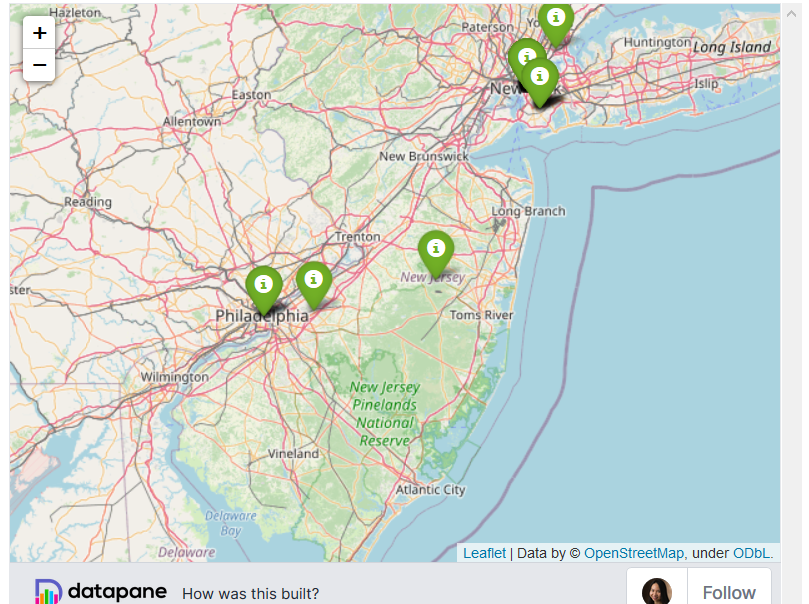
Помните, как мы создавали карту для визуализации местоположения
пользователей Github с помощью Plotly? Мы могли бы сделать карту
еще лучше с помощью Folium:
import folium# Load datalocation_df = dp.Blob.get(name='location_df', owner='khuyentran1401').download_df() # Save latitudes, longitudes, and locations' names in a listlats = location_df['latitude']lons = location_df['longitude']names = location_df['location']# Create a map with an initial locationm = folium.Map(location=[lats[0], lons[0]])for lat, lon, name in zip(lats, lons, names): # Create marker with other locations folium.Marker(location=[lat, lon], popup= name, icon=folium.Icon(color='green')).add_to(m) m

Живой вариант карты можно посмотреть в оригинале:
https://towardsdatascience.com/top-6-python-libraries-for-visualization-which-one-to-use-fe43381cd658
2. Добавление потенциального местоположения
Если мы хотим добавить потенциальные местоположения других
пользователей, Folium упрощает это, позволяя пользователям
добавлять маркеры:
# Code to generate map here#....# Enable adding more locations in the mapm = m.add_child(folium.ClickForMarker(popup='Potential Location'))
Живой вариант карты можно посмотреть в оригинале:
https://towardsdatascience.com/top-6-python-libraries-for-visualization-which-one-to-use-fe43381cd658
Кликните на карту, чтобы увидеть новое местоположение, созданное
прямо там, где вы кликнули.
3. Плагины
У Folium есть ряд плагинов, которые вы можете использовать со
своей картой, в том числе плагин для Altair. Что, если мы хотим
увидеть карту пользовательской активности общего количества
звездных пользователей Github в мире, чтобы определить, где
находится большое количество пользователей Github с большим
количеством звезд? Карта пользовательской активности в плагинах
Folium позволяет вам это сделать:
from folium.plugins import HeatMapm = folium.Map(location=[lats[0], lons[0]])HeatMap(data=location_df[['latitude', 'longitude', 'total_stars']]).add_to(m)
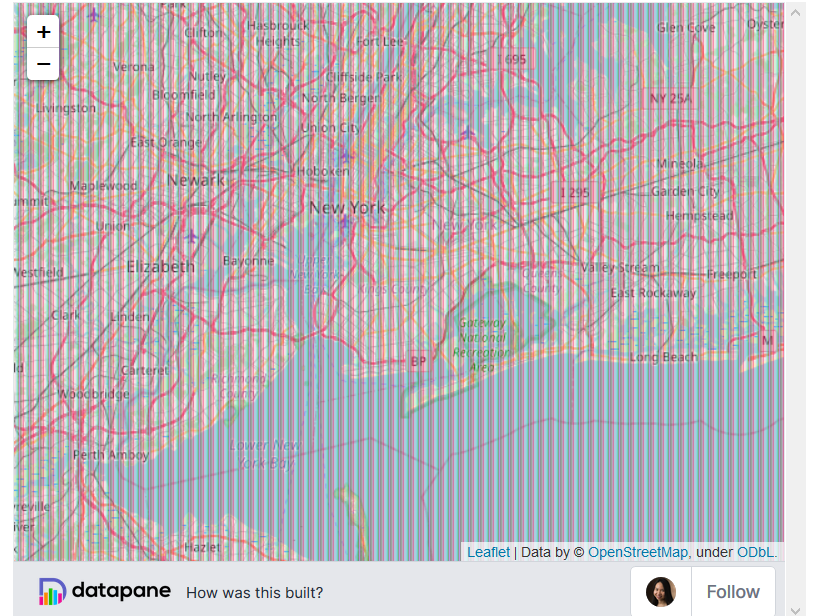
Живой вариант карты можно посмотреть в оригинале:
https://towardsdatascience.com/top-6-python-libraries-for-visualization-which-one-to-use-fe43381cd658
Уменьшите масштаб, чтобы увидеть полное отображение
пользовательской активности на карте.
Вывод: Folium позволяет создавать интерактивную
карту в несколько строк кода. Он дает вам ощущения близкие к
использованию Google Map.
Заключение
Поздравляем! Вы только что узнали о шести различных инструментах
визуализации. Я надеюсь, что эта статья даст вам представление о
возможностях каждой библиотеки и когда их лучше использовать.
Освоение ключевых функций каждой библиотеки позволит вам быстрее
определять нужную библиотеку для конкретной работы по мере
необходимости.
Если вы все еще не знаете, какую библиотеку использовать для
ваших данных, просто выберите ту, которая вам больше нравится.
Затем, если код слишком громоздкий или график не так хорош, как вы
думаете, просто попробуйте другую библиотеку!
Не стесняйтесь форкать и использовать код для этой статьи из
этого репозитория на Github.
Мне нравится писать об основных концепциях data science и
пробовать различные алгоритмы и инструменты анализа данных. Вы
можете связаться со мной в
LinkedIn и Twitter.
Отметьте
этот репозиторий, если хотите изучить код всех статей,
которые я писал. Следите за мной на Medium, чтобы быть в курсе моих
последних статей по data science.
Узнать подробнее о курсе "Machine
Learning. Basic"
Смотреть онлайн-интенсив Data Science
это проще, чем кажется


 Синяя линия - текущий гоод. Фиолетовая -
предыдущий. Пунктир - прогноз.
Синяя линия - текущий гоод. Фиолетовая -
предыдущий. Пунктир - прогноз.. Синяя линия - текущий год.") Прогнозирование по трем независимым
метрикам (пунктирные линии). Синяя линия - текущий год.
Прогнозирование по трем независимым
метрикам (пунктирные линии). Синяя линия - текущий год.

 Стандартный детектор DNN Face Detector
мог определить как лицо узор на занавеске, игрушечного медведя или
даже композицию из картин на стене и стула
Стандартный детектор DNN Face Detector
мог определить как лицо узор на занавеске, игрушечного медведя или
даже композицию из картин на стене и стула
 На всех трех кадрах родитель
присутствует, но по отдельному кадру найти его бывает непросто
На всех трех кадрах родитель
присутствует, но по отдельному кадру найти его бывает непросто
 На верхнем графике вероятность
присутствия родителя хотя бы плечом, а на нижнем вероятность того,
что родитель смотрит в камеру, например, общается с преподавателем
На верхнем графике вероятность
присутствия родителя хотя бы плечом, а на нижнем вероятность того,
что родитель смотрит в камеру, например, общается с преподавателем
 Пример аугментаций на одном изображении.
Для наглядности аугментации сделаны до масштабирования к разрешению
64х64Код для аугментаций
Пример аугментаций на одном изображении.
Для наглядности аугментации сделаны до масштабирования к разрешению
64х64Код для аугментаций
 Пример нормализации цвета на изображениях
из публичного датасетаКод для нормализации цвета
Пример нормализации цвета на изображениях
из публичного датасетаКод для нормализации цвета
 Качество на отложенной выборке растет по
мере увеличения выборки для дообучения
Качество на отложенной выборке растет по
мере увеличения выборки для дообучения
 Примеры изображений по запросам happy и unhappy
Примеры изображений по запросам happy и unhappy
 Примеры итоговых GIF с улыбками нашей
коллеги и ее детей
Примеры итоговых GIF с улыбками нашей
коллеги и ее детей
 Статистика дисконнектов. В этом уроке
был единственный дисконнект на стороне ученика
Статистика дисконнектов. В этом уроке
был единственный дисконнект на стороне ученика









 Папка проекта
Папка проекта

 Файл
логов
Файл
логов




























































 Образец
таблицы с информацией
Образец
таблицы с информацией
 Связь между
двумя столбцами
Связь между
двумя столбцами
 База данных NoSQL реального времени в Google Firebase
База данных NoSQL реального времени в Google Firebase
 pgAdmin4 на Mac
pgAdmin4 на Mac
 Создание новой базы данных для проекта
Создание новой базы данных для проекта
 Создание
таблицы пользователей
Создание
таблицы пользователей
 в pgAdmin") Инструмент запросов (Query Tool) в pgAdmin
Инструмент запросов (Query Tool) в pgAdmin


 Обновление записей
Обновление записей
 Удаление
записей из таблицы
Удаление
записей из таблицы
 Иллюстрация: UCI
Иллюстрация: UCI
 kdnuggets
kdnuggets


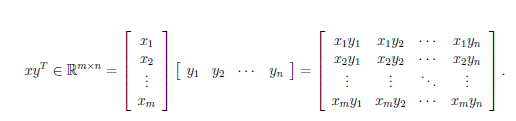
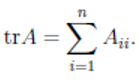
 TimoElliott
TimoElliott






 TimoElliott
TimoElliott

















 и мы считаем расстояние между точками, только одну из координат
заменили на время:
и мы считаем расстояние между точками, только одну из координат
заменили на время: Почему interaction это дробь?
Почему interaction это дробь?


 так как она убывает медленнее всего, значит позволит учитывать с
бОльшим весом влияние между клиентами, которые находятся друг от
друга далеко по времени или расстоянию, по сравнению с другими
функциями. Интуитивно, кажется, что даже "далекие" к друг другу
клиенты всё равно влияют на друг друга, поэтому мы и выбрали самую
медленно убывающую функцию.
так как она убывает медленнее всего, значит позволит учитывать с
бОльшим весом влияние между клиентами, которые находятся друг от
друга далеко по времени или расстоянию, по сравнению с другими
функциями. Интуитивно, кажется, что даже "далекие" к друг другу
клиенты всё равно влияют на друг друга, поэтому мы и выбрали самую
медленно убывающую функцию. , мы сравниваем между собой координаты
, мы сравниваем между собой координаты  и
и  , эти величины имеют одинаковый масштаб. В нашем случае мы
сравниваем метры и секунды. Поэтому чтобы они вносили одинаковый
вклад их необходимо привести к одному масштабу. Здесь мы поступили
очень просто и посмотрели на наших реальных данных отношение
среднего времени между заходами клиентов в приложение, к среднему
расстоянию между ними, и получили 1:16. Это соотношение и подставим
в наши
, эти величины имеют одинаковый масштаб. В нашем случае мы
сравниваем метры и секунды. Поэтому чтобы они вносили одинаковый
вклад их необходимо привести к одному масштабу. Здесь мы поступили
очень просто и посмотрели на наших реальных данных отношение
среднего времени между заходами клиентов в приложение, к среднему
расстоянию между ними, и получили 1:16. Это соотношение и подставим
в наши  при расчетах.
при расчетах.
 дисперсия выборки, а
дисперсия выборки, а  сколько Unit'ов у нас есть. При уменьшении периода переключения
или работе с более мелкими геозонами растет количество Unit'ов, с
которых мы собираем наблюдения. Но при этом растет и дисперсия
нашей выборки маленькие Unit'ы менее похожи друг на друга и
содержат больше выбросов. При увеличении сплита и, как следствие,
объема данных внутри него эти выбросы сглаживаются, дисперсия
снижается.
сколько Unit'ов у нас есть. При уменьшении периода переключения
или работе с более мелкими геозонами растет количество Unit'ов, с
которых мы собираем наблюдения. Но при этом растет и дисперсия
нашей выборки маленькие Unit'ы менее похожи друг на друга и
содержат больше выбросов. При увеличении сплита и, как следствие,
объема данных внутри него эти выбросы сглаживаются, дисперсия
снижается.





