Предыдущий пост см. здесь.
Проверка статистических гипотез
Для статистиков и исследователей данных проверка статистической
гипотезы представляет собой формальную процедуру. Стандартный
подход к проверке статистической гипотезы подразумевает определение
области исследования, принятие решения в отношении того, какие
переменные необходимы для измерения предмета изучения, и затем
выдвижение двух конкурирующих гипотез. Во избежание рассмотрения
только тех данных, которые подтверждают наши субъективные оценки,
исследователи четко констатируют свою гипотезу заранее. Затем,
основываясь на данных, они применяют выборочные статистики с целью
подтвердить либо отклонить эту гипотезу.
Проверка статистической гипотезы подразумевает использование
тестовой статистики, т.е. выборочной величины, как функции от
результатов наблюдений. Тестовая статистика (test statistic) - это
вычисленная из выборочных данных величина, которая используется для
оценивания прочности данных, подтверждающих нулевую статистическую
гипотезу и служит для выявления меры расхождения между
эмпирическими и гипотетическими значениями. Конкретные методы
проверки называются тестами, например, z-тест, t-тест
(соответственно z-тест Фишера, t-тест Студента) и т.д. в
зависимости от применяемых в них тестовых статистик.
Примечание. В отечественной статистической
науке используется туманный термин статистика критерия. Туманный
потому здесь мы снова наблюдаем мягкую подмену: вместо теста
возникает критерий. Если уж на то пошло, то критерий - это принцип
или правило. Например, выполняя z-тест, t-тест и т.д., мы
соответственно используем z-статистику, t-статистику и т.д. в
правиле отклонения гипотезы. Это хорошо резюмируется
следующей ниже таблицей:
|
Тестирование гипотезы
|
Тестовая статистика
|
Правило, или критерий, отклонения
гипотезы
|
|
z-тесты
|
z-статистика
|
Если тестовая статистика z или -z, то отклонить нулевую гипотезу
H0.
|
|
t-тесты
|
t-статистика
|
Если тестовая статистика t или -t, то отклонить нулевую гипотезу
H0.
|
|
Анализ дисперсии (ANOVA)
|
F-статистика
|
Если тестовая статистика F, то отклонить нулевую гипотезу
H0.
|
|
Тесты хи-квадрат
|
Статистика хи-квадрат
|
Если тестовая статистика , то отклонить нулевую гипотезу
H0.
|
Для того, чтобы помочь сохранить поток посетителей веб-сайта,
дизайнеры приступают к работе над вариантом веб-сайта с
использованием всех новейших методов по поддержанию внимания
аудитории. Мы хотели бы удостовериться, что наши усилия не
напрасны, и поэтому стараемся увеличить время пребывания
посетителей на обновленном веб-сайте.
Отсюда главный вопрос нашего исследования состоит в том,
приводит ли обновленный вид веб-сайта к увеличению времени
пребывания на нем посетителей? Мы принимаем решение проверить его
относительно среднего значения времени пребывания. Теперь, мы
должны изложить две наши гипотезы. По традиции считается, что
изучаемые данные не содержат того, что исследователь ищет. Таким
образом, консервативное мнение заключается в том, что данные не
покажут ничего необычного. Все это называется нулевой
гипотезой и обычно обозначается как
H0.
При тестировании статистической гипотезы исходят из того,
что нулевая гипотеза является истинной до тех пор, пока вес
представленных данных, подтверждающих обратное, не сделает ее
неправдоподобной. Этот подход к поиску доказательств в обратную
сторону частично вытекает из простого психологического факта, что,
когда люди пускаются на поиски чего-либо, они, как правило, это
находят.
Затем исследователь формулирует альтернативную гипотезу,
обозначаемую как H1. Она может попросту
заключаться в том, что популяционное среднее отличается от базового
уровня. Или же, что популяционное среднее больше или меньше
базового уровня, либо больше или меньше на некоторую указанную
величину. Мы хотели бы проверить, не увеличивает ли обновленный
дизайн веб-сайта время пребывания, и поэтому нашей нулевой и
альтернативной гипотезами будут следующие:
-
H0: Время пребывания для обновленного
веб-сайта не отличается от времени пребывания для существующего
веб-сайта
-
H1: Время пребывания для обновленного
веб-сайта больше по сравнению с временем пребывания для
существующего веб-сайта
Наше консервативное допущение состоит в том, что обновленный
веб-сайт никак не влияет на время пребывания посетителей на
веб-сайте. Нулевая гипотеза не обязательно должна быть нулевой
(т.е. эффект отсутствует), но в данном случае, у нас нет никакого
разумного оправдания, чтобы считать иначе. Если выборочные данные
не поддержат нулевую гипотезу (т.е. если данные расходятся с ее
допущением на слишком большую величину, чтобы носить случайный
характер), то мы отклоним нулевую гипотезу и предложим
альтернативную в качестве наилучшего альтернативного
объяснения.
Указав нулевую и альтернативную гипотезы, мы должны установить
уровень значимости, на котором мы ищем эффект.
Статистическая значимость
Проверка статистической значимости изначально разрабатывалась
независимо от проверки статистических гипотез, однако сегодня оба
подхода очень часто используются во взаимодействии друг с другом.
Задача проверки статистической значимости состоит в том, чтобы
установить порог, за пределами которого мы решаем, что наблюдаемые
данные больше не поддерживают нулевую гипотезу.
Следовательно, существует два риска:
-
Мы можем принять расхождение как значимое, когда на самом деле
оно возникло случайным образом
-
Мы можем приписать расхождение случайности, когда на самом деле
оно показывает истинное расхождение с популяцией
Эти две возможности обозначаются соответственно, как ошибки 1-го
и 2-го рода:
|
H0ложная
|
H0истинная
|
|
Отклонить H0
|
Истинноотрицательный исход
|
Ошибка 1-го рода (ложноположительный исход)
|
|
Принять H0
|
Ошибка 2-го рода (ложноотрицательный исход)
|
Истинноположительный исход
|
Чем больше мы уменьшаем риск совершения ошибок 1-го рода, тем
больше мы увеличиваем риск совершения ошибок 2-го рода. Другими
словами, с чем большей уверенностью мы хотим не заявлять о наличии
расхождения, когда его нет, тем большее расхождение между выборками
нам потребуется, чтобы заявить о статистической значимости. Эта
ситуация увеличивает вероятность того, что мы проигнорируем
подлинное расхождение, когда мы с ним столкнемся.
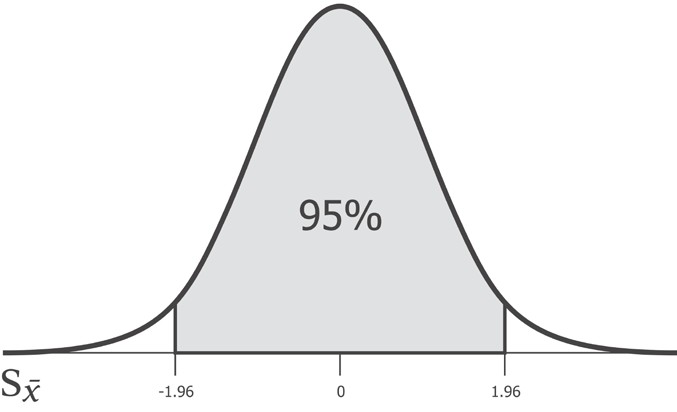
В статистической науке обычно используются два порога
значимости. Это уровни в 5% и 1%. Расхождение в 5% обычно называют
значимым, а расхождение в 1% крайне значимым. В
формулах этот порог часто обозначается греческой буквой (альфа) и
называется уровнем значимости. Поскольку, отсутствие
эффекта по результатам эксперимента может рассматриваться как
неуспех (эксперимента либо обновленного веб-сайта, как в нашем
случае), то может возникнуть желание корректировать уровень
значимости до тех пор, пока эффект не будет найден. По этой причине
классический подход к проверке статистической значимости требует,
чтобы мы устанавливали уровень значимости до того, как обратимся к
нашим данным. Часто выбирается уровень в 5%, и поэтому мы на нем и
остановимся.
Проверка обновленного дизайна веб-сайта
Веб-команда в AcmeContent была поглощена работой, конструируя
обновленный веб-сайт, который будет стимулировать посетителей
оставаться на нем в течение более длительного времени. Она
употребила все новейшие методы и, в результате мы вполне уверены,
что веб-сайт покажет заметное улучшение показателя времени
пребывания.
Вместо того, чтобы запустить его для всех пользователей сразу, в
AcmeContent хотели бы сначала проверить веб-сайт на небольшой
выборке посетителей. Мы познакомили веб-команду с понятием
искаженности выборки, и в результате там решили в течение одного
дня перенаправлять случайные 5% трафика на обновленный веб-сайт.
Результат с дневным трафиком был нам предоставлен одним текстовым
файлом. Каждая строка показывает время пребывания посетителей. При
этом, если посетитель пользовался исходным дизайном, ему
присваивалось значение "0", и если он пользовался обновленным (и
надеемся, улучшенным) дизайном, то ему присваивалось значение
"1".
Выполнение z-теста
Ранее при тестировании с интервалами уверенности мы располагали
лишь одним популяционным средним, с которым и выполнялось
сравнение.
При тестировании нулевой гипотезы с помощью z-теста мы
имеем возможность сравнивать две выборки. Посетители, которые
видели обновленный веб-сайт, отбирались случайно, и данные для
обеих групп были собраны в тот же день, чтобы исключить другие
факторы с временной зависимостью.
Поскольку в нашем распоряжении имеется две выборки, то и
стандартных ошибок у нас тоже две. Z-тест выполняется
относительно объединенной стандартной ошибки, т.е. квадратного
корня суммы дисперсий (вариансов), деленных на размеры выборок. Она
будет такой же, что и результат, который мы получим, если взять
стандартную ошибку обеих выборок вместе:

Здесь 2a это дисперсия выборки
a, 2b дисперсия выборки
bи соответственно na и
nb размеры выборок a и b. На
Python объединенная стандартная ошибка вычисляется следующим
образом:
def pooled_standard_error(a, b, unbias=False): '''Объединенная стандартная ошибка''' std1 = a.std(ddof=0) if unbias==False else a.std() std2 = b.std(ddof=0) if unbias==False else b.std() x = std1 ** 2 / a.count() y = std2 ** 2 / b.count() return sp.sqrt(x + y)
С целью выявления того, является ли видимое нами расхождение
неожиданно большим, можно взять наблюдавшиеся расхождения между
средними значениями на объединенной стандартной ошибке. Эту
статистическую величину принято обозначать переменной
z:

Используя функции pooled_standard_error, которая
вычисляет объединенную стандартную ошибку, z-статистику
можно получить следующим образом:
def z_stat(a, b, unbias=False): return (a.mean() - b.mean()) / pooled_standard_error(a, b, unbias)
Соотношение z объясняет, насколько средние значения
отличаются относительно величины, которую мы ожидаем при заданной
стандартной ошибке. Следовательно, z-статистика сообщает
нам о том, на какое количество стандартных ошибок расходятся
средние значения. Поскольку стандартная ошибка имеет нормальное
распределение вероятностей, мы можем связать это расхождение с
вероятностью, отыскав z-статистику в нормальной ИФР:
def z_test(a, b): return stats.norm.cdf([ z_stat(a, b) ])
В следующем ниже примере z-тест используется для
сравнения результативность двух веб-сайтов. Это делается путем
группировки строк по номеру веб-сайта, в результате чего
возвращается коллекция, в которой конкретному веб-сайту
соответствует набор строк. Мы вызываем
groupby('site')['dwell-time'] для конвертирования
набора строк в набор значений времени пребывания. Затем вызываем
функцию get_group с номером группы, соответствующей
номеру веб-сайта:
def ex_2_14(): '''Сравнение результативности двух вариантов дизайна веб-сайта на основе z-теста''' groups = load_data('new-site.tsv').groupby('site')['dwell-time'] a = groups.get_group(0) b = groups.get_group(1) print('a n: ', a.count()) print('b n: ', b.count()) print('z-статистика:', z_stat(a, b)) print('p-значение: ', z_test(a, b))
a n: 284b n: 16z-статистика: -1.6467438180091214p-значение: [0.04980536]
Установление уровня значимости в размере 5% во многом аналогично
установлению интервала уверенности шириной 95%. В сущности, мы
надеемся убедиться, что наблюдавшееся расхождение попадает за
пределы 95%-го интервала уверенности. Если это так, то мы можем
утверждать, что нашли результат с 5%-ым уровнем значимости.
P-значение это вероятность совершения
ошибки 1-го рода в результате неправильного отклонения нулевой
гипотезы, которая в действительности является истинной. Чем
меньше p-значение, тем больше
определенность в том, что нулевая гипотеза является ложной, и что
мы нашли подлинный эффект.
Этот пример возвращает значение 0.0498, или 4.98%. Поскольку оно
немногим меньше нашего 5% порога значимости, мы можем утверждать,
что нашли нечто значимое.
Приведем еще раз нулевую и альтернативную гипотезы:
-
H0: Время пребывания на обновленном
веб-сайте не отличается от времени пребывания на существующем
веб-сайте
-
H1: Время пребывания на обновленном
веб-сайте превышает время пребывания на существующем веб-сайте.
Наша альтернативная гипотеза состоит в том, что время пребывания
на обновленном веб-сайте больше.
Мы готовы заявить о статистической значимости, и что время
пребывания на обновленном веб-сайте больше по сравнению с
существующим веб-сайтом, но тут есть одна трудность чем меньше
размер выборки, тем больше неопределенность в том, что выборочное
стандартное отклонение совпадет с популяционным. Как показано в
результатах предыдущего примера, наша выборка из обновленного
веб-сайта содержит всего 16 посетителей. Столь малые выборки делают
невалидным допущение о том, что стандартная ошибка нормально
распределена.
К счастью, существует тест и связанное с ним распределение,
которое моделирует увеличенную неопределенность стандартных ошибок
для выборок меньших размеров.
t-распределение Студента
Популяризатором t-распределения был химик, работавший
на пивоварню Гиннес в Ирландии, Уилльям Госсетт, который включил
его в свой анализ темного пива Стаут.
В 1908 Уильям Госсет опубликовал статью об этой проверке в
журнале Биометрика, но при этом по распоряжению своего
работодателя, который рассматривал использованную Госсеттом
статистику как коммерческую тайну, был вынужден использовать
псевдоним. Госсет выбрал псевдоним
Студент.
В то время как нормальное распределение полностью описывается
двумя параметрами средним значением и стандартным отклонением,
t-распределение описывается лишь одним параметром, так
называемыми степенями свободы. Чем больше степеней
свободы, тем больше t-распределение похоже на нормальное
распределение с нулевым средним и стандартным отклонением, равным
1. По мере уменьшения степеней свободы, это распределение
становится более широким с более толстыми чем у нормального
распределения, хвостами.

Нормальное распределение, t-распределение
со степенью свободы df = 20 и степенью свободы df = 5
Приведенный выше рисунок показывает, как
t-распределение изменяется относительно нормального
распределения при наличии разных степеней свободы. Более толстые
хвосты для выборок меньших размеров соответствуют увеличенной
возможности наблюдать более крупные отклонения от среднего
значения.
Степени свободы
Степени свободы, часто обозначаемые сокращенно df от англ.
degrees of freedom, тесно связаны с размером выборки. Это полезная
статистика и интуитивно понятное свойство числового ряда, которое
можно легко продемонстрировать на примере.
Если бы вам сказали, что среднее, состоящее из двух значений,
равно 10 и что одно из значений равно 8, то Вам бы не потребовалась
никакая дополнительная информация для того, чтобы суметь заключить,
что другое значение равно 12. Другими словами, для размера выборки,
равного двум, и заданного среднего значения одно из значений
ограничивается, если другое известно.
Если напротив вам говорят, что среднее, состоящее из трех
значений, равно 10, и первое значение тоже равно 10, то Вы были бы
не в состоянии вывести оставшиеся два значения. Поскольку число
множеств из трех чисел, начинающихся с 10, и чье среднее равно 10,
является бесконечным, то прежде чем вы сможете вывести значение
третьего, второе тоже должно быть указано.
Для любого множества из трех чисел ограничение простое: вы
можете свободно выбрать первые два числа, но заключительное число
ограничено. Степени свободы могут таким образом быть обобщены
следующим образом: количество степеней свободы любой отдельной
выборки на единицу меньше размера выборки.
При сопоставлении двух выборок степени свободы на две единицы
меньше суммы размеров этих выборок, что равно сумме их
индивидуальных степеней свободы.
t-статистика
При использовании t-распределения мы обращаемся к
t-статистике. Как и z-статистика, эта величина
количественно выражает степень маловероятности отдельно взятого
наблюдавшегося отклонения. Для двухвыборочного t-теста
соответствующая t-статистика вычисляется следующим
образом:

Здесь Sab это объединенная стандартная
ошибка. Объединенная стандартная ошибка вычисляется таким же
образом, как и раньше:

Однако это уравнение допускает наличие информации о
популяционных параметрах aи
b, которые можно аппроксимировать только на
основе крупных выборок. t-тест предназначен для малых
выборок и не требует от нас принимать допущения о поплуляционной
дисперсии (вариансе).
Как следствие, объединенная стандартная ошибка для
t-теста записывается как квадратный корень суммы
стандартных ошибок:

На практике оба приведенных выше уравнения для объединенной
стандартной ошибки дают идентичные результаты при заданных
одинаковых входных последовательностях. Разница в математической
записи всего лишь служит для иллюстрации того, что в условиях
t-теста мы на входе зависим только от выборочных
статистик. Объединенная стандартная ошибка может быть вычислена
следующим образом:
def pooled_standard_error_t(a, b): '''Объединенная стандартная ошибка для t-теста''' return sp.sqrt(standard_error(a) ** 2 + standard_error(b) ** 2)
Хотя в математическом плане t-статистика и
z-статистика представлены по-разному, на практике
процедура вычисления обоих идентичная:
t_stat = z_statdef ex_2_15(): '''Вычисление t-статистики двух вариантов дизайна веб-сайта''' groups = load_data('new-site.tsv').groupby('site')['dwell-time'] a = groups.get_group(0) b = groups.get_group(1) return t_stat(a, b)
-1.6467438180091214
Различие между двумя выборочными показателями является не
алгоритмическим, а концептуальным z-статистика применима
только тогда, когда выборки подчинены нормальному
распределению.
t-тест
Разница в характере работы t-теста вытекает из
распределения вероятностей, из которого вычисляется наше
p-значение. Вычислив t-статистику, мы должны
отыскать ее значение в t-распределении, параметризованном
степенями свободы наших данных:
def t_test(a, b): df = len(a) + len(b) - 2 return stats.t.sf([ abs(t_stat(a, b)) ], df)
Значение степени свободы обеих выборок на две единицы меньше их
размеров, и для наших выборок составляет 298.

t-распределение, степень свободы = 298
Напомним, что мы выполняем проверку статистической гипотезы.
Поэтому выдвинем нашу нулевую и альтернативную гипотезы:
Выполним следующий ниже пример:
def ex_2_16(): '''Сравнение результативности двух вариантов дизайна веб-сайта на основе t-теста''' groups = load_data('new-site.tsv').groupby('site')['dwell-time'] a = groups.get_group(0) b = groups.get_group(1) return t_test(a, b)
array([ 0.05033241])
Этот пример вернет p-значение, составляющее более 0.05.
Поскольку оно больше , равного 5%, который мы установили для
проверки нулевой гипотезы, то мы не можем ее отклонить. Наша
проверка с использованием t-теста значимого расхождения
между средними значениями не обнаружила. Следовательно, наш едва
значимый результат z-теста отчасти объясняется наличием
слишком малой выборки.
Двухсторонние тесты
В нашей альтернативной гипотезе было принято неявное допущение,
что обновленный веб-сайт будет работать лучше существующего. В
процедуре проверки нулевой статистической гипотезы предпринимаются
особые усилия для обеспечения того, чтобы при поиске статистической
значимости мы не делали никаких скрытых допущений.
Проверки, при выполнении которых мы ищем только значимое
количественное увеличение или уменьшение, называются
односторонними и обычно не приветствуются, кроме случая,
когда изменение в противоположном направлении было бы невозможным.
Название термина односторонний обусловлено тем, что односторонняя
проверка размещает всю в одном хвосте распределения. Не делая
проверок в другом направлении, проверка имеет больше мощности
отклонить нулевую гипотезу в отдельно взятом направлении и, в
сущности, понижает порог, по которому мы судим о результате как
значимом.
Статистическая мощность это вероятность правильного
принятия альтернативной гипотезы. Она может рассматриваться как
способность проверки обнаруживать эффект там, где имеется искомый
эффект.
Хотя более высокая статистическая мощность выглядит желательной,
она получается за счет наличия большей вероятности совершить ошибку
1-го рода. Правильнее было бы допустить возможность того, что
обновленный веб-сайт может в действительности оказаться хуже
существующего. Этот подход распределяет нашу одинаково по обоим
хвостам распределения и обеспечивает значимый результат, не
искаженный под воздействием априорного допущения об улучшении
работы обновленного веб-сайта.

Надписи: t-распределение, степень свободы = 298
В действительности в модуле stats библиотеки scipy уже
предусмотрены функции для выполнения двухвыборочных
t-проверок. Это функция stats.ttest_ind. В
качестве первого аргумента мы предоставляем выборку данных и в
качестве второго - выборку для сопоставления. Если именованный
аргумент equal_var равен True, то
выполняется стандартная независимая проверка двух выборок, которая
предполагает равные популяционные дисперсии, в противном случае
выполняется проверка Уэлша (обратите внимание на служебную функцию
t_test_verbose, (которую можно найти среди примеров
исходного кода в репо):
def ex_2_17(): '''Двухсторонний t-тест''' groups = load_data('new-site.tsv').groupby('site')['dwell-time'] a = groups.get_group(0) b = groups.get_group(1) return t_test_verbose(a, sample2=b, fn=stats.ttest_ind) #t-тест Уэлша
{'p-значение': 0.12756432502462475, 'степени свободы ': 17.761382349686098, 'интервал уверенности': (76.00263198799597, 99.89877646270826), 'n1 ': 284, 'n2 ': 16, 'среднее x ': 87.95070422535211, 'среднее y ': 122.0, 'дисперсия x ': 10463.941024237296, 'дисперсия y ': 6669.866666666667, 't-статистика': -1.5985205593851322}
По результатам t-теста служебная функция
t_test_verbose возвращает много информации и в том
числе p-значение. P-значение примерно в 2 раза
больше того, которое мы вычислили для односторонней проверки. На
деле, единственная причина, почему оно не совсем в два раза больше,
состоит в том, что в модуле stats имплементирован легкий вариант
t-теста, именуемый t-тестом Уэлша, который
немного более робастен, когда две выборки имеют разные стандартные
отклонения. Поскольку мы знаем, что для экспоненциальных
распределений среднее значение и дисперсия тесно связаны, то этот
тест немного более строг в применении и даже возвращает более
низкую значимость.
Одновыборочный t-тест
Независимые выборки в рамках t-тестов являются наиболее
распространенным видом статистического анализа, который
обеспечивает очень гибкий и обобщенный способ установления, что две
выборки представляют одинаковую либо разную популяцию. Однако в
случаях, когда популяционное среднее уже известно, существует еще
более простая проверка, представленная функцией библиотеки
sciзy stats.ttest_1samp.
Мы передаем выборку и популяционное среднее относительно
которого выполняется проверка. Так, если мы просто хотим узнать, не
отличается ли обновленный веб-сайт значимо от существующего
популяционного среднего времени пребывания, равного 90 сек., то
подобную проверку можно выполнить следующим образом:
def ex_2_18(): groups = load_data('new-site.tsv').groupby('site')['dwell-time'] b = groups.get_group(1) return t_test_verbose(b, mean=90, fn=stats.ttest_1samp)
{'p-значение ': 0.13789520958229415, 'степени свободы df ': 15.0, 'интервал уверенности': (78.4815276659039, 165.5184723340961), 'n1 ': 16, 'среднее x ': 122.0, 'дисперсия x ': 6669.866666666667, 't-статистика ': 1.5672973291495713}
Служебная функция t_test_verbose не только
возвращает p-значение для выполненной проверки, но и
интервал уверенности для популяционного среднего. Интервал имеет
широкий диапазон между 78.5 и 165.5 сек., и, разумеется,
перекрывается 90 сек. нашего теста. Как раз он и объясняет, почему
мы не смогли отклонить нулевую гипотезу.
Многократные выборки
В целях развития интуитивного понимания относительно того, каким
образом t-тест способен подтвердить и вычислить эти
статистики из столь малых данных, мы можем применить подход,
который связан с многократными выборками, от англ.
resampling. Извлечение многократных выборок основывается на
допущении о том, что каждая выборка является лишь одной из
бесконечного числа возможных выборок из популяции. Мы можем лучше
понять природу того, какими могли бы быть эти другие выборки, и,
следовательно, добиться лучшего понимания опорной популяции, путем
извлечения большого числа новых выборок из нашей существующей
выборки.
На самом деле существует несколько методов взятия многократных
выборок, и мы обсудим один из самых простых бутстрапирование. При
бустрапировании мы генерируем новую выборку, неоднократно извлекая
из исходной выборки случайное значение с возвратом до тех пор, пока
не сгенерируем выборку, имеющую тот же размер, что и оригинал.
Поскольку выбранные значения возвращаются назад после каждого
случайного отбора, то в новой выборке то же самое исходное значение
может появляться многократно. Это как если бы мы неоднократно
вынимали случайную карту из колоды игральных карт и каждый раз
возвращали вынутую карту назад в колоду. В результате время от
времени мы будем иметь карту, которую мы уже вынимали.
Бутстраповская выборка, или бутстрап, синтетический набор
данных, полученный в результате генерирования повторных выборок (с
возвратом) из исследуемой выборки, используемой в качестве
суррогатной популяции, в целях аппроксимации выборочного
распределения статистики (такой как, среднее, медиана и
др.).
В библиотеке pandas при помощи функции sample можно легко
извлекать бутстраповские выборки и генерировать большое число
многократных выборок. Эта функция принимает ряд опциональных
аргументов, в т.ч. n (число элементов, которые нужно
вернуть из числового ряда), axis (ось, из которой
извлекать выборку) и replace (выборка с возвратом или
без), по умолчанию равный False. После этой функции
можно задать метод агрегирования, вычисляющий сводную статистику в
отношении бутстраповских выборок:
def ex_2_19(): '''Построение графика синтетических времен пребывания путем извлечения бутстраповских выборок''' groups = load_data('new-site.tsv').groupby('site')['dwell-time'] b = groups.get_group(1) xs = [b.sample(len(b), replace=True).mean() for _ in range(1000)] pd.Series(xs).hist(bins=20) plt.xlabel('Бутстрапированные средние значения времени пребывания, сек.') plt.ylabel('Частота') plt.show()
Приведенный выше пример наглядно показывает результаты на
гистограмме:

Гистограмма демонстрирует то, как средние значения изменялись
вместе с многократными выборками, взятыми из времени пребывания на
обновленном веб-сайте. Хотя на входе имелась лишь одна выборка,
состоящая из 16 посетителей, бутстрапированные выборки очень четко
просимулировали стандартную ошибку изначальной выборки и позволили
визуализировать интервал уверенности (между 78 и 165 сек.),
вычисленный ранее в результате одновыборочного
t-теста.
Благодаря бутстрапированию мы просимулировали взятие
многократных выборок, при том, что у нас на входе имелась всего
одна выборка. Этот метод обычно применяется для оценивания
параметров, которые мы не способны или не знаем, как вычислить
аналитически.
Проверка многочисленных вариантов дизайна
Было разочарованием обнаружить отсутствие статистической
значимости на фоне увеличенного времени пребывания пользователей на
обновленном веб-сайте. Хотя хорошо, что мы обнаружили это на малой
выборке пользователей, прежде чем выкладывать его на всеобщее
обозрение.
Не позволяя себя обескуражить, веб-команда AcmeContent берется
за сверхурочную работу и создает комплект альтернативных вариантов
дизайна веб-сайта. Беря лучшие элементы из других проектов, они
разрабатывают 19 вариантов для проверки. Вместе с нашим изначальным
веб-сайтом, который будет действовать в качестве контрольного,
всего имеется 20 разных вариантов дизайна веб-сайта, куда
посетители будут перенаправляться.
Вычисление выборочных средних
Веб-команда разворачивает 19 вариантов дизайна обновленного
веб-сайта наряду с изначальным. Как отмечалось ранее, каждый
вариант дизайна получает случайные 5% посетителей, и при этом наше
испытание проводится в течение 24 часов.
На следующий день мы получаем файл, показывающий значения
времени пребывания посетителей на каждом варианте веб-сайта. Все
они были промаркированы числами, при этом число 0 соответствовало
веб-сайту с исходным дизайном, а числа от 1 до 19 представляли
другие варианты дизайна:
def ex_2_20(): df = load_data('multiple-sites.tsv') return df.groupby('site').aggregate(sp.mean)
Этот пример сгенерирует следующую ниже таблицу:
|
site
|
dwell-time
|
|
0
|
79.851064
|
|
1
|
106.000000
|
|
2
|
88.229167
|
|
3
|
97.479167
|
|
4
|
94.333333
|
|
5
|
102.333333
|
|
6
|
144.192982
|
|
7
|
123.367347
|
|
8
|
94.346939
|
|
9
|
89.820000
|
|
10
|
129.952381
|
|
11
|
96.982143
|
|
12
|
80.950820
|
|
13
|
90.737705
|
|
14
|
74.764706
|
|
15
|
119.347826
|
|
16
|
86.744186
|
|
17
|
77.891304
|
|
18
|
94.814815
|
|
19
|
89.280702
|
Мы хотели бы проверить каждый вариант дизайна веб-сайта, чтобы
увидеть, не генерирует ли какой-либо из них статистически значимый
результат. Для этого можно сравнить варианты дизайна веб-сайта друг
с другом следующим образом, причем нам потребуется вспомогательный
модуль Python itertools, который содержит набор функций, создающих
итераторы для эффективной
циклической обработки:
import itertoolsdef ex_2_21(): '''Проверка вариантов дизайна веб-сайта на основе t-теста по принципу "каждый с каждым"''' groups = load_data('multiple-sites.tsv').groupby('site') alpha = 0.05 pairs = [list(x) # найти сочетания из n по k for x in itertools.combinations(range(len(groups)), 2)] for pair in pairs: gr, gr2 = groups.get_group( pair[0] ), groups.get_group( pair[1] ) site_a, site_b = pair[0], pair[1] a, b = gr['dwell-time'], gr2['dwell-time'] p_val = stats.ttest_ind(a, b, equal_var = False).pvalue if p_val < alpha: print('Варианты веб-сайта %i и %i значимо различаются: %f' % (site_a, site_b, p_val))
Однако это было бы неправильно. Мы скорее всего увидим
статистическое расхождение между вариантами дизайна, показавшими
себя в особенности хорошо по сравнению с вариантами, показавшими
себя в особенности плохо, даже если эти расхождения носили
случайный характер. Если вы выполните приведенный выше пример, то
увидите, что многие варианты дизайна веб-сайта статистически друг
от друга отличаются.
С другой стороны, мы можем сравнить каждый вариант дизайна
веб-сайта с нашим текущим изначальным значением средним значением
времени пребывания, равным 90 сек., измеренным на данный момент для
существующего веб-сайта:
def ex_2_22(): groups = load_data('multiple-sites.tsv').groupby('site') alpha = 0.05 baseline = groups.get_group(0)['dwell-time'] for site_a in range(1, len(groups)): a = groups.get_group( site_a )['dwell-time'] p_val = stats.ttest_ind(a, baseline, equal_var = False).pvalue if p_val < alpha: print('Вариант %i веб-сайта значимо отличается: %f' % (site_a, p_val))
В результате этой проверки будут идентифицированы два варианта
дизайна веб-сайта, которые существенно отличаются:
Вариант 6 веб-сайта значимо отличается: 0.005534Вариант 10 веб-сайта 10 значимо отличается: 0.006881
Малые p-значения (меньше 1%) указывают на то, что
существует статистически очень значимые расхождения. Этот результат
представляется весьма многообещающим, однако тут есть одна
проблема. Мы выполнили t-тест по 20 выборкам данных с
уровнем значимости , равным 0.05. Уровень значимости определяется,
как вероятность неправильного отказа от нулевой гипотезы. На самом
деле после 20-кратного выполнения t-теста становится
вероятным, что мы неправильно отклоним нулевую гипотезу по крайней
мере для одного варианта веб-сайта из 20.
Сравнивая таким одновременным образом многочисленные страницы,
мы делаем результаты t-теста невалидными. Существует целый
ряд альтернативных технических приемов решения проблемы выполнения
многократных сравнений в статистических тестах. Эти методы будут
рассмотрены в следующем разделе.
Поправка Бонферрони
Для проведения многократных проверок используется подход,
который объясняет увеличенную вероятность обнаружить значимый
эффект в силу многократных испытаний. Поправка Бонферрони это очень
простая корректировка, которая обеспечивает, чтобы мы вряд ли
совершили ошибки 1-го рода. Она выполняется путем настройки
значения уровня значимости для тестов.
Настройка очень простая поправка Бонферрони попросту делит
требуемое значение на число тестов. Например, если для теста
имелось kвариантов дизайна веб-сайта, и эксперимента равно
0.05, то поправка Бонферрони выражается следующим образом:

Она представляет собой безопасный способ смягчить увеличение
вероятности совершения ошибки 1-го рода при многократной проверке.
Следующий пример идентичен примеру ex-2-22, за
исключением того, что значение разделено на число групп:
def ex_2_23(): '''Проверка вариантов дизайна веб-сайта на основе t-теста против исходного (0) с поправкой Бонферрони''' groups = load_data('multiple-sites.tsv').groupby('site') alpha = 0.05 / len(groups) baseline = groups.get_group(0)['dwell-time'] for site_a in range(1, len(groups)): a = groups.get_group(site_a)['dwell-time'] p_val = stats.ttest_ind(a, baseline, equal_var = False).pvalue if p_val < alpha: print('Вариант %i веб-сайта значимо отличается от исходного: %f' % (site_a, p_val))
Если вы выполните приведенный выше пример, то увидите, что при
использовании поправки Бонферрони ни один из веб-сайтов больше не
считается статистически значимым.
Метод проверки статистической значимости связан с поддержанием
равновесия чем меньше шансы совершения ошибки 1-го рода, тем больше
риск совершения ошибки 2-го рода. Поправка Бонферрони очень
консервативна, и весьма возможно, что из-за излишней осторожности
мы пропускаем подлинное расхождение.
Примеры исходного кода для этого поста находятся в моемрепона Github. Все исходные
данные взяты врепозиторииавтора книги.
В заключительном посте, посте 4, этой серии постов мы
проведем исследование альтернативного подхода к проверке
статистической значимости, который позволяет устанавливать
равновесие между совершением ошибок 1-го и 2-го рода, давая нам
возможность проверить все 20 вариантов веб-сайта одновременно.


























, постранично и совмещенно") Длительности (сек), постранично и совмещенно
Длительности (сек), постранично и совмещенно







 F-распределение со степенями свободы 19 и 980
F-распределение со степенями свободы 19 и 980


















































![Как изменяется гистограмма при изменении количества интервалов. [Рисунок автора]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/7f1/71f/f40/7f171ff405334ac351d813ecfe7ca455.png "Как изменяется гистограмма при изменении количества интервалов. [Рисунок автора]") Как изменяется гистограмма при изменении
количества интервалов. [Рисунок автора]
Как изменяется гистограмма при изменении
количества интервалов. [Рисунок автора]
![Как меняется гистограмма при изменении максимального значения. [Рисунок автора]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/29c/73d/22f/29c73d22f14a324968ab201e3bea41cc.png "Как меняется гистограмма при изменении максимального значения. [Рисунок автора]") Как меняется гистограмма при изменении
максимального значения. [Рисунок автора]
Как меняется гистограмма при изменении
максимального значения. [Рисунок автора]
![Те же данные, разная ширина интервала. На левом графике невозможно обнаружить высокую концентрацию нулей. [Рисунок автора]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/568/6cc/b23/5686ccb23bbd5f013cc5f50f419bb43b.png "Те же данные, разная ширина интервала. На левом графике невозможно обнаружить высокую концентрацию нулей. [Рисунок автора]") Те же данные, разная ширина интервала. На
левом графике невозможно обнаружить высокую концентрацию нулей.
[Рисунок автора]
Те же данные, разная ширина интервала. На
левом графике невозможно обнаружить высокую концентрацию нулей.
[Рисунок автора]
![Слева непрерывная переменная. Справа дискретная переменная. Однако на верхних графиках они выглядят одинаково. [Рисунок автора]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/9b4/66d/054/9b466d0547e9bbd529cab99fd58aba6f.png "Слева непрерывная переменная. Справа дискретная переменная. Однако на верхних графиках они выглядят одинаково. [Рисунок автора]") Слева непрерывная переменная. Справа
дискретная переменная. Однако на верхних графиках они выглядят
одинаково. [Рисунок автора]
Слева непрерывная переменная. Справа
дискретная переменная. Однако на верхних графиках они выглядят
одинаково. [Рисунок автора]
![Сравнение гистограмм. [Рисунок автора]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/460/df1/ed4/460df1ed42f1a890f7b732953586512b.png "Сравнение гистограмм. [Рисунок автора]") Сравнение гистограмм. [Рисунок автора]
Сравнение гистограмм. [Рисунок автора]
![График кумулятивного распределения максимальной частоты сердечных сокращений. [Рисунок автора]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/5be/acf/f95/5beacff9594412dff001cd02e1ea2e82.png "График кумулятивного распределения максимальной частоты сердечных сокращений. [Рисунок автора]") График кумулятивного распределения
максимальной частоты сердечных сокращений. [Рисунок автора]
График кумулятивного распределения
максимальной частоты сердечных сокращений. [Рисунок автора]
![Сравнение распределений в CDP. [Рисунок автора]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/c14/de3/22d/c14de322da1e53ae4455357e8da017b5.png "Сравнение распределений в CDP. [Рисунок автора]") Сравнение распределений в CDP. [Рисунок автора]
Сравнение распределений в CDP. [Рисунок автора]

 Пример qr-кода с ссылкой
Пример qr-кода с ссылкой



 Пример qr-кода с вывозом FaceTime
Пример qr-кода с вывозом FaceTime

 Пример qr-кода для подключения к WiFi
Пример qr-кода для подключения к WiFi


 время существования явления к
настоящему моменту, а
время существования явления к
настоящему моменту, а  сколько остаётся ему до конца. Считая,
что попадание во временную точку t отрезка времени полного
существования
сколько остаётся ему до конца. Считая,
что попадание во временную точку t отрезка времени полного
существования  случайно и равновероятно, имеем
случайную величину
случайно и равновероятно, имеем
случайную величину
 с вероятностью
с вероятностью  находится внутри отрезка
есть
находится внутри отрезка
есть
 и получим интервал для времени
дальнейшего существования
и получим интервал для времени
дальнейшего существования 
 ) Готт оценил сколько осталось
Берлинской стене:
) Готт оценил сколько осталось
Берлинской стене:
 , так сказать, чтобы
наверняка, с вероятностью ошибки не более 1/20. В роли равномерно
распределённой случайной переменной взято отношение
, так сказать, чтобы
наверняка, с вероятностью ошибки не более 1/20. В роли равномерно
распределённой случайной переменной взято отношение  , где
, где  приблизительное число уже живших и
живущих людей на этом свете, а
приблизительное число уже живших и
живущих людей на этом свете, а  окончательное число всех, кто поживет
за все времена. Оно составит не более
окончательное число всех, кто поживет
за все времена. Оно составит не более  , то есть, если мы примем, что 60
млрд людей родились вплоть до настоящего момента (оценка Лесли), то
тогда мы можем сказать, что с уверенностью 95 % общее число людей N
будет менее, чем 2060 миллиардов = 1,2 триллиона. Предполагая, что
население мира стабилизируется на уровне 10 млрд человек, и средняя
продолжительность жизни составит 80 лет, нетрудно посчитать,
сколько потребуется времени, чтобы оставшиеся 1140 миллиардов людей
родились. А именно, данное рассуждение означает, что с 95 %
уверенностью мы можем утверждать, что человеческая раса исчезнет в
течение 9120 лет. Так написано в Википедии.
, то есть, если мы примем, что 60
млрд людей родились вплоть до настоящего момента (оценка Лесли), то
тогда мы можем сказать, что с уверенностью 95 % общее число людей N
будет менее, чем 2060 миллиардов = 1,2 триллиона. Предполагая, что
население мира стабилизируется на уровне 10 млрд человек, и средняя
продолжительность жизни составит 80 лет, нетрудно посчитать,
сколько потребуется времени, чтобы оставшиеся 1140 миллиардов людей
родились. А именно, данное рассуждение означает, что с 95 %
уверенностью мы можем утверждать, что человеческая раса исчезнет в
течение 9120 лет. Так написано в Википедии.


















 Рисунок 1 -
исходные данные
Рисунок 1 -
исходные данные
 ,
,
 ,
,  ,
, ![k=[n/2]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/c15/586/8f0/c155868f00da11564c2301d41b802803.svg) ;
; Рисунок 2 - пример расчета критерия Вилкоксона
Рисунок 2 - пример расчета критерия Вилкоксона
 Рисунок 3 - классификация статистических
критериев
Рисунок 3 - классификация статистических
критериев


{kind=link}