На одном из интенсивов по BI-аналитике от коуча услышал
высказывание: BI-аналитика создает ценность для предприятия, но
определить величину денежного эквивалента этой ценности
невозможно.
Я не согласился с этим высказыванием так как, на мой взгляд,
менеджмент создает систему метрик бизнес-аналитики с целью видеть
векторы развития предприятия и скрытые проблемы, приводящие к
снижению итоговых результатов. И если с помощью метрик вектора
развития сложно конкретизировать, то кризисные явления
идентифицируются достаточно надежно, при качественном исследовании
исторических данных. То есть проявляется явная функция пространства
метрик, показывающая зоны, в которые предприятию предпочтительно не
попадать и система бизнес-метрик является инструментом
риск-менеджмента. В настоящий момент технологии монетизации
мероприятий риск-менеджмента хорошо отлажены. Так же ресурс
Reports and Data
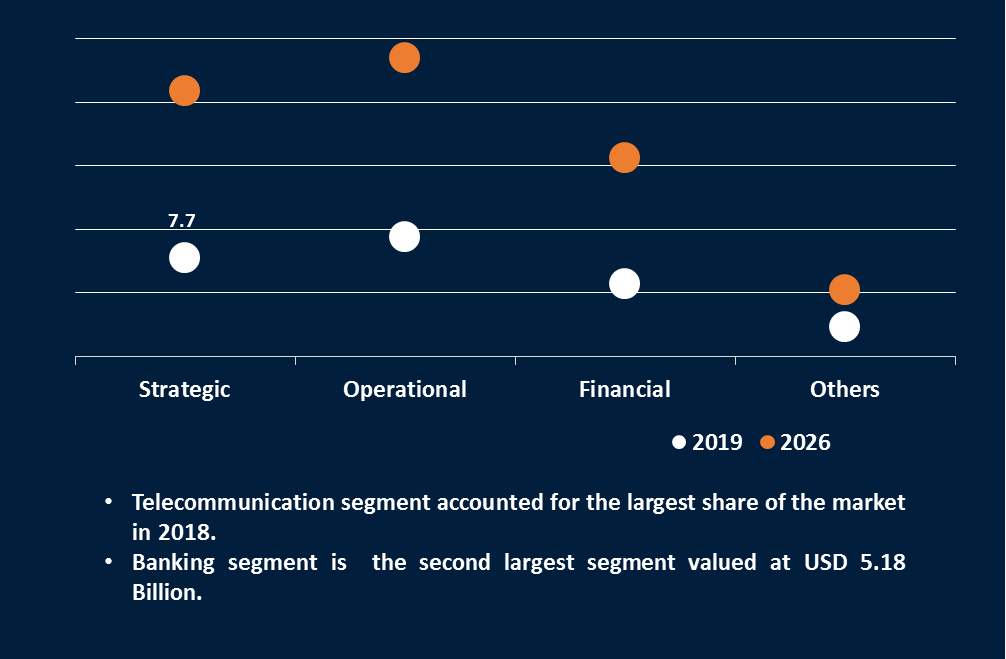
прогнозирует объем рынка анализа рисков к 2026 в объеме 65 млрд. долл.
Посерфил обнаружил в сети, что существует всего лишь один
университет, у которого есть программа обучения по данному курсу в
The Hong Kong University of
Science and Technology и нижепредставленную статью. После таких
результатов мне стало ясно, что тема исследована слабо и причина в
том, что риск-менеджмент отдельное направление с достаточно широким
диапазоном и риски в операционной деятельности предприятия -
подраздел этих мероприятий.
Чтобы читатель мог представить широту задач даю ссылку на статью
об инструментах в этой области The 19 Best Risk Management
Software of 2021.
После переведенной статьи изложил свои размышления о том, как
сделать набор бизнес-метрик инструментом риск-менеджмента.
Business intelligence in risk management: Some recent
progresses (2014 год)
Предисловие
Управление рисками стало важной темой, как в академических
кругах, так и на практике в течение последних нескольких
десятилетий. Большинство инструментов бизнес-аналитики
использовалось для улучшения управления рисками, а инструменты
управления рисками извлекли выгоду из подходов бизнес-аналитики.
Эта вводная статья представляет собой обзор современных
исследований в области бизнес-аналитики, в области управления
рисками, а также работ, которые были приняты для публикации в этом
выпуске.
Ключевые слова: бизнес-аналитика, управление рисками,
исследование операций.
1. Введение
Мы очень рады видеть завершение этого специального выпуска по
информационным наукам: Бизнес-аналитика в управлении рисками. Риски
существуют во всех аспектах нашей жизни и могут означать разные
вещи для разных людей, хотя в негативном плане они всегда в целом
причиняют большой потенциальный ущерб и неудобства для
заинтересованных сторон. Например, недавние риски стихийных
бедствий включают террористические акты, приведшие к отравлению
газом в японском метро, терракту 11 сентября 2001 г., взрывам
транспортных систем Испании и Великобритании, а также вирус
атипичной пневмонии, нарушающий общественную и деловую
деятельность, в частности в Азии.
Совсем недавно вирус H1N1 обострил осведомленность о системе
реагирования во всем мире, а глобальный финансовый кризис привел к
рецессии во всех аспектах экономики (59).
Для управления рисками, с которыми сталкивается организация,
требуются комплексные подходы, и иногда эффективные стратегии
принятия рисков могут включать в себя новые бизнес-концепции, такие
как управление корпоративными рисками. Большинство инструментов
бизнес-аналитики использовалось для улучшения управления рисками, и
инструменты управления рисками выигрывают от подходов
бизнес-аналитики. Например, модели искусственного интеллекта, такие
как нейронные сети и метод опорных векторов, широко используются
для создания системы предварительного предупреждения, для
мониторинга финансового состояния компании (38, 2, 36).
Агентно-ориентированные теории используются в управлении рисками
цепочки поставок (27, 34). Модели бизнес-аналитики также полезны
для хеджирования финансовых рисков путем включения рыночных рисков,
кредитных рисков и операционных рисков (59). Исследование
инструментов бизнес-аналитики в области управления рисками полезно
как практикам, так и академическим исследователям.
В этом выпуске мы представляем статьи, посвященные последним
достижениям в использовании бизнес-аналитики для управления.
2. Риски и управление рисками
Все человеческие усилия связаны с неопределенностью и риском. В
области производства продуктов питания наука добилась больших
успехов в генетическом управлении. Но есть опасения по поводу
некоторых манипуляций, связанных с различными взглядами,
преобладающими во все мире. В Соединенных Штатах генетическое
управление обычно рассматривается как способ получения качественных
и продуктивных источников пищи более надежным способом. Тем не
менее, существуют серьезные возражения против биоинженерных
продуктов питания в Европе и Азии. Появились некоторые естественные
болезни, например, коровье бешенство, с которыми очень трудно
бороться. Степень достигнутого контроля часто оспаривается. В
Европе существует строгий контроль над биоинженерией, но даже тогда
произошел скандал по свиноводству, связанный с опасными кормами и
запрещенными лекарствами (57). Риски, связанные с биоинженерией,
являются важными факторами в пищевой цепочке (50, 14). Генетическое
картирование предлагает огромный прорыв в мире науки, но сопряжено
с политическими рисками в применении к управлению человеческими
ресурсами (37).
Даже применение информационных технологий для лучшего управления
рисками в оказании медицинской помощи сопряжено с рисками (54).
Использование компьютерного управления применялось к летающим
самолетам, но не всегда работало (13). Риски можно рассматривать
как угрозы, но бизнес существует, чтобы справляться с рисками (45).
В разных дисциплинах используются разные способы классификации
рисков. Чтобы объяснить уроки управления рисками из кредитного
кризиса, Jorion (26) классифицировал риски на: известные -
известные, известные - неизвестные и неизвестные - неизвестные.
Фактически это основано на степени риска и аналогично тому, что
обсуждали Olson and Wu (45).
Мы предлагаем следующую общую классификацию рисков: отраслевые и
качественные.
- Финансовые риски отраслевого кластера, в основном включают в
себя всевозможные риски, связанные с финансовыми секторами и
финансовыми аспектами в других секторах. Они включают, но не
ограничивают рыночный риск, кредитный риск, операционный риск и
риск ликвидности. Нефинансовые риски, включающие риски из
источников, не связанных с финансами. К ним относятся, но не
ограничиваются ими, политические риски, репетиционные риски,
биоинженерные риски и риски стихийных бедствий.
- Качественные риски могут иметь четыре свойства:
неопределенность, динамика, взаимосвязь и зависимость, а также
сложность. Первые два свойства были широко признаны в межвременных
моделях из областей поведенческих решений и поведенческой экономики
(3); последние два свойства хорошо изучены в финансовых
дисциплинах. Существование риска требует применения различные
распределения теории вероятностей для моделирования рисков. Этот
подход может быть датирован 1700-ми годами, что привело к созданию
моделей событий Бернулли, Пуассона и Гаусса, а также общих
распределений Парето и общих распределений экстремальных значений
для моделирования экстремальных событий. Динамика рисков в основном
предполагает использование теории стохастических процессов в
управлении рисками. Это можно отнести к 1930-м годам, когда были
разработаны Марковские процессы, броуновские движения и процессы
Леви. Взаимосвязь и зависимость рисков имеет дело с корреляцией
между факторами риска. Строятся различные функции связки, а также
используются преобразования Фурье. Сложность риска требует
дальнейшего управления за счет использования различных моделей,
основанных на науке о сложности, таких как подходы к моделированию
на основе агентских моделей.
Управление рисками можно определить как процесс идентификации,
анализа и принятия или уменьшения неопределенности при принятии
инвестиционных решений.
Управление рисками - это управление неопределенностью возможного
сценария событий. Традиционное управление рисками сосредоточено на
рисках, связанных с физическими или юридическими причинами, такими
как стихийные бедствия или пожары, несчастные случаи, смерть и
судебные иски. Управление финансовыми рисками имеет дело с рисками,
которыми можно управлять с помощью имеющихся финансовых
инструментов. Самая последняя концепция, управление рисками
предприятия, предоставляет инструмент для повышения ценности
систем, как коммерческих, так и коммунальных, с систематической
точки зрения. Исследование операций (OR) всегда полезно для
оптимизации управления рисками.
В литературе можно выделить различные области, связанные с
бизнес-аналитикой в управлении рисками.
3. Различные точки зрения и инструменты
Последние несколько десятилетий стали свидетелями огромного
прогресса в области вычислительного интеллекта, включая нечеткую
логику, нейронные сети и генетические алгоритмы, эволюционные
вычисления и подходы к оптимизации, а также такие, как линейное
программирование, нелинейное программирование, теория игр и
многокритериальный анализ решений. Оптимизационные подходы широко
применяются в промышленности во многих областях прогнозирования,
оценки производительности, автоматического управления и
аппроксимации функций. В этом разделе представлен обзор ключевых
областей, а также связанных с ними методов.
3.1. Системы раннего предупреждения
Во многих работах рассматривалась ценность систем раннего
предупреждения как средства контроля риска. Krstevska (30) приводит
их использование в макроэкономических моделях с учетом специфики
экономики Македонии. Ряд моделей был реализован с помощью
компьютерных систем. Flores (15) рассматривал раннее предупреждение
в страховании с помощью стохастической оптимизации. Castell and
Dacuycuy (9) анализировали механизмы макроэкономического и
финансового надзора. Hua (23) рассмотрел методы, используемые для
раннего предупреждения в сфере недвижимости. В рамках промышленного
применения Xie et al. (61) описал процедуру выявления логистических
рисков для малых и средних предприятий.
3.2. Анализ рисков на основе нейронных
сетей
Нейронные сети - это инструменты искусственного интеллекта,
которые оказались очень полезными для выявления закономерностей в
сложных структурах данных, особенно тех, которые связаны с
нелинейными отношениями. Schneidewind (51) представил результаты
работ по применению нейронных сетей для оценки надежности
программного обеспечения, цель которых заключалась в снижении риска
провала проекта. Jin and Zhang (25) представили другое приложение,
демонстрирующее ценность моделей искусственных нейронных сетей в
проектах, в данном случае в проектах, предполагающих
государственно-частное партнерство. К отраслевым приложениям
относятся банки, использующие модели искусственных нейронных сетей
для анализа приложений кредитных карт (62), что позволяет банкам
более эффективно контролировать свои риски после пузыря 2008 года.
Модели нейронных сетей также были объединены с приложениями для
тестового майнинга, такими как Groth и Muntermann (20), где модель
применялась к финансовому риску, в дейтрейдинге. (12) применили
модели искусственных нейронных сетей для управления риском дефолта
малых предприятий в Италии.
3.3. Принятие решений на основе рисков
Использование компьютерных средств для принятия решений на
основе риска широко изучается в области информационных систем в
качестве систем поддержки принятия решений с 1970-х годов (28,56)
Warenski (58) использовал искусственный интеллект для другого
применения анализа кредитного риска, в данном случае демонстрируя
финансовое моделирование в целлюлозно-бумажной промышленности. Otim
et al. (46) представили недавний анализ, специально посвященный
оценке стоимости и риска инвестиций в информационные технологии.
Такие инвестиции включают в себя сложный набор заинтересованных
сторон, что приводит к необходимости учитывать политику
организации. Kozhikode and Li (29) изучали роль политического
плюрализма в экспансии коммерческих банков в Индии, включая
рассмотрение управления рисками. Принятие отраслевых решений
включает не только множество заинтересованных сторон, но и
множество критериев (44), отчасти обусловленных самим
существованием этих многочисленных заинтересованных сторон.
Silvestri et al. (53) представили методику многокритериальной
оценки рисков для анализа рисков в области безопасности
производства. Lakemond et al. (32) дали метод учета риска при
разработке продукта, позволяющий на ранней стадии оценить риск и
другие проблемы.
3.4. Анализ рисков на основе игр
Nash создал одну из самых плодотворных работ в теории игр (42),
изучив роль конкурентной стратегии. Эта хорошо изученная область
является одной из основных направлений в менеджменте промышленными
рисками. Zhao and Jianq (63) рассмотрели модель полной
информационной игры без взаимодействия, которая рассматривает
множество возникающих рисков в среде управления проектами. Merrick
and Parnell (39) расширили теоретико-игровые модели, включив в них
вероятностный анализ рисков в контексте борьбы с терроризмом. Их
применение включало в себя экранирование контейнеров для
радиологических материалов. Lin et al. (35) использовали теорию игр
для моделирования вертикальной дифференциации в онлайн-рекламе,
обнаружив, что более высокий уровень дохода от рекламы может
привести к снижению цен на услуги. Теория игр также применялась
Gnyawali and Park (19) к управлению рисками малых и средних
предприятий.
3.5. Определение кредитного риска
Основная задача финансового сектора в управлении рисками -
оценка вероятности дефолта. Gurny и Tichy (21) представили
скоринговую модель для банков США с использованием линейного
дискриминантного анализа. Chen et al. (11) предложили другое
исследование, в данном случае с использованием методологии Six
Sigma DMAIC для снижения финансового риска.
Wu and Olson (60) продемонстрировали, как прогностические
системы оценки использовались для управления крупными банковскими
рисками кредитоспособности. Caracota et al. (8) предоставили
скоринговую модель для малых и средних предприятий, ищущих
банковский кредит. Poon (48) проанализировал эффективность
кредитного скоринга финансируемых государством предприятий (Freddie
Mac и Fannie Mae), показывая, как скоринг кредитного бюро приводит
к поддержке противоположных стратегий избегания риска и скупого
инвестирования.
3.6. Data mining в управлении рисками
предприятия
Data mining стал очень популярным средством применения
инструментов статистического и искусственного интеллекта для
анализа больших массивов данных. Среди множества приложений для
управления рисками Shiri et al. (52) применили инструменты
интеллектуального анализа данных к корпоративным финансам, включая
выявление мошенничества в управлении, оценку кредитного риска и
прогнозирование результатов деятельности компании. Jans et al. (24)
сосредоточили свое исследование интеллектуального анализа данных на
устранении риска внутреннего мошенничества, обнаружив, что
инструменты интеллектуального анализа данных дают лучшие
результаты, чем одномерный анализ. Holton (22) также обратился к
профессиональному мошенничеству, применив интеллектуальный анализ
текста для поддержки аудита мошенничества. В других отраслях
Nateghi et al. (43) применили методы data mining для более точного
прогнозирования отключений электроэнергии, особенно, связанных с
ураганами. Ghadge et al. (17) проанализировали приложения для
интеллектуального анализа текста для поддержки управления рисками в
цепочках поставок. Два исследования специально посвящены
использованию интеллектуального анализа данных для снижения риска
профессиональных травм. (5, 41)
3.7. Агентно-ориентированное управление
рисками
Искусственный интеллект часто реализуется с помощью агентных
систем, в которых компьютеры имитируют людей, принимающих решения.
Этот подход был применен к управлению рисками в цепочках поставок
Smeureanu et al. (55) с конкретным исследованием риска банкротства
компании-партнера. Giannakis and Louis (18) также рассмотрели
управление рисками в цепочке поставок с помощью агентских моделей,
в данном случае исследуя риски, присущие как спросу на ресурсы, так
и их предложению в период экономических спадов. Агенты также были
специально применены к имитационным моделям, что позволяет
использовать имитационные модели для анализа более сложных проблем.
Caporale et al. (7) представили оптимальную модель финансовых
рынков в условиях кризиса, сочетающую моделирование и теорию игр
через агентов. Родственным подходом является оптимизация роя
частиц, которая была применена Chang Lee et al. (10) для управления
проектными рисками и Kumar et al. (31) для разработки более
надежных конструкций цепочек поставок. Было обнаружено, что этот
подход позволяет моделировать более сложные ситуации. Mizgier et
al. (40) прикладное агентно-ориентированное моделирование цепочек
поставок, моделирующее риск банкротства фирм-участников
саморазвивающихся сетей.
3.8. Анализ инженерных рисков на основе инструментов
оптимизации
Инструменты оптимизации имеют фундаментальное значение для
инженерных усилий по разработке более совершенных систем. (4)
Существование неопределенности нарушает некоторые из требуемых
допущений для многих моделей оптимизации. Наличие риска
подразумевает наличие неопределенности, что затрудняет разработку
моделей оптимизации. Однако были представлены модели оптимизации
инженерных систем. Ahmadi and Kumar (1) представили модель,
учитывающую повышенную вероятность отказа механических систем из-за
старения. Buurman et al. (6) ввел основу для динамического
стратегического планирования инженерных систем с использованием
анализа реальных вариантов, обнаружив, что этот подход имеет
значительные преимущества перед статическим проектированием.
Popovic et al. (49) применили комплексную оптимизацию к системам
обслуживания, связанным с риском.
3.9. Управление знаниями и data mining для управления
рисками стихийных бедствий в промышленности
Управление знаниями - это очень широкая область исследования,
развивающаяся от систем поддержки принятия решений, экспертных
систем и искусственного интеллекта до интеллектуального анализа
данных и бизнес-аналитики. Управление знаниями также включает в
себя рассмотрение того, как неявные знания в организациях могут
быть зафиксированы в компьютерных системах, таких как аргументация
на основе конкретных случаев. Несколько статей можно найти в
применении управления знаниями к управлению промышленными рисками.
Folino et al. (16) использовали сеточные технологии в геонауках
посредством интеллектуального анализа данных для анализа и
управления стихийными бедствиями, такими как оползни,
землетрясения, наводнения и лесные пожары. Их система
предназначалась для оказания помощи в предотвращении стихийных
бедствий и реагировании на них. Li et al. (33) сосредоточились на
прогнозировании стихийных бедствий с использованием знаний
предметной области и пространственных данных для разработки
байесовской сети.
4. Краткое содержание статьи
Документы, собранные в этом специальном выпуске, включают четыре
документа, моделирующих управление рисками: два - об управлении
финансовыми рисками, один - об управлении рисками безопасности и
один - об управлении рисками проекта планирования ресурсов
предприятия. Первый набор документов по управлению финансовыми
рисками охватывает все типичные темы: новый метод торговли акциями
с использованием оценки Kansei, интегрированный с
самоорганизующейся картографической моделью для улучшения системы
торговли акциями, гибридные модели рассуждений на основе конкретных
случаев для прогнозирования неудач финансового бизнеса и фондовый
рынок с агентскими аукционами, основанный на масштабном
анализе.
В статье Динамическое моделирование рисков в проектах
сопровождения ERP с помощью FCM, написанной Cristina Lopez and Jose
Salmeron, изучаются риски в проектах планирования ресурсов
предприятия (ERP). В частности, они построили нечеткие когнитивные
карты (FCM) рисков обслуживания ERP. Главное преимущество FCM
заключается в их способности моделировать сложные явления на основе
мнений экспертов. Этот инструмент моделирует неопределенность и
связанные с ней события, имитируя человеческое мышление.
Предлагаемый инструмент специально моделирует результаты проекта
технического обслуживания ERP и восприятие рисков, а также их
скрытые взаимодействия. Авторы показывают, что FCMS позволяют
разрабатывать упражнения по прогнозированию с помощью
моделирования. Таким образом, специалисты-практики будут оценивать
совместное влияние рисков обслуживания ERP на результаты проекта.
Предлагаемый инструмент поможет специалистам-практикам более
эффективно и проактивно управлять рисками проекта сопровождения
ERP.
В статье Hybrid Kansei-SOM Model using Risk Management and
Company Assessment for Stock Trading, авторами Hai Pham, Eric
Cooper, Thang Cao и Katsuari Kamei, представлен новый метод
торговли акциями с использованием оценки Kansei, интегрированной с
самоорганизующейся моделью карты для совершенствования системы
биржевой торговли. Предлагаемый подход направлен на объединение
нескольких экспертных решений, достижение наибольшей доходности
инвестиций и снижение потерь за счет работы со сложными ситуациями
в динамичной рыночной среде. Оценка Kansei и модели нечеткой оценки
применяются для количественной оценки чувствительности трейдера в
отношении торговли акциями, рыночных условий и факторов фондового
рынка с неопределенными рисками. В оценке Kansei групповая
психология и чувствительность трейдеров измеряются количественно и
представляются нечеткими весами. Наборы данных Kansei и фондового
рынка визуализируются SOM вместе с совокупными экспертными
предпочтениями для того, чтобы найти потенциальные компании,
соответствующие торговым стратегиям в нужное время и исключающие
рискованные акции.
Авторы апробируют предложенный подход в ежедневных биржевых
торгах на фондовых рынках HOSE, HNX (Вьетнам), NYSE и NASDAQ (США).
Авторы показывают, что новый подход применения оценки Kansei
повышает возможности получения инвестиционной отдачи и снижает
потери. Авторы также показывают, что предложенный подход работает
лучше, чем другие современные методы, при работе с различными
рыночными условиями.
В статье Модель анализа рисков безопасности для информационных
систем: причинно-следственные связи факторов риска и анализ
распространения уязвимости, авторами которой являются Nan Feng,
Harry Jiannan Wang, and Minqiang Li, разработана модель анализа
рисков безопасности для выявления причинно-следственных связей
между факторами риска и анализа, сложность и неопределенность
распространения уязвимости. В предложенной модели разработана
байесовская сеть (BN) для одновременного определения факторов риска
и их причинно-следственных связей на основе знаний из наблюдаемых
случаев и экспертов в предметной области. Авторы проводят анализ
распространения уязвимостей безопасности, чтобы определить путь
распространения с наибольшей вероятностью и наибольшей
подверженностью риску на пути. Оптимизация муравьиной колонии
используется в SRAM для установления структуры BN и определения
путей распространения уязвимостей и их вероятностей. SRAM позволяет
организациям создавать планы упреждающего управления рисками
безопасности для информационных систем.
В статье Calibration of the Agent-based Continuous Double
Auction Stock Market Scaling Analysis, авторами которой являются
Yuelei Li, Wei Zhang, Yongjie Zhang, Xiaotao Zhang, and Xiong,
предлагается метод калибровки для фондового рынка с непрерывным
двойным аукционом (CDA) и использованием агентов. масштабного
анализ на основе работы Pasquini and Serva. (47) Авторы
разрабатывают и строят фондовый рынок CDA, основанный на агентах, и
используют тот же торговый механизм, что и китайский фондовый
рынок. Авторы также проводят масштабный анализ абсолютной
доходности, как на искусственных, так и на реальных фондовых рынках
и показывают корреляции волатильности в виде степенных законов на
всех рынках, где показатель степени не является уникальным, и все
такие показатели следуют многомасштабному поведению.
5. Заключительные замечания
Модели бизнес-аналитики применялись и применяются в контексте
управления рисками по всему миру. Они доказали свою эффективность
уже более полувека. Мы надеемся, что этот специальный выпуск дает
представление о том, как можно применять бизнес-аналитику для
большего числа читателей, сталкивающихся с корпоративными
рисками.
Благодарности
Приглашенные редакторы хотели бы поблагодарить всех рецензентов,
включая Patrick Paulson, Karl Leung, Colin Johnson, Daniel Zeng,
Guo H. Huang, Chuen-Min Huang, Ching Huei Huang, Xiaoding Wang,
Chichen Wang, Guixiang Wang, Cheng Wang, Magnus Johnsson, Guangquan
Zhang, Futai Zhang, and David Mercie.
Мы благодарим редактора W. Pedrycz, редактора специального
выпуска P. P. Wang и руководителей журнала за их многочисленные
ценные предложения и усилия по выпуску этого специального выпуска.
Второй автор также признателен за поддержку исследований в виде
гранта NSC 101-2410-H-004-010-MY2.
References
1 A. Ahmadi, U. Kumar, Cost based risk analysis to identify
inspection and restoration intervals of hidden failures subject to
aging, IEEE Transactions on Reliability 60 (1) (2011) 197209.
2. E. Alfaro, N. Garcia, M. Gamez, D. Elizondo, Bankruptcy
forecasting: an empirical comparison of AdaBoost and neural
networks, Decision Support Systems 45 (1) (2008) 110122.
3. M. Baucells, F.H. Heukamp, Probability and time tradeoff,
SSRN working paper, 2009. http://ssrn.com/abstract=970570
4. Y. Ben-Haim, Doing our best: optimization and the management
of risk, Risk Analysis: An International Journal 32 (8) (2012)
13261332.
5. M. Bevilacqua, F.E. Ciarapica, G. Giacchetta, Data mining for
occupational injury risk: a case study, International Journal of
Reliability, Quality & Safety Engineering 17 (4) (2010) 351380.
6. J. Buurman, S. Zhang, V. Babovic, Reducing risk through real
options in systems design: the case of architecting a maritime
domain protection system, Risk Analysis: An International Journal
29 (3) (2009) 366379.
7. G.M. Caporale, A. Serguieva, H. Wu, Financial contagion:
evolutionary optimization of a multinational agent-based model,
Intelligent Systems in Accounting, Finance & Management 16 (1/2)
(2009) 111125.
8. R.C. Caracota, M. Dimitriu, M.R. Dinu, Building a scoring
model for small and medium enterprises, Theoretical & Applied
Economics 17 (9) (2010) 117128.
9. M.R.F. Castell, L.B. Dacuycuy, Exploring the use of exchange
market pressure and RMU deviation indicator for early warning
system (EWS) in the ASEAN+3 region, DLSU Business & Economics
Review 18 (2) (2009) 130.
10. K. Chang Lee, N. Lee, H. Li, A particle swarm
optimization-driven cognitive map approach to analyzing information
systems project risk, Journal of the American Society for
Information Science & Technology 60 (6) (2009) 12081221.
11. Y.C. Chen, S.C. Chen, M.Y. Huang, C.L. Tsai, Application of
six sigma DMAIC methodology to reduce financial risk: a study of
credit card usage in Taiwan, International Journal of Management 29
(2012) 166176.
12. F. Ciampi, N. Gordini, Small enterprise default prediction
modeling through artificial neural networks: an empirical analysis
of Italian small enterprises, Journal of Small Business Management
51 (1) (2013) 2345.
13. D. Dalcher, Why the pilot cannot be blamed: a cautionary
note about excessive reliance on technology, International Journal
of Risk Assessment and Management 7 (3) (2007) 350366.
14. A.L. Fletcher, Reinventing the pig: the negotiation of risks
and rights in the USA xenotransplantation debate, International
Journal of Risk Assessment and Management 7 (3) (2007) 341349.
15. C. Flores, Management of catastrophic risks considering the
existence of early warning systems, Scandinavian Actuarial Journal
2009 (1) (2009) 3862.
16. G. Folino, A. Forestiero, G. Papuzzo, G. Spezzano, A grid
portal for solving geoscience problems using distributed knowledge
discovery services, Future Generation Computer Systems 26 (1)
(2010) 8796.
17. A. Ghadge, S. Dani, R. Kalawsky, Supply chain risk
management: present and future scope, International Journal of
Logistics Management 23 (3) (2012) 313339.
18. M. Giannakis, M. Louis, A multi-agent based framework for
supply chain risk management, Journal of Purchasing & Supply
Management 17 (1) (2011) 2331.
19. D.R. Gnyawali, B. Park, Co-opetition and technological
innovation in small and medium-sized enterprises: a multilevel
conceptual model, Journal of Small Business Management 47 (3)
(2009) 308330.
20. S.S. Groth, J. Muntermann, Intraday market risk management
approach based on textual analysis, Decision Support Systems 50 (4)
(2011) 680691.
21. P. Gurny, T. Tichy, Estimation of future PD of financial
institutions on the basis of scoring model, in: 12th International
Conference on Finance & Banking: Structural & Regional Impacts of
Financial Crises, 2009, pp. 215228.
22. C. Holton, Identifying disgruntled employee systems fraud
risk through text mining: a simple solution for a multi-billion
dollar problem, Decision Support Systems 46 (4) (2009) 853864.
23. Y. Hua, On early-warning system for Chinese real estate,
International Journal of Marketing Studies 3 (3) (2011) 189193.
24. M. Jans, N. Lybaert, K. Vanhoof, Internal fraud risk
reduction: results of a data mining case study, International
Journal of Accounting Information Systems 11 (1) (2010) 1741.
25. X.H. Jin, G. Zhang, Modelling optimal risk allocation in PPP
projects using artificial neural networks, International Journal of
Project Management 29 (5) (2011) 591603.
26. P. Jorion, Risk management lessons from the credit crisis,
European Financial Management 15 (5) (2009) 923933.
27. N. Julka, R. Srinivasan, I. Karimi, Agent-based supply chain
management-1: framework, Computers & Chemical Engineering 26 (12)
(2002) 17551769.
28. P.G.W. Keen, M.S. Scott Morton, Decision Support Systems: An
Organizational Perspective, Addison-Wesley, Reading, MA, 1978.
29. R.K. Kozhikode, J. Li, Political pluralism, public policies,
and organizational choices: banking branch expansion in India,
19482003, Academy of Management Journal 55 (2) (2012) 339359.
30. A. Krstevska, Early warning systems: testing in practice,
IUP Journal of Financial Risk Management 9 (2) (2012) 722.
31. S.K. Kumar, M.K. Tiwari, R.F. Babiceanu, Minimisation of
supply chain cost with embedded risk using computational
intelligence approaches, International Journal of Production
Research 48 (13) (2010) 37173739.
32. N. Lakemond, T. Magnusson, G. Johansson, et al, Assessing
interface challenges in product development projects,
Research-Technology Management 56 (1) (2013) 4048.
33. L. Li, J. Wang, H. Leung, C. Jiang, Assessment of
catastrophic risk using Bayesian network constructed from domain
knowledge and spatial data, Risk Analysis: An International Journal
30 (7) (2010) 11571175.
34. W. Liang, C. Huang, Agent-based demand forecast in
multi-echelon supply chain, Decision Support Systems 42 (1) (2006)
390407.
35. M. Lin, X. Ke, A.B. Whinston, Vertical differentiation and a
comparison of on-line advertising models, Journal of Management
Information Systems 29 (1) (2012) 195236.
36. P. Lin, J. Chen, FuzzyTree crossover for multi-valued stock
valuation, Information Sciences 177 (5) (2007) 11931203.
37. K.S. Markel, L.A. Barclay, The intersection of risk
management and human resources: an illustration using genetic
mapping, International Journal of Risk Assessment and Management 7
(3) (2007) 326340.
38. D. Martens, B. Baesens, T. Van Gestel, J. Vanthienen,
Comprehensible credit scoring models using rule extraction from
support vector machines, European Journal of Operational Research
183 (3) (2007) 14661476.
39. J. Merrick, G.S. Parnell, A comparative analysis of PRA and
intelligent adversary methods for counterterrorism risk management,
Risk Analysis: An International Journal 31 (9) (2011) 14881510.
40. K.J. Mizgier, S.M. Wagner, J.A. Holyst, Modeling defaults of
companies in multistage supply chain networks, International
Journal of Production Economics 135 (1) (2012) 1423.
41. S. Murayama, K. Okuhara, J. Shibata, H. Ishii, Data mining
for hazard elimination through text information in accident report,
Asia Pacific Management Review 16 (1) (2011) 6581.
42. J. Nash, Equilibrium points in n-person games, Proceedings
of the National Academy of Sciences 36 (1) (1950) 4849.
43. R. Nateghi, S.D. Guikema, S.M. Quiring, Comparison and
validation of statistical methods for predicting power outage
durations in the event of hurricanes, Risk Analysis: An
International Journal 31 (12) (2011) 18971906.
44. D.L. Olson, Decision Aids for Selection Problems, Springer,
NY, 1996.
45. D.L. Olson, D. Wu, Enterprise Risk Management Models,
Springer, 2010.
46. S. Otim, K.E. Dow, V. Grover, J.A. Wong, The impact of
information technology investments on downside risk of the firm:
alternative measurement of the business value of IT, Journal of
Management Information Systems 29 (1) (2012) 159194.
47. M. Pasquini, M. Serva, Multiscale behaviour of volatility
autocorrelations in a financial market, Economics Letters 65 (3)
(1999) 275279.
48. M. Poon, From new deal institutions to capital markets:
commercial risk scores and the making of subprime mortgage finance,
Accounting, Organizations & Society 34 (5) (2009) 654674.
49. V.M. Popovic, B.M. Vasic, B.B. Rakicevic, G.S. Vorotovic,
Optimisation of maintenance concept choice using risk-decision
factor A case study, International Journal of Systems Science 43
(10) (2012) 19131926.
50. L.A. Reilly, O. Courtenay, Husbandry practices, badger sett
density and habitat composition as risk factors for transient and
persistent bovine tuberculosis on UK cattle farms, Preventive
Veterinary Medicine 80 (2-3) (2007) 129142.
51. N. Schneidewind, Applying neural networks to software
reliability assessment, International Journal of Reliability,
Quality & Safety Engineering 17 (4) (2010) 313329.
52. M.M. Shiri, M.T. Amini, M.B. Raftar, Data mining techniques
and predicting corporate financial distress, Interdisciplinary
Journal of Contemporary Research in Business 3 (12) (2012)
6168.
53. A. Silvestri, F. De Felice, A. Petrillo, Multi-criteria risk
analysis to improve safety in manufacturing systems, International
Journal of Production Research 50 (17) (2012) 48064821.
54. D.H. Smaltz, R. Carpenter, J. Saltz, Effective IT governance
in healthcare organizations: a tale of two organizations,
International Journal of Healthcare Technology Management 8 (1/2)
(2007) 2041.
55. I. Smeureanu, G. Ruxanda, A. Diosteanu, C. Delcea, L.A.
Cotfas, Intelligent agents and risk based model for supply chain
management, Technological & Economic Development of Economy 18 (3)
(2012) 452469.
56. R.H.J. Sprague, E.D. Carlson, Building Effective Decision
Support Systems, Prentice-Hall, Englewood Cliffs, NJ, 1982.
57. G. Suder, D.W. Gillingham, Paradigms and paradoxes of
agricultural risk governance, Internat Journal of Risk Assess
Manage 7 (3) (2007) 444457.
58. L. Warenski, Relative uncertainty in term loan projection
models: what lenders could tell risk managers, Journal of
Experimental & Theoretical Artificial Intelligence 24 (4) (2012)
501511.
59. D. Wu, D.L. Olson, Introduction to the special section on
optimizing risk management: methods and tools, Human and Ecological
Risk Assessment 15 (2) (2009) 220226.
60. D. Wu, D.L. Olson, Enterprise risk management: coping with
model risk in a large bank, Journal of the Operational Research
Society 61 (2) (2010) 179190.
61. K. Xie, J. Liu, H. Peng, G. Chen, Y. Chen, Early-warning
management of inner logistics risk in SMEs based on label-card
system, Production Planning & Control 20 (4) (2009) 306319.
62. M. Yazici, Combination of discriminant analysis and
artificial neural network in the analysis of credit card customers,
European Journal of Finance & Banking Research 4 (4) (2011)
110.
63. L. Zhao, Y. Jiang, A game theoretic optimization model
between project risk set and measurement, International Journal of
Information Technology & Decision Making 8 (4) (2009) 769786.
Размышления переводчика
Естественно понятно, что за созданием пространства метрик
BI-Аналитики обращаются компании, которым сложные информационные
системы управления не очень-то подходят, так как операционные
процессы хорошо просматриваемые и менеджменту достаточно
отслеживать определенный набор индикаторов.
Когда указанные компании обращаются к BI-аналитику, то
предоставляют все данные, которые они мониторят и других данных
нет. На основе имеющихся данных BI-аналитик создает пространство
метрик.
Это пространство может не только отслеживать текущие значения,
но и также в ретроспективе. Простой ответ менеджмента на вопрос:
Какие периоды в прошлой своей деятельности Вы считаете
напряженными, кризисными? дают интервалы на которых, отследив
показания метрик, можно с помощью скоринговых инструментов
вычленить критические значения метрик. Далее привязываем полученные
граничные значения к текущему мониторингу по принципу: нормально -
зеленый, опасно - красный и пользователь получает работающий
инструмент с детализацией участков, требующих обратить на них
внимание.
Не спорю, что вероятность реализовать универсальную модель,
практически, равна нулю, так как меняются условия деятельности
организации, но и само пространство бизнес-метрик не вечно. С
другой стороны, трудоемкость процесса реализации данной фичи в
каждом случае непредсказуема. Но, в принципе, просчитывается эффект
для заказчика от снижения рисков деятельности предприятия, то есть
можно определить стоимость данных индикаторов.
Обратимся к прогнозу Reports and Data где объем рынка
анализа рисков к 2026 в объеме 65 млрд.долл.

Чтобы представить в сравнении этот объем, скажу, что они
прогнозируют:
- объем рынка автомобильных шин на 2028 год в объеме 118,09 млрд.долл.;
- объем рынка альтернативных двигателей для автомобилей на 2027
год в объеме 541,53 млрд.долл.




















 с множеством вершин
с множеством вершин  и множеством ребер
и множеством ребер  , что определяет гипонимические
связи между семантическими понятиями. Другими словами, ребро
, что определяет гипонимические
связи между семантическими понятиями. Другими словами, ребро
 означает что
означает что  является подклассом
является подклассом  . Тогда классы являются вершинами
такого графа
. Тогда классы являются вершинами
такого графа  . Пример графа
представлен ниже:
. Пример графа
представлен ниже:
 , рассчитываемую по формуле
, рассчитываемую по формуле
 , где под высотой имеется в виду самый длинный
путь от текущей вершины до
листа.
, где под высотой имеется в виду самый длинный
путь от текущей вершины до
листа.  двух вершин это ближайший предок к
этим двум вершинам. Так как
двух вершин это ближайший предок к
этим двум вершинам. Так как  ограничено между 0 и 1, авторы
определили меру семантической близости между двумя семантическими
понятиями как
ограничено между 0 и 1, авторы
определили меру семантической близости между двумя семантическими
понятиями как  .
. для всех классов
для всех классов  , так, чтобы скалярное
произведение векторов соответствующих классов было равно мере их
похожести:
, так, чтобы скалярное
произведение векторов соответствующих классов было равно мере их
похожести:














































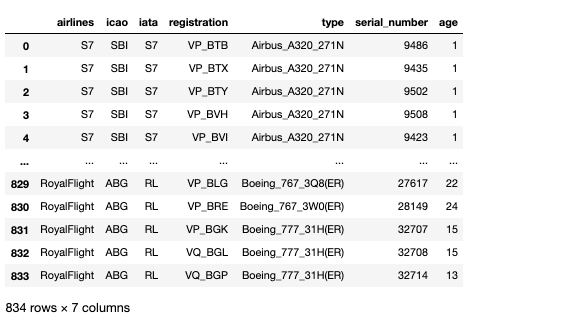
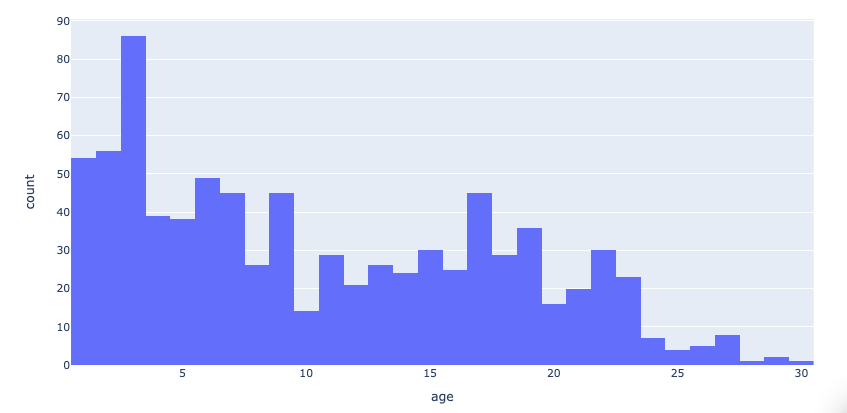

 Описательные статистики значений возраста,
количество воздушных судов в разрезе каждой авикомпании.
Описательные статистики значений возраста,
количество воздушных судов в разрезе каждой авикомпании.

 Количество часто встречающихся авиалайнеров
Количество часто встречающихся авиалайнеров















 Рис.1. Преобразование данных в аналитику в
BI-системах
Рис.1. Преобразование данных в аналитику в
BI-системах
 Рис 2. Для каких задач внедряют BI-системы
Рис 2. Для каких задач внедряют BI-системы
 Рис 3.
Преимущества BI-систем
Рис 3.
Преимущества BI-систем
 Рис.4.
Объем рынка BI-систем
Рис.4.
Объем рынка BI-систем
 Рис
5. BI-системы как часть бизнеса
Рис
5. BI-системы как часть бизнеса
 Рис 6. Эффекты от внедрения BI-систем для компаний
Рис 6. Эффекты от внедрения BI-систем для компаний
 Рис.7. Интерактивность современных BI-систем
Рис.7. Интерактивность современных BI-систем
 Рис.8. Разница между традиционной и
self-service BI-системами
Рис.8. Разница между традиционной и
self-service BI-системами
 Рис.9. Эволюция аналитики в BI-системы и
в Augmented Business Intelligence
Рис.9. Эволюция аналитики в BI-системы и
в Augmented Business Intelligence
 Рис.10. Инновационность ABI-систем
Рис.10. Инновационность ABI-систем
 Рис.11. Отличия BI-системы от ABI-системы
и ее преимущества
Рис.11. Отличия BI-системы от ABI-системы
и ее преимущества
 Рис.12. Тренды в развитии BI-систем
Рис.12. Тренды в развитии BI-систем
 Рис.13. Концепция DIKW
Рис.13. Концепция DIKW
 Рис. 14. Визуальное потребление информации
Рис. 14. Визуальное потребление информации
 Рис.15.
Инструментарий DataViz
Рис.15.
Инструментарий DataViz
 Рис.16. Преимущества 3D-визуализации
Рис.16. Преимущества 3D-визуализации
 Рис.17. Пример 3D визуализации данных на
карте для визуализации данных в проекте с Ingrad
Рис.17. Пример 3D визуализации данных на
карте для визуализации данных в проекте с Ingrad
 Рис.18. Пример интерактивных BIM-моделей зданий
Рис.18. Пример интерактивных BIM-моделей зданий
 Рис. 19. Фокусирование внимания
пользователя на данных с помощью анимации
Рис. 19. Фокусирование внимания
пользователя на данных с помощью анимации
 Рис.20. Феномен data storytelling
Рис.20. Феномен data storytelling
 Рис.21. Уникальные черты и roadmap
разработанной кроссплатформенной BI-системы для Ingrad
Рис.21. Уникальные черты и roadmap
разработанной кроссплатформенной BI-системы для Ingrad



![Как изменяется гистограмма при изменении количества интервалов. [Рисунок автора]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/7f1/71f/f40/7f171ff405334ac351d813ecfe7ca455.png "Как изменяется гистограмма при изменении количества интервалов. [Рисунок автора]") Как изменяется гистограмма при изменении
количества интервалов. [Рисунок автора]
Как изменяется гистограмма при изменении
количества интервалов. [Рисунок автора]
![Как меняется гистограмма при изменении максимального значения. [Рисунок автора]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/29c/73d/22f/29c73d22f14a324968ab201e3bea41cc.png "Как меняется гистограмма при изменении максимального значения. [Рисунок автора]") Как меняется гистограмма при изменении
максимального значения. [Рисунок автора]
Как меняется гистограмма при изменении
максимального значения. [Рисунок автора]
![Те же данные, разная ширина интервала. На левом графике невозможно обнаружить высокую концентрацию нулей. [Рисунок автора]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/568/6cc/b23/5686ccb23bbd5f013cc5f50f419bb43b.png "Те же данные, разная ширина интервала. На левом графике невозможно обнаружить высокую концентрацию нулей. [Рисунок автора]") Те же данные, разная ширина интервала. На
левом графике невозможно обнаружить высокую концентрацию нулей.
[Рисунок автора]
Те же данные, разная ширина интервала. На
левом графике невозможно обнаружить высокую концентрацию нулей.
[Рисунок автора]
![Слева непрерывная переменная. Справа дискретная переменная. Однако на верхних графиках они выглядят одинаково. [Рисунок автора]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/9b4/66d/054/9b466d0547e9bbd529cab99fd58aba6f.png "Слева непрерывная переменная. Справа дискретная переменная. Однако на верхних графиках они выглядят одинаково. [Рисунок автора]") Слева непрерывная переменная. Справа
дискретная переменная. Однако на верхних графиках они выглядят
одинаково. [Рисунок автора]
Слева непрерывная переменная. Справа
дискретная переменная. Однако на верхних графиках они выглядят
одинаково. [Рисунок автора]
![Сравнение гистограмм. [Рисунок автора]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/460/df1/ed4/460df1ed42f1a890f7b732953586512b.png "Сравнение гистограмм. [Рисунок автора]") Сравнение гистограмм. [Рисунок автора]
Сравнение гистограмм. [Рисунок автора]
![График кумулятивного распределения максимальной частоты сердечных сокращений. [Рисунок автора]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/5be/acf/f95/5beacff9594412dff001cd02e1ea2e82.png "График кумулятивного распределения максимальной частоты сердечных сокращений. [Рисунок автора]") График кумулятивного распределения
максимальной частоты сердечных сокращений. [Рисунок автора]
График кумулятивного распределения
максимальной частоты сердечных сокращений. [Рисунок автора]
![Сравнение распределений в CDP. [Рисунок автора]](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/c14/de3/22d/c14de322da1e53ae4455357e8da017b5.png "Сравнение распределений в CDP. [Рисунок автора]") Сравнение распределений в CDP. [Рисунок автора]
Сравнение распределений в CDP. [Рисунок автора]













 Данные объема продаж, выручки и средней
цены продажи товаров категории "Климатическая техника" маркетплейса
Ozon, период с 19.04 - 19.05.21, данные сервиса аналитики
маркетплейсов SelerFox
Данные объема продаж, выручки и средней
цены продажи товаров категории "Климатическая техника" маркетплейса
Ozon, период с 19.04 - 19.05.21, данные сервиса аналитики
маркетплейсов SelerFox
 Анализ категории Климатическая техника
маркетплейса Ozon, период с 19.04 - 19.05.2021, данные сервиса
аналитики SellerFox
Анализ категории Климатическая техника
маркетплейса Ozon, период с 19.04 - 19.05.2021, данные сервиса
аналитики SellerFox
 Анализ категории Климатическая техника
маркетплейса Ozon, период с 19.04 - 19.05.2021, данные сервиса
аналитики SellerFox
Анализ категории Климатическая техника
маркетплейса Ozon, период с 19.04 - 19.05.2021, данные сервиса
аналитики SellerFox
 Данные по объему продаж, выручке и средней
стоимость продажи товаров категории Климатическая техника
маркетплейса Яндекс.Маркет, период с 19.04 - 19.05.2021, данные
сервиса аналитики SellerFox
Данные по объему продаж, выручке и средней
стоимость продажи товаров категории Климатическая техника
маркетплейса Яндекс.Маркет, период с 19.04 - 19.05.2021, данные
сервиса аналитики SellerFox
 Анализ категории Климатическая техника
маркетплейса Яндекс.Маркет, период с 19.04 - 19.05.2021, данные
сервиса аналитики SellerFox
Анализ категории Климатическая техника
маркетплейса Яндекс.Маркет, период с 19.04 - 19.05.2021, данные
сервиса аналитики SellerFox
 Анализ категории Климатическая техника
маркетплейса Яндекс.Маркет, период с 19.04 - 19.05.2021, данные
сервиса аналитики SellerFox
Анализ категории Климатическая техника
маркетплейса Яндекс.Маркет, период с 19.04 - 19.05.2021, данные
сервиса аналитики SellerFox
 Анализ категории Климатическая техника
маркетплейса Яндекс.Маркет, период с 19.04 - 19.05.2021, данные
сервиса аналитики SellerFox
Анализ категории Климатическая техника
маркетплейса Яндекс.Маркет, период с 19.04 - 19.05.2021, данные
сервиса аналитики SellerFox
 Анализ категории Климатическая техника
маркетплейса Яндекс,Маркет, период с 19.04 - 19.05.2021, данные
сервиса аналитики SellerFox
Анализ категории Климатическая техника
маркетплейса Яндекс,Маркет, период с 19.04 - 19.05.2021, данные
сервиса аналитики SellerFox
 Данные по объему продаж, выручке и средней
стоимость продажи товаров категории Климатическая техника
маркетплейса Wildberries, период с 19.04 - 19.05.2021, данные
сервиса аналитики SellerFox
Данные по объему продаж, выручке и средней
стоимость продажи товаров категории Климатическая техника
маркетплейса Wildberries, период с 19.04 - 19.05.2021, данные
сервиса аналитики SellerFox
 Анализ категории Климатическая техника
маркетплейса Wildberries, период с 19.04 - 19.05.2021, данные
сервиса аналитики SellerFox
Анализ категории Климатическая техника
маркетплейса Wildberries, период с 19.04 - 19.05.2021, данные
сервиса аналитики SellerFox Анализ категории Климатическая техника
маркетплейса Wildberries, период с 19.04 - 19.05.2021, данные
сервиса аналитики SellerFox
Анализ категории Климатическая техника
маркетплейса Wildberries, период с 19.04 - 19.05.2021, данные
сервиса аналитики SellerFox Анализ категории Климатическая техника
маркетплейса Wildberries, период с 19.04 - 19.05.2021, данные
сервиса аналитики SellerFox
Анализ категории Климатическая техника
маркетплейса Wildberries, период с 19.04 - 19.05.2021, данные
сервиса аналитики SellerFox






























{kind=link}