В предыдущей статье я писал про формирование векторной графики SVG
с диаграммой телефонных звонков, напоминающей диаграмму Ганта.
Информацию о телефонных звонках я брал из детализации, которую
скачивал через личный кабинет на сайте мобильного оператора. Дело
было почти четыре года назад. В настоящее время у меня появилась
идея сделать проект посложнее: построить мультисессию в звуковом
редакторе Adobe Audition 1.5 из аудиозаписей телефонных разговоров.
При этом эти аудиозаписи расположить в мультисессии строго в
соответствии по времени, а так же по датам, которым будут
соответствовать треки. При этом визуально такая мультисессия будет
напоминать ту же диаграмму, что и строилась в предыдущей статье.
Кроме того, будет возможность оперативного масштабирования и
прослушивания записей телефонных разговоров, как в миксе, так и в
режиме соло по дням.
Мультисессию я решил строить из аудиозаписей, накопленных за один
календарный месяц во избежание лишних нагромождений для Adobe
Audition. Вручную такую сессию, конечно же, построить можно, но это
долгая и кропотливая работа. Главный интерес данной задачи
автоматизировать построение мультисессии программными средствами. А
точнее, написать программу, которая на основе списка файлов
аудиозаписей сформирует файл SES мультисессии Adobe Audition. Для
тех, кто не в курсе: мультисессия, кратко говоря, это проект,
состоящий из множества различных аудиозаписей, распределённых во
времени и по трекам (дорожкам) и предназначенный для создания микса
из них.
Прежде всего, стоит оговорить, каким образом я получаю файлы
аудиозаписей телефонных разговоров. Ни для кого не секрет, что
современные смартфоны обладают возможностью записывать телефонные
звонки различными инструментами, как встроенными в систему, так и
сторонними. Лично я пользуюсь планшетом Lenovo TAB3 (на процессоре
MT8735P). Аппарат позволяет совершать аудиозаписи в ручном режиме в
сжатом формате, получая на выходе файлы с расширением 3gpp. Записи
получаются стереофоническими с разделёнными каналами: в одном
канале пишется голос абонента, а в другом свой голос. Сжатый формат
аудиозаписей сказывается на их искажении при воспроизведении. В
связи с этим я пользуюсь сторонними приложениями для аудиозаписи,
которых существует бесчисленное множество. Одно из приложений,
которое мне понравилось больше всего Record My Call. Данное
приложение записывает звонки в автоматическом режиме, имеет
множество настроек, связанных, в частности, с выбором формата и
качества аудиозаписи. А также, в качестве бонуса, приложение имеет
неплохой очень удобный встроенный журнал звонков, который
сохраняется в файл базы данных db (рис. 1).
 Рис. 1. Журнал звонков в приложении Record My Call.
Рис. 1. Журнал звонков в приложении Record My Call.
Самые лучшие для качества звучания параметры аудиозаписи WAV 8000Hz
16bit Stereo. При таких настройках запись не имеет искажений,
звучит чётко, хоть и занимает в памяти больше места. Приложение
настроено таким образом, чтобы аудиозапись начиналась автоматически
ещё до начала телефонного разговора: при поступлении входящего
вызова до снятия трубки или при начале набора номера во время
гудков. То есть, пропущенные и неотвеченные вызовы также
записываются. Можно настроить так, чтобы записывался только
разговор. Формат имени файла аудиозаписи также настраивается. В
своём случае я настроил так, как показано на рисунке 2.
 Рис. 2. Настройка формата имени файла в Record My Call.
Рис. 2. Настройка формата имени файла в Record My Call.
Во время разработки программы формирования мультисессии необходимо
будет брать информацию о дате и времени аудиозаписи телефонного
звонка. Данная информация будет браться из имени файла по
фиксированным позициям.
Прежде чем браться за формирование файла SES мультисессии, нужно
разобраться, как такой файл устроен. Документации по данному
формату, разумеется, нигде нет, поэтому мне пришлось разгадывать
собственными силами, опираясь на личный опыт и знания. Данный файл
не является текстовым, поэтому в Блокноте его открывать толку мало.
На помощь приходит WinHex шестнадцатеричный редактор. Я уже писал
ряд статей по работе с двоичными данными и расшифровке информации,
в частности, статья о написании программы перепаковки видео
264-avi. Там я более-менее подробно написал об устройстве файла
формата avi.
Сначала я создал простую произвольную мультисессиию в Adobe
Audition 1.5, состоящую из одного трека и одного аудиофайла (рис.
3), сохранив её в файл с расширением ses. Файл получился размером
2422 байта. Затем данный файл я открыл в WinHex (рис. 4).
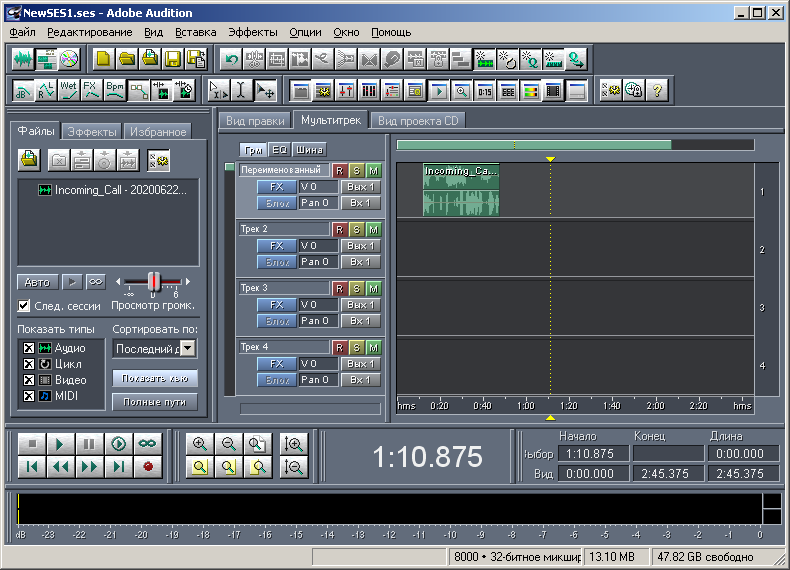 Рис. 3. Вид мультисессии в Adobe Audition 1.5 Пример 1.
Рис. 3. Вид мультисессии в Adobe Audition 1.5 Пример 1.
 Рис. 4. Файл мультисессии, открытый в WinHex.
Рис. 4. Файл мультисессии, открытый в WinHex.
На первый взгляд вообще ничего не понятно. В символьной части окна
можно увидеть смысловые слова COOLNESS, hdr, Мастер. Если полистать
документ ниже, можно увидеть текст, содержащий полный путь к файлу
(причём, в двух вариантах), который используется в мультисессии.
Это показано на рисунке 5 и обведено зелёным цветом. Сразу же
бросаются в глаза короткие смысловые слова, обведённые на том же
рисунке в красную рамку.
 Рис. 5. Байты путей к аудиофайлам мультисессии.
Рис. 5. Байты путей к аудиофайлам мультисессии.
Просматривая более внимательно данный документ от начала до конца,
я заметил ещё несколько других коротких смысловых слов. Так же я
заметил, что длина любого смыслового слова кратна четырём. Видимо,
эти слова являются заголовками блоков, из которых состоит весь файл
мультисессии. Мне это напомнило RIFF-структуру avi или wav файла,
состоящего из блоков, в которых также есть заголовки таких же
размеров. После таких заголовков там следовало 32-битное число (4
байта), обозначающее размер текущего блока. Принимая этот факт во
внимание, я решил проверить, работает ли этот принцип для файла
ses? Оказалось, что в случае с форматом ses это так же прокатывает
(рис. 6).
 Рис. 6. Схожесть с RIFF структурой (на примере блока
WLST).
Рис. 6. Схожесть с RIFF структурой (на примере блока
WLST).
Первое слово COOLNESS в файле ses, видимо, служит главным
заголовком и признаком типа данного файла. Следующие 4 байта размер
содержимого, что размещено далее, вплоть до конца файла. То есть,
если внимательно посчитать, это значение на 12 байт меньше, чем
размер всего файла. А дальнейшее содержимое состоит из совокупности
различных блоков. Блок имеет заголовок из четырёх или восьми байт,
затем следует 4 байта, обозначающие размер данного блока, а уже
после них следует содержимое данного блока. У некоторых блоков я
выявил наличие субблоков, но об этом будет сказано по ходу более
подробного описания каждого блока. В данном файле, что в примере, я
насчитал 17 блоков, они перечислены в таблице на рисунке 7.
 Рис. 7. Список блоков, входящих в состав мультисессии.
Рис. 7. Список блоков, входящих в состав мультисессии.
Как видно из таблицы, некоторая одна и та же информация
представлена в разных вариантах разными блоками. Наверно это
сделано для совместимости различных версий программы. Забегая
вперёд, зелёным цветом выделены те блоки, без которых
представленная в примере мультисессия существовать не может. Серым
цветом выделены два блока, размером 4 байта, которые в данной
сессии присутствуют фиктивно. Действительно, у меня стал вопрос: а
что будет, если выкинуть часть блоков из файла? Ведь мне, к
примеру, не нужна информация о метрономе и темпе, и огибающие на
клипах (точнее, на одном клипе) в моём простом примере отсутствуют.
Огибающие это кривые поверх аудиоклипа, задающие динамику
параметров звучания (громкость, баланс) во времени. Я
последовательно начал вырезать блоки из данного файла, не забывая
пересчитывать и корректировать значение после слова COOLNESS. В
итоге мультисессия успешно открывалась при наличии как минимум пяти
блоков, выделенных зелёным цветом. В сессии присутствуют два блока
списка аудиофайлов. Можно было оставить любой из них. Мне больше
симпатичен второй вариант (блок LISTFILE), так как в первом
варианте (блок WLST) в описании пути к файлу приходится по два
байта на символ. Возможно, это сделано для расширенного алфавита
символов, но мне достаточно стандартного алфавита ASCII. Тем более,
русские символы, как видно, отлично поддерживаются. Описание
аудиоклипов представлено в трёх вариантах. Я выбрал первый вариант
(блок bk20), потому что в его описании я разобрался быстрее
всего.
Мультисессия из аудиозаписей телефонных разговоров по своей
сложности будет схожей с мультисессией, представленной в данном
примере. Единственное отличие она будет объёмнее: число аудиофайлов
будет достаточно большим, а число треков будет равняться числу дней
в месяце. Для такой мультисессии другие какие-либо навороты не
нужны. Размеры блоков hdr и stat статичны и всегда составляют 936 и
40 байт соответственно, независимо от размера мультисессии. Размеры
блоков trks и bk20 зависят от количества треков и аудиоклипов в
мультисессии соответственно. А вот размер блока LISTFILE самый
непредсказуемый: он зависит не только от количества аудиофайлов в
мультисессии, но и от длины их имён и путей их расположения.
Расшифровать и составить полное описание блоков файла мультисессии
достаточно трудоёмкая задача. Поэтому я расшифровал информацию
частично, обращая внимание только на те байтовые участки, которые
необходимо учитывать при формировании мультисессиси упрощённого
содержания. В данной статье я приведу описание содержимого каждого
блока, которое я сумел расшифровать.
В содержимом блока заголовка мультисессии hdr (в конце именно
пробел) ключевыми байтами являются первые 12 байт, то есть, 3 слова
по 4 байта (рис. 8). Первое слово частота дискретизации семплов в
мультисессии. Для моей мультисессии это значение составляет 8000 Гц
(0x1F40). На рисунке 8 оно выделено зелёной заливкой. Напомню, что
байты в словах для числовых значений читаются задом наперёд. Второе
слово продолжительность (длина) мультисессии, выраженная в
количестве семплов (оранжевая заливка на рисунке). В
рассматриваемом примере это значение составляет 0x1A365E (1717854).
Если перевести в минуты, то получится 1717854/8000/60, что
составляет примерно три с половиной минуты. Так оно и есть: при
минимальном масштабе мультисессия имеет именно такую
продолжительность. А для мультисессии из записей телефонных вызовов
продолжительность должна составлять сутки, или 24*3600*8000 =
691200000 = 0x2932E000 семплов. При таком раскладе, кстати сказать,
текущее время воспроизведения мультисессии на панели внизу,
являющееся относительным временем, будет в точности совпадать со
значением абсолютного времени текущего телефонного звонка (или
группы звонков по дням). Следующее слово, выделенное жёлтой
заливкой, обозначает количество аудиоклипов в мультисессии. В
примере это значение равняется единице, но в случае с телефонными
звонками число таких клипов будет равняться числу аудиофайлов.
Забегая вперёд, последнее сказанное не совсем корректно. На самом
деле число аудиоклипов может быть чуть больше, чем число
аудиофайлов. На один файл может прийтись два клипа в том случае,
если наступили новые сутки во время телефонного разговора. В таком
случае придётся делать перенос записи на новый трек, и одним клипом
обойтись не получится. Но такие случаи на практике встречаются
редко, так как переход на новые сутки приходится на ночное время,
когда активность телефонных звонков минимальна. Кстати, этот момент
я не стал учитывать при формировании SVG диаграммы в предыдущей
статье. После слова значения количества блоков следует, вероятнее
всего полуслово из двух байт 0x0020, или 32 в десятичном виде. Его
тоже можно было выделить цветной заливкой, так как, скорее всего,
оно означает разрядность микширования. В Adobe Audition в статусной
строке внизу указано: 8000 Гц, 32-битное микширование. Кроме трёх
самых необходимых слов содержимого hdr присутствуют другие
непонятные байты. К примеру, слово Мастер я даже не знаю, к чему
относится. Видимо, это название главной шины микширования. Но самые
интересные группы байт я обвёл в серую рамку. Дело в том, что
именно такая последовательность часто встречается и в других блоках
файла мультисессии. Я не случайно объединил в группу именно 8 байт,
так как, скорее всего, это вещественный тип данных. В частности,
данная константа 00 00 00 00 00 00 F0 3F HEX редактором в типе
Double интерпретируется как 1.0e+0, то есть, как единица. Скорее
всего это значения уровней громкости и прочих крутилок, но заданные
не в децибелах, а в виде коэффициета. Сразу скажу, что все байты
любого блока, которые мне не удалось распознать (или не было в этом
необходимости) будут записываться в формируемый файл мультисессии
без изменений, как в примере.
 Рис. 8. Часть байтов блока заголовка hdr .
Рис. 8. Часть байтов блока заголовка hdr .
Блок stat текущего состояния мультисессии (самый короткий) я решил
не изучать. Я создал другую образцовую мультисессию из одного
аудиофайла, растянул её на продолжительность в 24 часа и сделал её
полный вид (масштаб) по горизонтали. А по вертикали вид треков
отмасштабировал так, чтобы при развёрнутом окне Adobe Audition на
FullHD экране помещался 31 трек. Это максимальное число дней в
одном месяце. Курсор мультисессии расположил в самом начале. Затем
я сохранил данную мультисессию в другой файл, после чего вытащил
оттуда блок stat со всеми его заголовками. Эти байты я сохранил в
файл stat_31_full.BLK для дальнейшего использования при разработке
программы. Вид содержимого такого файла представлен на рисунке 9.
Размер данного файла составил 48 байт (40 байт содержимого блока +
4 байта заголовка + 4 байта описания размера содержимого).
 Рис. 9. Байты блока состояния stat для моей
мультисессии.
Рис. 9. Байты блока состояния stat для моей
мультисессии.
Для более наглядного описания следующих трёх блоков по ходу
написания данной статьи я решил создать мультисессию посложнее,
состоящую из двух треков, двух файлов и трёх клипов (рис. 10).
Первый файл Incoming_Call 20200622_124844 +74999545237.wav имеет
длительность 281280 семплов. Второй файл Outgoing_Call
20200621_231753 +79536170218.wav имеет длительность 63360 семплов.
Первый трек с именем Первый (переименовал) содержит два клипа.
Первый клип смещён от начала сессии на 10 секунд (на 80000
семплов). Клип представлен полным содержимым первого аудиофайла, то
есть, длительность клипа совпадает с длительностью файла. Второй
клип смещён на 50 секунд от начала сессии (на 50*8000=400000
семплов). Клип представлен неполным содержимым второго аудиофайла.
Внутри данного клипа аудио начинается от начала файла, но длится
только 5 секунд (40000 семплов). То есть, длина клипа составляет 5
секунд. Второй трек с именем Второй содержит один клип. Он смещён
от начала сессии на одну секунду (на 8000 семплов). Данный клип
представлен неполным содержимым первого аудиофайла. Внутри данного
клипа аудио начинается не от начала, а спустя 3 секунды, но
содержит его до самого конца. Таким образом, смещение аудиоданных
внутри этого клипа составляет 3 секунды (24000 семплов). А длина
данного клипа вычисляется, как разность между длительностью
соответствующего аудио и смещением аудиоданных внутри клипа. В
данном случае длина клипа равняется 281280-24000 = 257280
семплам.
 Рис. 10. Вид мультисессии в Adobe Audition 1.5 Пример 2.
Рис. 10. Вид мультисессии в Adobe Audition 1.5 Пример 2.
На рисунке 11 представлен вид содержимого блока описания треков
trks. В красную рамку выделены 4 байта заголовка блока, в зелёную
размер содержимого блока. Об этом уже говорилось выше. Далее идёт
содержимое блока, байты которого выделены в редакторе WinHex
характерной голубоватой заливкой. Размер выделения, значение
которого отображается в нижнем правом углу редактора (также
обведено в зелёную рамку), совпадает со значением из байтов после
заголовка и уже в данном примере составляет 308 байт. Если в первом
(предыдущем) примере из одного трека размер блока составлял 156
байт, а в текущем 308 байт, то можно сделать следующий вывод. Ввиду
предположения об однородности и равнозначности треков, области
описания каждого трека должны иметь одинаковый размер. Данные
области, можно так сказать, являются субблоками блока trks. На
рисунке они обведены в синюю рамку. Выяснилось, что размер одного
такого субблока составляет 152 байта. А в самом начале идущих
подряд субблоков стоит подзаголовок из четырёх байт, отмеченных на
рисунке жёлтой заливкой. Эти четыре байта есть ничто иное, как
значение количества треков в мультисессии, или количества
субблоков. И так, размер S содержимого блока trks можно вычислить
по формуле S=4+152*n, где n число треков в сессии. Так оно и есть:
4+152*1=156, а 4+152*2=308.
 Рис. 11. Байты блока описания треков trks.
Рис. 11. Байты блока описания треков trks.
Теперь перейдём к описанию содержимого субблока. Там есть много
чего, но я расшифровал только самое необходимое. Это всего-навсего
три параметра: 4 байта двоичных флагов (обведено красным), имя
трека (обведено коричневым) и идентификатор трека (обведено
голубым). Идентификатором трека является его порядковый номер. Он
нужен для указания ссылки на трек в описании аудиоклипов (позже об
этом будет сказано). Имя трека занимает область в 36 байт. Это
максимальное число символов в имени трека, но оно может быть и
меньше, как в текущем примере. Незадействованные байты при этом
нулевые. В мультисессии с аудиозаписями телефонных звонков имена
треков будут совпадать с записью соответствующих дат. Можно
приписать рядом с датой соответствующий ей день недели двумя
заглавными буквами в сокращённом виде. Четыре байта двоичных флагов
(всего 32 флага) предназначены для описания двоичных параметров,
свойственных треку. На самом деле их может быть меньше, чем 32. Я
расшифровал только часть флагов. Из них как минимум три флага
указывают, активирован ли на треке параметр R (Record), S (Solo)
или M (Mute). В указанном примере ни одна из этих трёх кнопочек на
треках не нажата, а значение двоичных флагов равно нулю
(0x00000000). Но если нажать на треке кнопочку R (то есть,
поставить трек на запись) и заново сохранить сессию, то значение
двоичных флагов станет равно 0x00000004, иначе говоря, третий по
счёту бит справа (bit2) станет единичным. Именно этот бит и
отвечает за свойство трека запись. Данное свойство в моём проекте
не имеет никакого значения, так как моя мультисессия рассчитана на
визуальный просмотр и воспроизведение. Однако у меня появилась
идея, чтобы кнопочка R была нажата на тех треках, которые
соответствуют выходным дням. Этот приём позволит удобнее
визуализировать мультисессию.
Блок списка аудиофайлов мультисессии LISTFILE (рис. 12) состоит из
следующих частей. Как и в случае с блоком описания треков его также
можно разделить на субблоки по количеству файлов в сессии. По
аналогии с рисунком 11, я также выделил в красную рамку
восьмибайтный заголовок блока, а в зелёную рамку размер его
содержимого. В данном конкретном примере это значение составляет
188 байт. Содержимое выделено по аналогии с рис. 11. Оно разбито на
две зоны, выделенные синей линией. Это и есть субблоки блока списка
файлов.
 Рис. 12. Байты блока описания аудиофайлов LISTFILE.
Рис. 12. Байты блока описания аудиофайлов LISTFILE.
Каждый субблок соответствует одному аудиофайлу. В примере
используется два аудиофайла, поэтому количество субблоков
соответствующее. В отличие от предыдущего случая с описанием треков
здесь отсутствует подзаголовок о числе субблоков. В состав субблока
входят 4 байта его заголовка wav (выделено в чёрную рамку) и 4
байта, указывающие размер дальнейшего содержимого (выделено в
пурпурную рамку). Для обоих субблоков это значение в данном примере
одинаковое и составляет 0x56 (86) байт. Это связано с тем, что
файлы располагаются по одинаковому пути и имеют имена одинаковой
длины. Точнее говоря, полные имена файлов имеют одинаковое число
символов. В противном случае субблоки имели бы разный размер.
Область содержимого субблока (дальнейшие байты) содержит следующую
информацию. В голубую рамку выделено число, являющееся
идентификатором аудиофайла. В отличие от идентификатора трека,
данное число не является порядковым номером файла. Как я понял, при
сохранении мультисессии оно назначается случайно или псевдослучайно
для каждого файла. Главное, чтобы не было совпадения среди этих
значений. В этом я убедился, когда сохранил мультисессию дважды и
сравнил файлы ses по содержимому. В результате оказалось, что файлы
отличаются как раз на эти самые байты. И не только на эти.
Случайный номер назначается также идентификатору слоёв огибающих в
блоке ep20. Но в этом блоке, как уже говорилось выше, необходимость
напрочь отсутствует, и рассматриваться его описание в этой статье
не будет. Идентификаторы аудиофайлов нужны для их связки с клипами.
Данная связка происходит в блоке с описанием клипов. В своём случае
для мультисессии с записями телефонных разговоров идентификаторы
для аудиофайлов будут представлять собой последовательность
натуральных чисел, но начиная не с нуля, а, например, с 1000.
Следующие 4 байта, которые я не выделил, в обоих субблоках имеют
значение 0x13. Вероятнее всего, этим значением указывается тип
формата аудиофайла. Можно условно считать это значение константой,
так как все аудиофайлы у меня однотипные. Следующая цепочка байт
описывает полное имя аудиофайла с завершающим нулевым байтом (типа
признак конца строки). Размер этой цепочки на единицу больше, чем
число символов в полном имени аудиофайла. Далее идёт константа
0xFFFFFFFF. После неё следует значение, обозначающее число семплов
в данном аудиофайле (на рис. 12 выделено в жёлтую рамку). Для
первого файла это значение равняется 0x44AC0, а для второго 0xF780.
Они как раз соответствуют десятичным значениям 281280 и 63360
соответственно, которые уже фигурировали выше в описании второго
примера мультисессии.
Наконец, осталось рассмотреть описание самого сложного блока блока
описания аудиоклипов bk20 (рис. 13). По аналогии с предыдущими
двумя рисунками выделены заголовок и размер содержимого блока.
 Рис. 13. Байты блока описания аудиоклипов bk20.
Рис. 13. Байты блока описания аудиоклипов bk20.
В содержимом блока в первую очередь стоят два подзаголовка по 4
байта каждый. Они выделены пурпурной и голубой заливкой. Первый
подзаголовок число клипов в сессии. В примере их три. Второй
подзаголовок константа 0x48 (72). Видимо она обозначает размер
каждого субблока, а они как раз идут далее. Их число совпадает с
числом клипов в сессии. Каждый такой субблок описывает параметры
одного клипа. Кстати, размер D содержимого блока bk20, получается,
можно рассчитать по формуле D=8+72*b, где b количество аудиоклипов
в мультисессии. На рисунке отсутствуют поясняющие выделения байт
внутри субблоков, так как необходимых параметров получилось
достаточно много. Они вынесены в отдельную таблицу (рис. 14).
Голубой заливкой выделены те параметры, которые необходимы в моём
проекте, а серой заливкой неопознанные константы. Также в этой
таблице представлены значения параметров для каждого из трёх клипов
мультисессии из последнего примера.
 Рис. 14. Список параметров субблока описания аудиоклипа.
Рис. 14. Список параметров субблока описания аудиоклипа.
Первое слово (группа из 4-х байт) ссылка на огибающую, которая нам
не нужна. Второй параметр ссылка на аудиофайл. Значение данного
параметра равняется значению идентификатора того аудиофайла,
которому соответствует данный аудиоклип. Потом идут две
вещественные константы, которые уже фигурировали ранее. После них
идут три координирующих параметра, выраженные в числе семплов:
смещение клипа от начала сессии, длина (продолжительность) клипа в
сессии и смещение аудио внутри клипа. Из названия данных параметров
всё должно быть ясно. Чуть ранее при подробном описании второго
примера мультисессии я указывал числовые значения всех смещений и
продолжительностей. На рисунке 14 в таблице параметры для каждого
клипа указаны в шестнадцатеричной форме. Эти значения в таблицу я
заносил, переписывая их непосредственно из рисунка 13. Но если
преобразовать их в десятичную форму, то они совпадут с
соответствующими значениями из описания второго примера (проверял
отдельно). Стоит обратить внимание, что ссылки на аудиофайл у
первого и третьего клипов имею одно и то же значение 0x3F5B050, так
как оба клипа ссылаются на один и тот же аудиофайл с
соответствующим идентификатором. Затем следует блок байтов двоичных
параметров (4 байта). Как и в случае с описанием треков, я
расшифровал только часть битов. Значение по умолчанию составляет
0x00080000, то есть, если перевести в двоичную систему, то только
один bit19 поднят в единицу, а остальные 31 битов равны нулю. Без
данного единичного бита, как показала практика, мультисессия
загружаться отказывается. В текущем примере такое значение
свойственно первому и второму клипу, а вот у третьего почему-то
значение флагов равняется 0x000A0000. Если посчитать, то в этом
значении подняты два бита: по-прежнему bit19 и ещё bit17. Не знаю,
почему так получилось. Я попробовал сбросить bit17 в ноль, изменив
значение всего параметра на 0x00080000, как у соседних клипов. В
результате сессия в Adobe Audition открылась без видимых каких-либо
изменений. При работе в Adobe Audition я обратил внимание на такие
свойства клипов, как Фиксировать во времени и Фиксировать только
для воспроизведения. Логично предположить, что за сохранение данных
свойств отвечают какие-то определённые биты в блоке двоичных
параметров. Есть там ещё и другие двоичные свойства у клипов, но
они нам не требуются. А перечисленные два свойства будут весьма
полезны. Свойство Фиксировать во времени полезно тем, что клип
будет защищён от возможности случайного сдвига указателем мыши в
горизонтальном направлении. Но на таком клипе визуально в левом
нижнем углу будет нарисован символ в виде замка в кружочке, а это
лишняя для просмотра графическая информация. Второе свойство клипа
Фиксировать только для воспроизведения полезно тем, что при
активированном на соответствующем треке параметре R (Record) клип
не приобретёт принудительную красную окраску. Для чего я решил
использовать на некоторых треках параметр R написано выше. Опытным
путём я вычислил, что за первое свойство клипа отвечает bit1, а за
второе bit3. Из всего сказанного следует следующее. Чтобы присвоить
клипу свойство Фиксировать во времени, нужно записать в двоичные
параметры значение 0x00080002. Для свойства Фиксировать только для
воспроизведения 0x00080008. Для обоих свойств их логическую сумму
0x0008000A. С двоичными параметрами разобрались. После этих байтов
прописана ссылка на трек, на котором стоит клип. По сути дела
прописан идентификатор трека, совпадающий с его порядковым номером.
Программа Adobe Audition 1.5, кстати говоря, поддерживает не более
128 треков, поэтому такой идентификатор вписывается в один байт,
хотя и числится 32-разрядным значением. Затем идут нерасшифрованные
нулевые константы (4 константы по 4 байта каждая). Наконец,
последний значимый параметр цвет клипа. Редактор Adobe Audition 1.5
позволяет в соответствующем диалоговом окне выставить клипу
значение цвета от 0 до 239 или выбрать его из палитры (рис. 15).
Цветовая палитра особо не радует, но другие варианты не даны. Цвет
клипа по умолчанию 102 (0x66) (зелёненький).
 Рис. 15. Диалоговое окно выбора цвета аудиоклипа в Adobe
Audition 1.5.
Рис. 15. Диалоговое окно выбора цвета аудиоклипа в Adobe
Audition 1.5.
Параметр цвета в файле ses 32-разрядный, а цветов по факту всего
240, что помещается в один байт. Остальные три старших байта
нулевые. У меня была мысль, что если попробовать отредактировать
эти байты на другие значения, то при открытии мультисессии на клипе
появятся новые цвета. Но этот фокус не сработал. Как было сказано в
предыдущей статье, цвета на диаграмме полезны для визуального
выделения того или иного свойства телефонного вызова. Мультисессия
из аудиозаписей телефонных вызовов будет напоминать подобную
диаграмму, поэтому цвет клипов очень даже будет как нельзя кстати.
После параметра цвета клипа идут два слова из нулей. На этом
описание субблока завершено. Эти восемь байт нулей являются
последними в субблоке последнего блока. Следовательно, они же будут
последними во всём файле ses.
В процессе обдумывания проекта мне пришла ещё одна идея: добавить в
мультисессию маркеры (точки кью), расставив их через каждый час и
подписав к ним соответствующие метки. Если сравнивать эту мысль с
предыдущей статьёй, то это полная аналогия вертикальных линий на
диаграмме, расчерченных через каждый час. Для того чтобы в
мультисессии присутствовали точки кью, необходимо учесть шестой
блок под названием cues. Я не стал разбираться в байтах данного
блока. По аналогии с блоком stat, в созданной мультисессии на 24
часа я расставил 23 точки кью вручную через каждый час и дал им
соответствующие имена. Затем я сохранил мультисессию в отдельный
ses файл, вырезал содержимое блока cues и сохранил его в файл
cues_24h.BLK. При разработке программы этот файл будет учтён. Байты
этого файла показаны на рисунке 16. Не знаю почему, но сохранил я
именно содержимое, без заголовка и поля размера содержимого (в
отличие от stat_31_full.BLK). Эти два слова допишутся в коде
программы. А размер содержимого составляет 556 байт. Из них 4 байта
занимает подзаголовок (количество точек кью) и 23 субблока по 24
байта каждый. На рисунке 16 заливкой показаны байты содержимого
первого субблока. Имена точек кью (метки) я решил сделать такие:
01h, 02h,, 23h.
 Рис. 16. Байты содержимого блока точек кью cues для моей
мультисессии.
Рис. 16. Байты содержимого блока точек кью cues для моей
мультисессии.
На этом можно завершить описание формата мультисессии. Теперь
имеется необходимый багаж знаний, чтобы начать писать программу
формирования мультисессии. Написание программы более лёгкая задача,
по сравнению с изучением и расшифровкой формата ses. С программой я
справился за два вечера, а на изучение формата я потратил не меньше
одной недели. Тем более программу я писал, прибегая к ранее
используемым функциям, в частности, работы с файлами и каталогами.
Поэтому основной опорой для написания программы служили не
справочники или Интернет, а прошлые мои проекты, о которых я также
писал на хабре. Из Интернета я взял только одну функцию,
возвращающую день недели по дате. Но прежде чем привести текст
программы, я решил поделиться ещё кое-какой информацией, о чём я
изначально не хотел писать в этой статье.
Идея сформировать мультисессию из записей телефонных разговоров мне
пришла, когда я работал в более свежей версии программы Adobe
Audition 3.0, поддерживающий ввод/вывод звука через ASIO. При
сохранении мультисессии я обнаружил, что её можно сохранить на
выбор в двух форматах: обычный классический SES и новый формат XML,
чего не было в прошлых версиях программы. Сохранив сессию в XML
формате, я сразу же открыл этот файл в блокноте, где обнаружил
описание кучи параметров, связанных между собой в сложную
иерархическую структуру. Для удобства просмотра данной иерархии я
воспользовался программой WMHelp XmlPad. На рисунке 17 представлен
скриншот данной программы с открытым в нём файлом пробной простой
мультисессии. Слева представлена иерархия документа. Активным
(выбранным) элементом иерархии является параметр длины первого
аудиофайла, стоящий в первом субблоке блока описания
аудиофайлов.
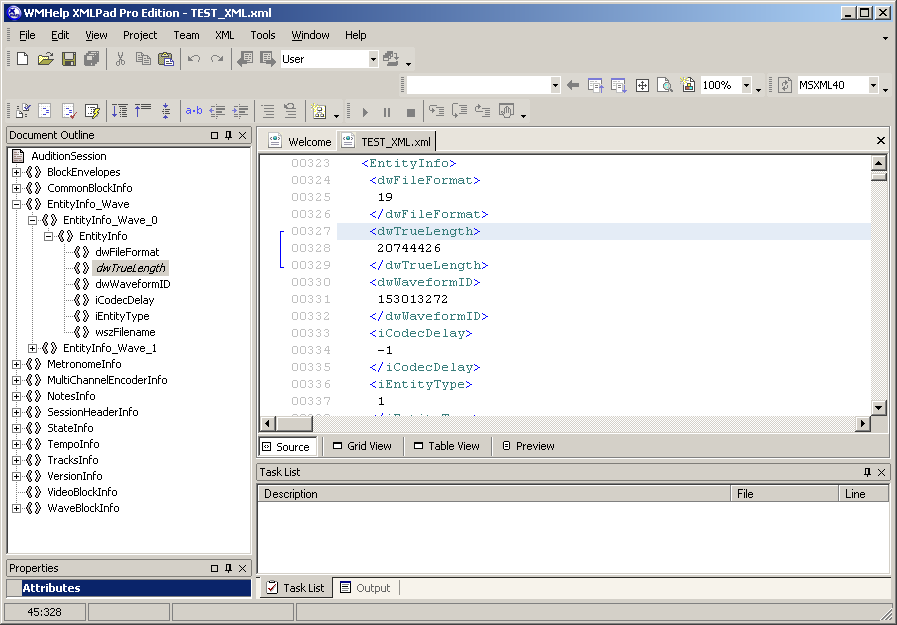 Рис. 17. Вид фрагмента XML мультисессии Adobe Audition
3.0.
Рис. 17. Вид фрагмента XML мультисессии Adobe Audition
3.0.
Я решил изучить именно этот формат, и в дальнейшем программно
генерировать нужный XML текст, получая на выходе нужную мне
мультисессию. Была даже идея воспользоваться для этих целей
программой Excel. Сложность была в том, что около 95% всего XML
файла занимает блок с описанием треков. Там колоссальное число
параметров, исключить которые без нанесения вреда мультисессии мне
не получилось. Дело в том, что в данной версии Adobe Audition
гораздо больше функций, относящихся к трекам. По логике вещей для
моей простой мультисессии в этих функциях нет никакой нужды.
Однако, исключая соответствующие поля из XML документа, сессия
перестаёт жить. И мне пришлось бы тянуть этот огромный кусок текста
в описании каждого трека для простейшей сессии. Это единственное
неудобство при формировании XML файла мультисессии. Знания,
полученные при изучении текстового XML варианта мультисессии,
безусловно, пригодились во время изучения бинарного ses. И даже в
XML некоторые параметры я не смог расшифровать. Поля каждого
параметра имеют сокращённое название на английском языке, но даже
при этом я не всегда понимал, что это за параметр. Главное мне
удалось изучить и расшифровать основные необходимые параметры, их
иерархические блоки и поля. Потом меня долго мучил вопрос: как
такую сессию открыть в более старой версии программы Adobe
Audition? Новые версии программ имеют слишком навороченный
интерфейс (чуть ли не 3D), что весьма неудобно для визуализации
мультисессии, как диаграммы. Да и из-за этого три-дэ в Adobe
Audition 3.0 при полностью развёрнутом окне на FullHD экране
помещается максимум (при минимальном масштабе) 28 треков. А в Adobe
Audition 1.5 помещалось бы 37 (рис. 18, масштаб 1:2). Всего же
нужно показать на экране 31 трек.
 Рис. 18. Сравнение фрагментов окон Adobe Audition двух разных
версий.
Рис. 18. Сравнение фрагментов окон Adobe Audition двух разных
версий.
Но больше всего меня добило качество звучания при воспроизведении
мультисессии с частотой 8000 Гц в новой версии программы. Звучание
не очень хорошее, присутствуют гармонические искажения. Это связано
с тем, что вывод звука производится на другой частоте семплов (48
кГц), а ASIO по-другому не может. При выборе в настройках другого
устройства вывода Audition 3.0 Windows Sound ситуация не
изменяется. Классические DirectSound устройства вывода новая версия
программы не поддерживает (версию 3.0 я называю новой). На рисунке
19 показан спектр звучания при воспроизведении в Adobe Audition 3.0
аудио 8 кГц (или сессии) с присутствующими гармоническими
искажениями в виде перевёрнутого спектра. Зелёным цветом обведены
те частоты, которые должны звучать в идеале (и ничего, кроме них).
А красным цветом обведены частоты, являющиеся дополнительным
искажением. Скорее всего этот эффект проявляется из-за отсутствия
фильтрации после процедуры апсемплинга. Именно после этого я решил
взяться за изучение бинарного формата SES более простой и приятной
программы Adobe Audition 1.5. Надеялся, что после изучения
человеческого XML формата от программы более новой версии мне не
составит особого труда в этом разобраться, учитывая опыт работы с
бинарными файлами. Так оно и вышло: я довольно быстро раскрутил SES
формат. И главное, что обратная совместимость, забегая вперёд,
вполне работает: сессия, сформированная для версии 1.5, успешно
открывается в версии 3.0. Выше я указал недостатки Adobe Audition
3.0, связанные с качеством звучания и графическим интерфейсом. Но у
этой версии программы есть преимущества в навигации по
мультисессии. Например, есть возможность оперативного прослушивания
одного аудиоклипа в мультисессии при клике по нему мышкой с
последующим сдвигом вправо.
 Рис. 19. Гармонические искажения при воспроизведении.
Рис. 19. Гармонические искажения при воспроизведении.
Теперь приведу текст программы под спойлером. Программа,
разумеется, не имеет графического интерфейса, так как для данной
задачи он и не требуется. Текст программы снабжён подробными
комментариями, поэтому в дополнительном пояснении не нуждается.
Программа запускается в командной строке и в течение секунды
обрабатывает список из четырёх сотен файлов, формируя файл
мультисесии. Внутри программы имеются четыре параметрические
переменные, которые при желании позволяют не формировать маркеры
кью, не ставить R на треки выходных дней, не ставить свойство
Фиксировать во времени на клипы и выбрать критерий раскраски клипов
(по типу вызова или по телефонным номерам). Данные три переменные
нужно было бы исключить из текста программы и вывести наружу, то
есть в отдельный файл с параметрами программы.
Исходный код программы на C
/********************************************************************В папке "RMC" на диске имеется множество папок, в которыхсодержатся файлы wav с записями телефонных звонков. Файлы имеют имяопределённого формата, который задаётся соответствующим приложением.Для удобства папки имеют имена в формате yyyy-mn, соответствующиегоду и месяцу. Внутри находятся записи за соответствующий срок.Программа при запуске запрашивает имя папки (т.е. год-месяц), из записейкоторой необходимо сформировать мультисессию. Результирующий файлсохраняется в том же каталоге, где расположена обрабатываемая папка,то есть в папке "RMC" на диске "I:".*********************************************************************/#include <windows.h>#include <stdio.h>#include <string.h>DWORD wr; //Сюда пишется, сколько байт прочитано;DWORD ww; //Сюда пишется, сколько байт записано;DWORD wi; //Сюда пишется, сколько байт записано;//День недели по дате (эту функцию я нашёл в интернете);int Date( int D, int M, int Y ){ int a, y, m, R; a = ( 14 - M ) / 12; y = Y - a; m = M + 12 * a - 2; R = 6999 + ( D + y + y / 4 - y / 100 + y / 400 + (31 * m) / 12 ); return R % 7;}//Открыть файл для чтения;HANDLE openInputFile(const char * filename) { return CreateFile ( filename, // Open Two.txt. GENERIC_READ, // Open for writing 0, // Do not share NULL, // No security OPEN_ALWAYS, // Open or create FILE_ATTRIBUTE_NORMAL, // Normal file NULL); // No template file }//Открыть файл для записи;HANDLE openOutputFile(const char * filename) { return CreateFile ( filename, // Open Two.txt. GENERIC_WRITE, // Open for writing 0, // Do not share NULL, // No security OPEN_ALWAYS, // Open or create FILE_ATTRIBUTE_NORMAL, // Normal file NULL); // No template file }//Перейти на позицию в файле;void filepos(HANDLE f, __int64 p){ LONG HPos; LONG LPos; HPos = p>>32; LPos = p; SetFilePointer (f, LPos, &HPos, FILE_BEGIN);}//Запись 32-битного целого числа;void write32(HANDLE f, signed long int a){ WriteFile(f, &a, 4, &ww, NULL); }//Заполнить одинаковыми байтами;void fill(HANDLE f, signed long int a, unsigned char c){ unsigned char i; for(i=0;i<c;i++){ write32(f,a); }}int main(){ HANDLE out; //Выходной файл мультисессии Adobe Audition; HANDLE stat; //Файл с готовым содержимым блока "stat" (+ заголовки); HANDLE cues; //Файл с готовым содержимым блока "cues"; HANDLE lf; //Файл для записи формируемого блока "LISTFILE"; HANDLE blk; //Файл для записи формируемого блока "bk20"; char* week[7]={"ПН", "ВТ", "СР", "ЧТ", "ПТ", "СБ", "ВС"}; //Дни недели по-русски; unsigned char dm[]={31,29,31,30,31,30,31,31,30,31,30,31}; //Число дней в месяцах; unsigned char p_cues=1; //Параметр: наличие ежечасных маркеров (cues); unsigned char p_R=1; //Параметр: визуальный флаг "R" (трек на запись) на трек выходного дня; unsigned char p_lock=1; //Параметр: фиксировать аудиоклипы во времени; unsigned char p_color=2; //Критерий цветовой раскраски аудиоклипов; unsigned char flg; //Вспомогательный флаг, нужен при сопоставлении тел. номеров с цветами; unsigned long int lfsize=0; //Размер блока "LISTFILE"; unsigned long int blksize=0; //Размер блока "bk20"; unsigned long int smp; //Число семплов ф аудиофайле; unsigned long int offset; //Смещение аудиоклипа от начала мультисессии; unsigned int cfile=0; //Число обработанных файлов; unsigned int cblk=0; //Число обработанных аудиоклипов; char name[100]; //Имя входного файла (и не только...); char fullname[100]; //Полное имя входного файла вместе с путём; char infld[8]; //Имя обрабатываемой папки; char number[11]; //Часть имени файла с тел. номером; unsigned char len; //Число символов в имени файла; printf("Input yyyy-dd name of folder:\n"); //Введите год и месяц; scanf("%s",infld); //Защита от некорректного ввода пока что отсутствует; WIN32_FIND_DATA fld; //Создаём структуру для доступа к атрибутам входных файлов; HANDLE hf; //Входной файл (в обработке не используется, так как нужны только атрибуты); char buf1[48],buf2[556]; //Вспомогательные буферы для копирования блоков "stat" и "cues"; char str[16]; //Буфер для имени трека; unsigned long int outpos=0; //Файловый курсор выходного файла; unsigned char byte; //Вспомогательная переменная для побайтного копирования блоков "LISTFILE" и "bk20"; unsigned char i; //Переменная для цикла; unsigned char mn,d,dw,h,m,s; //Переменные даты-времени; unsigned char cdm; //Число дней в выбранном месяце; int yy; //И отдельно год; yy=2000+(infld[2]-48)*10+(infld[3]-48); //Получаем год из входной строки; mn=(infld[5]-48)*10+(infld[6]-48); //Получаем месяц из входной строки; sprintf(name,"I:\\RMC\\%s.ses",infld); //Формируем полное имя выходного файла (с путём); out=openOutputFile(name); //Открываем выходной файл для записи; WriteFile(out, "COOLNESS", 8, &wi, NULL); //Начинаем формировать: сначала запишем главный заголовок; write32(out,0); //Пока пишем ноль (ибо не знаем, сколько будет весить весь файл); WriteFile(out, "hdr ", 4, &wi, NULL); //Далее, как по моей спецификации: блок заголовка; write32(out,936); //Размер блока заголовка статический, равен 936; write32(out,8000); //Частота семплов в мультисессии; write32(out,24*3600*8000); //Длинна мультисессии в семплах (соотв. 24 часам); write32(out,0); //Число аудиоблоков в сессии (пока неизвестно); write32(out,0x00010020); write32(out,0); write32(out,0x3ff00000); write32(out,0); write32(out,0x3ff00000); filepos(out,328); //Оставляем позади кучу нулей; write32(out,0x20); WriteFile(out, "Мастер", 6, &wi, NULL); //Так надо типа; filepos(out,376); //Оставляем позади кучу нулей; write32(out,0x3ff00000); filepos(out,892); //Оставляем позади кучу нулей; write32(out,0x0430041c); write32(out,0x04420441); write32(out,0x04400435); filepos(out,956); //Оставляем позади кучу нулей; stat=openInputFile("stat_31_full.BLK"); //Переписываем блок состояния сессии из заготовки, ReadFile(stat, &buf1, 48, &wr, NULL); //ибо я не заморачивался с его побайтным разбором; WriteFile(out, buf1, 48, &wi, NULL); CloseHandle(stat); if(mn==2){ //Если февраль, if(!(yy%4)){ //и если високосный год, cdm=29; //то 29 дней, }else{ cdm=28; //иначе - 28; } }else{ //Если не февраль, cdm=dm[mn-1]; //то число дней берём из заранее подготовленного массива; } WriteFile(out, "trks", 4, &wi, NULL); //Готовимся формировать блок с треками; write32(out,4+cdm*152); //Размер блока с треками можно расчитать так; write32(out,cdm); //Число треков соответствует числу дней в выбранном месяце; outpos=1016; //Не забываем обновлять переменную файлового курсора; for(i=0;i<cdm;i++){ //Цикл на число дней в выбранном месяце dw=Date(i+1,mn,yy); //Получам номер дня недели по дате; write32(out,0); //Такие константы часто втречаются в файле ses, но я не знаю что это такое; write32(out,0x3ff00000); write32(out,0); //Скорее всего это 8-байтовый тип double; write32(out,0x3ff00000); if((dw%7==5||dw%7==6)&&p_R){ //Если текущий трек - выходной день, и если разрешено ставить маркер "R", write32(out,4); //тогда тавим флаг для маркера "R", }else{ write32(out,0); //иначе - не ставим ничего; } sprintf(str,"%02d.%02d.%i %s",i+1,mn,yy,week[dw]); //Формируем имя трека, как моей душе угодно; WriteFile(out, str, strlen(str), &wi, NULL); filepos(out,1072+152*i); //Именно в этой позиции заканчивается имя (i+1)-го трека; write32(out,1); //Далее идут константы, в которых я не разбирался; write32(out,1); write32(out,4); write32(out,0); write32(out,0); write32(out,0x40590000); write32(out,0); write32(out,0); write32(out,0xffffff9d); write32(out,0xffffff9d); write32(out,i+1); //Приписываем идентификатор трека, как его порядковый номер; fill(out,0,11); write32(out,4); write32(out,0); outpos+=152; //Обновляем файловый курсор; } if(p_cues){ //Если задано в параметре расставить маркеры через каждый час, то формируем блок "cues"; WriteFile(out, "cues", 4, &wi, NULL); //Предварительно формируем заголовок, write32(out,556); //а также - размер содержимого; cues=openInputFile("cues_24h.BLK"); //Данный блок уже готовый, но без заголовка; ReadFile(cues, &buf2, 556, &wr, NULL); //(хотя можно было сделать полностью, как в "stat"); WriteFile(out, buf2, 556, &wi, NULL); CloseHandle(cues); outpos+=564; } DeleteFile("LISTFILE"); //Предварительно удалив (если они существуют от предыдущей работы программы) DeleteFile("bk20"); //временные файлы "LISTFILE" и "bk20", lf=openOutputFile("LISTFILE"); //открываем (создаём) их для накопления содержимым blk=openOutputFile("bk20"); //в результате сканирования папки с входными файлами; WriteFile(lf, "LISTFILE", 8, &wi, NULL); //Перед сканированием папки записывам заголовки блоков; WriteFile(blk, "bk20", 4, &wi, NULL); write32(lf,0); write32(blk,0); write32(blk,0); write32(blk,0x48); //Как я выяснил, это длина подблока для одного аудиоклипа; sprintf(name,"I:\\RMC\\%s\\*.wav",infld); //Шаблон поиска всех wav файлов в запрашиваемой папке; hf=FindFirstFile(name,&fld); //Ищем первый файл; do{ //Затем следующие файлы; len=strlen(fld.cFileName); //Число символов в имени файла; for(i=10;i>=1;i--){ //Переписываем последние 10 символов имени файла в буфер номера; number[10-i]=fld.cFileName[len-i-4]; //Без расширения файла; } number[10]=0; //Выставляем ноль в конце, как признак конца строки; cfile+=1; //Увеличиваем счётчик количества файлов; sprintf(fullname,"I:\\RMC\\%s\\%s",infld,fld.cFileName); //Формируем полное имя файла с путём; d=(fld.cFileName[22]-48)*10+(fld.cFileName[23]-48); //Вычисляем дату (день) из имени файла; h=(fld.cFileName[25]-48)*10+(fld.cFileName[26]-48); //Вычисляем час из имени файла; m=(fld.cFileName[27]-48)*10+(fld.cFileName[28]-48); //Вычисляем минуту из имени файла; s=(fld.cFileName[29]-48)*10+(fld.cFileName[30]-48); //Вычисляем секунду из имени файла; offset=(h*3600+m*60+s)*8000; //Вычисляем смещение аудиоклипа в сессии; smp=(fld.nFileSizeLow-44)/4; //Вычисляем длительность аудио в семплах (псевдовычисление через размер файла); WriteFile(lf, "wav ", 4, &wi, NULL); //Начинаем формировать запись подблока списка файлов; write32(lf,17+strlen(fullname)); //Запись размера подблока (его можно вычислить именно так); write32(lf,1000+cfile); //Идентификатор файла (можно рандомно, но я решил начать с 1000 и по порядку); write32(lf,0x14); //Тип файла (формат аудио); WriteFile(lf, fullname, strlen(fullname), &wi, NULL); //Путь к файлу (полное имя); WriteFile(lf, "\0", 1, &wi, NULL); //Конец строки полного имени; write32(lf,0xffffffff); //Отступ; write32(lf,smp); //Длительность аудио в семплах; lfsize+=(25+strlen(fullname)); //Обновляем размер блока "LISTFILE"; cblk+=1; //Формируем блок аудиоклипа на текущий аудиофайл; write32(blk,0); //Здесь должна быть ссылка на огибающую, но они в нашей задаче не востребованы; write32(blk,1000+cfile); //Ссылка на аудиофайл (соответствие); write32(blk,0); //Опять те самые константы; write32(blk,0x3ff00000); write32(blk,0); write32(blk,0x3ff00000); write32(blk,offset); //Записываем смещение аудиоклипа в мультисессии; if(((24*3600*8000)-offset)>smp){ //Если аудиофайл (по длительности) не выходит на следующие сутки, write32(blk,smp); //оставляем длительность аудиоклипа в мультисессии полной, }else{ write32(blk,(24*3600*8000)-offset); //иначе обрезаем длительность аудиоклипа на конце текущих суток; } write32(blk,0); //Начало аудиоклипа совпадает с началом аудиофайла; if(p_lock){ //Если в параметре задана фиксация аудиоклипов во времени, write32(blk,0x0008000a); //дополняем флаговый блок соответствующим битом (3 бита из 32 установлены), }else{ write32(blk,0x00080008); //иначе оставляем без этого бита(2 бита из 32 установлены); } //Один из двух битов выше - флаг свойства "клип только для воспроизведения"; write32(blk,d); //Ссылка на трек (соответствует дате); fill(blk,0,4); //Куча нулей; switch(p_color){ //Признак цветовой раскраски аудиоклипов; case 1: //Входящий или исходящий вызовы; switch(fld.cFileName[0]){ //Анализируем первый символ в имени файла; case 'I': //Если "I" (псевдо признак входящего вызова), write32(blk,0); //записываем красный цвет; break; case 'O': //Если "O" (псевдо признак исходящего вызова), write32(blk,102); //записываем зелёный цвет (значение по умолчанию); break; default: //Если вдруг что-то другое, write32(blk,102); //оставляем значение по умолчанию; break; } break; case 2: //Раскраска по номерам; flg=0; //Сбрасываем флаг; if(!strcmp("9530000000",number)){ //Если такой-то такой-то номер, write32(blk,05); //то цвет такой-то такой-то, flg=1; //(номер найден); } #include "numbers_and_colors.cpp" //Код со списком номеров и цветов - в отдельном файле (продолжение); if(!flg){ //Если флаг не поменял значение (номер не был найден в списке), write32(blk,102); //оставляем цвет клипа по умолчанию; } break; } write32(blk,0); write32(blk,0); if(((24*3600*8000)-offset)<=smp){ //Если аудиофайл (по длительности) выходит на следующие сутки (редкий случай), cblk+=1; //формируем ещё один аудиоклип на текущий файл; write32(blk,0); //Далее всё по аналогии, как выше; write32(blk,1000+cfile); write32(blk,0); write32(blk,0x3ff00000); write32(blk,0); write32(blk,0x3ff00000); write32(blk,0); //Но теперь данный аудиоклип ставится в самое начало мультисесисии, write32(blk,smp-((24*3600*8000)-offset)); //по длине на оставшееся время, write32(blk,(24*3600*8000)-offset); //и звучит не сначала аудиофайла, а как продолжение предыдущего аудиоклипа; if(p_lock){ write32(blk,0x0008000a); }else{ write32(blk,0x00080008); } write32(blk,d+1); //Ставим второй (дополнительный) аудиоклип на следующий трек (день); fill(blk,0,4); switch(p_color){ //В зависимости от параметра критерия раскраски; case 1: //Раскраска по типу вызова; switch(fld.cFileName[0]){ //Распознаём по первому симполу в имени файла (псевдо признак); case 'I': //Если входящий, write32(blk,0); //то цвет красный; break; case 'O': //Если исходящий, write32(blk,102); //то цвет зелёный, как по умолчанию; break; default: //Если вдруг что-то ещё (не дай бог), write32(blk,102); //то цвет по умолчанию; break; } break; case 2: //Раскраска по номерам; flg=0; if(!strcmp("9530000000",number)){ //Если такой-то такой-то номер, write32(blk,05); //то цвет такой-то такой-то, flg=1; //(номер найден); } #include "numbers_and_colors.cpp" //и так для всех раскрашиваемых номеров (во вложении); if(!flg){ //Если номер не найден, write32(blk,102); //то цвет по умолчанию; } break; } write32(blk,0); write32(blk,0); } }while(FindNextFile(hf,&fld)); //Пока не кончатся все wav файлы; filepos(lf,8); write32(lf,lfsize); //Записываем размер блока "LISTFILE", который накапливали в переменную; filepos(blk,4); blksize=8+72*cblk; //Расчитываем размер блока "bk20", зная количество аудиоклипов; write32(blk,blksize); //Записываем размер блока "bk20"; write32(blk,cblk); //Записываем количество аудиоклипов; blksize+=8; //Корректируем размер блока "bk20", чтобы приравняться к размеру соотв. временного файла; lfsize+=12; //Корректируем размер блока "LISTFILE", чтобы приравняться к размеру соотв. временного файла; CloseHandle(lf); //Закрываем врем. файл; CloseHandle(blk); //Закрываем врем. файл; lf=openInputFile("LISTFILE"); //Открываем врем. файл на чтение для перезаписи в основной; do{ //Перезапись происходит побайтно, пока не конец файла (есть байты на чтение); ReadFile(lf, &byte, 1, &wr, NULL); if(wr){ WriteFile(out, &byte, 1, &wi, NULL); } }while(wr); CloseHandle(lf); //Закрываем врем. файл; blk=openInputFile("bk20"); //Открываем врем. файл на чтение для перезаписи в основной; do{ //Перезапись происходит побайтно, пока не конец файла (есть байты на чтение); ReadFile(blk, &byte, 1, &wr, NULL); if(wr){ WriteFile(out, &byte, 1, &wi, NULL); } }while(wr); CloseHandle(blk); //Закрываем врем. файл; outpos=outpos+blksize+lfsize; //Обновляем файловый курсор выходного файла; filepos(out,8); write32(out,outpos-12); //Записываем в начале выходного файла размер содержимого; filepos(out,28); write32(out,cblk); //Записываем в блок главного заголовка число аудиоклипов; CloseHandle(out); //Выходной файл мультисессии готов! Закрываем его; printf("c_files: %i\nc_block: %i\n",cfile,cblk); //Выводим информацию на экран (число файлов и клипов); system("PAUSE"); return 0;}
Теперь можно привести скриншоты с результатами. Их будет несколько:
в разных масштабах просмотра, в разных версиях программы и с
разными критериями раскраски. Обрабатывался каталог 2020-05, то
есть, записи за май текущего года. Всего обработано 446 записей.
Количество блоков такое же, так как записи с переходом на новые
сутки отсутствуют.
 Рис. 20. Вид мультисессии в полном масштабе с раскраской по тел.
номерам.
Рис. 20. Вид мультисессии в полном масштабе с раскраской по тел.
номерам.
 Рис. 21. Вид мультисессии в полном масштабе с раскраской по типу
вызова.
Рис. 21. Вид мультисессии в полном масштабе с раскраской по типу
вызова.
 Рис. 22. Вид мультисессии в среднем масштабе.
Рис. 22. Вид мультисессии в среднем масштабе.
 Рис. 23. Вид мультисессии в крупном масштабе.
Рис. 23. Вид мультисессии в крупном масштабе.
 Рис. 24. Вид той же мультисессии в Adobe Audition 3.0.
Рис. 24. Вид той же мультисессии в Adobe Audition 3.0.

 Код
Код



























 Какие языки выбрать для локализации
сервиса, приложения или игры?
Какие языки выбрать для локализации
сервиса, приложения или игры?
 Диаграмма 1. Самые популярные языки для
локализации с английского
Диаграмма 1. Самые популярные языки для
локализации с английского
 Диаграмма 2. Пять самых популярных
языков для локализации с английского: распределение долей
Диаграмма 2. Пять самых популярных
языков для локализации с английского: распределение долей
 Диаграмма 3. Локализация с английского на
китайский: нюансы
Диаграмма 3. Локализация с английского на
китайский: нюансы








 Первые три строки таблицы с данными
Первые три строки таблицы с данными






 Схема волны цунами
Схема волны цунами

 Группа
Lordi в текущем составе
Группа
Lordi в текущем составе
, Нико Хурме (Калма) и Леэна Пейса (Ава) уже не в группе, поэтому им можно показывать лица, а самому Mr. Lordi нельзя") Если что, это старый состав группы. Сампса
Астала (Кита), Нико Хурме (Калма) и Леэна Пейса (Ава) уже не в
группе, поэтому им можно показывать лица, а самому Mr. Lordi нельзя
Если что, это старый состав группы. Сампса
Астала (Кита), Нико Хурме (Калма) и Леэна Пейса (Ава) уже не в
группе, поэтому им можно показывать лица, а самому Mr. Lordi нельзя



 Рис.1. Преобразование данных в аналитику в
BI-системах
Рис.1. Преобразование данных в аналитику в
BI-системах
 Рис 2. Для каких задач внедряют BI-системы
Рис 2. Для каких задач внедряют BI-системы
 Рис 3.
Преимущества BI-систем
Рис 3.
Преимущества BI-систем
 Рис.4.
Объем рынка BI-систем
Рис.4.
Объем рынка BI-систем
 Рис
5. BI-системы как часть бизнеса
Рис
5. BI-системы как часть бизнеса
 Рис 6. Эффекты от внедрения BI-систем для компаний
Рис 6. Эффекты от внедрения BI-систем для компаний
 Рис.7. Интерактивность современных BI-систем
Рис.7. Интерактивность современных BI-систем
 Рис.8. Разница между традиционной и
self-service BI-системами
Рис.8. Разница между традиционной и
self-service BI-системами
 Рис.9. Эволюция аналитики в BI-системы и
в Augmented Business Intelligence
Рис.9. Эволюция аналитики в BI-системы и
в Augmented Business Intelligence
 Рис.10. Инновационность ABI-систем
Рис.10. Инновационность ABI-систем
 Рис.11. Отличия BI-системы от ABI-системы
и ее преимущества
Рис.11. Отличия BI-системы от ABI-системы
и ее преимущества
 Рис.12. Тренды в развитии BI-систем
Рис.12. Тренды в развитии BI-систем
 Рис.13. Концепция DIKW
Рис.13. Концепция DIKW
 Рис. 14. Визуальное потребление информации
Рис. 14. Визуальное потребление информации
 Рис.15.
Инструментарий DataViz
Рис.15.
Инструментарий DataViz
 Рис.16. Преимущества 3D-визуализации
Рис.16. Преимущества 3D-визуализации
 Рис.17. Пример 3D визуализации данных на
карте для визуализации данных в проекте с Ingrad
Рис.17. Пример 3D визуализации данных на
карте для визуализации данных в проекте с Ingrad
 Рис.18. Пример интерактивных BIM-моделей зданий
Рис.18. Пример интерактивных BIM-моделей зданий
 Рис. 19. Фокусирование внимания
пользователя на данных с помощью анимации
Рис. 19. Фокусирование внимания
пользователя на данных с помощью анимации
 Рис.20. Феномен data storytelling
Рис.20. Феномен data storytelling
 Рис.21. Уникальные черты и roadmap
разработанной кроссплатформенной BI-системы для Ingrad
Рис.21. Уникальные черты и roadmap
разработанной кроссплатформенной BI-системы для Ingrad


















































































 данные сервиса аналитики SellerFox в
категории "Гели для душа" маркетплейса OZON, период с 12.01 -
11.02.2021
данные сервиса аналитики SellerFox в
категории "Гели для душа" маркетплейса OZON, период с 12.01 -
11.02.2021
 данные сервиса аналитики SellerFox в
категории "Гели для душа" маркетплейса OZON, период с
04.02-11.02.2021
данные сервиса аналитики SellerFox в
категории "Гели для душа" маркетплейса OZON, период с
04.02-11.02.2021
 данные сервиса аналитики SellerFox в
категории "Гели для душа" OZON, срез по продавцам, период с
12.01-11.02.21
данные сервиса аналитики SellerFox в
категории "Гели для душа" OZON, срез по продавцам, период с
12.01-11.02.21
 самый популярный товар на OZON в
категории "Гели для душа" OZON, период с 12.01-11.02, данные
SellerFox
самый популярный товар на OZON в
категории "Гели для душа" OZON, период с 12.01-11.02, данные
SellerFox



 данные сервиса SellerFox в категории
"Женская одежда-Чулки, носки, колготки" маркетплейса OZON
данные сервиса SellerFox в категории
"Женская одежда-Чулки, носки, колготки" маркетплейса OZON

 данные сервиса SellerFox в категории
"Чулки, носки, колготки" OZON, срез по продавцам, период с
12.01-11.02.21
данные сервиса SellerFox в категории
"Чулки, носки, колготки" OZON, срез по продавцам, период с
12.01-11.02.21
 данные сервиса SellerFox в категории
"Мужская одежда-Домашняя обувь" маркетплейса OZON, период с 12.01 -
11.02
данные сервиса SellerFox в категории
"Мужская одежда-Домашняя обувь" маркетплейса OZON, период с 12.01 -
11.02

 самый популярный товар на OZON в
категории "Мужская одежда-Домашняя обувь", период с 12.01-11.02.21
самый популярный товар на OZON в
категории "Мужская одежда-Домашняя обувь", период с 12.01-11.02.21

 данные сервиса SellerFox в категории
"Женская одежда-Домашняя обувь" маркетплейса OZON, период с 12.01 -
11.02
данные сервиса SellerFox в категории
"Женская одежда-Домашняя обувь" маркетплейса OZON, период с 12.01 -
11.02
 данные сервиса SellerFox в категории
"Мягкие игрушки" маркетплейса OZON, период с 12.01 - 11.02
данные сервиса SellerFox в категории
"Мягкие игрушки" маркетплейса OZON, период с 12.01 - 11.02
 самый популярный товар на OZON в
категории "Мягкие игрушки", период с 13.01-12.02.21, данные
SellerFox
самый популярный товар на OZON в
категории "Мягкие игрушки", период с 13.01-12.02.21, данные
SellerFox