

Наверняка многие из вас листая западные научные издания видели красивые и простые графики. Возможно некоторые из вас задумывались в чём же эти учёные мужи визуализируют свою данные. И вот есть шикарный и очень простой инструмент для построения графиков, который есть практически везде: Windows, linux, android, и прочих, уверен даже есть под ДОС. Он надёжен, прост и позволяет представить в виде красивых графиков любые текстовые-табличные данные.
Почему именно gnuplot?
Многие из вас, кто читают мои статьи видели красивые графики, которые привожу в них: Одновременный speedtest на нескольких LTE-модемах, Гармонические колебания, Создаём аппаратный генератор случайных чисел.

График из поста про генератор случайных чисел

Картинка из поста про speetest модемов
Графики простые и классные. А главное для их построения вам нужен только текстовый файл с исходными данными, gnuplot на вашей любимой ОС (хоть OpenWRT) и любимый тестовый редактор
На первый взгляд может показаться, что gnuplot сложнее в использовании для построения графиков чем MS Exel. Но это только так кажется, порог вхождения чуть выше (это вам не мышкой наклацать, тут надо документацию читать), но на практике выходит намного проще и удобнее. Один раз написал скрипт и используешь его всю жизнь. Мне реально намного сложнее построить график в Exel, где всё не логично, нежели в gnuplot. А главное преимущество gnuplot, то что его можно встраивать в свои программы и на ходу визуализировать данные. Так же gnuplot мне без особых проблем строил график с 30-ти гигабайтового файла статистических данных, тогда как Exel просто падал и не мог его открыть.
К плюсам gnuplot можно отнести что он легко интегрируется в языки программирования. Есть готовые библиотеки для многих языков, лично я сталкивался с php и python. Таким образом можно генерировать графики прямо из своей программы.
Для примера скажу, что моя хорошая подруга, когда писала диссертацию освоила gnuplot (с моей подачи). Она ни разу не технарь, но разобралась за один вечер. После чего строила графики только там, и уровень её работы сразу выгодно отличался от других, кто использует Exel. Лично для меня показатель качества научной работы, когда графики строятся в специализированных программах.
Таким образом, это просто, доступно и красиво. Едем дальше.
Gnuplot применение
Работа с gnuplot возможно двумя способами: командный режим и режим выполнения скриптов. Рекомендую сразу использовать второй режим, как наиболее удобный и быстрый. Тем более, что функционал абсолютно тот же.
Но для старта погоняем gnuplot в командном режиме. Запускаем gnuplot из командной строки, либо тем способом который предлагает ваша ОС. Обучение можно начать даже не с чтения этой статьи, а прямо с самой первой команды help. Она выведет шикарную справку и дальше по ней можно идти. Но мы пробежимся по основным моментам.
График строится командой plot. В качестве параметров команды можно задать функцию, либо имя файла данных. А так же какой столбец данных использовать и чем соединять точки, как их обозначать и т.д. Давайте проиллюстрирую.
gnuplot> plot sin(x)
После выполнения команды у нас откроется окно, где будет график синуса, с подписями по умолчанию. Давайте улучшим этот график, заодно разберёмся с дополнительными опциями.
Подпишем оси.
set xlabel "X"
Задает подпись для оси абсцисс.
set ylabel "Y"
Задает подпись для оси ординат.
Добавим сетку, чтобы было видно где построен график.
set grid
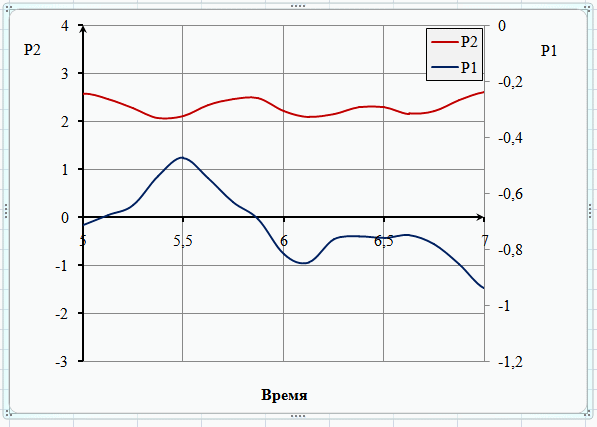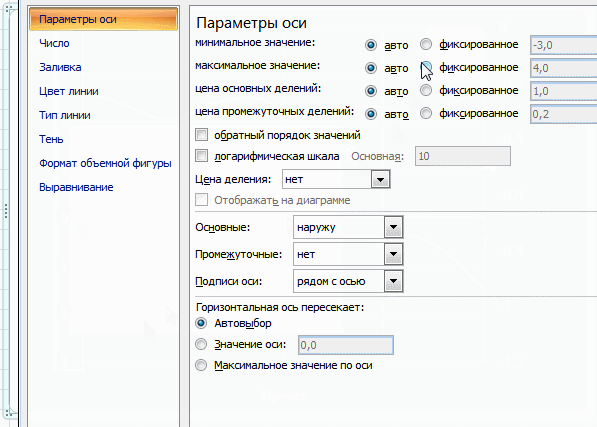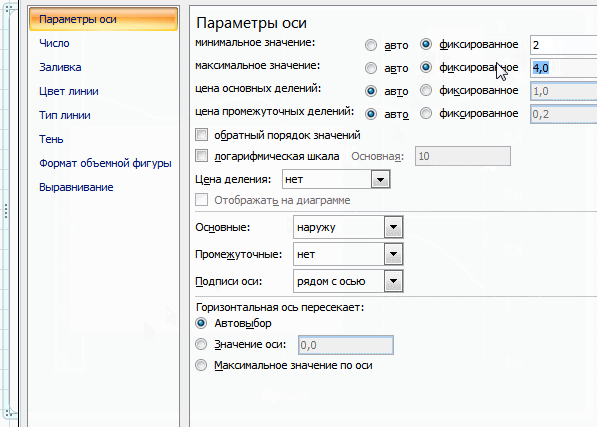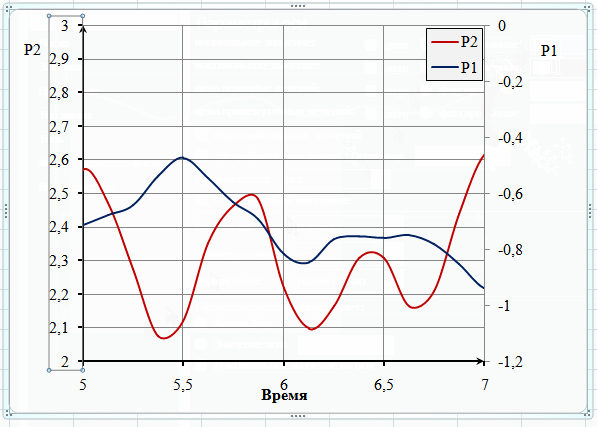
Мне не нравится, что по оси ординат синусоида у меня упирается в конец графика, поэтому зададим лимиты значений, которые будет отображены на графике.
set yrange [-1.1:1.1]
Таким образом график у нас будет отрисован от минимального значения -1,1 до максимального 1,1.
Точно так же, хочу задать оси абсцисс, чтобы был виден только один период синусоиды.
set xrange[-pi:pi]
Надо бы добавить заголовок к нашему графику, чтобы всё по феншую было.
set title "Gnuplot for habr" font "Helvetica Bold, 20"
Обратите внимание, что можно задавать шрифты и их размер. Какие шрифты можно использовать, смотрите в документации на gnuplot.
Ну и наконец, давайте кроме синуса на графике ещё нарисуем и косинус, да ещё и зададим тип линии и её цвет. А так же добавим легенды, что же мы чертим.
plot sin(x) title "sinux" lc rgb "red", cos(x) title "cosinus" lc rgb "green"
Здесь мы рисуем два графика на одном холсте, красным и зелёным цветом. Вообще вариантов линий (пунктир, штрих, сплошная), тощин линий, цветов великое множество. Как и типов точек. Моя цель лишь продемонстрировать возможности. Сведём все команды в одну кучку. И выполним их последовательно. Чтобы сбросить предыдущие настройки, введём reset.
resetset xlabel "X" set ylabel "Y"set gridset yrange [-1.1:1.1]set xrange[-pi:pi]set title "Gnuplot for habr" font "Helvetica Bold, 20"plot sin(x) title "sinux" lc rgb "red", cos(x) title "cosinus" lc rgb "green"
В результате получаем вот такую красоту.

График уже не стыдно опубликовать в научный журнал.
Если вы повторяли честно всё это за мной, то могли заметить, что вручную каждый раз вводить это, даже копируя, как-то не комильфо. Но это же готовый скрипт? Так давайте же его и сделаем!
Выходим из командного режима, командой exit и создаём файл:
vim testsin.gpi
#! /usr/bin/gnuplot -persistset xlabel "X" set ylabel "Y"set gridset yrange [-1.1:1.1]set xrange[-pi:pi]set title "Gnuplot for habr" font "Helvetica Bold, 20"plot sin(x) title "sinux" lc rgb "red", cos(x) title "cosinus" lc rgb "green"
Делаем его исполняемым и запускаем.
chmod +x testsin.gpi./testsin.gpi
В результате получаем такое же окно с графиками. Если в заголовке не добавить -persis, то окно автоматически закроется после выполнения скрипта.
Но окно создавать часто не очень нужно, плюс не всегда удобно им пользоваться. Значительно чаще нужно получать графические файлы. Лично я предпочитаю формат postscript, так как при большом количестве точек можно приближать различные участки графика, без потери данных. И так же просмоторщик в линуксе автоматически обновляет окно с графиком, при изменении файла, что тоже весьма удобно.
Для того, чтобы вывести данные в файл, а не на экран, надо переназначить терминал.
set terminal png size 800, 600set output "result.png"
Как не трудно догадаться, указываем тип файла, его разрешение, затем указываем имя файла. Добавляем эти две строки в начало нашего скрипта, и получаем эту картинку.

Для того, чтобы сохранять в postscript использую такие команды:
set terminal postscript eps enhanced color solidset output "result.ps"
Реальные данные
Синусы, косинусы рисовать конечно прикольно, но всё же реальные данные рисовать намного интереснее! Напомню недавнюю задачу, о которой писал статью это выводить графики скорости в зависимости от времени. Формат данных там был следующий.
Operator; #Test; Date; Time; Coordinates; Download Mb/s; Upload Mb/s; ping; Testserver
Rostelecom;0;21.05.2020;09:56:00;NA, NA;3.7877656948451692;5.231226008184113;132.227;MaximaTelecom (Moscow) [0.12 km]: 132.227 ms
Rostelecom;1;21.05.2020;10:01:02;NA, NA;5.274994541394363;5.1088572634075815;127.52;MaximaTelecom (Moscow) [0.12 km]: 127.52 ms
Rostelecom;2;21.05.2020;10:04:35;NA, NA;3.61044819424076;4.624132180211938;135.456;MaximaTelecom (Moscow) [0.12 km]: 135.456 ms
Видно, что разделителем у нас служит точка с запятой, нам нужно вывести скорость загрузки, скорость выгрузки в зависимости от времени. При этом, если обратить внимание дата и время находятся в разных столбцах. Сейчас расскажу, как я это обошёл. Сразу приведу скрипт, по которому строился график.
#! /usr/bin/gnuplot -persistset terminal postscript eps enhanced color solidset output "Rostelecom.ps"#set terminal png size 1024, 768#set output "Rostelecom.png" set datafile separator ';'set grid xtics yticsset xdata timeset timefmt '%d.%m.%Y;%H:%M:%S'set ylabel "Speed Mb/s"set xlabel 'Time'set title "Rostelecom Speed"plot "Rostelecom.csv" using 3:6 with lines title "Download", '' using 3:7 with lines title "Upload" set title "Rostelecom 2 Ping"set ylabel "Ping ms"plot "Rostelecom.csv" using 3:8 with lines title "Ping"
В начале файла мы задаём выходной файл postscript (либо png, если будет нужен).
set datafile separator ';' мы задаём символ разделитель. По умолчанию столбцы разделяет пробел, но csv-файл предлагает множество вариантов разделителей, и нужно уметь использовать все.
set grid xtics ytics устанавливаем сетку (можно сетку установить только по одной оси).
set xdata time это важный момент, мы говорим о том, что по оси X формат данных будет время.
set timefmt '%d.%m.%Y;%H:%M:%S' задаём формат данных времени. Обратите внимание, что не смотря на то что разделитель у нас идёт ";", она входит в строку дата-время. Хотя столбец будет другой.
Задаём подписи осей и графика. После чего строим график.
plot Rostelecom.csv using 3:6 with lines title Download, '' using 3:7 with lines title Upload на одном графике мы строим как скорость скачивания, так и скорость отдачи. Using 3:6 это номер столбца в нашем файле исходных данных, что от чего строим (X:Y).
Далее так же точно строим график для пинга. Результирующий график будет выглядеть следующим образом.

Это скриншот с postscript. Прямые линии в графике связанны с тем, что там данных не было. Вот вполне реальный пример построения графика.
А 3D???
Вы хотите 3D? Их есть у меня!
Долго думал, какой же пример трёхмерного графика привести, и не придумал ничего лучше, чем визуализировать картинку. Ведь по сути картинка это трёхмерный график, где яркость пикселя это координата по z. Поэтому давайте немного похулиганим.
Возьмём самое знаменитое фото Эйнштейна.

И сделаем из него график. Для этого конвертнём его в формат pgm ASCII и выкинем все пробелы, заменив переводом строки, такой простой командой.
convert Einstein.jpg -compress none pgm:- | tr -s '\012\015' ' ' | tr -s ' ' '\012'> outfile.pgm
Кто не понял, что здесь происходит, поясняю: мы конвертируем с помощью imagemagic картинку в формат pgm, а потом с помощью tr заменяем перевод каретки с пеносом на новую строку на пробел, а потом все пробелы на перенос каретки и сохраняем это всё в outfile.pgm. Кому это сложно, могут открыть файл в gimp и экспортировать его как pgm-ASCII.
После чего открываем получившийся файл нашим любимым редактором
f = open('outfile.pgm')for x in range(408):for y in range(325):line = f.readline()print ('%d %d %s' % (x, y, line)),f.close()
Сохраняем его как convert.py и запускаем:
python convert.py > res.txt
Всё, у нас теперь res.txt содержит координаты Эйнштейна Хм, ну точнее сказать координаты его изображения. Ну в общем, вы поняли :).
406 317 60
406 318 54
406 319 30
406 320 41
406 321 84
406 322 101
406 323 112
406 324 119
407 0 128
407 1 53
407 2 89
407 3 95
407 4 87
...
Пример файла.
Скрипт для построения этой красоты выглядит следующим образом.
#! /usr/bin/gnuplot -persist#set terminal png size 1024, 768#set output "result.png"#set grid xtics ytics#set terminal postscript eps enhanced color solid#set output "result.ps"set title "Albert Einstein"set palette grayset hidden3dset pm3d at bsset dgrid3d 100,100 qnorm 2set xlabel "X" font "Helvetica Bold,18"set ylabel "Y" rotate by 90 font "Helvetica Bold,18"set zlabel "Z" font "Helvetica Bold,18"set xrange [0:408]set yrange [0:325]set zrange [-256:256]unset key splot "./res.txt" with l
Прежде чем мы пойдём разбирать скрипт, если вы будете это повторять, то настоятельно рекомендую выполнить строки скрипта в командном режиме, чтобы можно было мышкой вращать график (разумеется не указывая set terminal). Это очень круто!
Вначале мы устанавливаем тип выходных данных, а так же границы данных. Границы выставлены по размерам картинки, и плюс от низа я отступил по оси Z на 256 символов, чтобы была видна проекция картинки. Дальше мы озаглавливаем график, подписываем оси. Командой unset key я отключаю легенды (она не нужна на графике). А вот далее идёт настоящая магия!
set palette gray мы задаём палитру. Если оставить по умолчанию, то график будет цветным, как тепловизоре. Чем выше, тем более жёлтое пятно, чем ниже тем темнее красный цвет.
set hidden3d как бы натягивает изогнутую поверхность (удаляет линии), таким образом формируется красивая изгнутая повехность.
set pm3d at bs включаем стиль рисования трёхмерный данных, который рисует данные с координатой сеткой и цветом. Более детально читайте в документации, более детальное описание выходит за рамки статьи.
set dgrid3d 100,100 qnorm 2 устанавливаем размер ячеек сетки 100х100, и сглаживание между ячейками. Значение 100х100 и так очень большое, и программа сильно тормозит. qnorm 2 это сглаживание (интерполяция данных между ячейками).
splot "./res.txt" with l рисуем получившийся график. With l, потому что точки видны на графике (можно задать маленькие точки).
После запуска ждём некоторое время, и получаем картинку, как в заголовке. Попробуйте поиграться с настройками и получить другие данные.

Изображение в командном режиме, после того как повращали.
Тут вспоминается сразу анекдот.
Как найти площадь Ленина?
Только необразованный человек ответит на этот вопрос, что нужно высоту Ленина умножить на ширину Ленина.
Образованный человек знает, что нужно взять интеграл по поверхности.
Применение gnuplot в своих программах
Пример взят со stackoverflow небольшими моими доработками.
Код генерирует текстовый файл и постоянно вызывает перестроение графика. Код приложу под спойлер, чтобы не рвать статью.
Пример кода на Си использующего gnuplot
#include <stdio.h>#include <stdlib.h>#include <unistd.h>float s=10.;float r=28.;float b=8.0/3.0;/* Definimos las funciones */float f(float x,float y,float z){ return s*(y-x);}float g(float x,float y,float z){ return x*(r-z)-y;}float h(float x,float y,float z){ return x*y-b*z;}FILE *output;FILE *gp;int main(){ gp = popen("gnuplot -","w"); output = fopen("lorenzgplot.dat","w"); float t=0.; float dt=0.01; float tf=30; float x=3.; float y=2.; float z=0.; float k1x,k1y,k1z, k2x,k2y,k2z,k3x,k3y,k3z,k4x,k4y,k4z; fprintf(output,"%f %f %f \n",x,y,z); fprintf(gp, "splot './lorenzgplot.dat' with lines \n");/* Ahora Runge Kutta de orden 4 */ while(t<tf){ /* RK4 paso 1 */ k1x = f(x,y,z)*dt; k1y = g(x,y,z)*dt; k1z = h(x,y,z)*dt; /* RK4 paso 2 */ k2x = f(x+0.5*k1x,y+0.5*k1y,z+0.5*k1z)*dt; k2y = g(x+0.5*k1x,y+0.5*k1y,z+0.5*k1z)*dt; k2z = h(x+0.5*k1x,y+0.5*k1y,z+0.5*k1z)*dt; /* RK4 paso 3 */ k3x = f(x+0.5*k2x,y+0.5*k2y,z+0.5*k2z)*dt; k3y = g(x+0.5*k2x,y+0.5*k2y,z+0.5*k2z)*dt; k3z = h(x+0.5*k2x,y+0.5*k2y,z+0.5*k2z)*dt; /* RK4 paso 4 */ k4x = f(x+k3x,y+k3y,z+k3z)*dt; k4y = g(x+k3x,y+k3y,z+k3z)*dt; k4z = h(x+k3x,y+k3y,z+k3z)*dt; /* Actualizamos las variables y el tiempo */ x += (k1x/6.0 + k2x/3.0 + k3x/3.0 + k4x/6.0); y += (k1y/6.0 + k2y/3.0 + k3y/3.0 + k4y/6.0); z += (k1z/6.0 + k2z/3.0 + k3z/3.0 + k4z/6.0); /* finalmente escribimos sobre el archivo */ fprintf(output,"%f %f %f \n",x,y,z); fflush(output); usleep(10000); fprintf(gp, "replot \n"); fflush(gp); t += dt; } fclose(gp); fclose(output); return 0;}
Код работает очень просто, мы открываем pipe:
gp = popen("gnuplot -","w");
Это аналогично вертикальной черте в bash, когда мы за одной командой пишем другую. Только в условиях программы. Пишем данные в файл lorenzgplot.dat. Один раз вызываем в gnuplot команду splot:
fprintf(gp, "splot './lorenzgplot.dat' with lines \n");
И далее при добавлении новой точки, мы перестраиваем график.
fprintf(gp, "replot \n");
В результате получаем очень красивое медленное построение Аттрактора Лоренца. Ниже видео, снятое почти десять лет назад, на старенький фотоаппарат, поэтому не ругайтесь сильно. Важно в видео другое, что всё это прекрасно работает на таком старом железе, как Nokia N800. Смотреть это желательно без звука.
Важно понимать, что команда replot очень хорошо кушает память и процессорное время, то есть, вот такое построение графика некисло так подтормаживает систему. Так что, при всей любви к gnuplot это не лучший способ его использования. Ещё одна проблема, что данное окно не удастся не закрыть ни передвинуть.
Заключение
Напоследок хочу показать видео, в котором я собрал сотни графиков случайного логарифмического распределения регистраций радиоактивных частиц, реальные данные одного исследования. Видео можно и нужно смотреть со звуком.
В этой статье не смог рассказать и тысячной доли возможностей данного графопостроителя, разве что немного ознакомил читателя с данной программой. Далее вам следует самостоятельно искать примеры, читать документацию на официальном сайте gnuplot.sourceforge.net либо www.gnuplot.info. Обязательно загляните в примеры, там очень много интересного и полезного.
Для старта так же могу порекомендовать Краткое введение в gnuplot (рус). Искренне удивлён, что такая замечательная программа не изучается во всех технических ВУЗах наравне с Latex. У нас зачем-то учили MS Exel и Word.
Изучить gnuplot не сложно, я потратил буквально несколько дней в попытке разобраться с нуля. Но с данной статьёй, верю, что у вас всё будет быстрее. Теперь я забыл о всяких Exel/Calc в качестве графопостроителей, использую только гнуплот. Тем более, что я даже не знаю и десятой доли всех возможностей построения графиков.
Хочу отметить, что существуют множество других графопостроителей, не хуже, чем гнуплот, тем более, что он достаточно старый. Но для меня gnuplot оказался наиболее простым и исчерпывающим. Плюс он самый распространённый графопостроитель, и в сети громадное количество примеров его использования. Спасибо что дочитали!

















































 Первые три строки таблицы с данными
Первые три строки таблицы с данными






 Схема волны цунами
Схема волны цунами

 Группа
Lordi в текущем составе
Группа
Lordi в текущем составе
, Нико Хурме (Калма) и Леэна Пейса (Ава) уже не в группе, поэтому им можно показывать лица, а самому Mr. Lordi нельзя") Если что, это старый состав группы. Сампса
Астала (Кита), Нико Хурме (Калма) и Леэна Пейса (Ава) уже не в
группе, поэтому им можно показывать лица, а самому Mr. Lordi нельзя
Если что, это старый состав группы. Сампса
Астала (Кита), Нико Хурме (Калма) и Леэна Пейса (Ава) уже не в
группе, поэтому им можно показывать лица, а самому Mr. Lordi нельзя

![|g(x)|=|f(x)cos[f(x)]|](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/df6/f19/f53/df6f19f53cb770f27ae8857b578a6a3f.svg)
![Рисунок 1 - График функций f(x)=35/x и |g(x)|=|f(x)cos[f(x)]|](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/e43/ea9/d01/e43ea9d01ef16cf978bee48e69743f1b.png "Рисунок 1 - График функций f(x)=35/x и |g(x)|=|f(x)cos[f(x)]|") Рисунок 1 - График функций f(x)=35/x и
|g(x)|=|f(x)cos[f(x)]|
Рисунок 1 - График функций f(x)=35/x и
|g(x)|=|f(x)cos[f(x)]|
![Рисунок 2 - График функции f(x)cos[f(x)]^10](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/dfb/b26/ee0/dfbb26ee0a865751b569026b90cd015a.png "Рисунок 2 - График функции f(x)cos[f(x)]^10") Рисунок 2 - График функции f(x)cos[f(x)]^10
Рисунок 2 - График функции f(x)cos[f(x)]^10
![Рисунок 3 - Фильтрация f(x)cos[f(x)]^10 с помощью sin(nx/2)](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/003/b37/2be/003b372beb393480a1b8cb6f6a6b9c2c.png "Рисунок 3 - Фильтрация f(x)cos[f(x)]^10 с помощью sin(nx/2)") Рисунок 3 - Фильтрация f(x)cos[f(x)]^10 с
помощью sin(nx/2)
Рисунок 3 - Фильтрация f(x)cos[f(x)]^10 с
помощью sin(nx/2)
=105/x и возможные делители") Рисунок 4 - Гипербола f(x)=105/x и возможные
делители
Рисунок 4 - Гипербола f(x)=105/x и возможные
делители=105/x и возможные делители (продолжение)") Рисунок 5 - Гипербола f(x)=105/x и
возможные делители (продолжение)
Рисунок 5 - Гипербола f(x)=105/x и
возможные делители (продолжение)
 Рисунок 6 - Множители чисел 21, 77, 187,
323, 437 в 3D.
Рисунок 6 - Множители чисел 21, 77, 187,
323, 437 в 3D.






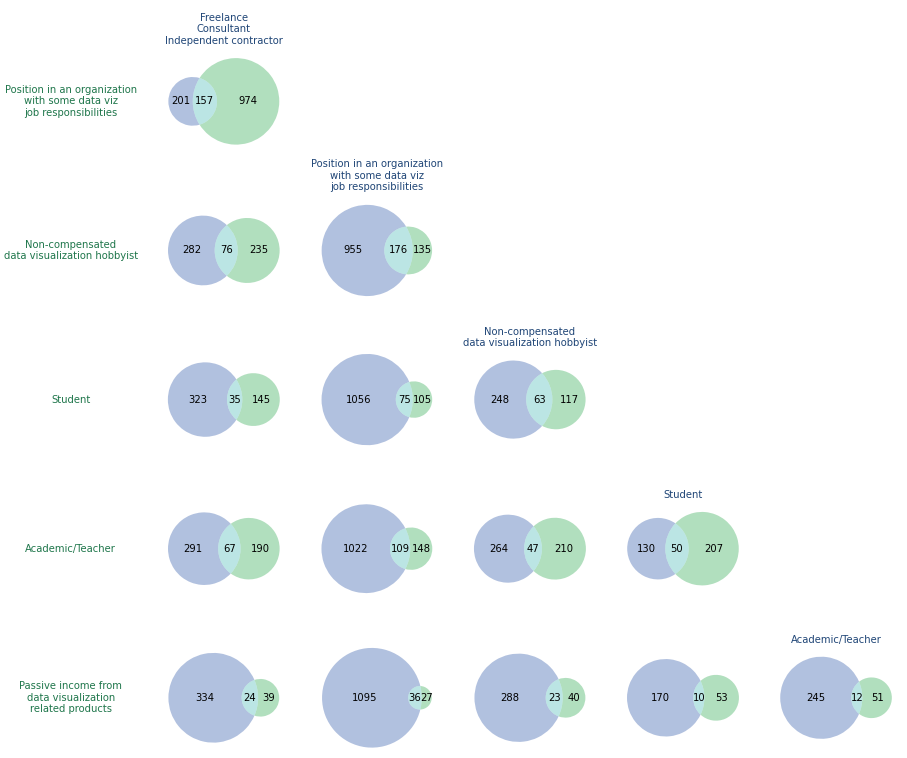

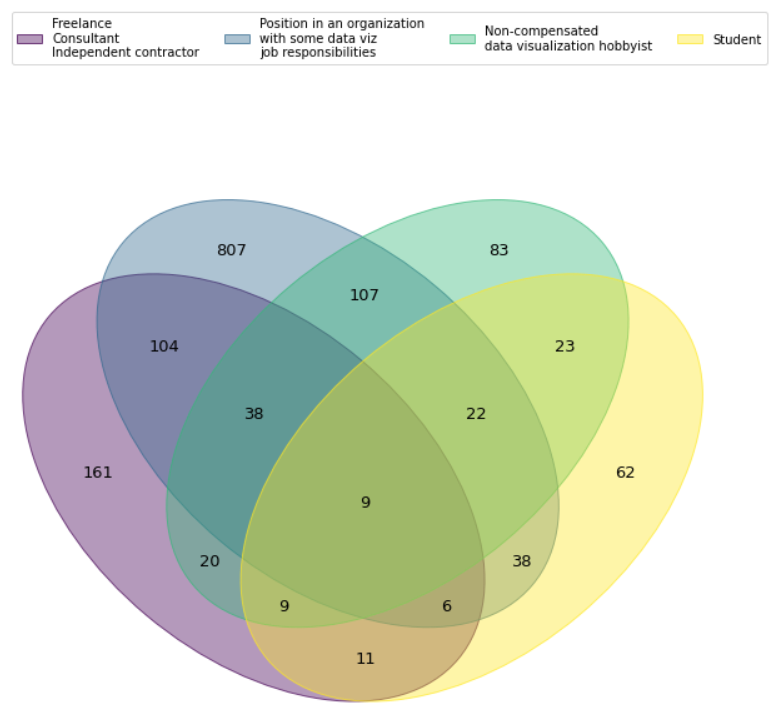

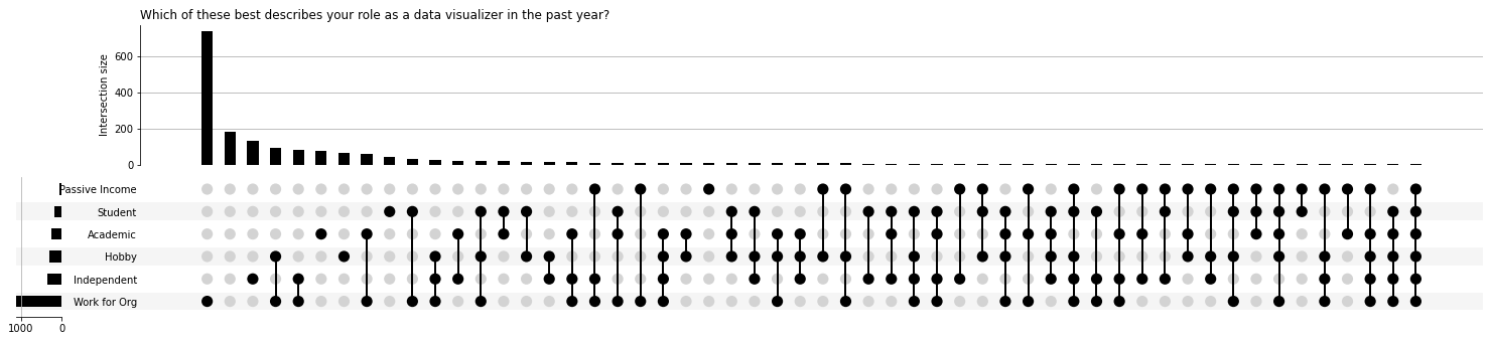


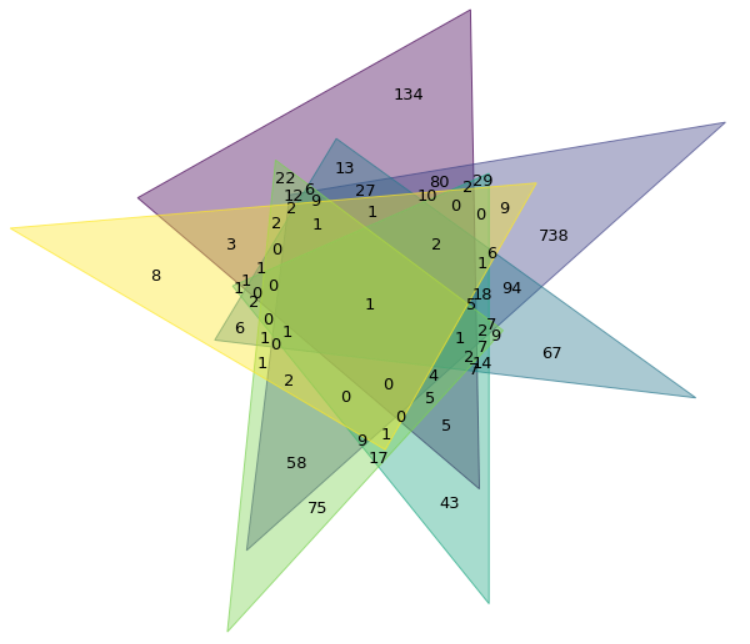






 Данные отчетов компании Data Insight
Данные отчетов компании Data Insight
 Данные отчета компании PIM Solutions
Данные отчета компании PIM Solutions
 Данные отчета компании PIM Solutions
Данные отчета компании PIM Solutions
 Данные отчета компании PIM Solutions
Данные отчета компании PIM Solutions
 Данные отчета Data Insight
Данные отчета Data Insight
 Данные
отчета Pim Solutions
Данные
отчета Pim Solutions Данные
отчета Pim Solutions
Данные
отчета Pim Solutions
 Данные сервиса аналитики SellerFox
Данные сервиса аналитики SellerFox
 Данные сервиса аналитики SellerFox
Данные сервиса аналитики SellerFox
 Данные сервиса аналитики SellerFox
Данные сервиса аналитики SellerFox
 Данные сервиса аналитики SellerFox
Данные сервиса аналитики SellerFox